history 23 ноября 2016 г.
- Группы статей
- Статистический вывод
Дадим определение терминам уровень надежности и уровень значимости. Покажем, как и где они используется в MS EXCEL .
СОВЕТ : Для понимания терминов Уровень значимости и Уровень надежности потребуется знание следующих понятий:
Уровень значимости статистического теста – это вероятность отклонить нулевую гипотезу , когда на самом деле она верна. Другими словами, это допустимая для данной задачи вероятность ошибки первого рода (type I error).
Уровень значимости обычно обозначают греческой буквой α ( альфа ). Чаще всего для уровня значимости используют значения 0,001; 0,01; 0,05; 0,10.
Например, при построении доверительного интервала для оценки среднего значения распределения , его ширину рассчитывают таким образом, чтобы вероятность события « выборочное среднее (Х ср ) находится за пределами доверительного интервала » было равно уровню значимости . Реализация этого события считается маловероятным (практически невозможным) и служит основанием для отклонения нулевой гипотезы о равенстве среднего заданному значению .
Ошибка первого рода часто называется риском производителя. Это осознанный риск, на который идет производитель продукции, т.к. он определяет вероятность того, что годная продукция может быть забракована, хотя на самом деле она таковой не является. Величина ошибки первого рода задается перед проверкой гипотезы , таким образом, она контролируется исследователем напрямую и может быть задана в соответствии с условиями решаемой задачи.
Чрезмерное уменьшение уровня значимости α (т.е. вероятности ошибки первого рода ) может привести к увеличению вероятности ошибки второго рода , то есть вероятности принять нулевую гипотезу , когда на самом деле она не верна. Подробнее об ошибке второго рода см. статью Ошибка второго рода и Кривая оперативной характеристики .
Уровень значимости обычно указывается в аргументах обратных функций MS EXCEL для вычисления квантилей соответствующего распределения: НОРМ.СТ.ОБР() , ХИ2.ОБР() , СТЬЮДЕНТ.ОБР() и др. Примеры использования этих функций приведены в статьях про проверку гипотез и про построение доверительных интервалов .
Уровень надежности
Уровень доверия (этот термин более распространен в отечественной литературе, чем Уровень надежности ) — означает вероятность того, что доверительный интервал содержит истинное значение оцениваемого параметра распределения.
Уровень доверия равен 1-α, где α – уровень значимости .
Термин Уровень надежности имеет синонимы: уровень доверия, коэффициент доверия, доверительный уровень и доверительная вероятность (англ. Confidence Level , Confidence Coefficient ).
В математической статистике обычно используют значения уровня доверия 90%; 95%; 99%, реже 99,9% и т.д.
Например, Уровень доверия 95% означает, что событие, вероятность которого 1-0,95=5% исследователь считать маловероятным или невозможным. Разумеется, выбор уровня доверия полностью зависит от исследователя. Так, степень доверия авиапассажира к надежности самолета, несомненно, должна быть выше степени доверия покупателя к надежности электрической лампочки.
Примечание : Стоит отметить, что математически не корректно говорить, что Уровень доверия является вероятностью, того что оцениваемый параметр распределения принадлежит доверительному интервалу , вычисленному на основе выборки . Поскольку, считается, что в математической статистике отсутствуют априорные сведения о параметре распределения. Математически правильно говорить, что доверительный интервал , с вероятностью равной Уровню доверия, накроет истинное значение оцениваемого параметра распределения.
Уровень надежности в MS EXCEL
В MS EXCEL Уровень надежности упоминается в надстройке Пакет анализа . После вызова надстройки, в диалоговом окне необходимо выбрать инструмент Описательная статистика . 
После нажатия кнопки ОК будет выведено другое диалоговое окно. 
В этом окне задается Уровень надежности, т.е.значениевероятности в процентах. После нажатия кнопки ОК в выходном интервале выводится значение равное половине ширины доверительного интервала . Этот доверительный интервал используется для оценки среднего значения распределения, когда дисперсия не известна (подробнее см. статью про доверительный интервал ).
Необходимо учитывать, что данный доверительный интервал рассчитывается при условии, что выборка берется из нормального распределения . Но, на практике обычно принимается, что при достаточно большой выборке (n>30), доверительный интервал будет построен приблизительно правильно и для распределения, не являющегося нормальным (если при этом это распределение не будет иметь сильной асимметрии ).
Примечание : Понять, что в диалоговом окне речь идет именно об оценке среднего значения распределения , достаточно сложно. Хотя в английской версии диалогового окна это указано прямо: Confidence Level for Mean .
Если Уровень надежности задан 95%, то надстройка Пакет анализа использует следующую формулу (выводится не сама формула, а лишь ее результат):
или эквивалентную ей
где =СТАНДОТКЛОН.В(Выборка)/КОРЕНЬ(СЧЁТ(Выборка)) – является стандартной ошибкой среднего (формулы приведены в файле примера ).
=ДОВЕРИТ.СТЬЮДЕНТ(1-0,95; СТАНДОТКЛОН.В(Выборка); СЧЁТ(Выборка))
Решение задач описательной статистики средствами пакета анализа Microsoft Excel Текст научной статьи по специальности « Компьютерные и информационные науки»
CC BY
Аннотация научной статьи по компьютерным и информационным наукам, автор научной работы — Трущелёв Сергей Андреевич
Представлено определение описательной статистики , изложены методика вычисления основных ее показателей, а также пошаговая процедура статистического анализа. Сообщение содержит обучающий компонент.
Похожие темы научных работ по компьютерным и информационным наукам , автор научной работы — Трущелёв Сергей Андреевич
Descriptive statistics using the Data Analysis Toolpak in Microsoft Excel
The paper presents a definition of descriptive statistics , and its main indicators. The necessity of their calculation is set out step by step in the procedure of statistical analysis. The message is a training component with.
Текст научной работы на тему «Решение задач описательной статистики средствами пакета анализа Microsoft Excel»
МЕТОДОЛОГИЯ НАУЧНО-ИССЛЕДОВАТЕЛЬСКОЙ ДЕЯТЕЛЬНОСТИ
Уважаемые читатели, коллеги!
В связи с возрастающими требованиями к качеству публикаций результатов научно-исследовательских работ в «Российском психиатрическом журнале» открыта новая рубрика «Методология научно-исследовательской деятельности». Планируется публикация обучающих и информационно-разъяснительных материалов по разным разделам науковедения, организации научной работы, биоинформатике, биостатистике, биоэтике и т.д. Приглашаем ученых и исследователей поделиться опытом в этой области. Надеемся, что наша инициатива будет поддержана не только в научном сообществе, но и воспринята в среде практикующих специалистов.
© С.А. Трущелёв, 2013 Для корреспонденции
УДК 311:004 Трущелёв Сергей Андреевич — кандидат медицинских наук,
доцент, ведущий научный сотрудник ФГБУ «Московский научно-исследовательский институт психиатрии Минздрава России»
Адрес: 107076, г. Москва, ул. Потешная, д. 3 Телефон: (495) 963-25-31 E-mail: sat-geo@mail.ru
Решение задач описательной статистики средствами пакета анализа Microsoft Excel
Descriptive statistics using the Data Analysis Toolpak in Microsoft Excel
The paper presents a definition of descriptive statistics, and its main indicators. The necessity of their calculation is set out step by step in the procedure of statistical analysis. The message is a training component with. Key words: science of science, biostatistics, descriptive statistics, data analysis toolpak, Excel
ФГБУ «Московский научно-исследовательский институт психиатрии Минздрава России»
Moscow Research Institute of Psychiatry
Представлено определение описательной статистики, изложены методика вычисления основных ее показателей, а также пошаговая процедура статистического анализа. Сообщение содержит обучающий компонент.
Ключевые слова: науковедение, биостатистика, описательная статистика, пакет анализа, Excel
Каждое явление (предмет исследования) определяется многими факторами. В научном исследовании полностью учесть все факторы и обеспечить их стабильность удается редко. Следовательно, явление, определяемое этими факторами, не поддается точному предсказанию — оно приобретает вероятностные черты, т.е. ведет себя случайным образом. Этому подвержены многие явления, поэтому они определяются случайной величиной, которая принимает в результате опыта или наблюдения одно из множества значений. Случайные величины могут быть дискретными (прерывными) и непрерывными. Немаловажно их распределение — правило, которое устанавливает связь между значениями случайной величины и вероятностями (частотами) их появления.
Наглядное представление о распределении случайных величин дает разброс песчинок, образующих кучу при высыпании (рассеивании) из некоторого точечного источника. Его проекция является параметром положения и соответствует математическому ожиданию распределения, если куча симметрична. Разброс песчинок (параметр рассеяния) характеризуется радиусом кучи на высоте примерно 2/3. Такой параметр рассеяния соответствует так называемому стандартному (среднеквадратичному) отклонению случайных величин в распределении. Горизонтальные расстояния песчинок от проекции источника (математического ожидания) моделируют рассеяние случайной величины. Поверхность кучи (ее высоты) соответствует частоте случайных величин на разных расстояниях от центра. Вершина кучи, расположенная под источником, отвечает максимуму частоты. На периферии высота кучи уменьшается до нуля, что соответствует уменьшению частот больших отклонений от центра рассеяния. Статистическая обработка совокупности данных состоит в некоторых осредняющих вычислительных процедурах, погашающих сугубо индивидуальные особенности — отклонения от общей закономерности и подчеркивающих типичные (популяцион-ные) свойства явления в целом. Начальный раздел математической статистики — описательная статистика — занимается характеристикой (описанием) картины случайного рассеяния по совокупности данных. В соответствии с законом распределения данных решаются вопросы выбора и вычислений надлежащих показателей. Описательная статистика включает методы организации, суммирования и описания данных. Дескриптивные (от англ. descriptive — описательный) показатели позволяют быстро обобщать данные. К описательным методам относят частотные распределения, меры централь-
ной тенденции и меры относительного положения [4, с. 95].
К основным показателям описательной статистики относятся среднее значение (среднее арифметическое, медиана, мода), усредненное значение, разброс (диапазон разброса данных), дисперсия, стандартное среднеквадратное отклонение (СКО), квартили, доверительный интервал [2, с. 28].
Статистическая обработка результатов исследований и получение показателей описательной статистики в недалеком прошлом обычно занимали много времени, однако с внедрением средств компьютерной техники многое изменилось — вычислительные процессы стали происходить очень быстро. Для проведения статистических расчетов в электронной таблице Microsoft Excel имеется пакет анализа. Надстройка «Анализ данных» располагается во вкладке «Данные», в крайне правом блоке ленты (рис. 1).
Для демонстрации вычислений будем использовать гипотетический набор данных. Далее приведем пошаговую инструкцию по созданию описательной статистики признака (показателя систолического давления), измеренного до лечения и после него, в группе наблюдения (n=60).
Для проведения вычисления обратитесь к ленте: Данные ^ Анализ данных ^ Описательная статистика ^ ОК. Затем, перейдя в окно инструмента, выберите входной интервал, группирование (по столбцам), поставьте галочку, если в первой строке выделены метки; в параметрах вывода на поле электронной страницы выберите ячейку вывода результатов, установите галочку рядом с итоговой статистикой. Потом нажмите кнопку ОК. После этого вы получите результаты описательной статистики выбранных признаков (рис. 2 и 3).
[й1 A «ï- V m И^ЭгшИ Главная Ш I» 1 Описательная статистика — Microsoft Excel □ 0 й Вставка Разметка страницы Формулы Данные Рецензирование Вид Разработчик Надстройки MetaXL Л □ S3
П внец m 1олучение jних данныхт ч [^Подключения ^Свойства Обновить все т && Изменить связи Подключения A I AIЯ I Я + Я 1А1 Я| Сортировка Со pi ч Ш ^ Очистить ^ Повторить Фильтр ™ № Дополнительно ировка и фильтр S Ii ы» вш а в Текст по Удалить ,—, столбцам дубликаты » Работа сданными Ф Фор» орма Jbi ssprfa ф ^ ^Анализданных Поиск решения Стр^И^ра Анализ
А в с D Е F G У 1 J К 1 L _
1 Номер_исс Признак_1 Признак_2 у
3 2 178 143 Анализ данным lia
Инструменты анализа У _ 1 о, 1
4 3 320 188 Двухфакторный дисперсионный^нализ без повторений Корреляция Л* 3 J d Отмена |
6 5 159 161 Экспоненциальное сглаживание Двухвыборочный Р-тест для дисперсии Анализ Фурье Гистограмма Скользящее среднее 1 Генерация случайных чисел_| Справка
Рис. 1. Пошаговый выбор инструмента анализа данных
Рис. 2. Окно инструмента описательной статистики
Среднее (арифметическое; М; х ) — одна из наиболее распространенных мер центральной тенденции, представляющая собой сумму всех значений, деленную на их количество. Если значения интересующего нас признака у большинства объектов близки к их среднему и с равной вероятностью отклоняются от него в большую или меньшую сторону, лучшими характеристиками совокупности будут само среднее значение и стандартное отклонение. Напротив, когда значения признака распределены несимметрично относительно среднего, совокупность лучше описать с помощью медианы и процен-тилей [1, с. 27].
Стандартная ошибка (т) — показатель надежности расчетного параметра; стандартное отклонение оценок, которые будут получены при многократной случайной выборке данного размера из одной и той же совокупности. Стандартная ошибка — это убывающая функция объема выборки: чем меньше стандартная ошибка, тем более достоверной является оценка параметра. Весьма часто для описания непрерывных количественных данных используют стандартную ошибку, которая (в отличие от СКО) является не характеристикой, описывающей распределение наблюдений исследуемой выборки по области значений, а только мерой точности оценки популяционного среднего и, следовательно, не характеризует дисперсию (разброс) в анализируемой выборке. Однако часто именно стандартную ошибку среднего приводят в качестве параметра описательной статистики, пытаясь продемонстрировать тем самым малую вариабельность своих данных, так как всегда (по определению) т Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
60 Среднее 161,77 Среднее 134,03
61 Стандартная ошибка 12,46 Стандартная ошибка 6.59
62 Медиана 167 Медиана 121,5
63 Мода 72 Мода 141
64 Стандартное отклонение 96.54 Стандартное отклонение 51,03
65 Дисперсия выборки 9320.59 Дисперсия выборки 2604.34
66 Эксцесс 0.89 Эксцесс 2.75
67 Асимметричность 0.96 Асимметричность 1,43
68 Интервал 420 Интервал 254
69 Минимум 50 Минимум 55
70 Максимум 470 Максимум 309
71 Сумма 9706 Сумма 8042
72 Счет 60 Счет 60
73 74 Уровень надежности(95.0%) 24.94 Уровень надежности(95.0%) 13,18
Коэффициент вариации 60% Коэффициент вариации 38%
Рис. 3. Результаты описательной статистики двух признаков
Медиану и интерквартильный размах рекомендуется применять для описания распределения, не являющегося нормальным (а это большинство распределений медико-биологических параметров) [1, с. 34]. Интерквартильный размах указывают в виде процентилей. Рекомендуется указывать уровни 25 и 75%, которые соответствуют верхней границе 1-го и нижней границе 4-го квартилей. Пример описания: Me (25%; 75%) = 60 (23; 78).
Мода (Мо) — значение, которое встречается наиболее часто во множестве. Иногда в совокупности встречается более одной моды. Тогда говорят, что совокупность мультимодальна — свидетельство того, что набор данных не подчиняется нормальному распределению. Мода как средняя величина употребляется чаще для данных, имеющих нечисловую природу. Например, в группе пациентов наибольшая частота тяжести болезни будет равна моде. При экспертной оценке с помощью этого показателя определяют предпочтения участников исследования. Недостаток — показатель не учитывает поведение распределения в других точках.
Стандартное отклонение (синонимы: среднеквадратичное отклонение, квадратичное отклонение; стандартный разброс; СКО; в; о) — в теории вероятностей и статистике наиболее распространенный показатель рассеивания значений случайной величины относительно ее математического ожидания. Измеряется в единицах случайной величины. Равно корню квадратному из дисперсии случайной величины. Стандартное отклонение используют при расчете стандартной ошибки среднего арифметического, построении доверительных интервалов, статистической проверке гипотез, измерении линейной взаимосвязи между случайными величинами. Большое значение СО показывает большой разброс значений в представленном множестве со средней величиной множества; маленькое значение, соответственно, показывает, что значения во множестве сгруппированы вокруг среднего. Если среднее значение измерений сильно отличается от предсказанных теорией значений (большое значение среднеквадратичного отклонения), то полученные значения или метод их получения следует перепроверить.
Дисперсия (D; о2) — мера разброса случайной величины, т.е. ее отклонения от математического ожидания. Квадратный корень из дисперсии называется стандартным отклонением. Дисперсия измеряется в квадратах единицы измерения. Однако в самостоятельном виде (как, например, средняя арифметическая) дисперсия используется редко. Это скорее вспомогательный и промежуточный показатель, который применяют в других методах статистического анализа.
Эксцесс — скалярная характеристика островершинности графика плотности вероятности унимо-
дального распределения, которую используют в качестве некоторой меры отклонения рассматриваемого распределения от нормального. Если коэффициент эксцесса равен нулю или близок к нему, то плотность вероятности распределения имеет нормальный эксцесс. Если коэффициент эксцесса сильно больше нуля, то плотность вероятности имеет положительный эксцесс. Это, как правило, соответствует тому, что график плотности рассматриваемого распределения в окрестности моды имеет более острую и более высокую вершину, чем нормальная кривая. Когда коэффициент эксцесса сильно больше нуля, говорят об отрицательном эксцессе плотности, при этом плотность вероятности имеет в окрестности моды более низкую и плоскую вершину, чем плотность нормального закона. Для генеральных совокупностей больших объемов его малыми значениями можно пренебречь.
Асимметричность (коэффициент асимметрии или скоса) — величина, характеризующая асимметрию распределения данной случайной величины. Коэффициент асимметрии положителен, если правый хвост распределения длиннее левого, и отрицателен в альтернативном случае. Если распределение симметрично относительно математического ожидания, то его коэффициент асимметрии равен нулю.
Интервал — размах показателей, т.е. разность между максимумом и минимумом значений вариант.
Максимум — наибольшее значение вариант.
Минимум — наименьшее значение вариант.
Сумма — сумма значений вариант.
Счет — количество вариант.
Уровень надежности — свойство объекта сохранять в установленных пределах значения всех параметров. Показывает величину доверительного интервала для математического ожидания согласно заданному уровню надежности или доверия. По умолчанию уровень надежности принят равным 95%.
Коэффициент вариации случайной величины -мера относительного разброса случайной величины. Показывает, какую долю среднего значения этой величины составляет ее средний разброс. Исчисляется в процентах. Вычисляется только для количественных данных. В отличие от стандартного отклонения, он измеряет не абсолютную, а относительную меру разброса значений признака в статистической совокупности. В Excel нет готовой функции для расчета коэффициента вариации. Расчет можно провести простым делением стандартного отклонения на среднее значение. Эти значения имеются в таблице описательной статистики. Для вычисления этого важного показателя в ячейке ниже надписи Уровень надежности пишем Коэффициент вариации, затем в ячейке справа делаем запись: =G64/G60. То же необходимо по-
вторить для вычисления коэффициента вариации для другого измерения.
Коэффициент вариации обычно выражается в процентах, поэтому ячейку с формулой можно обрамить процентным форматом. Нужная кнопка находится на панели инструментов в закладке «Главная». Коэффициент вариации, в отличие от других показателей разброса значений, используется как самостоятельный и весьма информативный индикатор вариации данных. В статистике принято считать, что совокупность данных является однородной, если коэффициент вариации менее 33%, неоднородной — если более 33%. Эта информация может быть полезна для предварительного описания данных и определения возможностей проведения дальнейшего анализа. Кроме того, коэффициент вариации, измеряемый в процентах, позволяет сравнивать степень разброса различных данных независимо от их масштаба и единиц измерений.
Анализ показателей описательной статистики
При сравнении значений среднего, медианы, моды в каждом измерении следует отметить, что эти показатели сильно отличаются друг от друга.
Коэффициенты эксцесса и асимметрии значимо отличаются от установленных границ, коэффициенты вариации больше критического (предельного) значения. Следовательно, распределение данных в обеих группах измерений отлично от нормального. В последующем необходимо применять непараметрические методы статистического анализа. Для быстрой сравнительной оценки можно использовать показатели доверительных интервалов.
Для представления результатов сравнения обычно используют формат в виде М (95% ДИ) — значение среднего и указание 95% доверительного интервала. В тексте публикации запись может выглядеть следующим образом: Средний уровень систолического давления в группе пациентов до лечения составил 161,77 мм рт. ст. (95% ДИ от 136,83 до 186,71 мм рт. ст.), после лечения -134,03 мм рт. ст. (95% ДИ от 120,85 до 147,21 мм рт. ст.). Указанные доверительные интервалы имеют зону совмещения, следовательно, существенного различия в изменении признака нет. Исходя из этого с большой долей вероятности можно утверждать, что для данной группы пациентов лекарственный препарат, примененный для снижения уровня систолического артериального давления, был не эффективен.
1. Гланц С. Медико-биологическая статистика / Пер. с англ. -М., Практика, 1998. — 459 с.
2. Ланг Т.А., Сесик М. Как описывать статистику в медицине. Аннотированное руководство для авторов, редакторов и рецензентов / Пер. с англ. под ред. В.П. Леонова. -М.: Практическая медицина, 2011. — 480 с.
3. Леонов В.П. Ошибки статистического анализа биомедицинских данных // Междунар. журн. мед. практики. — 2007. -№ 2. — С. 19-35.
4. Трущелев С.А. Медицинская диссертация: руководство: 3-е изд. / Под ред. проф. И.Н. Денисова. — М.: ГЭОТАР-Медиа, 2009. — 416 с.
Стандартная ошибка оценки по уравнению регрессии
Стандартная ошибка оценки, также известная как стандартная ошибка уравнения регрессии, определяется следующим образом (см. (6.23)) [c.280]
Стандартная ошибка уравнения регрессии, Эта статистика SEE представляет собой стандартное отклонение фактических значений теоретических значений У. [c.650]
Что такое стандартная ошибка уравнения регрессии ).Какие допущения лежат в основе парной регрессии 10. Что такое множественная регрессия [c.679]
Следующий этап корреляционного анализа — расчет уравнения связи (регрессии). Решение проводится обычно шаговым способом. Сначала в расчет принимается один фактор, который оказывает наиболее значимое влияние на результативный показатель, потом второй, третий и т.д. И на каждом шаге рассчитываются уравнение связи, множественный коэффициент корреляции и детерминации, /»»-отношение (критерий Фишера), стандартная ошибка и другие показатели, с помощью которых оценивается надежность уравнения связи. Величина их на каждом шаге сравнивается с предыдущей. Чем выше величина коэффициентов множественной корреляции, детерминации и критерия Фишера и чем ниже величина стандартной ошибки, тем точнее уравнение связи описывает зависимости, сложившиеся между исследуемыми показателями. Если добавление следующих факторов не улучшает оценочных показателей связи, то надо их отбросить, т.е. остановиться на том уравнении, где эти показатели наиболее оптимальны. [c.149]
Прогнозное значение ур определяется путем подстановки в уравнение регрессии ух =а + Ьх соответствующего (прогнозного) значения хр. Вычисляется средняя стандартная ошибка прогноза [c.9]
В линейной регрессии обычно оценивается значимость не только уравнения в целом, но и отдельных его параметров. С этой целью по каждому из параметров определяется его стандартная ошибка ть и та. [c.53]
В прогнозных расчетах по уравнению регрессии определяется предсказываемое (ур) значение как точечный прогноз ух при хр =хь т. е. путем подстановки в уравнение регрессии 5 = а + b х соответствующего значения х. Однако точечный прогноз явно не реален. Поэтому он дополняется расчетом стандартной ошибки ух, т. е. Шух, и соответственно интервальной оценкой прогнозного значения (у ) [c.57]
Чтобы понять, как строится формула для определения величин стандартной ошибки ух, обратимся к уравнению линейной регрессии ух = а + b х. Подставим в это уравнение выражение параметра а [c.57]
При прогнозировании на основе уравнения регрессии следует помнить, что величина прогноза зависит не только от стандартной ошибки индивидуального значения у, но и от точности прогноза значения фактора х. Его величина может задаваться на основе анализа других моделей исходя из конкретной ситуации, а также из анализа динамики данного фактора. [c.61]
В скобках указаны стандартные ошибки параметров уравнения регрессии. [c.327]
В скобках указаны стандартные ошибки параметров уравнения регрессии. Определим по этому уравнению расчетные значения >>, ,, а затем параметры уравнения регрессии (7.44). Получим следующие результаты [c.328]
На каждом шаге рассматриваются уравнение регрессии, коэффициенты корреляции и детерминации, F-критерий, стандартная ошибка оценки и другие оценочные показатели. После каждого шага перечисленные оценочные показатели сравниваются с [c.39]
Проблемы с методологией регрессии. Методология регрессии — это традиционный способ уплотнения больших массивов данных и их сведения в одно уравнение, отражающее связь между мультипликаторами РЕ и финансовыми фундаментальными переменными. Но данный подход имеет свои ограничения. Во-первых, независимые переменные коррелируют друг с другом . Например, как видно из таблицы 18,2, обобщающей корреляцию между коэффициентами бета, ростом и коэффициентами выплат для всех американских фирм, быстрорастущие фирмы обычно имеют большой риск и низкие коэффициенты выплат. Обратите внимание на отрицательную корреляцию между коэффициентами выплат и ростом, а также на положительную корреляцию между коэффициентами бета и ростом. Эта мультиколлинеарность делает мультипликаторы регрессии ненадежными (увеличивает стандартную ошибку) и, возможно, объясняет ошибочные знаки при коэффициентах и крупные изменения этих мультипликаторов в разные периоды. Во-вторых, регрессия основывается на линейной связи между мультипликаторами РЕ и фундаментальными переменными, и данное свойство, по всей вероятности, неадекватно. Анализ остаточных явлений, связанных с корреляцией, может привести к трансформациям независимых переменных (их квадратов или натуральных логарифмов), которые в большей степени подходят для объяснения мультипликаторов РЕ. В-третьих, базовая связь между мультипликаторами РЕ и финансовыми переменными сама по себе не является стабильной. Если же эта связь смещается из года в год, то прогнозы, полученные из регрессионного уравнения, могут оказаться ненадежными для более длительных периодов времени. По всем этим причинам, несмотря на полезность регрессионного анализа, его следует рассматривать только как еще один инструмент поиска подлинного значения ценности. [c.649]
На рисунке 16.6 явно просматривается четкая линейная зависимость объема частного потребления от величины располагаемого дохода. Уравнение парной линейной регрессии, оцененное по этим данным, имеет вид С= -217,6 + 1,007 Yf Стандартные ошибки для свободного члена и коэффициента парной регрессии равны, соответственно, 28,4 и 0,012, а -статистики — -7,7 и 81 9. Обе они по модулю существенно превышают 3, следовательно, их статистическая значимость весьма высока. Впрочем, несмотря на то, что здесь удалось оценить статистически значимую линейную функцию потребления, в ней нарушены сразу две предпосылки Кейнса — уровень автономного потребления С0 оказался отрицательным, а предель- [c.304]
Стандартные ошибки свободного члена и коэффициента регрессии равны, соответственно, 84,7 и 0,46 их /-статистики — (-21,4 и 36,8). По абсолютной величине /-статистики намного превышают 3, и это свидетельствует о высокой надежности оцененных коэффициентов. Коэффициент детерминации /Р уравнения равен 0,96, то есть объяснено 96% дисперсии объема потребления. И в то же время уже по рисунку видно, что оцененная рефессия не очень хоро- [c.320]
Эта стандартная ошибка S у, равная 0,65, указывает отклонение фактических данных от прогнозируемых на основании использования воздействующих факторов j i и Х2 (влияние среди покупателей бабушек с внучками и высокопрофессионального вклада Шарика). В то же время мы располагаем обычным стандартным отклонением Sn, равным 1,06 (см. табл.8), которое было рассчитано для одной переменной, а именно сами текущие значения уги величина среднего арифметического у, которое равно 6,01. Легко видеть, что S у tTa6n. В противном случае доверять полученной оценке параметра нет оснований. [c.139]
Для определения профиля посетителей магазинов местного торгового центра, не имеющих определенной цели (browsers), маркетологи использовали три набора независимых переменных демографические, покупательское поведение психологические. Зависимая переменная представляет собой индекс посещения магазина без определенной цели, индекс (browsing index). Методом ступенчатой включающей все три набора переменных, выявлено, что демографические факторы — наиболее сильные предикторы, определяющие поведение покупателей, не преследующих конкретных целей. Окончательное уравнение регрессии, 20 из 36 возможных переменных, включало все демографические переменные. В следующей таблице приведены коэффициенты регрессии, стандартные ошибки коэффициентов, а также их уровни значимости. [c.668]
Смотреть страницы где упоминается термин Стандартная ошибка уравнения регрессии
Маркетинговые исследования Издание 3 (2002) — [ c.650 ]
Лекции по дисциплине «Эконометрика» (заочное отделение) (стр. 2 )
 |
Из за большого объема этот материал размещен на нескольких страницах: 1 2 3 4 |

Параметр формально является значением Y при X = 0. Он может не иметь экономического содержания. Интерпретировать можно лишь знак при параметре . Если > 0, то относительное изменение результата происходит медленнее, чем изменение фактора. Иными словами, вариация по фактору X выше вариации для результата Y. Также считают, что включает в себя неучтенные в модели факторы.
По итогам 2008 года были собраны данные по прибыли и оборачиваемости оборотных средств 500 торговых предприятий г. Челябинска. Результаты наблюдения сведены в таблицу.
Годовая прибыль предприятия, млн. руб.
Годовая оборачиваемость оборотных средств, раз
Требуется построить зависимость прибыли предприятий от оборачиваемости оборотных средств и оценить качество полученного уравнения.
Пусть y – прибыль предприятия, x – оборачиваемость оборотных средств.
На основе исходных данных были рассчитаны следующие показатели:
Уровень доверия возьмем q=0,95 или 95%.

1. Стандартные ошибки оценок , . намного больше =0,39, следовательно, низкая точность коэффициента . очень мала по сравнению с , следовательно, высокая точность коэффициента .
2. Интервальные оценки коэффициентов уравнения регрессии.
n – 2 = 500 – 2 = 498;
α:  →
→  → очень низкая точность коэффициента;
→ очень низкая точность коэффициента;
β:  →
→  → высокая точность коэффициента.
→ высокая точность коэффициента.
3. Значимость коэффициентов регрессии.
 = >1,96 → коэффициент значим;
= >1,96 → коэффициент значим;
 = >1,96 → коэффициент значим.
= >1,96 → коэффициент значим.
4. Стандартная ошибка регрессии. Se=0,91, по сравнению со средним значением =34,5 ошибка невысокая, точность уравнения хорошая.
5. Коэффициент детерминации. R2 = rxy2=0,782=0,6084 не очень близко к 1, качество подгонки среднее.
6. Средняя ошибка аппроксимации. A=11%, качество подгонки уравнения среднее.
Экономическая интерпретация: при увеличении оборачиваемости оборотных средств предприятия на 1 раз в год средняя годовая прибыль увеличится на 5,86 млн. руб.
Тема 6. Нелинейная парная регрессия
Часто на практике между зависимой и независимыми переменными существует нелинейная форма взаимосвязи. В этом случае существует два выхода:
1) подобрать к анализируемым переменным преобразование, которое бы позволило представить существующую зависимость в виде линейной функции;
2) применить нелинейный метод наименьших квадратов.
Основные нелинейные регрессионные модели и приведение их к линейной форме
1. Экспоненциальное уравнение  .
.
Если прологарифмировать левую и правую части данного уравнения, то получится
 .
.
Это уравнение является линейным, но вместо y в левой части стоит ln y.
В данном случае параметр β1 имеет следующий экономический смысл: при увеличении переменной x на единицу переменная y в среднем увеличится примерно на 100·β% (более точно: y увеличится в  раз).
раз).
2. Логарифмическое уравнение  .
.
Переход к линейному уравнению осуществляется заменой переменной x на X=lnx..
Параметр β1 имеет следующий экономический смысл: для увеличения y на единицу необходимо увеличить переменную x в  раз, т. е. примерно на
раз, т. е. примерно на  .
.
3. Гиперболическое уравнение  .
.
В этом случае необходимо сделать замену переменных x на  . Для гиперболической зависимости нет простой интерпретации коэффициента регрессии β1.
. Для гиперболической зависимости нет простой интерпретации коэффициента регрессии β1.
4. Степенное уравнение  .
.
Прологарифмировав левую и правую части данного уравнения, получим
 .
.
Заменив соответствующие ряды их логарифмами, получится линейная регрессия.
Экономический смысл параметра β1: если значение переменной x увеличить на 1%, то y увеличится на β1%.
5. Показательное уравнение  (β1>0, β1≠1).
(β1>0, β1≠1).
Прологарифмировав левую и правую части уравнения, получим
 .
.
Проведя замены Y=ln y и B1=ln β1, получится линейная регрессия.
Экономический смысл параметра β1: при увеличении переменной x на единицу переменная y в среднем увеличится в β1 раз.
Тема 7. Множественная линейная регрессия: определение и оценка параметров
1. Понятие множественной линейной регрессии
Модель множественной линейной регрессии является обобщением парной линейной регрессии и представляет собой следующее выражение:
 , t=1. n,
, t=1. n,
где yt – значение зависимой переменной для наблюдения t,
xit – значение i-й независимой переменной для наблюдения t,
εt – значение случайной ошибки для наблюдения t,
n – число наблюдений,
m – число независимых переменных x.
2. Матричная форма записи множественной линейной регрессии
Уравнение множественной линейной регрессии можно записать в матричной форме:
 ,
,
где  ,
,  ,
,  ,
,  .
.
3. Основные предположения
2.  для всех наблюдений;
для всех наблюдений;
3.  = const для всех наблюдений;
= const для всех наблюдений;
4.  ;
;
В случае выполнения вышеперечисленных гипотез модель называется нормальной линейной регрессионной.
4. Метод наименьших квадратов
Параметры уравнения множественной регрессии оцениваются, как и в парной регрессии, методом наименьших квадратов (МНК):  .
.
Чтобы найти минимум этой функции необходимо вычислить производные по каждому из параметров и приравнять их к нулю, в результате получается система уравнений, решение которой в матричном виде следующее:
 →
→  .
.
 ,
,

5. Теорема Гаусса-Маркова
Если выполнены предположения 1-5 из пункта 3, то оценки , полученные методом наименьших квадратов, имеют наименьшую дисперсию в классе линейных несмещенных оценок, то есть являются несмещенными, состоятельными и эффективными.
Тема 8. Множественная линейная регрессия: оценка качества
1. Общая схема проверки качества парной регрессии
Адекватность модели – остатки должны удовлетворять условиям теоремы Гаусса-Маркова.
Основные показатели качества коэффициентов регрессии:
1. Стандартные ошибки оценок (анализ точности определения оценок).
2. Интервальные оценки коэффициентов уравнения регрессии (построение доверительных интервалов).
3. Значимость коэффициентов регрессии (проверка гипотез относительно коэффициентов регрессии).
Основные показатели качества уравнения регрессии в целом:
1. Стандартная ошибка регрессии Se (анализ точности уравнения регрессии).
2. Значимость уравнения регрессии в целом (проверка гипотезы относительно всех коэффициентов регрессии).
3. Коэффициент детерминации R2 (проверка качества подгонки уравнения к исходным данным).
4. Скорректированный коэффициент детерминации R2adj (проверка качества подгонки уравнения к исходным данным).
5. Средняя ошибка аппроксимации (проверка качества подгонки уравнения к эмпирическим данным).
2. Стандартные ошибки оценок
Стандартные ошибки коэффициентов регрессии – это средние квадратические отклонения коэффициентов регрессии от их истинных значений.
 ,
,
где 
 — диагональные элементы матрицы
— диагональные элементы матрицы  ,
,
 .
.
Стандартная ошибка является оценкой среднего квадратического отклонения коэффициента регрессии от его истинного значения. Чем меньше стандартная ошибка тем точнее оценка.
3. Интервальные оценки коэффициентов множественной линейной регрессии
Доверительные интервалы для коэффициентов регрессии определяются следующим образом:
1. Выбирается уровень доверия q (0,9; 0,95 или 0,99).
2. Рассчитывается уровень значимости g = 1 – q.
3. Рассчитывается число степеней свободы n – m – 1, где n – число наблюдений, m – число независимых переменных.
4. Определяется критическое значение t-статистики (tкр) по таблицам распределения Стьюдента на основе g и n – m – 1.
5. Рассчитывается доверительный интервал для параметра  :
:
 .
.
Доверительный интервал показывает, что истинное значение параметра с вероятностью q находится в данных пределах.
Чем меньше доверительный интервал относительно коэффициента, тем точнее полученная оценка.
4. Значимость коэффициентов регрессии
Процедура оценки значимости коэффициентов осуществляется аналогичной парной регрессии следующим образом:
1. Рассчитывается значение t-статистики для коэффициента регрессии по формуле  .
.
2. Выбирается уровень доверия q ( 0,9; 0,95 или 0,99).
3. Рассчитывается уровень значимости g = 1 – q.
4. Рассчитывается число степеней свободы n – m – 1, где n – число наблюдений, m – число независимых переменных.
5. Определяется критическое значение t-статистики (tкр) по таблицам распределения Стьюдента на основе g и n – m – 1.
6. Если  , то коэффициент является значимым на уровне значимости g. В противном случае коэффициент не значим (на данном уровне g).
, то коэффициент является значимым на уровне значимости g. В противном случае коэффициент не значим (на данном уровне g).
t-тесты обеспечивают проверку значимости предельного вклада каждой переменной при допущении, что все остальные переменные уже включены в модель.
5. Стандартная ошибка регрессии
Стандартная ошибка регрессии Se показывает, насколько в среднем фактические значения зависимой переменной y отличаются от ее расчетных значений
 .
.
Используется как основная величина для измерения качества модели (чем она меньше, тем лучше).
Значения Se в однотипных моделях с разным числом наблюдений и (или) переменных сравнимы.
6. Оценка значимости уравнения регрессии в целом
Уравнение значимо, если есть достаточно высокая вероятность того, что существует хотя бы один коэффициент, отличный от нуля.
Имеются альтернативные гипотезы:
Если принимается гипотеза H0, то уравнение статистически незначимо. В противном случае говорят, что уравнение статистически значимо.
Значимость уравнения регрессии в целом осуществляется с помощью F-статистики.
Оценка значимости уравнения регрессии в целом основана на тождестве дисперсионного анализа:
 Þ
Þ
TSS – общая сумма квадратов отклонений
ESS – объясненная сумма квадратов отклонений
RSS – необъясненная сумма квадратов отклонений
F-статистика представляет собой отношение объясненной суммы квадратов (в расчете на одну независимую переменную) к остаточной сумме квадратов (в расчете на одну степень свободы)

n – число выборочных наблюдений, m – число независимых переменных.
При отсутствии линейной зависимости между зависимой и независимой переменными F-статистика имеет F-распределение Фишера-Снедекора со степенями свободы k1 = m, k2 = n – m –1.
Процедура оценки значимости уравнения осуществляется следующим образом:
7. Рассчитывается значение F-статистики по формуле  .
.
8. Выбирается уровень доверия q ( 0,9; 0,95 или 0,99).
9. Рассчитывается уровень значимости g = 1 – q.
10. Рассчитывается число степеней свободы n – m – 1, где n – число наблюдений, m – число независимых переменных.
11. Определяется критическое значение F-статистики (Fкр) по таблицам распределения Фишера на основе g и n – m – 1.
12. Если  , то уравнение является значимым на уровне значимости g. В противном случае уравнение не значимо (на данном уровне g).
, то уравнение является значимым на уровне значимости g. В противном случае уравнение не значимо (на данном уровне g).
В парной регрессии F-статистика равна квадрату t-статистики:  , а значимость коэффициента регрессии и значимость уравнения в целом эквивалентны.
, а значимость коэффициента регрессии и значимость уравнения в целом эквивалентны.
Качество оценки уравнения можно проверить путем расчета коэффициента детерминации R2, который показывает степень соответствия найденного уравнения экспериментальным данным.
 .
.
Коэффициент R2 показывает долю дисперсии переменной y, объясненную регрессией, в общей дисперсии y.
Коэффициент детерминации лежит в пределах 0 £ R2 £ 1.
Чем ближе R2 к 1, тем выше качество подгонки уравнения к статистическим данным.
Чем ближе R2 к 0, тем ниже качество подгонки уравнения к статистическим данным.
Коэффициенты R2 в разных моделях с разным числом наблюдений и переменных несравнимы.
8. Скорректированный коэффициент детерминации R2adj
Низкое значение R2 не свидетельствует о плохом качестве модели, и может объясняться наличием существенных факторов, не включенных в модель
R2 всегда увеличивается с включением новой переменной. Поэтому его необходимо корректировать, и рассчитывают скорректированный коэффициент детерминации

Если R2adj выходит за пределы интервала [0;1], то его использовать нельзя.
Если при добавлении новой переменной в модель увеличивается не только R2, но и R2adj, то можно считать, что вклад этой переменной в повышение качества модели существенен.
9. Средняя ошибка аппроксимации
Средняя ошибка аппроксимации (средняя абсолютная процентная ошибка) – показывает в процентах среднее отклонение расчетных значений зависимой переменной от фактических значений yi

Если A ≤ 10%, то качество подгонки уравнения считается хорошим. Чем меньше значение A, тем лучше.
10. Использование показателей качества коэффициентов и уравнения регрессии для интерпретации и корректировки модели
В случае незначимости уравнения, необходимо устранить ошибки модели. Наиболее распространенными являются следующие ошибки:
— неправильно выбран вид функции регрессии;
— в модель включены незначимые регрессоры;
— в модели отсутствуют значимые регрессоры.
После устранения ошибок требуется заново оценить параметры уравнения и его качество, продолжая этот процесс до тех пор, пока качество уравнения не станет удовлетворительным. Если после поделанных процедур, мы не достигли требуемого уровня значимости, то необходимо устранять другие ошибки (спецификации, классификации, наблюдения и т. д., см. тему 3, п. 6).
11. Интерпретация множественной линейной регрессии
Коэффициент регрессии при переменной xi показывает, на сколько увеличится среднее значение зависимой переменной y при увеличении xi на 1, при условии постоянства других переменных.
В апреле 2006 года были собраны данные по стоимости 200 двухкомнатных квартир в Металлургическом районе г. Челябинска, их жилой площади, площади кухни и расстоянии до центра города (пл. Революции). Результаты наблюдения сведены в таблицу.
Оценка результатов линейной регрессии
Введение
Модель линейной регрессии
Итак, пусть есть несколько независимых случайных величин X1, X2, . Xn (предикторов) и зависящая от них величина Y (предполагается, что все необходимые преобразования предикторов уже сделаны). Более того, мы предполагаем, что зависимость линейная, а ошибки рапределены нормально, то есть 
где I — единичная квадратная матрица размера n x n.
Итак, у нас есть данные, состоящие из k наблюдений величин Y и Xi и мы хотим оценить коэффициенты. Стандартным методом для нахождения оценок коэффициентов является метод наименьших квадратов. И аналитическое решение, которое можно получить, применив этот метод, выглядит так: 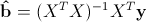
где b с крышкой — оценка вектора коэффициентов, y — вектор значений зависимой величины, а X — матрица размера k x n+1 (n — количество предикторов, k — количество наблюдений), у которой первый столбец состоит из единиц, второй — значения первого предиктора, третий — второго и так далее, а строки соответствуют имеющимся наблюдениям.
Функция summary.lm() и оценка получившихся результатов
Теперь рассмотрим пример построения модели линейной регрессии в языке R:
Таблица gala содержит некоторые данные о 30 Галапагосских островах. Мы будем рассматривать модель, где Species — количество разных видов растений на острове линейно зависит от нескольких других переменных.
Рассмотрим вывод функции summary.lm().
Сначала идет строка, которая напоминает, как строилась модель.
Затем идет информация о распределении остатков: минимум, первая квартиль, медиана, третья квартиль, максимум. В этом месте было бы полезно не только посмотреть на некоторые квантили остатков, но и проверить их на нормальность, например тестом Шапиро-Уилка.
Далее — самое интересное — информация о коэффициентах. Здесь потребуется немного теории.
Сначала выпишем следующий результат: 
при этом сигма в квадрате с крышкой является несмещенной оценкой для реальной сигмы в квадрате. Здесь b — реальный вектор коэффициентов, а эпсилон с крышкой — вектор остатков, если в качестве коэффициентов взять оценки, полученные методом наименьших квадратов. То есть при предположении, что ошибки распределены нормально, вектор коэффициентов тоже будет распределен нормально вокруг реального значения, а его дисперсию можно несмещенно оценить. Это значит, что можно проверять гипотезу на равенство коэффициентов нулю, а следовательно проверять значимость предикторов, то есть действительно ли величина Xi сильно влияет на качество построенной модели.
Для проверки этой гипотезы нам понадобится следующая статистика, имеющая распределение Стьюдента в том случае, если реальное значение коэффициента bi равно 0: 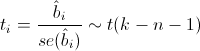
где
 — стандартная ошибка оценки коэффициента, а t(k-n-1) — распределение Стьюдента с k-n-1 степенями свободы.
— стандартная ошибка оценки коэффициента, а t(k-n-1) — распределение Стьюдента с k-n-1 степенями свободы.
Теперь все готово для продолжения разбора вывода функции summary.lm().
Итак, далее идут оценки коэффициентов, полученные методом наименьших квадратов, их стандартные ошибки, значения t-статистики и p-значения для нее. Обычно p-значение сравнивается с каким-нибудь достаточно малым заранее выбранным порогом, например 0.05 или 0.01. И если значение p-статистики оказывается меньше порога, то гипотеза отвергается, если же больше, ничего конкретного, к сожалению, сказать нельзя. Напомню, что в данном случае, так как распределение Стьюдента симметричное относительно 0, то p-значение будет равно 1-F(|t|)+F(-|t|), где F — функция распределения Стьюдента с k-n-1 степенями свободы. Также, R любезно обозначает звездочками значимые коэффициенты, для которых p-значение достаточно мало. То есть, те коэффициенты, которые с очень малой вероятностью равны 0. В строке Signif. codes как раз содержится расшифровка звездочек: если их три, то p-значение от 0 до 0.001, если две, то оно от 0.001 до 0.01 и так далее. Если никаких значков нет, то р-значение больше 0.1.
В нашем примере можно с большой уверенностью сказать, что предикторы Elevation и Adjacent действительно с большой вероятностью влияют на величину Species, а вот про остальные предикторы ничего определенного сказать нельзя. Обычно, в таких случаях предикторы убирают по одному и смотрят, насколько изменяются другие показатели модели, например BIC или Adjusted R-squared, который будет разобран далее.
Значение Residual standart error соответствует просто оценке сигмы с крышкой, а степени свободы вычисляются как k-n-1.
А теперь самая важные статистики, на которые в первую очередь стоит смотреть: R-squared и Adjusted R-squared: 
где Yi — реальные значения Y в каждом наблюдении, Yi с крышкой — значения, предсказанные моделью, Y с чертой — среднее по всем реальным значениям Yi. 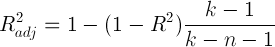
Начнем со статистики R-квадрат или, как ее иногда называют, коэффициента детерминации. Она показывает, насколько условная дисперсия модели отличается от дисперсии реальных значений Y. Если этот коэффициент близок к 1, то условная дисперсия модели достаточно мала и весьма вероятно, что модель неплохо описывает данные. Если же коэффициент R-квадрат сильно меньше, например, меньше 0.5, то, с большой долей уверенности модель не отражает реальное положение вещей.
Однако, у статистики R-квадрат есть один серьезный недостаток: при увеличении числа предикторов эта статистика может только возрастать. Поэтому, может показаться, что модель с большим количеством предикторов лучше, чем модель с меньшим, даже если все новые предикторы никак не влияют на зависимую переменную. Тут можно вспомнить про принцип бритвы Оккама. Следуя ему, по возможности, стоит избавляться от лишних предикторов в модели, поскольку она становится более простой и понятной. Для этих целей была придумана статистика скорректированный R-квадрат. Она представляет собой обычный R-квадрат, но со штрафом за большое количество предикторов. Основная идея: если новые независимые переменные дают большой вклад в качество модели, значение этой статистики растет, если нет — то наоборот уменьшается.
Для примера рассмотрим ту же модель, что и раньше, но теперь вместо пяти предикторов оставим два:
Как можно увидеть, значение статистики R-квадрат снизилось, однако значение скорректированного R-квадрат даже немного возросло.
Теперь проверим гипотезу о равенстве нулю всех коэффициентов при предикторах. То есть, гипотезу о том, зависит ли вообще величина Y от величин Xi линейно. Для этого можно использовать следующую статистику, которая, если гипотеза о равенстве нулю всех коэффициентов верна, имеет распределение Фишера c n и k-n-1 степенями свободы: 
Значение F-статистики и p-значение для нее находятся в последней строке вывода функции summary.lm().
Заключение
В этой статье были описаны стандартные методы оценки значимости коэффициентов и некоторые критерии оценки качества построенной линейной модели. К сожалению, я не касался вопроса рассмотрения распределения остатков и проверки его на нормальность, поскольку это увеличило бы статью еще вдвое, хотя это и достаточно важный элемент проверки адекватности модели.
Очень надеюсь что мне удалось немного расширить стандартное представление о линейной регрессии, как об алгоритме который просто оценивает некоторый вид зависимости, и показать, как можно оценить его результаты.
источники:
http://pandia.ru/text/78/101/1285-2.php
http://habr.com/ru/post/195146/
Качество
подбора функции регрессии можно оценить
с помощью стандартных ошибок или
дисперсий остатков и оценок параметров
регрессии.
Стандартная
ошибка или дисперсия остатков. Стандартная
ошибка остатков называется также
стандартной ошибкой оценки регрессии
в связи с интерпретацией возмущающей
переменной и как результата ошибки
спецификации функции регрессии.
Возмущающая переменная и является
случайной с определенным распределением
вероятностей. Математическое ожидание
этой переменной равно нулю, а дисперсия
— ![]() .
.
Таким образом,![]() —
—
это дисперсия возмущения в генеральной
совокупности. Нам неизвестны значения
возмущающей переменной. Можно судить
о ней только по остаткам![]() .
.
Вычисленная по этим остаткам дисперсия![]() является оценкой дисперсии возмущающей
является оценкой дисперсии возмущающей
переменной. Несмещенной оценкой дисперсии
возмущающего воздействия![]() будет, следующее выражение:
будет, следующее выражение:
![]() (35)
(35)
В
знаменателе формулы (35) стоит число
степеней свободы ![]() ,
,
гдеn— объем выборки,
am— число объясняющих переменных.
Такое выражение числа степеней свободы
связано с тем, что остатки должны
удовлетворятьm + 1условиям. Кратко поясним это утверждение.
Параметры множественной регрессии
![]() (36)
(36)
вычисляют путем решения системы
нормальных уравнений, в матричной форме
записи имеющих вид
![]() (37)
(37)
Подставим
(36) в (37):
![]()
Раскрыв
скобки и сделав соответствующие выкладки,
получим
![]() (38)
(38)
Матричное
уравнение (38) содержит m
+ 1условий (уравнений), которые
накладываются на остатки, и это приводит
к уменьшению числа степеней свободы.
Приk = 0в силу того, чтох1
= 1для всехi,
![]() (39)
(39)
что
является следствием того, что математическое
ожидание возмущающей переменной равно
нулю. Из (38) при k = 1, … , m,
т также получим
![]() (40)
(40)
что
вытекает из следующего: переменные xk(k = 1, … , m) не
коррелируют со значениями возмущения,
т. е.xk(k = 1, … , m) являются
действительно объясняющими, а не
подлежащими объяснению переменными.
Следовательно, в регрессионном анализе
могут обсуждаться только односторонне
направленные зависимости. Поскольку
термин «степень свободы» используется
для обозначения независимой информации,
в данном случае число связей, налагаемых
наnнезависимых
случайных наблюдений, можно интерпретировать
какm + 1параметров
(b0, b1
…, bm),
которыми определяется функция регрессии.
В
связи с тем что вычисление числителя в
формуле (35) довольно затруднительно, мы
хотим, опустив вывод, привести более
простой способ его определения:
![]() (41)
(41)
или
в матричной форме записи:
![]()
Выражения
сумм в правой части (41) содержатся в
рабочей таблице для построения регрессии,
а оценки параметров уже получены. Если
снова обратиться к понятию коэффициента
детерминации, введенному в разделах 1
и 2, то станет ясным физический смысл
дисперсии (или стандартного отклонения)
остатков — это та доля общей дисперсии
![]() ,
,
которая не может быть объяснена
зависимостью переменной у от переменныхxk(k = 1, … , m).
Стандартные
ошибки или дисперсии оценок параметров
регрессии. При описании этих показателей
будем исходить из заданных значений
объясняющих переменных.
Оценки
параметров регрессии являются случайными
величинами, имеющими определенное
распределение вероятностей. Возможные
значения оценок рассеиваются вокруг
истинного значения параметра β. Определим
меру рассеяния оценки параметра.
Обозначим через ![]() матрицу дисперсий и ковариаций оценок
матрицу дисперсий и ковариаций оценок
параметров регрессии:
 (42)
(42)
Симметрическая
матрица (42) на главной диагонали содержит
дисперсии оценок параметров регрессии
βk,k = 0,1,…,m
![]() (43)
(43)
а
вне главной диагонали — их ковариации
![]() (44)
(44)
для
k≠lиk = 0,1,…,m, l
= 0,1,…,m.
Краткая
форма записи матрицы (42):
![]() (45)
(45)
Подставив
в (45) формулу (46)
![]() (46)
(46)
получим
![]()
или
![]() (47)
(47)
Далее,
в силу того, что
![]() (48)
(48)
имеем
![]() (49)
(49)
Так
как ![]() неизвестно, используем его оценку
неизвестно, используем его оценку![]() .
.
В результате получаем оценку матрицы
(49),
![]() (50)
(50)
элементами
главной диагонали которой являются
искомые оценки дисперсий. Матрицу ![]() легко определить, поскольку матрица
легко определить, поскольку матрица![]() известна (см. приложение Б), a
известна (см. приложение Б), a![]() вычисляется по (35).
вычисляется по (35).
Если
мы обозначим через ![]() элемент главной диагонали матрицы
элемент главной диагонали матрицы![]() ,
,
то оценка дисперсии параметра регрессии
bkбудет определяться
выражением
![]() (51)
(51)
т.
е. она равна произведению дисперсии
остатков на k-й элемент главной
диагонали обратной матрицы![]() ,.
,.
Таким образом, стандартная ошибка оценки
параметра регрессии bkопределяется как
![]() (52)
(52)
Найдем
дисперсию и стандартную ошибку оценок
параметров b0и b1простой
линейной регрессии. В случае простой
линейной регрессии имеем
![]() .
.
а
также
 .
.
Согласно
формуле (50) получим
 .
.
Умножая
![]() на первый элемент главной диагонали
на первый элемент главной диагонали
матрицы![]() ,
,
получим оценку дисперсии постоянной
уравнения регрессии b0:
![]() (53)
(53)
а
также ее стандартную ошибку:
![]() (54)
(54)
Умножив
![]() на второй элемент главной диагонали
на второй элемент главной диагонали
матрицы![]() ,
,
получим оценку дисперсии коэффициента
регрессии b1
![]() (55)
(55)
а
также стандартную ошибку этого
коэффициента:
![]() (56)
(56)
Рассмотрим
более обстоятельно стандартную ошибку
коэффициента b1, простой линейной
регрессии. Для этого сумму квадратов
отклонений в (56) заменим на выражение,
полученное путем преобразования формулы
(![]() ):
):
![]()
Формула
(56) приобретет вид
![]() (57)
(57)
Итак,
стандартная ошибка коэффициента
регрессии зависит:
от
рассеяния остатков. Чем больше доля
вариации значений переменной у,
необъясненной ее зависимостью отх,
найденной методом наименьших квадратов,
тем больше стандартная ошибка коэффициента
регрессии. Следовательно, чем сильнее
наблюдаемые значения переменнойуотклоняются от расчетных значений
регрессии, тем менее точной является
полученная оценка параметра регрессии;
от
рассеяния значений объясняющей переменной
х. Чем сильнее это рассеяние, тем
меньше стандартная ошибка коэффициента
регрессии. Отсюда следует, что при
вытянутом облаке точек на диаграмме
рассеяния получаем более надежную
оценку функции регрессии, чем при
небольшом скоплении точек, близко
расположенных друг к другу;
от
объема выборки. Чем больше объем выборки,
тем меньше стандартная ошибка коэффициента
регрессии. Здесь существует непосредственная
связь с таким свойством оценки параметра
регрессии, как асимптотическая
несмещенность.
Стандартная
ошибка оценки параметра регрессии
используется для оценки качества подбора
функции регрессии. Для этого вычисляется
относительный показатель рассеяния,
обычно выражаемый в процентах:
![]() (58)
(58)
Чем
больше относительная стандартная ошибка
оценки параметра, тем более оцененные
величины отличаются от наблюдаемых
значений зависимой переменной и тем
менее надежны оценки прогноза, основанные
на данной функции регрессии.
1
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
What Is the Standard Error?
The standard error (SE) of a statistic is the approximate standard deviation of a statistical sample population.
The standard error is a statistical term that measures the accuracy with which a sample distribution represents a population by using standard deviation. In statistics, a sample mean deviates from the actual mean of a population; this deviation is the standard error of the mean.
Key Takeaways
- The standard error (SE) is the approximate standard deviation of a statistical sample population.
- The standard error describes the variation between the calculated mean of the population and one which is considered known, or accepted as accurate.
- The more data points involved in the calculations of the mean, the smaller the standard error tends to be.
Standard Error
Understanding Standard Error
The term «standard error» is used to refer to the standard deviation of various sample statistics, such as the mean or median. For example, the «standard error of the mean» refers to the standard deviation of the distribution of sample means taken from a population. The smaller the standard error, the more representative the sample will be of the overall population.
The relationship between the standard error and the standard deviation is such that, for a given sample size, the standard error equals the standard deviation divided by the square root of the sample size. The standard error is also inversely proportional to the sample size; the larger the sample size, the smaller the standard error because the statistic will approach the actual value.
The standard error is considered part of inferential statistics. It represents the standard deviation of the mean within a dataset. This serves as a measure of variation for random variables, providing a measurement for the spread. The smaller the spread, the more accurate the dataset.
Standard error and standard deviation are measures of variability, while central tendency measures include mean, median, etc.
Formula and Calculation of Standard Error
The standard error of an estimate can be calculated as the standard deviation divided by the square root of the sample size:
SE = σ / √n
where
- σ = the population standard deviation
- √n = the square root of the sample size
If the population standard deviation is not known, you can substitute the sample standard deviation, s, in the numerator to approximate the standard error.
Requirements for Standard Error
When a population is sampled, the mean, or average, is generally calculated. The standard error can include the variation between the calculated mean of the population and one which is considered known, or accepted as accurate. This helps compensate for any incidental inaccuracies related to the gathering of the sample.
In cases where multiple samples are collected, the mean of each sample may vary slightly from the others, creating a spread among the variables. This spread is most often measured as the standard error, accounting for the differences between the means across the datasets.
The more data points involved in the calculations of the mean, the smaller the standard error tends to be. When the standard error is small, the data is said to be more representative of the true mean. In cases where the standard error is large, the data may have some notable irregularities.
The standard deviation is a representation of the spread of each of the data points. The standard deviation is used to help determine the validity of the data based on the number of data points displayed at each level of standard deviation. Standard errors function more as a way to determine the accuracy of the sample or the accuracy of multiple samples by analyzing deviation within the means.
Standard Error vs. Standard Deviation
The standard error normalizes the standard deviation relative to the sample size used in an analysis. Standard deviation measures the amount of variance or dispersion of the data spread around the mean. The standard error can be thought of as the dispersion of the sample mean estimations around the true population mean. As the sample size becomes larger, the standard error will become smaller, indicating that the estimated sample mean value better approximates the population mean.
Example of Standard Error
Say that an analyst has looked at a random sample of 50 companies in the S&P 500 to understand the association between a stock’s P/E ratio and subsequent 12-month performance in the market. Assume that the resulting estimate is -0.20, indicating that for every 1.0 point in the P/E ratio, stocks return 0.2% poorer relative performance. In the sample of 50, the standard deviation was found to be 1.0.
The standard error is thus:
SE = 1.0/√50 = 1/7.07 = 0.141
Therefore, we would report the estimate as -0.20% ± 0.14, giving us a confidence interval of (-0.34 — -0.06). The true mean value of the association of the P/E on returns of the S&P 500 would therefore fall within that range with a high degree of probability.
Say now that we increase the sample of stocks to 100 and find that the estimate changes slightly from -0.20 to -0.25, and the standard deviation falls to 0.90. The new standard error would thus be:
SE = 0.90/√100 = 0.90/10 = 0.09.
The resulting confidence interval becomes -0.25 ± 0.09 = (-0.34 — -0.16), which is a tighter range of values.
What Is Meant by Standard Error?
Standard error is intuitively the standard deviation of the sampling distribution. In other words, it depicts how much disparity there is likely to be in a point estimate obtained from a sample relative to the true population mean.
What Is a Good Standard Error?
Standard error measures the amount of discrepancy that can be expected in a sample estimate compared to the true value in the population. Therefore, the smaller the standard error the better. In fact, a standard error of zero (or close to it) would indicate that the estimated value is exactly the true value.
How Do You Find the Standard Error?
The standard error takes the standard deviation and divides it by the square root of the sample size. Many statistical software packages automatically compute standard errors.
The Bottom Line
The standard error (SE) measures the dispersion of estimated values obtained from a sample around the true value to be found in the population. Statistical analysis and inference often involves drawing samples and running statistical tests to determine associations and correlations between variables. The standard error thus tells us with what degree of confidence we can expect the estimated value to approximate the population value.
What Is the Standard Error?
The standard error (SE) of a statistic is the approximate standard deviation of a statistical sample population.
The standard error is a statistical term that measures the accuracy with which a sample distribution represents a population by using standard deviation. In statistics, a sample mean deviates from the actual mean of a population; this deviation is the standard error of the mean.
Key Takeaways
- The standard error (SE) is the approximate standard deviation of a statistical sample population.
- The standard error describes the variation between the calculated mean of the population and one which is considered known, or accepted as accurate.
- The more data points involved in the calculations of the mean, the smaller the standard error tends to be.
Standard Error
Understanding Standard Error
The term «standard error» is used to refer to the standard deviation of various sample statistics, such as the mean or median. For example, the «standard error of the mean» refers to the standard deviation of the distribution of sample means taken from a population. The smaller the standard error, the more representative the sample will be of the overall population.
The relationship between the standard error and the standard deviation is such that, for a given sample size, the standard error equals the standard deviation divided by the square root of the sample size. The standard error is also inversely proportional to the sample size; the larger the sample size, the smaller the standard error because the statistic will approach the actual value.
The standard error is considered part of inferential statistics. It represents the standard deviation of the mean within a dataset. This serves as a measure of variation for random variables, providing a measurement for the spread. The smaller the spread, the more accurate the dataset.
Standard error and standard deviation are measures of variability, while central tendency measures include mean, median, etc.
Formula and Calculation of Standard Error
The standard error of an estimate can be calculated as the standard deviation divided by the square root of the sample size:
SE = σ / √n
where
- σ = the population standard deviation
- √n = the square root of the sample size
If the population standard deviation is not known, you can substitute the sample standard deviation, s, in the numerator to approximate the standard error.
Requirements for Standard Error
When a population is sampled, the mean, or average, is generally calculated. The standard error can include the variation between the calculated mean of the population and one which is considered known, or accepted as accurate. This helps compensate for any incidental inaccuracies related to the gathering of the sample.
In cases where multiple samples are collected, the mean of each sample may vary slightly from the others, creating a spread among the variables. This spread is most often measured as the standard error, accounting for the differences between the means across the datasets.
The more data points involved in the calculations of the mean, the smaller the standard error tends to be. When the standard error is small, the data is said to be more representative of the true mean. In cases where the standard error is large, the data may have some notable irregularities.
The standard deviation is a representation of the spread of each of the data points. The standard deviation is used to help determine the validity of the data based on the number of data points displayed at each level of standard deviation. Standard errors function more as a way to determine the accuracy of the sample or the accuracy of multiple samples by analyzing deviation within the means.
Standard Error vs. Standard Deviation
The standard error normalizes the standard deviation relative to the sample size used in an analysis. Standard deviation measures the amount of variance or dispersion of the data spread around the mean. The standard error can be thought of as the dispersion of the sample mean estimations around the true population mean. As the sample size becomes larger, the standard error will become smaller, indicating that the estimated sample mean value better approximates the population mean.
Example of Standard Error
Say that an analyst has looked at a random sample of 50 companies in the S&P 500 to understand the association between a stock’s P/E ratio and subsequent 12-month performance in the market. Assume that the resulting estimate is -0.20, indicating that for every 1.0 point in the P/E ratio, stocks return 0.2% poorer relative performance. In the sample of 50, the standard deviation was found to be 1.0.
The standard error is thus:
SE = 1.0/√50 = 1/7.07 = 0.141
Therefore, we would report the estimate as -0.20% ± 0.14, giving us a confidence interval of (-0.34 — -0.06). The true mean value of the association of the P/E on returns of the S&P 500 would therefore fall within that range with a high degree of probability.
Say now that we increase the sample of stocks to 100 and find that the estimate changes slightly from -0.20 to -0.25, and the standard deviation falls to 0.90. The new standard error would thus be:
SE = 0.90/√100 = 0.90/10 = 0.09.
The resulting confidence interval becomes -0.25 ± 0.09 = (-0.34 — -0.16), which is a tighter range of values.
What Is Meant by Standard Error?
Standard error is intuitively the standard deviation of the sampling distribution. In other words, it depicts how much disparity there is likely to be in a point estimate obtained from a sample relative to the true population mean.
What Is a Good Standard Error?
Standard error measures the amount of discrepancy that can be expected in a sample estimate compared to the true value in the population. Therefore, the smaller the standard error the better. In fact, a standard error of zero (or close to it) would indicate that the estimated value is exactly the true value.
How Do You Find the Standard Error?
The standard error takes the standard deviation and divides it by the square root of the sample size. Many statistical software packages automatically compute standard errors.
The Bottom Line
The standard error (SE) measures the dispersion of estimated values obtained from a sample around the true value to be found in the population. Statistical analysis and inference often involves drawing samples and running statistical tests to determine associations and correlations between variables. The standard error thus tells us with what degree of confidence we can expect the estimated value to approximate the population value.
Когда мы подгоняем регрессионную модель к набору данных, нас часто интересует, насколько хорошо регрессионная модель «подходит» к набору данных. Две метрики, обычно используемые для измерения согласия, включают R -квадрат (R2) и стандартную ошибку регрессии , часто обозначаемую как S.
В этом руководстве объясняется, как интерпретировать стандартную ошибку регрессии (S), а также почему она может предоставить более полезную информацию, чем R 2 .
Стандартная ошибка по сравнению с R-квадратом в регрессии
Предположим, у нас есть простой набор данных, который показывает, сколько часов 12 студентов занимались в день в течение месяца, предшествующего важному экзамену, а также их баллы за экзамен:

Если мы подгоним простую модель линейной регрессии к этому набору данных в Excel, мы получим следующий результат:

R-квадрат — это доля дисперсии переменной отклика, которая может быть объяснена предикторной переменной. При этом 65,76% дисперсии экзаменационных баллов можно объяснить количеством часов, потраченных на учебу.
Стандартная ошибка регрессии — это среднее расстояние, на которое наблюдаемые значения отклоняются от линии регрессии. В этом случае наблюдаемые значения отклоняются от линии регрессии в среднем на 4,89 единицы.
Если мы нанесем фактические точки данных вместе с линией регрессии, мы сможем увидеть это более четко:

Обратите внимание, что некоторые наблюдения попадают очень близко к линии регрессии, в то время как другие не так близки. Но в среднем наблюдаемые значения отклоняются от линии регрессии на 4,19 единицы .
Стандартная ошибка регрессии особенно полезна, поскольку ее можно использовать для оценки точности прогнозов. Примерно 95% наблюдений должны находиться в пределах +/- двух стандартных ошибок регрессии, что является быстрым приближением к 95% интервалу прогнозирования.
Если мы заинтересованы в прогнозировании с использованием модели регрессии, стандартная ошибка регрессии может быть более полезной метрикой, чем R-квадрат, потому что она дает нам представление о том, насколько точными будут наши прогнозы в единицах измерения.
Чтобы проиллюстрировать, почему стандартная ошибка регрессии может быть более полезной метрикой для оценки «соответствия» модели, рассмотрим другой пример набора данных, который показывает, сколько часов 12 студентов занимались в день в течение месяца, предшествующего важному экзамену, а также их экзаменационная оценка:

Обратите внимание, что это точно такой же набор данных, как и раньше, за исключением того, что все значения s сокращены вдвое.Таким образом, студенты из этого набора данных учились ровно в два раза дольше, чем студенты из предыдущего набора данных, и получили ровно половину экзаменационного балла.
Если мы подгоним простую модель линейной регрессии к этому набору данных в Excel, мы получим следующий результат:

Обратите внимание, что R-квадрат 65,76% точно такой же, как и в предыдущем примере.
Однако стандартная ошибка регрессии составляет 2,095 , что ровно вдвое меньше стандартной ошибки регрессии в предыдущем примере.
Если мы нанесем фактические точки данных вместе с линией регрессии, мы сможем увидеть это более четко:

Обратите внимание на то, что наблюдения располагаются гораздо плотнее вокруг линии регрессии. В среднем наблюдаемые значения отклоняются от линии регрессии на 2,095 единицы .
Таким образом, несмотря на то, что обе модели регрессии имеют R-квадрат 65,76% , мы знаем, что вторая модель будет давать более точные прогнозы, поскольку она имеет более низкую стандартную ошибку регрессии.
Преимущества использования стандартной ошибки
Стандартную ошибку регрессии (S) часто бывает полезнее знать, чем R-квадрат модели, потому что она дает нам фактические единицы измерения. Если мы заинтересованы в использовании регрессионной модели для получения прогнозов, S может очень легко сказать нам, достаточно ли точна модель для прогнозирования.
Например, предположим, что мы хотим создать 95-процентный интервал прогнозирования, в котором мы можем прогнозировать результаты экзаменов с точностью до 6 баллов от фактической оценки.
Наша первая модель имеет R-квадрат 65,76%, но это ничего не говорит нам о том, насколько точным будет наш интервал прогнозирования. К счастью, мы также знаем, что у первой модели показатель S равен 4,19. Это означает, что 95-процентный интервал прогнозирования будет иметь ширину примерно 2*4,19 = +/- 8,38 единиц, что слишком велико для нашего интервала прогнозирования.
Наша вторая модель также имеет R-квадрат 65,76%, но опять же это ничего не говорит нам о том, насколько точным будет наш интервал прогнозирования. Однако мы знаем, что вторая модель имеет S 2,095. Это означает, что 95-процентный интервал прогнозирования будет иметь ширину примерно 2*2,095= +/- 4,19 единиц, что меньше 6 и, следовательно, будет достаточно точным для использования для создания интервалов прогнозирования.
Дальнейшее чтение
Введение в простую линейную регрессию
Что такое хорошее значение R-квадрата?
Значение слова «СТАНДАРТНАЯ ОШИБКА» найдено в 13 источниках
СТАНДАРТНАЯ ОШИБКА
- СТАНДАРТНАЯ ОШИБКА
-
(standard error) Показатель надежности расчетного параметра. Стандартная ошибка – это стандартное отклонение оценок, которые будут получены при многократной случайной выборке данного размера из одной и той же совокупности. Стандартная ошибка – это убывающая функция объема выборки: чем меньше стандартная ошибка, тем более достоверной является оценка.
Экономика. Толковый словарь. — М.: «ИНФРА-М», Издательство «Весь Мир»..2000.
величина, характеризующая случайную ошибку выборки стандартное отклонение выборочного распределения статистики; обозначается SE (standard error). Может вычисляться для любых выборочных статистик; используется при построении соответствующих доверительных интервалов и статистической проверке гипотез .
Наиболее часто используется С.О. среднего арифметического . Она вычисляется по формуле SE = s / Vn, где s стандартное отклонение переменной, n объем выборки. Чем меньше стандартное отклонение s и больше объем выборки n, тем меньше С.О. С.О. среднего арифметического применяется при построении доверительного интервала для математического ожидания , интервального оценивания случайной ошибки выборки , нахождения объема репрезентативной выборки при заданных доверительной вероятности и предельно допустимой ошибке выборки.
О.В. Терещенко
показатель отклонения полученного коэффициента регрессии от предполагаемого значения реального (но неизвестного) коэффициента для массива. В (t-тесте стандартная ошибка определенного коэффициента делится на этот коэффициент, показывая t-значение. t-таблица, численная таблица, состоящая из значений f-отношения и частоты их появления в (-распределении, чье среднее значение равняется нулю, t-тест: тест статистической значимости полученных коэффициентов регрессии. Если коэффициент проходит этот тест, то исследователь может быть вполне уверен в том, что значение коэффициента для массива не равняется нулю;
Стандартное отклонение распределения теоретической выборки. Оно обеспечивает оценку вариативности, которая может ожидаться в фактических выборках из основной теоретической популяции и, таким образом, и в популяционном параметре. См. стандартная ошибка среднего, которая является оценкой стандартной ошибки, наиболее часто используемой для оценки репрезентативности выборки.
Стандартное
отклонение статистики, в
частности, выборочного распределения оценки. Как правило, употребляется в
выражениях типа «стандартная ошибка среднего» (которая равна стандартному
отклонению, деленному на корень квадратный из объема выборки).
• kvadratická chyba
• směrodatná odchylka
• standardní odchylka
• střední chyba
1) mean-square error
2) standard error
. см. ВЫБОРКИ ОШИБКА.
Antinazi.Энциклопедия социологии,2009