Линейная регрессия используется для поиска линии, которая лучше всего «соответствует» набору данных.
Мы часто используем три разных значения суммы квадратов , чтобы измерить, насколько хорошо линия регрессии действительно соответствует данным:
1. Общая сумма квадратов (SST) – сумма квадратов разностей между отдельными точками данных (y i ) и средним значением переменной ответа ( y ).
- SST = Σ(y i – y ) 2
2. Регрессия суммы квадратов (SSR) – сумма квадратов разностей между прогнозируемыми точками данных (ŷ i ) и средним значением переменной ответа ( y ).
- SSR = Σ(ŷ i – y ) 2
3. Ошибка суммы квадратов (SSE) – сумма квадратов разностей между предсказанными точками данных (ŷ i ) и наблюдаемыми точками данных (y i ).
- SSE = Σ(ŷ i – y i ) 2
Между этими тремя показателями существует следующая зависимость:
SST = SSR + SSE
Таким образом, если мы знаем две из этих мер, мы можем использовать простую алгебру для вычисления третьей.
SSR, SST и R-квадрат
R-квадрат , иногда называемый коэффициентом детерминации, является мерой того, насколько хорошо модель линейной регрессии соответствует набору данных. Он представляет собой долю дисперсии переменной отклика , которая может быть объяснена предикторной переменной.
Значение для R-квадрата может варьироваться от 0 до 1. Значение 0 указывает, что переменная отклика вообще не может быть объяснена предикторной переменной. Значение 1 указывает, что переменная отклика может быть полностью объяснена без ошибок с помощью переменной-предиктора.
Используя SSR и SST, мы можем рассчитать R-квадрат как:
R-квадрат = SSR / SST
Например, если SSR для данной модели регрессии составляет 137,5, а SST — 156, тогда мы рассчитываем R-квадрат как:
R-квадрат = 137,5/156 = 0,8814
Это говорит нам о том, что 88,14% вариации переменной отклика можно объяснить переменной-предиктором.
Расчет SST, SSR, SSE: пошаговый пример
Предположим, у нас есть следующий набор данных, который показывает количество часов, отработанных шестью разными студентами, а также их итоговые оценки за экзамены:
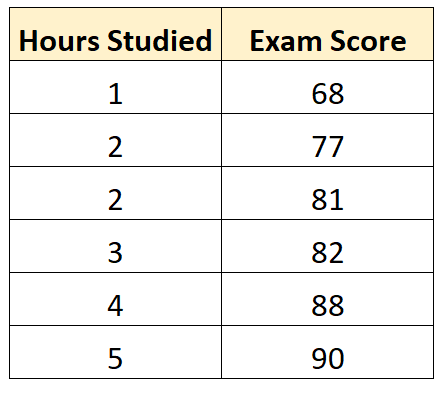
Используя некоторое статистическое программное обеспечение (например, R , Excel , Python ) или даже вручную , мы можем найти, что линия наилучшего соответствия:
Оценка = 66,615 + 5,0769 * (часы)
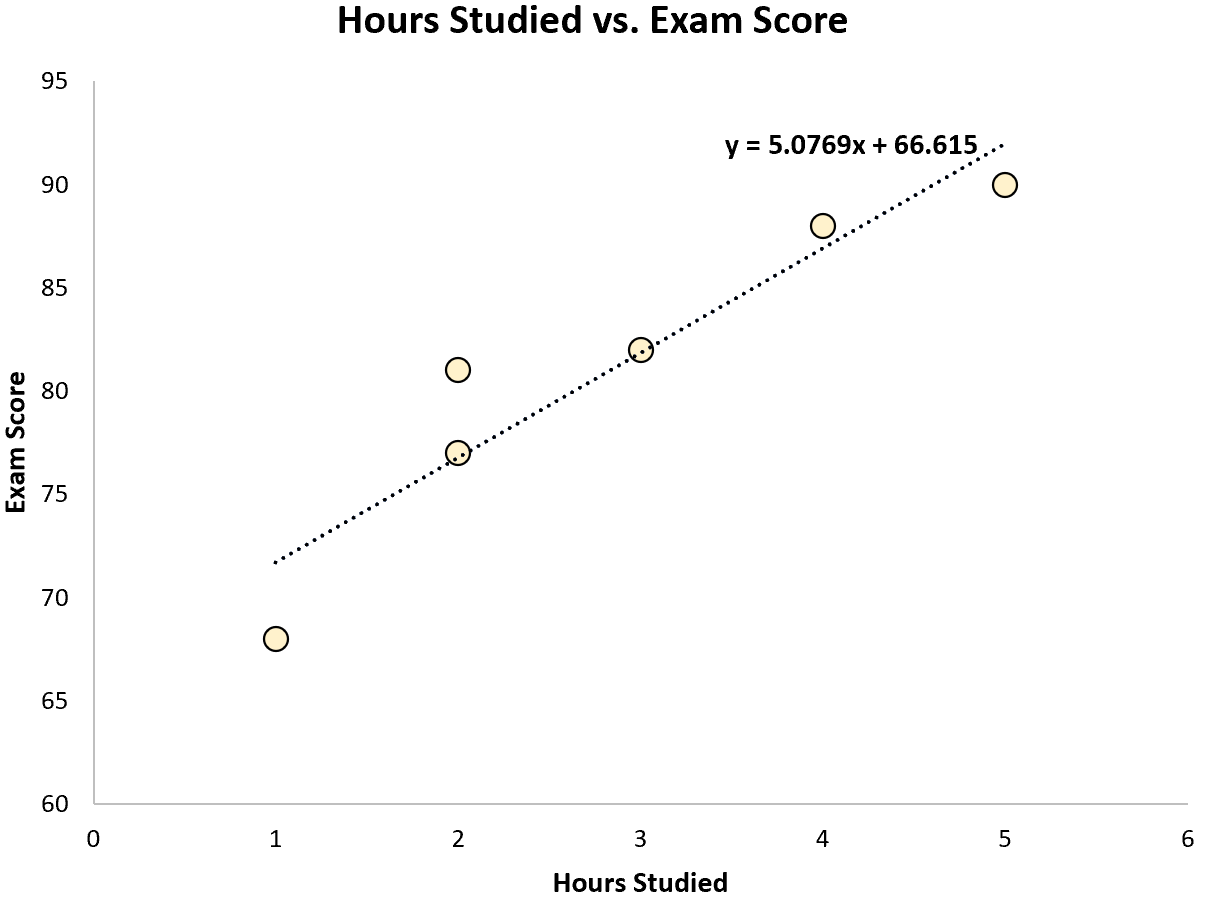
Как только мы узнаем строку уравнения наилучшего соответствия, мы можем использовать следующие шаги для расчета SST, SSR и SSE:
Шаг 1: Рассчитайте среднее значение переменной ответа.
Среднее значение переменной отклика ( y ) оказывается равным 81 .
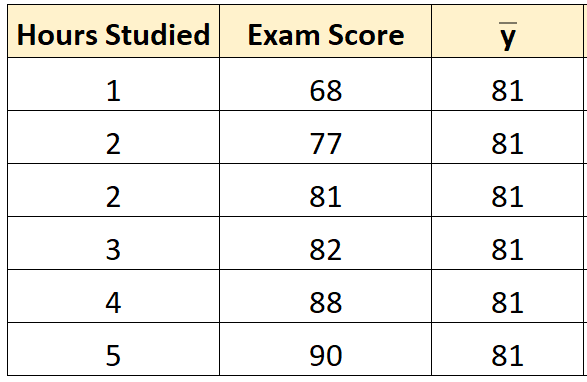
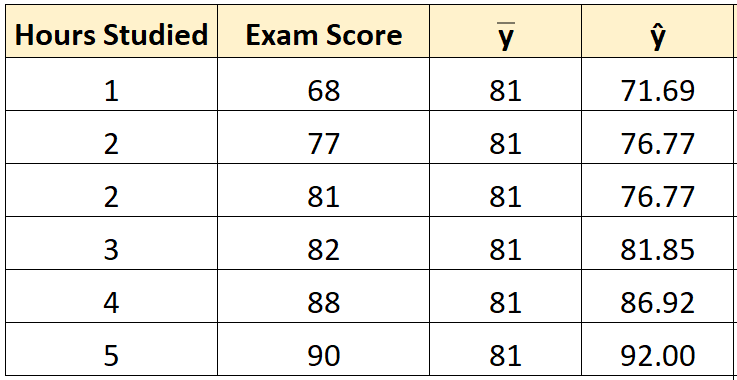
Шаг 2: Рассчитайте прогнозируемое значение для каждого наблюдения.
Затем мы можем использовать уравнение наилучшего соответствия для расчета прогнозируемого экзаменационного балла () для каждого учащегося.
Например, предполагаемая оценка экзамена для студента, который учился один час, такова:
Оценка = 66,615 + 5,0769*(1) = 71,69 .
Мы можем использовать тот же подход, чтобы найти прогнозируемый балл для каждого ученика:
Шаг 3: Рассчитайте общую сумму квадратов (SST).
Далее мы можем вычислить общую сумму квадратов.
Например, сумма квадратов для первого ученика равна:
(y i – y ) 2 = (68 – 81) 2 = 169 .
Мы можем использовать тот же подход, чтобы найти общую сумму квадратов для каждого ученика:
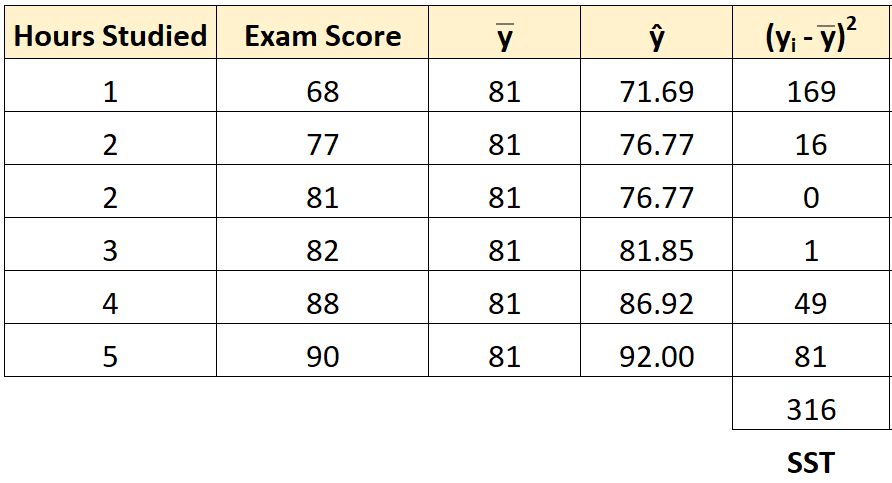
Сумма квадратов получается 316 .
Шаг 4: Рассчитайте регрессию суммы квадратов (SSR).
Далее мы можем вычислить сумму квадратов регрессии.
Например, сумма квадратов регрессии для первого ученика равна:
(ŷ i – y ) 2 = (71,69 – 81) 2 = 86,64 .
Мы можем использовать тот же подход, чтобы найти сумму квадратов регрессии для каждого ученика:
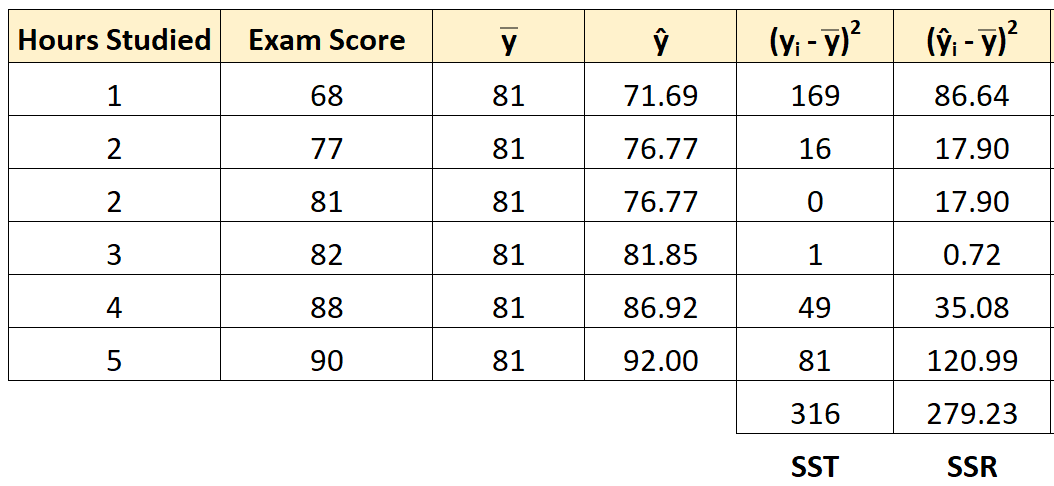
Сумма квадратов регрессии оказывается равной 279,23 .
Шаг 5: Рассчитайте ошибку суммы квадратов (SSE).
Далее мы можем вычислить сумму квадратов ошибок.
Например, ошибка суммы квадратов для первого ученика:
(ŷ i – y i ) 2 = (71,69 – 68) 2 = 13,63 .
Мы можем использовать тот же подход, чтобы найти сумму ошибок квадратов для каждого ученика:
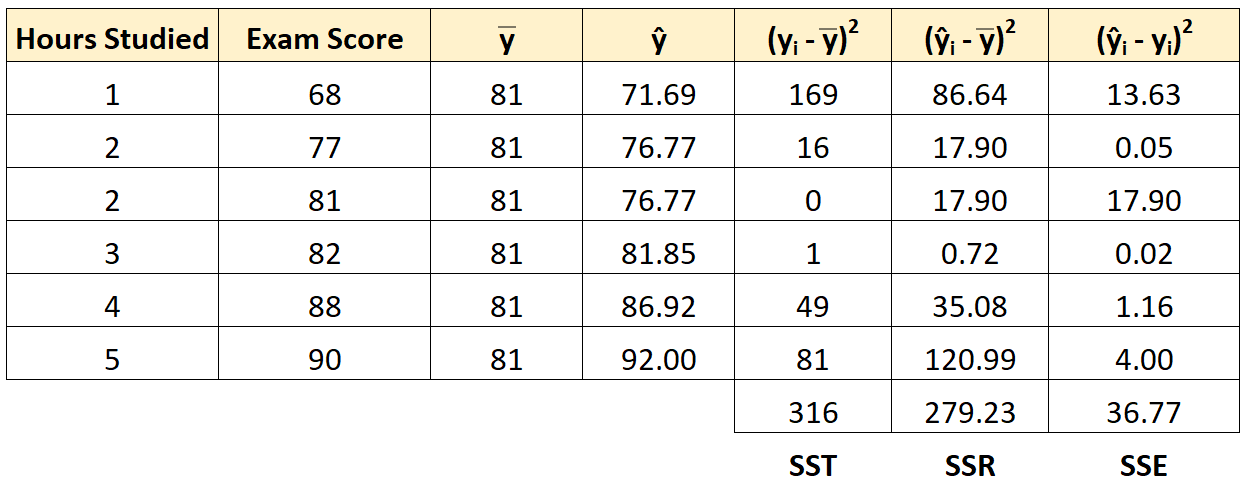
Мы можем проверить, что SST = SSR + SSE
- SST = SSR + SSE
- 316 = 279,23 + 36,77
Мы также можем рассчитать R-квадрат регрессионной модели, используя следующее уравнение:
- R-квадрат = SSR / SST
- R-квадрат = 279,23/316
- R-квадрат = 0,8836
Это говорит нам о том, что 88,36% вариаций в экзаменационных баллах можно объяснить количеством часов обучения.
Дополнительные ресурсы
Вы можете использовать следующие калькуляторы для автоматического расчета SST, SSR и SSE для любой простой линии линейной регрессии:
Калькулятор ТПН
Калькулятор ССР
Калькулятор SSE
![]()
Download Article
![]()
Download Article
The sum of squared errors, or SSE, is a preliminary statistical calculation that leads to other data values. When you have a set of data values, it is useful to be able to find how closely related those values are. You need to get your data organized in a table, and then perform some fairly simple calculations. Once you find the SSE for a data set, you can then go on to find the variance and standard deviation.
-

1
Create a three column table. The clearest way to calculate the sum of squared errors is begin with a three column table. Label the three columns as
,
, and
.[1]
-

2
Fill in the data. The first column will hold the values of your measurements. Fill in the
- In this case, suppose you are working with some medical data and you have a list of the body temperatures of ten patients. The normal body temperature expected is 98.6 degrees. The temperatures of ten patients are measured and give the values 99.0, 98.6, 98.5, 101.1, 98.3, 98.6, 97.9, 98.4, 99.2, and 99.1. Write these values in the first column.
Advertisement
-

3
Calculate the mean. Before you can calculate the error for each measurement, you must calculate the mean of the full data set.[3]
-

4
Calculate the individual error measurements. In the second column of your table, you need to fill in the error measurements for each data value. The error is the difference between the measurement and the mean.[4]
- For the given data set, subtract the mean, 98.87, from each measured value, and fill in the second column with the results. These ten calculations are as follows:
-

5
Calculate the squares of the errors. In the third column of the table, find the square of each of the resulting values in the middle column. These represent the squares of the deviation from the mean for each measured value of data.[5]
- For each value in the middle column, use your calculator and find the square. Record the results in the third column, as follows:
-

6
Add the squares of errors together. The final step is to find the sum of the values in the third column. The desired result is the SSE, or the sum of squared errors.[6]
- For this data set, the SSE is calculated by adding together the ten values in the third column:

Advertisement
-

1
Label the columns of the spreadsheet. You will create a three column table in Excel, with the same three headings as above.
- In cell A1, type in the heading “Value.”
- In cell B1, enter the heading “Deviation.»
- In cell C1, enter the heading “Deviation squared.”
-

2
Enter your data. In the first column, you need to type in the values of your measurements. If the set is small, you can simply type them in by hand. If you have a large data set, you may need to copy and paste the data into the column.
-

3
Find the mean of the data points. Excel has a function that will calculate the mean for you. In some vacant cell underneath your data table (it really doesn’t matter what cell you choose), enter the following:[7]
- =Average(A2:___)
- Do not actually type a blank space. Fill in that blank with the cell name of your last data point. For example, if you have 100 points of data, you will use the function:
- =Average(A2:A101)
- This function includes data from A2 through A101 because the top row contains the headings of the columns.
- When you press Enter or when you click away to any other cell on the table, the mean of your data values will automatically fill the cell that you just programmed.
-

4
Enter the function for the error measurements. In the first empty cell in the “Deviation” column, you need to enter a function to calculate the difference between each data point and the mean. To do this, you need to use the cell name where the mean resides. Let’s assume for now that you used cell A104.[8]
- The function for the error calculation, which you enter into cell B2, will be:
- =A2-$A$104. The dollar signs are necessary to make sure that you lock in cell A104 for each calculation.
- The function for the error calculation, which you enter into cell B2, will be:
-

5
Enter the function for the error squares. In the third column, you can direct Excel to calculate the square that you need.[9]
- In cell C2, enter the function
- =B2^2
- In cell C2, enter the function
-

6
Copy the functions to fill the entire table. After you have entered the functions in the top cell of each column, B2 and C2 respectively, you need to fill in the full table. You could retype the function in every line of the table, but this would take far too long. Use your mouse, highlight cells B2 and C2 together, and without letting go of the mouse button, drag down to the bottom cell of each column.
- If we are assuming that you have 100 data points in your table, you will drag your mouse down to cells B101 and C101.
- When you then release the mouse button, the formulas will be copied into all the cells of the table. The table should be automatically populated with the calculated values.
-

7
Find the SSE. Column C of your table contains all the square-error values. The final step is to have Excel calculate the sum of these values.[10]
- In a cell below the table, probably C102 for this example, enter the function:
- =Sum(C2:C101)
- When you click Enter or click away into any other cell of the table, you should have the SSE value for your data.
- In a cell below the table, probably C102 for this example, enter the function:
Advertisement
-

1
Calculate variance from SSE. Finding the SSE for a data set is generally a building block to finding other, more useful, values. The first of these is variance. The variance is a measurement that indicates how much the measured data varies from the mean. It is actually the average of the squared differences from the mean.[11]
- Because the SSE is the sum of the squared errors, you can find the average (which is the variance), just by dividing by the number of values. However, if you are calculating the variance of a sample set, rather than a full population, you will divide by (n-1) instead of n. Thus:
- Variance = SSE/n, if you are calculating the variance of a full population.
- Variance = SSE/(n-1), if you are calculating the variance of a sample set of data.
- For the sample problem of the patients’ temperatures, we can assume that 10 patients represent only a sample set. Therefore, the variance would be calculated as:
- Because the SSE is the sum of the squared errors, you can find the average (which is the variance), just by dividing by the number of values. However, if you are calculating the variance of a sample set, rather than a full population, you will divide by (n-1) instead of n. Thus:
-

2
Calculate standard deviation from SSE. The standard deviation is a commonly used value that indicates how much the values of any data set deviate from the mean. The standard deviation is the square root of the variance. Recall that the variance is the average of the square error measurements.[12]
- Therefore, after you calculate the SSE, you can find the standard deviation as follows:
- For the data sample of the temperature measurements, you can find the standard deviation as follows:
- Therefore, after you calculate the SSE, you can find the standard deviation as follows:
-

3
Use SSE to measure covariance. This article has focused on data sets that measure only a single value at a time. However, in many studies, you may be comparing two separate values. You would want to know how those two values relate to each other, not only to the mean of the data set. This value is the covariance.[13]
- The calculations for covariance are too involved to detail here, other than to note that you will use the SSE for each data type and then compare them. For a more detailed description of covariance and the calculations involved, see Calculate Covariance.
- As an example of the use of covariance, you might want to compare the ages of the patients in a medical study to the effectiveness of a drug in lowering fever temperatures. Then you would have one data set of ages and a second data set of temperatures. You would find the SSE for each data set, and then from there find the variance, standard deviations and covariance.

Advertisement
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
Thanks for submitting a tip for review!
References
About This Article
Article SummaryX
To calculate the sum of squares for error, start by finding the mean of the data set by adding all of the values together and dividing by the total number of values. Then, subtract the mean from each value to find the deviation for each value. Next, square the deviation for each value. Finally, add all of the squared deviations together to get the sum of squares for error. To learn how to calculate the sum of squares for error using Microsoft Excel, scroll down!
Did this summary help you?
Thanks to all authors for creating a page that has been read 487,301 times.
Did this article help you?
![]()
Download Article
![]()
Download Article
The sum of squared errors, or SSE, is a preliminary statistical calculation that leads to other data values. When you have a set of data values, it is useful to be able to find how closely related those values are. You need to get your data organized in a table, and then perform some fairly simple calculations. Once you find the SSE for a data set, you can then go on to find the variance and standard deviation.
-
1
Create a three column table. The clearest way to calculate the sum of squared errors is begin with a three column table. Label the three columns as
-
2
Fill in the data. The first column will hold the values of your measurements. Fill in the
- In this case, suppose you are working with some medical data and you have a list of the body temperatures of ten patients. The normal body temperature expected is 98.6 degrees. The temperatures of ten patients are measured and give the values 99.0, 98.6, 98.5, 101.1, 98.3, 98.6, 97.9, 98.4, 99.2, and 99.1. Write these values in the first column.
Advertisement
-
3
Calculate the mean. Before you can calculate the error for each measurement, you must calculate the mean of the full data set.[3]
-
4
Calculate the individual error measurements. In the second column of your table, you need to fill in the error measurements for each data value. The error is the difference between the measurement and the mean.[4]
- For the given data set, subtract the mean, 98.87, from each measured value, and fill in the second column with the results. These ten calculations are as follows:
-
5
Calculate the squares of the errors. In the third column of the table, find the square of each of the resulting values in the middle column. These represent the squares of the deviation from the mean for each measured value of data.[5]
- For each value in the middle column, use your calculator and find the square. Record the results in the third column, as follows:
-
6
Add the squares of errors together. The final step is to find the sum of the values in the third column. The desired result is the SSE, or the sum of squared errors.[6]
- For this data set, the SSE is calculated by adding together the ten values in the third column:
Advertisement
-
1
Label the columns of the spreadsheet. You will create a three column table in Excel, with the same three headings as above.
- In cell A1, type in the heading “Value.”
- In cell B1, enter the heading “Deviation.»
- In cell C1, enter the heading “Deviation squared.”
-
2
Enter your data. In the first column, you need to type in the values of your measurements. If the set is small, you can simply type them in by hand. If you have a large data set, you may need to copy and paste the data into the column.
-
3
Find the mean of the data points. Excel has a function that will calculate the mean for you. In some vacant cell underneath your data table (it really doesn’t matter what cell you choose), enter the following:[7]
- =Average(A2:___)
- Do not actually type a blank space. Fill in that blank with the cell name of your last data point. For example, if you have 100 points of data, you will use the function:
- =Average(A2:A101)
- This function includes data from A2 through A101 because the top row contains the headings of the columns.
- When you press Enter or when you click away to any other cell on the table, the mean of your data values will automatically fill the cell that you just programmed.
-
4
Enter the function for the error measurements. In the first empty cell in the “Deviation” column, you need to enter a function to calculate the difference between each data point and the mean. To do this, you need to use the cell name where the mean resides. Let’s assume for now that you used cell A104.[8]
- The function for the error calculation, which you enter into cell B2, will be:
- =A2-$A$104. The dollar signs are necessary to make sure that you lock in cell A104 for each calculation.
- The function for the error calculation, which you enter into cell B2, will be:
-
5
Enter the function for the error squares. In the third column, you can direct Excel to calculate the square that you need.[9]
- In cell C2, enter the function
- =B2^2
- In cell C2, enter the function
-
6
Copy the functions to fill the entire table. After you have entered the functions in the top cell of each column, B2 and C2 respectively, you need to fill in the full table. You could retype the function in every line of the table, but this would take far too long. Use your mouse, highlight cells B2 and C2 together, and without letting go of the mouse button, drag down to the bottom cell of each column.
- If we are assuming that you have 100 data points in your table, you will drag your mouse down to cells B101 and C101.
- When you then release the mouse button, the formulas will be copied into all the cells of the table. The table should be automatically populated with the calculated values.
-
7
Find the SSE. Column C of your table contains all the square-error values. The final step is to have Excel calculate the sum of these values.[10]
- In a cell below the table, probably C102 for this example, enter the function:
- =Sum(C2:C101)
- When you click Enter or click away into any other cell of the table, you should have the SSE value for your data.
- In a cell below the table, probably C102 for this example, enter the function:
Advertisement
-
1
Calculate variance from SSE. Finding the SSE for a data set is generally a building block to finding other, more useful, values. The first of these is variance. The variance is a measurement that indicates how much the measured data varies from the mean. It is actually the average of the squared differences from the mean.[11]
- Because the SSE is the sum of the squared errors, you can find the average (which is the variance), just by dividing by the number of values. However, if you are calculating the variance of a sample set, rather than a full population, you will divide by (n-1) instead of n. Thus:
- Variance = SSE/n, if you are calculating the variance of a full population.
- Variance = SSE/(n-1), if you are calculating the variance of a sample set of data.
- For the sample problem of the patients’ temperatures, we can assume that 10 patients represent only a sample set. Therefore, the variance would be calculated as:
- Because the SSE is the sum of the squared errors, you can find the average (which is the variance), just by dividing by the number of values. However, if you are calculating the variance of a sample set, rather than a full population, you will divide by (n-1) instead of n. Thus:
-
2
Calculate standard deviation from SSE. The standard deviation is a commonly used value that indicates how much the values of any data set deviate from the mean. The standard deviation is the square root of the variance. Recall that the variance is the average of the square error measurements.[12]
- Therefore, after you calculate the SSE, you can find the standard deviation as follows:
- For the data sample of the temperature measurements, you can find the standard deviation as follows:
- Therefore, after you calculate the SSE, you can find the standard deviation as follows:
-
3
Use SSE to measure covariance. This article has focused on data sets that measure only a single value at a time. However, in many studies, you may be comparing two separate values. You would want to know how those two values relate to each other, not only to the mean of the data set. This value is the covariance.[13]
- The calculations for covariance are too involved to detail here, other than to note that you will use the SSE for each data type and then compare them. For a more detailed description of covariance and the calculations involved, see Calculate Covariance.
- As an example of the use of covariance, you might want to compare the ages of the patients in a medical study to the effectiveness of a drug in lowering fever temperatures. Then you would have one data set of ages and a second data set of temperatures. You would find the SSE for each data set, and then from there find the variance, standard deviations and covariance.
Advertisement
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
Thanks for submitting a tip for review!
References
About This Article
Article SummaryX
To calculate the sum of squares for error, start by finding the mean of the data set by adding all of the values together and dividing by the total number of values. Then, subtract the mean from each value to find the deviation for each value. Next, square the deviation for each value. Finally, add all of the squared deviations together to get the sum of squares for error. To learn how to calculate the sum of squares for error using Microsoft Excel, scroll down!
Did this summary help you?
Thanks to all authors for creating a page that has been read 487,301 times.
Did this article help you?
Линейная регрессия
Перевод
Ссылка на автора
Введение
Недавно я написал об оценке максимального правдоподобия в своей продолжающейся серии статей об основах машинного обучения:
Оценка максимального правдоподобия
Основы машинного обучения (часть 2)
towardsdatascience.com
В этом посте мы узнали, что значит «моделировать» данные, а затем, как использовать MLE, чтобы найти параметры нашей модели. В этом посте мы собираемся погрузиться в линейную регрессию, одну из наиболее важных моделей в статистике, и научимся формировать ее с точки зрения MLE. Решение представляет собой прекрасный математический пример, который, как и большинство моделей MLE, богат интуицией. Я предполагаю, что вы получили представление о словаре, который я рассмотрел в других сериях (плотности вероятностей, условные вероятности, функция вероятности, данные iid и т. Д.). Если вы видите здесь что-то, что вас не устраивает, проверьте Вероятность а также MLE сообщения из этой серии для ясности.
Модель
Мы используем линейную регрессию, когда наши данные имеют линейную связь между независимыми переменными (нашими функциями) и зависимой переменной (нашей целью). В посте MLE мы увидели некоторые данные, которые тоже выглядели примерно так:

Мы заметили, что между x и y существует линейная зависимость, но она не идеальна. Мы думаем об этих недостатках как о результате некоторой ошибки или шумового процесса. Представьте, что проведете линию прямо через облако точек. Ошибка для каждой точки — это расстояние от точки до нашей линии. Мы хотели бы явно включить эти ошибки в нашу модель. Один из способов сделать это — предположить, что ошибки распределены из гауссовского распределения со средним значением 0 и некоторой неизвестной дисперсией σ². Gaussian кажется хорошим выбором, потому что наши ошибки выглядят симметричными относительно линии, и маленькие ошибки более вероятны, чем большие. Мы пишем нашу линейную модель с гауссовым шумом так:

Термин ошибки взят из нашего гауссовского алгоритма, а затем вычисленный нами у вычисляется путем добавления ошибки к выходным данным линейного уравнения. Эта модель имеет три параметра: наклон и пересечение нашей линии и дисперсию распределения шума. Наша главная цель — найти наилучшие параметры для наклона и пересечения нашей линии.
Функция правдоподобия
Чтобы применить максимальное правдоподобие, нам сначала нужно вывести функцию правдоподобия. Во-первых, давайте перепишем нашу модель сверху как единое условное распределение, заданное x:

Это эквивалентно проталкиванию нашего x через уравнение линии, а затем добавлению шума от среднего гауссова 0.
Теперь мы можем записать условное распределение y для заданного x в терминах этого гауссиана. Это просто уравнение функции плотности вероятности распределения Гаусса с нашим линейным уравнением вместо среднего значения:

Точка с запятой в условном распределении действует как запятая, но это полезное обозначение для отделения наших наблюдаемых данных от параметров.
Каждая точка является независимой и одинаково распределенной (iid), поэтому мы можем записать функцию правдоподобия относительно всех наших наблюдаемых точек как произведение каждой отдельной плотности вероятности. Поскольку σ² одинаково для каждой точки данных, мы можем вычленить термин гауссианы, который не включает x или y из произведения:

Log-правдоподобие:
Следующий шаг в MLE — найти параметры, которые максимизируют эту функцию. Чтобы упростить наше уравнение, давайте возьмем журнал нашей вероятности. Напомним, что максимизация логарифмической вероятности такая же, как максимизация вероятности, поскольку логарифм является монотонным. Натуральный логарифм вычитается по экспоненте, превращает произведения в суммы бревен и делится на вычитание бревен; так что наша логарифмическая вероятность выглядит намного проще:

Сумма квадратов ошибок:
Чтобы еще кое-что прояснить, давайте запишем вывод нашей строки как одно значение:

Теперь наша логарифмическая вероятность может быть записана как:

Чтобы убрать отрицательные знаки, давайте вспомним, что максимизация числа — это то же самое, что минимизация отрицания числа. Поэтому вместо того, чтобы максимизировать вероятность, давайте минимизируем отрицательную логарифмическую вероятность:

Наша конечная цель — найти параметры нашей линии. Чтобы минимизировать отрицательное логарифмическое правдоподобие по отношению к линейным параметрам (θs), мы можем представить, что наш дисперсионный член является фиксированной константой.
Удаление любых констант, которые не включают наши θs, не изменит решение Поэтому мы можем выбросить любые постоянные термины и изящно написать то, что мы пытаемся минимизировать, как:

Оценка максимального правдоподобия для нашей линейной модели — это линия, которая минимизирует сумму квадратов ошибок! Это прекрасный результат, и вы увидите, что минимизация квадратичных ошибок повсеместно встречается в машинном обучении и статистике.
Решение для параметров
Мы пришли к выводу, что оценки максимального правдоподобия для нашего наклона и перехвата можно найти путем минимизации суммы квадратов ошибок. Давайте расширим нашу цель минимизации и используемякак наш индекс над нашимNТочки данных:

Квадрат в формуле SSE делает его квадратичным с одним минимумом. Минимум можно найти, взяв производную по каждому из параметров, установив ее равной 0 и решив для параметров по очереди.
Перехват:
Давайте начнем с решения для перехвата. Взятие частной производной по отношению к перехвату и проработка дает нам:

Горизонтальные полосы над переменными показывают среднее значение этих переменных. Мы использовали тот факт, что сумма значений переменных равна среднему значению этих значений, умноженному на количество значений, которые у нас есть. Установка производной равной 0 и решение для перехвата дает нам:

Это довольно аккуратный результат. Это уравнение линии со средствами х и у вместо этих переменных. Перехват по-прежнему зависит от наклона, поэтому нам нужно найти его дальше.
Склон:
Мы начнем с частной производной SSE относительно нашего наклона. Мы включаем наше решение для перехвата и используем алгебру, чтобы изолировать термин наклона:

Установка этого значения равным 0 и решение для наклона дает нам:

Хотя технически мы закончили, мы можем использовать некоторую причудливую алгебру, чтобы переписать это, не используяN:

Собираем все вместе:
Мы можем использовать эти производные уравнения, чтобы написать простую функцию в python для решения параметров для любой линии, заданной как минимум двумя точками:
def find_line(xs, ys):
"""Calculates the slope and intercept"""# number of points
n = len(xs) # calculate means
x_bar = sum(xs)/n
y_bar = sum(ys)/n# calculate slope
num = 0
denom = 0
for i in range(n):
num += (xs[i]-x_bar)*(ys[i]-y_bar)
denom += (xs[i]-x_bar)**2
slope = num/denom# calculate intercept
intercept = y_bar - slope*x_barreturn slope, intercept
Используя этот код, мы можем поместить строку в наши исходные данные (см. Ниже). Это максимальная оценка правдоподобия для наших данных. Линия минимизирует сумму квадратов ошибок, поэтому этот метод линейной регрессии часто называют обычными наименьшими квадратами.

Последние мысли
Я хотел написать этот пост главным образом для того, чтобы подчеркнуть связь между минимизацией суммы квадратов ошибок и подходом оценки максимального правдоподобия к линейной регрессии. Большинство людей сначала учатся решать линейную регрессию путем минимизации квадратичной ошибки, но, как правило, не понимают, что это происходит из вероятностной модели с запечатленными в допущениях (например, гауссовых распределенных ошибок).
Существует более элегантное решение для нахождения параметров этой модели, но для этого требуется линейная алгебра. Я планирую вернуться к линейной регрессии после того, как расскажу о линейной алгебре в своей серии основ, и покажу, как ее можно использовать для подбора более сложных кривых, таких как полиномы и экспоненты.
Увидимся в следующий раз!
В
идеале, когда все точки лежат на прямой
регрессии, все остатки равны нулю и
значения Y
полностью вычисляются или объясняются
линейной функцией от Х.
Используя
формулу отклонений и отнимая
![]()
от обеих частей равенства, имеем
следующее.
![]()
Несложными
алгебраическими преобразованиями можно
показать, что суммы квадратов
складываются:
![]()
или
![]()
где
![]()
![]()
![]()


 Здесь
Здесь
SS
обозначает «сумма квадратов» (Sum
of Squares), a T, R, Е— соответственно «общая»
(Total), «регрессионная» (Regression) и
«ошибки» (Error). С этими суммами
квадратов связаны следующие величины
степеней свободы.
![]()
![]()
![]()
Если
линейной связи нет, Y
не зависит от X
и дисперсия Y
оценивается значением выборочной
дисперсии.
![]()
Если
связь между X и Y
имеется, она может влиять на некоторые
разности значений Y.
Регрессионная
сумма квадратов, SSR, измеряет часть
дисперсии Y,
объясняемую линейной зависимостью.
Сумма квадратов ошибок, SSE
— это оставшаяся часть дисперсии Y,
или дисперсия Y,
не объясненная линейной зависимостью.
2.5 Коэффициент детерминации
Как
было указано в предыдущем разделе,
показатель SST измеряет общую вариацию
относительно Y,
а ее часть, объясненная изменением X,
соответствует SSR. Оставшаяся, или
необъясненная вариация, соответствует
SSE. Отношение объясненной вариации к
общей называется выборочным коэффициентом
детерминации и обозначается
![]()

Коэффициент
детерминации измеряет долю изменчивости
Y,
которую можно объяснить с помощью
информации об изменчивости (разнице
значений) независимой переменной X.
В
случае прямолинейной регрессии
коэффициент детерминации
![]()
равен квадрату коэффициента корреляции
![]() .
.
В
регрессионном анализе коэффициенты
![]()
и
![]()
необходимо рассматривать отдельно, так
как они несут различную информацию.
Коэффициент корреляции выявляет не
только силу, но и направление линейной
связи. Следует отметить, что когда
коэффициент корреляции возводится в
квадрат, полученное значение всегда
будет положительным и информация о
характере взаимосвязи теряется.
Коэффициент
детерминации
![]()
измеряет силу взаимосвязи между Y и X
иначе, чем коэффициент корреляции
![]() .
.
Значение
![]()
измеряет долю изменчивости Y, объясненную
разницей значений X. Эту полезную
интерпретацию можно обобщить на
взаимосвязь между Y и более чем одной
переменной X.
2.6 Проверка гипотез
Прямая
регрессии вычисляется по выборке пар
значений Х-Y. Статистическая модель
простой линейной регрессии предполагает,
что линейная связь величин X и Y имеет
место для всех возможных пар X-Y. Для
проверки гипотезы, что соотношение
![]() истинно
истинно
для всех X и Y рассмотрим гипотезу:
![]() ,
,
Если
эта гипотеза справедлива, в генеральной
совокупности нет связи между значениями
X и Y. Если мы не можем опровергнуть
гипотезу, то, несмотря на ненулевое
значение вычисленного по выборке
углового коэффициента регрессионной
прямой, мы не имеем оснований гарантированно
утверждать, что значения X
и Y
взаимозависимы. Иными словами, нельзя
исключить возможность того, что
регрессионная прямая совокупности
горизонтальна.
Если
гипотеза
![]()
верна, проверочная статистика t со
значением
![]()
имеет t-распределение с количеством
степеней свободы df = n-2.
Здесь оценка стандартного отклонения
(или стандартная ошибка) равна
![]()
Для
выборки очень большого объема можно
отклонить гипотезу
![]()
и заключить, что между X и Y
есть линейная связь даже в тех случаях,
когда значение
![]()
мало (например, 10%). Аналогично для малых
выборок и очень большого значения
![]()
(например, 95%) можно сделать вывод, что
регрессионная зависимость имеет место.
Малое значение коэффициента детерминации
![]()
означает, что вычисленное уравнение
регрессии не имеет большого значения
для прогноза. С другой стороны, большое
значение
![]()
при очень малом объеме выборки не может
удовлетворить исследователя, и потребуются
дополнительные обоснования, чтобы
вычисленную функцию регрессии использовать
для целей прогноза. Такова разница между
статистической и практической значимостью.
В то же время вся собранная информация,
а также понимание сущности рассматриваемого
объекта будут необходимы, чтобы
определить, может ли вычисленная функция
регрессии быть подходящим средством
для прогноза.
Еще
один способ проверки гипотезы
![]()
возможен с помощью таблицы ANOVA. При
предположении, что статистическая
модель линейной регрессии правильна и
нулевая гипотеза
![]()
истинна, отношение
![]()
имеет
F-распределение со степенями свободы
df= 1, n-2.
Если гипотеза
![]()
истинна, каждая из величин MSR и MSE будет
оценкой
![]() ,
,
дисперсии слагаемого ошибки
![]() в
в
статистической модели прямолинейной
регрессии. С другой стороны, если верна
гипотеза
![]() ,
,
числитель в отношении F стремится стать
большим, чем знаменатель. Большое
значение F согласуется с истинностью
альтернативной гипотезы.
Для
модели прямолинейной регрессии проверка
гипотезы
![]()
при альтернативе
![]()
основывается на отношении
![]()
с df= 1, n-2.
При уровне значимости
![]()
область отклонения гипотезы:![]() .
.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
[c.328]
Для проверки этой гипотезы разделим эмпирические данные на две группы по 350 точек с 1-й по 350-ю и с 467-й по 816-ю точки. Серединные точки с 351-й по 466-ю (14.2% от объема выборки) исключаем для лучшего разграничения между группами. Рассчитаем суммы квадратов ошибок для каждой из этих групп [c.152]
При сложении планируемых величин для нескольких работ суммарная ошибка составляет квадратичный корень из суммы квадратов ошибок по каждому виду работы.
[c.42]
Кумулятивная сумма квадратов ошибок Se 100 104 273 .498 982 [c.24]
В табл. 1.2 дана типичная схема построения с помощью экспоненциально взвешенного среднего целочисленного прогноза ежемесячного спроса на некоторый товар. Значение константы экспоненциального сглаживания а была выбрано равным 0,2. На практике чаще всего а необходимо брать из интервала от 0,1 до 0,2. В некоторых программах для ЭВМ пользователю предоставляется возможность найти значение а исходя из минимума суммы квадратов ошибок. Для коротких временных рядов (как в табл, 1,2) более значимым представляется выбор начальной оценки прогноза.
[c.25]
Покажите, что для данных из табл. 1.2 с начальным условием щ-г — 70 при а, = 0,If 0,3 и 0,4 значения суммы квадратов ошибок будут соответственно равны 2615, 2357 и 2212, Причина достаточно высокого оптимального значения а объясняется повышением спроса на товар, начиная с октября и далее.
[c.26]
Теперь вместо составления и вычисления суммы квадратов ошибок, как при нахождении дисперсии, определим другую меру разброса, известную под названием среднее абсолютное отклонение ошибки (MAD,). Из названия следует, что среднее абсолютное отклонение есть просто абсолютное значение ошибки (отклонения). В гл. 1 было рассмотрено экспоненциально взвешенное среднее в качестве одной из форм среднего, поэтому нет причин не вычислять среднее абсолютное отклонение опять по формуле экспоненциально взвешенного среднего абсолютных значений ошибок [c.42]
Сумма квадратов ошибок 2е [c.56]
Используя данные табл. 5.1, при а = 0,2 по методу адаптивной скорости реакции (с лагом и без лага) постройте прогноз значений показателя покажите, что сумма квадратов ошибок прогноза по этим двум методам соответственно рав на 3176 и 1986.
[c.65]
Критерий F в (13.20) при у = 0 имеет / -распределение с 1, (// — / — J) степенями свободы. Гипотезы НА и Нв проверяются так же, как в п. 13.3.2, только сумма квадратов ошибок определяется как СКе = ОСК — СКг и имеет на одну степень свободы меньше, чем в табл. 13.3.
[c.387]
Кумулятивная сумма квадратов ошибок Se,2 1 1,04 4,43 6,74 9,91 10,09
[c.125]
Метод адаптивного сглаживания Брауна. Согласно второму методу Брауна, предполагается, что если ряд значений спроса можно описать некоторой моделью, то желательно применить регрессионный анализ на основе взвешенной регрессии, т. е. большее внимание необходимо уделять той информации, которая поступает позже. Данный метод основывается на простом способе вычисления оценок по методу минимизации взвешенной суммы квадратов ошибок прогноза в случае линейно-аддитивного тренда. Оценка по взвешенному методу наименьших квадратов равна [c.127]
На практике пригодность определяется функцией пригодности — блоком программы, который рассчитывает показатель относительной привлекательности решения. Функция может быть запрограммирована для определения пригодности именно так, как пожелает трейдер например, пригодность можно определять как общую прибыль за вычетом максимального падения капитала. Функция расходов устроена аналогично, но чем выше ее значение, тем хуже работает система. Сумма квадратов ошибок, часто вычисляемая при использовании систем с нейронными сетями или линейной регрессией, может служить примером функции расходов.
[c.48]
Анализ (в смысле. математический или комплексный анализ) является расширением классического исчисления. Аналитические оптимизаторы используют наработанные методы, в особенности методы дифференциального исчисления и исследования аналитических функций для решения практических задач. В некоторых случаях анализ дает прямой (без перебора вариантов) ответ на задачу оптимизации. Так происходит при использовании множественной регрессии, где решение находится с помощью нескольких матричных вычислений. Целью множественной регрессии является подбор таких весов регрессии, при которых минимизируется сумма квадратов ошибок. В других случаях требуется перебор вариантов, например невозможно определить напрямую веса связей в нейронной сети, их требуется оценивать при помощи алгоритма обратного распространения.
[c.57]
Сумма квадратов ошибок. Значения расстояний всех точек до линии регрессии возводят в квадрат и суммируют, получая сумму квадратов ошибок, которая является показателем общей ошибки
[c.650]
Задавшись затем значением р, мы получим оценки р , р и р2, i процесс такого последовательного оценивания можно продолжать до ех пор, пока не будет достигнута сходимость с выбранной заранее точ-юстью. Некоторые эконометрики предпочитают комбинировать поиск итеративной процедурой, применяя поиск для решетки с очень широкими относительно р ячейками и выбирая в качестве начального значе-П1я р для итеративной процедуры тот узел решетки, который обеспе-шл наименьшее значение суммы квадратов ошибок.
[c.318]
По аналогии с моделью регрессии для оценки качества построения модели или для выбора наилучшей модели можно применять сумму квадратов полученных абсолютных ошибок. Для данной аддитивной модели сумма квадратов абсолютных ошибок равна 1,10. По отношению к общей сумме квадратов отклонений уровней ряда от его среднего уровня, равной 71,59, эта величина составляет чуть более 1,5% [c.245]
Численные значения ошибки приведены в гр. 7 табл. 5.14. Если временной ряд ошибок не содержит автокорреляции, его можно использовать вместо исходного ряда для изучения его взаимосвязи с другими временными рядами. Для того чтобы сравнить мультипликативную модель и другие модели временного ряда, можно по аналогии с аддитивной моделью использовать сумму квадратов абсолютных ошибок. Абсолютные ошибки в мультипликативной модели определяются как
[c.250]
В данной модели сумма квадратов абсолютных ошибок составляет 207,40. Общая сумма квадратов отклонений фактических уровней этого ряда от среднего значения равна 5023. Таким образом, доля объясненной дисперсии уровней ряда равна (1 — 207,40/5023) = 0,959, или 95,9%.
[c.250]
Остаточная сумма квадратов по аддитивной модели (сумма квадратов абсолютных ошибок) была рассчитана ранее (табл. 5.10) и составляет 1,10. Следовательно, модель регрессии с фиктивными переменными описывает динамику временного ряда потребления электроэнергии лучше, чем аддитивная модель.
[c.255]
Сумма квадратов абсолютных ошибок = 1,0981 [c.27]
Сумма квадратов абсолютных ошибок S Е = 1,0981
[c.28]
Для его вычисления отклонения по итоговым показателям по каждому признаку в отдельности возводятся в квадрат, полученные величины умножаются на соответствующие частоты, произведения суммируются, сумма делится на все число случаев, результаты уменьшаются на квадраты ошибок и из полученных чисел извлекается квадратный корень.
[c.270]
Главная причина зависимости меры разброса от квадратов ошибок, а, например, не просто от суммы ошибок в том, что возведение в квадрат делает результат положительным вне зависимости от того, была ли первоначальная ошибка отрицательной или положительной. Для большинства прогнозов сумма ошибок стремится к нулю, т. е. положительные и отрицательные ошибки компенсируют одна другую. Вот почему сумма ошибок не может служить удовлетворительной мерой разброса.
[c.42]
Метод, используемый чаще других для нахождения параметров уравнения регрессии и известный как метод наименьших квадратов, дает наилучшие линейные несмещенные оценки. Он называется так потому, что при расчете параметров прямой линии, которая наиболее соответствует фактическим данным, с помощью этого метода стараются найти линию, минимизирующую сумму квадратов значений ошибок или расхождений между величинами Y, которые рассчитаны по уравнению прямой и обозначаются Y, и фактическими наблюдениями. Это показано на рис. 6.2.
[c.265]
После построения сети следует этап ее обучения (тренировки). На этапе обучения происходит подбор коэффициентов в формулах (2.4.1), (2.4.2) для нейронов сети. Эту процедуру можно назвать контролируемым обучением на вход сети подается вектор исходных данных, а сигнал на выходе сравнивается с известным результатом. Целью обучения является минимизация функции ошибок или невязки на множестве примеров путем выбора значений коэффициентов сети. Обычно в качестве меры погрешности берется средняя квадратичная ошибка, которая определяется как сумма квадратов разностей между истинной величиной выхода d k и полученными на сети значениями по всем Р примерам
[c.144]
В ряде случаев проблема мультиколлинеарности может быть решена изменением спецификации модели либо изменением формы модели, либо добавлением объясняющих переменных, которые не учтены в первоначальной модели, но существенно влияющие на зависимую переменную. Если данный метод имеет основания, то его использование уменьшает сумму квадратов отклонений, тем самым сокращая стандартную ошибку регрессии. Это приводит к уменьшению стандартных ошибок коэффициентов.
[c.252]
Сумма квадратов остатков е2 = е е является естественным кандидатом на оценку дисперсии ошибок а1 (конечно, с некоторым поправочным коэффициентом, зависящим от числа степеней свободы) [c.73]
Формально это записывается как минимизация суммы квадратов отклонений (ошибок) функции регрессии и исходных точек
[c.112]
Эти два выражения показывают, как возникает ковариация между [52 и Рз в СИЛУ присутствия 2ыу в каждом из выражений для ошибок Р2 и (33. Положительное и большое значение ос приводит, как мы видим, к большим противоположным значениям ошибок J32 и(33- Если (32 оценивает значение р 2 снизу, то р3 оценивает значение ps сверху, и наоборот. Очень важным является то обстоятельство, что стандартные ошибки могут служить одним из индикаторов наличия мульти-коллинеарности. Формула (5.84) показывает, что истинное значение стандартной ошибки возрастает с увеличением а, однако эта формула содержит неизвестный параметр а . В оцененной величине стандартной ошибки значение а заменяется на Ее2/(п — /г), где 2е2 — сумма квадратов остатков после подгонки уравнения регрессии к эмпирическим данным. Как было показано в (5.19),
[c.162]
| Рис. А.4. Блок-схема вычисления мер точности прогноза 1) суммы квадратов ошибок 2) среднего квадрата ошибок 3) средней ошибки 4) среднеа45сол отной процентной ошибки 5) средней лроцентной |  |
Статистика ошибок. Следующая немаловажная разработка сетевых решений заключается в определении того, что использовать в качестве статистики ошибок (отклонений) для апробации и для тестирования. Мерой измерения ошибок (отклонений) может служить разность между точно вычисленным каким-то статистическим значением ошибок, например их скользящей средней, и выходными данными нейросети. Эта разность должна быть определена для каждого из событий в тестовом множестве, просуммирована и затем разделена на число событий в тесте. Это стандартная мера ошибок, которая называется средней ошибкой . Другие способы вычисления ошибки включают в себя среднее значение абсолютных ошибок, сумму квадратов ошибок или же квадратный корень ошибок (Root-mean-squared — RMS). После того как будет выбрана нейросетевая модель, ее следует апробировать еще раз на определенных временных промежутках. Следующий этап исследования должен заключаться в модификации вхо-
[c.134]
Частные производные от суммы квадратов разности по данному весу довольно легко вычисляются и оказываются пропорциональными расчетным ошибкам, полученным в ходе данной итерации. При этом расчетная ошибка нейрона выходного слоя пропорциональна фактической ошибке на его выходе, а расчетная ошибка нейрона слоя, предшествующего выходному, пропорциональна сумме ошибок всех нейронов выходного слоя, умноженных на соответствующие синаптические веса. Поэтому сначала вычисляют ошибки выходного слоя и определяют приращение весов его связей, а затем вычисляют ошибки предыдущего слоя и вычисляются веса его связей и так корректируются все веса по направлению от входа к выходу. Поэтому такой алгоритм и назван
[c.132]
При выполнении предпосылок 1)-4) относительно ошибок е( оценки параметров множественной линейной регрессии являются несмещенными, состоятельными и эффективными. Отклонение зависимой переменной у ву-м наблюдении от линии регрессии, ер записывается следующим образом е = у — а0 — atx — a fl -. .. — amxjm. Обозначим сумму квадратов этих величин, которую нужно минимизировать в соответствии с методом наименьших квадратов, через Q.
[c.308]
Возникает естественный вопрос, при каких обстоятельствах можно пользоваться описанным выше методом. Ниже будут описаны некоторые процедуры, позволяющие выявлять гетероскеда-стичность того или иного рода (тесты на гетероскедастичность). Здесь мы ограничимся лишь практическими рекомендациями. Если есть предположение о зависимости ошибок от одной из независимых переменных, то целесообразно расположить наблюдения в порядке возрастания значений этой переменной, а затем провести обычную регрессию и получить остатки. Если размах их колебаний тоже возрастает (это хорошо заметно при обычном визуальном исследовании), то это говорит в пользу исходного предположения. Тогда надо сделать описанное выше преобразование, вновь провести регрессию и исследовать остатки. Если теперь их колебание имеет неупорядоченный характер, то это может служить показателем того, что коррекция на гетероскедастичность прошла успешно. Естественно, следует сравнивать и другие параметры регрессии (значимость оценок, сумму квадратов отклонений и т. п.) и только тогда принимать окончательное решение, какая из моделей более приемлема.
[c.170]
Пусть теперь Е( ) = О Q, где Q — вещественная, симметрическая положительно определенная матрица (структура ковариации ошибок). Обобщенный метод наименьших квадратов (ОМНК), приводящий к оценкам класса BLUE, означает минимизацию взвешенной суммы квадратов отклонений [c.27]
Чтобы сделать определенным анализ системы уравнений, предполагаемой уравнением (3.25), допустим, что NS — это положения ПВ, NR — положения сейсмоприемни-ков, NG — положения ОСТ. Определим кратность как NF. Задача состоит в том, чтобы разложить наблюденные времена пробега, оцененные (пикированные) по данным ( уй) на составляющие, как определено в правой части уравнения (3.25). Количество пиков времени (или отдельных уравнений) равно NG x NF. Количество неизвестных равно NS + NR + NG + NG. Обычно NG x NF > NS + NR + NG + NG количество уравнений превышает количество неизвестных. Это задача наименьших квадратов, в которой мы должны минимизировать сумму энергии ошибок наименьших квадратов между наибольшими пиками t ijh и смоделированными временами t [c.49]
Расчет F-критерия Фишера онлайн
Быстрая навигация по странице:
Понятие F-критерия Фишера
F-критерий Фишера – это один из важных статистических критериев, используемых при проверке значимости как уравнения регрессии в целом, так и отдельных его коэффициентов. Для оценки статистической значимости отдельных коэффициентов уравнения множественной регрессии используют так называемые частные F-критерий Фишера. Критическое значение данного критерия при проведении анализа определяется по специальным таблицам, а также может быть определено при помощи специальных функций в различных компьютерных программах. Например, в MS Excel для этого может быть использована функция FРАСПОБР.
Размещено на www.rnz.ru
Формулы расчета F-критерия Фишера
В общем виде F-критерий Фишера рассчитывается по следующей формуле:
F = S 2 факт / S 2 ост;
где: S 2 факт — факторная дисперсия;
S 2 ост — остаточная дисперсия
Соответствующие виды дисперсий определяются по следующим формулам:
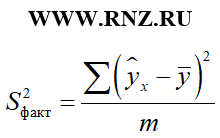 формула расчета факторной дисперсии
формула расчета факторной дисперсии
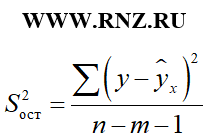 формула расчета остаточной дисперсии
формула расчета остаточной дисперсии
В приведенных формулах n – это число наблюдений, m – число параметров при переменной x (то есть количество факторов в модели регрессии).
При этом необходимо обратить внимание на то, что в зависимости от типа исследуемой модели регрессии применяемая формула определения F-критерия Фишера может изменяться. Например, для расчета F-критерия Фишера для парной линейной регрессии может использоваться следующая формула:
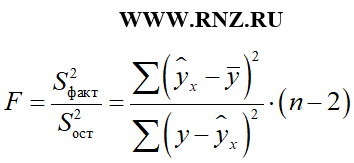 формула расчета F-критерия Фишера для парной линейной регрессии
формула расчета F-критерия Фишера для парной линейной регрессии
При использовании коэффициента детерминации расчет F-критерия Фишера для парной линейной регрессии может быть выполнен по такой формуле:
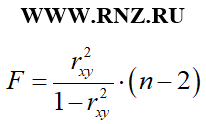 формула расчета F-критерия Фишера через коэффициент детерминации
формула расчета F-критерия Фишера через коэффициент детерминации
Для парной нелинейной модели регрессии расчет F-критерия Фишера может быть осуществлен через связь с индексом детерминации по следующей формуле:
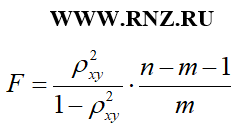 формула расчета F-критерия Фишера для парной нелинейной модели регрессии через индекс детерминации
формула расчета F-критерия Фишера для парной нелинейной модели регрессии через индекс детерминации
Описания параметров n и m приведено выше.
Для уравнения множественной регрессии F-критерий Фишера рассчитывается по следующей формуле:
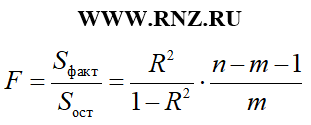 формула расчета F-критерия Фишера для уравнения множественной регрессии
формула расчета F-критерия Фишера для уравнения множественной регрессии
В процессе исследования уравнения множественной регрессии кроме общего F-критерий Фишера могут быть рассчитаны частные F-критерии. В случае анализа уравнения с двумя регрессорами (переменными) вычисление частных F-критериев может быть выполнено по следующим формулам:
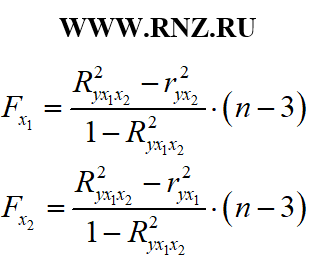 формула расчета частных F-критериев Фишера для уравнения множественной регрессии
формула расчета частных F-критериев Фишера для уравнения множественной регрессии
Значимость F-критерия Фишера
Для определения статистической значимости рассчитанного значения F-критерия Фишера его сравнивают с критическим или табличным значением. При этом табличное значение определяется на основе числа наблюдений, степеней свободы и заданного уровня значимости следующим образом: Fтабл (a; k1; k2), где k1 = m – это количество факторов в построенной регрессионной модели, а k2 = n – m – 1 (n – число наблюдений). Для частного F-критерия k1 = 1, k2 = n – m – 1 (n – число наблюдений).
Интерпретация F — критерия Фишера для уравнения регрессии в целом следующая: в том случае, когда фактическая величина F — критерия Фишера больше табличного показателя, то уравнение регрессии в целом является статистически значимым.
Интерпретация частного F — критерия Фишера следующая: в том случае, когда рассчитанная величина частного Fxi превышает критическое значение, то дополнительное включение фактора xi в регрессионную модель статистически оправданно и коэффициент регрессии bi при соответствующем факторе xi статистически значим. Но если рассчитанная величина Fxi меньше табличного, то дополнительное включение в модель фактора xi не оправдано, т.к. данный фактор, как и коэффициент регрессии при нём является статистически незначимым.
Пример расчета F-критерия Фишера
Приведем условные примеры расчета F-критерия Фишера
Пример №1. Предположим, что исследуется регрессия с одним фактором (парная), на основе 30-ти наблюдений, в которой коэффициент детерминации составил 0,77. Тогда по приведённой выше формуле фактическое значение F-критерия Фишера составит: F = 0,77/(1-0,77)*(30-2) = 93,74. Для определения значимости его нужно сравнить с табличным значением. Предположим, что используется уровень значимости α = 0.05. Тогда критическая величины Fтабл(0,05; 1; 30-1-1) = 4,2. Так как F > Fтабл, то полученное уравнение регрессии является статистически значимым.
Пример №2. Предположим, что исследуется множественная регрессия с тремя факторами, на основе 40 наблюдений, в которой коэффициент множественной детерминации составил 0,89. Тогда по приведённой выше формуле фактическое значение F-критерия Фишера для уравнения множественной регрессии составит: F = (0,89/(1-0,89))*((40-3-1)/3) = 97,09. Для определения значимости его нужно сравнить с табличным значением. Предположим, что используется уровень значимости α = 0.05. Тогда критическая величины Fтабл(0,05; 3; 40-3-1) = 2,87. Так как F > Fтабл, то полученное уравнение множественной регрессии является статистически значимым.
Онлайн-калькулятор F-критерия Фишера
Представляем онлайн калькулятор расчета F-критерия Фишера, используя который, Вы можете самостоятельно определить значения соответствующего показателя. При заполнении приведенной формы калькулятора внимательно соблюдайте размерность полей, что позволит выполнить и точно выполнить вычисления. В приведенной форме онлайн калькулятора уже содержатся данные условного примера, чтобы пользователь мог посмотреть, как это работает и посмотреть, как правильно заполнять поля. Для определения значений соответствующих показателей по своим данным просто внесите их в соответствующие поля формы онлайн калькулятора и нажмите кнопку «Выполнить вычисления». При заполнении формы соблюдайте размерность показателей! Дробные числа записываются с точной, а не запятой!
Калькулятор позволяет вычислить значение F-критерия Фишера на основе коэффициента детерминации (первый вариант) или на основе показателей сумм квадратов отклонений, т.е. используя элементы дисперсионного анализа. Выберите необходимый способ и выполните соответствующие вычисления. Для проверки статистической значимости используется уровень значимости α = 0.05.
Онлайн-калькулятор расчета значения F-критерия Фишера:
1-й вариант: на основе значения коэффициент (индекса) детерминации
2-й вариант: на основе сумм квадратов отклонений
Критерий Фишера и критерий Стьюдента в эконометрике
С помощью критерия Фишера оценивают качество регрессионной модели в целом и по параметрам.
Для этого выполняется сравнение полученного значения F и табличного F значения. F-критерия Фишера. F фактический определяется из отношения значений факторной и остаточной дисперсий, рассчитанных на одну степень свободы:
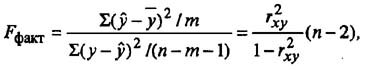
где n — число наблюдений;
m — число параметров при факторе х.
F табличный — это максимальное значение критерия под влиянием случайных факторов при текущих степенях свободы и уровне значимости а.
Уровень значимости а — вероятность не принять гипотезу при условии, что она верна. Как правило а принимается равной 0,05 или 0,01.
Если Fтабл > Fфакт то признается статистическая незначимость модели, ненадежность уравнения регрессии.
Таблицы по нахождению критерия Фишера и Стьюдента
Таблицы значений F-критерия Фишера и t-критерия Стьюдента Вы можете посмотреть здесь.
Табличное значение критерия Фишера вычисляют следующим образом:
- Определяют k1, которое равно количеству факторов (Х). Например, в однофакторной модели (модели парной регрессии) k1=1, в двухфакторной k=2.
- Определяют k2, которое определяется по формуле n — m — 1, где n — число наблюдений, m — количество факторов. Например, в однофакторной модели k2 = n — 2.
- На пересечении столбца k1 и строки k2 находят значение критерия Фишера
Для нахождения табличного значения критерия Стьюдента определяют число степеней свободы, которое определяется по формуле n — m — 1 и находят его значение при определенном уровне значимости (0,10, 0,05, 0,01).
Критерии Стьюдента
Для оценки статистической значимости модели по параметрам рассчитывают t-критерии Стьюдента.
Оценка значимости модели с помощью критерия Стьюдента проводится путем сравнения их значений с величиной случайной ошибки:
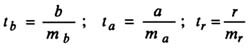
Случайные ошибки коэффициентов линейной регрессии и коэффициента корреляции определяются по формулам:
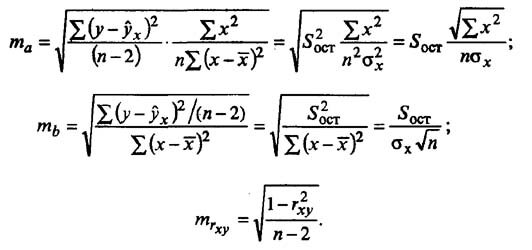
Сравнивая фактическое и табличное значения t-статистики и принимается или отвергается гипотеза о значимости модели по параметрам.
Зависимость между критерием Фишера и значением t-статистики Стьюдента определяется так
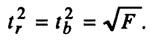
Как и в случае с оценкой значимости уравнения модели в целом, модель считается ненадежной если tтабл > tфакт
Видео лекциий по расчету критериев Фишера и Стьюдента
Для более подробного изучения расчетов критериев Фишера и Стьюдента советуем посмотреть это видео
Лекция 1. Критерии и Гипотезы
Лекция 2. Критерии и Гипотезы
Лекция 3. Критерии и Гипотезы
Определение доверительных интервалов
Для построения доверительного интервала определяется предельная ошибка А для обоих показателей:

Формулы для нахождения доверительных интервалов выглядят так
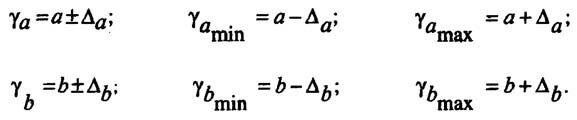
Прогнозное значение у определяется с помощью подстановки в
уравнение регрессии прогнозного значения х. Вычисляется средняя стандартная ошибка прогноза
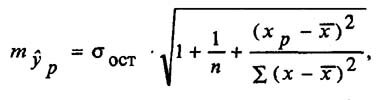
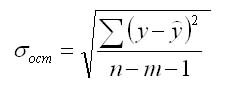
и находится доверительный интервал
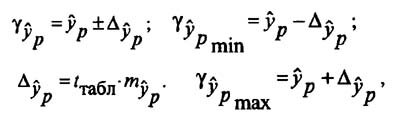
Задача регрессионного анализа в предмете эконометрика состоит в анализе дисперсии изучаемого показателя y:
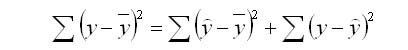
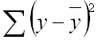 общая сумма квадратов отклонений (TSS)
общая сумма квадратов отклонений (TSS)
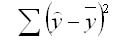 сумма квадратов отклонений, обусловленная регрессией (RSS)
сумма квадратов отклонений, обусловленная регрессией (RSS)
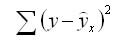 остаточная сумма квадратов отклонений (ESS)
остаточная сумма квадратов отклонений (ESS)
Долю дисперсии, обусловленную регрессией, в общей дисперсии показателя у характеризует коэффициент детерминации R, который должен превышать 50% (R 2 > 0,5). В контрольных по эконометрике в ВУЗах этот показатель рассчитывается всегда.
F-тест качества спецификации множественной регрессионной модели
Цель этой статьи — рассказать о роли степеней свободы в статистическом анализе, вывести формулу F-теста для отбора модели при множественной регрессии.
1. Роль степеней свободы (degree of freedom) в статистике
Имея выборочную совокупность, мы можем лишь оценивать числовые характеристики совокупности, параметры выбранной модели. Так не имеет смысла говорить о среднеквадратическом отклонении при наличии лишь одного наблюдения. Представим линейную регрессионную модель в виде:

Сколько нужно наблюдений, чтобы построить линейную регрессионную модель? В случае двух наблюдений можем получить идеальную модель (рис.1), однако есть в этом недостаток. Причина в том, что сумма квадратов ошибки (MSE) равна нулю и не можем оценить оценить неопределенность коэффициентов  . Например не можем построить доверительный интервал для коэффициента наклона по формуле:
. Например не можем построить доверительный интервал для коэффициента наклона по формуле:

А значит не можем сказать ничего о целесообразности использования коэффициента  в данной регрессионной модели. Необходимо по крайней мере 3 точки. А что же, если все три точки могут поместиться на одну линию? Такое может быть. Но при большом количестве наблюдений маловероятна идеальная линейная зависимость между зависимой и независимыми переменными (рис. 1).
в данной регрессионной модели. Необходимо по крайней мере 3 точки. А что же, если все три точки могут поместиться на одну линию? Такое может быть. Но при большом количестве наблюдений маловероятна идеальная линейная зависимость между зависимой и независимыми переменными (рис. 1).
 Рисунок 1 — простая линейная регрессия
Рисунок 1 — простая линейная регрессия
Количество степеней свободы — количество значений, используемых при расчете статистической характеристики, которые могут свободно изменяться. С помощью количества степеней свободы оцениваются коэффициенты модели и стандартные ошибки. Так, если имеется n наблюдений и нужно вычислить дисперсию выборки, то имеем n-1 степеней свободы.

Мы не знаем среднее генеральной совокупности, поэтому оцениваем его средним значением по выборке. Это стоит нам одну степень свободы.
Представим теперь что имеется 4 выборочных совокупностей (рис.3).
 Рисунок 3
Рисунок 3
Каждая выборочная совокупность имеет свое среднее значение, определяемое по формуле  . И каждое выборочное среднее может быть оценено
. И каждое выборочное среднее может быть оценено  . Для оценки мы используем 2 параметра
. Для оценки мы используем 2 параметра  , а значит теряем 2 степени свободы (нужно знать 2 точки). То есть количество степеней свобод
, а значит теряем 2 степени свободы (нужно знать 2 точки). То есть количество степеней свобод  Заметим, что при 2 наблюдениях получаем 0 степеней свободы, а значит не можем оценить коэффициенты модели и стандартные ошибки.
Заметим, что при 2 наблюдениях получаем 0 степеней свободы, а значит не можем оценить коэффициенты модели и стандартные ошибки.
Таким образом сумма квадратов ошибок имеет (SSE, SSE — standard error of estimate) вид:

Стоит упомянуть, что в знаменателе стоит n-2, а не n-1 в связи с тем, что среднее значение оценивается по формуле  . Квадратные корень формулы (4) — ошибка стандартного отклонения.
. Квадратные корень формулы (4) — ошибка стандартного отклонения.
В общем случае количество степеней свободы для линейной регрессии рассчитывается по формуле:

где n — число наблюдений, k — число независимых переменных.
2. Анализ дисперсии, F-тест
При выполнении основных предположений линейной регрессии имеет место формула:

где  ,
,
 ,
,

В случае, если имеем модель по формуле (1), то из предыдущего раздела знаем, что количество степеней свободы у SSTO равно n-1. Количество степеней свободы у SSE равно n-2. Таким образом количество степеней свободы у SSR равно 1. Только в таком случае получаем равенство  .
.
Масштабируем SSE и SSR с учетом их степеней свободы:


Получены хи-квадрат распределения. F-статистика вычисляется по формуле:

Формула (9) используется при проверке нулевой гипотезы  при альтернативной гипотезе
при альтернативной гипотезе  в случае линейной регрессионной модели вида (1).
в случае линейной регрессионной модели вида (1).
3. Выбор линейной регрессионной модели
Известно, что с увеличением количества предикторов (независимых переменных в регрессионной модели) исправленный коэффициент детерминации увеличивается. Однако с ростом количества используемых предикторов растет стоимость модели (под стоимостью подразумевается количество данных которые нужно собрать). Однако возникает вопрос: “Какие предикторы разумно использовать в регрессионной модели?”. Критерий Фишера или по-другому F-тест позволяет ответить на данный вопрос.
Определим “полную” модель:  (10)
(10)
Определим “укороченную” модель:  (11)
(11)
Вычисляем сумму квадратов ошибок для каждой модели:
 (12)
(12)
 (13)
(13)
Определяем количество степеней свобод 
 (14)
(14)
Нулевая гипотеза — “укороченная” модель мало отличается от “полной (удлиненной) модели”. Поэтому выбираем “укороченную” модель. Альтернативная гипотеза — “полная (удлиненная)” модель объясняет значимо большую долю дисперсии в данных по сравнению с “укороченной” моделью.
Коэффициент детерминации из формулы (6):

Из формулы (15) выразим SSE(F):

SSTO одинаково как для “укороченной”, так и для “длинной” модели. Тогда (14) примет вид:

Поделим числитель и знаменатель (14a) на SSTO, после чего прибавим и вычтем единицу в числителе.

Используя формулу (15) в конечном счете получим F-статистику, выраженную через коэффициенты детерминации.

3 Проверка значимости линейной регрессии
Данный тест очень важен в регрессионном анализе и по существу является частным случаем проверки ограничений. Рассмотрим ситуацию. У линейной регрессионной модели всего k параметров (Сейчас среди этих k параметров также учитываем  ).Рассмотрим нулевую гипотеза — об одновременном равенстве нулю всех коэффициентов при предикторах регрессионной модели (то есть всего ограничений k-1). Тогда “короткая модель” имеет вид
).Рассмотрим нулевую гипотеза — об одновременном равенстве нулю всех коэффициентов при предикторах регрессионной модели (то есть всего ограничений k-1). Тогда “короткая модель” имеет вид  . Следовательно
. Следовательно . Используя формулу (14.в), получим
. Используя формулу (14.в), получим

Заключение
Показан смысл числа степеней свободы в статистическом анализе. Выведена формула F-теста в простом случае(9). Представлены шаги выбора лучшей модели. Выведена формула F-критерия Фишера и его запись через коэффициенты детерминации.
Можно посчитать F-статистику самому, а можно передать две обученные модели функции aov, реализующей ANOVA в RStudio. Для автоматического отбора лучшего набора предикторов удобна функция step.
Надеюсь вам было интересно, спасибо за внимание.
При выводе формул очень помогли некоторые главы из курса по статистике STAT 501
источники:
http://univer-nn.ru/ekonometrika/kriterij-fishera-i-kriterij-styudenta-v-ekonometrike/
http://habr.com/ru/post/592677/