15. Оценка дисперсии случайной ошибки модели регрессии
При проведении регрессионного анализа основная трудность заключается в том, что генеральная дисперсия случайной ошибки является неизвестной величиной, что вызывает необходимость в расчёте её несмещённой выборочной оценки.
Несмещённой оценкой дисперсии (или исправленной дисперсией) случайной ошибки линейной модели парной регрессии называется величина, рассчитываемая по формуле:
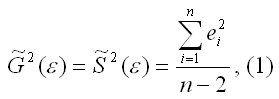
где n – это объём выборочной совокупности;
еi– остатки регрессионной модели:
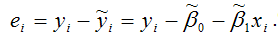
Для линейной модели множественной регрессии несмещённая оценка дисперсии случайной ошибки рассчитывается по формуле:
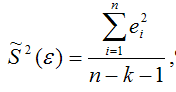
где k – число оцениваемых параметров модели регрессии.
Оценка матрицы ковариаций случайных ошибок Cov(?) будет являться оценочная матрица ковариаций:
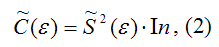
где In – единичная матрица.
Оценка дисперсии случайной ошибки модели регрессии распределена по ?2(хи-квадрат) закону распределения с (n-k-1) степенями свободы.
Для доказательства несмещённости оценки дисперсии случайной ошибки модели регрессии необходимо доказать справедливость равенства
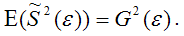
Доказательство. Примем без доказательства справедливость следующих равенств:
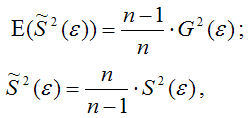
где G2(?) – генеральная дисперсия случайной ошибки;
S2(?) – выборочная дисперсия случайной ошибки;
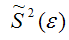
– выборочная оценка дисперсии случайной ошибки.
Тогда:
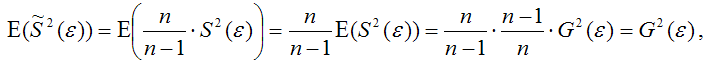
т. е.
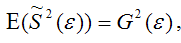
что и требовалось доказать.
Следовательно, выборочная оценка дисперсии случайной ошибки
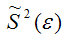
является несмещённой оценкой генеральной дисперсии случайной ошибки модели регрессии G2(?).
При условии извлечения из генеральной совокупности нескольких выборок одинакового объёма n и при одинаковых значениях объясняющих переменных х, наблюдаемые значения зависимой переменной у будут случайным образом колебаться за счёт случайного характера случайной компоненты ?. Отсюда можно сделать вывод, что будут варьироваться и зависеть от значений переменной у значения оценок коэффициентов регрессии и оценка дисперсии случайной ошибки модели регрессии.
Для иллюстрации данного утверждения докажем зависимость значения МНК-оценки
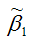
от величины случайной ошибки ?.
МНК-оценка коэффициента ?1 модели регрессии определяется по формуле:
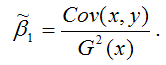
В связи с тем, что переменная у зависит от случайной компоненты ? (yi=?0+?1xi+?i), то ковариация между зависимой переменной у и независимой переменной х может быть представлена следующим образом:
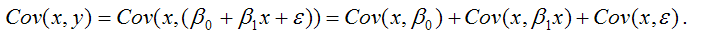
Для дальнейших преобразования используются свойства ковариации:
1) ковариация между переменной х и константой С равна нулю: Cov(x,C)=0, C=const;
2) ковариация переменной х с самой собой равна дисперсии этой переменной: Cov(x,x)=G2(x).
Исходя из указанных свойств ковариации, справедливы следующие равенства:
Cov(x,?0)=0 (?0=const);
Cov(x, ?1x)= ?1*Cov(x,x)= ?1*G2(x).
Следовательно, ковариация между зависимой и независимой переменными Cov(x,y) может быть записана как:
Cov(x,y)= ?1G2(x)+Cov(x,?).
В результате МНК-оценка коэффициента ?1 модели регрессии примет вид:
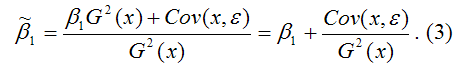
Таким образом, МНК-оценка
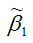
может быть представлена как сумма двух компонент:
1) константы ?1, т. е. истинного значения коэффициента;
2) случайной ошибки Cov(x,?), вызывающей вариацию коэффициента модели регрессии.
Однако на практике подобное разложение МНК-оценки невозможно, потому что истинные значения коэффициентов модели регрессии и значения случайной ошибки являются неизвестными. Теоретически данное разложение можно использовать при изучении статистических свойств МНК-оценок.
Аналогично доказывается, что МНК-оценка
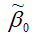
коэффициента модели регрессии и несмещённая оценка дисперсии случайной ошибки
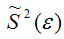
могут быть представлены как сумма постоянной составляющей (константы) и случайной компоненты, зависящей от ошибки модели регрессии ?.
Данный текст является ознакомительным фрагментом.
Читайте также
11. Критерии оценки неизвестных коэффициентов модели регрессии
11. Критерии оценки неизвестных коэффициентов модели регрессии
В ходе регрессионного анализа была подобрана форма связи, которая наилучшим образом отражает зависимость результативной переменной у от факторной переменной х:y=f(x).Необходимо оценить неизвестные
14. Оценка коэффициентов модели парной регрессии с помощью выборочного коэффициента регрессии
14. Оценка коэффициентов модели парной регрессии с помощью выборочного коэффициента регрессии
Помимо метода наименьших квадратов, с помощью которого в большинстве случаев определяются неизвестные параметры модели регрессии, в случае линейной модели парной регрессии
18. Характеристика качества модели регрессии
18. Характеристика качества модели регрессии
Качеством модели регрессии называется адекватность построенной модели исходным (наблюдаемым) данным.Для оценки качества модели регрессии используются специальные показатели.Качество линейной модели парной регрессии
22. Проверка гипотезы о значимости коэффициентов модели парной регрессии
22. Проверка гипотезы о значимости коэффициентов модели парной регрессии
Проверкой статистической гипотезы о значимости отдельных параметров модели называется проверка предположения о том, что данные параметры значимо отличаются от нуля.Необходимость проверки
25. Точечный и интервальный прогнозы для модели парной регрессии
25. Точечный и интервальный прогнозы для модели парной регрессии
Одна из задач эконометрического моделирования заключается в прогнозировании поведения исследуемого явления или процесса в будущем. В большинстве случаев данная задача решается на основе регрессионных
32. Построение частных коэффициентов корреляции для модели множественной регрессии через показатель остаточной дисперсии и коэффициент множественной детерминации
32. Построение частных коэффициентов корреляции для модели множественной регрессии через показатель остаточной дисперсии и коэффициент множественной детерминации
Помимо рекуррентных формул, которые используются для построения частных коэффициентов корреляции для
35. Проверка гипотезы о значимости коэффициентов регрессии и модели множественной регрессии в целом
35. Проверка гипотезы о значимости коэффициентов регрессии и модели множественной регрессии в целом
Проверка значимости коэффициентов регрессии означает проверку основной гипотезы об их значимом отличии от нуля.Основная гипотеза состоит в предположении о незначимости
39. Модели регрессии, нелинейные по факторным переменным
39. Модели регрессии, нелинейные по факторным переменным
При исследовании социально-экономических явлений и процессов далеко не все зависимости можно описать с помощью линейной связи. Поэтому в эконометрическом моделировании широко используется класс нелинейных
40. Модели регрессии, нелинейные по оцениваемым коэффициентам
40. Модели регрессии, нелинейные по оцениваемым коэффициентам
Нелинейными по оцениваемым параметрам моделями регрессииназываются модели, в которых результативная переменная yi нелинейно зависит от коэффициентов модели ?0…?n.К моделям регрессии, нелинейными по
41. Модели регрессии с точками разрыва
41. Модели регрессии с точками разрыва
Определение. Моделями регрессии с точками разрыва называются модели, которые нельзя привести к линейной форме, т. е. внутренне нелинейные модели регрессии.Модели регрессии делятся на два класса:1) кусочно-линейные модели регрессии;2)
44. Методы нелинейного оценивания коэффициентов модели регрессии
44. Методы нелинейного оценивания коэффициентов модели регрессии
Функцией потерь или ошибок называется функционал вида
Также в качестве функции потерь может быть использована сумма модулей отклонений наблюдаемых значений результативного признака у от теоретических
46. Проверка гипотезы о значимости нелинейной модели регрессии. Проверка гипотезы о линейной зависимости между переменными модели регрессии
46. Проверка гипотезы о значимости нелинейной модели регрессии. Проверка гипотезы о линейной зависимости между переменными модели регрессии
На нелинейные модели регрессии, которые являются внутренне линейными, т. е. сводимыми к линейному виду, распространяются все
57. Гетероскедастичность остатков модели регрессии
57. Гетероскедастичность остатков модели регрессии
Случайной ошибкой называется отклонение в линейной модели множественной регрессии:?i=yi–?0–?1x1i–…–?mxmiВ связи с тем, что величина случайной ошибки модели регрессии является неизвестной величиной, рассчитывается
60. Устранение гетероскедастичности остатков модели регрессии
60. Устранение гетероскедастичности остатков модели регрессии
Существует множество методов устранения гетероскедастичности остатков модели регрессии. Рассмотрим некоторые из них.Наиболее простым методом устранения гетероскедастичности остатков модели регрессии
63. Устранение автокорреляции остатков модели регрессии
63. Устранение автокорреляции остатков модели регрессии
В связи с тем, что наличие в модели регрессии автокорреляции между остатками модели может привести к негативным результатам всего процесса оценивания неизвестных коэффициентов модели, автокорреляция остатков
67. Модели регрессии с переменной структурой. Фиктивные переменные
67. Модели регрессии с переменной структурой. Фиктивные переменные
При построении модели регрессии может возникнуть ситуация, когда в неё необходимо включить не только количественные, но и качественные переменные (например, возраст, образование, пол, расовую
В предыдущем параграфе мы научились описывать облако точек некоторой прямой, не делая никаких предположений по поводу природы анализируемых данных. Иными словами, мы не предполагали никакой конкретной модели, описывающей процесс порождения наших данных. Для дальнейшего продвижения, однако, это будет нам необходимо.
Вернемся к нашему примеру с квартирами. Естественно ожидать, что на цену квартиры (y) влияет её площадь (x), а также прочие факторы, например, удаленность квартиры от метро, этаж, наличие балкона и так далее. Обозначим эти прочие факторы переменной (varepsilon ). С учетом этих соображений естественно предположить следующую модель цены квартиры:
( {y}_i = {β}_1 + {β}_2 {x}_i + {ε}_i , i = 1,2 , … , n ).
Здесь — площадь i-ой квартиры в квадратных метрах, — цена i-ой квартиры в миллионах рублей, — прочие факторы, которые оказывают влияние на цену квартиры (y_i). Переменную (varepsilon ) принято называть случайной ошибкой модели. Буквой n будем обозначать число наблюдений в доступной нам выборке.
В целом такая модель выглядит достаточно разумно. Если бы мы знали точные значения коэффициентов (beta _1) и (beta _2), мы могли бы использовать её в практических целях. Например, зная, что (beta _2=0,3), строительная компания могла бы учитывать при планировании продаж, что один дополнительный квадратный метр площади квартиры оценивается рынком в 0,3 млн рублей. К сожалению, на практике значения параметров (beta _1) и (beta _2) нам не известны, зато мы можем собрать статистические данные и получить их (приблизительные) оценки.
Здесь уместно подчеркнуть важное различие между
- параметрами (beta _k) (без «крышек») в выражении (y_i=beta _1+beta _2x_i+varepsilon _i),
- и их оценками (widehat {beta _k})(c «крышками») в выражении .
Это различие состоит в том, что и — это некоторые истинные значения параметров модели, которые на практике никогда не известны исследователю. Все, что исследователь в силах сделать — собрать данные и эти значения оценить приближенно. — это оценки истинных значений, которые мы получаем, используя наши выборочные данные. Так как (widehat {beta _1}text{и}widehat {beta _2}) рассчитываются на основе случайной выборки, то они являются случайными величинами.
Естественно, мы хотим, чтобы оценки были близки к истинным значениям оцениваемых параметров. Поэтому нам важно знать: при каких условиях мы можем доверять этим оценкам, то есть рассчитывать на то, что результат использования МНК будет близок к истине? Эти условия называют предпосылками классической линейной модели парной регрессии.
Предпосылки классической линейной модели парной регрессии (КЛМПР):
- Модель линейна по параметрам и корректно специфицирована
(y_i=beta _1+beta _2x_i+varepsilon _i,i=1,2,{dots},n.) - (x_1,x_2,{dots},x_n) — детерминированные (неслучайные) величины, не все одинаковые.
- Математическое ожидание случайных ошибок равно нулю
(Evarepsilon _i=0). - Дисперсия случайной ошибки одинакова для всех наблюдений (mathit{var}left(varepsilon _iright)=sigma ^2).
- Случайные ошибки, относящиеся к разным наблюдениям, взаимно независимы.
- Случайные ошибки имеют нормальное распределение (varepsilon _iNleft(0,sigma ^2right)).
Мы обсудили выше соображения, исходя из которых может быть сформулирована предпосылка №1. Как мы увидим в дальнейшем, правильная спецификация подразумевает в первую очередь отсутствие среди прочих факторов других переменных, которые одновременно влияют на y и коррелируют с x. Нарушение этого требования приводит к серьезным проблемам, которые мы осветим в конце данной главы.
Предпосылка №2 касается двух важных аспектов. Во-первых, мы предполагаем, что регрессоры (x_i) являются неслучайными величинами. Это техническое предположение, которое упростит некоторые выкладки в этом разделе. Обратите внимание, что (varepsilon _i) в отличие от регрессоров являются случайными величинами, а следовательно, и (y_i) тоже случайны, так как представляют собой сумму неслучайной компоненты (beta _1+beta _2x_i) и случайной величины (varepsilon _i). В терминах нашего примера с квартирами про эту предпосылку можно думать так: представим, что вы собрали случайную выборку из 100 квартир площадью 30 м2, 100 квартир площадью 35 м2 и 100 квартир площадью 40 м2. Если вы соберете другую выборку из трехсот квартир с такими же площадями, то значения регрессоров (x_i) останутся теми же самыми, а вот значения объясняемой переменной (y_i) поменяются, поэтому в данном примере разумно думать про регрессоры как про неслучайные величины, а про величины (y_i) — как про случайные.
Во-вторых, в рамках предпосылки №2 мы предполагаем, что не все значения регрессоров одинаковы. Нетрудно понять, зачем нужно это предположение, если взглянуть на формулу оценки коэффициента
(widehat {beta _2}=frac{widehat {mathit{Cov}}left(x,yright)}{widehat {mathit{Var}}left(xright)}). Обратите внимание, что в знаменателе этой формулы стоит выборочная дисперсия переменной x, но если все значения этой переменной в выборке будут одинаковы, то эта дисперсия окажется равной нулю, и из-за этого мы не сможем рассчитать МНК-оценку (widehat {beta _2}).
Предпосылка №3 говорит о том, что прочие факторы могут приводить к отклонению (y_i) от величины (beta _1+beta _2x_i) как вверх, так и вниз, но в среднем эти отклонения компенсируют друг друга.
Предпосылка №4 требует, чтобы разброс случайных ошибок в среднем был постоянен для всех наблюдений. Её смысл удобно пояснить, используя картинку. Посмотрите на рисунки 2.3а и 2.3б. В первом случае предпосылка о постоянстве дисперсии случайной ошибки выполнена, а во втором — нет, так как разброс точек вокруг линии регрессии растет по мере увеличения объясняющей переменной, следовательно, мы можем заключить, что дисперсия случайной ошибки не является одинаковой для всех наблюдений. Ситуация, когда предпосылка №4 выполнена (то есть ситуация, соответствующая рисунку 2.3а) называется гомоскедастичностью случайных ошибок. Альтернативная ситуация называется гетероскедастичностью случайных ошибок.
Рисунок 2.3а. Гомоскедастичность случайных ошибок
Рисунок 2.3б. Гетероскедастичность случайных ошибок
Из предпосылки №5 следует, что случайные ошибки, относящиеся к разным наблюдениям, не коррелированы друг с другом: (mathit{cov}left(varepsilon _i,varepsilon _jright)=0) при (i{neq}j).
Предпосылка №6 не требуется для обеспечения хороших свойств оценок коэффициентов (обратите внимание, что ниже, в формулировке теоремы Гаусса — Маркова, она не фигурирует), однако будет полезна для тестирования гипотез и построения доверительных интервалов.
Теорема Гаусса — Маркова. Если выполнены предпосылки 1-5 классической линейной модели парной регрессии, то МНК-оценки коэффициентов (widehat {beta _1}text{и}widehat {beta _2}) будут:
(а) несмещенными,
(б) эффективными в классе всех несмещенных и линейных по y оценок1.
Напомним, что оценка называется несмещенной, если её математическое ожидание совпадает с истинным значением оцениваемого параметра: (Ewidehat {beta _2}=beta _2). Свойство эффективности означает, что оценка характеризуется минимальной дисперсией среди всех альтернативных оценок в данном классе, то есть является «наиболее точной» оценкой интересующего нас параметра. Линейность по y означает, что мы рассматриваем все оценки, которые могут быть представлены в виде линейной комбинации значений объясняемой переменной, то есть записаны в виде (sum _{i=1}^nc_i{ast}y_i).
Если переформулировать свойства несмещенности и эффективности нестрого, то можно сказать, что при выполнении предпосылок 1-5 МНК-оценки параметров окажутся хорошими: они будут «в среднем правильными» и наиболее точными. Теорема Гаусса — Маркова дает нам важную мотивацию для того, чтобы оценивать параметры нашей модели именно методом наименьших квадратов, а не каким-то альтернативным способом.
Лирическое отступление о предпосылках
Каждый раз, когда я рассказываю студентам об этой теореме, в моей голове разыгрывается примерно такой диалог между двумя эконометристами (назовем их Филипп и Дима).
Дима: Реалистичны ли предпосылки КЛМПР?
Филипп: Не очень. Например, в реальных исследованиях на пространственных данных ты почти всегда будешь сталкиваться с нарушением требования постоянства дисперсии случайной ошибки (нарушением предпосылки №4). Во многих прикладных исследованиях также окажется более целесообразным думать про регрессоры как про случайные, а не детерминированные случайные величины (это отклонение от предпосылки №2). На нормальность случайных ошибок (предпосылка №6) я бы тоже не рассчитывал…
Дима: Зачем же тогда мы её изучаем? Давайте сразу перейдем к более реалистичной модели.
Филипп: Мы начинаем с КЛМПР, так как это самая простая модель, на примере которой мы можем обсудить ряд важных эконометрических идей и при этом не погрязнуть в технических трудностях. В последующих главах мы будем постепенно отказываться от предпосылок КЛМПР и в результате получим набор моделей и методов, которые хорошо подходят для реальных исследований на живых данных. Кроме того, мы научимся проверять выполнение тех или иных предположений КЛМПР, чтобы понять, когда стоит их использовать, а когда — нет.
В частности, последствия нарушения предпосылки №3 читателю предлагается проанализировать уже в этом параграфе, в одном из заданий для самостоятельного решения.
- Несмещенность и эффективность — это свойства оценок при фиксированном объеме выборки (при фиксированном n). Во многих случаях удобно также использовать асимптотические свойства оценок, то есть свойства, которые имеют место при (nrightarrow {infty}) (например, состоятельность). Об асимптотических свойствах МНК-оценок мы подробно поговорим в одной из последующих глав. ↵
Гетероскедастичность
Случайной ошибкой
называется отклонение в линейной модели
множественной регрессии:
εi=yi–β0–β1x1i–…–βmxmi
В связи с тем, что
величина случайной ошибки модели
регрессии является неизвестной величиной,
рассчитывается выборочная оценка
случайной ошибки модели регрессии по
формуле:
![]()
где ei – остатки
модели регрессии.
Термин
гетероскедастичность в широком смысле
понимается как предположение о дисперсии
случайных ошибок модели регрессии.
При построении
нормальной линейной модели регрессии
учитываются следующие условия, касающиеся
случайной ошибки модели регрессии:
6) математическое
ожидание случайной ошибки модели
регрессии равно нулю во всех наблюдениях:
![]()
7) дисперсия случайной
ошибки модели регрессии постоянна для
всех наблюдений:
![]()
8) между значениями
случайных ошибок модели регрессии в
любых двух наблюдениях отсутствует
систематическая взаимосвязь, т. е.
случайные ошибки модели регрессии не
коррелированны между собой (ковариация
случайных ошибок любых двух разных
наблюдений равна нулю):
![]()
Второе условие
![]()
означает
гомоскедастичность (homoscedasticity – однородный
разброс) дисперсий случайных ошибок
модели регрессии.
Под гомоскедастичностью
понимается предположение о том, что
дисперсия случайной ошибки βi является
известной постоянной величиной для
всех наблюдений.
Но на практике
предположение о гомоскедастичности
случайной ошибки βi или остатков модели
регрессии ei выполняется не всегда.
Под гетероскедастичностью
(heteroscedasticity – неоднородный разброс)
понимается предположение о том, что
дисперсии случайных ошибок являются
разными величинами для всех наблюдений,
что означает нарушение второго условия
нормальной линейной модели множественной
регрессии:
![]()
Гетероскедастичность
можно записать через ковариационную
матрицу случайных ошибок модели
регрессии:

Тогда можно
утверждать, что случайная ошибка модели
регрессии βi подчиняется нормальному
закону распределения с нулевым
математическим ожиданием и дисперсией
G2Ω:
εi~N(0; G2Ω),
где Ω – матрица
ковариаций случайной ошибки.
Если дисперсии
случайных ошибок
![]()
модели регрессии
известны заранее, то проблема
гетероскедастичности легко устраняется.
Однако в большинстве случаев неизвестными
являются не только дисперсии случайных
ошибок, но и сама функция регрессионной
зависимости y=f(x), которую предстоит
построить и оценить.
Для обнаружения
гетероскедастичности остатков модели
регрессии необходимо провести их анализ.
При этом проверяются следующие гипотезы.
Основная гипотеза
H0 предполагает постоянство дисперсий
случайных ошибок модели регрессии, т.
е. присутствие в модели условия
гомоскедастичности:
![]()
Альтернативная
гипотеза H1 предполагает непостоянство
дисперсиий случайных ошибок в различных
наблюдениях, т. е. присутствие в модели
условия гетероскедастичности:
![]()
Гетероскедастичность
остатков модели регрессии может привести
к негативным последствиям:
1) оценки неизвестных
коэффициентов нормальной линейной
модели регрессии являются несмещёнными
и состоятельными, но при этом теряется
свойство эффективности;
2) существует большая
вероятность того, что оценки стандартных
ошибок коэффициентов модели регрессии
будут рассчитаны неверно, что конечном
итоге может привести к утверждению
неверной гипотезы о значимости
коэффициентов регрессии и значимости
модели регрессии в целом.
Гомоскедастичность
Гомоскедастичность
остатков означает, что дисперсия каждого
отклонения одинакова для всех значений
x. Если это условие не соблюдается, то
имеет место гетероскедастичность.
Наличие гетероскедастичности можно
наглядно видеть из поля корреляции.


Т.к. дисперсия
характеризует отклонение то из рисунков
видно, что в первом случае дисперсия
остатков растет по мере увеличения x, а
во втором – дисперсия остатков достигает
максимальной величины при средних
значениях величины x и уменьшается при
минимальных и максимальных значениях
x. Наличие гетероскедастичности будет
сказываться на уменьшении эффективности
оценок параметров уравнения регрессии.
Наличие гомоскедастичности или
гетероскедастичности можно определять
также по графику зависимости остатков
от теоретических значений
![]() .
.

Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
[c.85]
Основные положения теории Шарпа. Коэффициенты регрессии. Измерение ожидаемой доходности и риска портфеля. Дисперсия ошибок. Определение весов ценных бумаг в модели Шарпа. Нахождение оптимального портфеля. Сравнительный анализ методов Г. Марковица и В. Шарпа.
[c.335]
Наиболее хорошо изучены линейные регрессионные модели, удовлетворяющие условиям (1.6), (1.7) и свойству постоянства дисперсии ошибок регрессии, — они называются классическими моделями.
[c.19]
Очевидно, для продвижения к этой цели необходимы некоторые дополнительные предположения относительно характера гетероскедастичности. В самом деле, без подобных предположений, очевидно, невозможно было бы оценить п параметров (п дисперсий ошибок регрессии а ) с помощью п наблюдений.
[c.161]
Решение. Предположим, что дисперсии ошибок о, связаны уравнением регрессии
[c.163]
Вспомним, что наиболее часто употребляемые процедуры устранения гетероскедастичности так или иначе были основаны на предположении, что дисперсия ошибок регрессии ст2 является функцией от каких-то регрессоров. Если а2 существенно зависит от регрессора Z, а при спецификации модели регрессор Z не был включен в модель, стандартные процедуры могут не привести к устранению гетероскедастичности.
[c.250]
В случае постоянства дисперсии ошибок МНК необъясненная дисперсия для меньших значений X должна быть приблизительно равна необъясненной дисперсии для больших значений X, то есть должно быть справедливым следующее равенство [c.125]
Чем ближе к единице отношение / S2, тем больше оснований рассчитывать на то, что дисперсия ошибок МНК постоянна. Случайная величина F = Sl / S2 подчиняется F -распределению
[c.125]
Непостоянство дисперсии ошибок МНК возникает как правило в том случае, если неправильно выбран вид математической модели зависимости фактора X и отклика 7. Например, если нелинейную зависимость пытаются аппроксимировать линейной функцией.
[c.126]
Пятая часть полностью посвящена приложению матричного дифференциального исчисления к линейной регрессионной модели. Она содержит исчерпывающее изложение проблемы оценивания, связанной с неслучайной частью модели при различных предположениях о рангах и других ограничениях. Кроме того, она содержит ряд параграфов, связанных со стохастической частью модели, например оценивание дисперсии ошибок и прогноз ошибок. Включен также небольшой параграф, посвященный анализу чувствительности. Вводная глава содержит необходимые предварительные сведения из теории вероятностей и математической статистики.
[c.16]
Дисперсия ошибок прогноза в задаче (3.6) — (3.7) достигает минимума в точке , являющейся основанием перпендикуляра, опущенного из точки т] на подпространство Q, определяемое равенством (3.7). Соотношение (3.10) эквивалентно равенству
[c.309]
Ограничение (а) не вызывает претензий. Условие (б) также естественно. Ясно, что механизм сглаживания и прогноза, при котором математическое ожидание или дисперсия ошибок фильтрации или интенсивность искусственного рассеивания достаточно велики, вряд ли рационален и тем более не может быть признан оптимальным.
[c.320]
Задача прогнозирования по минимуму дисперсии ошибок при различных статистических характеристиках входных случайных процессов и ошибок измерений подробно обсуждалась в литературе. Имеются и стандартные аналоговые устройства и программы для ЦВМ, реализующие соответствующие схемы. Экстремальная задача, к которой сводится вычисление характеристик генераторов случайных шумов, несомненно, проще исходной вариационной задачи.
[c.334]
Матрица корреляции k j R регулируемых ошибок прогноза, оптимального в смысле показателя качества R( k ), может быть получена из корреляционной матрицы kff a ошибок прогноза, оптимальных в смысле минимума дисперсии ошибок в каждой координате в каждый момент времени, по следующей формуле [c.339]
Из (1.14), в частности, следует, что коэффициент корреляции признаков, на которые наложены ошибки измерения, всегда меньше по абсолютной величине, чем коэффициент корреляции исходных признаков. Другими словами, ошибки измерения всегда ослабляют исследуемую корреляционную связь между исходными переменными, и это искажение тем меньше, чем меньше отношения дисперсий ошибок к дисперсиям самих исходных переменных. Формула (1.14) позволяет скорректировать искаженное значение коэффициента корреляции для этого нужно либо знать разрешающие характеристики измерительных приборов (и, следовательно, величины дисперсий ошибок а и а ), либо провести дополнительное исследование по их выявлению.
[c.73]
Пример 7.4 ]. Известно, что дисперсия о2, вызванная ошибками измерения, при некоторых видах количественного анализа составляет 0,5. Если заменить измерительный прибор и произвести 10-кратное измерение одного и того же стандартного образца, а затем подсчитать дисперсию, то она составит s2 = 0,25. Может показаться, что дисперсия ошибок измерения изменилась, превысив 5%-ный уровень значимости. Так ли это [c.128]
Теорема Гаусса-Маркова. Оценка дисперсии ошибок сг2
[c.41]
Оценка дисперсии ошибок а2
[c.43]
Формулы (2.11), (2.13) дают дисперсии оценок о, Ь коэффициентов регрессии в том случае, если а2 известно. На практике, как правило, дисперсия ошибок а2 неизвестна и оценивается по наблюдениям одновременно с коэффициентами регрессии а, Ь. В этом случае вместо дисперсий оценок о, b мы можем получить лишь оценки дисперсий о, 6, заменив а2 на s2 из (2.15) в (2.11), (2.13), (2.14) [c.45]
Распределение оценки дисперсии ошибок s2
[c.47]
Так как оценка дисперсии ошибок s2 является функцией от остатков регрессии et, то для того чтобы доказать независимость s2 и (2,6), достаточно доказать независимость et и (2,6). Оценки 2, 6 так же, как и остатки регрессии et, являются линейными функциями ошибок t (см. (2.4а), (2.46), (2.20)) и поэтому имеют совместное нормальное распределение. Известно (приложение МС, п. 4, N4), что два случайных вектора, имеющие совместное нормальное распределение, независимы тогда и только тогда, когда они некоррелированы. Таким образом, чтобы доказать независимость s2 и (а, 6), нам достаточно доказать некоррелированность et и (2,6).
[c.48]
Значение Д2 увеличилось по сравнению с первой регрессией. Переход к удельным данным приводит к уменьшению дисперсии ошибок модели.
[c.58]
Пусть SML = Y et/ n и OLS — ] et/ (n — 1 — оценки методов максимального правдоподобия и наименьших квадратов для дисперсии ошибок <т2 в классической модели парной регрессии Yt =
[c.62]
Оценка дисперсии ошибок а1. Распределение s2
[c.72]
Сумма квадратов остатков е2 = е е является естественным кандидатом на оценку дисперсии ошибок а1 (конечно, с некоторым поправочным коэффициентом, зависящим от числа степеней свободы) [c.73]
Тест ранговой корреляции Спирмена использует наиболее общие предположения о зависимости дисперсий ошибок регрессии от значений регрессоров [c.158]
Тест Уайта. Тест ранговой корреляции Спирмена и тест Голдфелда—Квандта позволяют обнаружить лишь само наличие гетероскедастичности, но они не дают возможности проследить количественный характер зависимости дисперсий ошибок регрессии от значений регрессоров и, следовательно, не представляют каких-либо способов устранения гетероскедастичности.
[c.161]
Наиболее простой и часто употребляемый тест на гетероске-дастичность — тест Уайта. При использовании этого теста предполагается, что дисперсии ошибок регрессии представляют собой одну и ту же функцию от наблюдаемых значений регрессоров, т.е.
[c.161]
Другим недостатком тестов Уайта и Глейзера является то, что факт невыявления ими гетероскедастичности, вообще говоря, не означает ее отсутствия. В самом деле, принимая гипотезу Щ, мы принимаем лишь тот факт, что отсутствует определенного вида зависимость дисперсий ошибок регрессии от значений регрессоров.
[c.166]
Построенные экологометрические модели требуют оценки их достоверности. При выполнении статистических исследований полученные данные тщательно анализируются на предмет удовлетворения их предположения о независимости случайных наблюдений, симметричности распределения, из которого получена выборка, равенства дисперсии ошибок, одинаковости распределения нескольких случайных величин и т.д. Все эти предположения могут рассматриваться как гипотезы, которые необходимо проверить.
[c.57]
Доказано (см., например, [37]), что приведенную задачу оптимального стохастического управления можно разделить на две задачу сглаживания и лрогноза по минимуму дисперсии ошибок и задачу оптимального детерминированного управления. При более сложном критерии качества управления и при дополнительных ограничениях на переменные состояния и управляющие параметры такое разделение не всегда удается я, его, по-видимому, не всегда целесообразно производить.
[c.44]
Здесь Paaa(tt, » ) — система функций веса, минимизирующих дисперсию ошибок За(/г-) прогноза W (ti, т) — тождественно не равные нулю функ-22 339
[c.339]
В ходе анализа финансовых данных любой ряд динамики, будь то процентные ставки или цены на финансовые активы, можно разбить на две компоненты, одна из которых изменяется случайным образом, а другая подчиняется определенному закону. Колебания финансовых переменных значительно изменяются во времени бурные периоды с высокой волатильностью переменных сменяют спокойные периоды и наоборот. В некоторых случаях вола-тильность играет ключевую роль в ценообразовании на финансовые активы. В частности, курсы акций напрямую зависят от ожидаемой волатильности доходов корпораций. Все финансовые учреждения без исключения стремятся адекватно оценить волатильность в целях успешного управления рисками. В свое время Трюгве Хаавельмо, нобелевский лауреат по экономике 1989 г., предложил рассматривать изменение экономических переменных как однородный стохастический (случайный) процесс. Вплоть до 1980-х гг. экономисты для анализа финансовых рынков применяли статистические методы, предполагавшие постоянную волатильность во времени. В 1982 г. Роберт Ингл развил новую эконометрическую концепцию, позволяющую анализировать периоды с разной волатильностью. Он ввел кластеризацию данных и условную дисперсию ошибок, которая завесит от времени. Свою разработку Ингл назвал авторегрессионной гетероскедастической моделью , с ее помощью можно точно описать множество временных рядов, встречающихся в экономике. Метод Ингла сегодня применяется финансовыми аналитиками в целях оценки финансовых активов и портфельных рисков.
[c.197]
Отметим, что оценки максимального правдоподобия параметров а, 6 совпадают с оценками метода наименьших квадратов OML = SOLS, ML OLS- Это легко видеть из того, что уравнения (2.37а) и (2.376) совпадают с соответствующими уравнениями метода наименьших квадратов (2.2). Оценка максимального правдоподобия для <т2 не совпадает с
несмещенной оценкой дисперсии ошибок. Таким образом, с = ((п — 2)/n)<7OLS является смещенной, но тем не менее состоятельной оценкой <т2.
[c.57]
В этом разделе мы рассмотрим частный случай обобщенной регрессионной модели, а именно, модель с гетероскедастичностъю, Это означает, что ошибки некоррелированы, но имеют непостоянные дисперсии. (Классическая модель с постоянными дисперсиями ошибок называется гомоскедастичной.) Как уже отмечалось, Гетероскедастичность довольно часто возникает, если анализируемые объекты, говоря нестрого, неоднородны. Например, если исследуется зависимость прибыли предприятия от каких-либо факторов, скажем, от размера основного фонда, то естественно ожидать, что для больших предприятий колебание прибыли будет выше, чем для малых.
[c.168]