Когда вы, наконец, настроили источники данных и формируете данные именно так, как вам нужно, это очень важно. Надеемся, что при обновлении данных из внешнего источника данные будут проходить плавно. Но это не всегда так. Изменение потока данных на этом пути может привести к проблемам, которые при попытке обновить данные могут стать ошибками. Некоторые ошибки может быть легко исправить, некоторые из них могут быть временными, а некоторые трудно диагностировать. Вот что следует сделать, это набор стратегий, которые можно использовать для обработки ошибок, которые вам последуют.
При обновлении данных могут возникать ошибки двух типов.
Местных Если в книге Excel возникает ошибка, по крайней мере, ваши усилия по устранению неполадок ограничены и ими можно управлять. Возможно, обновленные данные вызывали ошибку с функцией или создавали недопустимые условия в списке. Эти ошибки надоедливы, но их довольно просто отслеживать, определять и исправлять. Excel улучшена обработка ошибок с помощью более понятных сообщений и контекстных ссылок на целевые разделы справки, которые помогут вам разобраться и устранить проблему.
Удаленного Однако ошибки, которые приходят из удаленного внешнего источника данных, являются другими. Произошла что-то в системе, которая может быть на улице, на полпути по всему миру или в облаке. Для таких типов ошибок требуется другой подход. Распространенные удаленные ошибки:
-
Не удалось подключиться к службе или ресурсу. Проверьте подключение.
-
Не удалось найти файл, к который вы пытаетесь получить доступ.
-
Сервер не отвечает и, возможно, находится в состоянии обслуживания.
-
Это содержимое не доступно. Возможно, он был удален или временно недоступен.
-
Подождите… данные загружаются.
Вот несколько советов, которые помогут вам справиться с ошибками, которые могут возникнуть.
Поиск и сохранение конкретной ошибки Сначала проверьте области Запросы & connections (Выберите Data > Queries & Connections, выберите подключение, а затем отобразите вылет). Узнайте, какие ошибки произошли при доступе к данным, и обратите внимание на дополнительные сведения. Затем откройте запрос, чтобы увидеть все конкретные ошибки в каждом шаге запроса. Все ошибки отображаются на желтом фоне для удобной идентификации. Запишите сообщение об ошибке или запишите ее на экране, даже если вы не полностью понимаете ее. Коллега, администратор или служба поддержки в вашей организации могут помочь вам понять, что произошло, и предложить решение. Дополнительные сведения см. в теме Работа с ошибками в Power Query.
Получить сведения о справке На сайте Office справки и обучения. Она не только содержит большой объем справки, но и сведения об устранении неполадок. Дополнительные сведения см. в устранении и обходных решениях недавних проблем в Excel для Windows.
Использование технического сообщества Используйте веб-Community Майкрософт для поиска обсуждений, относящихся к вашей проблеме. Весьма вероятно, что вы не первый, кто испытывает проблему, другие люди занимаются ее решением и даже могут найти решение. Дополнительные сведения см. в Microsoft Excel Community и Office Answers Community.
Поиск в Интернете Используйте предпочитаемую поисковую система для поиска дополнительных сайтов в Интернете, которые могут предоставлять обсуждения или подсказки. Это может быть отнимает много времени, но это может привести к более широкой сети для того, чтобы найти ответы на наиболее сложные вопросы.
Обратитесь в Office поддержки На этом этапе, скорее всего, вы понимаете проблему гораздо лучше. Это поможет вам сосредоточиться на беседе и сократить время, затраченное на поддержку Майкрософт. Дополнительные сведения см. в Microsoft 365 и Office службе поддержки клиентов.
Возможно, вам не удастся устранить проблему, но вы можете точно определить, в чем заключается проблема, чтобы помочь другим понять ситуацию и решить ее за вас.
Проблемы со службами и серверами Скорее всего, причина — периодические ошибки сети и связи. Лучше всего подождите и попробуйте еще раз. Иногда проблема просто утихает.
Изменения расположения или доступности База данных или файл были перемещены, повреждены, переведены в автономный режим на обслуживание или аварийно сбой базы данных. Дисковые устройства могут быть повреждены, а файлы будут потеряны. Дополнительные сведения см. в этой Windows 10.
Изменения в проверке подлинности и конфиденциальности Неожиданно может произойти, что разрешение больше не работает или в параметр конфиденциальности было внося изменение. Оба события могут препятствовать доступу к внешнему источнику данных. Обратитесь к администратору или администратору внешнего источника данных, чтобы узнать, что изменилось. Дополнительные сведения см. в настройкахи разрешениях источника данных и Настройка уровней конфиденциальности.
Открытые или заблокированные файлы Если открыт текст, CSV или книга, изменения, внесенные в файл, не включаются в обновление до тех пор, пока файл не будет сохранен. Кроме того, если файл открыт, он может быть заблокирован и к нему нельзя получить доступ, пока он не будет закрыт. Это может произойти, если другой человек использует версию Excel. Попросите их закрыть файл или проверить его. Дополнительные сведения см. в статьи Разблокировкафайла, заблокированного для редактирования.
Изменения схем на заднем Кто-то изменяет имя таблицы, имя столбца или тип данных. Это почти никогда не разумно, может иметь огромное влияние и особенно опасно для баз данных. Одной из них является то, что группа управления базами данных наила правильные средства контроля, чтобы избежать этого, но происходят спапцы.
Блокирование ошибок при сложении запросов Power Query пытается повысить производительность, когда это возможно. Для более производительности и емкости часто бывает лучше выполнить запрос к базе данных на сервере. Этот процесс называется сгибом запроса. Тем не менее Power Query блокирует запрос, если существует вероятность компрометации данных. Например, слияние определено между таблицей книги и SQL Server таблицей. Для конфиденциальности данных книги за установлено SQL Server конфиденциальность данных организации. Поскольку политика конфиденциальности является более строгой, чем в организации, Power Query блокирует обмен информацией между источниками данных. Сгиб запроса происходит за кадром, поэтому вас может удивить, когда возникает ошибка блокировки. Дополнительные сведения см. взадачах Основные сведения о сгибе запросов, Сгибзапросов и Сгиб с помощью диагностики запросов.
Часто с помощью Power Query вы можете точно определить, в чем заключается проблема, и устранить ее самостоятельно.
Переименованные таблицы и столбцы Изменения исходных имен таблиц и столбцов или столбцов почти наверняка приводят к проблемам при обновлении данных. Запросы используют имена таблиц и столбцов для формировать данные практически на каждом этапе. Не изменяйте или удаляйте исходные имена таблиц и столбцов, если только их не нужно использовать в источнике данных.
Изменения типов данных Изменение типа данных иногда может привести к ошибкам или непредвиденным результатам, особенно в функциях, для которых в аргументах требуется определенный тип данных. Примерами могут быть замена текстового типа данных в числовой функции или попытка вычисления с нечисловой типом данных. Дополнительные сведения см. в теме Добавление и изменение типов данных.
Ошибки уровня ячейки Такие типы ошибок не предотвращают загрузку запроса, но отображают в ячейке сообщение Ошибка. Чтобы увидеть сообщение, выберите whitespace в ячейке таблицы, содержащей ошибку. Вы можете удалить, заменить или просто сохранить ошибки. Примеры ошибок в ячейках:
-
Преобразования Вы попытались преобразовать ячейку, содержащую 0, в целое число.
-
Математические Вы пытаетесь умножить текстовое значение на числовое значение.
-
Объединения Вы попытались объединить строки, но одна из них числовая.
Безопасно экспериментируйте и итерации Если вы не уверены, что преобразование может иметь отрицательное влияние, скопируйте запрос, проверьте изменения и итерации с помощью вариантов команды Power Query. Если команда не работает, просто удалите созданное вами шаг и попробуйте еще раз. Чтобы быстро создать образец данных с одной схемой и структурой, создайте Excel таблицу из нескольких столбцов и строк и импортировать их (выберите данные > Из таблицы илидиапазона). Дополнительные сведения см. в таблицах Создание таблицы и Импорт из Excel таблицы.
Когда вы впервые будете понять, что можно делать с данными в редакторе Power Query, вам может показаться, что вы ребенок в конфетном магазине. Но не хочется есть все конфеты. Вы хотите избежать преобразования, которое может непреднамеренно вызывать ошибки обновления. Некоторые операции, например перемещение столбцов в другое место таблицы, не должны приводить к ошибкам в обновлении, так как Power Query отслеживает столбцы по их именам.
Другие операции могут привести к ошибкам обновления. Одним из общих правил может быть ваш световой свет. Не внося существенных изменений в исходные столбцы. Чтобы безопасно воспроизвести столбец, скопируйте исходный столбец с командой(Добавитьстолбец, Настраиваемый столбец, Дублировать столбец и так далее), а затем внести изменения в скопированную версию исходного столбца. Вот операции, которые иногда могут привести к ошибкам обновления, и некоторые из лучших методик, которые помогут ухладить работу.
|
Операции |
Руководство |
|---|---|
|
Фильтрации |
Повышение эффективности за счет максимально ранней фильтрации данных в запросе и удаления ненужных данных для уменьшения лишней обработки. Кроме того, с помощью автофильтра можно искать или выбирать определенные значения, а также использовать фильтры для определенных типов, доступные в столбцах даты, даты и времени и времени (например, Месяц,Неделя,День). |
|
Типы данных и заглавные колонок столбцов |
Power Query автоматически добавляет в запрос два шага сразу после первого шага: «Продвиганые заглавные колонок», которая преобразует первую строку таблицы в заглавный, и Changed Type(Измененный тип), который преобразует значения из типа Данных Any в тип данных на основе проверки значений из каждого столбца. Это удобно, но иногда может потребоваться явно контролировать это поведение, чтобы предотвратить ошибки случайного обновления. Дополнительные сведения см. в статьях Добавление и изменение типов данных и Повысить или понизить их в строках и столбцах. |
|
Переименование столбца |
Избегайте переименования исходных столбцов. Используйте команду Переименовать для столбцов, добавленных другими командами или действиями. Дополнительные сведения см. в статье Переименование столбца. |
|
Разделить столбец |
Разделение копий исходного столбца, а не исходного столбца. Дополнительные сведения см. в статье Разделение текстового столбца. |
|
Объединение столбцов |
Объединять копии исходных столбцов, а не исходных. Дополнительные сведения см. в статье Объединение столбцов. |
|
Удаление столбца |
Если нужно сохранить небольшое количество столбцов, используйте выбор столбца, чтобы сохранить нужные. Рассмотрим разницу между удалением столбцов и удалением других столбцов. Когда вы удаляете другие столбцы и обновляете данные, новые столбцы, добавленные в источник данных после последнего обновления, могут остаться незащищенными, так как они будут считаться другими столбцы при повторном выполнении в запросе шага Удалить столбец. Такая ситуация не возникает при явном удалите столбец. Наконечник Скрыть столбец (как в Excel) не Excel. Однако если у вас много столбцов и вы хотите скрыть многие из них, чтобы сосредоточиться на своей работе, вы можете сделать следующее: удалить столбцы, запомнить созданный шаг, а затем удалить его перед загрузкой запроса обратно на таблицу. Дополнительные сведения см. в статье Удаление столбцов. |
|
Замена значения |
При замене значения источник данных не редактируется. Вместо этого нужно изменить значения в запросе. При следующем обновлении данных ищемые значения могут немного измениться или перестать быть там, поэтому команда Заменить может не работать так, как планировалось изначально. Дополнительные сведения см. в области Замена значений. |
|
Pivot и Unpivot |
При использовании команды Столбец сводной сводной столбца при сводном столбце может возникнуть ошибка, при этом не агрегируются значения, но возвращается больше одного значения. Такая ситуация может возникнуть после операции обновления, которая меняет данные несмежным образом. Используйте команду Открепить другие столбцы, если известны не все столбцы и вы хотите, чтобы новые столбцы, добавленные во время обновления, также были неотвечены. Используйте команду Открепить только выбранный столбец, если вы не знаете количество столбцов в источнике данных и хотите, чтобы выбранные столбцы оставались неотвеченными после обновления. Дополнительные сведения см. в статьях Сводные столбцы и Ото всех столбцов. |
Предотвращение ошибок Если внешним источником данных управляет другая группа в организации, им необходимо знать о вашей зависимости от них и избегать изменений в их системах, которые могут привести к проблемам ниже. Фиксировать влияние на данные, отчеты, диаграммы и другие артефакты, которые зависят от данных. Настройте линии связи, чтобы убедиться в том, что они понимают последствия, и примите необходимые меры, чтобы обеспечить бесперебойную работу. Находите способы создания элементов управления, которые минимизируют ненужные изменения и предугадать последствия необходимых изменений. Конечно, это легко сказать и иногда сложно сделать.
Future-proof with query parameters Используйте параметры запроса для уменьшения изменений, например расположения данных. Вы можете создать параметр запроса, чтобы заменить новое расположение, например путь к папке, имя файла или URL-адрес. Существуют и другие способы уменьшения проблем с помощью параметров запроса. Дополнительные сведения см. в теме Создание запроса с параметрами.
См. также
Справка по Power Query для Excel
Методики работы с Power Query (docs.com)
- Remove From My Forums
-
Question
-
Hi
I am using PQ in quite a few models but am experiencing the above error and lack of data in two specifically which are fired by task scheduler and VBA code runs under a Workbook_Open() event. ‘Background Refresh’, ‘Refresh on opening workbook’ and ‘refresh
connection on refresh all’ are all switched OFF and my code iterates the connections refreshing each one explicitly. The two scenarios are:- (Fired once a day) A two query model fetching data from a SQL server and comparing that to file names in a folder structure (Making sure the SQL Server and folder files are in sync). It works fine when right clicking the queries in PQ and refreshing but
when opened though automation are left ‘hanging’ with the ‘Download did not complete’ error alongside each one. These load directly to the worksheet - (Fired every 15 minutes), connects to an html document on the server (a licence file created by the ERP system), parses it and loads to the worksheet. Same thing, the workbook_open() event fires but the query never seems to complete. If I open manually
and right-click, refreshes fine and quickly
Any advice as to how I may get these working would be greatly appreaciated
- (Fired once a day) A two query model fetching data from a SQL server and comparing that to file names in a folder structure (Making sure the SQL Server and folder files are in sync). It works fine when right clicking the queries in PQ and refreshing but
Answers
-
I see. One other thing to try is to use the Application.OnTime function to schedule calling Workbook.Save() and Application.Quit() some time after the AfterCalculate event, rather than immediately; this should give both the table and the task pane enough
time to update themselves.-
Proposed as answer by
Monday, March 16, 2015 7:34 AM
-
Marked as answer by
Ed Price — MSFTMicrosoft employee
Monday, March 16, 2015 7:34 AM
-
Proposed as answer by
-
Could You Please, Upload Your Code For More understanding.
Thanks
-
Proposed as answer by
Neelesh P
Wednesday, January 28, 2015 3:06 PM -
Marked as answer by
Ed Price — MSFTMicrosoft employee
Monday, March 16, 2015 7:33 AM
-
Proposed as answer by
- Remove From My Forums
-
Question
-
Hi
I am using PQ in quite a few models but am experiencing the above error and lack of data in two specifically which are fired by task scheduler and VBA code runs under a Workbook_Open() event. ‘Background Refresh’, ‘Refresh on opening workbook’ and ‘refresh
connection on refresh all’ are all switched OFF and my code iterates the connections refreshing each one explicitly. The two scenarios are:- (Fired once a day) A two query model fetching data from a SQL server and comparing that to file names in a folder structure (Making sure the SQL Server and folder files are in sync). It works fine when right clicking the queries in PQ and refreshing but
when opened though automation are left ‘hanging’ with the ‘Download did not complete’ error alongside each one. These load directly to the worksheet - (Fired every 15 minutes), connects to an html document on the server (a licence file created by the ERP system), parses it and loads to the worksheet. Same thing, the workbook_open() event fires but the query never seems to complete. If I open manually
and right-click, refreshes fine and quickly
Any advice as to how I may get these working would be greatly appreaciated
- (Fired once a day) A two query model fetching data from a SQL server and comparing that to file names in a folder structure (Making sure the SQL Server and folder files are in sync). It works fine when right clicking the queries in PQ and refreshing but
Answers
-
I see. One other thing to try is to use the Application.OnTime function to schedule calling Workbook.Save() and Application.Quit() some time after the AfterCalculate event, rather than immediately; this should give both the table and the task pane enough
time to update themselves.-
Proposed as answer by
Monday, March 16, 2015 7:34 AM
-
Marked as answer by
Ed Price — MSFTMicrosoft employee
Monday, March 16, 2015 7:34 AM
-
Proposed as answer by
-
Could You Please, Upload Your Code For More understanding.
Thanks
-
Proposed as answer by
Neelesh P
Wednesday, January 28, 2015 3:06 PM -
Marked as answer by
Ed Price — MSFTMicrosoft employee
Monday, March 16, 2015 7:33 AM
-
Proposed as answer by
- Remove From My Forums
-
Вопрос
-
Применяю FromTable/Range для получения данных, выкладываю эти данные на лист — «Загрузка в лист завершилась ошибкой. Сбой инициализации источника данных»
последовательность моих действий:
— делаю новый файл, заполняю А1 заголовком («Title»), А2 значением («1»)
— делаю (через ленту PowerQuery): «from Table/Range» А1:А2
— в PQ нажимаю «Закрыть и выгрузить»
это приводит к появлению ошибки: «Сбой инициализации источника данных. Проверьте сервер или обратитесь к администратору данных ..»
При этом данные на лист выгружает («Title», «1»). Но не обновляет, выдает ошибкучто и как исправить?
Ответы
-
переустановка PQ и всего MSO не помогла
нашел решение в переустановке Framework — и все заработало!
-
Помечено в качестве ответа
26 апреля 2017 г. 11:00
-
Помечено в качестве ответа
Ловушки/проблемы и ошибки — это ситуации, в которых у нас не получается правильно решить задачу. Для начала определимся, что именно мы будем называть ловушками, что ошибками, а что проблемами.
Ошибки в Power Query
Ошибкой мы будем называть ситуацию, когда появляется сообщение Error. Ошибкой мы будем называть ситуацию именно, когда мы неправильно построили запрос. Пример ошибки на изображении ниже.
Проблемы в Power Query
Проблемой мы будем называть ситуацию, в которой нам нужно составить более уникальный запрос, потому что простое решение не работает. Например, каждую неделю нам присылают примерно одну и ту же Excel-книгу с новыми данными. Вроде бы все хорошо. Количество столбцов и их названия совпадают, но названия листов всегда разные как на картинке ниже.
Вы получили таблицу, обработали ее в Power Query. Проходит неделя. Вы получаете новую книгу, но получаете сообщение об ошибке.
Составлять универсальные запросы для этой и подобных ситуаций мы будем в уроках по проблемам.
Ловушки Power Query
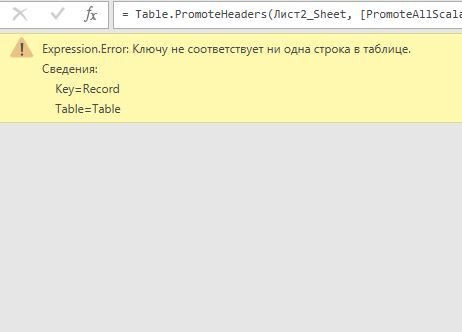
Ловушка — это ситуация, в которой мы что-то не учли. Распространенный пример — это разворот табличного столбца (Table.ExpandTableColumn). Допустим у нас в запросе есть шаг с разворотом табличного столбца. Мы при развороте отметили все столбцы галочками. Через месяц получаем новые данные. Запрос вроде бы работает как надо, но потом ваш руководитель говорит, что отчет неправильный. Вы выясняете, что не так и обнаруживаете в шаге с разворотом столбца такую картину.
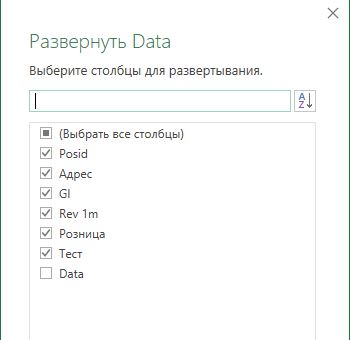
Оказалось, что в новом файле с данными были какие-то новые столбца, которые не разворачиваются. Как быть в этой и других ситуациях мы разберем в уроках по ловушкам.
Это фрагмент книги Гил Равив. Power Query в Excel и Power BI: сбор, объединение и преобразование данных.
Предыдущий раздел К содержанию Следующий раздел
10 ловушек, рассмотренные в этой главе, подробно обсуждаются в блоге автора книги.
Причины и следствия ловушек
В основе редактора Power Query лежат два основополагающих принципа:
- Пользовательский интерфейс переводит шаги в код.
- Предварительный просмотр данных помогает формировать логику преобразования.
Эти принципы весьма удобны, но… они же являются виновниками большинства ошибок, которые приводят к сбоям при обновлении или потере данных. Одна из частых ситуаций, приводящих к сбоям обновления, возникает при изменении имени столбца в исходной таблице. А потеря данных может возникать из-за некорректной фильтрации.
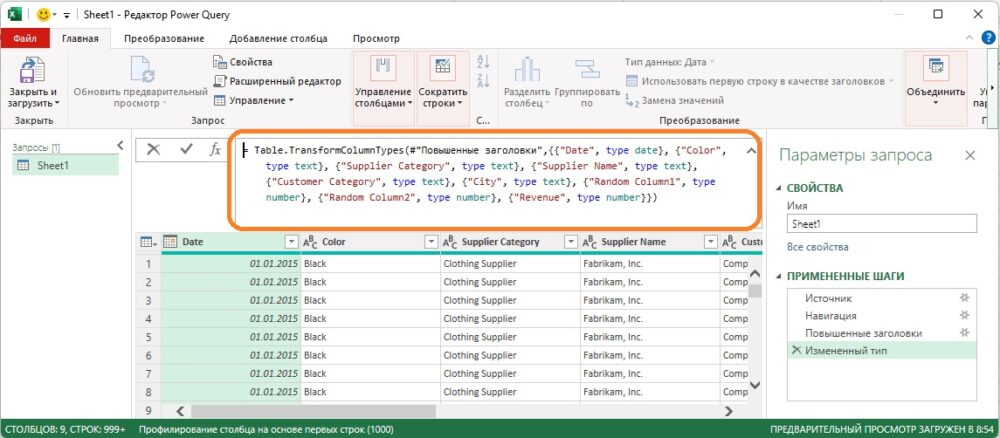
Рис. 1. Жесткая ссылка на имена столбцов; чтобы увеличить изображение кликните на нем правой кнопкой мыши и выберите Открыть картинку в новой вкладке
Скачать заметку в формате Word или pdf, примеры в формате архива (внутри несколько файлов Excel без поддержки макросов)
Прежде чем перейти к подводным камням и методам их преодоления, рассмотрим несколько первоочередных принципов. Эти принципы помогают минимизировать влияние ловушек. Они подразделяются на три темы: осведомленность, лучшие практики, модификация кода.
Осведомленность
Следуйте этим рекомендациям после каждого шага преобразования:
- Убедитесь, что данные на панели предварительного просмотра выглядят правильно. Прокрутите вниз для просмотра большего числа строк. Прокрутите вправо, чтобы увидеть все столбцы.
- Всегда отображайте строку формул. Это имеет решающее значение для предотвращения попадания в ловушки.
- Просмотрите код в строке формул. Обратите внимание на жестко закодированные элементы в формуле, такие как имена и значения столбцов. Например, если удалить столбец Column1 в запросе, то можно заметить в строке формул, что столбец на самом деле назван Column1 (с завершающим пробелом в названии). Если владелец источника данных заметит это, то вполне вероятно сделает исправление, и обновление потерпит неудачу. Просмотр строки формул повысит вашу осведомленность и позволит предотвратить сбои в будущем.
Лучшие практики
Придерживайтесь нескольких хорошо зарекомендовавших себя методик:
- Сохраняйте копии отчета до обновления. Если произошел сбой при обновлении можно сравнить отчеты и выявить причину сбоев.
- Общайтесь с коллегами, предоставляющими внешние данные. Убедитесь, что коллеги осведомлены о ваших отчетах, взаимодействуйте с ними, чтобы они знали, что их работа является частью вашей отчетности.
- Некоторых ловушек можно избежать, сделав правильный выбор операции (например, удаление столбца) или, наоборот, избегая выполнения некоторых ненужных преобразований (например, изменение типа или порядка столбцов).
Модификации кода
Имеется ряд модификаций, которые можно выполнить на уровне формул для создания надежных запросов. И хотя существует множество таких модификаций, наиболее распространенный способ основан на функции Table.ColumnNames. Она позволяет преобразовать ссылку на жестко закодированное имя столбца в динамическую ссылку, которая не дает сбоев.
Ловушка 1. Игнорирование строки формул
Если в редакторе PQ строка формул не активна, пройдите Просмотр –> Строка формул. С помощью строки формул легко обнаружить статические ссылок на имена столбцов. Загрузите файл C10E01.xlsx и сохраните его в папке C:DataC10. Откройте новую книгу Excel. Пройдите Данные –> Получить данные –> Из файла –> Из книги.
Выберите файл C10E01.xlsx и щелкните Импорт. В окне Навигатор выберите Shit1, кликните Преобразовать данные (см. рис. 1). В редакторе PQ в строке формул видно, что шаг Измененный тип ссылается на имена столбцов. Эти значения имен – именно то, что следует искать в строке формул, если желаете избежать ловушек.
Видно, что имеются два столбца с именами Random Column1 и Random Column2. Предположим, что эти столбцы содержат случайные числа, и они не нужны в вашем отчете. В реальных сценариях вы встретите имена столбцов, которые могут иметь произвольный или временный контекст. Можно сохранить их в отчете или удалить, но на шаге Измененный тип становится ясно, что код уже жестко запрограммирован со ссылкой на эти столбцы. Если эти столбцы не важны, то велика вероятность, что в будущем вы не найдете их в исходной таблице, поскольку владелец внешнего источника данных может их удалить.
Пройдите Главная –> Закрыть и загрузить. Сохраните файл под именем C10E01 — Solution.xlsx. Откройте файл C10E01.xlsx и удалите столбцы Random Column1 и Random Column2. Сохраните файл C10E01.xlsx. Вернитесь к файлу C10E01 — Solution.xlsx. Пройдите Данные –> Обновить всё. Обновление завершится ошибкой:
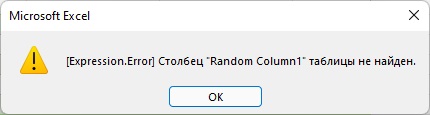
Рис. 2. Ошибка обновления
Как можно справиться с описанным сценарием с помощью трех основных принципов, упомянутых ранее: осведомленность, лучшие практики и модификации кода? Изучив строку формул, вы увидите, что названия столбцов жестко закодированы. Вы можете обратиться к владельцам данных и сообщить им о существовании таких столбцов. Попросить их не изменять структуру данных или информировать вас, если они удалят или переименуют.
Наверное, самое эффективное – удалить части формулы:
|
{«Random Column1», type number}, {«Random Column2», type number}, |
Вот более надежная версия формулы, которая игнорирует случайные столбцы:
|
= Table.TransformColumnTypes( #»Повышенные заголовки», { {«Date», type date}, {«Color», type text}, {«Supplier Category», type text}, {«Supplier Name», type text}, {«Customer Category», type text}, {«City», type text}, {«Revenue», type number} } ) |
В этой формуле всё еще имеется множество столбцов, которые могут быть удалены или переименованы в будущем. Действительно ли нужно ссылаться на все эти столбцы? Это – суть второй ловушки.
Ловушка 2. Измененные типы
Чтобы избежать второй ловушки обратитесь к шагу Измененный тип, который был создан автоматически. Самое простое и наиболее распространенное решение, позволяющее избежать этой ловушки, состоит в удалении шага Измененный тип.
Уточним, в чем состоит суть проблемы. Вам иногда необходимы правильные типы столбцов. Без определения типов в некоторых столбцах нельзя выполнять арифметические операции или операции с датами. Учитывая это обстоятельство, редактор Power Query неявно определяет типы всех столбцов в таблице. При отсутствии этого автоматического шага, если вы забудете явно изменить тип, то не сможете, например, рассчитать сумму по столбцу. Вместо того чтобы использовать автоматический шаг Измененный тип, удалите его и задайте типы вручную.
«Чем позже, тем лучше» – полезный девиз для изменения типов в Power Query. Рекомендуется изменять типы столбцов в редакторе Power Query, а не полагаться на автоматический шаг Измененный тип, и чем позже вы явно измените типы, тем лучше.
Изменяя тип на последнем шаге сценария, вы получите следующие преимущества:
- Изменение типа требует определенных вычислительных усилий. Если вы уменьшите число строк (применяя фильтры), то сократите время обновления запроса, выполняя изменение типа после шага фильтрации.
- Изменение типов может привести к ошибкам из-за того, что в ячейках содержатся значения, которые невозможно преобразовать в новый тип. Чем позже подобные ошибки появятся в цепочке этапов преобразования, тем проще их устранить. (Пример ошибки, которую трудно обнаружить из-за применения шага Измененный тип на раннем этапе, описывается в заметке.)
- Изменение типа на ранних стадиях может не сохраняться в некоторых сценариях. Например, если добавить все файлы из папки, то изменение типа, выполненное на уровне образца запроса, не распространяется на добавленные результаты.
Power Query позволяет отключать автоопределение и изменение типов, но сделать это можно лишь для текущего файла Excel. Опции глобальной настройки нет. В редакторе Power Query пройдите Файл –> Параметры и настройки –> Параметры запроса. Снимите галку Определять типы и заголовки столбцов для неструктурированных источников.
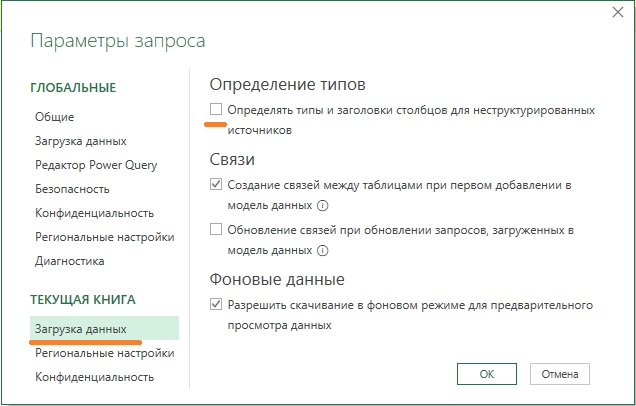
Рис. 3. Отключите автоматическую проверку и изменение типов
Теперь вы должны постоянно помнить и изменять типы данных вручную. Это относится ко всем нетекстовым столбцам. В нашем примере необходимо изменить типы столбцов Date и Revenue. Это можно также сделать, отредактировав автоматически созданный шаг Измененный тип:
|
= Table.TransformColumnTypes( #»Повышенные заголовки», { {«Date», type date}, {«Revenue», type number} } ) |
Если выполняется обработка таблиц, которые включают большое число столбцов для выполнения явного преобразования типов и возникает необходимость в автоматическом способе определения типов столбцов без ссылки на имена столбцов, удобное выражение M можно найти в следующей заметке.
Ловушка 3. Небезопасная фильтрация
Рассмотрим базовый сценарий, демонстрирующий ошибку фильтрации. Допустим, вас попросили проанализировать влияние на бизнес прекращения импорта товаров, окрашенных в черный цвет. Поэтому необходимо отфильтровать запрос и выбрать товары, окрашенные не в черный цвет.
Откройте новую книгу Excel. Пройдите Данные –> Получить данные –> Из файла –> Из книги. Выберите файл C10E01.xlsx и щелкните Импорт. В окне Навигатор выберите Sheet1, кликните Преобразовать данные. Удалите шаг Измененный тип. Измените тип столбца Date на Дата, а тип столбца Revenue – на Десятичное число. Отфильтруйте все товары, окрашенные в черный цвет, щелкнув на элементе управления фильтра в столбце Color и отменив выбор флажка Black.
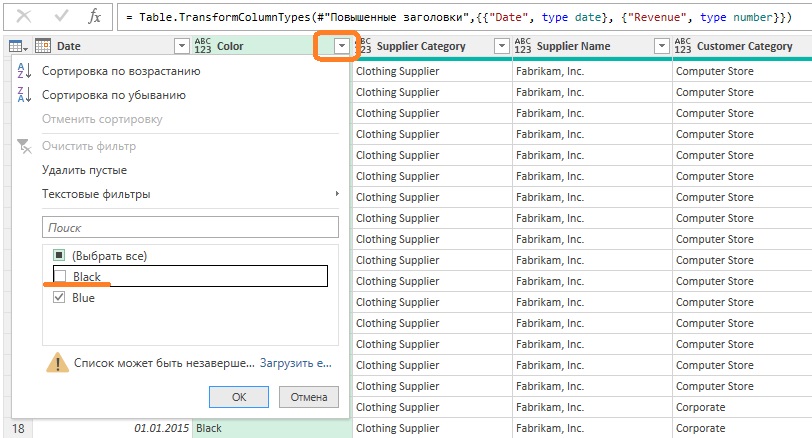
Рис. 4. Отмена выделения флажка Black приводит к нежелательным результатам
После выполнения этого шага фильтрации можно ожидать, что в качестве выходных данных будут применяться все цвета, кроме черного. Однако код шага…
|
= Table.SelectRows(#»Измененный тип», each ([Color] = «Blue»)) |
…говорит о другом. Поскольку в текущем запросе присутствуют только два цвета, отмена выбора флажка Black приводит к неверному коду. В результате отфильтрованы только товары синего цвета. Если в будущем появятся иные цвета, они не попадут в выборку. Следует исправить формулу:
|
= Table.SelectRows(#»Измененный тип», each ([Color] <> «Black»)) |
Вместо редактирования формулы можно тоньше настроить фильтр. Удалите шаг Строки с примененным фильтром. Снова выберите элемент управления фильтром для столбца Color. На панели Фильтр выберите команду Текстовые фильтры –> Не равно –> Black. Щелкните Ok. Убедитесь, что шагу соответствует корректная формула М. Всегда лучше использовать текстовые фильтры, чем выбирать значения на панели ввода текста.
Можете изучить файл решения C10E02 — Solution.xlsx.
Логика, определяющая условия фильтрации
При выборе значений на панели Фильтр PQ следует двум правилам:
- Если число выбранных значений меньше или равно числу невыбранных значений, редактор Power Query создает позитивное условие, применяя знак равенства для выбранных значений.
- Если число выбранных значений больше числа невыбранных значений, редактор Power Query создает отрицательное условие, применяя знак неравенства для невыбранных значений.
Рассмотрим пример столбца, содержащего значения от 1 до 6. Создайте новый файл Excel. Пройдите Данные –> Получить данные –> Из других источников –> Пустой запрос. В строке формул введите:
Пройдите Средства для списков –> Преобразование –> В таблицу. Щелкните Ok. Выберите элемент управления фильтром для столбца Column1. В окне Фильтр снимите галочку для значения 1 и закройте окно. В строке формул отразится:
|
= Table.SelectRows(#»Преобразовано в таблицу», each ([Column1] <> 1)) |
Повторите фильтрацию, отменив выбор для значений 1 и 2:
|
= Table.SelectRows(#»Преобразовано в таблицу», each ([Column1] <> 1 and [Column1] <> 2)) |
Далее отмените выбор значений 1, 2 и 3. Теперь строка формул содержит позитивное условие:
|
= Table.SelectRows( #»Преобразовано в таблицу», each ( [Column1] = 4 or [Column1] = 5 or [Column1] = 6 ) ) |
Это потенциально неверное условие. Корректное условие должно оставаться отрицательным:
|
= Table.SelectRows( #»Преобразовано в таблицу», each ( [Column1] <> 1 or [Column1] <> 2 or [Column1] <> 3 ) ) |
Позитивное условие приведет к ошибке при появлении новых значений. Представьте, что в ваших данных в будущем появятся значения 7, 8, 9 и 10. При позитивном условии обновление приведет к тому, что по-прежнему в фильтр попадут только значения 4, 5 и 6.
Поиск значений на панели Фильтр
Откройте новую книгу Excel. Пройдите Данные –> Получить данные –> Из файла –> Из книги. Выберите файл C10E01.xlsx и щелкните Импорт. В окне Навигатор выберите Sheet1, кликните Преобразовать данные. Удалите шаг Измененный тип. Измените тип столбца Date на Дата, а тип столбца Revenue – на Десятичное число. Допустим вы хотите исключить строки, относящиеся к городу Baldwin City. Выберите элемент управления фильтром для столбца City. Поскольку список городов довольно длинный в поле поиска начните вводить Ba...

Рис. 5. Поиск значений на панели Фильтр
Список сократится. Снимите выделение для Baldwin City. Нажмите Ok. К сожалению, при просмотре строки формул оказывается, что полученное выражение содержит неверное положительное условие:
|
= Table.SelectRows( #»Измененный тип», each ( [City] = «Bakers Mill» or [City] = «Baraboo» or [City] = «Bayou Cane» or [City] = «Bazemore» or [City] = «Beaver Bay» or [City] = «Bombay Beach» or [City] = «Greenback» or [City] = «New Baden» or [City] = «Wilkes-Barre» ) ) |
Выбранными оказались все города, содержащие Ba, кроме Baldwin City. А все другие города будут отфильтрованы.
Для устранения ошибки измените формулу:
|
= Table.SelectRows(#»Измененный тип», each ([City] <> «Baldwin City»)) |
Сценарии, описанные в этом разделе, весьма распространены, поэтому попасть в третью ловушку довольно легко. Лучшая защита – применение окна Текстовые фильтры.
Ловушка 4. Переупорядочение столбцов
При переупорядочении используется функция Table.ReorderColumns со ссылкой на все имена столбцов. Это ослабляет запрос и увеличивает вероятность ошибок обновления в будущем, если столбцы будут переименованы или удалены из исходных данных. Старайтесь не использовать переупорядочение ради наглядности.
Но существуют сценарии, которые требуют определенного порядка столбцов в запросе. Например, в главе 4 переупорядочение требовалось, чтобы переместить вычисляемый столбец в начало таблицы, что позволило после транспонирования использовать его в качестве заголовков. Если переупорядочение необходимо, применяйте его после того, как в отчете останутся только те столбцы, которые действительно необходимы.
Откройте новую книгу Excel. Пройдите Данные –> Получить данные –> Из файла –> Из книги. Выберите файл C10E01.xlsx и щелкните Импорт. В окне Навигатор выберите Sheet1, кликните Преобразовать данные. Удалите шаг Измененный тип. Переместите столбец City на место второго столбца, а Revenue – на место третьего столбца:
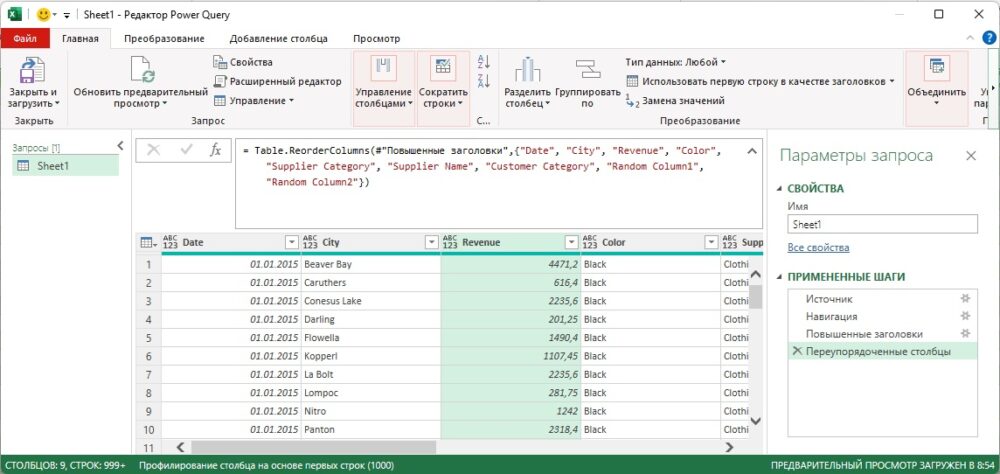
Рис. 6. Переупорядочение столбцов City и Revenue
Изучите код в строке формул:
|
= Table.ReorderColumns( #»Повышенные заголовки», { «Date», «City», «Revenue», «Color», «Supplier Category», «Supplier Name», «Customer Category», «Random Column1», «Random Column2» } ) |
Понятно, что формула не будет обновляться, если имена столбцов изменятся. Измените формулу: Удалите из формулы фрагмент…
|
= Table.ReorderColumns( #»Повышенные заголовки», List.InsertRange( List.Difference( Table.ColumnNames(#»Повышенные заголовки»), {«City», «Revenue»} ), 1, {«City», «Revenue»} ) ) |
Функция List.InsertRange получает список в качестве входных данных и вставляет другой список с определенным смещением от нуля. Например, если имеется список А и нужно добавить поля City и Revenue в качестве второго и третьего пунктов списка A, можно применить следующую формулу:
|
List.InsertRange(A, 1, {«City», «Revenue»} |
Осталось исключить из списка А столбцы City и Revenue. Для этого используется функция List.Difference. Она принимает один список в качестве первого аргумента, а другой список – в качестве второго аргумента и возвращает новый список со всеми элементами из первого списка, которых нет во втором списке (левостороннее объединение двух списков).
Таким образом, если B – список имен столбцов, то следующая функция вернет все названия столбцов, кроме City и Revenue:
|
A = List.Difference(B, {«City», «Revenue»}) |
Теперь при указании функции Table.ColumnNames в следующей формуле вместо B можно собрать все части для формирования полного выражения:
|
B = Table.ColumnNames(#»Повышенные заголовки») |
И наконец, при объединении всех элементов вместе получим окончательную формулу.
Пользовательская функция FnReorderSubsetOfColumns
Можно упростить, описанный выше подход, с помощью пользовательской функции. Откройте книгу Excel, созданную в предыдущем разделе. Пройдите Данные –> Получить данные –> Из других источников –> Пустой запрос. В редакторе PQ пройдите Главная –> Расширенный редактор. Вставьте код:
|
(tbl as table, reorderedColumns as list, offset as number) as table => Table.ReorderColumns( tbl, List.InsertRange( List.Difference( Table.ColumnNames(tbl), reorderedColumns ), offset, reorderedColumns ) ) |
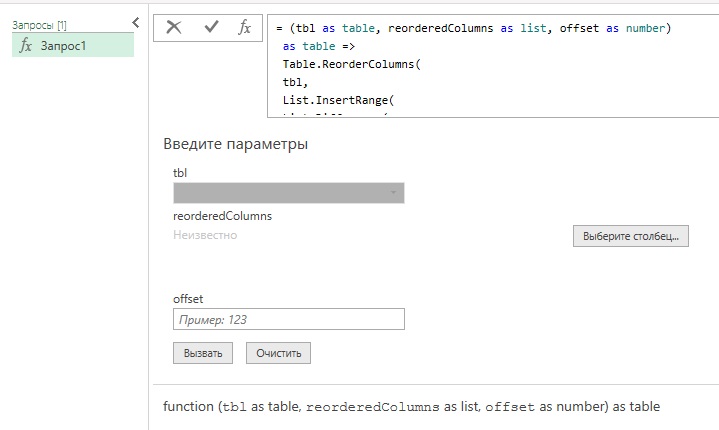
Рис. 7. Пользовательская функция
Переименуйте Запрос1 в FnReorderSubsetOfColumns.
Вернитесь к запросу Sheet1, удалите шаг Переупорядоченные столбцы. Щелкните на значке fx в строке формул для создания нового шага. Введите:
|
= FnReorderSubsetOfColumns(#»Повышенные заголовки», {«City», «Revenue»}, 1) |
Функция FnReorderSubsetOfColumns получает таблицу, подмножество переупорядоченных имен столбцов в виде списка и индекс, начинающийся с нуля. Затем выполняется переупорядочение очень надежным способом, без ссылок на имена других столбцов. Файлы решения C10E03 — Solution.xlsx.
Есть и другие способы реализации функции Table.ReorderColumns, которые позволяют избежать ошибок обновления. Можно задать третий аргумент, который позволит игнорировать пропущенные поля или добавлять нулевые значения для пропущенных полей. И хотя эти методы предотвращают сбои обновления, они могут приводить к неожиданным результатам. Подробнее см. заметку.
Ловушка 5. Удаление и выделение столбцов
Хотя удаление ненужных столбцов является важным моментом при формировании эффективных отчетов (меньшее число столбцов приводит к сокращению объема памяти и размера файла), при удалении столбца вы ухудшаете запрос, подвергая его риску будущих сбоев при обновлениях. Всякий раз, удаляя столбец, вы рискуете, что в будущем обновление может завершиться ошибкой, если удаленный столбец будет отсутствовать во внешнем источнике данных.
Чтобы снизить риск сбоев при обновлениях, можно следовать простой рекомендации: сосредоточьтесь на столбцах, которые необходимо сохранить, а не на тех, которые следует удалить. Редактор Power Query позволяет удалять или сохранять столбцы. И хотя более естественно нажать на кнопку Удалить, во многих случаях предпочтительнее выбирать столбцы, которые желательно сохранить.
Откройте новую книгу Excel. Пройдите Данные –> Получить данные –> Из файла –> Из книги. Выберите файл C10E01.xlsx и щелкните Импорт. В окне Навигатор выберите Sheet1, кликните Преобразовать данные. Удалите шаг Измененный тип. Выберите столбцы Random Column1 и Random Column2 и нажмите Удалить. Обратите внимание на код в строке формул:
|
= Table.RemoveColumns(#»Повышенные заголовки», {«Random Column1», «Random Column2»}) |
В будущем, если исходная таблица не будет содержать один из этих столбцов, то обновление не пройдет. Удалим случайные столбцы другим способом и повысим робастность запроса.
Удалите шаг Удаленные столбцы. Пройдите Главная –> Выбрать столбцы и отмените выделение столбцов Random Column1 и Random Column2.

Рис. 8. Выбор столбцов
Нажмите Ok. Изучите строку формул:
|
= Table.SelectColumns(#»Повышенные заголовки», {«Date», «Color», «Supplier Category», «Supplier Name», «Customer Category», «City», «Revenue»}) |
Игнорирование пропущенного столбца
В некоторых ситуациях необходимо сохранить очень большое число столбцов, а риск удаления нескольких столбцов может быть ниже, чем проблемы, связанные с указанием столь большого числа столбцов. Часто не имеет значения, удаляются или выбираются столбцы. Вы имеете дело с внешними источниками данных, которые могут меняться. Для предотвращения ошибок обновления существует необязательный третий аргумент, который можно задать в функциях Table.RemoveColumns и Table.SelectColumns, что позволит игнорировать ошибки вместо того, чтобы прекращать обновление.
Аргумент MissingField.Ignore игнорирует пропущенный столбец, MissingField.UseNull сохраняет имя столбца при ошибках, но заполняет его нулями. Аргумент MissingField.UseNull более практичен, чем MissingField.Ignore, поскольку гарантирует, что выбранные имена столбцов будут включены в конечные результаты. Однако оба варианта могут привести к ошибкам, которые трудно обнаружить. Таким образом, ошибка обновления может оказаться предпочтительнее неожиданных результатов, которые вы получите, задав эти аргументы.
Выделение или удаление столбцов на основе их расположения
Во многих сценариях удаление или выбор столбцов на основе их расположения является более точным, чем обращение к ним по имени. Используя функцию Table.ColumnNames для получения списка всех имен столбцов и функцию List.Range для формирования подмножества столбцов, можно выбрать любое подмножество столбцов в зависимости от их расположения.
Следующие формулы удаляют первый столбец в таблице:
|
= Table.RemoveColumns(Source, List.First(Table.ColumnNames(Source))) = Table.RemoveColumns(Source, Table.ColumnNames(Source){0}) |
Заменив функцию List.First на List.FirstN, получите удаление N первых столбцов таблицы:
|
= Table.RemoveColumns(Source, List.FirstN(Table.ColumnNames(Source), N)) |
Следующая формула удаляет последний столбец таблицы:
|
= Table.RemoveColumns(Source, List.Last(Table.ColumnNames(Source), 1)) |
А эта формула сохраняет второй и третий столбцы в таблице:
|
= Table.SelectColumns(Source, List.Range(Table.ColumnNames(Source), 1, 2)) |
Функция List.Range получает список в качестве первого аргумента, смещение от нуля и количество возвращаемых элементов.
Можно выбрать отдельные столбцы. Следующая формула выбирает первый и второй столбец:
|
= Table.SelectColumns(Source, {Table.ColumnNames(Source){0}, Table.ColumnNames(Source){1}}) |
Выделение или удаление столбцов на основе их имен
Существует бесчисленное множество возможностей выбора или удаления столбцов в языке M. Следующая формула применяет функцию List.Select к именам столбцов, что позволит удалить столбцы, содержащие подстроку Random:
|
= Table.RemoveColumns(#»Повышенные заголовки», List.Select(Table.ColumnNames(#»Повышенные заголовки»), each Text.Contains(_, «Random»))) |
Аналогичный результат можно получить с помощью функции Table.SelectColumns и негативной логики (т.е. можно выбрать все столбцы, которые не содержат «Random»):
|
= Table.SelectColumns(#»Повышенные заголовки», List.Select (Table.ColumnNames(#»Повышенные заголовки»), each not Text.Contains(_, «Random»))) |
Файл решения C10E04 — Solution.xlsx.
Ловушка 6. Переименование столбцов
Столбцы принято переименовывать довольно часто. Это дает пользователям удобные имена в отчетах. Всякий раз при переименовании столбца возрастает вероятность сбоев обновления в будущем. Можно повысить надежность запроса, изменяя формулу и избегая ссылок на имена текущих столбцов.
Загрузите файл C10E05.xlsx и сохраните ее в папке C:DataC10. Откройте новую книгу Excel. Пройдите Данные –> Получить данные –> Из файла –> Из книги. Выберите файл C10E05.xlsx и щелкните Импорт. В окне Навигатор выберите Sheet1, кликните Преобразовать данные. Удалите шаг Измененный тип. Импортированная таблица включает семь столбцов, в названии которых присутствует слово Random.
В ручном режиме переименуйте столбцы Random Column1 и Random Column2 в Factor 1 и Factor 2. Строка формул содержит код:
|
= Table.RenameColumns(#»Повышенные заголовки», {{«Random Column1», «Factor 1»}, {«Random Column2», «Factor 2»}}) |
Если исходная таблица больше не включает один из этих столбцов, то обновление завершится неудачей. Представьте, что владелец данных исходной таблицы уведомит вас о том, что он в будущем переименует эти столбцы, но порядок всех столбцов сохранит. Тогда можно сослаться на эти столбцы по их расположению. Например, так:
|
= Table.RenameColumns(#»Повышенные заголовки», {{Table.ColumnNames (#»Повышенные заголовки»){6}, «Factor 1»}, {Table.ColumnNames(#»Повышенные заголовки»){7}, «Factor 2»}}) |
Настраиваемая функция FnRenameColumnsByIndices
Для того чтобы переименовать столбцы на основе их расположения в таблице, можно написать настраиваемую функцию, позволяющую переименовывать большое подмножество имен столбцов без необходимости отдельно записывать пары для старых и новых имен столбцов. Синтаксис такой функции:
|
= FnRenameColumnsByIndices(#»Повышенные заголовки», {«Factor 1», «Factor 2»}, {6, 7}) |
Подход с применением настраиваемых функций является масштабируемым, позволяя переименовывать большое количество столбцов одновременно и даже импортировать старые и новые имена столбцов из внешнего списка.
Начнем с неэффективного метода. Можно написать код, который задает пары старых и новых имен:
|
= Table.RenameColumns( #»Повышенные заголовки», { {Table.ColumnNames(#»Повышенные заголовки»){6}, «Factor 1»}, {Table.ColumnNames(#»Повышенные заголовки»){7}, «Factor 2»}, {Table.ColumnNames(#»Повышенные заголовки»){8}, «Factor 3»}, {Table.ColumnNames(#»Повышенные заголовки»){9}, «Factor 4»}, {Table.ColumnNames(#»Повышенные заголовки»){10}, «Factor 5»}, {Table.ColumnNames(#»Повышенные заголовки»){11}, «Factor 6»}, {Table.ColumnNames(#»Повышенные заголовки»){12}, «Factor 7»} } ) |
Можно написать более интеллектуальный код:
|
= FnRenameColumnsByIndices( #»Повышенные заголовки», List.Transform( {1..7}, each «Factor « & Text.From(_) ), {6..12} ) |
В этой формуле второй аргумент функции FnRenameColumnsByIndices – динамический список, который создается функцией List.Transform. Первый аргумент функции List.Transform – список индексов от 1 до 7. Функция List.Transform возвращает преобразованный список, объединяющий префикс Factor и соответствующий индекс. Третьим аргументом функции FnRenameColumnsByIndices служит список от 6 до 12 для индексов столбцов для переименования.
Код функции FnRenameColumnsByIndices:
|
(Source as table, ColumnNamesNew as list, Indices as list) => let ColumnNamesOld = List.Transform(Indices, each Table.ColumnNames(Source){_}), ZippedList = List.Zip({ ColumnNamesOld, ColumnNamesNew}), #»Переименованные столбцы» = Table.RenameColumns(Source, ZippedList ) in #»Переименованные столбцы» |
Аргументы Source соответствуют исходной таблице, ColumnNamesNew – списку новых имен столбцов и индексов для списка индексов в исходной таблице. Первая строка внутри выражения let получает индексы и возвращает имена соответствующих столбцов в таблице Source. В следующей строке применяется функция List.Zip для формирования вложенных списков. Каждый вложенный список содержит два элемента – старые и новые имена столбцов, относящиеся к одному и тому же индексу в разных списках. Например, эта функция List.Zip:
|
List.Zip({«a»,«b»,«c»}, {«A», «B», «C»}} |
Возвратит следующий список из вложенных списков:
|
{{«a», «A»}, {«b», «B»}, {«c», «C»}} |
Этот формат является обязательным для второго аргумента функции Table.RenameColumns – список вложенных списков, куда входят пары старых и новых имен столбцов, он применяется в третьей строке внутри выражения let.
Функция Table.TransformColumnNames
Существует и другая методика для переименования столбцов. Напомним, что в главе 4 применялась функция Table.TransformColumnNames для переименования всех столбцов. Она заменяла подчеркивания пробелами или выполняла переход к заглавным буквам. Эта функция подойдет в рассматриваемом здесь сценарии для замены имен столбцов:
|
= Table.TransformColumnNames(#»Повышенные заголовки», each Text.Replace(_, «Random Column», «Factor «)) |
Преимущество этого метода в том, что он успешно переименовывает столбцы, даже если случайные столбцы будут переупорядочены в исходной таблице. Тем не менее следует быть осторожным с логикой переименования, чтобы избежать переименования столбцов там, где не нужно.
В большинстве случаев достаточно простого переименования, как это обычно и делается. Не особенно углубляйтесь в этот вопрос.
Файл решения C10E05 — Solution.xlsx.
Ловушка 7. Разбиение столбца на другие столбцы
Очередная ловушка поджидает вас при использовании команды Разделить столбец по разделителю. Эта операция обычно применяется в двух случаях:
- Базовая операция позволяет разбивать столбец на несколько столбцов. Часто применяется для разделения на дату и время или имя и фамилию.
- Расширенная операция позволяет разделять каждую запись на несколько строк. После этого можно создавать новую таблицу, которая связывает каждое разделяемое значение с его сущностью. Как показано на рис. 9, можно создавать справочную таблицу для исходной таблицы, с помощью которой устанавливается соответствие между кодами продуктов и их цветами.
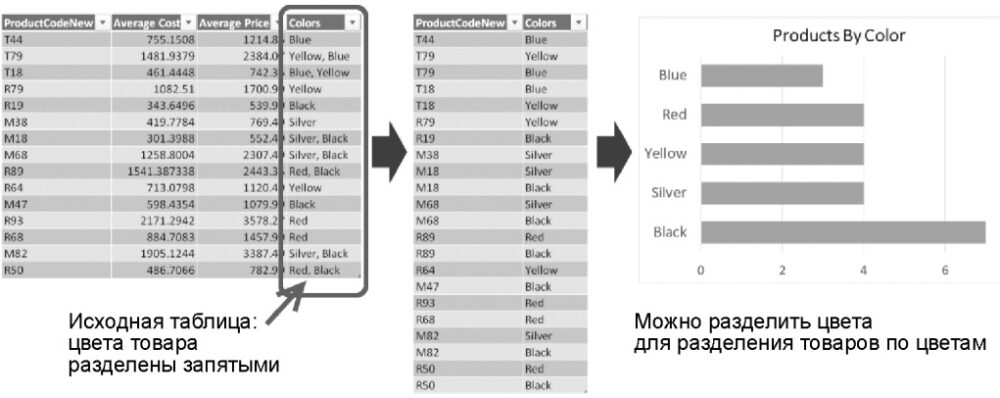
Рис. 9. Разделите столбец Color с данными, записанными через запятую, чтобы узнать, сколько выпущено товаров с разными цветами
Ранее мы уже разделяли столбец Colors для установления связи между товарами и цветами, что позволяло определить, сколько выпущено товаров с учетом цвета. Вспомните, что для решения этой проблемы столбец Colors разбивался на строки. Следующий сценарий показывает, что может произойти, если вы разбиваете столбец на столбцы, а не на строки.
Загрузите файл C10E06.xlsx и сохраните его в папке C:Data C10. Откройте новую книгу Excel. Пройдите Данные –> Получить данные –> Из файла –> Из книги. Выберите файл C10E05.xlsx и щелкните Импорт. В окне Навигатор выберите Products, кликните Преобразовать данные. Удалите шаг Измененный тип. На панели Запросы щелкните правой кнопки мыши на Products и выберите Ссылка. Ваша цель состоит в создании новой таблицы, включающей коды и цвета продуктов.
Переименуйте запрос Products (2) в Products and Colors. Пройдите Главная –> Выбрать столбцы, в окне Выбор столбцов оставьте галочки напротив ProductCodeNew и Colors. Щелкните Ok. Выделите столбец Colors, пройдите Преобразование –> Разделить столбец –> По разделителю. Оставьте настройки окна Разделить столбец по разделителю по умолчанию. Щелкните Ok.
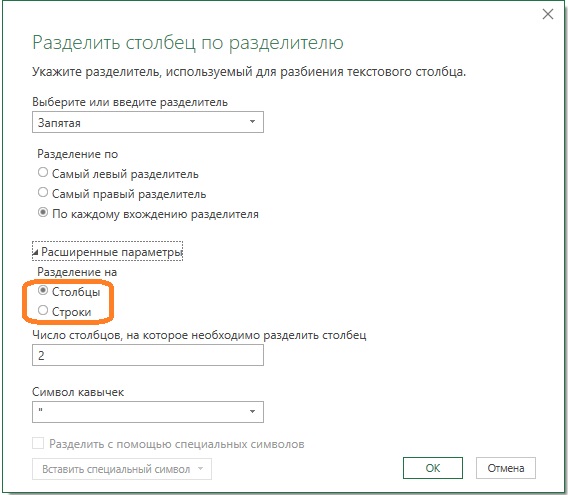
Рис. 10. Окне Разделить столбец по разделителю
К сожалению, по умолчанию выполняется разделение на столбцы, а не строки. Столбец Colors разделился на Colors.1 и Colors.2. На панели Примененные шаги выберите шаг Разделить столбец по разделителю. Код в строке формул:
|
= Table.TransformColumnTypes( #»Разделить столбец по разделителю», {{«Colors.1», type text}, {«Colors.2», type text}}) |
Поскольку цель – сопоставить коды товаров и цвета, необходимо использовать преобразование отмены свертывания столбцов для получения таблицы, состоящей из пар код/цвет. Выберете столбец ProductCodeNew. Пройдите Преобразование –> Отменить свертывание столбцов –> Отменить свертывание других столбцов. Столбцы Colors.1 и Colors.2 трансформируются в столбцы Атрибут и Значение. Последний столбец включает цвета, которые теперь корректно сопоставлены соответствующим кодам товаров. Некоторые названия цветов начинаются с пробела. Чтобы это исправить, кликните правой кнопкой мыши на столбце Значение и выберите Преобразование –> Усечь. Альтернативный вариант – на панели Примененные шаги выберите шестеренку возле шага Разделить столбец по разделителю и измените разделитель на Пользовательский, а затем введите запятую и пробел.
Удалите столбец Атрибут и загрузите запрос в таблицу на лист Excel. Можно создать сводную диаграмму и построить гистограмму:
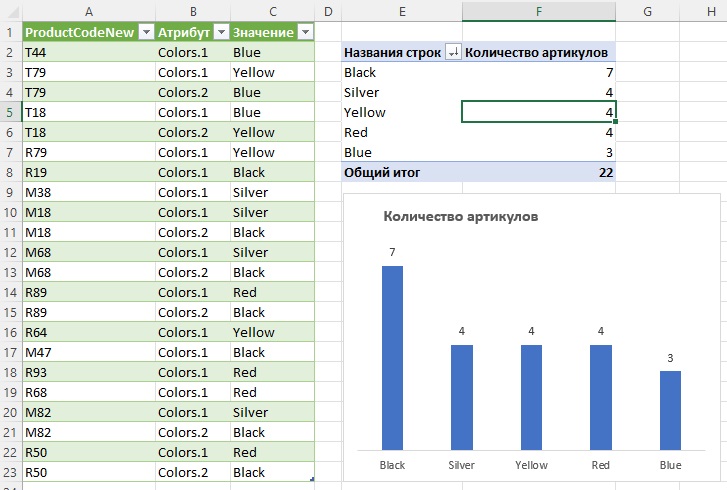
Рис. 11. Анализ цветовой гаммы продукции
Давайте проверим, что произойдет, если какой-то код продукта относится к более чем двум цветам, сохраните отчет и откройте файл C10E06.xslx. В ячейку D3 добавьте еще два цвета к имеющимся двум: Black, Red. Сохраните файл C10E06.xslx и закройте его. Вернитесь к отчету и обновите его. К сожалению, новые цвета не будут включены в отчет по артикулы T79.
Решить проблему можно, разбивая столбец Colors на строки. Но если по какой-то причине необходимо разбить столбец на столбцы, а не на строки, то можно отмасштабировать решение, увеличивая число столбцов, на которые нужно выполнить разбиение. Допустим, заранее известно, что количество цветов не может превышать 20. Можно модифицировать формулу на шаге Разделить столбец по разделителю:
|
= Table.SplitColumn(Products_Table, «Colors», Splitter.SplitTextByDelimiter(«, «, QuoteStyle.Csv), 20) |
Заменяя жестко закодированную часть, {«Colors.1», «Colors.2»}, на 20, т. е. на максимальное число столбцов, которое вы ожидаете получить. Это усилит запрос и придаст уверенности, что данные не будут утеряны.
Файлы решения C10E06 — Solution.xlsx. В файле C10E06 — v2.xlsx содержится вторая версия книги C10E06.xlsx, с обновленными значениями цветов. Запросы в файлах решения требуют наличия рабочей книги C10E06 — v2.xlsx в папке C:DataC10.
Ловушка 8. Слияние столбцов
При объединении нескольких столбцов в один формула сначала преобразует все числовые столбцы в текст, а затем объединяет вместе все столбцы. Следующий код генерится автоматически при объединении трех столбцов в исходной таблице, первые из которых являются числовыми (Numeric Column1 и Numeric Column 2), а третий — текстовым (Textual Column3):
|
#»Merged Columns» = Table.CombineColumns( Table.TransformColumnTypes( Source, { {«Numeric Column1», type text}, {«Numeric Column2», type text} }, «en-US» ), {«Numeric Column1», «Numeric Column2», «Textual Column3»}, Combiner.CombineTextByDelimiter(«:», QuoteStyle.None), «Merged» ) |
Функция Table.TransformColumnTypes обеспечивает преобразование типов всех числовых столбцов, а затем объединяет соответствующие столбцы. Эта формула может привести к ошибкам обновления. Целесообразнее изменить код и масштабировать его для объединения заданного списка столбцов, не ссылаясь на какие-либо жестко закодированные имена столбцов.
Допустим, имеются имена столбцов для слияния в списке ColumnsToMerge. Модифицированная формула:
|
#»Merged Columns» = Table.CombineColumns( Table.TransformColumnTypes( Source, List.Transform( ColumnsToMerge, each {_, type text} ), «en-US» ), ColumnsToMerge, Combiner.CombineTextByDelimiter(«:», QuoteStyle.None), «Merged» ) |
Основное различие этих двух формул сконцентрировано в следующей части кода:
|
{ «Numeric Column1», type text}, {«Numeric Column2», type text} } |
Замена выполняется с помощью функции List.Transform, функция генерит то же преобразование, но без ссылки на имена столбцов:
|
List.Transform( ColumnsToMerge, each {_, type text} ) |
Этот код выполняет итерации по каждому имени столбца в ColumnsToMerge и преобразует его в список имен столбцов и текстового типа: {_, type text}. И хотя обычно подобная функция может и не понадобиться, рассмотренный пример служит важной демонстрацией применения функций списка при формировании масштабируемых и надежных версий для ваших автоматически сгенерированных формул.
Дополнительные ловушки и методы для создания надежных запросов
Еще одна ловушка связана с разворачиванием столбцов таблицы. Операция Развернуть столбцы таблицы выполняется при объединении нескольких файлов из папки, объединении двух таблиц или при работе с неструктурированными наборами данных, такими как JSON. При развертывании столбцов таблицы необходимо на первом этапе выбрать столбцы для развертывания. В результате редактор Power Query автоматически генерирует формулу с жестко закодированными именами столбцов, а новые имена столбцов могут быть пропущены. Чтобы узнать, как обойти эту ловушку, а также, как избежать пропусков новых столбцов, см. заметку. Еще одна ловушка относится к удалению дубликатов, она рассматривалась ранее.
Содержание
- SPBDEV Blog
- Пример набора данных
- Происходит ошибка
- Почему Power Query Editor не поймал ошибку?
- Работа с ошибками: поиск строк ошибок
- Удаление ошибок из загрузки таблицы в Power BI
- Храните ошибки в таблице исключений
- Получение информации об ошибке
- Удалите столбец ошибок
- Отчет об исключении
- Подведем итоги
- Работа с ошибками в Power Query
- Ошибка на уровне шага
- Распространенные ошибки на уровне шага
- Не удается найти источник — DataSource.Error
- Столбец таблицы не найден
- Другие распространенные ошибки на уровне шага
- Ошибка уровня ячейки
- Обработка ошибок на уровне ячейки
- Удаление ошибок
- Замена ошибок
- Сохранение ошибок
- Распространенные ошибки на уровне ячеек
- Ошибки преобразования типов данных
- Ошибки операций
SPBDEV Blog
Чтобы создать надежную систему BI, вам необходимо тщательно учитывать и обрабатывать ошибки. Если вы создаете решение для отчетов, обновление которого не выполняется при каждом возникновении ошибки, это не надежная система. Ошибки могут произойти по многим причинам. В этом сообщении мы покажем вам способ поймать возможные ошибки в Power Query и как создать страницу отчета об исключении, чтобы визуализировать строки ошибок для дальнейшего изучения. Метод, о котором вы здесь узнаете, сохранит вашу модель от сбоя во время обновления. Эо означает, что вы обновили набор данных, и вы можете поймать любые строки, вызвавшие ошибку на странице отчета об исключении.
Пример набора данных
Мы будем использовать пример файла Excel в качестве источника данных, который содержит 18 484 строки клиентов. В образце Dataset у нас есть поле BirthDate рядом со всеми другими полями, которые должны иметь в нем значение даты. Вот как выглядят данные, когда мы вводим их в Power Query:
Происходит ошибка
Когда мы получаем этот набор данных в окне редактора Power Query Editor (как показано на приведенном выше снимке экрана), Power Query автоматически преобразует тип данных столбца BirthDate в Date. Вы можете увидеть это автоматическое преобразование типа данных в списке шагов;
Конечно, вы можете отключить автоматическое определение типа данных Power Query, но наша точка зрения отличается. Мы хотим, чтобы набор данных не показывал вам, как с этим бороться. Ошибки происходят в Power Query в реальном мире, и мы хотим показать вам, как их найти.
Как вы можете видеть в редакторе Power Query Editor, мы не видим ошибок для этого типа данных, и все выглядит великолепно;
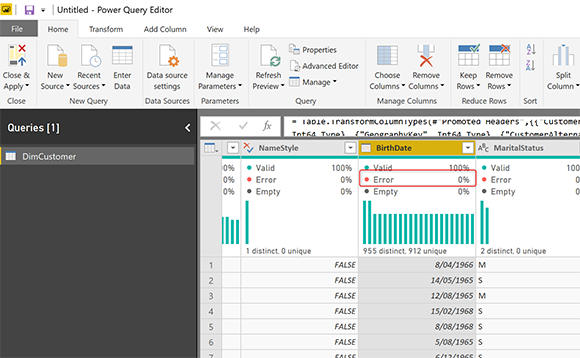
Теперь мы загружаем этот набор данных в Power BI, используя Close и Apply в окне редактора запросов, и мы ждем, что все загрузится успешно, однако это выходит из-под контроля!
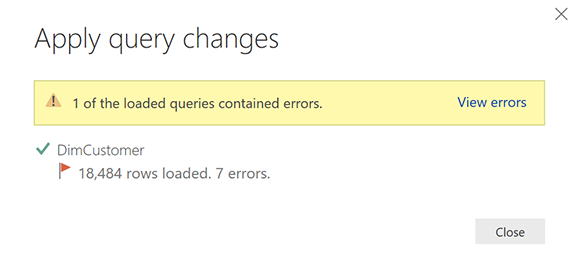
Звучит знакомо? Да, если вы некоторое время работали с Power BI, возможно, вы это испытали. В редакторе Power Query Editor нет ошибок, но когда мы загружаем данные в Power BI, они появляются ! Как это возможно? Давайте сначала узнаем, почему это происходит.
Почему Power Query Editor не поймал ошибку?
Редактор Power Query Editor всегда работает с предварительным просмотром набора данных, размер предварительного просмотра зависит от того, сколько столбцов у вас есть, иногда это 1000 строк, а иногда и 200 строк. Если вы нажмете на Query в окне редактора Power Query, вы можете увидеть это, как показано ниже в строке состояния;
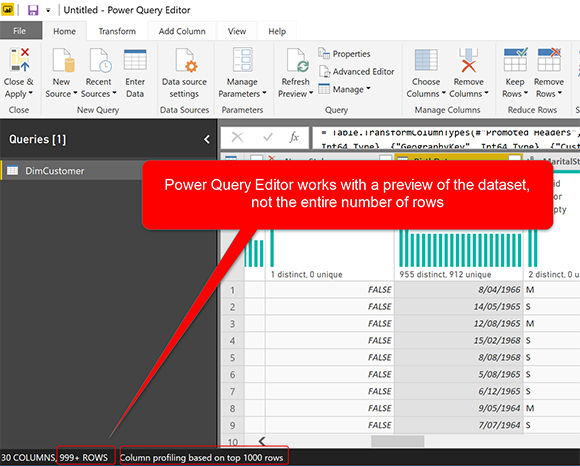
Причина использования Power Query для использования набора данных предварительного просмотра заключается, главным образом, в ускорении процесса разработки трансформации. Представьте, что если у вас есть таблица с 10 миллионами строк, каждое преобразование, которое вы хотите применить к этому набору данных, займет много времени, и вам придется подождать, прежде чем вы начнете делать следующий шаг. Ожидание ответа каждый раз замедляет процесс разработки. Именно по этой причине предпочтительным вариантом является работа над предварительным просмотром в наборе данных. Вы можете применить все преобразования, которые вы хотите в предварительном просмотре, и когда вы им довольны, затем примените его ко всему набору данных. Как правило, первые 1000 строк или первые 200 строк являются хорошим образцом всего набора данных, и вы можете ожидать увидеть большинство проблем с данными. Не всегда, конечно.
Как тогда преобразование будет применено ко всему набору данных? Когда вы загружаете данные в Power BI, а именно — когда вы нажимаете «Close» и «APPLY» в окне Power Query Editor. Этот APPLY означает применить эти преобразования теперь во всем наборе данных. Именно по этой причине процесс загрузки может занять больше времени, особенно если набор данных большой.
Power Query Editor всегда работает с предварительным просмотром данных, чтобы ускорить процесс разработки. Когда вы загружаете данные в Power BI, преобразования будут применяться ко всему набору данных.
Теперь, когда вы знаете, как Power Query Editor имеет дело с предварительным просмотром данных, вы можете догадаться, почему произошла ошибка выше? Причина в том, что предварительный просмотр данных (около 1000 строк) не имел проблем с применяемыми преобразованиями (в этом случае автоматический тип данных изменяется на Date для столбца BirthDate). Однако весь набор данных (около 18 тыс. строк) имеет проблемы с этим преобразованием! Когда вы увидите вышеприведенную ошибку в Power BI Desktop, вы можете нажать View errors и перейти в Power Query editor, посмотреть их, разобраться с ними и исправить. Однако этого недостаточно.
Что делать, если ошибка не возникает в Power BI Desktop, но происходит в запланированном обновлении в службе Power BI?
Это хороший вопрос! Исправить ошибки в Power BI Desktop легко, но учтите, что ошибка также не произошла в Desktop, и вы опубликовали отчет Power BI на веб-сайт и запланировали его обновление. Затем на следующий день вы увидите, что отчет не обновился с ошибкой! Вы должны научиться правильно обращаться к строкам ошибок до того, как это приведет к сбою запланированного обновления. Давайте посмотрим, как с этим справиться.
Работа с ошибками: поиск строк ошибок
Чтобы справиться с ошибками, вы должны поймать ошибку до того, как она загрузится в Power BI. Один из способов сделать это — создать две ссылки одной и той же таблицы, одну в качестве окончательного запроса, а другую — как строки ошибок.
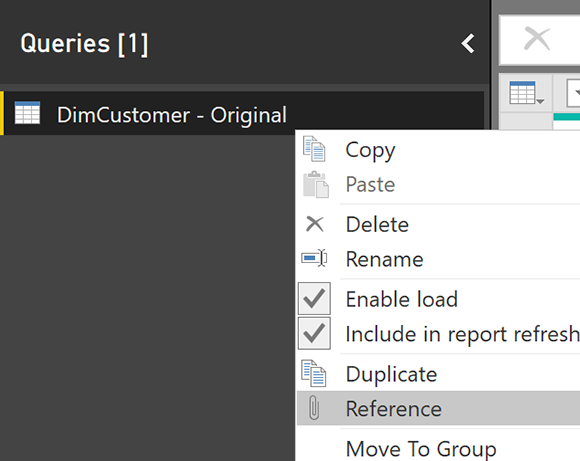
На скриншоте выше, мы переименовали таблицу DimCustomer в DimCustomer — Original, а затем создали ссылку из нее. Если вы хотите узнать, что такое Reference, прочитайте статью о Reference и Duplicate здесь . Новый запрошенный запрос можно назвать DimCustomer. Это будет чистый запрос без ошибок (мы удалим ошибки из него на следующем шаге);
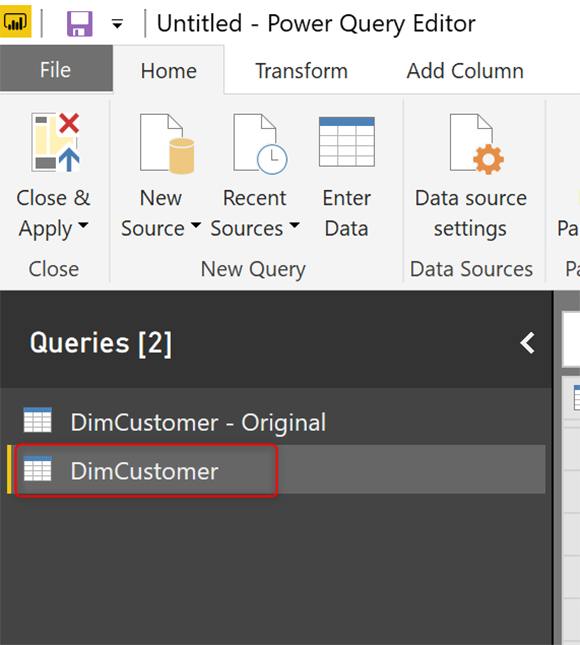
Новая таблица — это таблица, которая будет чистой, без ошибок, и мы можем использовать ее в отчете. Давайте очистим это от любых ошибок
Удаление ошибок из загрузки таблицы в Power BI
Поскольку DimCustomer станет для нас окончательным запросом, я хочу удалить из него ошибки. Удаление ошибок — это простой вариант на вкладке «Главная» в разделе Reduce Rows -> Remove Rows -> Remove Errors.. Перед этим выберите столбец BirthDate.
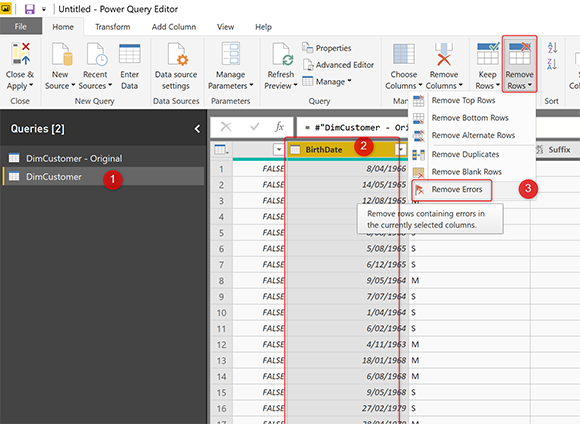
Вы также можете сделать это для всех столбцов, если хотите; выбрав все столбцы, а затем выбрав «Remove Errors». Это сообщение — всего лишь образец одного столбца и может быть продлен до конца.
Remove Errors — это шаг на этапе преобразования данных, а это означает, что при нажатии APPLY он будет применяться ко всему набору данных, поэтому в результате, когда изменение типа данных приведет к ошибке, следующий шаг после этого — Remove Errors, уничтожит строки, вызвавшие ошибку. Но DimCustomer — Original все еще может вызвать ошибку, поэтому мы должны снять галочку Enable Load с этого запроса.
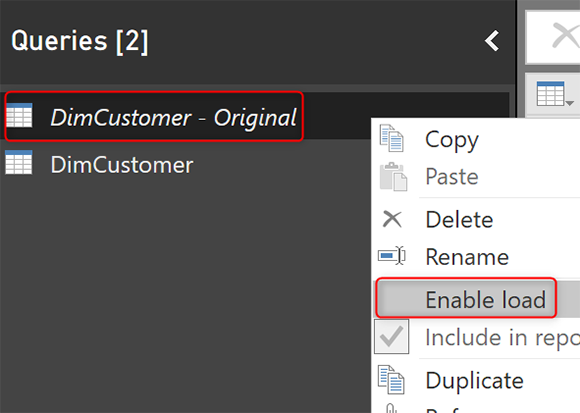
Теперь мы успешно удалили ошибки и загрузили данные в Power BI. Ошибок не будет.
Но подождите! Как насчет этих строк ошибок? Как мы можем их поймать? Нам нужно поймать эти строки и выяснить, что произошло, и подумать о плане действий, чтобы исправить их, не так ли? Таким образом, нам нужна другая ссылка запроса из исходного запроса, но для сохранения строк ошибок.
Храните ошибки в таблице исключений
Аналогично опции «Remove Errors» есть опция «Keep Errors». Если вы уже видели этот вариант, возможно, вам интересно, как его использовать? Вот точный сценарий использования. Keep Errors поможет уловить строки ошибок в таблице исключений.
Создайте еще одну ссылку из DimCustomer — Original.
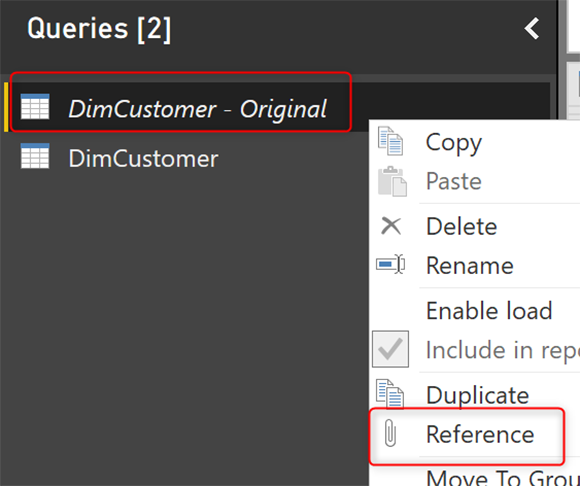
Переименуйте этот новый запрос как строки ошибок DimCustomer. Для этого запроса нам нужно сохранить ошибки, которые можно найти рядом с ошибками удаления, но в разделе Keep Rows.
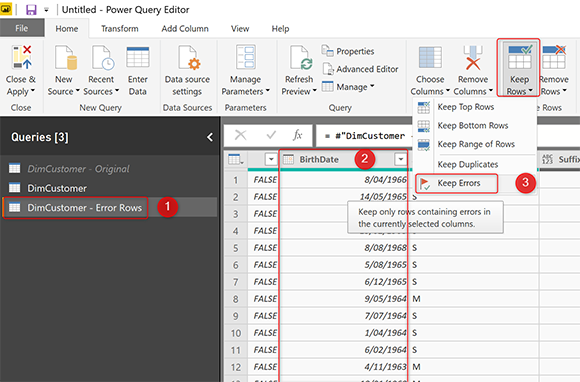
Теперь эта таблица будет содержать строки, которые вызывают ошибку. Вот пример набора;
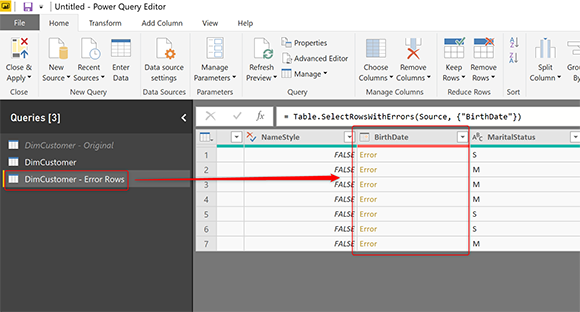
Это еще не конец истории. Если вы загрузите эту новую таблицу DimCustomer — строки ошибок в Power BI, вы снова получите ту же ошибку. Зачем? ну, потому что этот запрос, безусловно, собирается возвращать строки ошибок! Вам необходимо удалить ошибку из этого набора данных.
Получение информации об ошибке
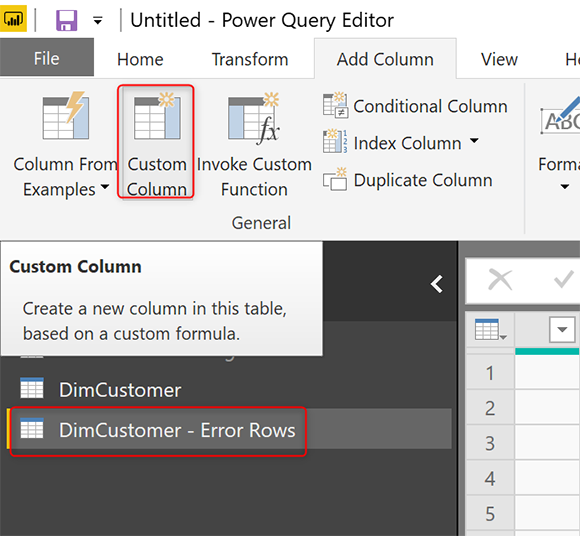
Если вы удалите столбец ошибок из таблицы исключений, которые мы создали, то у вас не будет никаких подробностей о произошедшей ошибке, и было бы трудно отследить ее и устранить неполадки. Лучше всего поймать детали ошибки. Сообщение об ошибке и значение, вызвавшее ошибку, являются важными деталями, которые вы не хотите пропустить. Выполните следующие шаги, чтобы получить эту информацию.
В таблице Error Rows добавьте Custom Column.
В редакторе Custom Column напишите «try», а затем пробел, имя поля, вызвавшего ошибку. В нашем примере: BirthDate;
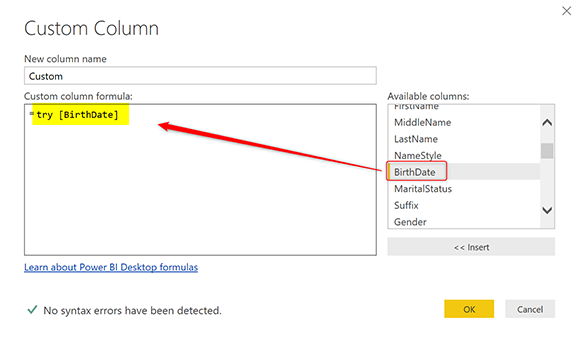
try (все строчные буквы), это ключевое слово в M, которое будет ловить данные об ошибке. Вместо того, чтобы возвращать только ошибку, она вернет запись, содержащую данные об ошибках, такие как исходное значение и сообщение об ошибке. Ниже, снимок экрана показывает, как будет выводиться результат попытки;
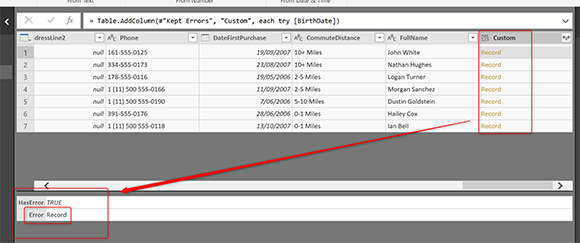
Выход записи «try» будет иметь два поля; HasError (мы уже знаем, что это будет правда) и Error. Ошибка — это еще одна запись с более подробной информацией. Нажмите «Expand » в столбце «Custom column» и выберите «Error».
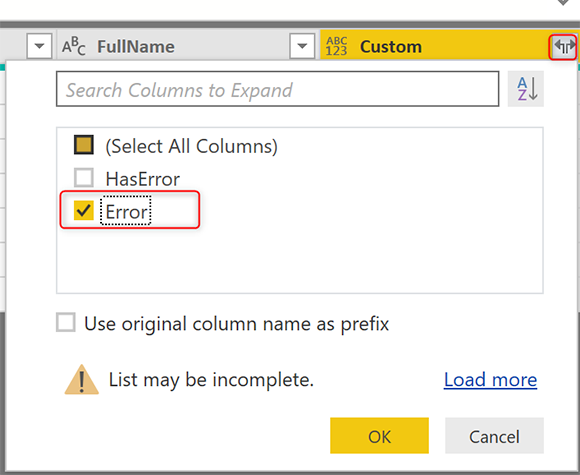
В столбце вывода с именем «Error» снова нажмите на «Expand» и на этот раз выберите все столбцы;
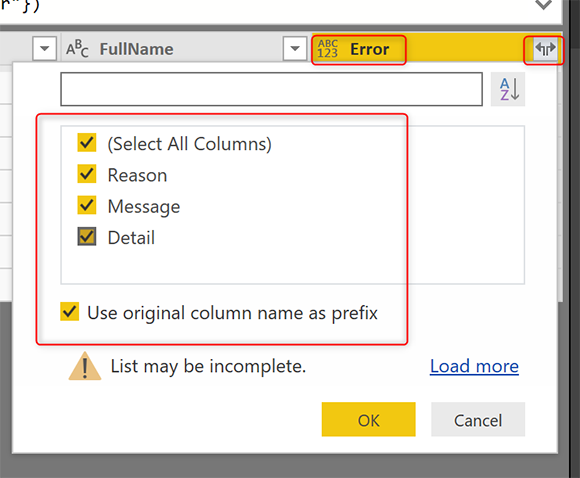
Хорошо иметь исходное имя столбца в качестве префикса, потому что тогда вы бы знали, что это столбцы с подробными сведениями об ошибках.
Теперь вы получите полную информацию об ошибке, как показано ниже;
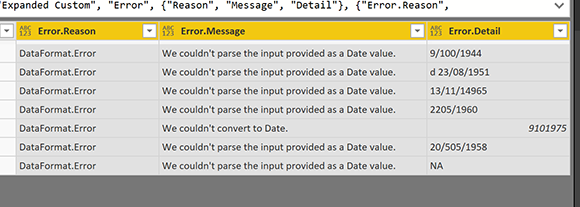
Вышеупомянутая информация является вашим самым ценным активом для отчетности об исключениях.
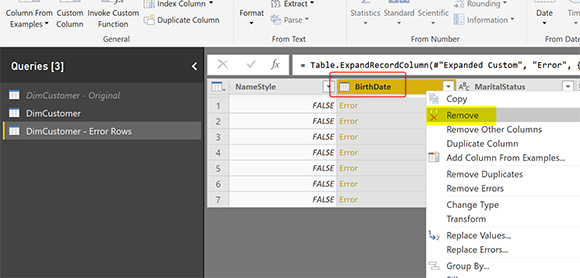
Удалите столбец ошибок
Теперь последний шаг перед загрузкой данных в Power BI — удалить столбец, который вызывает ошибку. В нашем примере; Столбец BirthDate должен быть удален (в противном случае обновление снова завершится неудачей);
Отчет об исключении
Теперь вы можете загрузить данные в Power BI. У вас будет две таблицы; DimCustomer и DimCustomer – Error Rows. DimCustomer — это таблица, которую вы можете использовать для обычной отчетности. DimCustomer – Error Rows — это таблица, которую вы можете использовать для отчетов об исключениях. Отчет об исключении — это отчет, который можно использовать для устранения неполадок, и перечисляет все ошибки для дальнейшего расследования. Убедитесь, что между этими двумя таблицами нет никакой связи.
Вот созданный нами образец визуального отчета, который показывает ошибки:

Подведем итоги
Ошибки случаются, и вам приходится иметь дело с ними. Вместо того, чтобы ждать ошибки, а затем находить их лишь через месяц после появления, лучше выявлять их, как только они произойдут. В этой статье вы узнали способ обработки строк ошибок.
Источник
Работа с ошибками в Power Query
В Power Query можно столкнуться с двумя типами ошибок:
- Ошибки на уровне шага
- Ошибки на уровне ячеек
В этой статье приводятся рекомендации по устранению наиболее распространенных ошибок, которые можно найти на каждом уровне, а также описывает причину ошибки, сообщение об ошибке и подробные сведения об ошибке для каждого из них.
Ошибка на уровне шага
Пошаговая ошибка предотвращает загрузку запроса и отображает компоненты ошибок на желтой панели.
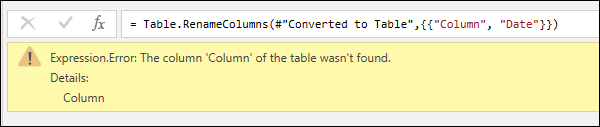
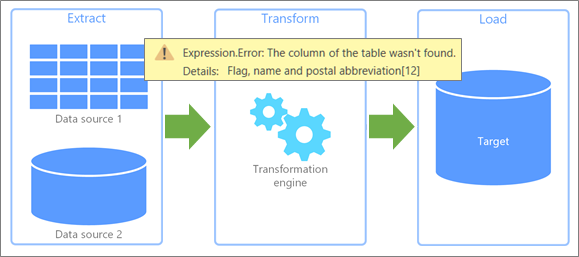
- Причина ошибки: первый раздел перед двоеточием. В приведенном выше примере причина ошибки — Expression.Error.
- Сообщение об ошибке: раздел непосредственно после причины. В приведенном выше примере сообщение об ошибке — столбец «Столбец» таблицы не найден.
- Сведения об ошибке: раздел непосредственно после строки Details: В приведенном выше примере сведения об ошибке — «Столбец«.
Распространенные ошибки на уровне шага
Во всех случаях рекомендуется внимательно ознакомиться с причиной ошибки, сообщением об ошибке и подробными сведениями об ошибке, чтобы понять, что вызывает ошибку. Вы можете нажать кнопку «Перейти к ошибке» , если она доступна, чтобы просмотреть первый шаг, в котором произошла ошибка.

Не удается найти источник — DataSource.Error
Эта ошибка обычно возникает, когда источник данных недоступен пользователем, у пользователя нет правильных учетных данных для доступа к источнику данных или источник был перемещен в другое место.
Пример. У вас есть запрос из текстовой плитки, которая была расположена на диске D и создана пользователем A. Пользователь A предоставляет общий доступ к запросу пользователю B, у которого нет доступа к диску D. Когда этот пользователь пытается выполнить запрос, он получает dataSource.Error , так как в своей среде нет диска D.

Возможные решения. Вы можете изменить путь к файлу текстового файла на путь, к которому у обоих пользователей есть доступ. Как пользователь Б, вы можете изменить путь к файлу, чтобы он был локальной копией того же текстового файла. Если кнопка «Изменить параметры» доступна в области ошибок, ее можно выбрать и изменить путь к файлу.
Столбец таблицы не найден
Эта ошибка обычно активируется, когда шаг создает прямую ссылку на имя столбца, которое не существует в запросе.
Пример. У вас есть запрос из текстового файла, в котором одно из имен столбцов — Column. В запросе есть шаг, который переименовывает этот столбец в date. Но в исходном текстовом файле произошло изменение, и у него больше нет заголовка столбца с именем Column , так как он был изменен вручную на Date. Power Query не удается найти заголовок столбца с именем Column, поэтому он не может переименовать столбцы. Отображается ошибка, показанная на следующем рисунке.
Возможные решения: существует несколько решений для этого случая, но все они зависят от того, что вы хотите сделать. В этом примере, так как правильный заголовок столбца Date уже поступает из текстового файла, можно просто удалить шаг, который переименовывает столбец. Это позволит выполнять запрос без этой ошибки.
Другие распространенные ошибки на уровне шага
При объединении или объединении данных между несколькими источниками данных может возникнуть ошибка Formula.Firewall , например, показанная на следующем рисунке.

Эта ошибка может быть вызвана рядом причин, таких как уровни конфиденциальности данных между источниками данных или способом объединения или объединения этих источников данных. Дополнительные сведения о диагностике этой проблемы см. в брандмауэре конфиденциальности данных.
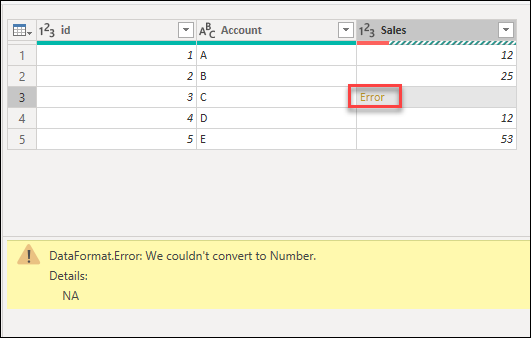
Ошибка уровня ячейки
Ошибка на уровне ячейки не препятствует загрузке запроса, но отображает значения ошибок в ячейке. При выборе пробела в ячейке отображается область ошибок под предварительным просмотром данных.
Средства профилирования данных помогают более легко выявлять ошибки на уровне ячеек с помощью функции качества столбца. Дополнительные сведения: средства профилирования данных
Обработка ошибок на уровне ячейки
При возникновении ошибок на уровне ячеек Power Query предоставляет набор функций для их обработки путем удаления, замены или сохранения ошибок.
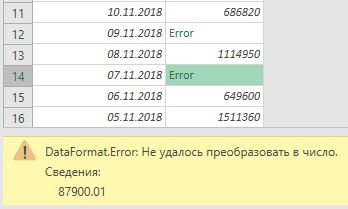
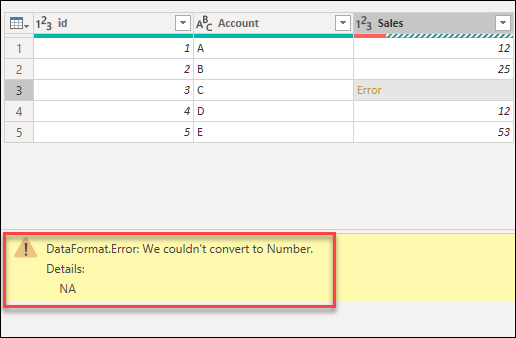
В следующих разделах указанные примеры будут использовать тот же пример запроса, что и начальная точка. В этом запросе есть столбец Sales с одной ячейкой с ошибкой, вызванной ошибкой преобразования. Значение внутри этой ячейки было NA, но при преобразовании этого столбца в целое число Power Query не удалось преобразовать НС в число, поэтому отображается следующая ошибка.
Удаление ошибок
Чтобы удалить строки с ошибками в Power Query, сначала выберите столбец, содержащий ошибки. На вкладке «Главная» в группе «Уменьшить строки» выберите «Удалить строки«. В раскрывающемся меню выберите «Удалить ошибки«.
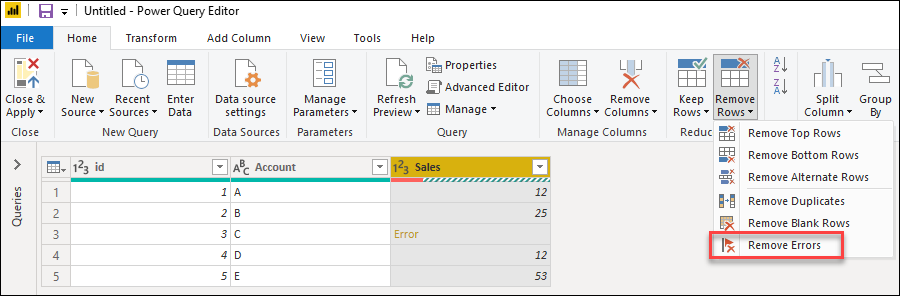
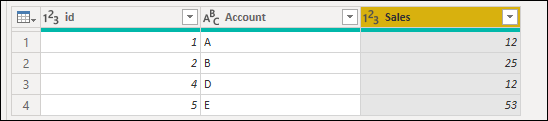
Результат этой операции даст вам таблицу, которую вы ищете.
Замена ошибок
Если вместо удаления строк с ошибками необходимо заменить ошибки фиксированным значением, это также можно сделать. Чтобы заменить строки с ошибками, сначала выберите столбец, содержащий ошибки. На вкладке «Преобразование» в группе «Любой столбец » выберите «Заменить значения«. В раскрывающемся меню выберите «Заменить ошибки«.
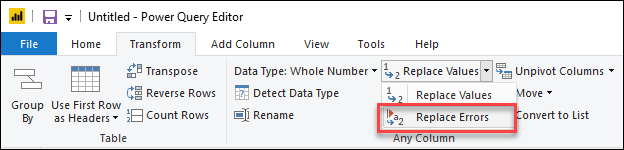
В диалоговом окне «Замена ошибок » введите значение 10 , так как вы хотите заменить все ошибки значением 10.

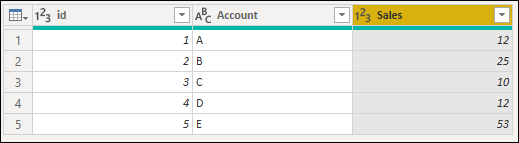
Результат этой операции даст вам таблицу, которую вы ищете.
Сохранение ошибок
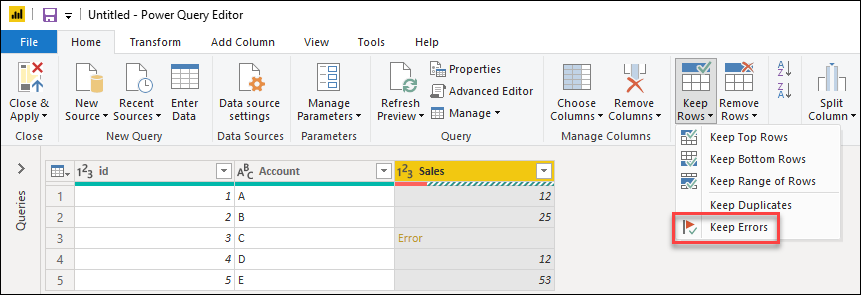
Power Query может служить хорошим средством аудита для выявления строк с ошибками, даже если вы не исправите ошибки. Здесь могут быть полезны ошибки keep . Чтобы сохранить строки с ошибками, сначала выберите столбец, содержащий ошибки. На вкладке «Главная» в группе «Уменьшить строки» выберите «Сохранить строки«. В раскрывающемся меню выберите «Сохранить ошибки«.
Результат этой операции даст вам таблицу, которую вы ищете.

Распространенные ошибки на уровне ячеек
Как и в случае с любой ошибкой на уровне шага, мы рекомендуем внимательно изучить причины ошибок, сообщения об ошибках и сведения об ошибках, предоставленные на уровне ячейки, чтобы понять, что вызывает ошибки. В следующих разделах рассматриваются некоторые наиболее частые ошибки на уровне ячеек в Power Query.
Ошибки преобразования типов данных
Обычно активируется при изменении типа данных столбца в таблице. Некоторые значения, найденные в столбце, не удалось преобразовать в нужный тип данных.
Пример. У вас есть запрос, содержащий столбец с именем Sales. Одна ячейка в этом столбце содержит значение NA в качестве значения ячейки, а остальные имеют целые числа в качестве значений. Вы решили преобразовать тип данных столбца из текста в целое число, но ячейка со значением NA приводит к ошибке.
Возможные решения. После идентификации строки с ошибкой можно либо изменить источник данных, чтобы отразить правильное значение, а не NA, либо применить операцию «Заменить» , чтобы указать значение для любых значений NA , вызывающих ошибку.
Ошибки операций
При попытке применить операцию, которая не поддерживается, например умножение текстового значения на числовое значение, возникает ошибка.
Пример. Вы хотите создать настраиваемый столбец для запроса, создав текстовую строку, содержащую фразу «Total Sales: » сцеплено со значением из столбца Sales . Ошибка возникает из-за того, что операция объединения поддерживает только текстовые столбцы, а не числовые.

Возможные решения. Перед созданием этого настраиваемого столбца измените тип данных столбца Sales на текст.
Источник