@Wyn Hopkins you may well be sorry you asked, but here goes.
BTW, my present solution on my full data set (10 — 15 CSV files with ~100,000 rows x 100 columns) is now working really well. Dividing the munge functions between G&T and the DM is giving me what I need*, and it is working faster and more smoothly than before. So I don’t have an immediate issue, just a nagging sense of something not being quite right.
(* apart from not being able to filter by table as I explained previously, but I can live with that).
Note — this is a ‘toy’ example using smaller data-sets that I had built just to try out filtering techniques in PQ. But essentially identical to what I was doing on the full data-set.
There are 2 key Queries A : Load from folder of CSV files, do some basic filtering and manipulation, resulting in a table. Query B takes that table and does some more complicated operation, the key is using a table (loaded from cells in the workbook) to test a column in the table for presence of text strings.
IN checking this for reproducibility, I found that with a very small data set (2 files each of 10 rows), everything worked fine and I could load to the DM no problem. When I increased the size 10 files, each 10,000 rows then :
Query A worked and either loaded to DM or made connection, no problem.
Query B worked on load to Table (or connection only), but ticking the ‘Load to DM’ meant the query never refreshed. I say ‘never’ — I leave it for up to 15/20 minutes and find it is still saying ‘retrieving data’ and never gets on to incrementing rows.
Query A :
let
Source = Folder.Files(«H:My DocumentsSupplyAndDemandONDBToyDataCSVExtractFruit»),
#»Filtered Hidden Files1″ = Table.SelectRows(Source, each [Attributes]?[Hidden]? <> true),
#»Invoke Custom Function1″ = Table.AddColumn(#»Filtered Hidden Files1″, «Transform File from CSVExtractFruit», each #»Transform File from CSVExtractFruit»([Content])),
#»Renamed Columns1″ = Table.RenameColumns(#»Invoke Custom Function1″, {«Name», «Source.Name»}),
#»Removed Other Columns1″ = Table.SelectColumns(#»Renamed Columns1″, {«Source.Name», «Transform File from CSVExtractFruit»}),
#»Expanded Table Column1″ = Table.ExpandTableColumn(#»Removed Other Columns1″, «Transform File from CSVExtractFruit», Table.ColumnNames(#»Transform File from CSVExtractFruit»(#»Sample File»))),
#»Changed Type» = Table.TransformColumnTypes(#»Expanded Table Column1″,{{«Source.Name», type text}, {«Column1», type text}, {«Column2», type text}, {«Column3», type text}, {«Column4», type text}, {«Column5», type text}, {«Column6», type text}, {«Column7», type text}, {«Column8», type text}, {«Column9», type text}, {«Column10», type text}}),
#»Promoted Headers» = Table.PromoteHeaders(#»Changed Type», [PromoteAllScalars=true]),
#»Changed Type1″ = Table.TransformColumnTypes(#»Promoted Headers»,{{«Fruit2018Week49.csv», type text}, {«Week», type text}, {«Market», type text}, {«City», type text}, {«XS_Col1», type text}, {«XS_Col2», type text}, {«What_Ships», type text}, {«Fruit_Desc», type text}, {«Shipment_size», type number}, {«Shipment_Value», Int64.Type}, {«XS_Col3», type text}}),
#»Removed Columns» = Table.RemoveColumns(#»Changed Type1″,{«XS_Col1», «XS_Col2», «XS_Col3»}),
#»Merged Queries» = Table.NestedJoin(#»Removed Columns»,{«Market»},Country_to_include,{«CC_to_include»},»Country_to_include»,JoinKind.Inner),
#»Removed Columns1″ = Table.RemoveColumns(#»Merged Queries»,{«Country_to_include»}),
#»Merged Queries1″ = Table.NestedJoin(#»Removed Columns1″,{«Week»},Weeks_to_include,{«Week»},»Weeks_to_include»,JoinKind.Inner),
#»Removed Columns2″ = Table.RemoveColumns(#»Merged Queries1″,{«Weeks_to_include»})
in
#»Removed Columns2″
Query B : (doesn’t load to DM)
let
Source = CSVExtractFruit,
#»Added Custom» = Table.AddColumn(#»Source»,»US Fruit», each if [Market] = «US» then List.Intersect({Text.Split([Fruit_Desc],» «),{US_Fruit[US_Fruit]}{0}}){0}? else null),
#»Added Custom1″ = Table.AddColumn(#»Added Custom», «FruitKeyWord», each if Text.Contains([Fruit_Desc], «FRUIT:») then Text.BetweenDelimiters([Fruit_Desc],»FRUIT:»,» «) else null),
#»Merged Columns» = Table.CombineColumns(#»Added Custom1″,{«FruitKeyWord», «US Fruit»},Combiner.CombineTextByDelimiter(«», QuoteStyle.None),»AllFruitFound»),
#»Filtered Rows» = Table.SelectRows(#»Merged Columns», each ([AllFruitFound] <> «»)),
#»Merged Queries» = Table.NestedJoin(#»Filtered Rows»,{«AllFruitFound»},Top_Fruit,{«Top_Fruit»},»Top_Fruit»,JoinKind.LeftOuter),
#»Expanded Top_Fruit» = Table.ExpandTableColumn(#»Merged Queries», «Top_Fruit», {«Top_Fruit»}, {«Top_Fruit.Top_Fruit»}),
#»Renamed Columns» = Table.RenameColumns(#»Expanded Top_Fruit»,{{«Top_Fruit.Top_Fruit», «TopFruitFound»}})
in
#»Renamed Columns»
Example data-file — first few rows of 10,000
| Week | Market | City | XS_Col1 | XS_Col2 | What_Ships | Fruit_Desc | Shipment_size | Shipment_Value |
| 2019-Week07 | CA | Toronto | All_Fruit | An assortment of FRUIT:Honeydew Couried to dest | 10 | 1 | ||
| 2019-Week07 | CA | Ottawa | Vegetable | Shipment of VEG:konjac sent by overland shipping | 10 | 1 | ||
| 2019-Week07 | US | Chicago | All_Fruit | Shipment of FRUIT:Redcurrant sent by overland shipping | 10 | 3 | ||
| 2019-Week07 | CA | Ottawa | Vegetable | Shipment of VEG:butternut squash Couried to dest | 100 | 84 |
@Wyn Hopkins you may well be sorry you asked, but here goes.
BTW, my present solution on my full data set (10 — 15 CSV files with ~100,000 rows x 100 columns) is now working really well. Dividing the munge functions between G&T and the DM is giving me what I need*, and it is working faster and more smoothly than before. So I don’t have an immediate issue, just a nagging sense of something not being quite right.
(* apart from not being able to filter by table as I explained previously, but I can live with that).
Note — this is a ‘toy’ example using smaller data-sets that I had built just to try out filtering techniques in PQ. But essentially identical to what I was doing on the full data-set.
There are 2 key Queries A : Load from folder of CSV files, do some basic filtering and manipulation, resulting in a table. Query B takes that table and does some more complicated operation, the key is using a table (loaded from cells in the workbook) to test a column in the table for presence of text strings.
IN checking this for reproducibility, I found that with a very small data set (2 files each of 10 rows), everything worked fine and I could load to the DM no problem. When I increased the size 10 files, each 10,000 rows then :
Query A worked and either loaded to DM or made connection, no problem.
Query B worked on load to Table (or connection only), but ticking the ‘Load to DM’ meant the query never refreshed. I say ‘never’ — I leave it for up to 15/20 minutes and find it is still saying ‘retrieving data’ and never gets on to incrementing rows.
Query A :
let
Source = Folder.Files(«H:My DocumentsSupplyAndDemandONDBToyDataCSVExtractFruit»),
#»Filtered Hidden Files1″ = Table.SelectRows(Source, each [Attributes]?[Hidden]? <> true),
#»Invoke Custom Function1″ = Table.AddColumn(#»Filtered Hidden Files1″, «Transform File from CSVExtractFruit», each #»Transform File from CSVExtractFruit»([Content])),
#»Renamed Columns1″ = Table.RenameColumns(#»Invoke Custom Function1″, {«Name», «Source.Name»}),
#»Removed Other Columns1″ = Table.SelectColumns(#»Renamed Columns1″, {«Source.Name», «Transform File from CSVExtractFruit»}),
#»Expanded Table Column1″ = Table.ExpandTableColumn(#»Removed Other Columns1″, «Transform File from CSVExtractFruit», Table.ColumnNames(#»Transform File from CSVExtractFruit»(#»Sample File»))),
#»Changed Type» = Table.TransformColumnTypes(#»Expanded Table Column1″,{{«Source.Name», type text}, {«Column1», type text}, {«Column2», type text}, {«Column3», type text}, {«Column4», type text}, {«Column5», type text}, {«Column6», type text}, {«Column7», type text}, {«Column8», type text}, {«Column9», type text}, {«Column10», type text}}),
#»Promoted Headers» = Table.PromoteHeaders(#»Changed Type», [PromoteAllScalars=true]),
#»Changed Type1″ = Table.TransformColumnTypes(#»Promoted Headers»,{{«Fruit2018Week49.csv», type text}, {«Week», type text}, {«Market», type text}, {«City», type text}, {«XS_Col1», type text}, {«XS_Col2», type text}, {«What_Ships», type text}, {«Fruit_Desc», type text}, {«Shipment_size», type number}, {«Shipment_Value», Int64.Type}, {«XS_Col3», type text}}),
#»Removed Columns» = Table.RemoveColumns(#»Changed Type1″,{«XS_Col1», «XS_Col2», «XS_Col3»}),
#»Merged Queries» = Table.NestedJoin(#»Removed Columns»,{«Market»},Country_to_include,{«CC_to_include»},»Country_to_include»,JoinKind.Inner),
#»Removed Columns1″ = Table.RemoveColumns(#»Merged Queries»,{«Country_to_include»}),
#»Merged Queries1″ = Table.NestedJoin(#»Removed Columns1″,{«Week»},Weeks_to_include,{«Week»},»Weeks_to_include»,JoinKind.Inner),
#»Removed Columns2″ = Table.RemoveColumns(#»Merged Queries1″,{«Weeks_to_include»})
in
#»Removed Columns2″
Query B : (doesn’t load to DM)
let
Source = CSVExtractFruit,
#»Added Custom» = Table.AddColumn(#»Source»,»US Fruit», each if [Market] = «US» then List.Intersect({Text.Split([Fruit_Desc],» «),{US_Fruit[US_Fruit]}{0}}){0}? else null),
#»Added Custom1″ = Table.AddColumn(#»Added Custom», «FruitKeyWord», each if Text.Contains([Fruit_Desc], «FRUIT:») then Text.BetweenDelimiters([Fruit_Desc],»FRUIT:»,» «) else null),
#»Merged Columns» = Table.CombineColumns(#»Added Custom1″,{«FruitKeyWord», «US Fruit»},Combiner.CombineTextByDelimiter(«», QuoteStyle.None),»AllFruitFound»),
#»Filtered Rows» = Table.SelectRows(#»Merged Columns», each ([AllFruitFound] <> «»)),
#»Merged Queries» = Table.NestedJoin(#»Filtered Rows»,{«AllFruitFound»},Top_Fruit,{«Top_Fruit»},»Top_Fruit»,JoinKind.LeftOuter),
#»Expanded Top_Fruit» = Table.ExpandTableColumn(#»Merged Queries», «Top_Fruit», {«Top_Fruit»}, {«Top_Fruit.Top_Fruit»}),
#»Renamed Columns» = Table.RenameColumns(#»Expanded Top_Fruit»,{{«Top_Fruit.Top_Fruit», «TopFruitFound»}})
in
#»Renamed Columns»
Example data-file — first few rows of 10,000
| Week | Market | City | XS_Col1 | XS_Col2 | What_Ships | Fruit_Desc | Shipment_size | Shipment_Value |
| 2019-Week07 | CA | Toronto | All_Fruit | An assortment of FRUIT:Honeydew Couried to dest | 10 | 1 | ||
| 2019-Week07 | CA | Ottawa | Vegetable | Shipment of VEG:konjac sent by overland shipping | 10 | 1 | ||
| 2019-Week07 | US | Chicago | All_Fruit | Shipment of FRUIT:Redcurrant sent by overland shipping | 10 | 3 | ||
| 2019-Week07 | CA | Ottawa | Vegetable | Shipment of VEG:butternut squash Couried to dest | 100 | 84 |
Tags:
Power BI, Power Query
Чтобы создать надежную систему BI, вам необходимо тщательно учитывать и обрабатывать ошибки. Если вы создаете решение для отчетов, обновление которого не выполняется при каждом возникновении ошибки, это не надежная система. Ошибки могут произойти по многим причинам. В этом сообщении мы покажем вам способ поймать возможные ошибки в Power Query и как создать страницу отчета об исключении, чтобы визуализировать строки ошибок для дальнейшего изучения. Метод, о котором вы здесь узнаете, сохранит вашу модель от сбоя во время обновления. Эо означает, что вы обновили набор данных, и вы можете поймать любые строки, вызвавшие ошибку на странице отчета об исключении.
Пример набора данных
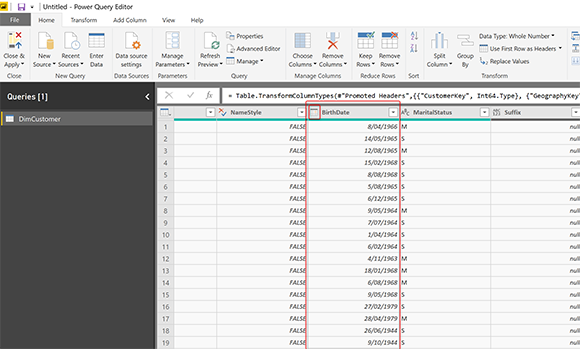
Мы будем использовать пример файла Excel в качестве источника данных, который содержит 18 484 строки клиентов. В образце Dataset у нас есть поле BirthDate рядом со всеми другими полями, которые должны иметь в нем значение даты. Вот как выглядят данные, когда мы вводим их в Power Query:
Происходит ошибка
Когда мы получаем этот набор данных в окне редактора Power Query Editor (как показано на приведенном выше снимке экрана), Power Query автоматически преобразует тип данных столбца BirthDate в Date. Вы можете увидеть это автоматическое преобразование типа данных в списке шагов;
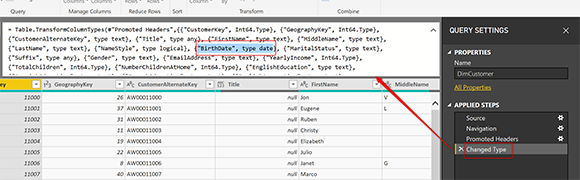
Конечно, вы можете отключить автоматическое определение типа данных Power Query, но наша точка зрения отличается. Мы хотим, чтобы набор данных не показывал вам, как с этим бороться. Ошибки происходят в Power Query в реальном мире, и мы хотим показать вам, как их найти.
Как вы можете видеть в редакторе Power Query Editor, мы не видим ошибок для этого типа данных, и все выглядит великолепно;
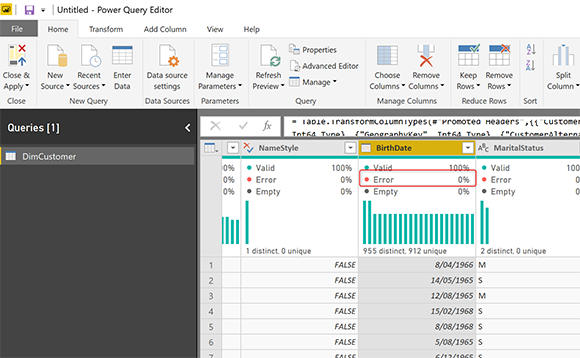
Теперь мы загружаем этот набор данных в Power BI, используя Close и Apply в окне редактора запросов, и мы ждем, что все загрузится успешно, однако это выходит из-под контроля!
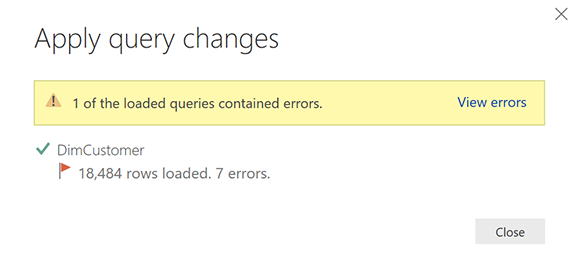
Звучит знакомо? Да, если вы некоторое время работали с Power BI, возможно, вы это испытали. В редакторе Power Query Editor нет ошибок, но когда мы загружаем данные в Power BI, они появляются ! Как это возможно? Давайте сначала узнаем, почему это происходит.
Почему Power Query Editor не поймал ошибку?
Редактор Power Query Editor всегда работает с предварительным просмотром набора данных, размер предварительного просмотра зависит от того, сколько столбцов у вас есть, иногда это 1000 строк, а иногда и 200 строк. Если вы нажмете на Query в окне редактора Power Query, вы можете увидеть это, как показано ниже в строке состояния;
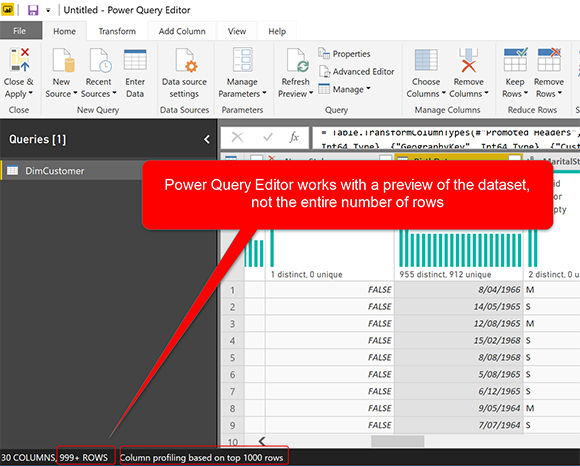
Причина использования Power Query для использования набора данных предварительного просмотра заключается, главным образом, в ускорении процесса разработки трансформации. Представьте, что если у вас есть таблица с 10 миллионами строк, каждое преобразование, которое вы хотите применить к этому набору данных, займет много времени, и вам придется подождать, прежде чем вы начнете делать следующий шаг. Ожидание ответа каждый раз замедляет процесс разработки. Именно по этой причине предпочтительным вариантом является работа над предварительным просмотром в наборе данных. Вы можете применить все преобразования, которые вы хотите в предварительном просмотре, и когда вы им довольны, затем примените его ко всему набору данных. Как правило, первые 1000 строк или первые 200 строк являются хорошим образцом всего набора данных, и вы можете ожидать увидеть большинство проблем с данными. Не всегда, конечно.
Как тогда преобразование будет применено ко всему набору данных? Когда вы загружаете данные в Power BI, а именно — когда вы нажимаете «Close» и «APPLY» в окне Power Query Editor. Этот APPLY означает применить эти преобразования теперь во всем наборе данных. Именно по этой причине процесс загрузки может занять больше времени, особенно если набор данных большой.
Power Query Editor всегда работает с предварительным просмотром данных, чтобы ускорить процесс разработки. Когда вы загружаете данные в Power BI, преобразования будут применяться ко всему набору данных.
Теперь, когда вы знаете, как Power Query Editor имеет дело с предварительным просмотром данных, вы можете догадаться, почему произошла ошибка выше? Причина в том, что предварительный просмотр данных (около 1000 строк) не имел проблем с применяемыми преобразованиями (в этом случае автоматический тип данных изменяется на Date для столбца BirthDate). Однако весь набор данных (около 18 тыс. строк) имеет проблемы с этим преобразованием! Когда вы увидите вышеприведенную ошибку в Power BI Desktop, вы можете нажать View errors и перейти в Power Query editor, посмотреть их, разобраться с ними и исправить. Однако этого недостаточно.
Что делать, если ошибка не возникает в Power BI Desktop, но происходит в запланированном обновлении в службе Power BI?
Это хороший вопрос! Исправить ошибки в Power BI Desktop легко, но учтите, что ошибка также не произошла в Desktop, и вы опубликовали отчет Power BI на веб-сайт и запланировали его обновление. Затем на следующий день вы увидите, что отчет не обновился с ошибкой! Вы должны научиться правильно обращаться к строкам ошибок до того, как это приведет к сбою запланированного обновления. Давайте посмотрим, как с этим справиться.
Работа с ошибками: поиск строк ошибок
Чтобы справиться с ошибками, вы должны поймать ошибку до того, как она загрузится в Power BI. Один из способов сделать это — создать две ссылки одной и той же таблицы, одну в качестве окончательного запроса, а другую — как строки ошибок.
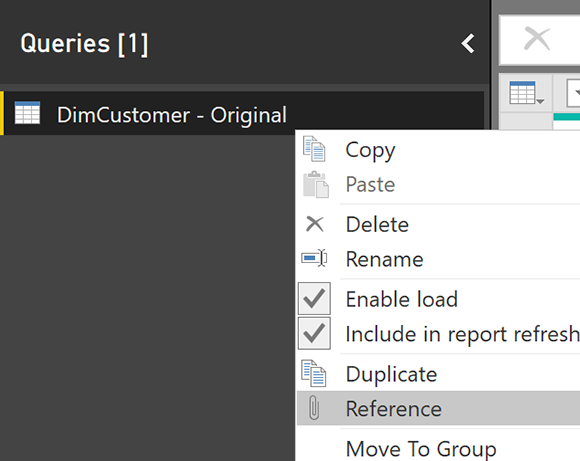
На скриншоте выше, мы переименовали таблицу DimCustomer в DimCustomer — Original, а затем создали ссылку из нее. Если вы хотите узнать, что такое Reference, прочитайте статью о Reference и Duplicate здесь. Новый запрошенный запрос можно назвать DimCustomer. Это будет чистый запрос без ошибок (мы удалим ошибки из него на следующем шаге);
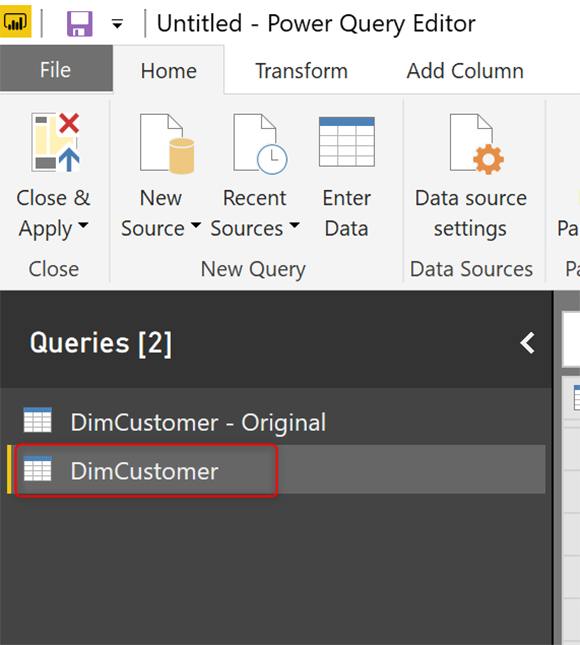
Новая таблица — это таблица, которая будет чистой, без ошибок, и мы можем использовать ее в отчете. Давайте очистим это от любых ошибок
Удаление ошибок из загрузки таблицы в Power BI
Поскольку DimCustomer станет для нас окончательным запросом, я хочу удалить из него ошибки. Удаление ошибок — это простой вариант на вкладке «Главная» в разделе Reduce Rows -> Remove Rows -> Remove Errors.. Перед этим выберите столбец BirthDate.
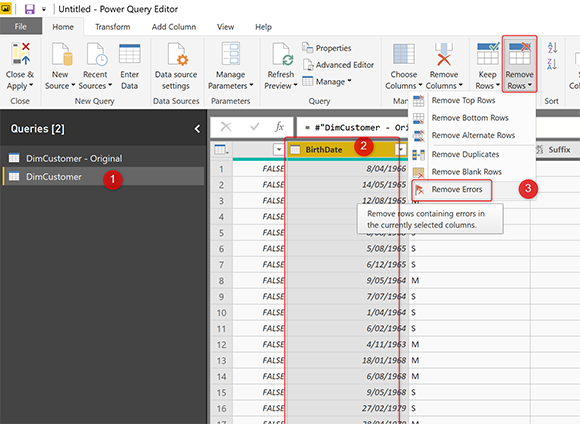
Вы также можете сделать это для всех столбцов, если хотите; выбрав все столбцы, а затем выбрав «Remove Errors». Это сообщение — всего лишь образец одного столбца и может быть продлен до конца.
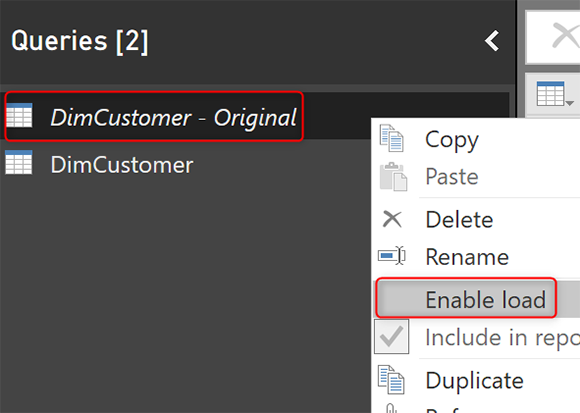
Remove Errors — это шаг на этапе преобразования данных, а это означает, что при нажатии APPLY он будет применяться ко всему набору данных, поэтому в результате, когда изменение типа данных приведет к ошибке, следующий шаг после этого — Remove Errors, уничтожит строки, вызвавшие ошибку. Но DimCustomer — Original все еще может вызвать ошибку, поэтому мы должны снять галочку Enable Load с этого запроса.
Теперь мы успешно удалили ошибки и загрузили данные в Power BI. Ошибок не будет.
Но подождите! Как насчет этих строк ошибок? Как мы можем их поймать? Нам нужно поймать эти строки и выяснить, что произошло, и подумать о плане действий, чтобы исправить их, не так ли? Таким образом, нам нужна другая ссылка запроса из исходного запроса, но для сохранения строк ошибок.
Храните ошибки в таблице исключений
Аналогично опции «Remove Errors» есть опция «Keep Errors». Если вы уже видели этот вариант, возможно, вам интересно, как его использовать? Вот точный сценарий использования. Keep Errors поможет уловить строки ошибок в таблице исключений.
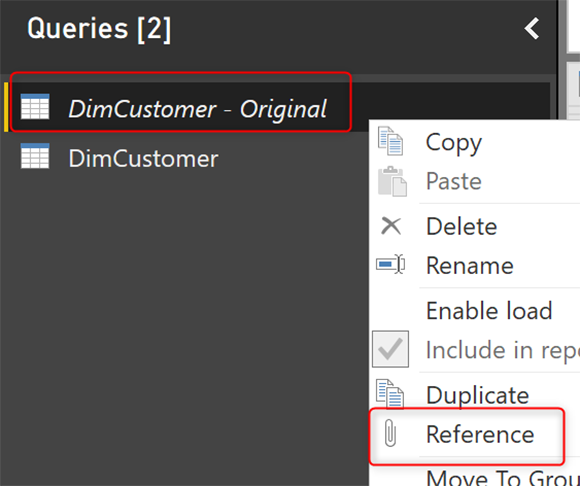
Создайте еще одну ссылку из DimCustomer — Original.
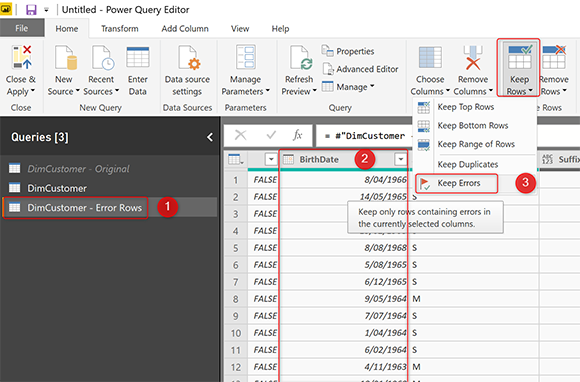
Переименуйте этот новый запрос как строки ошибок DimCustomer. Для этого запроса нам нужно сохранить ошибки, которые можно найти рядом с ошибками удаления, но в разделе Keep Rows.
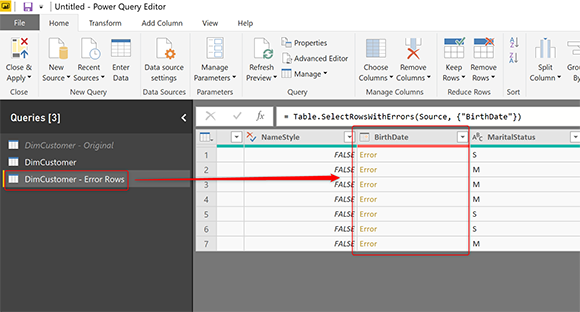
Теперь эта таблица будет содержать строки, которые вызывают ошибку. Вот пример набора;
Это еще не конец истории. Если вы загрузите эту новую таблицу DimCustomer — строки ошибок в Power BI, вы снова получите ту же ошибку. Зачем? ну, потому что этот запрос, безусловно, собирается возвращать строки ошибок! Вам необходимо удалить ошибку из этого набора данных.
Получение информации об ошибке
Если вы удалите столбец ошибок из таблицы исключений, которые мы создали, то у вас не будет никаких подробностей о произошедшей ошибке, и было бы трудно отследить ее и устранить неполадки. Лучше всего поймать детали ошибки. Сообщение об ошибке и значение, вызвавшее ошибку, являются важными деталями, которые вы не хотите пропустить. Выполните следующие шаги, чтобы получить эту информацию.
В таблице Error Rows добавьте Custom Column.
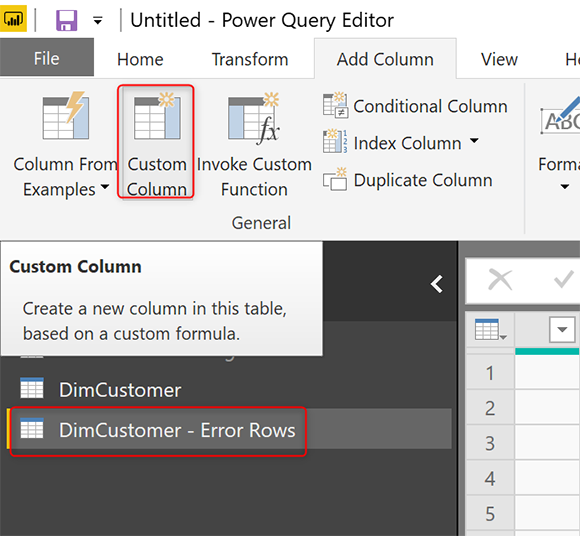
В редакторе Custom Column напишите «try», а затем пробел, имя поля, вызвавшего ошибку. В нашем примере: BirthDate;
try [BirthDate]
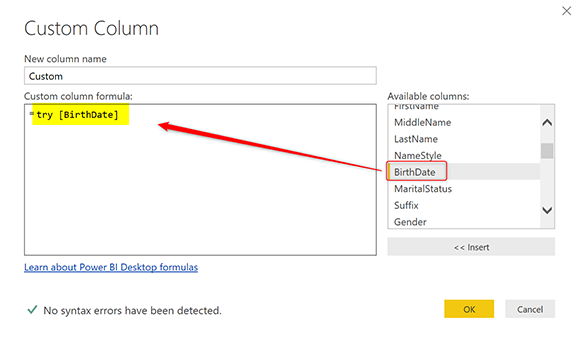
try (все строчные буквы), это ключевое слово в M, которое будет ловить данные об ошибке. Вместо того, чтобы возвращать только ошибку, она вернет запись, содержащую данные об ошибках, такие как исходное значение и сообщение об ошибке. Ниже, снимок экрана показывает, как будет выводиться результат попытки;
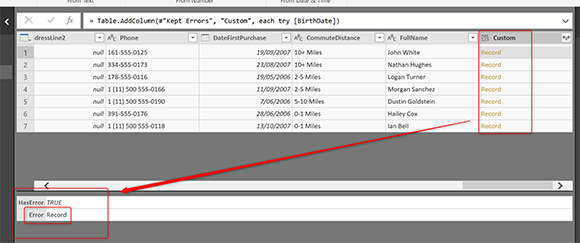
Выход записи «try» будет иметь два поля; HasError (мы уже знаем, что это будет правда) и Error. Ошибка — это еще одна запись с более подробной информацией. Нажмите «Expand » в столбце «Custom column» и выберите «Error».
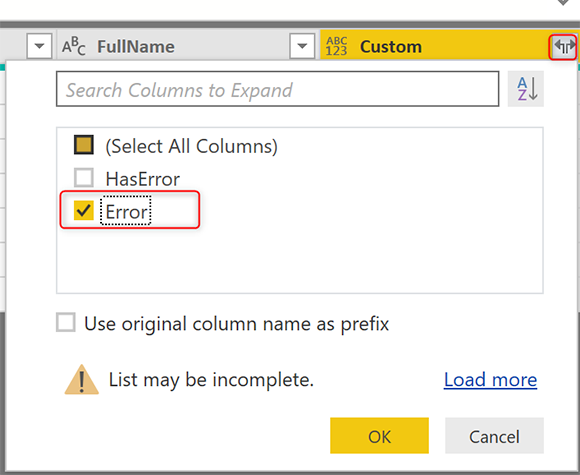
В столбце вывода с именем «Error» снова нажмите на «Expand» и на этот раз выберите все столбцы;
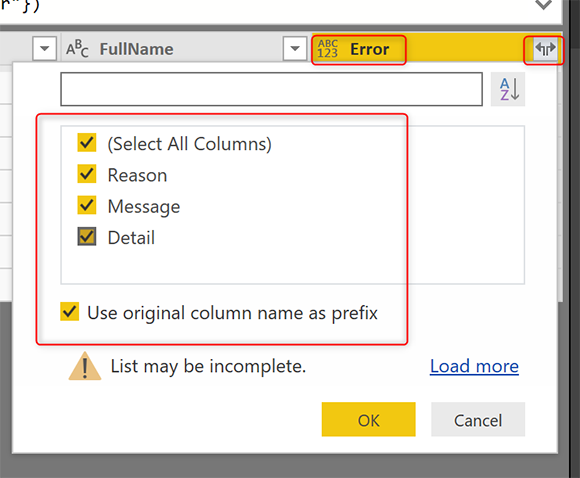
Хорошо иметь исходное имя столбца в качестве префикса, потому что тогда вы бы знали, что это столбцы с подробными сведениями об ошибках.
Теперь вы получите полную информацию об ошибке, как показано ниже;
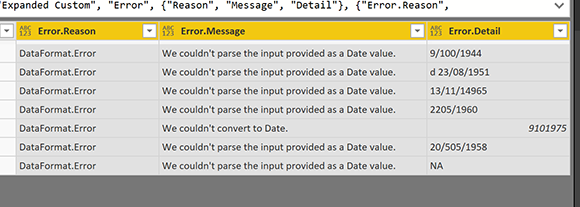
Вышеупомянутая информация является вашим самым ценным активом для отчетности об исключениях.
Удалите столбец ошибок
Теперь последний шаг перед загрузкой данных в Power BI — удалить столбец, который вызывает ошибку. В нашем примере; Столбец BirthDate должен быть удален (в противном случае обновление снова завершится неудачей);
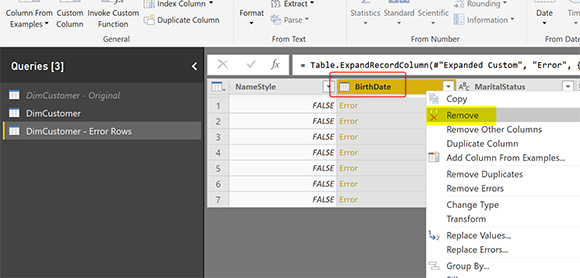
Отчет об исключении
Теперь вы можете загрузить данные в Power BI. У вас будет две таблицы; DimCustomer и DimCustomer – Error Rows. DimCustomer — это таблица, которую вы можете использовать для обычной отчетности. DimCustomer – Error Rows — это таблица, которую вы можете использовать для отчетов об исключениях. Отчет об исключении — это отчет, который можно использовать для устранения неполадок, и перечисляет все ошибки для дальнейшего расследования. Убедитесь, что между этими двумя таблицами нет никакой связи.
Вот созданный нами образец визуального отчета, который показывает ошибки:

Подведем итоги
Ошибки случаются, и вам приходится иметь дело с ними. Вместо того, чтобы ждать ошибки, а затем находить их лишь через месяц после появления, лучше выявлять их, как только они произойдут. В этой статье вы узнали способ обработки строк ошибок.
Почему в вашей итоговой таблицы не все данные, которые должны там оказаться? Вероятно вы совершили ошибку неверной фильтрации в пользовательском интерфейсе.
Text.SplitAny
List.Select
Character.FromNumber
Text.Combine
Содержание
- SPBDEV Blog
- Пример набора данных
- Происходит ошибка
- Почему Power Query Editor не поймал ошибку?
- Работа с ошибками: поиск строк ошибок
- Удаление ошибок из загрузки таблицы в Power BI
- Храните ошибки в таблице исключений
- Получение информации об ошибке
- Удалите столбец ошибок
- Отчет об исключении
- Подведем итоги
- Работа с ошибками в Power Query
- Ошибка на уровне шага
- Распространенные ошибки на уровне шага
- Не удается найти источник — DataSource.Error
- Столбец таблицы не найден
- Другие распространенные ошибки на уровне шага
- Ошибка уровня ячейки
- Обработка ошибок на уровне ячейки
- Удаление ошибок
- Замена ошибок
- Сохранение ошибок
- Распространенные ошибки на уровне ячеек
- Ошибки преобразования типов данных
- Ошибки операций
SPBDEV Blog
Чтобы создать надежную систему BI, вам необходимо тщательно учитывать и обрабатывать ошибки. Если вы создаете решение для отчетов, обновление которого не выполняется при каждом возникновении ошибки, это не надежная система. Ошибки могут произойти по многим причинам. В этом сообщении мы покажем вам способ поймать возможные ошибки в Power Query и как создать страницу отчета об исключении, чтобы визуализировать строки ошибок для дальнейшего изучения. Метод, о котором вы здесь узнаете, сохранит вашу модель от сбоя во время обновления. Эо означает, что вы обновили набор данных, и вы можете поймать любые строки, вызвавшие ошибку на странице отчета об исключении.
Пример набора данных
Мы будем использовать пример файла Excel в качестве источника данных, который содержит 18 484 строки клиентов. В образце Dataset у нас есть поле BirthDate рядом со всеми другими полями, которые должны иметь в нем значение даты. Вот как выглядят данные, когда мы вводим их в Power Query:
Происходит ошибка
Когда мы получаем этот набор данных в окне редактора Power Query Editor (как показано на приведенном выше снимке экрана), Power Query автоматически преобразует тип данных столбца BirthDate в Date. Вы можете увидеть это автоматическое преобразование типа данных в списке шагов;
Конечно, вы можете отключить автоматическое определение типа данных Power Query, но наша точка зрения отличается. Мы хотим, чтобы набор данных не показывал вам, как с этим бороться. Ошибки происходят в Power Query в реальном мире, и мы хотим показать вам, как их найти.
Как вы можете видеть в редакторе Power Query Editor, мы не видим ошибок для этого типа данных, и все выглядит великолепно;
Теперь мы загружаем этот набор данных в Power BI, используя Close и Apply в окне редактора запросов, и мы ждем, что все загрузится успешно, однако это выходит из-под контроля!
Звучит знакомо? Да, если вы некоторое время работали с Power BI, возможно, вы это испытали. В редакторе Power Query Editor нет ошибок, но когда мы загружаем данные в Power BI, они появляются ! Как это возможно? Давайте сначала узнаем, почему это происходит.
Почему Power Query Editor не поймал ошибку?
Редактор Power Query Editor всегда работает с предварительным просмотром набора данных, размер предварительного просмотра зависит от того, сколько столбцов у вас есть, иногда это 1000 строк, а иногда и 200 строк. Если вы нажмете на Query в окне редактора Power Query, вы можете увидеть это, как показано ниже в строке состояния;
Причина использования Power Query для использования набора данных предварительного просмотра заключается, главным образом, в ускорении процесса разработки трансформации. Представьте, что если у вас есть таблица с 10 миллионами строк, каждое преобразование, которое вы хотите применить к этому набору данных, займет много времени, и вам придется подождать, прежде чем вы начнете делать следующий шаг. Ожидание ответа каждый раз замедляет процесс разработки. Именно по этой причине предпочтительным вариантом является работа над предварительным просмотром в наборе данных. Вы можете применить все преобразования, которые вы хотите в предварительном просмотре, и когда вы им довольны, затем примените его ко всему набору данных. Как правило, первые 1000 строк или первые 200 строк являются хорошим образцом всего набора данных, и вы можете ожидать увидеть большинство проблем с данными. Не всегда, конечно.
Как тогда преобразование будет применено ко всему набору данных? Когда вы загружаете данные в Power BI, а именно — когда вы нажимаете «Close» и «APPLY» в окне Power Query Editor. Этот APPLY означает применить эти преобразования теперь во всем наборе данных. Именно по этой причине процесс загрузки может занять больше времени, особенно если набор данных большой.
Power Query Editor всегда работает с предварительным просмотром данных, чтобы ускорить процесс разработки. Когда вы загружаете данные в Power BI, преобразования будут применяться ко всему набору данных.
Теперь, когда вы знаете, как Power Query Editor имеет дело с предварительным просмотром данных, вы можете догадаться, почему произошла ошибка выше? Причина в том, что предварительный просмотр данных (около 1000 строк) не имел проблем с применяемыми преобразованиями (в этом случае автоматический тип данных изменяется на Date для столбца BirthDate). Однако весь набор данных (около 18 тыс. строк) имеет проблемы с этим преобразованием! Когда вы увидите вышеприведенную ошибку в Power BI Desktop, вы можете нажать View errors и перейти в Power Query editor, посмотреть их, разобраться с ними и исправить. Однако этого недостаточно.
Что делать, если ошибка не возникает в Power BI Desktop, но происходит в запланированном обновлении в службе Power BI?
Это хороший вопрос! Исправить ошибки в Power BI Desktop легко, но учтите, что ошибка также не произошла в Desktop, и вы опубликовали отчет Power BI на веб-сайт и запланировали его обновление. Затем на следующий день вы увидите, что отчет не обновился с ошибкой! Вы должны научиться правильно обращаться к строкам ошибок до того, как это приведет к сбою запланированного обновления. Давайте посмотрим, как с этим справиться.
Работа с ошибками: поиск строк ошибок
Чтобы справиться с ошибками, вы должны поймать ошибку до того, как она загрузится в Power BI. Один из способов сделать это — создать две ссылки одной и той же таблицы, одну в качестве окончательного запроса, а другую — как строки ошибок.
На скриншоте выше, мы переименовали таблицу DimCustomer в DimCustomer — Original, а затем создали ссылку из нее. Если вы хотите узнать, что такое Reference, прочитайте статью о Reference и Duplicate здесь . Новый запрошенный запрос можно назвать DimCustomer. Это будет чистый запрос без ошибок (мы удалим ошибки из него на следующем шаге);
Новая таблица — это таблица, которая будет чистой, без ошибок, и мы можем использовать ее в отчете. Давайте очистим это от любых ошибок
Удаление ошибок из загрузки таблицы в Power BI
Поскольку DimCustomer станет для нас окончательным запросом, я хочу удалить из него ошибки. Удаление ошибок — это простой вариант на вкладке «Главная» в разделе Reduce Rows -> Remove Rows -> Remove Errors.. Перед этим выберите столбец BirthDate.
Вы также можете сделать это для всех столбцов, если хотите; выбрав все столбцы, а затем выбрав «Remove Errors». Это сообщение — всего лишь образец одного столбца и может быть продлен до конца.
Remove Errors — это шаг на этапе преобразования данных, а это означает, что при нажатии APPLY он будет применяться ко всему набору данных, поэтому в результате, когда изменение типа данных приведет к ошибке, следующий шаг после этого — Remove Errors, уничтожит строки, вызвавшие ошибку. Но DimCustomer — Original все еще может вызвать ошибку, поэтому мы должны снять галочку Enable Load с этого запроса.
Теперь мы успешно удалили ошибки и загрузили данные в Power BI. Ошибок не будет.
Но подождите! Как насчет этих строк ошибок? Как мы можем их поймать? Нам нужно поймать эти строки и выяснить, что произошло, и подумать о плане действий, чтобы исправить их, не так ли? Таким образом, нам нужна другая ссылка запроса из исходного запроса, но для сохранения строк ошибок.
Храните ошибки в таблице исключений
Аналогично опции «Remove Errors» есть опция «Keep Errors». Если вы уже видели этот вариант, возможно, вам интересно, как его использовать? Вот точный сценарий использования. Keep Errors поможет уловить строки ошибок в таблице исключений.
Создайте еще одну ссылку из DimCustomer — Original.
Переименуйте этот новый запрос как строки ошибок DimCustomer. Для этого запроса нам нужно сохранить ошибки, которые можно найти рядом с ошибками удаления, но в разделе Keep Rows.
Теперь эта таблица будет содержать строки, которые вызывают ошибку. Вот пример набора;
Это еще не конец истории. Если вы загрузите эту новую таблицу DimCustomer — строки ошибок в Power BI, вы снова получите ту же ошибку. Зачем? ну, потому что этот запрос, безусловно, собирается возвращать строки ошибок! Вам необходимо удалить ошибку из этого набора данных.
Получение информации об ошибке
Если вы удалите столбец ошибок из таблицы исключений, которые мы создали, то у вас не будет никаких подробностей о произошедшей ошибке, и было бы трудно отследить ее и устранить неполадки. Лучше всего поймать детали ошибки. Сообщение об ошибке и значение, вызвавшее ошибку, являются важными деталями, которые вы не хотите пропустить. Выполните следующие шаги, чтобы получить эту информацию.
В таблице Error Rows добавьте Custom Column.
В редакторе Custom Column напишите «try», а затем пробел, имя поля, вызвавшего ошибку. В нашем примере: BirthDate;
try (все строчные буквы), это ключевое слово в M, которое будет ловить данные об ошибке. Вместо того, чтобы возвращать только ошибку, она вернет запись, содержащую данные об ошибках, такие как исходное значение и сообщение об ошибке. Ниже, снимок экрана показывает, как будет выводиться результат попытки;
Выход записи «try» будет иметь два поля; HasError (мы уже знаем, что это будет правда) и Error. Ошибка — это еще одна запись с более подробной информацией. Нажмите «Expand » в столбце «Custom column» и выберите «Error».
В столбце вывода с именем «Error» снова нажмите на «Expand» и на этот раз выберите все столбцы;
Хорошо иметь исходное имя столбца в качестве префикса, потому что тогда вы бы знали, что это столбцы с подробными сведениями об ошибках.
Теперь вы получите полную информацию об ошибке, как показано ниже;
Вышеупомянутая информация является вашим самым ценным активом для отчетности об исключениях.
Удалите столбец ошибок
Теперь последний шаг перед загрузкой данных в Power BI — удалить столбец, который вызывает ошибку. В нашем примере; Столбец BirthDate должен быть удален (в противном случае обновление снова завершится неудачей);
Отчет об исключении
Теперь вы можете загрузить данные в Power BI. У вас будет две таблицы; DimCustomer и DimCustomer – Error Rows. DimCustomer — это таблица, которую вы можете использовать для обычной отчетности. DimCustomer – Error Rows — это таблица, которую вы можете использовать для отчетов об исключениях. Отчет об исключении — это отчет, который можно использовать для устранения неполадок, и перечисляет все ошибки для дальнейшего расследования. Убедитесь, что между этими двумя таблицами нет никакой связи.
Вот созданный нами образец визуального отчета, который показывает ошибки:
Подведем итоги
Ошибки случаются, и вам приходится иметь дело с ними. Вместо того, чтобы ждать ошибки, а затем находить их лишь через месяц после появления, лучше выявлять их, как только они произойдут. В этой статье вы узнали способ обработки строк ошибок.
Источник
Работа с ошибками в Power Query
В Power Query можно столкнуться с двумя типами ошибок:
- Ошибки на уровне шага
- Ошибки на уровне ячеек
В этой статье приводятся рекомендации по устранению наиболее распространенных ошибок, которые можно найти на каждом уровне, а также описывает причину ошибки, сообщение об ошибке и подробные сведения об ошибке для каждого из них.
Ошибка на уровне шага
Пошаговая ошибка предотвращает загрузку запроса и отображает компоненты ошибок на желтой панели.
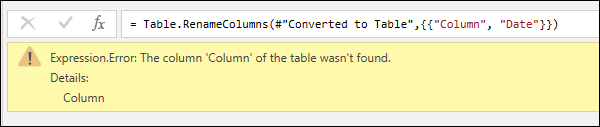
- Причина ошибки: первый раздел перед двоеточием. В приведенном выше примере причина ошибки — Expression.Error.
- Сообщение об ошибке: раздел непосредственно после причины. В приведенном выше примере сообщение об ошибке — столбец «Столбец» таблицы не найден.
- Сведения об ошибке: раздел непосредственно после строки Details: В приведенном выше примере сведения об ошибке — «Столбец«.
Распространенные ошибки на уровне шага
Во всех случаях рекомендуется внимательно ознакомиться с причиной ошибки, сообщением об ошибке и подробными сведениями об ошибке, чтобы понять, что вызывает ошибку. Вы можете нажать кнопку «Перейти к ошибке» , если она доступна, чтобы просмотреть первый шаг, в котором произошла ошибка.

Не удается найти источник — DataSource.Error
Эта ошибка обычно возникает, когда источник данных недоступен пользователем, у пользователя нет правильных учетных данных для доступа к источнику данных или источник был перемещен в другое место.
Пример. У вас есть запрос из текстовой плитки, которая была расположена на диске D и создана пользователем A. Пользователь A предоставляет общий доступ к запросу пользователю B, у которого нет доступа к диску D. Когда этот пользователь пытается выполнить запрос, он получает dataSource.Error , так как в своей среде нет диска D.

Возможные решения. Вы можете изменить путь к файлу текстового файла на путь, к которому у обоих пользователей есть доступ. Как пользователь Б, вы можете изменить путь к файлу, чтобы он был локальной копией того же текстового файла. Если кнопка «Изменить параметры» доступна в области ошибок, ее можно выбрать и изменить путь к файлу.
Столбец таблицы не найден
Эта ошибка обычно активируется, когда шаг создает прямую ссылку на имя столбца, которое не существует в запросе.
Пример. У вас есть запрос из текстового файла, в котором одно из имен столбцов — Column. В запросе есть шаг, который переименовывает этот столбец в date. Но в исходном текстовом файле произошло изменение, и у него больше нет заголовка столбца с именем Column , так как он был изменен вручную на Date. Power Query не удается найти заголовок столбца с именем Column, поэтому он не может переименовать столбцы. Отображается ошибка, показанная на следующем рисунке.
Возможные решения: существует несколько решений для этого случая, но все они зависят от того, что вы хотите сделать. В этом примере, так как правильный заголовок столбца Date уже поступает из текстового файла, можно просто удалить шаг, который переименовывает столбец. Это позволит выполнять запрос без этой ошибки.
Другие распространенные ошибки на уровне шага
При объединении или объединении данных между несколькими источниками данных может возникнуть ошибка Formula.Firewall , например, показанная на следующем рисунке.

Эта ошибка может быть вызвана рядом причин, таких как уровни конфиденциальности данных между источниками данных или способом объединения или объединения этих источников данных. Дополнительные сведения о диагностике этой проблемы см. в брандмауэре конфиденциальности данных.
Ошибка уровня ячейки
Ошибка на уровне ячейки не препятствует загрузке запроса, но отображает значения ошибок в ячейке. При выборе пробела в ячейке отображается область ошибок под предварительным просмотром данных.
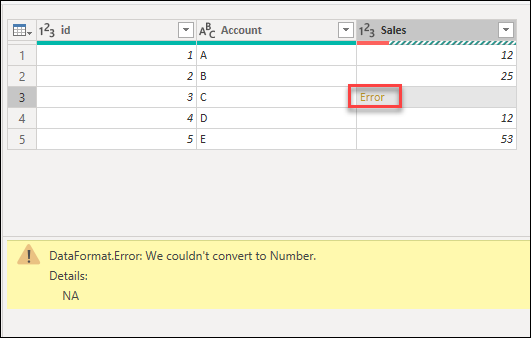
Средства профилирования данных помогают более легко выявлять ошибки на уровне ячеек с помощью функции качества столбца. Дополнительные сведения: средства профилирования данных
Обработка ошибок на уровне ячейки
При возникновении ошибок на уровне ячеек Power Query предоставляет набор функций для их обработки путем удаления, замены или сохранения ошибок.
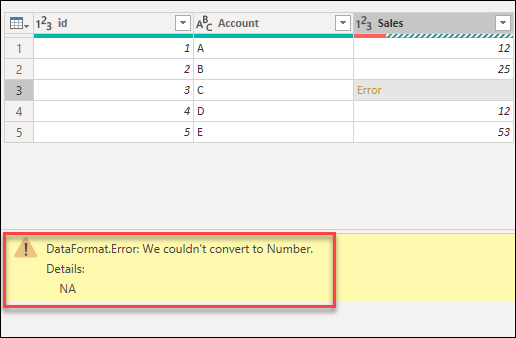
В следующих разделах указанные примеры будут использовать тот же пример запроса, что и начальная точка. В этом запросе есть столбец Sales с одной ячейкой с ошибкой, вызванной ошибкой преобразования. Значение внутри этой ячейки было NA, но при преобразовании этого столбца в целое число Power Query не удалось преобразовать НС в число, поэтому отображается следующая ошибка.
Удаление ошибок
Чтобы удалить строки с ошибками в Power Query, сначала выберите столбец, содержащий ошибки. На вкладке «Главная» в группе «Уменьшить строки» выберите «Удалить строки«. В раскрывающемся меню выберите «Удалить ошибки«.
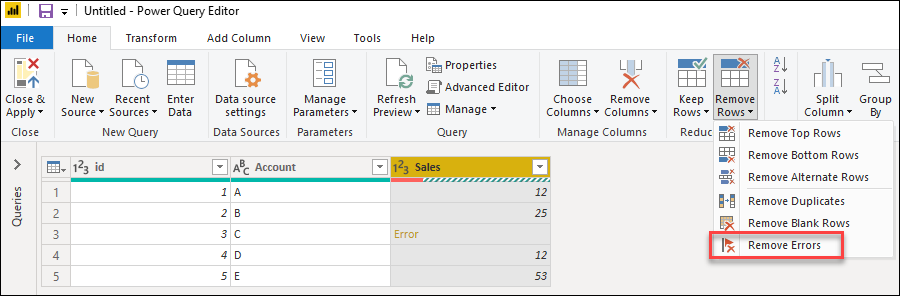
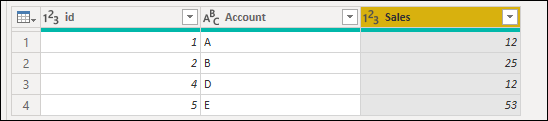
Результат этой операции даст вам таблицу, которую вы ищете.
Замена ошибок
Если вместо удаления строк с ошибками необходимо заменить ошибки фиксированным значением, это также можно сделать. Чтобы заменить строки с ошибками, сначала выберите столбец, содержащий ошибки. На вкладке «Преобразование» в группе «Любой столбец » выберите «Заменить значения«. В раскрывающемся меню выберите «Заменить ошибки«.
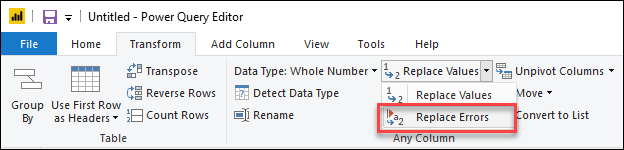
В диалоговом окне «Замена ошибок » введите значение 10 , так как вы хотите заменить все ошибки значением 10.

Результат этой операции даст вам таблицу, которую вы ищете.
Сохранение ошибок
Power Query может служить хорошим средством аудита для выявления строк с ошибками, даже если вы не исправите ошибки. Здесь могут быть полезны ошибки keep . Чтобы сохранить строки с ошибками, сначала выберите столбец, содержащий ошибки. На вкладке «Главная» в группе «Уменьшить строки» выберите «Сохранить строки«. В раскрывающемся меню выберите «Сохранить ошибки«.
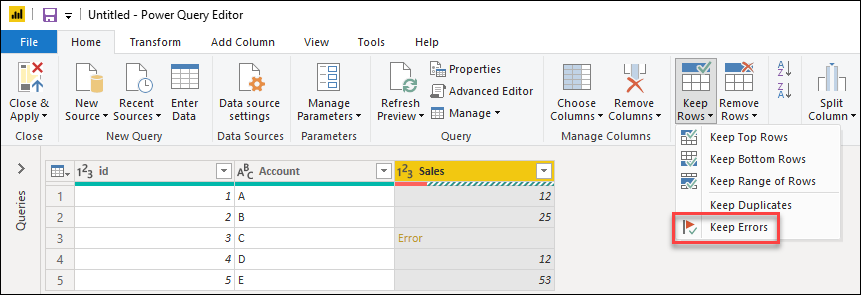
Результат этой операции даст вам таблицу, которую вы ищете.

Распространенные ошибки на уровне ячеек
Как и в случае с любой ошибкой на уровне шага, мы рекомендуем внимательно изучить причины ошибок, сообщения об ошибках и сведения об ошибках, предоставленные на уровне ячейки, чтобы понять, что вызывает ошибки. В следующих разделах рассматриваются некоторые наиболее частые ошибки на уровне ячеек в Power Query.
Ошибки преобразования типов данных
Обычно активируется при изменении типа данных столбца в таблице. Некоторые значения, найденные в столбце, не удалось преобразовать в нужный тип данных.
Пример. У вас есть запрос, содержащий столбец с именем Sales. Одна ячейка в этом столбце содержит значение NA в качестве значения ячейки, а остальные имеют целые числа в качестве значений. Вы решили преобразовать тип данных столбца из текста в целое число, но ячейка со значением NA приводит к ошибке.
Возможные решения. После идентификации строки с ошибкой можно либо изменить источник данных, чтобы отразить правильное значение, а не NA, либо применить операцию «Заменить» , чтобы указать значение для любых значений NA , вызывающих ошибку.
Ошибки операций
При попытке применить операцию, которая не поддерживается, например умножение текстового значения на числовое значение, возникает ошибка.
Пример. Вы хотите создать настраиваемый столбец для запроса, создав текстовую строку, содержащую фразу «Total Sales: » сцеплено со значением из столбца Sales . Ошибка возникает из-за того, что операция объединения поддерживает только текстовые столбцы, а не числовые.

Возможные решения. Перед созданием этого настраиваемого столбца измените тип данных столбца Sales на текст.
Источник