
Доверительные интервалы и доверительная вероятность, уровень значимости. Проверка статистических гипотез, критерии значимости, ошибки первого и второго рода. Построение доверительного интервала для математического ожидания непосредственно измеряемой величины. Распределение Стъюдента.
4.1.Доверительные интервалы и доверительная вероятность, уровень значимости.
Выборочные параметры распределения, определяемые по серии измерений, являются случайными величинами, следовательно, и их отклонения от генеральных параметров также будут случайными. Оценка этих отклонений носит вероятностный характер — при статистическом анализе можно лишь указать вероятность той или иной погрешности.
Пусть для генерального параметра а получена из опыта несмещенная оценка а*. Назначим достаточно большую вероятность β (такую, что событие с вероятностью β можно считать практически достоверным) и найдем такое значение εβ = f (β), для которого
|
P ( |
a* − a |
≤ εβ )= β. |
(4.1) |
||
Диапазон практически возможных значений ошибки, возникающей при замене а на а*, будет ±εβ. Большие по абсолютной величине ошибки будут появляться только с малой вероятностью
называемой уровнем значимости. Иначе выражение (4.1) можно интерпретировать как вероятность того, что истинное значение параметра а лежит в пределах
|
a* −εβ ≤ a ≤ a* + εβ . |
(4.3) |
Вероятность β называется доверительной вероятностью и характеризует надежность полученной оценки. Интервал Iβ = a* ± εβ называет-
ся доверительным интервалом. Границы интервала a′ = a* — εβ и a′′ = a* + εβ называются доверительными границами. Доверительный интервал при данной доверительной вероятности определяет точность оценки. Величина доверительного интервала зависит от доверительной вероятности, с которой гарантируется нахождение параметра а внутри доверительного интервала: чем больше величина β, тем больше интер-
вал Iβ (и величина εβ). Увеличение числа опытов проявляется в сокра-
35

щении доверительного интервала при постоянной доверительной вероятности или в повышении доверительной вероятности при сохранении доверительного интервала.
На практике обычно фиксируют значение доверительной вероятности (0,9; 0,95 или 0,99) и затем определяют доверительный интервал результата Iβ. При построении доверительного интервала решается задача об абсолютном отклонении:
εβ
P (a* − a ≤ εβ )= P(∆a ≤ εβ )= F(εβ )− F(— εβ )= ∫f (a) da =β. (4.4)
—εβ
Таким образом, если бы был известен закон распределения оценки а*, задача определения доверительного интервала решалась бы просто. Рассмотрим построение доверительного интервала для математического ожидания нормально распределенной случайной величины Х с известным генеральным стандартом σ по выборке объемом n. Наилучшей оценкой для математического ожидания m является среднее выборки x со стандартным отклонением среднего
|
σ(x) = σ/ n . |
|||||||||
|
Используя функцию Лапласа, получаем |
εβ |
||||||||
|
P ( |
x − mx |
≤ εβ )= β = 2Ф |
. |
(4.5) |
|||||
|
σ(x) |
Задавшись доверительной вероятностью β, определим по таблице функции Лапласа (приложение 1) величину kβ = εβ / σ(x) . Тогда дове-
рительный интервал для математического ожидания принимает вид
|
− kβ σ( |
) ≤ mx ≤ |
+ kβσ( |
) , |
(4.6) |
||||||
|
x |
x |
x |
x |
|||||||
|
или |
||||||||||
|
x − kβ |
σ |
≤ mx ≤ x + kβ |
σ . |
(4.7) |
||||||
|
n |
n |
Из (4.7) видно, что уменьшение доверительного интервала обратно пропорционально корню квадратному из числа опытов.
Знание генеральной дисперсии позволяет оценивать математическое ожидание даже по одному наблюдению. Если для нормально распределенной случайной величины Х в результате эксперимента получено значение х1, то доверительный интервал для математического ожидания при выбранной β имеет вид
36

|
x1 −σU1− p / 2 ≤ mx ≤ x1 + σU1− p / 2 , |
(4.8) |
где U1-p/2 — квантиль стандартного нормального распределения (приложение 2).
Закон распределения оценки а* зависит от закона распределения величины Х и, в частности, от самого параметра а. Чтобы обойти это затруднение, в математической статистике применяют два метода:
1)приближенный — при n ≥ 50 заменяют в выражении для εβ неизвестные параметры их оценками, например:
kβ = εβ / σ(x) ≈ εβ / s (x) ;
2)от случайной величины а* переходят к другой случайной величине Θ*, закон распределения которой не зависит от оцениваемого параметра а, а зависит только от объема выборки n и от вида закона распределения величины Х. Такого рода величины наиболее подробно изучены для нормального распределения случайных величин. В качестве доверительных границ Θ′ и Θ′′ обычно используются симметричные квантили
|
Θ(1−β) / 2 ≤ Θ* ≤ Θ(1+β) / 2 , |
(4.9) |
|||
|
или с учетом (4.2) |
||||
|
Θ |
p/2 |
≤ Θ* ≤ Θ |
. |
(4.10) |
|
1− p/2 |
4.2.Проверка статистических гипотез, критерии значимости, ошибки первого и второго рода.
Под статистическими гипотезами понимаются некоторые предположения относительно распределений генеральной совокупности той или иной случайной величины. Под проверкой гипотезы понимают сопоставление некоторых статистических показателей, критериев проверки (критериев значимости), вычисляемых по выборке, с их значениями, определенными в предположении, что данная гипотеза верна. При проверке гипотез обычно подвергается испытанию некоторая гипотеза Н0 в сравнении с альтернативной гипотезой Н1.
Чтобы решить вопрос о принятии или непринятии гипотезы, задаются уровнем значимости р. Наиболее часто используются уровни значимости, равные 0.10, 0.05 и 0.01. По этой вероятности, используя гипотезу о распределении оценки Θ* (критерия значимости), находят квантильные доверительные границы, как правило, симметричные Θp/2
37
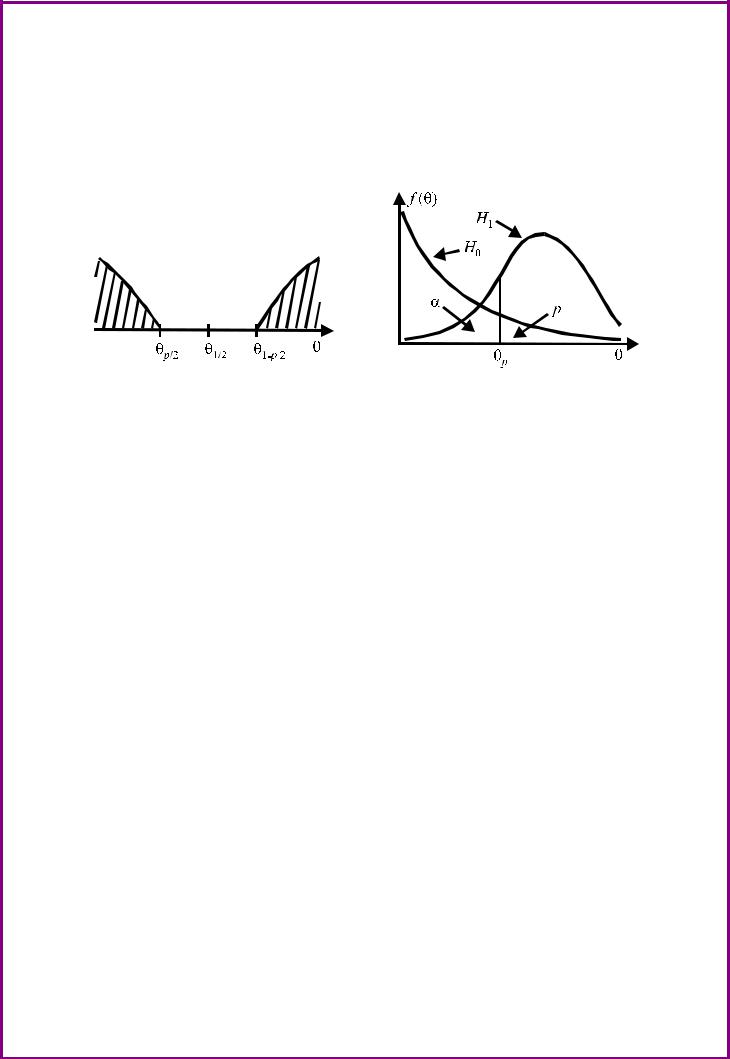
и Θ1-p/2. Числа Θp/2 и Θ1-p/2 называются критическими значениями гипо-
тезы; значения Θ* < Θp/2 и Θ* > Θ1-p/2 образуют критическую область гипотезы (или область непринятия гипотезы) (рис. 12).
|
Рис. 12. Критическая область |
Рис. 13. Проверка статистических |
|
гипотезы. |
гипотез. |
Если найденное по выборке Θ0 попадает между Θp/2 и Θ1-p/2, то гипотеза допускает такое значение в качестве случайного и поэтому нет оснований ее отвергать. Если же значение Θ0 попадает в критическую область, то по данной гипотезе оно является практически невозможным. Но поскольку оно появилось, то отвергается сама гипотеза.
При проверке гипотез можно совершить ошибки двух типов. Ошиб-
ка первого рода состоит в том, что отвергается гипотеза, которая на самом деле верна. Вероятность такой ошибки не больше принятого уровня значимости. Ошибка второго рода состоит в том, что гипотеза принимается, а на самом деле она неверна. Вероятность этой ошибки тем меньше, чем выше уровень значимости, так как при этом увеличивается число отвергаемых гипотез. Если вероятность ошибки второго рода равна α, то величину (1 — α) называют мощностью критерия.
На рис. 13 приведены две кривые плотности распределения случайной величины Θ, соответствующие двум гипотезам Н0 и Н1. Если из опыта получается значение Θ > Θp, то отвергается гипотеза Н0 и принимается гипотеза Н1, и наоборот, если Θ < Θp.
Площадь под кривой плотности вероятности, соответствующей справедливости гипотезы Н0 вправо от значения Θp, равна уровню значимости р, т. е. вероятности ошибки первого рода. Площадь под кривой плотности вероятности, соответствующей справедливости гипотезы Н1 влево от Θp, равна вероятности ошибки второго рода α, а вправо от Θp — мощности критерия (1 — α). Таким образом, чем больше р, тем
38

больше (1 — α). При проверке гипотезы стремятся из всех возможных критериев выбрать тот, у которого при заданном уровне значимости меньше вероятность ошибки второго рода.
Обычно в качестве оптимального уровня значимости при проверке гипотез используют p = 0,05, так как если проверяемая гипотеза принимается с данным уровнем значимости, то гипотезу, безусловно, следует признать согласующейся с экспериментальными данными; с другой стороны, использование данного уровня значимости не дает оснований для отбрасывания гипотезы.
Например, найдены два значения a1* и a2* некоторого выборочного параметра, которые можно рассматривать как оценки генеральных параметров а1 и а2. Высказывается гипотеза, что различие между a1* и a2*
случайное и что генеральные параметры а1 и а2 равны между собой, т. е. а1 = а2. Такая гипотеза называется нулевой, или нуль-гипотезой.
Для ее проверки нужно выяснить, значимо ли расхождение между a1* и a2* в условиях нулевой гипотезы. Для этого обычно исследуют случай-
|
ную величину ∆a* = a* – a* |
и проверяют, значимо ли ее отличие от |
|||
|
1 |
2 |
a* / a* , сравнивая ее с |
||
|
нуля. Иногда удобнее рассматривать величину |
||||
|
1 |
2 |
единицей.
Отвергая нулевую гипотезу, тем самым принимают альтернативную, которая распадается на две: a1* > a2* и a1* < a2* . Если одно из этих
равенств заведомо невозможно, то альтернативная гипотеза называется односторонней, и для ее проверки применяют односторонние критерии значимости (в отличие от обычных, двусторонних). При этом необходимо рассматривать лишь одну из половин критической области
(рис. 12).
Например, р = 0,05 при двустороннем критерии соответствуют критические значения Θ0.025 и Θ0.975, т. е. значимыми (неслучайными) счи-
таются Θ*, принявшие значения Θ* < Θ0.025 и Θ* > Θ0.975. При одностороннем критерии одно из этих неравенств заведомо невозможно (на-
пример, Θ* < Θ0.025) и значимыми будут лишь Θ* > Θ0.975. Вероятность последнего неравенства равна 0,025, и, следовательно, уровень значи-
мости будет равен 0,025. Таким образом, если при одностороннем критерии значимости использовать те же критические числа, что и при двустороннем, этим значениям будет соответствовать вдвое меньший уровень значимости.
Обычно для одностороннего критерия берут тот же уровень значимости, что и для двустороннего, так как при этих условиях оба крите-
39
![]()
рия обеспечивают одинаковую ошибку первого рода. Для этого одно-
сторонний критерий надо выводить из двустороннего, соответствующего вдвое большему уровню значимости, чем тот, что принят.
Чтобы сохранить для одностороннего критерия уровень значимости р = 0,05, для двустороннего необходимо взять р = 0,10, что дает критические значения Θ0.05 и Θ0.95. Из них для одностороннего критерия останется какое-нибудь одно, например, Θ0.95. Уровень значимости для одностороннего критерия равен при этом 0.05. Этому же уровню значимости для двустороннего критерия соответствует критическое значе-
ние Θ0.975. Но Θ0.95 < Θ0.975, значит, при одностороннем критерии большее число гипотез будет отвергнуто и, следовательно, меньше будет
ошибка второго рода.
4.3.Построение доверительного интервала для математического ожидания непосредственно измеряемой величины. Распределение Стъюдента.
При отсутствии грубых и систематических ошибок математическое ожидание случайной величины совпадает с истинным результа-
том наблюдений. Легче всего оценить математическое ожидание при известной дисперсии генеральной совокупности (выражения 4.6 – 4.8). Однако значение σ2 нельзя получить из наблюдений, ее можно только оценить при помощи выборочной дисперсии s2. Ошибка от этой замены будет тем меньше, чем больше объем выборки n. На практике эту погрешность не учитывают при n ≤ 50 и в формуле (4.7) для доверительного интервала генеральный параметр σ заменяют выборочным стандартом. В дальнейшем примем, что наблюдаемая случайная величина имеет нормальное распределение.
При небольших объемах выборок для построения доверительного интервала математического ожидания используют распределение Стъюдента, или t-распределение. Распределение Стъюдента имеет величина t
с плотностью вероятности
40
|
f |
+1 |
f +1 |
|||||||||||
|
1 |
Г |
2 |
− |
||||||||||
|
ϕ(t) = |
2 |
2 |
, |
−∞ < t < +∞, |
(4.12) |
||||||||
|
1+ t |
|||||||||||||
|
π |
f |
f |
f |
||||||||||
|
Г |
|||||||||||||
|
2 |
|||||||||||||
|
где Г(f ) — гамма-функция Эйлера: |
|||||||||||||
|
∞ |
|||||||||||||
|
Г(z) = ∫e−y yz −1dy ; |
(4.13) |
||||||||||||
|
0 |
f — число степеней свободы выборки. Если дисперсия s2 и среднее x определяются по одной и той же выборке, то f = n – 1.
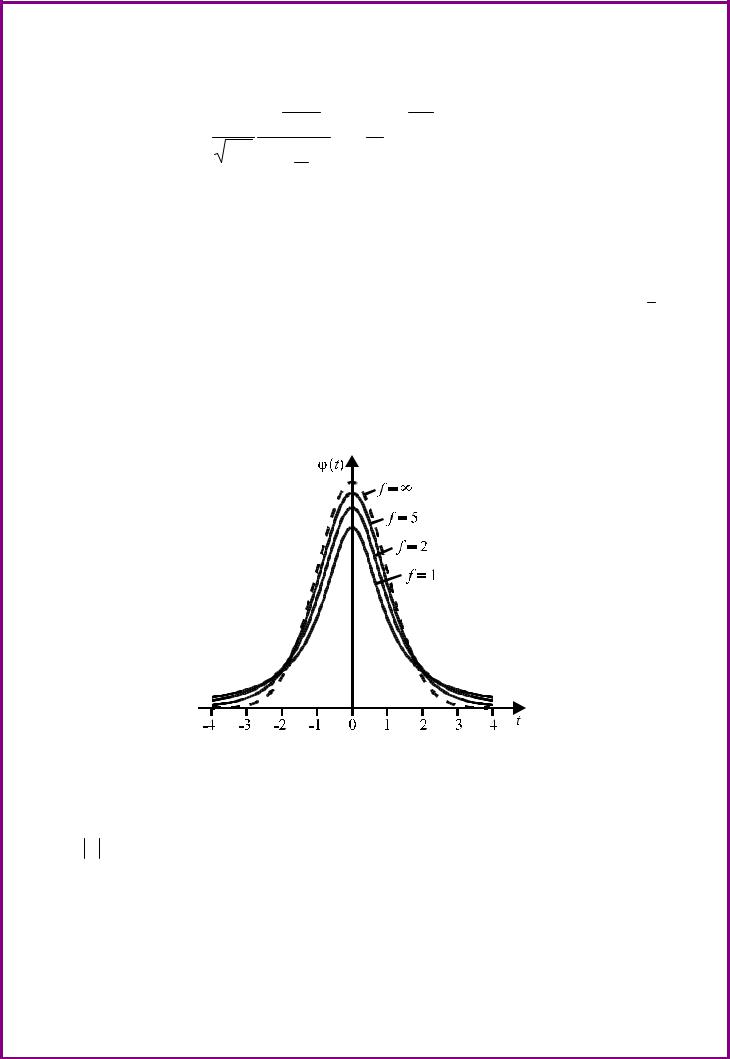
Распределение Стъюдента зависит только от числа степеней свободы f, с которым определена выборочная дисперсия. На рис. 14 приведены графики плотности t-распределения для нескольких чисел свободы f и нормальная кривая.
Рис. 14. Плотность распределения Стъюдента.
Кривые t-распределения по своей форме напоминают нормальную кривую, но при малых f они медленнее сближаются с осью абсцисс при
t → ∞. При f → ∞ s2 → σ2 , поэтому распределение Стъюдента
сближается (в пределе соответствует) с нормальным распределением. Вероятность того, что случайная величина попадет в интервал (tp/2;
t1-p/2), определяется выражением
41

|
P (t p/2 ≤ t ≤ t1− p/2 ) =1− p = β. |
(4.14) |
Распределение Стъюдента симметрично относительно нуля, поэтому
|
t p/2 = −t1- p/2 . |
(4.15) |
Учитывая симметрию t-распределения, часто пользуются обозначением tp(f ), где f — число степеней свободы, р — уровень значимости, т. е. вероятность того, что t находится за пределами интервала (tp/2; t1- p/2). Подставляя в (4.14) выражение для t (4.11) с учетом (4.15), получаем неравенство
|
−t1− p/2 ≤ |
x − mx |
n ≤t1− p/2 |
, |
(4.16) |
|
|
sx |
|||||
и после преобразований имеем
|
x − |
sx t |
≤ m |
≤ x + |
sx t |
. |
(4.17) |
|
|
n 1− p/2 |
x |
n 1− p/2 |
Значения квантилей t1-p/2 для различных чисел степеней свободы f и уровней значимости р приведены в приложении 3. Выражение (4.17) означает, что интервал с доверительными границами
|
( |
− s ( |
) t1− p/2 )÷ ( |
+ s ( |
) t1− p/2 ) |
(4.18) |
||||
|
x |
x |
x |
x |
накрывает с вероятностью β генеральное среднее измеряемой величины. Величина доверительного интервала (4.18) определяет надежность среднего выборки. Величину
|
s (x)t |
= |
sx t |
= ε |
, |
(4.19) |
|
|
1− p/2 |
n 1− p/2 |
случ |
т. е. половину доверительного интервала, называют случайной ошибкой. С учетом только случайной ошибки результат измерений некоторой величины следует записывать так:
|
X = x ± ε |
= x ± |
sx t |
. |
(4.20) |
|
|
случ |
n 1− p/2 |
42
Соседние файлы в предмете Химия
- #
- #
- #
- #
16.08.20133.95 Mб30Стелл Д.Р. — Таблицы давления паров индивидуальных веществ (1949).pdf
- #
- #
- #
- #
- #
- #
16.08.201328.07 Mб25Томас Ч. — Безводный xлористый алюминий в органической xимии (1949).djvu
- #
16.08.201331.55 Mб26Тонкослойная хроматография реагенты и методы определения т.pdf
Что влияет на ширину доверительного интервала?
К этому моменту мы обсудили два фактора, которые влияют на ширину интервала:
- выбор статистики ((t) или (z)) и
- выбор степени доверия (влияющий на то, какую величину (t) или (z) мы используем).
Эти два варианта определяют фактор надежности.
Напомним, что доверительный интервал имеет следующую структуру:
Точечная оценка (pm) Фактор надежности (times) Стандартная ошибка.
Выбор размера выборки также влияет на ширину доверительного интервала. При прочих равных, больший размер выборки уменьшает ширину доверительного интервала.
Напомним формулу стандартной ошибки выборочного среднего:
( Large substack{ textbf{Стандартная ошибка} \ textbf{выборочного среднего} } = { textbf{Стандартное отклонение выборки} over sqrt { textbf{Размер выборки}}} )
Мы видим, что стандартная ошибка меняется обратно пропорционально квадратному корню из размера выборки.
По мере увеличения размера выборки, стандартная ошибка уменьшается и, следовательно, ширина доверительного интервала также уменьшается. Чем больше размер выборки, тем выше точность, с которой мы можем оценить параметр совокупности.
Существует формула для определения размера выборки, необходимого для получения доверительного интервала нужной ширины.
Определим (E) = Фактор надежности (times) Стандартная ошибка.
Чем меньше (E), тем меньше ширина доверительного интервала, так как (2E) — это ширина доверительного интервала.
Размер выборки, необходимый для получения нужного значения (E) при заданной степени уверенности ((1 — alpha) ) равен:
( Large {n = [(t_{alpha / 2}s) / E]^2} ).
При прочих равных, более крупные выборки лучше в этом смысле. На практике, однако, два соображения могут повлиять на решение против увеличения размера выборки.
- Во-первых, как мы уже видели в Примере (2) расчета коэффициента Шарпа, увеличение размера выборки может привести к выборке из более чем одной совокупности.
- Во-вторых, увеличение размера выборки может означать дополнительные затраты времени и денег, которые не окупятся благодаря дополнительной точности.
Таким образом, есть три фактора, которые финансовый аналитик должен оценить при определении размера выборки, — это:
- потребность в точности,
- риск отбора выборки из более чем одной совокупности, а также
- издержки на получение выборок различных размеров.
Пример (6) оценки инвестиционным менеджером чистого притока денежных средств клиентов.
Инвестиционный менеджер хочет построить 95-процентный доверительный интервал для притоков и оттоков денежных средств своих клиентов в течение следующих 6 месяцев.
Он начинается с обзвона случайной выборки из 10 клиентов, чтобы опросить их о планируемых взносах и изъятиях средств из инвестиционного фонда.
Затем менеджер вычисляет изменение денежного потока для каждого клиента из выборки, как процентное изменение от общего объема средств, размещенных у менеджера. Положительное процентное изменение указывает на чистый приток денежных средств на счет клиента, а отрицательное процентное изменение указывает на чистый отток денежных средств со счета клиента.
Менеджер взвешивает каждый ответ клиента по относительному размеру счета в рамках выборки, а затем вычисляет взвешенное среднее.
Проделав все это, инвестиционный менеджер вычисляет взвешенное среднее значение равное 5.5%. Таким образом, проведенная точечная оценка означает, что общая сумма средств под управлением менеджера увеличится на 5.5% в течение следующих 6 месяцев.
Стандартное отклонение наблюдений в выборке составляет 10%. Гистограмма прошлых данных выглядит довольно близко к нормальному распределению, так что менеджер предполагает, что генеральная совокупность также соответствует нормальному распределению.
1. Рассчитайте 95-процентный доверительный интервал для среднего по совокупности и интерпретируйте результаты.
Менеджер решил проанализировать, каким будет доверительный интервал, если использовать размер выборки 20 или 30, и получил то же самое среднее (5.5%) и стандартное отклонение (10%).
2. Используя выборочное среднее 5.5% и стандартное отклонение 10%, вычислите доверительный интервал для размеров выборки от 20 до 30. Для размера выборки 30 используйте Формулу 6.
3. Интерпретируйте результаты для частей 1 и 2.
Решение для части 1:
Поскольку совокупность неизвестна, а размер выборки мал, менеджер должен использовать t-статистику из Формулы 6 для расчета доверительного интервала.
Для выборки размера 10, (rm{df} = n — 1 = 10 — 1 = 9).
Для 95-процентного доверительного интервала, он должен использовать значение (t_{0.025}) для df = 9.
В соответствии с таблицами распределения Стьюдента это значение равно 2.262.
Таким образом, 95-процентный доверительный интервал для среднего значения по совокупности равен:
( begin{aligned} overline X pm t_{0.025} {s over sqrt{n}} &= 5.5% pm 2.262 {10% over sqrt {10}} \ &= 5.5% pm 2.262(3.162) \ &= 5.5% pm 7.15% end{aligned} )
Доверительный интервал для среднего по совокупности охватывает значения -1.65% до + 12,65%.
Мы предположили, что в этом примере размер выборки достаточно мал по сравнению с размером клиентской базы, поэтому мы можем пренебречь поправкой для конечной совокупности.
Менеджер может быть уверен на 95%, что этот диапазон включает в себя среднее значение по совокупности.
Решение для части 2:
В Таблице 4 приведены расчеты для выборок трех размеров.
|
Распределение |
95% доверительный интервал |
Нижняя граница |
Верхняя граница |
Относительный размер |
|---|---|---|---|---|
|
( t(n = 10) ) |
(5.5% pm 2.262(3.162) ) |
-1.65% |
12.65% |
100.0% |
|
( t(n = 20) ) |
(5.5% pm 2.093(2.236) ) |
0.82 |
10.18 |
65.5 |
|
( t(n = 30) ) |
(5.5% pm 2.045(1.826) ) |
1.77 |
9.23 |
52.2 |
Решение для части 3:
Ширина доверительного интервала уменьшается по мере увеличения размера выборки. Это уменьшение является функцией стандартной ошибки, которая становится меньше при увеличении (n).
Коэффициент надежности также становится меньше, так как число степеней свободы возрастает.
В последней колонке Таблицы 4 показан относительный размер ширины доверительных интервалов, если принять (n = 10 ) за 100%. Размер выборки 20 уменьшает ширину доверительного интервала до 65.5% от ширины интервала для размера выборки 10.
При размере выборки 30 ширина интервала сокращается почти в два раза. На основе этих данных, инвестиционный менеджер получил бы наиболее точные результаты, используя размер выборки 30.
Рассмотрев многие из фундаментальных понятий статистической выборки и оценки, мы можем сосредоточить внимание на вопросах отбора выборки, представляющих особый интерес для финансовых аналитиков. Качество выводов зависит от качества данных, а также от качества используемого плана выборки.
Финансовые данные создают особые проблемы, и планы выборки часто отражают одну или несколько систематических ошибок (смещений). В следующем разделе этого чтения обсуждаются эти вопросы.

Калькулятор для расчета достаточного объема выборки
Калькулятор ошибки выборки для доли признака
Калькулятор ошибки выборки для среднего значения
Калькулятор значимости различий долей
Калькулятор значимости различий средних
1. Формула (даже две)
Бытует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с размером генеральной совокупности. Например, при опросах организаций (B2B).
Если речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная.
На рис.1. пример выборки 15000 человек (!) при опросе в муниципальном районе. Возможно, от численности населения взяли 10%?
Размер выборки никогда не рассчитывается как процент от генеральной совокупности!

Рис.1. Размер выборки 15000 человек, как реальный пример некомпетентности (или хуже).
В таких случаях для расчета объема выборки используется следующая формула:

где
n – объем выборки,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует,
∆ – предельная ошибка выборки.
Доверительный уровень – это вероятность того, что реальная доля лежит в границах полученного доверительного интервала: выборочная доля (p) ± ошибка выборки (Δ). Доверительный уровень устанавливает сам исследователь в соответствии со своими требованиями к надежности полученных результатов. Чаще всего применяются доверительные уровни, равные 0,95 или 0,99. В маркетинговых исследованиях, как правило, выбирается доверительный уровень, равный 0,95. При этом уровне коэффициент Z равен 1,96.
Значения p и q чаще всего неизвестны до проведения исследования и принимаются за 0,5. При этом значении размер ошибки выборки максимален.
Допустимая предельная ошибка выборки выбирается исследователем в зависимости от целей исследования. Считается, что для принятия бизнес-решений ошибка выборки должна быть не больше 4%. Этому значению соответствует объем выборки 500-600 респондентов. Для важных стратегических решений целесообразно минимизировать ошибку выборки.
Рассмотрим кривую зависимости ошибки выборки от ее объема (Рис.2).

Рис.2. Зависимость ошибки выборки от ее объема при 95% доверительном уровне
Как видно из диаграммы, с ростом объема выборки значение ошибки уменьшается все медленнее. Так, при объеме выборки 1500 человек предельная ошибка выборки составит ±2,5%, а при объеме 2000 человек – ±2,2%. То есть, при определенном объеме выборки дальнейшее его увеличение не дает значительного выигрыша в ее точности.
Подходы к решению проблемы:
Случай 1. Генеральная совокупность значительно больше выборки:

Случай 2. Генеральная совокупность сопоставима с объемом выборки: (см. раздел исследований B2B)

где
n – объем выборки,
N – объем генеральной совокупности,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует, (значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования)
∆ – предельная ошибка выборки.
Например,
рассчитаем ошибку выборки объемом 1000 человек при 95% доверительном уровне, если генеральная совокупность значительно больше объема выборки:
Ошибка выборки = 1,96 * КОРЕНЬ(0,5*0,5/1000) = 0,031 = ±3,1%
При расчете объема выборки следует также учитывать стоимость проведения исследования. Например, при цене за 1 анкету 200 рублей стоимость опроса 1000 человек составит 200 000 рублей, а опрос 1500 человек будет стоить 300 000 рублей. Увеличение затрат в полтора раза сократит ошибку выборки всего на 0,6%, что обычно неоправданно экономически.
2. Причины «раздувать» выборку
Анализ полученных данных обычно включает в себя и анализ подвыборок, объемы которых меньше основной выборки. Поэтому ошибка для выводов по подвыборкам больше, чем ошибка по выборке в целом. Если планируется анализ подгрупп / сегментов, объем выборки должен быть увеличен (в разумных пределах).
Рис.3 демонстрирует данную ситуацию. Если для исследования авиапассажиров используется выборка численностью 500 человек, то для выводов по выборке в целом ошибка составляет 4,4%, что вполне приемлемо для принятия бизнес-решений. Но при делении выборки на подгруппы в зависимости от цели поездки, выводы по каждой подгруппе уже недостаточно точны. Если мы захотим узнать какие-либо количественные характеристики группы пассажиров, совершающих бизнес-поездку и покупавших билет самостоятельно, ошибка полученных показателей будет достаточно велика. Даже увеличение выборки до 2000 человек не обеспечит приемлемой точности выводов по этой подвыборке.

Рис.3. Проектирование объема выборки с учетом необходимости анализа подвыборок
Другой пример – анализ подгрупп потребителей услуг торгово-развлекательного центра (Рис.4).

Рис.4. Потенциальный спрос на услуги торгово-развлекательного центра
При объеме выборки в 1000 человек выводы по каждой отдельной услуге (например, социально-демографический профиль, частота пользования, средний чек и др.) будут недостаточно точными для использования в бизнес планировании. Особенно это касается наименее популярных услуг (Таблица 1).
Таблица 1. Ошибка по подвыборкам потенциальных потребителей услуг торгово-развлекательного центра при выборке 1000 чел.

Чтобы ошибка в самой малочисленной подвыборке «Ночной клуб» составила меньше 5%, объем выборки исследования должен составлять около 4000 человек. Но это будет означать 4-кратное удорожание проекта. В таких случаях возможно компромиссное решение:
- увеличение выборки до 1800 человек, что даст достаточную точность для 6 самых популярных видов услуг (от кинотеатра до парка аттракционов);
- добор 200-300 пользователей менее популярных услуг с опросом по укороченной анкете (см. Таблицу 2).
Таблица 2. Разница в ошибке выборки по подвыборкам при разных объемах выборки.

При обсуждении с исследовательским агентством точности результатов планируемого исследования рекомендуется принимать во внимание бюджет, требования к точности результатов в целом по выборке и в разрезе подгрупп. Если бюджет не позволяет получить информацию с приемлемой ошибкой, лучше пока отложить проект (или поторговаться).
КАЛЬКУЛЯТОРЫ ДЛЯ РАСЧЕТА СТАТИСТИЧЕСКИХ ПОКАЗАТЕЛЕЙ И ОПРЕДЕЛЕНИЯ ЗНАЧИМОСТИ РАЗЛИЧИЙ:
КАЛЬКУЛЯТОР ДЛЯ РАСЧЕТА
ДОСТАТОЧНОГО ОБЪЁМА ВЫБОРКИ
Доверительный уровень:
Ошибка выборки (?):
%
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
РЕЗУЛЬТАТ
Один из важных вопросов, на которые нужно ответить при планировании исследования, — это оптимальный объем выборки. Слишком маленькая выборка не сможет обеспечить приемлемую точность результатов опроса, а слишком большая приведет к лишним расходам.
Онлайн-калькулятор объема выборки поможет рассчитать оптимальный размер выборки, исходя из максимально приемлемого для исследователя размера ошибки выборки.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке!
Формулы для других типов выборки отличаются.
Объем выборки рассчитывается по следующим формулам
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели соков и нектаров, постоянно проживающие в Москве и Московской области). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален. В данном калькуляторе значения p и q по умолчанию равны 0,5.
Δ– предельная ошибка выборки (для доли признака), приемлемая для исследователя. Считается, что для принятия бизнес-решений ошибка выборки не должна превышать 4%.
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании.
ПРИМЕР РАСЧЕТА ОБЪЕМА ВЫБОРКИ:
Допустим, мы хотим рассчитать объем выборки, предельная ошибка которой составит 4%. Мы принимаем доверительный уровень, равный 95%. Генеральная совокупность значительно больше выборки. Тогда объем выборки составит:
n = 1,96 * 1,96 * 0,5 * 0,5 / (0,04 * 0,04) = 600,25 ≈ 600 человек
Таким образом, если мы хотим получить результаты с предельной ошибкой 4%, нам нужно опросить 600 человек.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Доля признака (p):
%
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для доли признака рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели шоколада, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален.
Δ– предельная ошибка выборки.
Таким образом, зная объем выборки исследования, мы можем заранее оценить показатель ее ошибки.
А получив значение p, мы можем рассчитать доверительный интервал для доли признака: (p — ∆; p + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА:
Например, в ходе исследования были опрошены 1000 человек (n=1000). 20% из них заинтересовались новым продуктом (p=0,2). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * КОРЕНЬ (0,2*0,8/1000) = 0,0248 = ±2,48%
Рассчитаем доверительный интервал:
(p — ∆; p + ∆) = (20% — 2,48%; 20% + 2,48%) = (17,52%; 22,48%)
Таким образом, с вероятностью 95% мы можем быть уверены, что реальная доля заинтересованных в новом продукте (среди всей генеральной совокупности) находится в пределах полученного диапазона (17,52%; 22,48%).
Если бы мы выбрали доверительный уровень, равный 99%, то для тех же значений p и n ошибка выборки была бы больше, а доверительный интервал – шире. Это логично, поскольку, если мы хотим быть более уверены в том, что наш доверительный интервал «накроет» реальное значение признака, то интервал должен быть более широким.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Среднее значение (x̄):
Стандартное отклонение (s):
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для среднего значения рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:

(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели мороженого, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
s — выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:

где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Δ– предельная ошибка выборки.
Зная среднее значение показателя x ̅ и ошибку ∆, мы можем рассчитать доверительный интервал для среднего значения:(x ̅ — ∆; x ̅ + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ:
Например, в ходе исследования были опрошены 1000 человек (n=1000). Каждого из них попросили указать их примерную среднюю сумму покупки (средний чек) в известной сети магазинов. Среднее арифметическое всех ответов составило 500 руб. (x ̅=500), а стандартное отклонение составило 120 руб. (s=120). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * 120 / КОРЕНЬ (1000) = 7,44
Рассчитаем доверительный интервал:
(x ̅ — ∆; x ̅ + ∆) = (500 – 7,44; 500 + 7,44) = (492,56; 507,44)
Таким образом, с вероятностью 95% мы можем быть уверены, что значение среднего чека по всей генеральной совокупности находится в границах полученного диапазона: от 492,56 руб. до 507,44 руб.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ ДОЛЕЙ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Доля признака (p): | % | % |
| Объём выборки (n): |
РЕЗУЛЬТАТ
Если в прошлогоднем исследовании вашу марку вспомнили 10% респондентов, а в исследовании текущего года – 15%, не спешите открывать шампанское, пока не воспользуетесь нашим онлайн-калькулятором для оценки статистической значимости различий.
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для долей. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Произведения n*p и n*(1-p), где n=размер выборки а p=доля признака, – не меньше 5.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Доля признака (p) – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ СРЕДНИХ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Среднее значение (x̄): | ||
| Стандартное отклонение (s): | ||
| Объём выборки (n): |
РЕЗУЛЬТАТ
Допустим, выборочный опрос посетителей двух разных ТРЦ показал, что средний чек в одном из них равен 1000 рублей, а в другом – 1200 рублей. Следует ли отсюда вывод, что суммы среднего чека в двух этих ТРЦ действительно отличаются?
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для средних значений. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Распределения значений в выборках близки к нормальному распределению.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Среднее значение ( ̅x) – среднее арифметическое показателя.
Стандартное отклонение (s) – выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:
где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
Вы можете подписаться на уведомления о новых материалах СканМаркет
11.2. Оценка результатов выборочного наблюдения
11.2.1. Средняя и предельная ошибки выборки. Построение доверительных границ для средней и доли
Средняя ошибка выборки показывает, насколько отклоняется в среднем параметр выборочной совокупности от соответствующего параметра генеральной. Если рассчитать среднюю из ошибок всех возможных выборок определенного вида заданного объема (n), извлеченных из одной и той же генеральной совокупности, то получим их обобщающую характеристику — среднюю ошибку выборки ( ).
).
В теории выборочного наблюдения выведены формулы для определения , которые индивидуальны для разных способов отбора (повторного и бесповторного), типов используемых выборок и видов оцениваемых статистических показателей.
Например, если применяется повторная собственно случайная выборка, то определяется как:
 — при оценивании среднего значения признака;
— при оценивании среднего значения признака;
 — если признак альтернативный, и оценивается доля.
— если признак альтернативный, и оценивается доля.
При бесповторном собственно случайном отборе в формулы вносится поправка (1 — n/N):
 — для среднего значения признака;
— для среднего значения признака;
 — для доли.
— для доли.
Вероятность получения именно такой величины ошибки всегда равна 0,683. На практике же предпочитают получать данные с большей вероятностью, но это приводит к возрастанию величины ошибки выборки.
Предельная ошибка выборки ( ) равна t-кратному числу средних ошибок выборки (в теории выборки принято коэффициент t называть коэффициентом доверия):
) равна t-кратному числу средних ошибок выборки (в теории выборки принято коэффициент t называть коэффициентом доверия):
 .
.
Если ошибку выборки увеличить в два раза (t = 2), то получим гораздо большую вероятность того, что она не превысит определенного предела (в нашем случае — двойной средней ошибки) — 0,954. Если взять t = 3, то доверительная вероятность составит 0,997 — практически достоверность.
Уровень предельной ошибки выборки зависит от следующих факторов:
- степени вариации единиц генеральной совокупности;
- объема выборки;
- выбранных схем отбора (бесповторный отбор дает меньшую величину ошибки);
- уровня доверительной вероятности.
Если объем выборки больше 30, то значение t определяется по таблице нормального распределения, если меньше — по таблице распределения Стьюдента.
Приведем некоторые значения коэффициента доверия из таблицы нормального распределения.
| Значение доверительной вероятности P | 0,683 | 0,954 | 0,997 |
|---|---|---|---|
| Значение коэффициента доверия t | 1,0 | 2,0 | 3,0 |
Доверительный интервал для среднего значения признака и для доли в генеральной совокупности устанавливается следующим образом:

Итак, определение границ генеральной средней и доли состоит из следующих этапов:
Ошибки выборки при различных видах отбора
- Собственно случайная и механическая выборка. Средняя ошибка собственно случайной и механической выборки находятся по формулам, представленным в табл. 11.3.
 |
|
где |
Пример 11.2. Для изучения уровня фондоотдачи было проведено выборочное обследование 90 предприятий из 225 методом случайной повторной выборки, в результате которого получены данные, представленные в таблице.
| Уровень фондоотдачи, руб. | До 1,4 | 1,4-1,6 | 1,6-1,8 | 1,8-2,0 | 2,0-2,2 | 2,2 и выше | Итого |
|---|---|---|---|---|---|---|---|
| Количество предприятий | 13 | 15 | 17 | 15 | 16 | 14 | 90 |
В рассматриваемом примере имеем 40%-ную выборку (90 : 225 = 0,4, или 40%). Определим ее предельную ошибку и границы для среднего значения признака в генеральной совокупности по шагам алгоритма:
- По результатам выборочного обследования рассчитаем среднее значение и дисперсию в выборочной совокупности:
| Результаты наблюдения | Расчетные значения | |||
|---|---|---|---|---|
| уровень фондоотдачи, руб., xi | количество предприятий, fi | середина интервала, xixb4 | xixb4fi | xixb42fi |
| До 1,4 | 13 | 1,3 | 16,9 | 21,97 |
| 1,4-1,6 | 15 | 1,5 | 22,5 | 33,75 |
| 1,6-1,8 | 17 | 1,7 | 28,9 | 49,13 |
| 1,8-2,0 | 15 | 1,9 | 28,5 | 54,15 |
| 2,0-2,2 | 16 | 2,1 | 33,6 | 70,56 |
| 2,2 и выше | 14 | 2,3 | 32,2 | 74,06 |
| Итого | 90 | — | 162,6 | 303,62 |
Выборочная средняя

Выборочная дисперсия изучаемого признака

- Определяем среднюю ошибку повторной случайной выборки

- Зададим вероятность, на уровне которой будем говорить о величине предельной ошибки выборки. Чаще всего она принимается равной 0,999; 0,997; 0,954.
Для наших данных определим предельную ошибку выборки, например, с вероятностью 0,954. По таблице значений вероятности функции нормального распределения (см. выдержку из нее, приведенную в Приложении 1) находим величину коэффициента доверия t, соответствующего вероятности 0,954. При вероятности 0,954 коэффициент t равен 2.
- Предельная ошибка выборки с вероятностью 0,954 равна

- Найдем доверительные границы для среднего значения уровня фондоотдачи в генеральной совокупности

Таким образом, в 954 случаях из 1000 среднее значение фондоотдачи будет не выше 1,88 руб. и не ниже 1,74 руб.
Выше была использована повторная схема случайного отбора. Посмотрим, изменятся ли результаты обследования, если предположить, что отбор осуществлялся по схеме бесповторного отбора. В этом случае расчет средней ошибки проводится по формуле

Тогда при вероятности равной 0,954 величина предельной ошибки выборки составит:

Доверительные границы для среднего значения признака при бесповторном случайном отборе будут иметь следующие значения:

Сравнив результаты двух схем отбора, можно сделать вывод о том, что применение бесповторной случайной выборки дает более точные результаты по сравнению с применением повторного отбора при одной и той же доверительной вероятности. При этом, чем больше объем выборки, тем существеннее сужаются границы значений средней при переходе от одной схемы отбора к другой.
По данным примера определим, в каких границах находится доля предприятий с уровнем фондоотдачи, не превышающим значения 2,0 руб., в генеральной совокупности:
- рассчитаем выборочную долю.
Количество предприятий в выборке с уровнем фондоотдачи, не превышающим значения 2,0 руб., составляет 60 единиц. Тогда
m = 60, n = 90, w = m/n = 60 : 90 = 0,667;
- рассчитаем дисперсию доли в выборочной совокупности
 ;
;
- средняя ошибка выборки при использовании повторной схемы отбора составит

Если предположить, что была использована бесповторная схема отбора, то средняя ошибка выборки с учетом поправки на конечность совокупности составит

- зададим доверительную вероятность и определим предельную ошибку выборки.
При значении вероятности Р = 0,997 по таблице нормального распределения получаем значение для коэффициента доверия t = 3 (см. выдержку из нее, приведенную в Приложении 1):

- установим границы для генеральной доли с вероятностью 0,997:

Таким образом, с вероятностью 0,997 можно утверждать, что в генеральной совокупности доля предприятий с уровнем фондоотдачи, не превышающим значения 2,0 руб., не меньше, чем 54,7%, и не больше 78,7%.
- Типическая выборка. При типической выборке генеральная совокупность объектов разбита на k групп, тогда
N1 + N2 + … + Ni + … + Nk = N.
Объем извлекаемых из каждой типической группы единиц зависит от принятого способа отбора; их общее количество образует необходимый объем выборки
n1 + n2 + … + ni + … + nk = n.
Существуют следующие два способа организации отбора внутри типической группы: пропорциональной объему типических групп и пропорциональной степени колеблемости значений признака у единиц наблюдения в группах. Рассмотрим первый из них, как наиболее часто используемый.
Отбор, пропорциональный объему типических групп, предполагает, что в каждой из них будет отобрано следующее число единиц совокупности:
n = ni · Ni/N
где ni — количество извлекаемых единиц для выборки из i-й типической группы;
n — общий объем выборки;
Ni — количество единиц генеральной совокупности, составивших i-ю типическую группу;
N — общее количество единиц генеральной совокупности.
Отбор единиц внутри групп происходит в виде случайной или механической выборки.
Формулы для оценивания средней ошибки выборки для среднего и доли представлены в табл. 11.6.

|
 ) при использовании типического отбора, пропорционального объему типических групп
) при использовании типического отбора, пропорционального объему типических группЗдесь  — средняя из групповых дисперсий типических групп.
— средняя из групповых дисперсий типических групп.
Пример 11.3. В одном из московских вузов проведено выборочное обследование студентов с целью определения показателя средней посещаемости вузовской библиотеки одним студентом за семестр. Для этого была использована 5%-ная бесповторная типическая выборка, типические группы которой соответствуют номеру курса. При отборе, пропорциональном объему типических групп, получены следующие данные:
| Номер курса | Всего студентов, чел., Ni | Обследовано в результате выборочного наблюдения, чел., ni | Среднее число посещений библиотеки одним студентом за семестр, xi | Внутригрупповая выборочная дисперсия, 
|
|---|---|---|---|---|
| 1 | 650 | 33 | 11 | 6 |
| 2 | 610 | 31 | 8 | 15 |
| 3 | 580 | 29 | 5 | 18 |
| 4 | 360 | 18 | 6 | 24 |
| 5 | 350 | 17 | 10 | 12 |
| Итого | 2 550 | 128 | 8 | — |
Число студентов, которое необходимо обследовать на каждом курсе, рассчитаем следующим образом:
- общий объем выборочной совокупности:
n = 2550/130*5 =128 (чел.);
- количество единиц, отобранных из каждой типической группы:

аналогично для других групп:
n2 = 31 (чел.);
n3 = 29 (чел.);
n4 = 18 (чел.);
n5 = 17 (чел.).
Проведем необходимые расчеты.
- Выборочная средняя, исходя из значений средних типических групп, составит:

- Средняя из внутригрупповых дисперсий

- Средняя ошибка выборки:

С вероятностью 0,954 находим предельную ошибку выборки:

- Доверительные границы для среднего значения признака в генеральной совокупности:

Таким образом, с вероятностью 0,954 можно утверждать, что один студент за семестр посещает вузовскую библиотеку в среднем от семи до девяти раз.
- Малая выборка. В связи с небольшим объемом выборочной совокупности те формулы для определения ошибок выборки, которые использовались нами ранее при «больших» выборках, становятся неподходящими и требуют корректировки.
Среднюю ошибку малой выборки определяют по формуле

Предельная ошибка малой выборки:

Распределение значений выборочных средних всегда имеет нормальный закон распределения (или приближается к нему) при п > 100, независимо от характера распределения генеральной совокупности. Однако в случае малых выборок действует иной закон распределения — распределение Стьюдента. В этом случае коэффициент доверия находится по таблице t-распределения Стьюдента в зависимости от величины доверительной вероятности Р и объема выборки п. В Приложении 1 приводится фрагмент таблицы t-распределения Стьюдента, представленной в виде зависимости доверительной вероятности от объема выборки и коэффициента доверия t.
Пример 11.4. Предположим, что выборочное обследование восьми студентов академии показало, что на подготовку к контрольной работе по статистике они затратили следующее количество часов: 8,5; 8,0; 7,8; 9,0; 7,2; 6,2; 8,4; 6,6.
Оценим выборочные средние затраты времени и построим доверительный интервал для среднего значения признака в генеральной совокупности, приняв доверительную вероятность равной 0,95.
- Среднее значение признака в выборке равно

- Значение среднего квадратического отклонения составляет

- Средняя ошибка выборки:

- Значение коэффициента доверия t = 2,365 для п = 8 и Р = 0,95 .
- Предельная ошибка выборки:

- Доверительный интервал для среднего значения признака в генеральной совокупности:

То есть с вероятностью 0,95 можно утверждать, что затраты времени студента на подготовку к контрольной работе находятся в пределах от 6,9 до 8,5 ч.
11.2.2. Определение численности выборочной совокупности
Перед непосредственным проведением выборочного наблюдения всегда решается вопрос, сколько единиц исследуемой совокупности необходимо отобрать для обследования. Формулы для определения численности выборки выводят из формул предельных ошибок выборки в соответствии со следующими исходными положениями (табл. 11.7):
- вид предполагаемой выборки;
- способ отбора (повторный или бесповторный);
- выбор оцениваемого параметра (среднего значения признака или доли).
Кроме того, следует заранее определиться со значением доверительной вероятности, устраивающей потребителя информации, и с размером допустимой предельной ошибки выборки.
 |
Примечание: при использовании приведенных в таблице формул рекомендуется получаемую численность выборки округлять в большую сторону для обеспечения некоторого запаса в точности.
Пример 11.5. Рассчитаем, сколько из 507 промышленных предприятий следует проверить налоговой инспекции, чтобы с вероятностью 0,997 определить долю предприятий с нарушениями в уплате налогов. По данным прошлого аналогичного обследования величина среднего квадратического отклонения составила 0,15; размер ошибки выборки предполагается получить не выше, чем 0,05.
При использовании повторного случайного отбора следует проверить

При бесповторном случайном отборе потребуется проверить

Как видим, использование бесповторного отбора позволяет проводить обследование гораздо меньшего числа объектов.
Пример 11.6. Планируется провести обследование заработной платы на предприятиях отрасли методом случайного бесповторного отбора. Какова должна быть численность выборочной совокупности, если на момент обследования в отрасли число занятых составляло 100 000 чел.? Предельная ошибка выборки не должна превышать 100 руб. с вероятностью 0,954. По результатам предыдущих обследований заработной платы в отрасли известно, что среднее квадратическое отклонение составляет 500 руб.

Следовательно, для решения поставленной задачи необходимо включить в выборку не менее 100 человек.