Задана система
точек (узлы интерполяции)
xi ,
i=1,2,…,N; a
xi
b, и значения
fi,
i = 1,2,….,N.
Требуется построить полиномы:
-
1-ой степени
P1(x)=a1+a2x, -
2-ой
степени
P2(x)=a1+a2x+a3x2, -
3-ой
степени
P3(x)=a1+a2x+a3x2+a4x3,
имеющие в узлах
интерполяции минимальное отклонение
от заданных значений fi.
Искомыми величинами являются коэффициенты
полинома (ai).
Полиномы
должны быть самым близким к заданным
точкам из всех возможных полиномов,
соответствующей степени в смысле МНК,
т.е. сумма квадратов отклонений
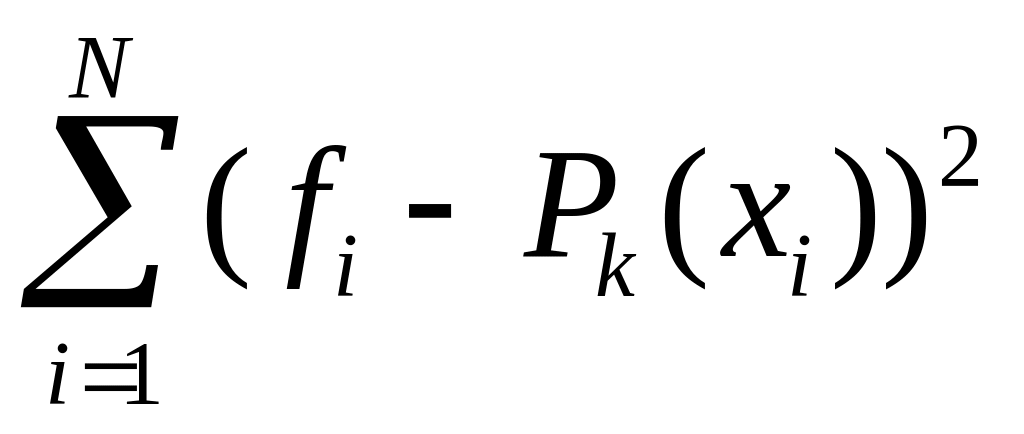
должна быть минимальной.
-
Получить систему
нормальных уравнений для каждого
полинома. -
Вычислить
коэффициенты ai
. -
Определить какой
из полиномов имеет минимальную сумму
квадратов отклонений.
|
x |
-10 |
-8,3 |
-6,7 |
-5 |
-3 |
-1,67 |
|
Вар.9 |
-100 |
-60 |
-33 |
-16 |
-7 |
-2,08 |
|
0 |
1,67 |
3,33 |
5 |
6,7 |
8,33 |
10 |
|
0 |
2,08 |
6,67 |
16 |
33 |
60,4 |
100 |
-
Полином 1-ой степени.
|
xi |
Xi^2 |
fi |
fi xi |
|
0,36 |
503,7256 |
0,07 |
3653,4903 |
|
S |
|
|
13 |
0,36 |
|
0,36 |
503,7256 |
|
S(-1) |
0,076924599 |
-5,49761E-05 |
|
-5,49761E-05 |
0,001985247 |
|
z |
|
0,07 |
|
3653,49 |
|
a |
-0,19546983 |
|
7,253077209 |
Ф(x)=-0,19547+7,25308x
Сумма квадратов
отклонений:
|
G1= |
3541,268153 |
-
Полином 2-ой степени.
|
xi |
Xi^2 |
Xi^3 |
Xi^4 |
fi |
fi xi |
fi xi^2 |
|
0,36 |
503,7256 |
16,148574 |
35060,3954 |
0,07 |
3653,4903 |
68,652523 |
|
S |
13 |
0,36 |
503,7256 |
|
0,36 |
503,7256 |
16,14857 |
|
|
503,7256 |
16,14857 |
35060,3954 |
|
S(-1) |
0,173528 |
-4,4091E-05 |
-0,00249312 |
|
-4,4E-05 |
0,001985248 |
-2,8092E-07 |
|
|
-0,00249 |
-2,8092E-07 |
6,43419E-05 |
|
z |
0,07 |
|
3653,49 |
|
|
68,65252 |
|
a |
-0,32009809 |
|
7,253062571 |
|
|
0,003216379 |
Ф(х)=-0,32009809+7,253062571*х+0,003216379*х^2
Сумма квадратов
отклонений:
|
G2 |
3541,10737 |
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Метод наименьших квадратов регрессия
Метод наименьших квадратов (МНК) заключается в том, что сумма квадратов отклонений значений y от полученного уравнения регрессии — минимальное. Уравнение линейной регрессии имеет вид
y=ax+b
a, b – коэффициенты линейного уравнения регрессии;
x – независимая переменная;
y – зависимая переменная.
Нахождения коэффициентов уравнения линейной регрессии через метод наименьших квадратов:
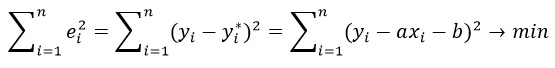
частные производные функции приравниваем к нулю
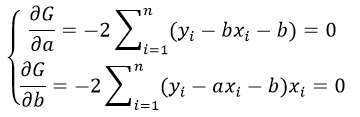
отсюда получаем систему линейных уравнений
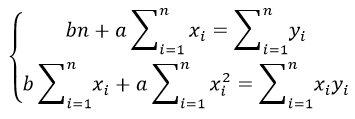
Формулы определения коэффициентов уравнения линейной регрессии:
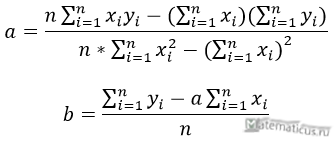
Также запишем уравнение регрессии для квадратной нелинейной функции:
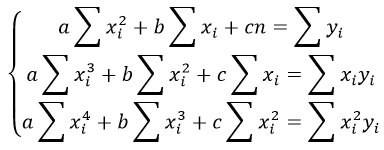
Система линейных уравнений регрессии полинома n-ого порядка:
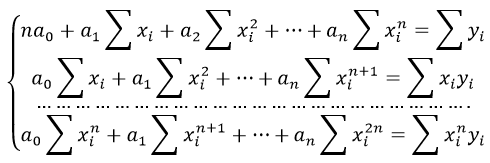
Формула коэффициента детерминации R 2 :
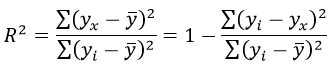
Формула средней ошибки аппроксимации для уравнения линейной регрессии (оценка качества модели):
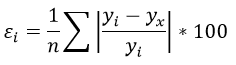
Чем меньше ε, тем лучше. Рекомендованный показатель ε
Формула среднеквадратической погрешности: 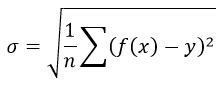
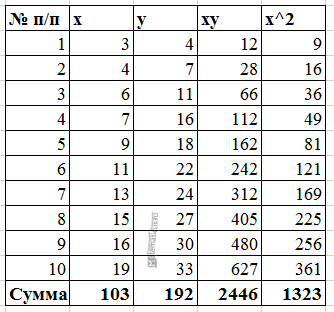
Для примера, проведём расчет для получения линейного уравнения регрессии аппроксимации функции, заданной в табличном виде:
| x | y |
| 3 | 4 |
| 4 | 7 |
| 6 | 11 |
| 7 | 16 |
| 9 | 18 |
| 11 | 22 |
| 13 | 24 |
| 15 | 27 |
| 16 | 30 |
| 19 | 33 |
Решение
Расчеты значений суммы, произведения x и у приведены в таблицы.
Расчет коэффициентов линейной регрессии:
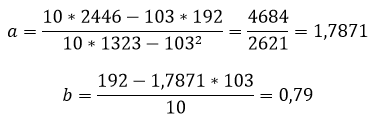
при этом средняя ошибка аппроксимации равна:
ε=11,168%
Получаем уравнение линейной регрессии с помощью метода наименьших квадратов:
y=1,7871x+0,79
График функции линейной зависимости y=1,7871x+0,79 и табличные значения, в виде точек
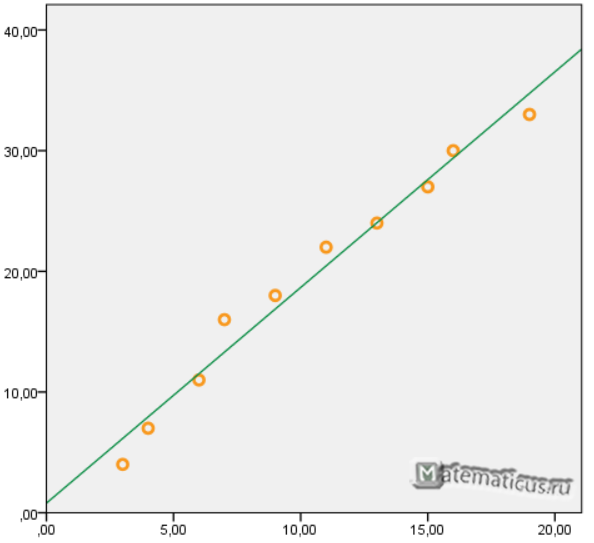
Коэффициент корреляции равен 0,988
Коэффициента детерминации равен 0,976
Решения задач: метод наименьших квадратов
Метод наименьших квадратов применяется для решения различных математических задач и основан на минимизации суммы квадратов отклонений функций от исходных переменных. Мы рассмотриваем его приложение к математической статистике в простейшем случае, когда нужно найти зависимость (парную линейную регрессию) между двумя переменными, заданными выборочными данным. В этом случае речь идет об отклонениях теоретических значений от экспериментальных.
Краткая инструкция по методу наименьших квадратов для чайников: определяем вид предполагаемой зависимости (чаще всего берется линейная регрессия вида $y(x)=ax+b$), выписываем систему уравнений для нахождения параметров $a, b$. По экспериментальным данным проводим вычисления и подставляем значения в систему, решаем систему любым удобным методом (для размерности 2-3 можно и вручную). Получается искомое уравнение.
Иногда дополнительно к нахождению уравнения регрессии требуется: найти остаточную дисперсию, сделать прогноз значений, найти значение коэффициента корреляции, проверить качество аппроксимации и значимость модели. Примеры решений вы найдете ниже. Удачи в изучении!
Примеры решений МНК
Пример 1. Методом наименьших квадратов для данных, представленных в таблице, найти линейную зависимость
Пример 2. Прибыль фирмы за некоторый период деятельности по годам приведена ниже:
Год 1 2 3 4 5
Прибыль 3,9 4,9 3,4 1,4 1,9
1) Составьте линейную зависимость прибыли по годам деятельности фирмы.
2) Определите ожидаемую прибыль для 6-го года деятельности. Сделайте чертеж.
Пример 3. Экспериментальные данные о значениях переменных х и y приведены в таблице:
1 2 4 6 8
3 2 1 0,5 0
В результате их выравнивания получена функция Используя метод наименьших квадратов, аппроксимировать эти данные линейной зависимостью (найти параметры а и b). Выяснить, какая из двух линий лучше (в смысле метода наименьших квадратов) выравнивает экспериментальные данные. Сделать чертеж.
Пример 4. Данные наблюдений над случайной двумерной величиной (Х, Y) представлены в корреляционной таблице. Методом наименьших квадратов найти выборочное уравнение прямой регрессии Y на X.
Пример 5. Считая, что зависимость между переменными x и y имеет вид $y=ax^2+bx+c$, найти оценки параметров a, b и c методом наименьших квадратов по выборке:
x 7 31 61 99 129 178 209
y 13 10 9 10 12 20 26
Пример 6. Проводится анализ взаимосвязи количества населения (X) и количества практикующих врачей (Y) в регионе.
Годы 81 82 83 84 85 86 87 88 89 90
X, млн. чел. 10 10,3 10,4 10,55 10,6 10,7 10,75 10,9 10,9 11
Y, тыс. чел. 12,1 12,6 13 13,8 14,9 16 18 20 21 22
Оцените по МНК коэффициенты линейного уравнения регрессии $y=b_0+b_1x$.
Существенно ли отличаются от нуля найденные коэффициенты?
Проверьте значимость полученного уравнения при $alpha = 0,01$.
Если количество населения в 1995 году составит 11,5 млн. чел., каково ожидаемое количество врачей? Рассчитайте 99%-й доверительный интервал для данного прогноза.
Рассчитайте коэффициент детерминации
Основы линейной регрессии
Что такое регрессия?
Разместим точки на двумерном графике рассеяния и скажем, что мы имеем линейное соотношение, если данные аппроксимируются прямой линией.
Если мы полагаем, что y зависит от x, причём изменения в y вызываются именно изменениями в x, мы можем определить линию регрессии (регрессия y на x), которая лучше всего описывает прямолинейное соотношение между этими двумя переменными.
Статистическое использование слова «регрессия» исходит из явления, известного как регрессия к среднему, приписываемого сэру Френсису Гальтону (1889).
Он показал, что, хотя высокие отцы имеют тенденцию иметь высоких сыновей, средний рост сыновей меньше, чем у их высоких отцов. Средний рост сыновей «регрессировал» и «двигался вспять» к среднему росту всех отцов в популяции. Таким образом, в среднем высокие отцы имеют более низких (но всё-таки высоких) сыновей, а низкие отцы имеют сыновей более высоких (но всё-таки довольно низких).
Линия регрессии
Математическое уравнение, которое оценивает линию простой (парной) линейной регрессии:
x называется независимой переменной или предиктором.
Y – зависимая переменная или переменная отклика. Это значение, которое мы ожидаем для y (в среднем), если мы знаем величину x, т.е. это «предсказанное значение y»
- a – свободный член (пересечение) линии оценки; это значение Y, когда x=0 (Рис.1).
- b – угловой коэффициент или градиент оценённой линии; она представляет собой величину, на которую Y увеличивается в среднем, если мы увеличиваем x на одну единицу.
- a и b называют коэффициентами регрессии оценённой линии, хотя этот термин часто используют только для b.
Парную линейную регрессию можно расширить, включив в нее более одной независимой переменной; в этом случае она известна как множественная регрессия.

Рис.1. Линия линейной регрессии, показывающая пересечение a и угловой коэффициент b (величину возрастания Y при увеличении x на одну единицу)
Метод наименьших квадратов
Мы выполняем регрессионный анализ, используя выборку наблюдений, где a и b – выборочные оценки истинных (генеральных) параметров, α и β , которые определяют линию линейной регрессии в популяции (генеральной совокупности).
Наиболее простым методом определения коэффициентов a и b является метод наименьших квадратов (МНК).
Подгонка оценивается, рассматривая остатки (вертикальное расстояние каждой точки от линии, например, остаток = наблюдаемому y – предсказанный y, Рис. 2).
Линию лучшей подгонки выбирают так, чтобы сумма квадратов остатков была минимальной.

Рис. 2. Линия линейной регрессии с изображенными остатками (вертикальные пунктирные линии) для каждой точки.
Предположения линейной регрессии
Итак, для каждой наблюдаемой величины  остаток равен разнице
остаток равен разнице  и соответствующего предсказанного
и соответствующего предсказанного  Каждый остаток может быть положительным или отрицательным.
Каждый остаток может быть положительным или отрицательным.
Можно использовать остатки для проверки следующих предположений, лежащих в основе линейной регрессии:
- Остатки нормально распределены с нулевым средним значением;
Если допущения линейности, нормальности и/или постоянной дисперсии сомнительны, мы можем преобразовать или и рассчитать новую линию регрессии, для которой эти допущения удовлетворяются (например, использовать логарифмическое преобразование или др.).
Аномальные значения (выбросы) и точки влияния
«Влиятельное» наблюдение, если оно опущено, изменяет одну или больше оценок параметров модели (т.е. угловой коэффициент или свободный член).
Выброс (наблюдение, которое противоречит большинству значений в наборе данных) может быть «влиятельным» наблюдением и может хорошо обнаруживаться визуально, при осмотре двумерной диаграммы рассеяния или графика остатков.
И для выбросов, и для «влиятельных» наблюдений (точек) используют модели, как с их включением, так и без них, обращают внимание на изменение оценки (коэффициентов регрессии).
При проведении анализа не стоит отбрасывать выбросы или точки влияния автоматически, поскольку простое игнорирование может повлиять на полученные результаты. Всегда изучайте причины появления этих выбросов и анализируйте их.
Гипотеза линейной регрессии
При построении линейной регрессии проверяется нулевая гипотеза о том, что генеральный угловой коэффициент линии регрессии β равен нулю.
Если угловой коэффициент линии равен нулю, между и нет линейного соотношения: изменение не влияет на 
Для тестирования нулевой гипотезы о том, что истинный угловой коэффициент  равен нулю можно воспользоваться следующим алгоритмом:
равен нулю можно воспользоваться следующим алгоритмом:
Вычислить статистику критерия, равную отношению  , которая подчиняется
, которая подчиняется  распределению с
распределению с  степенями свободы, где
степенями свободы, где  стандартная ошибка коэффициента
стандартная ошибка коэффициента 

 ,
,
 — оценка дисперсии остатков.
— оценка дисперсии остатков.
Обычно если достигнутый уровень значимости  нулевая гипотеза отклоняется.
нулевая гипотеза отклоняется.
Можно рассчитать 95% доверительный интервал для генерального углового коэффициента :

где  процентная точка распределения со степенями свободы
процентная точка распределения со степенями свободы  что дает вероятность двустороннего критерия
что дает вероятность двустороннего критерия 
Это тот интервал, который содержит генеральный угловой коэффициент с вероятностью 95%.
Для больших выборок, скажем,  мы можем аппроксимировать
мы можем аппроксимировать  значением 1,96 (то есть статистика критерия будет стремиться к нормальному распределению)
значением 1,96 (то есть статистика критерия будет стремиться к нормальному распределению)
Оценка качества линейной регрессии: коэффициент детерминации R 2
Из-за линейного соотношения и мы ожидаем, что изменяется, по мере того как изменяется , и называем это вариацией, которая обусловлена или объясняется регрессией. Остаточная вариация должна быть как можно меньше.
Если это так, то большая часть вариации будет объясняться регрессией, а точки будут лежать близко к линии регрессии, т.е. линия хорошо соответствует данным.
Долю общей дисперсии , которая объясняется регрессией называют коэффициентом детерминации, обычно выражают через процентное соотношение и обозначают R 2 (в парной линейной регрессии это величина r 2 , квадрат коэффициента корреляции), позволяет субъективно оценить качество уравнения регрессии.
Разность  представляет собой процент дисперсии который нельзя объяснить регрессией.
представляет собой процент дисперсии который нельзя объяснить регрессией.
Нет формального теста для оценки  мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
Применение линии регрессии для прогноза
Можно применять регрессионную линию для прогнозирования значения по значению в пределе наблюдаемого диапазона (никогда не экстраполируйте вне этих пределов).
Мы предсказываем среднюю величину для наблюдаемых, которые имеют определенное значение  путем подстановки этого значения в уравнение линии регрессии.
путем подстановки этого значения в уравнение линии регрессии.
Итак, если  прогнозируем как
прогнозируем как  Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Повторение этой процедуры для различных величин позволяет построить доверительные границы для этой линии. Это полоса или область, которая содержит истинную линию, например, с 95% доверительной вероятностью.
Подобным образом можно рассчитать более широкую область, внутри которой, как мы ожидаем, лежит наибольшее число (обычно 95%) наблюдений.
Простые регрессионные планы
Простые регрессионные планы содержат один непрерывный предиктор. Если существует 3 наблюдения со значениями предиктора P , например, 7, 4 и 9, а план включает эффект первого порядка P , то матрица плана X будет иметь вид

а регрессионное уравнение с использованием P для X1 выглядит как
Если простой регрессионный план содержит эффект высшего порядка для P , например квадратичный эффект, то значения в столбце X1 в матрице плана будут возведены во вторую степень:

а уравнение примет вид
Y = b 0 + b 1 P 2
Сигма -ограниченные и сверхпараметризованные методы кодирования не применяются по отношению к простым регрессионным планам и другим планам, содержащим только непрерывные предикторы (поскольку, просто не существует категориальных предикторов). Независимо от выбранного метода кодирования, значения непрерывных переменных увеличиваются в соответствующей степени и используются как значения для переменных X . При этом перекодировка не выполняется. Кроме того, при описании регрессионных планов можно опустить рассмотрение матрицы плана X , а работать только с регрессионным уравнением.
Пример: простой регрессионный анализ
Этот пример использует данные, представленные в таблице:

Рис. 3. Таблица исходных данных.
Данные составлены на основе сравнения переписей 1960 и 1970 в произвольно выбранных 30 округах. Названия округов представлены в виде имен наблюдений. Информация относительно каждой переменной представлена ниже:

Рис. 4. Таблица спецификаций переменных.
Задача исследования
Для этого примера будут анализироваться корреляция уровня бедности и степень, которая предсказывает процент семей, которые находятся за чертой бедности. Следовательно мы будем трактовать переменную 3 ( Pt_Poor ) как зависимую переменную.
Можно выдвинуть гипотезу: изменение численности населения и процент семей, которые находятся за чертой бедности, связаны между собой. Кажется разумным ожидать, что бедность ведет к оттоку населения, следовательно, здесь будет отрицательная корреляция между процентом людей за чертой бедности и изменением численности населения. Следовательно мы будем трактовать переменную 1 ( Pop_Chng ) как переменную-предиктор.
Просмотр результатов
Коэффициенты регрессии

Рис. 5. Коэффициенты регрессии Pt_Poor на Pop_Chng.
На пересечении строки Pop_Chng и столбца Парам. не стандартизованный коэффициент для регрессии Pt_Poor на Pop_Chng равен -0.40374 . Это означает, что для каждого уменьшения численности населения на единицу, имеется увеличение уровня бедности на .40374. Верхний и нижний (по умолчанию) 95% доверительные пределы для этого не стандартизованного коэффициента не включают ноль, так что коэффициент регрессии значим на уровне p . Обратите внимание на не стандартизованный коэффициент, который также является коэффициентом корреляции Пирсона для простых регрессионных планов, равен -.65, который означает, что для каждого уменьшения стандартного отклонения численности населения происходит увеличение стандартного отклонения уровня бедности на .65.
Распределение переменных
Коэффициенты корреляции могут стать существенно завышены или занижены, если в данных присутствуют большие выбросы. Изучим распределение зависимой переменной Pt_Poor по округам. Для этого построим гистограмму переменной Pt_Poor .

Рис. 6. Гистограмма переменной Pt_Poor.
Как вы можете заметить, распределение этой переменной заметно отличается от нормального распределения. Тем не менее, хотя даже два округа (два правых столбца) имеют высокий процент семей, которые находятся за чертой бедности, чем ожидалось в случае нормального распределения, кажется, что они находятся «внутри диапазона.»

Рис. 7. Гистограмма переменной Pt_Poor.
Это суждение в некоторой степени субъективно. Эмпирическое правило гласит, что выбросы необходимо учитывать, если наблюдение (или наблюдения) не попадают в интервал (среднее ± 3 умноженное на стандартное отклонение). В этом случае стоит повторить анализ с выбросами и без, чтобы убедиться, что они не оказывают серьезного эффекта на корреляцию между членами совокупности.
Диаграмма рассеяния
Если одна из гипотез априори о взаимосвязи между заданными переменными, то ее полезно проверить на графике соответствующей диаграммы рассеяния.

Рис. 8. Диаграмма рассеяния.
Диаграмма рассеяния показывает явную отрицательную корреляцию ( -.65 ) между двумя переменными. На ней также показан 95% доверительный интервал для линии регрессии, т.е., с 95% вероятностью линия регрессии проходит между двумя пунктирными кривыми.
Критерии значимости

Рис. 9. Таблица, содержащая критерии значимости.
Критерий для коэффициента регрессии Pop_Chng подтверждает, что Pop_Chng сильно связано с Pt_Poor , p .
На этом примере было показано, как проанализировать простой регрессионный план. Была также представлена интерпретация не стандартизованных и стандартизованных коэффициентов регрессии. Обсуждена важность изучения распределения откликов зависимой переменной, продемонстрирована техника определения направления и силы взаимосвязи между предиктором и зависимой переменной.
источники:
http://www.matburo.ru/ex_ms.php?p1=msmnk
http://statistica.ru/theory/osnovy-lineynoy-regressii/
На этом занятии
мы с вами рассмотрим алгоритм, который носит название метод наименьших
квадратов. Для начала немного теории. Чтобы ее хорошо понимать нужны
базовые знания по теории вероятностей, в частности понимание ПРВ, а также
знать, что такое производная и как она вычисляется. Остальное я сейчас
расскажу.
На практике
встречаются задачи, когда производились измерения некоторой функциональной
зависимости, но из-за погрешностей приборов, или неточных сведений или еще по
какой-либо причине, измерения немного отстоят от истинных значений функции и
образуют некий разброс:
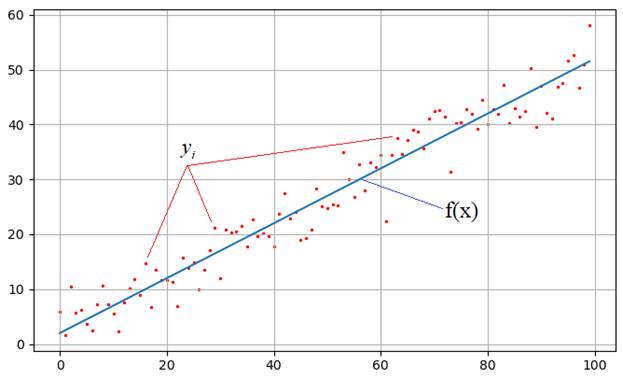
Наша задача:
зная характер функциональной зависимости, подобрать ее параметры так, чтобы она
наилучшим образом описывала экспериментальные данные ![]() Например, на
Например, на
рисунке явно прослеживается линейная зависимость. Мы это можем определить либо
чисто визуально, либо заранее знать о характере функции. Но, в любом случае
предполагается, что ее общий вид нам известен. Так вот, для линейной функции
достаточно определить два параметра k и b:
![]()
чтобы построить
аппроксимацию (приближение) линейного графика к экспериментальным зависимостям.
Конечно, вид функциональной зависимости может быть и другим, например,
квадратической (парабола), синусоидальной, или даже определяться суммой
известных функций, но для простоты понимания, мы для начала рассмотрим именно
линейный график с двумя неизвестными коэффициентами.
Итак, будем
считать, что на первый вопрос о характере функциональной зависимости
экспериментальных данных ответ дан. Следующий вопрос: как измерить качество
аппроксимации измерений ![]() функцией
функцией
![]() ? Вообще, таких
? Вообще, таких
критериев можно придумать множество, например:
— сумма квадратов
ошибок отклонений:
![]()
— сумма модулей
ошибок отклонений:
![]()
— минимум
максимальной по модулю ошибки:
![]()
и так далее. Каждый
из критериев может приводить к своему алгоритму обработки экспериментальных
значений. Так вот, в методе наименьших квадратов используется минимум суммы
квадратов ошибок. И этому есть математическое обоснование. Часто результаты
реальных измерений имеют стандартное (гауссовское) отклонение относительно
измеряемого параметра:
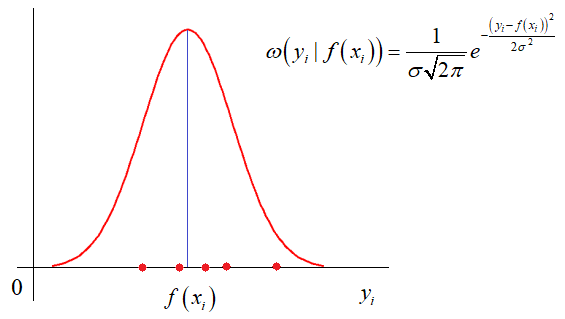
Здесь σ –
стандартное отклонение (СКО) наблюдаемых значений ![]() от функции
от функции ![]() . Отсюда хорошо
. Отсюда хорошо
видно, что чем ближе измерение к истинному значению параметра, тем больше
значение функции плотности распределения условной вероятности. И, так для всех
точек измерения. Учитывая, что они выполняются независимо друг от друга, то
можно записать следующее функциональное выражение:
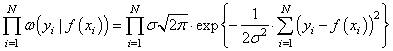
Получается, что лучшее
описание экспериментальных данных с помощью функции ![]() должно проходить по
должно проходить по
точкам, в которых достигается максимум этого выражения. Очевидно, что при
поиске максимума можно не учитывать множитель 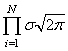 , а экспонента будет
, а экспонента будет
принимать максимальное значение при минимуме ее отрицательной степени:
![]()
Здесь также
множитель можно не учитывать, получаем критерий качества минимум суммы квадрата
ошибок:
![]()
Как мы помним,
наша цель – подобрать параметры ![]() функции
функции
![]()
которые как раз
и обеспечивают минимум этого критерия, то есть, величина E зависит от этих
подбираемых величин:
![]()
И ее можно
рассматривать как квадратическую функцию от аргументов ![]() Из школьного курса
Из школьного курса
математики мы знаем как находится точка экстремума функции – это точка, в
которой производная равна нулю:
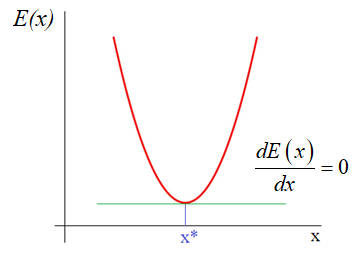
Здесь все также,
нужно взять частные производные по каждому параметру и приравнять результат
нулю, получим систему линейных уравнений:
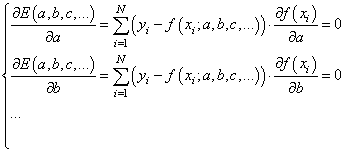
Чтобы наполнить
конкретикой эту систему, нам нужно вернуться к исходному примеру с линейной
функцией:
![]()
Эта функция
зависит от двух параметров: k и b с частными
производными:
![]()
Подставляем все
в систему, имеем:
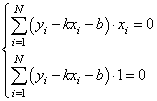
или, в виде:
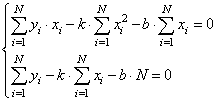
Разделим все на N:
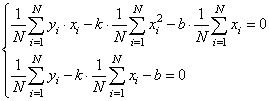
Смотрите, что в
итоге получилось. Формулы с суммами представляют собой первые и вторые
начальные моменты, а также один смешанный момент:
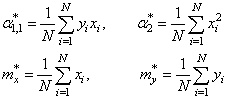
Здесь * означает
экспериментальные моменты. В этих обозначениях, получаем:
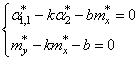
Отсюда находим,
что
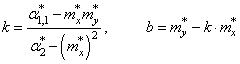
Все, мы получили
оценки параметров k и b для линейной
аппроксимации экспериментальных данных по методу наименьших квадратов. По
аналогии можно вычислять параметры для других функциональных зависимостей,
например, квадратической:
![]()
Здесь будет уже
три свободных параметра и три уравнения, решая которые будем получать лучшую
аппроксимацию по критерию минимума суммарной квадратической ошибки отклонений.
Реализация на Python
В заключение
этого занятия реализуем метод наименьших квадратов на Python. Для этого нам
понадобятся две довольно популярные библиотеки numpy и matplotlib. Если они у вас
не установлены, то делается это просто – через команды:
pip install numpy
pip install matplotlib
После этого, мы
можем их импортировать и использовать в программе:
import numpy as np import matplotlib.pyplot as plt
Первая довольно
эффективная для выполнения различных математических операций, включая векторные
и матричные. Вторая служит для построения графиков.
Итак, вначале
определим необходимые начальные величины:
N = 100 # число экспериментов sigma = 3 # стандартное отклонение наблюдаемых значений k = 0.5 # теоретическое значение параметра k b = 2 # теоретическое значение параметра b
Формируем
вспомогательный вектор
![]()
с помощью метода
array, который
возвращает объект-вектор на основе итерируемой функции range:
Затем, вычисляем
значения теоретической функции:
f = np.array([k*z+b for z in range(N)])
и добавляем к
ней случайные отклонения для моделирования результатов наблюдений:
y = f + np.random.normal(0, sigma, N)
Если сейчас
отобразить наборы точек y, то они будут выглядеть следующим
образом:
plt.scatter(x, y, s=2, c='red') plt.grid(True) plt.show()
Теперь у нас все
есть для вычисления коэффициентов k и b по экспериментальным
данным:
# вычисляем коэффициенты mx = x.sum()/N my = y.sum()/N a2 = np.dot(x.T, x)/N a11 = np.dot(x.T, y)/N kk = (a11 - mx*my)/(a2 - mx**2) bb = my - kk*mx
Здесь выражение x.T*x – это
произведение:
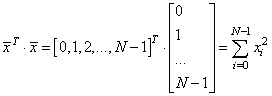
Далее, построим
точки полученной аппроксимации:
ff = np.array([kk*z+bb for z in range(N)])
и отобразим оба
линейных графика:
plt.plot(f) plt.plot(ff, c='red')
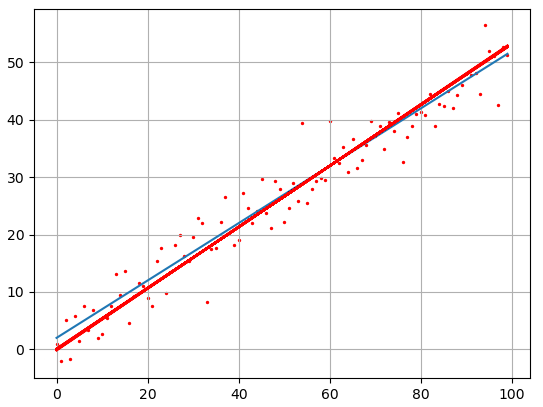
Как видите
результат аппроксимации довольно близок начальному, теоретическому графику. Вот
так работает метод наименьших квадратов.
Реализация алгоритма на Python (файл mnsq.py)
Видео по теме
Цель любого физического эксперимента — проверить, выполняется ли некоторая
теоретическая закономерность (модель), а также получить или уточнить
её параметры. Поскольку набор экспериментальных данных неизбежно ограничен,
а каждое отдельное измерение имеет погрешность, можно говорить лишь
об оценке этих параметров. В большинстве случаев измеряется не одна
величина, а некоторая функциональная зависимость величин друг от друга.
В таком случае возникает необходимость построить оценку параметров этой зависимости.
Пример. Рассмотрим процедуру измерения сопротивления некоторого резистора.
Простейшая теоретическая модель для резистора — закон Ома U=RI,
где сопротивление R — единственный параметр модели. Часто при измерениях
возможно возникновение систематической ошибки — смещение нуля напряжения или тока.
Тогда для получения более корректной оценки сопротивления стоит использовать
модель с двумя параметрами: U=RI+U0.
Для построения оценки нужны следующие компоненты
-
•
данные — результаты измерений {xi,yi}
и их погрешности {σi}
(экспериментальная погрешность является неотъемлемой
частью набора данных!); -
•
модель y=f(x|θ1,θ2,…) —
параметрическое описание исследуемой зависимости
(θ — набор параметров модели, например,
коэффициенты {k,b} прямой f(x)=kx+b); -
•
процедура построения оценки параметров по
измеренным данным («оценщик»):
Рассмотрим самые распространенные способы построения оценки.
3.1 Метод минимума хи-квадрат
Обозначим отклонения результатов некоторой серии измерений от теоретической
модели y=f(x|θ) как
| Δyi=yi-f(xi|θ),i=1…n, |
где θ — некоторый параметр (или набор параметров),
для которого требуется построить наилучшую оценку. Нормируем Δyi
на стандартные отклонения σi и построим сумму
которую принято называть суммой хи-квадрат.
Метод минимума хи-квадрат (метод Пирсона) заключается в подборе такого
θ, при котором сумма квадратов отклонений от теоретической
модели, нормированных на ошибки измерений, достигает минимума:
Замечание. Подразумевается, что погрешность измерений σi указана только для
вертикальной оси y. Поэтому, при использовании метода следует выбирать оcи
таким образом, чтобы относительная ошибка по оси абсцисс была значительно меньше,
чем по оси ординат.
Данный метод вполне соответствует нашему интуитивному представлению
о том, как теоретическая зависимость должна проходить через экспериментальные
точки. Ясно, что чем ближе данные к модельной кривой, тем
меньше будет сумма χ2. При этом, чем больше погрешность точки, тем
в большей степени дозволено результатам измерений отклоняться от модели.
Метода минимума χ2 является частным случаем
более общего метода максимума правдоподобия (см. ниже),
реализующийся при нормальном (гауссовом) распределении ошибок.
Можно показать (см. [5]), что оценка по методу хи-квадрат является состоятельной,
несмещенной и, если данные распределены нормально,
имеет максимальную эффективность (см. приложение 5.2).
Замечание. Простые аналитические выражения для оценки методом хи-квадрат существуют
(см. п. 3.6.1, 3.6.4) только в случае линейной
зависимости f(x)=kx+b (впрочем, нелинейную зависимость часто можно
заменой переменных свести к линейной). В общем случае задача поиска
минимума χ2(θ) решается численно, а соответствующая процедура
реализована в большинстве специализированных программных пакетов
по обработке данных.
3.2 Метод максимального правдоподобия.
Рассмотрим кратко один
из наиболее общих методов оценки параметров зависимостей —
метод максимума правдоподобия.
Сделаем два ключевых предположения:
-
•
зависимость между измеряемыми величинами действительно может
быть описана функцией y=f(x|θ) при некотором θ; -
•
все отклонения Δyi результатов измерений от теоретической модели
являются независимыми и имеют случайный (не систематический!) характер.
Пусть P(Δyi) — вероятность обнаружить отклонение Δyi
при фиксированных {xi}, погрешностях {σi} и параметрах модели θ.
Построим функцию, равную вероятности обнаружить
весь набор отклонений {Δy1,…,Δyn}. Ввиду независимости
измерений она равна произведению вероятностей:
Функцию L называют функцией правдоподобия.
Метод максимума правдоподобия заключается в поиске такого θ,
при котором наблюдаемое отклонение от модели будет иметь
наибольшую вероятность, то есть
Замечание. Поскольку с суммой работать удобнее, чем с произведениями, чаще
используют не саму функцию L, а её логарифм:
lnL=∑ilnP(Δyi).
Пусть теперь ошибки измерений имеют нормальное распределение
(напомним, что согласно центральной предельной теореме нормальное распределение
применимо, если отклонения возникают из-за большого
числа независимых факторов, что на практике реализуется довольно часто).
Согласно (2.5), вероятность обнаружить в i-м измерении
отклонение Δyi пропорциональна величине
где σi — стандартная ошибка измерения величины yi. Тогда
логарифм функции правдоподобия (3.2) будет равен (с точностью до константы)
| lnL=-∑iΔyi22σi2=-12χ2. |
Таким образом, максимум правдоподобия действительно будет соответствовать
минимуму χ2.
3.3 Метод наименьших квадратов (МНК).
Рассмотрим случай, когда все погрешности измерений одинаковы,
σi=const. Тогда множитель 1/σ2 в сумме χ2
выносится за скобки, и оценка параметра сводится к нахождению минимума суммы
квадратов отклонений:
| S(θ)=∑i=1n(yi-f(xi|θ))2→min. | (3.3) |
Оценка по методу наименьших квадратов (МНК) удобна в том случае,
когда не известны погрешности отдельных измерений. Однако тот факт, что
метод МНК игнорирует информацию о погрешностях, является и его основным
недостатком. В частности, это не позволяет определить точность оценки
(например, погрешности коэффициентов прямой σk и
σb) без привлечения дополнительных предположений
(см. п. 3.6.2 и 3.6.3).
3.4 Проверка качества аппроксимации
Значение суммы χ2 позволяет оценить, насколько хорошо данные описываются
предлагаемой моделью y=f(x|θ).
Предположим, что распределение ошибок при измерениях нормальное.
Тогда можно ожидать, что большая часть отклонений данных от модели будет
порядка одной среднеквадратичной ошибки: Δyi∼σi.
Следовательно, сумма хи-квадрат (3.1) окажется по порядку
величины равна числу входящих в неё слагаемых: χ2∼n.
Замечание. Точнее, если функция f(x|θ1,…,θp)
содержит p подгоночных параметров
(например, p=2 для линейной зависимости f(x)=kx+b),
то при заданных θ лишь n-p слагаемых в сумме хи-квадрат будут независимы.
Иными словами, когда параметры θ определены
из условия минимума хи-квадрат, сумму χ2 можно рассматривать как функцию
n-p переменных. Величину n-p называют числом степеней свободы задачи.
В теории вероятностей доказывается (см. [4] или [5]),
что ожидаемое среднее значение (математическое ожидание) суммы χ2
в точности равно числу степеней свободы:
Таким образом, при хорошем соответствии модели и данных,
величина χ2/(n-p) должна в среднем быть равна единице.
Значения существенно большие (2 и выше) свидетельствуют либо о
плохом соответствии теории и результатов измерений,
либо о заниженных погрешностях.
Значения меньше 0,5 как правило свидетельствуют о завышенных погрешностях.
Замечание. Чтобы дать строгий количественный критерий, с какой долей вероятности
гипотезу y=f(x) можно считать подтверждённой или опровергнутой,
нужно знать вероятностный закон, которому подчиняется функция χ2.
Если ошибки измерений распределены нормально, величина хи-квадрат подчинятся
одноимённому распределению (с n-p степенями свободы).
В элементарных функциях распределение хи-квадрат не выражается,
но может быть легко найдено численно: функция встроена во все основные
статистические пакеты, либо может быть вычислена по таблицам.
3.5 Оценка погрешности параметров
Важным свойством метода хи-квадрат является «встроенная» возможность
нахождения погрешности вычисленных параметров σθ.
Пусть функция L(θ) имеет максимум при θ=θ^, то есть
θ^ — решение задачи о максимуме правдоподобия. Согласно центральной предельной теореме мы ожидаем, что функция правдоподобия будем близка к нормальному распределению: L(θ)∝exp(-(θ-θ^)22σθ2),
где σθ — искомая погрешность параметра. Тогда в окрестности θ^ функция χ2(θ)=-2ln(L(θ)) имеет вид параболы:
Легко убедиться, что:
Иными словами, при отклонении параметра θ на одну ошибку σθ от значения
θ^,
минимизирующего χ2, функция χ2(θ) изменится на единицу. Таким образом для нахождения интервальной оценки для искомого параметра достаточно графическим или численным образом решить уравнение
Вероятностное содержание этого интервала будет равно 68% (его еще называют 1–σ интервалом).
Отклонение χ2 на 2 будет соответствовать уже 95% доверительному интервалу.
Замечание.
Приведенное решение просто использовать только в случае одного параметра. Впрочем, все приведенные рассуждения верны и в много-параметрическом случае. Просто решением уравнения 3.4 будет не отрезок, а некоторая многомерная фигура (эллипс в двумерном случае и гипер-эллипс при больших размерностях пространства параметров). Вероятностное содержание области, ограниченной такой фигурой будет уже не равно 68%, но может быть вычислено по соответствующим таблицам. Подробнее о многомерном случае в разделе 5.5.
3.6 Методы построения наилучшей прямой
Применим перечисленные выше методы к задаче о построении наилучшей прямой
y=kx+b по экспериментальным точкам {xi,yi}.
Линейность функции позволяет записать решение в относительно
простом аналитическом виде.
Обозначим расстояние от i-й экспериментальной точки до искомой прямой,
измеренное по вертикали, как
и найдём такие параметры {k,b}, чтобы «совокупное» отклонение
результатов от линейной зависимости было в некотором смысле минимально.
3.6.1 Метод наименьших квадратов
Пусть сумма квадратов расстояний от точек до прямой минимальна:
| S(k,b)=∑i=1n(yi-(kxi+b))2→min. | (3.5) |
Данный метод построения наилучшей прямой называют методом наименьших
квадратов (МНК).
Рассмотрим сперва более простой частный случай, когда искомая прямая
заведомо проходит через «ноль», то есть b=0 и y=kx.
Необходимое условие минимума функции S(k), как известно,
есть равенство нулю её производной. Дифференцируя сумму (3.5)
по k, считая все величины {xi,yi} константами,
найдём
| dSdk=-∑i=1n2xi(yi-kxi)=0. |
Решая относительно k, находим
Поделив числитель и знаменатель на n, этот результат можно записать
более компактно:
Напомним, что угловые скобки означают усреднение по всем экспериментальным точкам:
В общем случае при b≠0 функция S(k,b) должна иметь
минимум как по k, так и по b. Поэтому имеем систему из двух
уравнений ∂S/∂k=0, ∂S/∂b=0,
решая которую, можно получить (получите самостоятельно):
| k=⟨xy⟩-⟨x⟩⟨y⟩⟨x2⟩-⟨x⟩2,b=⟨y⟩-k⟨x⟩. | (3.7) |
Эти соотношения и есть решение задачи о построении наилучшей прямой
методом наименьших квадратов.
Замечание. Совсем кратко формулу (3.7) можно записать, если ввести обозначение
Dxy≡⟨xy⟩-⟨x⟩⟨y⟩=⟨x-⟨x⟩⟩⋅⟨y-⟨y⟩⟩.
(3.8)
В математической статистике величину Dxy называют ковариацией.
При x≡y имеем дисперсию
Dxx=⟨(x-⟨x⟩)2⟩.
Тогда
k=DxyDxx,b=⟨y⟩-k⟨x⟩.
(3.9)
3.6.2 Погрешность МНК в линейной модели
Погрешности σk и σb коэффициентов, вычисленных
по формуле (3.7) (или (3.6)), можно оценить в
следующих предположениях.
Пусть погрешность измерений величины x пренебрежимо мала: σx≈0,
а погрешности по y одинаковы для всех экспериментальных точек
σy=const, независимы и имеют случайный характер
(систематическая погрешность отсутствует).
Пользуясь в этих предположениях формулами для погрешностей косвенных
измерений (см. раздел (2.6)) можно получить следующие
соотношения:
| σk=1n-2(DyyDxx-k2), | (3.10) |
где использованы введённые выше сокращённые обозначения (3.8).
Коэффициент n-2 отражает число независимых <<степеней
свободы>>: n экспериментальных точек за вычетом двух
условий связи (3.7).
В частном случае y=kx:
| σk=1n-1(⟨y2⟩⟨x2⟩-k2). | (3.12) |
3.6.3 Недостатки и условия применимости МНК
Формулы (3.7) (или (3.6)) позволяют провести
прямую по любому набору экспериментальных данных, а полученные
выше соотношения — вычислить
соответствующую среднеквадратичную ошибку для её коэффициентов. Однако
далеко не всегда результат будет иметь физический смысл. Перечислим
ограничения применимости данного метода.
В первую очередь метод наименьших квадратов — статистический,
и поэтому он предполагает использование достаточно большого количества
экспериментальных точек (желательно n>10).
Поскольку метод предполагает наличие погрешностей только по y,
оси следует выбирать так, чтобы погрешность σx откладываемой
по оси абсцисс величины была минимальна.
Кроме того, метод предполагает, что все погрешности в опыте —
случайны. Соответственно, формулы (3.10)–(3.12)
применимы только для оценки случайной составляющей ошибки k
или b. Если в опыте предполагаются достаточно большие систематические
ошибки, они должны быть оценены отдельно. Отметим, что для
оценки систематических ошибок не существует строгих математических
методов, поэтому в таком случае проще и разумнее всего воспользоваться
графическим методом.
Одна из основных проблем, связанных с определением погрешностей методом
наименьших квадратов заключается в том, что он дает разумные погрешности даже в
том случае, когда данные вообще не соответствуют модели.
Если погрешности измерений известны, предпочтительно использовать
метод минимума χ2.
Наконец, стоит предостеречь от использования любых аналитических
методов «вслепую», без построения графиков. В частности, МНК не способен
выявить такие «аномалии», как отклонения от линейной зависимости,
немонотонность, случайные всплески и т.п. Все эти случаи требуют особого
рассмотрения и могут быть легко обнаружены визуально при построении графика.
3.6.4 Метод хи-квадрат построения прямой
Пусть справедливы те же предположения, что и для метода наименьших квадратов,
но погрешности σi экспериментальных точек различны. Метод
минимума хи-квадрат сводится к минимизации суммы квадратов отклонений,
где каждое слагаемое взято с весом wi=1/σi2:
| χ2(k,b)=∑i=1nwi(yi-(kxi+b))2→min. |
Этот метод также называют взвешенным методом наименьших квадратов.
Определим взвешенное среднее от
некоторого набора значений {xi} как
где W=∑iwi — нормировочная константа.
Повторяя процедуру, использованную при выводе (3.7), нетрудно
получить (получите) совершенно аналогичные формулы для искомых коэффициентов:
| k=⟨xy⟩′-⟨x⟩′⟨y⟩′⟨x2⟩′-⟨x⟩′2,b=⟨y⟩′-k⟨x⟩′, | (3.13) |
с тем отличием от (3.7), что под угловыми скобками
⟨…⟩′
теперь надо понимать усреднение с весами wi=1/σi2.
Записанные формулы позволяют вычислить коэффициенты прямой,
если известны погрешности σyi. Значения σyi
могут быть получены либо из некоторой теории, либо измерены непосредственно
(многократным повторением измерений при каждом xi), либо оценены из
каких-то дополнительных соображений (например, как инструментальная погрешность).
Материал из MachineLearning.
Перейти к: навигация, поиск
Метод наименьших квадратов — метод нахождения оптимальных параметров линейной регрессии, таких, что сумма квадратов ошибок (регрессионных остатков) минимальна. Метод заключается в минимизации евклидова расстояния между двумя векторами — вектором восстановленных значений зависимой переменной и вектором фактических значений зависимой переменной.
Содержание
- 1 Постановка задачи
- 2 Пример построения линейной регрессии
- 3 Смотри также
- 4 Литература
- 5 Внешние ссылки
Постановка задачи
Задача метода наименьших квадратов состоит в выборе вектора , минимизирующего ошибку
.
Эта ошибка есть расстояние от вектора до вектора
.
Вектор лежит в простанстве столбцов матрицы
,
так как есть линейная комбинация столбцов этой матрицы с коэффициентами
.
Отыскание решения по методу наименьших квадратов эквивалентно задаче отыскания такой точки
,
которая лежит ближе всего к и находится при этом в пространстве столбцов матрицы
.
Таким образом, вектор должен быть проекцией
на пространство столбцов и вектор невязки
должен быть ортогонален этому пространству. Ортогональность состоит в том, что каждый вектор в пространстве столбцов
есть линейная комбинация столбцов с некоторыми коэффициентами , то есть это вектор
.
Для всех в пространстве
, эти векторы должны быть перпендикулярны невязке
:
Так как это равенство должно быть справедливо для произвольного вектора , то
Решение по методу наименьших квадратов несовместной системы ,
состоящей из уравнений с
неизвестными, есть уравнение
которое называется нормальным уравнением.
Если столбцы матрицы линейно независимы, то матрица
обратима
и единственное решение
Проекция вектора на пространство столбцов матрицы имеет вид
Матрица называется матрицей проектирования вектора
на пространство столбцов матрицы
.
Эта матрица имеет два основных свойства: она идемпотентна, , и симметрична,
.
Обратное также верно: матрица, обладающая этими двумя свойствами есть матрица проектирования на свое пространство столбцов.
Пример построения линейной регрессии
Задана выборка — таблица
Задана регрессионная модель — квадратичный полином
Назначенная модель является линейной. Для нахождения оптимального
значения вектора параметров выполняется следующая подстановка:
Тогда матрица значений подстановок свободной переменной
будет иметь вид
Задан критерий качества модели: функция ошибки
Здесь вектор . Требуется найти такие параметры
, которые бы доставляли
минимум этому функционалу,
Требуется найти такие параметры , которые доставляют минимум
— норме вектора
невязок .
Для того, чтобы найти минимум функции невязки, требуется
приравнять ее производные к нулю. Производные данной функции
по составляют
Это выражение совпадает с нормальным уравнением. Решение
этой задачи должно удовлетворять системе линейных уравнений
то есть,
После получения весов можно построить график найденной функции.
При обращении матрицы предполагается, что эта
матрица невырождена и не плохо обусловлена. О том, как работать с плохо обусловленными матрицами см. в статье Сингулярное разложение.
Смотри также
- Линейная регрессия (пример)
- Нелинейная регрессия и метод наименьших квадратов
- Регрессионный анализ
- Анализ регрессионных остатков
- Сингулярное разложение
Литература
- Стренг Г. Линейная алгебра и ее применения. М.: Мир. 1980.
- Каханер Д., Моулер К., Нэш С. Численные методы и программное обеспечение. М.: Мир. 1998.
- Стрижов В. В. Методы индуктивного порождения регрессионных моделей. М.: ВЦ РАН. 2008. 55 с. Брошюра, PDF.
Внешние ссылки
Wikipedia.org, Least squares

Метод наименьших квадратов (МНК) — математический метод, применяемый для решения различных задач, основанный на минимизации суммы квадратов отклонений некоторых функций от экспериментальных входных данных. Он может использоваться для «решения» переопределенных систем уравнений (когда количество уравнений превышает количество неизвестных), для поиска решения в случае обычных (не переопределенных) нелинейных систем уравнений, для аппроксимации точечных значений некоторой функции. МНК является одним из базовых методов регрессионного анализа (b) для оценки неизвестных параметров регрессионных моделей по выборочным данным.
История
До начала XIX в. учёные не имели определённых правил для решения системы уравнений (b) , в которой число неизвестных меньше, чем число уравнений; до этого времени употреблялись частные приёмы, зависевшие от вида уравнений и от остроумия вычислителей, и потому разные вычислители, исходя из тех же данных наблюдений, приходили к различным выводам. Гауссу (b) (1795) принадлежит первое применение метода, а Лежандр (b) (1805) независимо открыл и опубликовал его под современным названием (фр. (b) Méthode des moindres quarrés)[1]. Лаплас (b) связал метод с теорией вероятностей (b) , а американский математик Эдрейнru (b) en (1808) рассмотрел его теоретико-вероятностные приложения[2]. Метод распространён и усовершенствован дальнейшими изысканиями Энке (b) , Бесселя (b) , Ганзена и других.
Работы А. А. Маркова (b) в начале XX века позволили включить метод наименьших квадратов в теорию оценивания (b) математической статистики, в которой он является важной и естественной частью. Усилиями Ю. Неймана, Ф. Дэвида, А. Эйткена, С. Рао было получено множество немаловажных результатов в этой области[3].
Суть метода наименьших квадратов
Пусть , набор скалярных экспериментальных данных, , набор векторных экспериментальных данных и предполагается, что зависит от .
Вводится некоторая (в простейшем случае линейная) скалярная функция , которая определяется вектором неизвестных параметров .
Ставится задача найти вектор такой, чтобы совокупность погрешностей была в некотором смысле минимальной.
Согласно методу наименьших квадратов решением этой задачи является вектор , который минимизирует функцию
В простейшем случае , и тогда результатом МНК будет среднее арифметическое (b) входных данных.
Преимущество МНК перед минимизацией других видов ошибок состоит в том, что если дифференцируема по , то тоже дифференцируема. Приравнивание частных производных к нулю сводит задачу к решению системы уравнений, причём если зависит от линейно, то и система уравнений будет линейной.
Пример — система линейных уравнений
В частности, метод наименьших квадратов может использоваться для «решения» системы линейных уравнений
- ,
где прямоугольная матрица размера (то есть число строк матрицы A больше количества искомых переменных).
Такая система уравнений в общем случае не имеет решения. Поэтому эту систему можно «решить» только в смысле выбора такого вектора , чтобы минимизировать «расстояние» между векторами и . Для этого можно применить критерий минимизации суммы квадратов разностей левой и правой частей уравнений системы, то есть . Нетрудно показать, что решение этой задачи минимизации приводит к решению следующей системы уравнений
- .
Используя оператор псевдоинверсии (b) , решение можно переписать так:
- ,
где — псевдообратная матрица для .
Эту задачу также можно «решить», используя так называемый взвешенный МНК (см. ниже), когда разные уравнения системы получают разный вес из теоретических соображений.
Строгое обоснование и установление границ содержательной применимости метода даны А. А. Марковым (b) и А. Н. Колмогоровым (b) .
МНК в регрессионном анализе (аппроксимация данных)
Пусть имеется значений некоторой переменной (это могут быть результаты наблюдений, экспериментов и т. д.) и соответствующих переменных . Задача заключается в том, чтобы взаимосвязь между и аппроксимировать некоторой функцией , известной с точностью до некоторых неизвестных параметров , то есть фактически найти наилучшие значения параметров , максимально приближающие значения к фактическим значениям . Фактически это сводится к случаю «решения» переопределенной системы уравнений относительно :
.
В регрессионном анализе и в частности в эконометрике используются вероятностные модели зависимости между переменными
,
где — так называемые случайные ошибки модели.
Соответственно, отклонения наблюдаемых значений от модельных предполагается уже в самой модели. Сущность МНК (обычного, классического) заключается в том, чтобы найти такие параметры , при которых сумма квадратов отклонений (ошибок, для регрессионных моделей их часто называют остатками регрессии) будет минимальной:
- ,
где — англ. (b) Residual Sum of Squares[4] определяется как:
- .
В общем случае решение этой задачи может осуществляться численными методами оптимизации (минимизации). В этом случае говорят о нелинейном МНК (NLS или NLLS — англ. (b) Non-Linear Least Squares). Во многих случаях можно получить аналитическое решение. Для решения задачи минимизации необходимо найти стационарные точки функции , продифференцировав её по неизвестным параметрам , приравняв производные к нулю и решив полученную систему уравнений:
- .
МНК в случае линейной регрессии
Пусть регрессионная зависимость является линейной (b) :
- .
Пусть y — вектор-столбец наблюдений объясняемой переменной, а — это -матрица наблюдений факторов (строки матрицы — векторы значений факторов в данном наблюдении, по столбцам — вектор значений данного фактора во всех наблюдениях). Матричное представление линейной модели имеет вид:
- .
Тогда вектор оценок объясняемой переменной и вектор остатков регрессии будут равны
- .
соответственно сумма квадратов остатков регрессии будет равна
- .
Дифференцируя эту функцию по вектору параметров и приравняв производные к нулю, получим систему уравнений (в матричной форме):
- .
В расшифрованной матричной форме эта система уравнений выглядит следующим образом:
где все суммы берутся по всем допустимым значениям .
Если в модель включена константа (как обычно), то при всех , поэтому в левом верхнем углу матрицы системы уравнений находится количество наблюдений , а в остальных элементах первой строки и первого столбца — просто суммы значений переменных: и первый элемент правой части системы — .
Решение этой системы уравнений и дает общую формулу МНК-оценок для линейной модели:
- .
Для аналитических целей оказывается полезным последнее представление этой формулы (в системе уравнений при делении на n вместо сумм фигурируют средние арифметические). Если в регрессионной модели данные центрированы, то в этом представлении первая матрица имеет смысл выборочной ковариационной матрицы факторов, а вторая — вектор ковариаций факторов с зависимой переменной. Если кроме того данные ещё и нормированы на СКО (то есть в конечном итоге стандартизированы), то первая матрица имеет смысл выборочной корреляционной матрицы факторов, второй вектор — вектора выборочных корреляций факторов с зависимой переменной.
Немаловажное свойство МНК-оценок для моделей с константой — линия построенной регрессии проходит через центр тяжести выборочных данных, то есть выполняется равенство:
- .
В частности, в крайнем случае, когда единственным регрессором является константа, получаем, что МНК-оценка единственного параметра (собственно константы) равна среднему значению объясняемой переменной. То есть среднее арифметическое, известное своими хорошими свойствами из законов больших чисел, также является МНК-оценкой — удовлетворяет критерию минимума суммы квадратов отклонений от неё.
Простейшие частные случаи
В случае парной линейной регрессии , когда оценивается линейная зависимость одной переменной от другой, формулы расчёта упрощаются (можно обойтись без матричной алгебры). Система уравнений имеет вид:
- .
Отсюда несложно найти оценки коэффициентов:
Несмотря на то, что в общем случае модели с константой предпочтительней, в некоторых случаях из теоретических соображений известно, что константа должна быть равна нулю. Например, в физике зависимость между напряжением и силой тока имеет вид ; замеряя напряжение и силу тока, необходимо оценить сопротивление. В таком случае речь идёт о модели . В этом случае вместо системы уравнений имеем единственное уравнение
.
Следовательно, формула оценки единственного коэффициента имеет вид
.
Случай полиномиальной модели
Если данные аппроксимируются полиномиальной функцией регрессии одной переменной , то, воспринимая степени как независимые факторы для каждого можно оценить параметры модели исходя из общей формулы оценки параметров линейной модели. Для этого в общей формуле достаточно учесть, что при такой интерпретации и . Следовательно, матричные уравнения в данном случае примут вид:
Статистические свойства МНК-оценок
В первую очередь отметим, что для линейных моделей МНК-оценки являются линейными оценками, как это следует из вышеприведённой формулы. Для несмещённости (b) МНК-оценок необходимо и достаточно выполнения важнейшего условия регрессионного анализа (b) : условное по факторам математическое ожидание (b) случайной ошибки должно быть равно нулю. Данное условие, в частности, выполнено, если
- математическое ожидание случайных ошибок равно нулю и
- факторы и случайные ошибки — независимые случайные величины (b) .
Первое условие для моделей с константой можно считать выполненным всегда, так как константа берёт на себя ненулевое математическое ожидание ошибок (поэтому модели с константой в общем случае предпочтительнее).
Второе условие — условие экзогенности (b) факторов — принципиальное. Если это свойство не выполнено, то можно считать, что практически любые оценки будут крайне неудовлетворительными: они не будут даже состоятельными (b) (то есть даже очень большой объём данных не позволяет в этом случае получить качественные оценки). В классическом случае делается более сильное предположение о детерминированности факторов, в отличие от случайной ошибки, что автоматически означает выполнение условия экзогенности. В общем случае для состоятельности оценок достаточно выполнения условия экзогенности вместе со сходимостью матрицы к некоторой невырожденной матрице при увеличении объёма выборки до бесконечности.
Для того, чтобы кроме состоятельности и несмещённости (b) , оценки (обычного) МНК были ещё и эффективными (наилучшими в классе линейных несмещённых оценок), необходимо выполнение дополнительных свойств случайной ошибки:
- Постоянная (одинаковая) дисперсия случайных ошибок во всех наблюдениях (отсутствие гетероскедастичности (b) ): .
- Отсутствие корреляции (автокорреляции (b) ) случайных ошибок в разных наблюдениях между собой .
Данные предположения можно сформулировать для ковариационной матрицы (b) вектора случайных ошибок .
Линейная модель, удовлетворяющая таким условиям, называется классической. МНК-оценки для классической линейной регрессии являются несмещёнными (b) , состоятельными (b) и наиболее эффективными (b) оценками в классе всех линейных несмещённых оценок (в англоязычной литературе иногда употребляют аббревиатуру BLUE (Best Linear Unbiased Estimator) — наилучшая линейная несмещённая оценка; в отечественной литературе чаще приводится теорема Гаусса — Маркова (b) ). Как нетрудно показать, ковариационная матрица вектора оценок коэффициентов будет равна:
.
Эффективность (b) означает, что эта ковариационная матрица является «минимальной» (любая линейная комбинация оценок коэффициентов, и в частности сами оценки коэффициентов имеют минимальную дисперсию), то есть в классе линейных несмещённых оценок оценки МНК-наилучшие. Диагональные элементы этой матрицы — дисперсии оценок коэффициентов — важные параметры качества полученных оценок. Однако рассчитать ковариационную матрицу невозможно, поскольку дисперсия случайных ошибок неизвестна. Можно доказать, что несмещённой и состоятельной (для классической линейной модели) оценкой дисперсии случайных ошибок является величина:
.
Подставив данное значение в формулу для ковариационной матрицы, получим оценку ковариационной матрицы. Полученные оценки также являются несмещёнными (b) и состоятельными (b) . Важно также то, что оценка дисперсии ошибок (а значит и дисперсий коэффициентов) и оценки параметров модели являются независимыми случайными величинами, что позволяет получить тестовые статистики для проверки гипотез о коэффициентах модели.
Необходимо отметить, что если классические предположения не выполнены, МНК-оценки параметров не являются наиболее эффективными (b) оценками (оставаясь несмещёнными (b) и состоятельными (b) ). Однако ещё более ухудшается оценка ковариационной матрицы: она становится смещённой (b) и несостоятельной (b) . Это означает, что статистические выводы о качестве построенной модели в таком случае могут быть крайне недостоверными. Одним из вариантов решения этой проблемы является применение специальных оценок ковариационной матрицы, которые являются состоятельными при нарушениях классических предположений (стандартные ошибки в форме Уайта (b) и стандартные ошибки в форме Ньюи-Уеста (b) ). Другой подход заключается в применении так называемого обобщённого МНК (b) .
Обобщённый МНК
Метод наименьших квадратов допускает широкое обобщение. Вместо минимизации суммы квадратов остатков можно минимизировать некоторую положительно определённую квадратичную форму (b) от вектора остатков , где — некоторая симметрическая положительно определённая весовая матрица. Обычный МНК является частным случаем данного подхода, когда весовая матрица пропорциональна единичной матрице. Как известно, для симметрических матриц (или операторов) существует разложение . Следовательно, указанный функционал можно представить следующим образом: , то есть этот функционал можно представить как сумму квадратов некоторых преобразованных «остатков». Таким образом, можно выделить класс методов наименьших квадратов — LS-методы (Least Squares).
Доказано (теорема Айткена), что для обобщённой линейной регрессионной модели (в которой на ковариационную матрицу случайных ошибок не налагается никаких ограничений) наиболее эффективными (в классе линейных несмещённых оценок) являются оценки т. н. обобщённого МНК (ОМНК, GLS — Generalized Least Squares) — LS-метода с весовой матрицей, равной обратной ковариационной матрице случайных ошибок: .
Можно показать, что формула ОМНК-оценок параметров линейной модели имеет вид
.
Ковариационная матрица этих оценок соответственно будет равна
.
Фактически сущность ОМНК заключается в определённом (линейном) преобразовании (P) исходных данных и применении обычного МНК к преобразованным данным. Цель этого преобразования — для преобразованных данных случайные ошибки уже удовлетворяют классическим предположениям.
Взвешенный МНК
В случае диагональной весовой матрицы (а значит и ковариационной матрицы случайных ошибок) имеем так называемый взвешенный МНК. В данном случае минимизируется взвешенная сумма квадратов остатков модели, то есть каждое наблюдение получает «вес», обратно пропорциональный дисперсии случайной ошибки в данном наблюдении: . Фактически данные преобразуются взвешиванием наблюдений (делением на величину, пропорциональную предполагаемому стандартному отклонению случайных ошибок), а к взвешенным данным применяется обычный МНК.
См. также
- Обобщенный метод наименьших квадратов (b)
- Двухшаговый метод наименьших квадратов (b)
- Рекурсивный МНК (b)
- Алгоритм Гаусса — Ньютона (b)
Примечания
- ↑ Legendre, On Least Squares. Translated from the French by Professor Henry A. Ruger and Professor Helen M. Walker, Teachers College, Columbia University, New York City.Архивная копия от 7 января 2011 на Wayback Machine (b) (англ.)
- ↑ Александрова, 2008, с. 102.
- ↑ Линник, 1962, с. 21.
- ↑ Магнус, Катышев, Пересецкий, 2007, Обозначение RSS не унифицировано. RSS может быть сокращением от regression sum of squares, а ESS — error sum of squares, то есть, RSS и ESS будут иметь обратный смысл. с. 52. Издания 2004 года..
Литература
- Линник Ю. В (b) . Метод наименьших квадратов и основы математико-статистической теории обработки наблюдений. — 2-е изд. — М., 1962. (математическая теория)
- Айвазян С. А. (b) Прикладная статистика. Основы эконометрики. Том 2. — М.: Юнити-Дана, 2001. — 432 с. — ISBN 5-238-00305-6.
- Доугерти К. Введение в эконометрику: Пер. с англ. — М.: ИНФРА-М, 1999. — 402 с. — ISBN 8-86225-458-7.
- Кремер Н. Ш., Путко Б. А. Эконометрика. — М.: Юнити-Дана, 2003—2004. — 311 с. — ISBN 8-86225-458-7.
- Магнус Я. Р., Катышев П. К., Пересецкий А. А. Эконометрика. Начальный курс. — М.: Дело, 2007. — 504 с. — ISBN 978-5-7749-0473-0.
- Эконометрика. Учебник / Под ред. Елисеевой И. И. — 2-е изд. — М.: Финансы и статистика, 2006. — 576 с. — ISBN 5-279-02786-3.
- Александрова Н. В. История математических терминов, понятий, обозначений: словарь-справочник. — 3-е изд.. — М.: ЛКИ, 2008. — 248 с. — ISBN 978-5-382-00839-4.
- Витковский В. В. (b) Наименьшие квадраты // Энциклопедический словарь Брокгауза и Ефрона (b) : в 86 т. (82 т. и 4 доп.). — СПб., 1890—1907.
- Митин И. В., Русаков В. С. Анализ и обработка экспериментальных данных. — 5-е издание. — 24 с.
Ссылки
- Метод наименьших квадратов онлайн для зависимости y = a + bx с вычислением погрешностей коэффициентов и оцениванием автокорреляции.