В процессе
проектирования системы обработки данных
проектировщик может ориентироваться
на несколько вариантов аппаратной
платформы и разработать несколько
вариантов технологических процессов,
среди которых ему необходимо выбрать
наилучший. К основным требованиям,
предъявляемым к выбираемому
технологическому процессу, относятся:
• обеспечение
пользователя своевременной информацией;
• обеспечение
высокой степени достоверности полученной
информации;
• обеспечение
минимальности трудовых и стоимостных
затрат,
связанных с
обработкой данных.
При выборе варианта
технологического процесса обработки
экономической информации используют
две группы показателей оценки
эффективности: показатели достоверности
получения и обработки информации и
показатели трудовых и стоимостных
затрат на проектирование системы и
обработку информации.
Для обеспечения
выполнения этих требований необходимо
в первую очередь выбрать высокопроизводительную
и надежную техническую базу, разработать
состав основных операций и методы
их реализации. Однако для достижения
высокой достоверности обработки и
получения результатной информации
проектировщик должен помимо этого
организовать систему контроля за
достоверностью обработки информации.
Для разработки такой системы
проектировщик обязан проанализировать
частоту возникновения ошибок по типам
решаемых задач, по классам операций
технологического процесса, по видам
ошибок и по причинам их возникновения.
С этой целью необходимо собрать
статистику ошибок и получить
распределение частоты их возникновения
по следующим направлениям:
• по видам решаемых
задач: например, аналитические, плановые,
статистические, учетные;
• по классам
операций технологического процесса;
• по видам ошибок,
связанных с состоянием первичных
документов, с переносом данных на
машинные носители, с обработкой в
ЭВМ, с контролем и выпуском результатных
документов;
• по причинам
возникновения ошибок: небрежность
пользователей и плохое освоение
операций по вводу информации в
ЭВМ, вина исполнителя
документов, ошибки в проекте (вина
проектировщиков)
и др.
Затем следует
выбрать определенный метод контроля
за каждой операцией или группой
операций и выполнить оценку степени
достоверности получаемой после обработки
результатной информации.
Показатель
достоверности обработки информации(D) может быть рассчитан по следующей
формуле:
D =
1 — P, (1)
где D — величина
достоверности процесса обработки;
Р
— вероятность появления ошибки, которую
можно рассчитать по формуле
P = N / Q,
(2)
где N- количество
ошибочных действий, допущенных на
множестве Q;
Q — общее количество
действий.
Поскольку
проектировщики, как правило, владеют
ограниченной выборкой по величинам
Q и N, то для оценки достоверности
технологических процессов они используют
показатель частоты появления ошибок(f), который рассчитывается по формуле
(3):
f = N
/ Q,
(3)
где f- частота
возникновения ошибок;
N
— число ошибок, допущенных на множестве
Q;
Q
— величина доступной выборки общего
количества действий.
Для практической
оценки степени достоверности вариантов
технологических процессов разработано
несколько методик, например, применяется
методика с помощью оценки величины,
обратной величине достоверности, —
степени недостоверности технологического
процесса, заданного для множества n- рабочих иm- контрольных
операций некоторого технологического
процесса и представленного в виде
схемы (рис. 7.3).
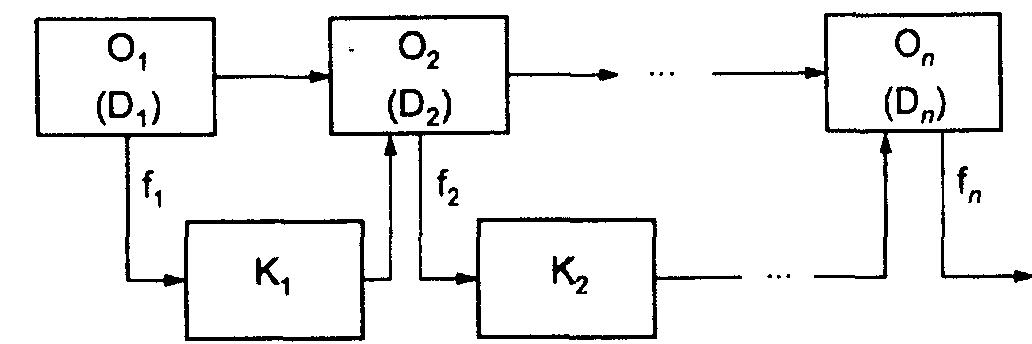
Рис. 7.3. Схема
технологического процесса обработки
данных
Каждая рабочая
операция (Oi) характеризуется
некоторым количеством выполняемых на
ней действий или количеством знаков
(Di) и частотой появления
ошибок (fi). Каждая контрольная
операция характеризуется применением
некоторого j-го метода контроля и
показателем эффективности использования
данного метода (Lij) для контроляi-й
операции, который можно рассчитать
по формуле (4).
![]() (4)
(4)
где
Lij — коэффициент эффективности j-го
метода контроля по i-й
операции;
Ni,
— общее количество ошибок, допущенных
на i-й операции и проверяемых j-м
методом контроля, которое включает в
себя две величины:
![]() (5)
(5)
где
Noij
— число обнаруженных ошибок;
Nnij
— число пропущенных ошибок.
Для характеристики
данной системы контроля используются
следующие показатели:
• коэффициент
исходной недостоверности технологического
процесса, характеризующий надежность
используемой техники и квалификацию
работников, показывающий количество
ошибок, приходящееся на одно действие
(Кинд):
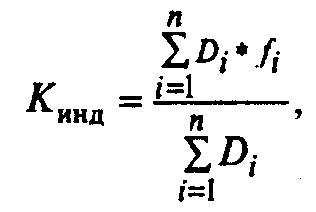 (6)
(6)
где Di — количество
действий на i-й операции;
• коэффициент
контролируемости технологического
процесса(Ккон), характеризующий
качество системы контроля и определяющий
количество обнаруженных ошибок,
приходящееся на одно действие:
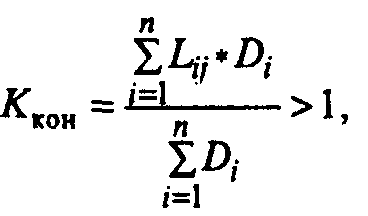 (7)
(7)
• интегральный
коэффициент конечной недостоверности(Ккнд), характеризующий количество
пропущенных ошибок при заданной
системе контроля, приходящееся на одно
действие:
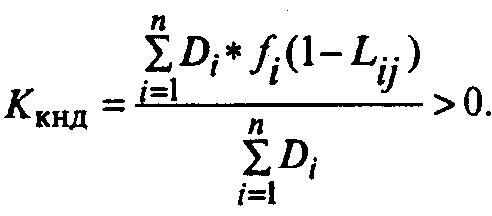 (8)
(8)
При выборе наилучшего
технологического процесса обработки
экономической информации, помимо
использования показателей достоверности,
применяют оценку, сравнение и выбор по
соотношению уровня производительности
того или иного варианта процесса и
значению величин показателей трудовых
и стоимостных затрат на проектирование
и эксплуатацию этих процессов.
В этом комплексе
рассчитывают абсолютныеиотносительныепоказатели оценки
экономической эффективности
технологических процессов.
К группе абсолютных
показателейотносят:
• показатели,
оценивающие величину трудоемкости
обработки информации за год по
базовому (т.е. тому варианту, который
берется за основу для сравнения) и
предлагаемым вариантам (То) и (Тj);
• показатели,
оценивающие величину эксплуатационных
стоимостных затрат за год по базовому
и предлагаемому вариантам (Сo)
и (Сj);
• показатель
оценки снижения трудовых затрат за год
(T), который
рассчитывается по формуле
T = То — Тj, (9)
• показатель
снижения стоимостных затрат за год
(С), который можно
рассчитать по формуле
C = Cо
— Cj. (10)
Группа относительных
показателейоценки эффективности
технологических процессов включает:
• коэффициент
снижения трудовых затрат за год (Кm),
показывающий, на какую долю или какой
процент снижаются затраты предлагаемого
варианта по сравнению с базовым, который
рассчитывается по формуле
Кm = Т
/ Тo; (11)
• индекс снижения
трудовых затрат (Iт), показывающий, во
сколько раз снижаются трудовые затраты
предлагаемого j-го варианта
по сравнению с базовым, и рассчитываемый
по формуле
Iт
= Тo / Тj,
(12)
• коэффициент
снижения стоимостных затрат за год
(Кc), который рассчитывается
по формуле
Кc = C
/ Cj; (13)
• индекс снижения
стоимостных затрат (Ic), рассчитываемый
по формуле
Iс
= Сo/ Сj,
(14)
В свою очередь,
показатель трудовых затрат j-й технологический процесс (Tj)
рассчитывается по формуле
Tj=tij,
(14)
где
tij
— показатель трудовых затрат на i-ю
операцию j-го
технологического процесса, который
можно рассчитать по формуле
tij = Q ij / Ni, (16)
где Qij — объем работ,
выполненных на i-й операции j-му
технологическому процессу;
Ni
— норма выработки на 1-й операции.
Показатель
стоимостных затрат на j-й технологический
процесс (Сj) представляет собой сумму
затрат на j-й технологический процесс
по следующим статьям затрат:
• на заработную
плату;
• на амортизацию;
• на материалы;
• на оплату
машинного времени;
• на ведение
информационной базы;
• накладные
расходы.
Этот показатель
рассчитывается по формуле
Cj=Cij,
(17)
где
Сij — показатель стоимостных затрат на
(i-ю
операцию j-го
технологического процесса, в состав
которого включаются следующие компоненты:
Cij = Cзп
+ Cнр + Cа +
Cмв + Cм + Cвб
(18)
где Сзп — затраты
на заработную плату оператора, которые
можно рассчитать по формуле
Cзп
= tij * ri, (19)
где
tij-трудоемкость
выполнения i-й операции j-го технологического
процесса;
ri
— тарифная ставка i-q операции;
Снр — затраты на
накладные расходы, рассчитываемые как
производная величина от затрат на
заработную плату:
Cнр
= Cзп * Кнр,
(20)
где Кнр — величина
коэффициента накладных расходов,
принимаемая, как правило, в размере 0,6
— 0,7 от величины С зп;
Cа — величина
амортизационных отчислений на используемую
технику, рассчитываемая по формуле
Cа
= tij * ai, (21)
где
ai,
— норма амортизационных отчислений;
Cмв
— стоимость машинного времени на ввод
информации в ЭВМ, обработку данных
и выдачу результатной информации:
Cмj
= tmj * c, (22)
где с — стоимость
машинного часа;
tmj
— длительность выполнения м-й машинной
операции j-го технологического
процесса, включающая в себя следующие
компоненты:
tm = t1 + t2 + t3, (23)
где t1, — длительность
выполнения операции ввода исходной
информации в ЭВМ, рассчитываемая по
формуле
t1 = Qви
/ Nви, (24)
где
Qви
— объем вводимой информации в символах
(байтах);
Nви
— норма вводимой информации с клавиатуры
ЭВМ в час;
t2
— длительность обработки информации
при решении задачи (в час.), определяемая
экспертным путем, если задача сдана в
эксплуатацию, или рассчитываемая
гипотетически, например по следующей
формуле
t2 =Qоп /Vоб, (25)
где
Vоб
— быстродействие работы ЭВМ;
Qоп
— объем операций, выполняемых ЭВМ по
обработке данных при решении задачи,
определяемый различными способами,
например, произведение объема вводимой
информации на предполагаемое количество
операторов, реализуемых алгоритмом
определенного класса задач, т.е.
Qоп
=Qоп *R, (26)
где R — число
операторов, приходящееся на один байт
вводимой информации, характерное
для определенного класса задач.
При этом выделяют
три класса задач:
-
задачи,
связанные с актуализацией данных в
ЭВМ, для которых характерно приблизительно
500 операторов на один байт вводимой
информации; -
задачи,
связанные с оперативной обработкой
данных, для которых на один байт вводимой
информации приходится выполнение 5000
операторов, -
задачи сложной
аналитической обработки данных или
связанные с применением
экономико-математических методов
и моделей, в которых эта величина
составляет 20000 операторов на один
байт вводимой информации;
t3
— время вывода результатной информации
пользователю на печать или по каналам
связи, рассчитываемое по формуле
t3 =Qвыв /Vвыв, (27)
где
Qвыв
— объем выводимой информации (в строках
или байтах);
Vвыв
— скорость работы печатающего устройства
(стр./ч) или канала связи (байт/ч);
См — затраты на
материалы за год (например, на бумагу);
Свб — годовые
затраты на ведение информационной базы.
Кроме того,
рассчитывают приведенный показатель
годовой экономии (Эг) по формуле
Эг = (Со + Ен * Ко) —
(Сj+ Ен * Кj),
(28)
где Кj и Ko„ —
капитальные затраты, включающие в себя
затраты на следующие направления:
• на приобретение
вычислительной техники в базовом и
предлагаемом вариантах;
• на приобретение
вычислительной техники;
• на покупку
программного обеспечения;
• на освоение
программного обеспечения;
• на проектирование
и отладку проекта.
Помимо вышеприведенных
показателей эффективности проектировщики
рассчитывают также показатель срока
окупаемости капитальных затрат
(Ток), представляющий собой отношение
капитальных затрат к экономии стоимостных
затрат:
Ток = (Кj– Кo) /С
. (29)
Расчетный коэффициент
эффективности Ep является обратной
величиной сроку окупаемости и
рассчитывается по формуле
Ep = 1 / Ток . (30)
По совокупности
вышеприведенных показателей проектировщики
выбирают наиболее эффективный вариант
технологического процесса обработки
информации. Обобщенная технологическая
сеть выбора варианта организации
технологического процесса обработки
данных в ЭИС представлена на рис. 7.4.
Вначале осуществляются
работы «Определение состава основных
операций»(П1) и«Уточнение состава
технических средств выполнения операций»(П2). Входными документами для выполнения
этой работы служат материалы обследования,«Постановка задачи»(Д1.1),«Техническое задание»(Д1.2) и множество
предварительно выбранных технических
средств для операций технологического
процесса (U2.1). В результате выполнения
этих работ проектировщики получают
перечень основных операций (Д1.3), описание
технико-эксплуатационных характеристик
выбранных технических средств (Д2.1) и
методов работы с ними (Д2.2), которые
поступают в качестве исходных данных
на вход следующей операции.
На следующей
операции выполняется «Выбор метода
контроля и технических средств,
осуществляющих контроль»(ПЗ). На вход
операции поступает универсум методов
контроля (U3.1). В результате выполнения
процедуры получают описание технических
средств и методов выполнения контроля
(ДЗ.1).
Далее осуществляется
«Разработка вариантов схем
технологического процесса обработки
данных»(П4). Входными документами
для данной операции являются перечни
основных операций, технических
характеристик средств и методик
выполнения контроля (Д1.3, Д2.2, Д2.1, ДЗ.1).
Целью выполнения данной работы
является получение блок-схем нескольких
вариантов технологических процессов
(Д4.1).
Содержанием пятой
операции является «Оценка технологических
процессов по достоверности, трудовым
и стоимостным показателям»(П5). Данная
оценка производится на основе технического
задания и методик расчета показателей
(U5.1). Результатом выполнения работы
является получение таблиц значений
показателей (Д5.1).
Заключительной
операцией служит «Выбор варианта
технологического процесса и разработка
технологической документации»(П6). Выполнение данной работы основывается
на содержании технического задания,
требовании гостов и остов на техно-рабочий
проект (Д6.1). В результате получают
совокупность технологических и
инструкционных карт (Д6.2).
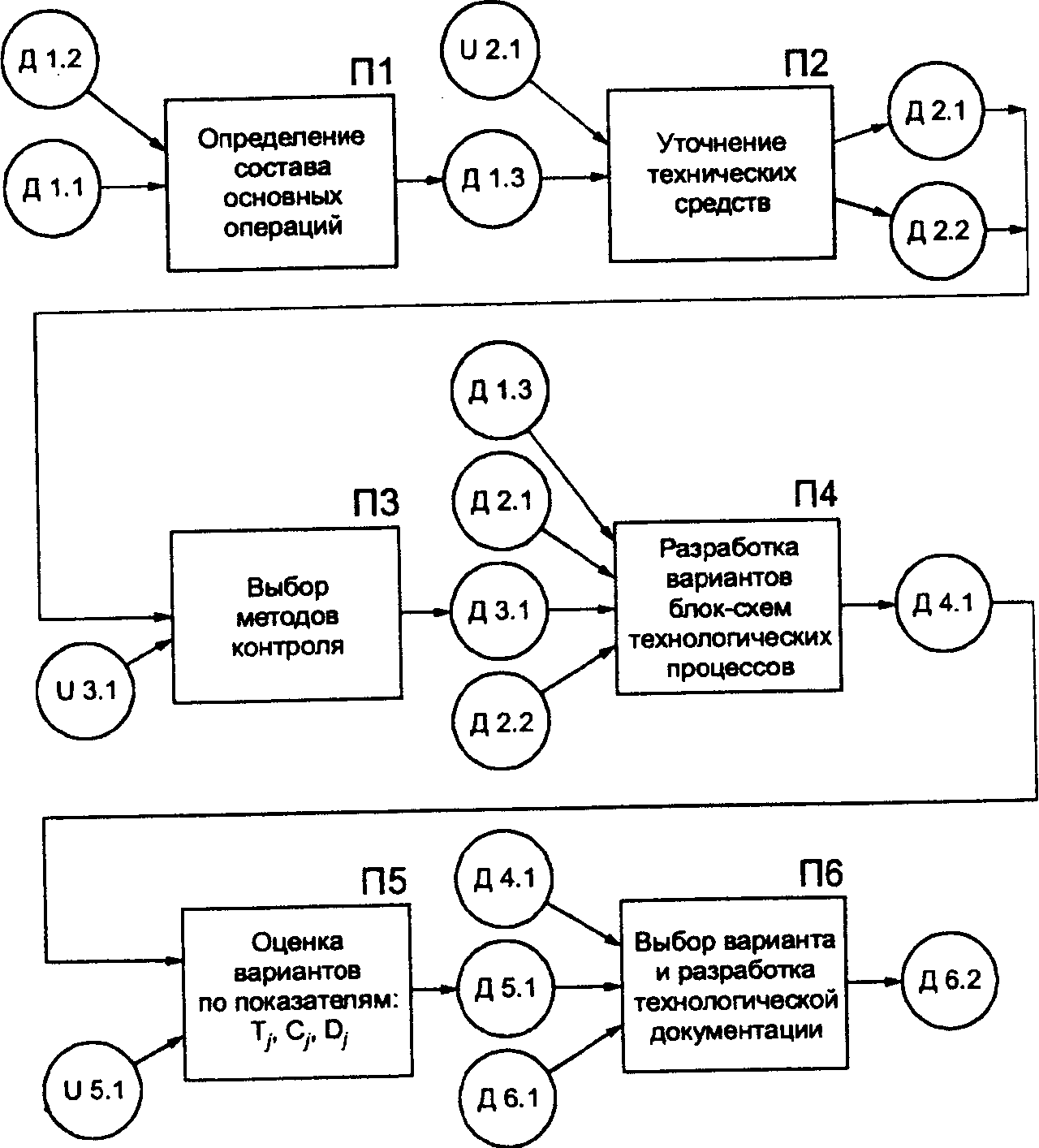
Рис. 7.4.
Технологическая сеть выбора варианта
технологического процесса обработки
данных в ЭИС:
Д 1.1 — постановка
задачи; Д 1.2 — состав основных операций;
U 2.1 — универсум комплекса предварительно
выбранных вариантов ТС; Д 2.1 — описание
выбранного КТС; Д 2.2 — методы работы; U
3.1 — универсум методов контроля; Д 3.1 —
описание методов контроля; Д 3.2 — уточненный
вариант КТС; Д 4.1 — варианты схем технических
процессов; U 5.1 — универсум методик оценки
Т. С., D.; Д 5.1 — таблицы значений показателей;
Д 6.1 — требования ТЗ; Д 6.2 — технологические
и инструкционные карты
Вопросы
для самопроверки
1. Что такое
технологический процесс и по каким
признакам классифицируются технологические
процессы?
2. Что такое
технологическая операция и каковы виды
технологических операций?
3. Каковы принципы
и методы организации контроля за
достоверностью обработки данных?
4. Каковы требования,
предъявляемые к технологическим
процессам?
5. Каковы основные
показатели определения степени
достоверности, обеспечиваемые
технологическим процессом?
6. Каковы абсолютные
и относительные показатели оценки
трудовых затрат, связанных с реализацией
технологического процесса?
7. Каковы абсолютные
и относительные показатели оценки
стоимостных затрат, связанных с
реализацией технологического
процесса?
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Содержание:

Введение
Программное обеспечение, согласно ГОСТ 19781-90, – совокупность программ системы обработки информации и программных документов, необходимых для их эксплуатации.
Существует и другое, более простое определение, согласно которому программное обеспечение представляет собой совокупность компьютерных инструкций. Оно охватывает программы, подпрограммы (разделы программы) и данные. Таким образом, программное обеспечение указывает компьютеру, что делать, как, когда, в какой последовательности и как часто. Нередко программное обеспечение называют просто программой.
Проблема надежности программного обеспечения относится, похоже, к категории «вечных». В посвященной ей монографии Г.Майерса, выпущенной в 1980 году (американское издание — в 1976), отмечается, что, хотя этот вопрос рассматривался еще на заре применения вычислительных машин, в 1952 году, он не потерял актуальности до настоящего времени. Отношение к проблеме довольно выразительно сформулировано в книге Р.Гласса: «Надежность программного обеспечения — беспризорное дитя вычислительной техники». Следует далее отметить, что сама проблема надежности программного обеспечения имеет, по крайней мере, два аспекта: обеспечение и оценка (измерение) надежности. Практически вся имеющаяся литература на эту тему, включая упомянутые выше монографии, посвящена первому аспекту, а вопрос оценки надежности компьютерных программ оказывается еще более «беспризорным». Вместе с тем очевидно, что надежность программы гораздо важнее таких традиционных ее характеристик, как время исполнения или требуемый объем оперативной памяти, однако никакой общепринятой количественной меры надежности программ до сих пор не существует.
Для обеспечения надежности программ предложено множество подходов, включая организационные методы разработки, различные технологии и технологические программные средства, что требует, очевидно, привлечения значительных ресурсов. Однако отсутствие общепризнанных критериев надежности не позволяет ответить на вопрос, насколько надежнее становится программное обеспечение при соблюдении данных процедур и технологий и в какой степени оправданы расходы. Получается, что таким образом, приоритет задачи оценки надежности должен быть выше приоритета задачи ее обеспечения, чего на самом деле не наблюдается.
Цель данной работы – рассмотреть классификацию ошибок программного обеспечения для обеспечения его надежности.
1. Надежность программного обеспечения
Показатели качества программного обеспечения
Оценка качества программного обеспечения могут проводиться с двух позиций: с позиции положительной эффективности и непосредственной адекватности их характеристик назначению, целям создания и применения, а также с негативной позиции, возможного при этом ущерба – риска от пользования ПС или системы. Показатели качества преимущественно отражают положительный эффект от применения программного обеспечения и основная задача разработчиков проекта состоит в обеспечении высоких значений качества. Риски характеризуют возможные негативные последствия проявившихся в ходе эксплуатации ошибок или ущерб для пользователя при применении и функционировании программного обеспечения.
Согласно ГОСТ 9126[2], качество программного обеспечения – это весь объем признаков и характеристик программного обеспечения, который относится к ее способности удовлетворять установленным или предполагаемым потребностям.
Качество программного обеспечения оценивается следующими характеристиками:
- Функциональные возможности (Functionality). Набор атрибутов, относящихся к сути набора функций и их конкретным свойствам. Функциями являются те, которые реализуют установленные или предполагаемые потребности.
- Надежность (Reliability). Набор атрибутов относящихся к способности программного обеспечения сохранять свой уровень качества функционирования при установленных условиях за установленный период времени.
- Практичность (Usability). Набор атрибутов, относящихся к объему работ, требуемых для использования и индивидуальной оценки такого использования определенным и предполагаемым кругом пользователей.
- Эффективность (Efficiencies). Набор атрибутов, относящихся к соотношению между уровнем качества функционирования программного обеспечения и объемом используемых ресурсов при установленных условиях.
- Сопровождаемость (Maintainability). Набор атрибутов, относящихся к объему работ, требуемых для проведения конкретных изменений (модификаций).
- Мобильность (Portability). Набор атрибутов, относящихся к способности программного обеспечения быть перенесенным из одного окружения в другое.
В общем случае под ошибкой подразумевается неправильность, погрешность или неумышленное искажение объекта или процесса, что может быть причиной ущерба – риска при функционировании или применении программы. При этом предполагается, что известно правильное, эталонное состояние объекта или процесса по отношению к которому может быть определено наличие отклонения. Исходным эталоном для любого программного обеспечения являются спецификации требований заказчика или потенциального пользователя, предъявляемых к программам и ожидаемый пользователем или заказчиком эффект от использования программного обеспечения. Важной особенностью при этом является отсутствие полностью определенной программы – эталона, которой должны соответствовать текст и результаты функционирования разрабатываемой программы. Поэтому определить качество программного обеспечения и наличие ошибок в нем путем сравнения разрабатываемой программы с эталонной программой невозможно.
Риски проявляются как негативные последствия проявления ошибок в программном обеспечении в ходе его пользования и функционирования, которые могут нанести ущерб системе, в которой используется это программное обеспечение, внешней среде или пользователям этой системы в результате отклонения характеристик программного обеспечения заданных или ожидаемых пользователем или заказчиком.
Исходя из определения ошибки в программном обеспечении, приведенном выше, можно сделать вывод, что ошибки, возникающие в ходе использования программного обеспечения, могут изменять некоторые или все показатели качества. В работе рассматриваются ошибки, изменения которых влияют на надежность использования программного обеспечения.
По правилу, установленному в [2], надежность – свойство объекта осуществлять заданные функции, храня во времени значения установленных эксплуатационных показателей в заданных пределах, соответствующим заданным режимам и условиям использования, ремонта, технического обслуживания, хранения, транспортирования.

Рис. 1. Надежность по ГОСТ 27.002 – 89
При этом надежность является комплексным свойством, которое в зависимости от функции объекта и условий его использования может включать безотказность, ремонтопригодность, долговечность, сохраняемость или некоторые сочетания данных свойств (рис. 1). Так как программное обеспечение в процессе эксплуатации не изнашивается, его поломка и ремонт в общепринятом смысле не делается, то надежность программного обеспечения имеет смысл характеризовать только с точки зрения безотказности его функционирования и возможности исправления функционирования после отказов по вызванных проявлениями ошибок.
В [3] надежность программного обеспечения предлагается характеризовать с помощью следующих характеристик (рис. 2): стабильность, устойчивость и восстанавливаемость.

Рис. 2. Надежность программного обеспечения
В этом случае стабильность и устойчивость характеризуют безотказность программного обеспечения, а восстанавливаемость – возможность восстановления функционирования программного обеспечения после его отказа. Для количественной оценки надежности программного обеспечения необходимо определить показатели надежности для каждого свойства и методику их определения (оценки).
Для оценки стабильности программного обеспечения возможно использование показателей характеризующих безотказность технических устройств [2] (рис. 3).

Рис. 3. Показатели безотказности
В большинстве случаев поток программных ошибок может быть описан негомогенным процессом Пуассона [4]. Это означает, что программные ошибки происходят в статистически независимые моменты времени, наработки подчиняются экспоненциальному распределению, а интенсивность проявления ошибок изменяется во времени. Обычно используют убывающую интенсивность проявления ошибок. Это означает, что ошибки, как только они выявлены, эффективно устраняются без введения новых ошибок. Главная цель анализа надежности программного обеспечения заключается в том, чтобы определить форму функции интенсивности проявления ошибок и оценить ее параметры по наблюдаемым данным. Как только функция интенсивности проявления ошибок определена, могут быть найдены такие показатели надежности как:
- общее количество ошибок;
- количество остающихся ошибок;
- время до проявления следующей ошибки;
- вероятность безошибочной работы;
- интенсивность проявления ошибок;
- остаточное время испытаний (до принятия решения);
- максимальное количество ошибок (относительно срока службы).
При этом следует различать понятия ошибка и отказ. Применительно к надежности программного обеспечения ошибка это погрешность или искажение кода программы, неумышленно внесенные в нее в процессе разработки, которые в ходе функционирования этой программы могут вызвать отказ или снижение эффективности функционирования. Под отказом в общем случае понимают событие, заключающееся в нарушении работоспособности объекта [2]. Состояние объекта, при котором значения всех параметров характеризующих способность выполнять заданные функции, соответствуют требованиям нормативно – технической и (или) конструкторской (проектной) документации – называется работоспособным. При этом критерии отказов, как признаки или совокупность признаков нарушения работоспособного состояния программного обеспечения, должны определяться исходя из его предназначения в нормативно – технической и (или) конструкторской (проектной) документации.
В общем случае отказ программного обеспечения можно определить как:
- прекращение функционирования программы (искажения нормального хода ее выполнения, зацикливание) на время превышающее заданный порог;
- прекращение функционирования программы (искажения нормального хода ее выполнения, зацикливание) на время не превышающее заданный порог, но с потерей всех или части обрабатываемых данных;
- прекращение функционирования программы (искажения нормального хода ее выполнения, зацикливание) потребовавшее перезагрузки ЭВМ, на которой функционирует программное обеспечение.
При этом исходя из [2], все отказы в программном обеспечении следует трактовать как сбои (самоустраняющиеся отказы или однократные отказы, устраняемые незначительным вмешательством оператора), поскольку восстановление работоспособного состояния программного обеспечения может произойти без вмешательства оператора (перезагрузка ЭВМ не требуется), либо при участии оператора или эксплуатирующего персонала (перезагрузка ЭВМ необходима).
Приведенные выше критерии отказов приводят к необходимости анализа временных характеристик функционирования программы и динамических характеристик потребителей данных, полученных в ходе функционирования программного обеспечения. Временная зона перерыва нормальной выдачи информации и потери работоспособности, которую следует рассматривать как зону сбоя (отказа), тем шире, чем более инертный объект находится под воздействием данных, полученным в ходе работы программы. Пороговое время восстановления работоспособного состояния системы, при превышении которого следует соответствующему потребителю (абоненту).
Для любого потребителя данных существует допустимое время отсутствия данных от программы, при котором его характеристики находятся в допустимых пределах. Исходя из этого времени, можно установить границы временной зоны, которая разделяет работоспособное и неработоспособное состояние программного обеспечения и позволяет использовать данные критерии отказов.
Из приведенного выше определения программной ошибки с точки зрения надежности, можно сделать вывод о том, что ошибки, при их проявлении, не всегда вызывают отказ программного обеспечения и каждую ошибку можно характеризовать условной вероятностью возникновения отказа при проявлении этой ошибки. Следует также отметить, что само по себе наличие ошибки в исходном коде не определяет надежность программы до тех пор, пока не произойдет проявления этой ошибки, поэтому пользоваться для оценки надежности программного обеспечения только показателями характеризующие общее количество ошибок в программе, количество оставшихся ошибок и максимального количества ошибок нельзя.
В [5] стабильность предлагается оценивать вероятностью безотказной работы, которая оценивается исходя из модели относительной частоты, при этом применение ее ограничено периодом эксплуатации программного обеспечения, что не всегда приемлемо, поскольку надежность объекта, как правило, необходимо оценивать не только в процессе его эксплуатации, но и до начала эксплуатации этого объекта. Ограничение модели относительной частоты вызвано тем, что в этой модели не учитываются процессы тестирования и отладки, а конкретно то, что при возникновении отказа программного обеспечения, ошибка, вызвавшая этот отказ, исправляется.
Наиболее приемлемыми показателями характеризующими стабильность (безотказность) программного обеспечения представляются показатели сходные с показателями безотказности технических систем: вероятность безотказной работы, интенсивность отказов, и среднее время наработки на отказ. Эти показатели взаимосвязаны и, зная один из них, можно определить другие [2]. При определении этих показателей в большинстве случаев можно исходить из модели надежности, предполагающей, что интенсивность проявления ошибок убывает по мере исправления этих ошибок, время между проявлениями ошибок распределено экспоненциально, а интенсивность проявления ошибок постоянна между двумя соседними проявлениями ошибок. Применение такой модели надежности программного обеспечения позволит оценить надежность программного обеспечения во время тестирования и отладки.
Устойчивость, как свойство или совокупность свойств программного обеспечения, характеризующие его возможность поддерживать приемлемый уровень функционирования при проявлениях ошибок в нем, можно оценивать условной вероятностью безотказной работы при проявлении ошибки. Согласно [5] устойчивость оценивается с помощью трех метрик, включающих двадцать оценочных элементов (рис. 4). Результаты оценки каждой метрики определяются результатами оценки определяющих ее оценочных элементов, а результат оценки устойчивости определяются результатами соответствующих ему метрик. Программное обеспечение по каждому из оценочных элементов оценивается группой экспертов – специалистов, компетентных в решении данной задачи, на базе их опыта и интуиции. Для оценочных элементов принимается единая шкала оценки от 0 до 1.
Недостатком такого подхода является одинаковая оценка устойчивости для всех возможных ошибок. Поскольку вероятность возникновения отказа при проявлении разных ошибок может быть разной, возникает необходимость разделения ошибок на несколько категорий. Признаком, по которому в этом случае можно относить ошибки к той или иной категории, можно считать тяжесть ошибки. Под тяжестью ошибки в этом случае следует понимать количественную или качественную оценку вероятного ущерба при проявлении этой ошибки [6], а если говорить о надежности, то оценку вероятности возникновения отказа при проявлении ошибки. При этом категорией тяжести последствий ошибки будет являться классификационная группа ошибок по тяжести их последствий, характеризуемая определенным сочетанием качественных и/или количественных учитываемых составляющих ожидаемого (вероятного) отказа или нанесенного отказом ущерба.
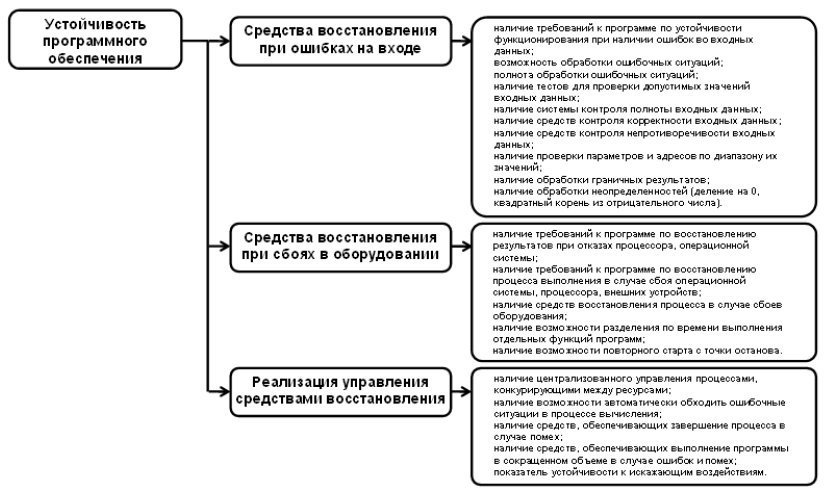
Рис. 4. Метрики и оценочные элементы устойчивости программного обеспечения по ГОСТ 28195 – 89
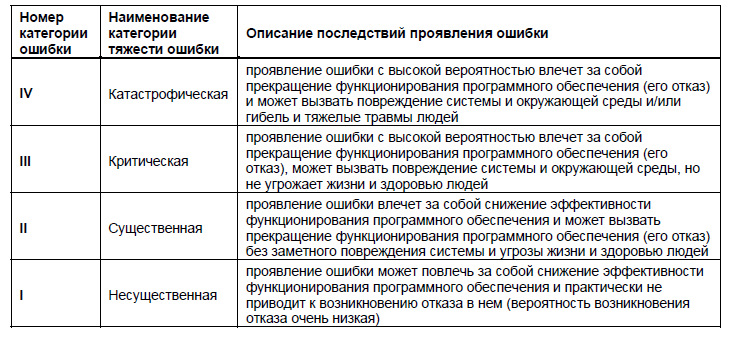
В качестве показателя степени тяжести ошибки, позволяющего дать количественную оценку тяжести проявления последствий ошибки целесообразно использовать условную вероятность отказа и его возможных последствий при проявлении ошибок разных категорий. Для программного обеспечения, создаваемого для систем управления, потеря работоспособности которых может повлечь за собой катастрофические последствия, возможные категории тяжести ошибок приведены в таблице 1.
Таблица 1. Категории тяжести ошибки в программном обеспечении, нарушение работоспособности которого могут привести к катастрофическим последствиям
Для программного обеспечения общего применения или программного обеспечения систем, нарушение работоспособности которых не представляет угрозы жизни людей и не приводит к разрушению самой системы, возможные категории тяжести приведены в таблице 2.
Таблица 2. Категории тяжести ошибки в программном обеспечении, нарушение работоспособности которого не приводят к катастрофическим последствиям

Оценку степени тяжести ошибки как условной вероятности возникновения отказа (последствий этого отказа), можно производить согласно [5], используя метрики и оценочные элементы, характеризующие устойчивость программного обеспечения. При этом оценка производится для каждой ошибки в отдельности, а не для всего программного обеспечения. Далее исходя из проведенных оценок возможно определение устойчивости программного обеспечения к проявлениям ошибок каждой из категорий.
Восстанавливаемость программного обеспечения, как свойство или совокупность свойств характеризующих способность программного обеспечения восстановления своего уровня пригодности и восстановления данных, непосредственно поврежденных вследствии проявлении ошибки (отказа), характеризуется полнотой и длительностью восстановления функционирования программ в процессе перезапуска или перезагрузки ЭВМ. В [5] восстанавливаемость предлагается оценивать по среднему времени восстановления. При этом следует учитывать, что время восстановления функционирования программного обеспечения складывается не только из времени потребного для перезагрузки ЭВМ и загрузки самого программного обеспечения, но и из времени необходимого для восстановления данных и это время в ряде случаев может значительно превышать время перезагрузки.
Показатели надежности программного обеспечения в значительной степени адекватны аналогичным характеристикам, принятых для других технических систем. Наиболее широко используется показатель наработки на отказ. Наработка на отказ – это отношение суммарной наработки объекта к математическому ожиданию числа его отказов в течении этой наработки. Для программного обеспечения использование данного показателя затруднено, в силу особенностей тестирования и отладки программного обеспечения (ошибка вызвавшая отказ, как правило, исправляется и больше не повторяется). Поэтому целесообразно использовать показатель средней наработки до отказа – математического ожидания времени функционирования программного обеспечения до отказа. При использовании модели надежности программного обеспечения предполагающей экспоненциальное распределение времени между отказами, среднее время наработки до отказа равно величине обратной интенсивности отказов. Интенсивность отказов можно оценить исходя из оценок стабильности и устойчивости программного обеспечения. Обобщение характеристик отказов и восстановлений производится в показателе коэффициент готовности [2]. Коэффициент готовности программного обеспечения это вероятность того, что программное обеспечение окажется в работоспособном состоянии в произвольный момент времени. Значение коэффициента готовности соответствует доле времени полезной работы программного обеспечения на достаточно большом интервале времени, содержащем отказы и восстановления.
2. Источники ошибок программного обеспечения
Источниками ошибок в программном обеспечении являются специалисты – конкретные люди с их индивидуальными особенностями, квалификацией, талантом и опытом. Вследствие этого плотность потоков ошибок и размеры необходимых корректировок в модулях и компонентах при разработке и сопровождении программного обеспечения могут различаться в десятки раз. Однако в крупных комплексах программ статистика и распределение ошибок и типов выполняемых изменений, необходимых для их исправления, для коллективов разных специалистов нивелируются и проявляются общие закономерности, которые могут использоваться как ориентиры при выявлении ошибок и их систематизации. Этому могут помогать оценки типовых ошибок, модификаций и корректировок путем их накопления и обобщения по опыту создания определенных классов программного обеспечения.
Основными причинами ошибок программного обеспечения являются:
- Большая сложность программного обеспечения, например, по сравнению с аппаратурой ЭВМ.
- Неправильный перевод информации из одного представления в другое на макро и микро уровнях. На макро уровне, уровне проекта, осуществляется передача и преобразование различных видов информации между организациями, подразделениями и конкретными исполнителями на всех этапах жизненного цикла ПО. На микро уровне, уровне исполнителя, производится преобразование информации по схеме: получить информацию, запомнить, выбрать из памяти, воспроизвести информацию.
Источниками ошибок программного обеспечения являются:
Внутренние: ошибки проектирования, ошибки алгоритмизации, ошибки программирования, недостаточное качество средств защиты, ошибки в документации.
Внешние: ошибки пользователей, сбои и отказы аппаратуры ЭВМ, искажение информации в каналах связи, изменения конфигурации системы.
- Признаками выявления ошибок являются:
- Преждевременное окончание программы.
- Увеличение времени выполнения программы.
- Нарушение последовательности вызова отдельных подпрограмм.
Ошибки выхода информации, поступающей от внешних источников, между входной информацией возникает не соответствие из-за: искажение данных на первичных носителях, сбои и отказы в аппаратуре, шумы и сбои в каналах связи, ошибки в документации.
Ошибки, скрытые в самой программе: ошибка вычислений, ошибка ввода-вывода, логические ошибки, ошибка манипулирования данными, ошибка совместимости, ошибка сопряжения.
Искажения входной информации, подлежащей обработке: искажения данных на первичных носителях информации; сбои и отказы в аппаратуре ввода данных с первичных носителей информации; шумы и сбои в каналах связи при передачи сообщений по линиям связи; сбои и отказы в аппаратуре передачи или приема информации; потери или искажения сообщений в буферных накопителях вычислительных систем; ошибки в документировании; используемой для подготовки ввода данных; ошибки пользователей при подготовки исходной информации.
Неверные действия пользователя:
- Неправильная интерпретация сообщений.
- Неправильные действия пользователя в процессе диалога с программным обеспечением.
- Неверные действия пользователя или по-другому, их можно назвать ошибками пользователя, которые возникают вследствие некачественной программной документации: неверные описания возможности программ; неверные описания режимов работы; неверные описания форматов входной и выходной информации; неверные описания диагностических сообщений.
Неисправности аппаратуры установки: приводят к нарушениям нормального хода вычислительного процесса; приводят к искажениям данных и текстов программ в основной и внешней памяти.
Итак, при рассмотрении основных причин возникновения отказа и сбоев программного обеспечения можно сказать, что эти знания позволяют своевременно принимать необходимые меры по недопущению отказов и сбоев программного обеспечения.
3. Виды ошибок программного обеспечения
Характеристика основных видов ошибок программного обеспечения
Рассмотрим классификацию ошибок по месту их возникновения, которая рассмотрена в книге С. Канера «Тестирование программного обеспечения». Фундаментальные концепции менеджмента бизнес-приложений. Главным критерием программы должно быть ее качество, которое трактуется как отсутствие в ней недостатков, а также сбоев и явных ошибок. Недостатки программы зависят от субъективной оценкой ее качества потенциальным пользователем. При этом авторы скептически относятся к спецификации и утверждают, что даже при ее наличии, выявленные на конечном этапе недостатки говорят о ее низком качестве. При таком подходе преодоление недостатков программы, особенно на заключительном этапе проектирования, может приводить к снижению надежности. Очевидно, что для разработки ответственного и безопасного программного обеспечения (ПО) такой подход не годится, однако проблемы наличия ошибок в спецификациях, субъективного оценивания пользователем качества программы существуют и не могут быть проигнорированы. Должна быть разработана система некоторых ограничений, которая бы учитывала эти факторы при разработке и сертификации такого рода ПО. Для обычных программ все проблемы, связанные с субъективным оцениванием их качества и наличием ошибок, скорее всего неизбежны.
В краткой классификации выделяются следующие ошибки.
- ошибки пользовательского интерфейса.
- ошибки вычислений.
- ошибки управления потоком.
- ошибки передачи или интерпретации данных.
- перегрузки.
- контроль версий.
- ошибка выявлена и забыта.
- ошибки тестирования.
1. Ошибки пользовательского интерфейса.
Многие из них субъективны, т.к. часто они являются скорее неудобствами, чем «чистыми» логическими ошибками. Однако они могут провоцировать ошибки пользователя программы или же замедлять время его работы до неприемлемой величины. В результате чего мы будем иметь ошибки информационной системы (ИС) в целом. Основным источником таких ошибок является сложный компромисс между функциональностью программы и простотой обучения и работы пользователя с этой программой. Проблему надо начинать решать при проектировании системы на уровне ее декомпозиции на отдельные модули, исходя из того, что вряд ли удастся спроектировать простой и удобный пользовательский интерфейс для модуля, перегруженного различными функциями. Кроме того, необходимо учитывать рекомендации по проектированию пользовательских интерфейсов. На этапе тестирования ПО полезно предусмотреть встроенные средства тестирования, которые бы запоминали последовательности действий пользователя, время совершения отдельных операций, расстояния перемещения курсора мыши. Кроме этого возможно применение гораздо более сложных средств психо-физического тестирования на этапе тестирования интерфейса пользователя, которые позволят оценить скорость реакции пользователя, частоту этих реакций, утомляемость и т.п. Необходимо отметить, что такие ошибки очень критичны с точки зрения коммерческого успеха разрабатываемого ПО, т.к. они будут в первую очередь оцениваться потенциальным заказчиком.
2.Ошибки вычислений.
Выделяют следующие причины возникновения таких ошибок:
- неверная логика (может быть следствием, как ошибок проектирования, так и кодирования);
- неправильно выполняются арифметические операции (как правило — это ошибки кодирования);
- неточные вычисления (могут быть следствием, как ошибок проектирования, так и кодирования). Очень сложная тема, надо выработать свое отношение к ней с точки зрения разработки безопасного ПО.
Выделяются подпункты: устаревшие константы; ошибки вычислений; неверно расставленные скобки; неправильный порядок операторов; неверно работает базовая функция; переполнение и потеря значащих разрядов; ошибки отсечения и округления; путаница с представлением данных; неправильное преобразование данных из одного формата в другой; неверная формула; неправильное приближение.
3.Ошибки управления потоком.
В этот раздел относится все то, что связано с последовательностью и обстоятельствами выполнения операторов программы.
Выделяются подпункты:
- очевидно неверное поведение программы;
- переход по GOTO;
- логика, основанная на определении вызывающей подпрограммы;
- использование таблиц переходов;
- выполнение данных (вместо команд). Ситуация возможна из-за ошибок работы с указателями, отсутствия проверок границ массивов, ошибок перехода, вызванных, например, ошибкой в таблице адресов перехода, ошибок сегментирования памяти.
4.Ошибки обработки или интерпретации данных.
Выделяются подпункты:
- проблемы при передаче данных между подпрограммами (сюда включены несколько видов ошибок: параметры указаны не в том порядке или пропущены, несоответствие типов данных, псевдонимы и различная интерпретация содержимого одной и той же области памяти, неправильная интерпретация данных, неадекватная информация об ошибке, перед аварийным выходом из подпрограммы не восстановлено правильное состояние данных, устаревшие копии данных, связанные переменные не синхронизированы, локальная установка глобальных данных (имеется в виду путаница локальных и глобальных переменных), глобальное использование локальных переменных, неверная маска битового поля, неверное значение из таблицы);
- границы расположения данных (сюда включены несколько видов ошибок: не обозначен конец нуль-терминированной строки, неожиданный конец строки, запись/чтение за границами структуры данных или ее элемента, чтение за пределами буфера сообщения, чтение за пределами буфера сообщения, дополнение переменных до полного слова, переполнение и выход за нижнюю границу стека данных, затирание кода или данных другого процесса);
- проблемы с обменом сообщений (сюда включены несколько видов ошибок: отправка сообщения не тому процессу или не в тот порт, ошибка распознавания полученного сообщения, недостающие или несинхронизированные сообщения, сообщение передано только N процессам из N+1, порча данных, хранящихся на внешнем устройстве, потеря изменений, не сохранены введенные данные, объем данных слишком велик для процесса-получателя, неудачная попытка отмены записи данных).
5.Повышенные нагрузки.
При повышенных нагрузках или нехватке ресурсов могут возникнуть дополнительные ошибки. Выделяются подпункты: требуемый ресурс недоступен; не освобожден ресурс; нет сигнала об освобождении устройства; старый файл не удален с накопителя; системе не возвращена неиспользуемая память; лишние затраты компьютерного времени; нет свободного блока памяти достаточного размера; недостаточный размер буфера ввода или очереди; не очищен элемент очереди, буфера или стека; потерянные сообщения; снижение производительности; повышение вероятности ситуационных гонок; при повышенной нагрузке объем необязательных данных не сокращается; не распознается сокращенный вывод другого процесса при повышенной загрузке; не приостанавливаются задания с низким приоритетом.
7.Ошибки тестирования.
Являются ошибками сотрудников группы тестирования, а не программы. Выделяются подпункты:
- пропущенные ошибки в программе;
- не замечена проблема (отмечаются следующие причины этого: тестировщик не знает, каким должен быть правильный результат, ошибка затерялась в большом объеме выходных данных, тестировщик не ожидал такого результата теста, тестировщик устал и невнимателен, ему скучно, механизм выполнения теста настолько сложен, что тестировщик уделяет ему больше внимания, чем результатам);
- пропуск ошибок на экране;
- не документирована проблема (отмечаются следующие причины этого: тестировщик неаккуратно ведет записи, тестировщик не уверен в том, что данные действия программы являются ошибочными, ошибка показалась слишком незначительной, тестировщик считает, что ошибку не будет исправлена, тестировщика просили не документировать больше подобные ошибки).
8.Ошибка выявлена и забыта.
Описываются ошибки использования результатов тестирования. По-моему, раздел следует объединить с предыдущим. Выделяются подпункты: не составлен итоговый отчет; серьезная проблема не документирована повторно; не проверено исправление; перед выпуском продукта не проанализирован список нерешенных проблем.
Необходимо заметить, что изложенные в 2-х последних разделах ошибки тестирования требуют для устранения средств автоматизации тестирования и составления отчетов. В идеальном случае, эти средства должны быть проинтегрированы со средствами и технологиями проектирования ПО. Они должны стать важными инструментальными средствами создания высококачественного ПО. При разработке средств автоматизированного тестирования следует избегать ошибок, которые присущи любому ПО, поэтому нужно потребовать, чтобы такие средства обладали более высокими характеристиками надежности, чем проверяемое с их помощью ПО.
4. Меры по повышению надежности программного обеспечения
Лучшим и самым оптимальным способом (если не брать во внимание научно-технический прогресс и постоянное развитие IT-технологий, которые способствуют повышению качества характеристик программ) повышения надёжности программного обеспечения является строжайший контроль продукции на выходе с предприятия.
В последние годы сформировалась комплексная система управления качеством продукции TQM (Totaly Quality Management), которая концептуально близка к предшествующей более общей системе на основе стандартов ИСО серии 9000. Система ориентирована на удовлетворение требований потребителя, на постоянное улучшение процессов производства или проектирования, на управление процессами со стороны руководства предприятия на основе фактического состояния проекта. Основные достижения TQM состоят в углублении и дифференциации требований потребителей по реализации процессов, их взаимодействию и обеспечению качества продукции. Системный подход поддержан рядом специализированных инструментальных средств, ориентированных на управление производством продукции. Поэтому эта система пока не находит применения в области обеспечения качества жизненного цикла программных средств.
Применение этого комплекса может служить основой для систем обеспечения качества программных средств, однако требуется корректировка, адаптация или исключение некоторых положений стандартов применительно к принципиальным особенностям технологий и характеристик этого вида продукции. Кроме того, при реализации систем качества необходимо привлечение ряда стандартов, формально не относящихся к этой серии и регламентирующих показатели качества, жизненный цикл, верификацию и тестирование, испытания, документирование и другие особенности комплексов программ.
Активные методы повышения надежности ПС совершенствуются за счет развития средств автоматизации тестирования программ. Сложность ПС и высокие требования по их надежности требуют выработки принципов структурного построения сложных программных средств, обеспечивающих гибкость модификации ПС и эффективность их отладки. К таким принципам в работе относят:
- модульность и строгую иерархию в структурном построении программ;
- унификацию правил проектирования, структурного построения и взаимодействия компонент ПС;
- унификацию правил организации межмодульного интерфейса;
- поэтапный контроль полноты и качества решения функциональных задач.
Заключение
Несмотря на очевидную актуальность, вопрос надежности программного обеспечения не привлекает должного внимания. Вместе с тем, даже поверхностный анализ проблемы с теоретико-вероятностной точки зрения позволяет выявить некоторые закономерности.
В заключение можно подвести итог:
- В программном обеспечении имеется ошибка, если оно не выполняет того, что пользователю разумно от него ожидать;
- Отказ программного обеспечения — это появление в нем ошибки;
- Надежность программного обеспечения — есть вероятность его работы без отказов в течении определенного периода времени, рассчитанного с учетом стоимости для пользователя каждого отказа.
Из данных определений можно сделать важные выводы:
- Надежность программного обеспечения является не только внутренним свойством программы;
- Надежность программного обеспечения — это функция как самого ПО, так и ожиданий (действий) его пользователей.
Основными причинами ошибок программного обеспечения являются:
- большая сложность ПО, например, по сравнению с аппаратурой ЭВМ;
- неправильный перевод информации из одного представления в другое.
Список использованной литературы
- ГОСТ 27.002 – 89. Надежность в технике. Основные понятия. Термины и определения. // М.: Издательство стандартов, 1990.
- ГОСТ Р ИСО/МЭК 9126 – 93. Информационная технология. Оценка программной продукции. Характеристики качества и руководства по их применению. // М.: Издательство стандартов, 1994.
- ГОСТ 51901.5 – 2005. Менеджмент риска. Руководство по применению методов анализа надежности. // М.: Издательство стандартов, 2007.
- ГОСТ 28195 – 89. Оценка качества программных средств. Общие положения. // М.: Издательство стандартов, 1989.
- ГОСТ 27.310 – 95. Надежность в технике. Анализ видов, последствий и критичности отказов. // М.: Издательство стандартов, 1995.
- ГОСТ 51901.12 – 2007. Менеджмент риска. Метод анализа видов и последствий отказов. // М.: Издательство стандартов, 2007.
- Братчиков И.Л. «Синтаксис языков программирования» Наука, М.:Инси, 2005. — 344 с.
- Дейкстра Э. Заметки по структурному программированию.- М.:Дрофа, 2006, — 455 с.
- Ершов А.П. Введение в теоретическое программирование.- М.:РОСТО, 2008, — 288 с.
- Кнут Д. Искусство программирования для ЭВМ, т.1. М.: 2006, 735 с.
- Коган Д.И., Бабкина Т.С. «Основы теории конечных автоматов и регулярных языков. Учебное пособие» Издательство ННГУ, 2002. — 97 с.
- Липаев В. В. / Программная инженерия. Методологические основы. // М.: ТЕИС, 2006.
- Майерс Г. Надежность программного обеспечения.- М.:Дрофа, 2008, — 360 с.
- Рудаков А. В. Технология разработки программных продуктов. М.:Издательский центр «Академия», 2006. — 306 с.
- Тыугу, Э.Х. Концептуальное программирование. — М.: Наука, 2001, — 256 с.
- Хьюз Дж., Мичтом Дж. Структурный подход к программированию.-М.:Мир, 2000, — 278 с.

- Бухгалтерия предприятия (Обоснование выбора системы имитационного моделирования)
- Бухгалтерия предприятия
- Классификация ошибок в программном обеспечении
- Коммерческие банки, их виды и основные направления деятельности (Общая характеристика ОАО «Сбербанк России»)
- Формирование и использование финансовых ресурсов коммерческих организаций
- Анализ и оценка показателей оборотных активов.
- Управление рисками в проектной среде (Риск – менеджмент проектов)
- Программно-целевое управление в организации (регионе) и его эффективность
- СТАНДАРТЫ УПРАВЛЕНИЯ ПРОЕКТАМИ (Общие соображения по созданию стандарта. Специализация и детализация)
- Методы оценки эффективности финансово-кредитных институтов (Теоретические основы эффективности деятельности банка в рыночной экономике)
- Понятие денежной системы, генезис ее названия (Происхождение, сущность и виды денег)
- Налоговая система РФ и проблемы еe совершенствования (Принципы налогообложения)
На практике в реальных данных очень часто встречаются пропуски. Причинами могут быть ошибки ввода данных, сокрытие информации, фрод. Разбираем в статье, в каких случаях неправильная обработка пропусков простыми методами приведет к ошибкам в моделях и принятии решений.
Часто в данных, с которыми необходимо работать, присутствуют пропуски, в результате чего аналитик оказывается перед выбором: игнорировать, отбросить или же заполнить пропущенные значения. Заполнение пропусков зачастую и вполне обоснованно кажется более предпочтительным решением. Однако это не всегда так.
Неудачный выбор метода заполнения пропусков может не только не улучшить, но и сильно ухудшить результаты. В данной статье рассмотрены простые методы обработки пропусков, получившие широкое применение на практике, их преимущества и недостатки.
Исключение и игнорирование строк с пропущенными значениями стало решением по умолчанию в некоторых популярных прикладных пакетах, в результате чего у начинающих аналитиков может возникнуть представление, что данное решение — правильное. Кроме того, существуют довольно простые в реализации и использовании методы обработки пропусков, получившие название ad-hoc методы, простота которых может послужить причиной их выбора:
- заполнение пропусков нулями;
- заполнение медианой;
- заполнение средним арифметическим значением;
- введение индикаторных переменных и тому подобное.
Вероятно, именно из-за своей простоты ad-hoc методы широко использовались на заре развития современной теории обработки пропусков. И, хотя по состоянию на сегодняшний день известно, что применение этих методов может приводить к искажению статистических свойств выборки и, как следствие, к ухудшению результатов, получаемых после такой обработки пропусков [Horton, 2007], их по-прежнему часто используют.
Так, известны статьи, посвященные сбору и оценке статистики использования методов заполнения пропусков в научных работах медицинской тематики [Burton, 2004, Karahalios, 2012, Rezvan, 2015], из результатов которых можно сделать вывод, что даже ученые часто отдают предпочтение интуитивно-понятным ad-hoc методам и игнорированию/удалению строк, несмотря на то, что применение этих методов в контексте решаемой задачи порой неуместно.
Применение ad-hoc методов и удаление строк таит в себе множество подводных камней, о которых необходимо знать каждому аналитику. В данной статье мы кратко расскажем про эти методы и укажем на основные проблемы, связанные с их использованием на практике.
Механизмы формирования пропусков
Для того чтобы понять, как правильно обработать пропуски, необходимо определить механизмы их формирования. Различают следующие 3 механизма формирования пропусков: MCAR, MAR, MNAR:
- MCAR (Missing Completely At Random) — механизм формирования пропусков, при котором вероятность пропуска для каждой записи набора одинакова. Например, если проводился социологический опрос, в котором каждому десятому респонденту один случайно выбранный вопрос не задавался, причем на все остальные заданные вопросы респонденты отвечали, то имеет место механизм MCAR. В таком случае игнорирование/исключение записей, содержащих пропущенные данные, не ведет к искажению результатов.
- MAR (Missing At Random) — на практике данные обычно пропущены не случайно, а ввиду некоторых закономерностей. Пропуски относят к MAR, если вероятность пропуска может быть определена на основе другой имеющейся в наборе данных информации (пол, возраст, занимаемая должность, образование…), не содержащей пропуски. В таком случае удаление или замена пропусков на значение «Пропуск», как и в случае MCAR, не приведет к существенному искажению результатов.
- MNAR (Missing Not At Random) — механизм формирования пропусков, при котором данные отсутствуют в зависимости от неизвестных факторов. MNAR предполагает, что вероятность пропуска могла бы быть описана на основе других атрибутов, но информация по этим атрибутам в наборе данных отсутствует. Как следствие, вероятность пропуска невозможно выразить на основе информации, содержащейся в наборе данных.
Рассмотрим различия между механизмами MAR и MNAR на примере.
Люди, занимающие руководящие должности и/или получившие образование в престижном вузе чаще, чем другие респонденты, не отвечают на вопрос о своих доходах. Поскольку занимаемая должность и образование сильно коррелируют с доходами, то в таком случае пропуски в поле доходы уже нельзя считать совершенно случайными, то есть говорить о случае MCAR не представляется возможным.
Если в наборе данных есть информация об образовании и должности респондентов, то зависимость между повышенной вероятностью пропуска в графе доходов и этой информацией может быть выражена математически, следовательно, выполняется гипотеза MAR. В случае MAR исключение пропусков вполне приемлемо.
Однако если информация о занимаемой должности и образовании у нас отсутствует, то тогда имеет место случай MNAR. При MNAR просто игнорировать или исключить пропуски уже нельзя, так как это приведет к значительному искажению распределения статистических свойств выборки.
Рассмотрим простые методы обработки пропусков и связанные с ними проблемы.
Удаление/игнорирование пропусков
Complete-case Analysis (он же Listwise Deletion Method) — метод обработки пропусков, применяемый во множестве прикладных пакетов как метод по умолчанию. Заключается в исключении из набора данных записей/строк или атрибутов/колонок, содержащих пропуски.
В случае первого механизма пропусков (MCAR) применение данного метода не приведет к существенному искажению параметров модели. Однако удаление строк приводит к тому, что при дальнейших вычислениях используется не вся доступная информация, стандартные отклонения возрастают, полученные результаты становятся менее репрезентативными. В случаях, когда пропусков в данных много, это становится ощутимой проблемой.
Кроме того, в случае второго (MAR) и, особенно, третьего механизма пропусков (MNAR) смещение статистических свойств выборки, значений параметров построенных моделей и увеличение стандартных отклонений становятся еще сильнее.
Таким образом, несмотря на широкое распространение, применение данного метода для решения практических задач ограничено.
Available-case analysis (он же Pairwise Deletion) — методы обработки, основанные на игнорировании пропусков в расчетах. Эти методы, как и Complete-case Analysis, тоже часто применяются по умолчанию.
Статистические характеристики, такие как средние значения, стандартные отклонения, можно рассчитать, используя все непропущенные значения для каждого из атрибутов/столбцов. Как и в случае Complete-case Analysis, при условии выполнения гипотезы MCAR применение данного метода не приведет к существенному искажению параметров модели.
Преимущество данного подхода в том, что при построении модели используется вся доступная информация.
Главный же недостаток данных методов заключается в том, что они применимы для расчета далеко не всех показателей и, как правило, сопряжены с алгоритмическими и вычислительными сложностями, приводящими к некорректным результатам.
Например, рассчитанные значения коэффициентов корреляции могут оказаться вне диапазона [-1; 1]. Кроме того, не всегда удается однозначно ответить на вопрос об оптимальном выборе числа отсчетов, используемого при расчете стандартных отклонений.
Приведем пример, демонстрирующий проблемы методов Available-case analysis.
Рассмотрим следующую задачу: необходимо рассчитать линейный коэффициент корреляции (коэффициент корреляции Пирсона) между двумя факторами/переменными X и Y, истинные значения которых приведены в таблице 1.
Таблица 1 — Данные без пропусков
На основе таблицы 1 определим истинные значения статистических параметров.
- Среднее значение X = 10,8000.
- Среднее значение Y = -10,7768.
Оценка ковариации:
- sigma_{11} = sum X_i^2 / n — ( sum X_i / n)^2 = 37,7600,
- sigma_{12} = sum (X_i cdot Y_i) / n — ( sum X_i cdot sum Y_i)/ n^2 = -38,1691,
- sigma_{22} = sum Y_i^2 / n — ( sum Y_i / n)^2 = 42,6608,
- среднее значение X = 11,8889,
- среднее значение Y = -10,7768,
- sigma_{11} = 30,0988,
- sigma_{12} = -43,6174,
- sigma_{22} = 60,2952.
- Использование всего набора данных (репрезентативность выборки не страдает).
- Явное использование информации о пропущенных значениях.
- [Burton, 2004] — Burton A., Altman D. G. Missing covariate data within cancer prognostic studies: A review of current reporting and proposed guidelines. British Journal of Cancer, 2004, 91(1):4–8.
- Wa[Horton, 2007] — Horton N.J., Kleinman K.P. Much ado about nothing: A comparison of missing data methods and software to fit incomplete data regression models. Am. Stat. 2007; 61: pp 79–90.
- [Karahalios, 2012] — Karahalios A., Baglietto L., Carlin J.B., English D.R., Simpson J.A. A review of the reporting and handling of missing data in cohort studies with repeated assessment of exposure measures. BMC Med Res Methodology, 2012;12:96.
- [Knol, 2010] — Knol, M. J., Janssen, K. J. M., Donders, A. R. T., Egberts, A. C. G., Heerdink, E. R., Grobbee, D. E., Moons, K. G. M., and Geerlings, M. I. (2010). Unpredictable bias when using the missing indicator method or complete case analysis for missing confounder values: an empirical example. Journal of Clinical Epidemiology, 63: pp 728–736.
- [Miettinen, 1985] — Miettinen, O. S. Theoretical Epidemiology: Principles of Occurrence Research in Medicine. John Wiley & Sons, New York. 1985, p. 232.
- [Molenberghs, 2007] — Molenberghs, G. and Kenward, M. G. Missing Data in Clinical Studies. John Wiley & Sons, Chichester, UK. 2007 — pp. 47-50.
- [Rezvan, 2015] — Panteha Hayati Rezvan, Katherine J Lee, Julie A Simpson -The rise of multiple imputation: a review of the reporting and implementation of the method in medical research. BMC Medical Research Methodology, 15(30), pp 1–14.
- [Vach, 1991] — Vach, W. and Blettner, M. (1991). Biased estimation of the odds ratio in case-control studies due to the use of ad hoc methods of correcting for missing values for confounding variables. American Journal of Epidemiology, 134(8), pp 895–907.
- [Van Buuren, 2012] — Van Buuren S. Flexible Imputation of Missing Data. Chapman and Hall/CRC; 1 ed., 2012 — 342 p.
где n — число наблюдений (n=20).
Значение коэффициента корреляции:
r = sigma_{12}/ sqrt{sigma_{11} cdot sigma_{22}} = -0,9510
Рассмотрим результаты аналогичных расчетов при наличии пропусков в данных (данные представлены в таблице 2).
Таблица 2 – Данные с пропусками
То есть работаем с тем же набором данных (что и в таблице 1), с тем лишь отличием, что в данном случае нам неизвестны два первых значения переменной X.
В рамках Available-case analysis подхода мы считаем среднее значение, используя всю доступную информацию, то есть для переменной X на основе 18 известных значений, а для переменной Y на основе всех 20 значений.
Таким образом, на основе таблицы 2 получим следующие результаты:
Оценка ковариации:
В расчетах использовалось n наблюдений, для которых известны как значения X, так и Y (n=18).
Значение коэффициента корреляции:
r = -1,0239.
Таким образом, расчет среднего значения на основе подхода Available-case Analysis привел к смещению данного значения, что, в свою очередь, проявилось в рассчитанном значении коэффициента корреляции, меньшем -1. Таким образом, рассчитанное значение вышло за пределы теоретически возможного диапазона [-1; 1], что противоречит физическому смыслу.
Если же рассчитать значение коэффициента корреляции в рамках подхода Complete-case Analysis, то получим значение коэффициента корреляции -0,9311.
Когда гипотеза MCAR не выполняется, методы Available-case analysis, так же, как и методы Complete-case Analysis, приводят к существенным искажениям статистических свойств выборки (среднего значения, медианы, вариации, корреляции…).
К недостаткам первых двух методов обработки пропусков (Complete-case Analysis и Available-case analysis) относится и то, что далеко не всегда исключение строк в принципе приемлемо. Нередко процедуры последующей обработки данных предполагают, что все строки и колонки участвуют в расчетах (например, когда пропусков в каждой колонке не очень много, но при этом строк, в которых нет ни одного пропущенного поля, мало).
Далее в данной статье мы рассмотрим методы, которые предполагают заполнение пропусков на основе имеющейся информации. Часто эти методы объединяют в одну группу, называемую Single-imputation methods.
Заполнение пропуска средним значением
Заполнение пропуска средним значением (Mean Substitution) (другие варианты: заполнение нулем, медианой и тому подобные) — название метода говорит само за себя.
Всем вариантам данного метода свойственны одни и те же недостатки. Рассмотрим эти недостатки на примере одного из наиболее простых способов заполнить пропуски непрерывной характеристики: заполнения пропусков средним арифметическим значением и модой.
Пример 1. На рисунке 1 показано распределение значений непрерывной характеристики до заполнения пропусков средним значением и после него.

Рисунок 1a — Распределение значений непрерывной характеристики до заполнения пропусков

Рисунок 1б — Распределение значений непрерывной характеристики после заполнения пропусков
На рисунке 1 хорошо видно, что распределение после заполнения пропусков выглядит крайне неестественно. Это в итоге проявляется в искажении всех показателей, характеризующих свойства распределения (кроме среднего значения), заниженной корреляции и завышенной оценке стандартных отклонений.
Таким образом, данный метод приводит к существенному искажению распределения характеристики даже в случае MCAR.
Пример 2. В случае категориальной дискретной характеристики наиболее часто используется заполнение модой.
На рисунке 2 показано распределение категориальной характеристики до и после заполнения пропусков.

Рисунок 2а — Распределение дискретной характеристики до заполнения пропусков модой

Рисунок 2б — Распределение дискретной характеристики после заполнения пропусков модой
Таким образом, при заполнении пропусков категориальной характеристики модой проявляются те же недостатки, что и при заполнении пропусков непрерывной характеристики средним арифметическим (нулем, медианой и тому подобным).
Повторение результата последнего наблюдения
LOCF (Last observation carried forward) — повторение результата последнего наблюдения. Данный метод применяется, как правило, при заполнении пропусков во временных рядах, когда последующие значения априори сильно взаимосвязаны с предыдущими.
Рассмотрим 2 случая, когда применение LOCF обосновано.
Случай 1. Если мы измеряем температуру воздуха в некоторой географической точке на открытом пространстве, причем измерения проводятся каждую минуту, то при нормальных условиях — если исключить природные катаклизмы — измеряемая величина априори не может резко (на 10–20 °C) измениться за столь короткий интервал времени между последующими измерениями. Следовательно, заполнение пропусков предшествующим известным значением в такой ситуации обоснованно.
Случай 2. Если данные представляют собой результаты измерения (допустим, той же температуры воздуха) в один и тот же момент времени в близких географических точках таким образом, что гипотеза о малых изменениях значений от одной точки набора данных до другой остается справедливой, то опять же использование LOCF логично.
Ситуации, когда использование LOCF обосновано, не ограничиваются только этими двумя случаями.
Хотя в описанных выше ситуациях метод логичен и обоснован, он тоже может привести к существенным искажениям статистических свойств даже в случае MCAR [Molenberghs, 2007]. Так, возможна ситуация, когда применение LOCF приведет к дублированию выброса (заполнению пропусков аномальным значением). Кроме того, если в данных много последовательно пропущенных значений, то гипотеза о небольших изменениях уже не выполняется и, как следствие, использование LOCF приводит к неправильным результатам.
Indicator Method
Indicator Method — метод, предполагающий замену пропущенных значений нулями и добавление специального атрибута-индикатора, принимающего нулевые значения для записей, где данные изначально не содержали пропусков, и ненулевые значения там, где ранее были пропуски [Miettinen, 1985].
Проще и нагляднее продемонстрировать данный метод на примере.
Пример. В таблице 3 приведены данные до заполнения пропусков.
Таблица 3 — Данные до заполнения пропусков
Знаком ? обозначены пропуски в наборе данных.
В таблице 4 приведены данные после заполнения пропусков.
Таблица 4 —Таблица после заполнения пропусков
На практике применяются и модификации этого метода, предполагающие заполнение пропусков ненулевыми значениями. Стоит отметить, что при таком заполнении (например, средним) допустимо использование инверсных значений поля флагов (то есть 0 — для случая, когда в исходных данных значения изначально были пропущены, и ненулевое значение для случаев, когда значение поля исходных данных было известно).
Также при заполнении пропусков ненулевыми значениями часто добавляется взаимодействие поля-флага и исходного поля.
К преимуществам данного метода относятся:
Несмотря на эти преимущества, даже при выполнении гипотезы MCAR и небольшом числе пропущенных значений данный метод может привести к существенному искажению результатов [Vach, 1991, Knol, 2010].
Восстановление пропусков на основе регрессионных моделей
Данный метод заключается в том, что пропущенные значения заполняются с помощью модели линейной регрессии, построенной на известных значениях набора данных.
На рисунке 3 показан пример результатов заполнения пропущенных значений характеристики 1 на основе известных значений характеристики 2.

Рисунок 3 — Заполнение пропусков на основе линейной регрессии
Метод линейной регрессии позволяет получить правдоподобно заполненные данные. Однако реальным данным свойственен некоторый разброс значений, который при заполнении пропусков на основе линейной регрессии отсутствует. Как следствие, вариация значений характеристики становится меньше, а корреляция между характеристикой 2 и характеристикой 1 искусственно усиливается. В результате данный метод заполнения пропусков становится тем хуже, чем выше вариация значений характеристики, пропуски в которой мы заполняем, и чем выше процент пропущенных строк.
Стоит отметить, что есть метод, решающий эту проблему: метод стохастической линейной регрессии, проиллюстрированный на рисунке 4 (аналогично рисунку 3).

Рисунок 4 — заполнение пропусков на основе стохастической линейной регрессии
Модель стохастической линейной регрессии отражает не только линейную зависимость между характеристиками, но и отклонения от этой линейной зависимости. Этот метод обладает положительными свойствами заполнения пропусков на основе линейной регрессии и, кроме того, не так сильно искажает значения коэффициентов корреляции.
Из всех методов, которые мы рассмотрели в данной части статьи, заполнение пропусков с помощью стохастической линейной регрессии в общем случае приводит к наименьшим искажениям статистических свойств выборки. А в случае когда между характеристиками прослеживаются явно выраженные линейные зависимости, метод стохастической линейной регрессии нередко превосходит даже более сложные методы.
Подводя итоги
В представленной статье мы рассмотрели простые методы заполнения пропусков. Хотя применение этих методов может приводить к существенному искажению статистических свойств набора данных (среднее значение, медиана, вариация, корреляция…) даже в случае MCAR, они остаются часто используемыми не только среди обычных пользователей, но и в научной среде (как минимум в областях, связанных с медициной).
Так, согласно [Burton, 2004], из 100 работ, посвященных проблеме раковых заболеваний, которые были опубликованы в 2002 году, в 82% случаев авторы указали, что столкнулись с необходимостью заполнения пропусков в данных. При этом в 32 случаях был явно указан метод заполнения пропусков. В 12 из этих 32 работ использовался Complete Case Analysis, еще в 12 — Available Case Analysis, в 4 — Indicator Method, в 3— ad-hoc методы, и только в 1 случае использовался более сложный метод.
Спустя десятилетие ситуация не сильно изменилась к лучшему. [Karahalios, 2012] пишут, что среди рассмотренных ими научных трудов в 54% случаев (в 21 статье) использовался Complete Case Analysis, в 7 случаях – LOCF, в 3 случаях – заполнение средним значением, в 1 случае — Indicator Method.
И даже по состоянию на 2014 год рекомендуемые к использованию методы заполнения пропусков (Multiple Imputation, методы функции максимального правдоподобия) в научных статьях медицинской тематики по-прежнему применяются редко [Rezvan, 2015].
В качестве заключения хотелось бы отметить, что использование простых методов, таких как удаление строк или применение ad-hoc методов, не всегда приводит к ухудшению результатов. Более того, когда это уместно, использование простых методов более предпочтительно.
Литература
Другие материалы по теме:
Loginom Data Quality. Очистка клиентских данных. Деморолик
Как найти и объединить дубли клиентов
-
Помощь студентам
-
Онлайн тесты
-
Информатика
-
Тесты с ответами по предмету — Информационные технологии в управлении
Тест по теме «Тесты с ответами по предмету — Информационные технологии в управлении»
-

Обновлено: 18.03.2021
-

466 936
77 вопросов
Выполним любые типы работ
- Дипломные работы
- Курсовые работы
- Рефераты
- Контрольные работы
- Отчет по практике
- Эссе
Популярные тесты по информатике

Информатика
Тесты с ответами по предмету — Информационные технологии в управлении
![]()
18.03.2021
![]()
466 937
![]()
77
Информатика
Тесты с ответами по предмету — Основы информационной безопасности
![]()
26.03.2021
![]()
210 499
![]()
51
Информатика
Тесты с ответами по предмету — Информатика
![]()
04.05.2021
![]()
145 153
![]()
35
Информатика
Тесты с ответами по предмету — Базы данных
![]()
07.05.2021
![]()
129 598
![]()
27
Информатика
Тесты с ответами по теме — Windows
![]()
11.04.2021
![]()
73 622
![]()
35
Информатика
Тесты с ответами по предмету — Компьютерные технологии
![]()
17.04.2021
![]()
73 490
![]()
178
Информатика
Информатика. Тест по теме Текстовый редактор MS Word
![]()
17.08.2021
![]()
34 604
![]()
44
Информатика
Тесты текущего контроля по дисциплине «Теория систем и системный анализ»
![]()
18.03.2021
![]()
32 208
![]()
14
Информатика
Информатика. Тест по теме Табличный процессор MS Excel
![]()
17.08.2021
![]()
19 413
![]()
38
Мы поможем сдать на отлично и без пересдач
-
Контрольная работа
от 1 дня
/от 100 руб
-
Курсовая работа
от 5 дней
/от 1800 руб
-
Дипломная работа
от 7 дней
/от 7950 руб
-
Реферат
от 1 дня
/от 700 руб
-
Онлайн-помощь
от 1 дня
/от 300 руб
Нужна помощь с тестами?
Оставляй заявку — и мы пройдем все тесты за тебя!