В языке T-SQL, как и во многих других языках программирования, есть возможность отслеживать и перехватывать ошибки, сегодня мы с Вами рассмотрим конструкцию TRY CATCH, с помощью которой мы как раз и можем обрабатывать исключительные ситуации, т.е. непредвиденные ошибки.
Как Вы уже поняли, речь здесь пойдет не о синтаксических ошибках, о которых нам сообщает SQL сервер еще до начала выполнения самих SQL инструкций, а об ошибках, которые могут возникнуть на том или ином участке кода при определенных условиях.
Самый простой пример — это деление на ноль, как Вы знаете, делить на ноль нельзя, но эта цифра все-таки может возникнуть в операциях деления. Также существуют и другие ошибки, которые могут возникнуть в операциях над нестандартными, некорректными данными, хотя те же самые операции с обычными данными выполняются без каких-либо ошибок.
Поэтому в языке Transact-SQL существует специальная конструкция TRY…CATCH, она появилась в 2005 версии SQL сервера, и которая используется для обработки ошибок. Если кто знаком с другими языками программирования, то Вам эта конструкция скорей всего знакома, так как она используется во многих языках программирования.
Заметка! Для профессионального изучения языка T-SQL рекомендую посмотреть мои видеокурсы по T-SQL.
Содержание
- Конструкция TRY CATCH в T-SQL
- Важные моменты про конструкцию TRY CATCH в T-SQL
- Функции для получения сведений об ошибках
- Пример использования конструкции TRY…CATCH для обработки ошибок
TRY CATCH – это конструкция языка Transact-SQL для обработки ошибок. Все, что Вы хотите проверять на ошибки, т.е. код в котором могут возникнуть ошибки, Вы помещаете в блок TRY. Начало данного блока обозначается инструкцией BEGIN TRY, а окончание блока, соответственно, END TRY.
Все, что Вы хотите выполнять в случае появления ошибки, т.е. те инструкции, которые должны выполниться, если в блоке TRY возникла ошибка, Вы помещаете в блок CATCH, его начало обозначается BEGIN CATCH, а окончание END CATCH. Если никаких ошибок в блоке TRY не возникло, то блок CATCH пропускается и выполняются инструкции, следующие за ним. Если ошибки возникли, то выполняются инструкции в блоке CATCH, а после выполняются инструкции, следующие за данным блоком, иными словами, все инструкции, следующие за блоком CATCH, будут выполнены, если, конечно же, мы принудительно не завершили выполнение пакета в блоке CATCH.

Сам блок CATCH не передает никаких сведений об обнаруженных ошибках в вызывающее приложение, если это нужно, например, узнать номер или описание ошибки, то для этого Вы можете использовать инструкции SELECT, RAISERROR или PRINT в блоке CATCH.
Важные моменты про конструкцию TRY CATCH в T-SQL
- Блок CATCH должен идти сразу же за блоком TRY, между этими блоками размещение инструкций не допускается;
- TRY CATCH перехватывает все ошибки с кодом серьезности, большим 10, которые не закрывают соединения с базой данных;
- В конструкции TRY…CATCH Вы можете использовать только один пакет и один блок SQL инструкций;
- Конструкция TRY…CATCH может быть вложенной, например, в блоке TRY может быть еще одна конструкция TRY…CATCH, или в блоке CATCH Вы можете написать обработчик ошибок, на случай возникновения ошибок в самом блоке CATCH;
- Оператор GOTO нельзя использовать для входа в блоки TRY или CATCH, он может быть использован только для перехода к меткам внутри блоков TRY или CATCH;
- Обработка ошибок TRY…CATCH в пользовательских функциях не поддерживается;
- Конструкция TRY…CATCH не обрабатывает следующие ошибки: предупреждения и информационные сообщения с уровнем серьезности 10 или ниже, разрыв соединения, вызванный клиентом, завершение сеанса администратором с помощью инструкции KILL.
Функции для получения сведений об ошибках
Для того чтобы получить информацию об ошибках, которые повлекли выполнение блока CATCH можно использовать следующие функции:
- ERROR_NUMBER() – возвращает номер ошибки;
- ERROR_MESSAGE() — возвращает описание ошибки;
- ERROR_STATE() — возвращает код состояния ошибки;
- ERROR_SEVERITY() — возвращает степень серьезности ошибки;
- ERROR_PROCEDURE() — возвращает имя хранимой процедуры или триггера, в котором произошла ошибка;
- ERROR_LINE() — возвращает номер строки инструкции, которая вызвала ошибку.
Если эти функции вызвать вне блока CATCH они вернут NULL.
Пример использования конструкции TRY…CATCH для обработки ошибок
Для демонстрации того, как работает конструкция TRY…CATCH, давайте напишем простую SQL инструкцию, в которой мы намеренно допустим ошибку, например, попытаемся выполнить операцию деление на ноль.
--Начало блока обработки ошибок
BEGIN TRY
--Инструкции, в которых могут возникнуть ошибки
DECLARE @TestVar1 INT = 10,
@TestVar2 INT = 0,
@Rez INT
SET @Rez = @TestVar1 / @TestVar2
END TRY
--Начало блока CATCH
BEGIN CATCH
--Действия, которые будут выполняться в случае возникновения ошибки
SELECT ERROR_NUMBER() AS [Номер ошибки],
ERROR_MESSAGE() AS [Описание ошибки]
SET @Rez = 0
END CATCH
SELECT @Rez AS [Результат]
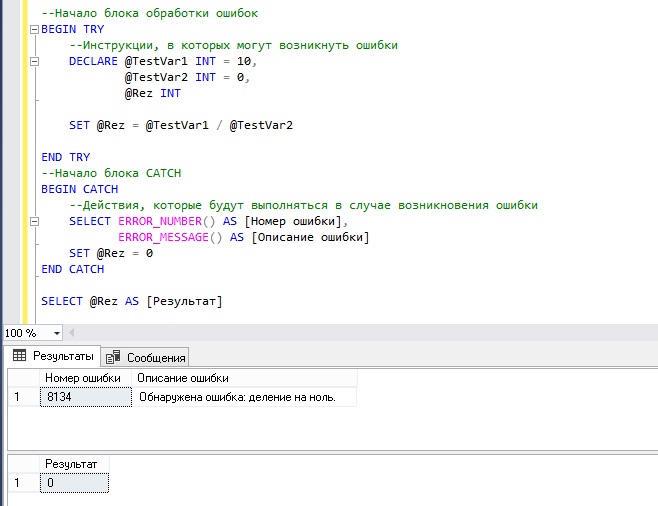
В данном случае мы выводим номер и описание ошибки с помощью функций ERROR_NUMBER() и ERROR_MESSAGE(), а также присваиваем переменной с итоговым результатом значение 0, как видим, инструкции после блока CATCH продолжают выполняться.
У меня на этом все, надеюсь, материал был Вам полезен, пока!
| title | description | author | ms.author | ms.reviewer | ms.date | ms.service | ms.subservice | ms.topic | ms.custom | f1_keywords | helpviewer_keywords | dev_langs | monikerRange | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
TRY…CATCH (Transact-SQL) |
TRY…CATCH (Transact-SQL) |
rwestMSFT |
randolphwest |
03/16/2017 |
sql |
t-sql |
reference |
|
|
TSQL |
>= aps-pdw-2016 || = azuresqldb-current || = azure-sqldw-latest || >= sql-server-2016 || >= sql-server-linux-2017 || = azuresqldb-mi-current |
[!INCLUDE sql-asdb-asdbmi-asa-pdw]
Implements error handling for [!INCLUDEtsql] that is similar to the exception handling in the [!INCLUDEmsCoName] Visual C# and [!INCLUDEmsCoName] Visual C++ languages. A group of [!INCLUDEtsql] statements can be enclosed in a TRY block. If an error occurs in the TRY block, control is usually passed to another group of statements that is enclosed in a CATCH block.
:::image type=»icon» source=»../../includes/media/topic-link-icon.svg» border=»false»::: Transact-SQL syntax conventions
Syntax
BEGIN TRY
{ sql_statement | statement_block }
END TRY
BEGIN CATCH
[ { sql_statement | statement_block } ]
END CATCH
[ ; ]
[!INCLUDEsql-server-tsql-previous-offline-documentation]
Arguments
sql_statement
Is any [!INCLUDEtsql] statement.
statement_block
Any group of [!INCLUDEtsql] statements in a batch or enclosed in a BEGIN…END block.
Remarks
A TRY…CATCH construct catches all execution errors that have a severity higher than 10 that do not close the database connection.
A TRY block must be immediately followed by an associated CATCH block. Including any other statements between the END TRY and BEGIN CATCH statements generates a syntax error.
A TRY…CATCH construct cannot span multiple batches. A TRY…CATCH construct cannot span multiple blocks of [!INCLUDEtsql] statements. For example, a TRY…CATCH construct cannot span two BEGIN…END blocks of [!INCLUDEtsql] statements and cannot span an IF…ELSE construct.
If there are no errors in the code that is enclosed in a TRY block, when the last statement in the TRY block has finished running, control passes to the statement immediately after the associated END CATCH statement.
If there is an error in the code that is enclosed in a TRY block, control passes to the first statement in the associated CATCH block. When the code in the CATCH block finishes, control passes to the statement immediately after the END CATCH statement.
[!NOTE]
If the END CATCH statement is the last statement in a stored procedure or trigger, control is passed back to the statement that called the stored procedure or fired the trigger.
Errors trapped by a CATCH block are not returned to the calling application. If any part of the error information must be returned to the application, the code in the CATCH block must do so by using mechanisms such as SELECT result sets or the RAISERROR and PRINT statements.
TRY…CATCH constructs can be nested. Either a TRY block or a CATCH block can contain nested TRY…CATCH constructs. For example, a CATCH block can contain an embedded TRY…CATCH construct to handle errors encountered by the CATCH code.
Errors encountered in a CATCH block are treated like errors generated anywhere else. If the CATCH block contains a nested TRY…CATCH construct, any error in the nested TRY block will pass control to the nested CATCH block. If there is no nested TRY…CATCH construct, the error is passed back to the caller.
TRY…CATCH constructs catch unhandled errors from stored procedures or triggers executed by the code in the TRY block. Alternatively, the stored procedures or triggers can contain their own TRY…CATCH constructs to handle errors generated by their code. For example, when a TRY block executes a stored procedure and an error occurs in the stored procedure, the error can be handled in the following ways:
-
If the stored procedure does not contain its own TRY…CATCH construct, the error returns control to the CATCH block associated with the TRY block that contains the EXECUTE statement.
-
If the stored procedure contains a TRY…CATCH construct, the error transfers control to the CATCH block in the stored procedure. When the CATCH block code finishes, control is passed back to the statement immediately after the EXECUTE statement that called the stored procedure.
GOTO statements cannot be used to enter a TRY or CATCH block. GOTO statements can be used to jump to a label inside the same TRY or CATCH block or to leave a TRY or CATCH block.
The TRY…CATCH construct cannot be used in a user-defined function.
Retrieving Error Information
In the scope of a CATCH block, the following system functions can be used to obtain information about the error that caused the CATCH block to be executed:
-
ERROR_NUMBER() returns the number of the error.
-
ERROR_SEVERITY() returns the severity.
-
ERROR_STATE() returns the error state number.
-
ERROR_PROCEDURE() returns the name of the stored procedure or trigger where the error occurred.
-
ERROR_LINE() returns the line number inside the routine that caused the error.
-
ERROR_MESSAGE() returns the complete text of the error message. The text includes the values supplied for any substitutable parameters, such as lengths, object names, or times.
These functions return NULL if they are called outside the scope of the CATCH block. Error information can be retrieved by using these functions from anywhere within the scope of the CATCH block. For example, the following script shows a stored procedure that contains error-handling functions. In the CATCH block of a TRY...CATCH construct, the stored procedure is called and information about the error is returned.
-- Verify that the stored procedure does not already exist. IF OBJECT_ID ( 'usp_GetErrorInfo', 'P' ) IS NOT NULL DROP PROCEDURE usp_GetErrorInfo; GO -- Create procedure to retrieve error information. CREATE PROCEDURE usp_GetErrorInfo AS SELECT ERROR_NUMBER() AS ErrorNumber ,ERROR_SEVERITY() AS ErrorSeverity ,ERROR_STATE() AS ErrorState ,ERROR_PROCEDURE() AS ErrorProcedure ,ERROR_LINE() AS ErrorLine ,ERROR_MESSAGE() AS ErrorMessage; GO BEGIN TRY -- Generate divide-by-zero error. SELECT 1/0; END TRY BEGIN CATCH -- Execute error retrieval routine. EXECUTE usp_GetErrorInfo; END CATCH;
The ERROR_* functions also work in a CATCH block inside a natively compiled stored procedure.
Errors Unaffected by a TRY…CATCH Construct
TRY…CATCH constructs do not trap the following conditions:
-
Warnings or informational messages that have a severity of 10 or lower.
-
Errors that have a severity of 20 or higher that stop the [!INCLUDEssDEnoversion] task processing for the session. If an error occurs that has severity of 20 or higher and the database connection is not disrupted, TRY…CATCH will handle the error.
-
Attentions, such as client-interrupt requests or broken client connections.
-
When the session is ended by a system administrator by using the KILL statement.
The following types of errors are not handled by a CATCH block when they occur at the same level of execution as the TRY…CATCH construct:
-
Compile errors, such as syntax errors, that prevent a batch from running.
-
Errors that occur during statement-level recompilation, such as object name resolution errors that occur after compilation because of deferred name resolution.
-
Object name resolution errors
These errors are returned to the level that ran the batch, stored procedure, or trigger.
If an error occurs during compilation or statement-level recompilation at a lower execution level (for example, when executing sp_executesql or a user-defined stored procedure) inside the TRY block, the error occurs at a lower level than the TRY…CATCH construct and will be handled by the associated CATCH block.
The following example shows how an object name resolution error generated by a SELECT statement is not caught by the TRY...CATCH construct, but is caught by the CATCH block when the same SELECT statement is executed inside a stored procedure.
BEGIN TRY -- Table does not exist; object name resolution -- error not caught. SELECT * FROM NonexistentTable; END TRY BEGIN CATCH SELECT ERROR_NUMBER() AS ErrorNumber ,ERROR_MESSAGE() AS ErrorMessage; END CATCH
The error is not caught and control passes out of the TRY...CATCH construct to the next higher level.
Running the SELECT statement inside a stored procedure will cause the error to occur at a level lower than the TRY block. The error will be handled by the TRY...CATCH construct.
-- Verify that the stored procedure does not exist. IF OBJECT_ID ( N'usp_ExampleProc', N'P' ) IS NOT NULL DROP PROCEDURE usp_ExampleProc; GO -- Create a stored procedure that will cause an -- object resolution error. CREATE PROCEDURE usp_ExampleProc AS SELECT * FROM NonexistentTable; GO BEGIN TRY EXECUTE usp_ExampleProc; END TRY BEGIN CATCH SELECT ERROR_NUMBER() AS ErrorNumber ,ERROR_MESSAGE() AS ErrorMessage; END CATCH;
Uncommittable Transactions and XACT_STATE
If an error generated in a TRY block causes the state of the current transaction to be invalidated, the transaction is classified as an uncommittable transaction. An error that ordinarily ends a transaction outside a TRY block causes a transaction to enter an uncommittable state when the error occurs inside a TRY block. An uncommittable transaction can only perform read operations or a ROLLBACK TRANSACTION. The transaction cannot execute any [!INCLUDEtsql] statements that would generate a write operation or a COMMIT TRANSACTION. The XACT_STATE function returns a value of -1 if a transaction has been classified as an uncommittable transaction. When a batch finishes, the [!INCLUDEssDE] rolls back any active uncommittable transactions. If no error message was sent when the transaction entered an uncommittable state, when the batch finishes, an error message will be sent to the client application. This indicates that an uncommittable transaction was detected and rolled back.
For more information about uncommittable transactions and the XACT_STATE function, see XACT_STATE (Transact-SQL).
Examples
A. Using TRY…CATCH
The following example shows a SELECT statement that will generate a divide-by-zero error. The error causes execution to jump to the associated CATCH block.
BEGIN TRY -- Generate a divide-by-zero error. SELECT 1/0; END TRY BEGIN CATCH SELECT ERROR_NUMBER() AS ErrorNumber ,ERROR_SEVERITY() AS ErrorSeverity ,ERROR_STATE() AS ErrorState ,ERROR_PROCEDURE() AS ErrorProcedure ,ERROR_LINE() AS ErrorLine ,ERROR_MESSAGE() AS ErrorMessage; END CATCH; GO
B. Using TRY…CATCH in a transaction
The following example shows how a TRY...CATCH block works inside a transaction. The statement inside the TRY block generates a constraint violation error.
BEGIN TRANSACTION; BEGIN TRY -- Generate a constraint violation error. DELETE FROM Production.Product WHERE ProductID = 980; END TRY BEGIN CATCH SELECT ERROR_NUMBER() AS ErrorNumber ,ERROR_SEVERITY() AS ErrorSeverity ,ERROR_STATE() AS ErrorState ,ERROR_PROCEDURE() AS ErrorProcedure ,ERROR_LINE() AS ErrorLine ,ERROR_MESSAGE() AS ErrorMessage; IF @@TRANCOUNT > 0 ROLLBACK TRANSACTION; END CATCH; IF @@TRANCOUNT > 0 COMMIT TRANSACTION; GO
C. Using TRY…CATCH with XACT_STATE
The following example shows how to use the TRY...CATCH construct to handle errors that occur inside a transaction. The XACT_STATE function determines whether the transaction should be committed or rolled back. In this example, SET XACT_ABORT is ON. This makes the transaction uncommittable when the constraint violation error occurs.
-- Check to see whether this stored procedure exists. IF OBJECT_ID (N'usp_GetErrorInfo', N'P') IS NOT NULL DROP PROCEDURE usp_GetErrorInfo; GO -- Create procedure to retrieve error information. CREATE PROCEDURE usp_GetErrorInfo AS SELECT ERROR_NUMBER() AS ErrorNumber ,ERROR_SEVERITY() AS ErrorSeverity ,ERROR_STATE() AS ErrorState ,ERROR_LINE () AS ErrorLine ,ERROR_PROCEDURE() AS ErrorProcedure ,ERROR_MESSAGE() AS ErrorMessage; GO -- SET XACT_ABORT ON will cause the transaction to be uncommittable -- when the constraint violation occurs. SET XACT_ABORT ON; BEGIN TRY BEGIN TRANSACTION; -- A FOREIGN KEY constraint exists on this table. This -- statement will generate a constraint violation error. DELETE FROM Production.Product WHERE ProductID = 980; -- If the DELETE statement succeeds, commit the transaction. COMMIT TRANSACTION; END TRY BEGIN CATCH -- Execute error retrieval routine. EXECUTE usp_GetErrorInfo; -- Test XACT_STATE: -- If 1, the transaction is committable. -- If -1, the transaction is uncommittable and should -- be rolled back. -- XACT_STATE = 0 means that there is no transaction and -- a commit or rollback operation would generate an error. -- Test whether the transaction is uncommittable. IF (XACT_STATE()) = -1 BEGIN PRINT N'The transaction is in an uncommittable state.' + 'Rolling back transaction.' ROLLBACK TRANSACTION; END; -- Test whether the transaction is committable. -- You may want to commit a transaction in a catch block if you want to commit changes to statements that ran prior to the error. IF (XACT_STATE()) = 1 BEGIN PRINT N'The transaction is committable.' + 'Committing transaction.' COMMIT TRANSACTION; END; END CATCH; GO
D. Using TRY…CATCH
The following example shows a SELECT statement that will generate a divide-by-zero error. The error causes execution to jump to the associated CATCH block.
BEGIN TRY -- Generate a divide-by-zero error. SELECT 1/0; END TRY BEGIN CATCH SELECT ERROR_NUMBER() AS ErrorNumber ,ERROR_SEVERITY() AS ErrorSeverity ,ERROR_STATE() AS ErrorState ,ERROR_PROCEDURE() AS ErrorProcedure ,ERROR_MESSAGE() AS ErrorMessage; END CATCH; GO
See Also
THROW (Transact-SQL)
Database Engine Error Severities
ERROR_LINE (Transact-SQL)
ERROR_MESSAGE (Transact-SQL)
ERROR_NUMBER (Transact-SQL)
ERROR_PROCEDURE (Transact-SQL)
ERROR_SEVERITY (Transact-SQL)
ERROR_STATE (Transact-SQL)
RAISERROR (Transact-SQL)
@@ERROR (Transact-SQL)
GOTO (Transact-SQL)
BEGIN…END (Transact-SQL)
XACT_STATE (Transact-SQL)
SET XACT_ABORT (Transact-SQL)
Обработка ошибок
Последнее обновление: 14.08.2017
Для обработки ошибок в T-SQL применяется конструкция TRY…CATCH. Она имеет следующий формальный синтаксис:
BEGIN TRY инструкции END TRY BEGIN CATCH инструкции END CATCH
Между выражениями BEGIN TRY и END TRY помещаются инструкции, которые потенциально могут вызвать ошибку, например,
какой-нибудь запрос. И если в этом блоке TRY возникнет ошибка, то управление передается в блок CATCH, где можно обработать ошибку.
В блоке CATCH для обаботки ошибки мы можем использовать ряд функций:
-
ERROR_NUMBER(): возвращает номер ошибки
-
ERROR_MESSAGE(): возвращает сообщение об ошибке
-
ERROR_SEVERITY(): возвращает степень серьезности ошибки. Степень серьезности представляет числовое значение. И если оно равно 10 и меньше, то
такая ошибка рассматривается как предупреждение и не обрабатывается конструкцией TRY…CATCH. Если же это значение равно 20 и выше, то
такая ошибка приводит к закрытию подключения к базе данных, если она не обрабатывается конструкцией TRY…CATCH. -
ERROR_STATE(): возвращает состояние ошибки
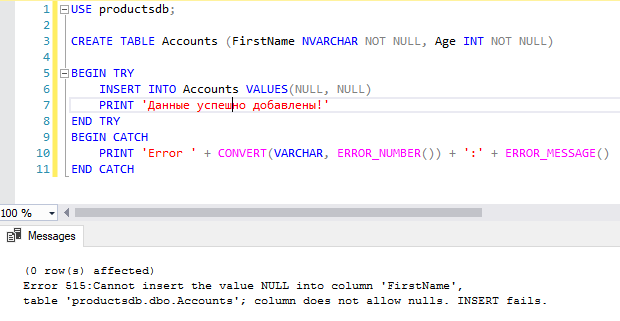
Например, добавим в таблицу данные, которые не соответствуют ограничениям столбцов:
CREATE TABLE Accounts (FirstName NVARCHAR NOT NULL, Age INT NOT NULL) BEGIN TRY INSERT INTO Accounts VALUES(NULL, NULL) PRINT 'Данные успешно добавлены!' END TRY BEGIN CATCH PRINT 'Error ' + CONVERT(VARCHAR, ERROR_NUMBER()) + ':' + ERROR_MESSAGE() END CATCH
В данном случае для столбцов таблицы вставляются недопустимые данные — значения NULL, поэтому обработка программы перейдет к блоку CATCH:
- Другие части статьи:
- 1
- 2
- 3
- вперед »
Конечно сейчас уже сложно найти хоть одного человека работающего с SQL сервером достаточно плотно и при этом не знающего (или хотя бы не слышавшего) «кодовую фразу»: «блок TRY/CATCH». Ведь с момента первого появления означенного блока как такового в синтаксисе языка T-SQL прошло, круглым счетом, лет семь — срок более чем достаточный, что бы о «новинке» узнал любой желающий изучить хоть что-то новое. При этом нельзя сказать, что в вопросе правильного перехвата ошибок для кода написанного на языке T-SQL поставлена последняя точка, отнюдь. Во-первых самому блоку как синтаксическому элементу есть куда расти, и вышедший на днях сервер 2012-й версии тому подтверждение. Во-вторых, даже реализация того же блока в серверах версий 2005-2008-R2 все еще остается непонятой до конца многими SQL-специалистами. Из опыта проведений курсов (как официальных, от Microsoft, так и курсов по программе заказчика), из общений на форумах, из встреч в обстановке формальной и не очень, автор данного блога, как ему кажется, обнаружил «корень» такого непонимания. Дело в том, что 95% литературы освещающих данную тему (BOL так же входит в число указанных процентов, и даже лучше сказать возглавляет их) впадают в одну и ту же… ошибку? Нет, это, пожалуй, слишком жесткая оценка. В один и тот же неверный «посыл» они впадают — вот так вернее будет. Так вот этот самый ошибочный посыл сводится к следующему: раз общая идея и концепция перехвата исключений (а наш блок именно этим и занимается) появилась в языках высокого уровня пару десятков лет тому назад, то тратить слова и печатное пространство на описание этой самой идеи/концепции резона нет — все и так все знают. Просто переходим к описанию сути происходящего внутри блока, и все дела.
Почему такой посыл кажется автору ошибочным? Потому что не все IT-профессионалы пишущие T-SQL код имели счастье (или несчастье, тут уж у каждого свой опыт и впечатления) попробовать реализовать свои алгоритмы на языках C++, C# и иже с ними. Разумеется, профессиональный программист на языке T-SQL знающий, до некоторой степени подробности или очень хорошо, тот же C# исключением не будет. Но и не станет исключением другой программист, пишущий всю жизнь на T-SQL, а C# знающий ну очень поверхностно, или не знающий его вовсе. Кроме того, для контекста нашей беседы, знание синтаксиса конкретного высокоуровневого языка не столь и значимо, гораздо важнее та самая «идея», а точнее ее полное понимание, а как раз с последним у большинства SQL-профессионалов — проблема.
В силу всего изложенного, автор решился взяться за эту уже порядком «заезженную» тему обработки ошибок, но построить подачу материала на несколько иной основе. «Что если», подумалось автору, «программист знает T-SQL и только его»? А тогда простая логика подсказывает, что объяснение блока TRY/CATCH нужно, для таких программистов, начинать с вещей куда как более фундаментальных, чем это делают иные источники информации. И уж потом, на этом фундаменте, излагать факты с которых традиционно принято начинать рассмотрение данного вопроса. Кроме того, с учетом того, что 100% материалов данного блога пишутся по методологии «основательно — масштабно — достоверно» автор не мог закончить данный труд простым перечислением тех самых фактов. Нами непременно будут так же рассмотрены:
- как происходит переключение потока исполнения между блоками TRY и CATCH;
- зачем, уже перехватив ошибку и обработав ее, мы можем захотеть вновь ее «поднять» или «бросить» (throw);
- как блок TRY/CATCH работает с ошибками разных уровней серьезности (severity);
- как обрабатываются ошибки периода исполнения и как — периода компиляции кода;
- как взаимодействуют вложенные блоки TRY/CATCH и как взаимодействуют блоки из разных программных модулей вызывающих друг друга;
- допустимо ли вкладывать новый блок TRY/CATCH в блок CATCH вышестоящего уровня;
- как блок TRY/CATCH влияет на работу транзакций и как они влияют на него;
- и, наконец, как же в общем, с позиций «большой IT-науки», правильно использовать этот инструмент — обработку и перехват ошибок.
Кроме того, в завершение материала вас ждет «контрольная работа» которая поможет вам провести самооценку усвоения излагаемых далее фактов и правил. Вопросов, как видите, немало (да еще и экзамен ![]() ), в пару страниц нам точно не уложиться, а поэтому — устраивайтесь поудобнее.
), в пару страниц нам точно не уложиться, а поэтому — устраивайтесь поудобнее. ![]() И, как для любого другого материала данного блога, позаботьтесь что бы ваша любимая Sql Server Management Studio была от вас не дальше чем на расстоянии вытянутой руки, она вам потребуется уже буквально через несколько экранов текста.
И, как для любого другого материала данного блога, позаботьтесь что бы ваша любимая Sql Server Management Studio была от вас не дальше чем на расстоянии вытянутой руки, она вам потребуется уже буквально через несколько экранов текста.
Строго говоря, термины «ошибка» и «исключения» синонимами
не
являются. Если бы статья описывала технологию их перехвата и обработки вообще, применительно к любому языку программирования, такое «смешение понятий» стало бы несомненным «провалом» автора статьи. Однако данный материал «затачивается» исключительно под язык T-SQL, а это язык со своей спецификой, причем спецификой изрядной. И вот в нем, с совсем небольшой натяжкой, можно считать что два указанных термина определяют одно и тоже, а именно: в ходе выполнения программы возникла ситуация хоть и возможная с точки зрения здравого смысла и общей логики, но такая, в которую ни мы, программисты, ни наши пользователи, попадать решительно не хотим. И нам определенно нужны особые действия в коде, раз уж такая нежелательная ситуация все же возникла. С учетом данного замечания далее в тексте статьи оба указанных термина применяются на принципах полного равенства между ними. Тоже самое относится к словосочетаниям с участием тех же терминов: «обработка ошибок», «перехват исключения» и т.п.
Обработка исключений, базовая идея.
Итак, начнем мы, как договорились, с самого фундамента, с идеи и концепции исключений их обработки. Если абстрагироваться от любого конкретного языка программирования (и даже от T-SQL), то выяснится, что:
- при реализации любого программного алгоритма уровня сложности выше чем элементарный, на любом языке программирования, мы никак не можем на 100% гарантировать что программа, даже написанная идеально, даже абсолютно точно не содержащая «багов» в своем коде, при выполнении отработает успешно и произведет планируемые расчеты/действия/модификацию данных/и т.д. Есть факторы не подвластные ни нам, ни нашему коду. Если временно «выключить» нашу абстракцию от конкретных языков программирования, и представить что мы на T-SQL написали простейший INSERT, то можем ли мы гарантировать успешность исполнения этой единственной команды, даже если мы при указании значений для этого простейшего INSERT-а учли все ключи существующие в целевой таблице, все ограничения в ней же, аккуратно проверили типы значений на соответствие типам целевых колонок и сделали еще 50 подобных телодвижений? Не можем мы этого гарантировать! Почему? Да хотя бы потому, что INSERT безусловно требует известного числа байт (килобайт?) свободного пространства в журнале транзакций, а при его (свободного места) отсутствии и если у нас к тому же отключено автоприращение LDF-файла, мы будем иметь гарантированную ошибку 9002. А однозначно утверждать, что это самое место в журнале будет всегда, сейчас и в будущем, невозможно;
- если программист знает что он написал реально качественный код, что «багов» в нем точно нет, то он очень надеется, что в большинстве случаев выполнение программы будет все же успешным. Ровно как и мы с нашим INSERT-ом надеемся что в 99.99% случаев он просто, тихо и мирно вставит строку в таблицу и передаст управление следующему за ним оператору;
- тем не менее, пункт последний не отменяет пункт предпоследний, 99.99% <> 100%. И это еще без учета того фактора, что в более-менее сложном коде гарантия отсутствия «багов» будет заявлением, ну… несколько самоуверенным, назовем это так. Запросто можно не учесть все то разнообразие значений и их типов, что получает на вход наша хранимая процедура и из которых и формируется код все того же INSERT-а. И это только первый пункт из того длинного списка чего еще «можно не учесть»;
- итого, любой код во время своего исполнения подвержен риску «нарваться» на проблему, будь то проблема от автора кода вообще никак не зависящая (та же ошибка 9002), а равно и проблема им же самим порожденная, вроде попытки вставить дублирующее значение в колонку первичного ключа;
- проблемы предыдущего пункта принято называть термином более техническим — ошибки (errors), или даже термином еще более техническим — исключения (exceptions). Название термина как бы предполагает, что при возникновении такой ошибке на системе сданной в промышленную эксплуатацию программист разводит руками и как бы говорит нам: «ну, я надеялся, что раз оно две недели отработало, то и дальше все OK будет, а оно вон как… Исключение из правила, понимаешь!»;
Ну а если исключительных (сбойных, ошибочных, нестандартных… синонимов у этого определения много) ситуаций избежать нельзя, можно ли с этими ситуациями сделать хоть что-то толковое? Можно! Их можно обработать. Такая обработка говорит нашему коду: «брось тратить время на основной алгоритм — его уже не завершить корректно. Переключись на другой (под-)алгоритм в котором попробуй, во-первых, выяснить суть случившейся проблемы (т.е. была ли это ошибка 9002, или это все же был дубликат ключа, или еще что-то третье), а, во-вторых, попробуй изящно выйти из сложившейся ситуации». «Изящество» выхода из сложившейся ситуации полностью определяется снова программистом, который должен предвидеть и предвосхищать возможные проблемы с INSERT-ом и еще с миллионом вещей ему подобным. И вот тогда программист может:
- вывести очень любезное сообщение клиенту вместо по-спартански лаконичного «transaction log full» от сервера;
- вывести тоже самое любезное сообщение и дополнительно зафиксировать технические детали проблемы в некотором локальном (для сервера) txt-файле для дальнейшего анализа ситуации;
- или нечто совсем отдельное, например можно принудительно добавить свободного места в LDF-файл и повторить операцию вставки. Правда вот тут нам не обойтись без «многоэтажных», вложенных TRY/CATCH, которые вполне реальны и разговор о которых у нас впереди.
И так далее, и тому подобное — вас ограничивает только ваша фантазия. А самая главная прелесть обработки исключений в том, что она совершенно четко делит код на два ясно выраженных блока. Например, если переключится уже на конкретную реализацию обсуждаемого механизма в SQL Server версии 2005-й (и более поздних, разумеется), то такими «четко различимыми» блоками будут:
- блок TRY — блок основного алгоритма. Тут мы пишем наш INSERT и тут мы надеемся что все будет хорошо. Иными словами тут находится бизнес-логика нашего решения;
- блок CATCH — блок под-алгоритма. Тут мы реализуем те самые фантазии на тему «изящного» выхода из ситуации и уже ни на что хорошее не надеемся. Раз мы тут очутились — наши надежны точно не оправдались.
Такой подход к структуре программы гораздо яснее и четче того единственно возможного варианта, что был доступен до версии сервера 2000-го включительно: после каждого оператора имеющего потенциал ошибочного завершения оценивать этот самый оператор на результат его исполнения и если результат именно ошибочный — писать код «выхода из ситуации». Т.е. в целом T-SQL код был явно «спагетный», поскольку функция сообщающая нам была ли ошибка или нет (а таковой функцией являлась @@ERROR) требовала своего вызова сразу же (и только сразу!) после любого «опасного» оператора. И эти самые операторы (а они и есть бизнес-логика, основной алгоритм) щедро перемежались вставками вызова @@ERROR и набором инструкций по теме «если что пошло не так» (а это явно алгоритм вспомогательный):
|
1 |
DECLARE @ErrorNum INT INSERT … |
А вот тоже самое в стилистике TRY/CATCH:
|
1 |
BEGIN TRY |
Полагаю никто не будет спорить — второе приятнее даже для глаза, не говоря уж про чтение чужих кодов с целью их поддержания и развития. Все очень четко: пока мы в блоке TRY — мы вообще ни о чем не беспокоимся, а просто реализуем только основную бизнес-логику нашего решения и надеемся на лучшее. Ну а в блоке CATCH мы реализуем только выход из ситуации, полностью игнорируя главный алгоритм — ведь он к этому моменту (имеется в виду к моменту «сваливания» в этот блок в исполняющейся программе) уже прекратил свою работу.
Передача управления исполнения между блоками. Понятие обработанного исключения.
Итак, формально говоря, программа на любом языке (но и на T-SQL в том числе) использующая обработку исключений будет, или, как минимум, может, в ходе своего исполнения проходить через такие стадии и ветвления:
- вход в блок TRY и исполнение всех операторов данного блока последовательно, в порядке определенным программистом;
- если все операторы блока исполнены (т.е. достигнута метка END TRY) и никаких ошибок и проблем зафиксировано не было — блок CATCH полностью игнорируется (нам не нужен под-алгоритм выхода из «кризисных» ситуаций) и очередным оператором отправляющимся на исполнение будет первый оператор после метки END CATCH;
- если же очередной оператор блока TRY вызывает ту самую ошибку которую мы условились называть исключением, то:
- исполнение блока TRY заканчивается этим самым проблемным оператором (мы не можем продолжать основной алгоритм, у нас проблемы);
- очередным оператором отправляющимся на исполнение будет первый оператор после метки BEGIN CATCH;
- затем исполняются все операторы этого блока (CATCH) в порядке определенным программистом, вплоть до метки END CATCH;
- после чего возврат в блок TRY не происходит. Вообще идея обработки исключений как таковая предполагает два возможных продолжения в этой точке: подход «обработка с возвратом» вернет нас нас обратно, в блок TRY, в точку сбоя, откуда и продолжится исполнение главного алгоритма. Однако подавляющее большинство современных языков (и T-SQL в том числе) пропагандируют подход встречный, «обработка без возврата», который как раз предписывает остаток основного алгоритма игнорировать, а продолжить исполнение оператором следующим за обработчиком. Так что у нас после достижения метки END CATCH очередным оператором отправляющимся на исполнение будет оператор непосредственно за ней следующий в тексте T-SQL скрипта.
Обычно понимание описанной методики выбора пути исполнения программы проблем не вызывает, алгоритм ясен и четок, всегда можно предсказать что будет дальше. А вот тонким моментом, ускользающим от понимания SQL-программистов, является тот факт, что ошибка «прогнанная» через блок CATCH, по сути, перестает быть ошибкой! То есть, у нас была проблема в блоке TRY и нас перекинули в CATCH. Мы что-то сделали в последнем блоке, и теперь у нас все в порядке, можно продолжать далее. Да, у нас отработал не весь основной алгоритм, а лишь его часть, но программист, применяя блок CATCH, фактически заявляет «я знаю как из этого выпутаться без того, что бы заставлять клиента повторить всю операцию с самого начала». А если программист такого обходного пути не знает? Или знает как выпутаться если нет места в LDF-файле, но не знает как, если INSERT пытается задублировать значение ключа? Ну тогда он может:
- вообще не применять блоки TRY/CATCH. И позволить клиенту получить стандартное серверное сообщение об ошибке, причем о любой ошибке. И, как следствие, заставить клиента повторить операцию. Этот подход даже еще хуже, чем тот что был в сервере 2000-м и тот который интенсивно использовал функцию @@ERROR — тот хоть какую-то обработку ошибок предполагал…
- применить блоки TRY/CATCH и во втором из них извлечь информацию о данной конкретной ошибке, проанализировать ее, и если ошибка окажется «класса» «я знаю как» — реализовать это «как» в коде. А если ошибка окажется «класса» противоположного — повторно ее генерировать, тем самым честно сообщая о своей неготовности к полной ее обработке. Теоретические основы и правильный дизайн кода для этого варианта более подробно обсуждается в заключительной части статьи.
Сразу определимся, что проблему извлечения информации в блоке CATCH, т.е. пути узнавания что же конкретно привело к переходу из блока TRY в блок CATCH, мы в нашей статье рассматривать не будем. Во-первых, это одна из самых простых задач и совершенно прямолинейная — нужно просто в блоке CATCH «дернуть» соответствующую системную функцию. Во-вторых, статья в BOL Получение сведений об ошибках в языке Transact-SQL описывает общее назначение этих функций, а в конце ее есть набор ссылок на персональную страницу каждой из упомянутых функций. Мы, в наших практических экспериментах, из всего этого богатого набора будем использовать единственную функцию ERROR_MESSAGE, возвращающую текст сообщения об ошибке. Однако совершенно все функции из указанного набора должны быть в арсенале SQL-разработчика готовыми к применению. Тем более функций не так и много (всего шесть), а их вызов и интерпретация результатов ими возвращаемых просто элементарны. Не будем мы говорить и о вопросе «я знаю как из этого выпутаться» — этот момент не поддается обобщению, каждый отдельный код уникален и знать (либо не знать) обходной маневр может и должен только программист его создающий. Но зато мы подробно, и даже весьма, поговорим о третьем компоненте решения — повторной генерации («броске», throw) ошибки с целью информирования клиента что на этот раз случилось нечто серьезное и мы бессильны. Только разговор этот будет не прямо сейчас, а в следующем разделе — продолжайте чтение статьи.
Так вот, самое важное для нас на текущий момент, что если ошибка была проведена через блок CATCH и не была в нем повторно сгенерирована (или, выражаясь более технически, не была «брошена» (throw) повторно), то такая ошибка считается обработанной. Клиент спокойно продолжает свою работу с оператора следующим за меткой END CATCH. Повторю, что для изрядного числа специалистов создающих модули на языке T-SQL, такое «исчезновение» ошибки становится большой неожиданностью, однако все обстоит именно так: блок CATCH «подавляет» ошибку, не дает ей «прорваться» к клиенту. Ну и обратное тоже верно: если блок CATCH не использовать (а это автоматически означает отказ и от блока TRY), или использовать, но произвести в нем повторный бросок ошибки — клиент получит соответствующее уведомление. Мы, кстати, не обязаны сообщать последнему ошибку истинную, или сообщать все ее подробности. Вполне возможно использовать «подмену», когда в блоке CATCH мы видим, что истинной ошибкой приведшей к прерыванию работы является исключение A, но повторно генерируем не его, а исключение B. Мотивы для такой подмены могут быть самыми разными, начиная от желания предоставить клиенту больше информации, чем та что стандартно предоставляется сервером в исключении A, и заканчивая желанием ровно противоположным — скрыть подробности случившегося, например для затруднения потенциального взлома нашего решения. Технически, любое (правда тут, как обычно в SQL Server, тоже есть свои тонкости, разберем их далее; пока остановимся на термине «любое» как наиболее близком к истинному положению вещей) исключение «вброс» которого произведен в границах блока CATCH отменяет обсуждавшееся только что «подавление» и ведет к невозможности продолжения работы с точки зрения клиента.
Повторная генерации исключения (throw) и инструкция RAISERROR.
Итак, как неопровержимо доказал нам предшествующий раздел, нам совершенно необходимо уметь не только ошибки обрабатывать, но и, как ни парадоксально это прозвучит, создавать их. Первая причина такой парадоксальности уже была приведена — отмена нежелательного подавления случившегося исключения. Вторая причина может и не столь насущна, но не менее востребована — изучение и тесты блоков TRY/CATCH. Дело в том, что полностью понять работу разбираемого нами блока можно лишь одним путем — брать его и пробовать писать T-SQL код с его участием. То есть писать короткие скрипты, запускать их и анализировать результат. Собственно, это, наверно, вообще единственно действующая метода изучения любого синтаксического элемента любого языка программирования. И вот при написании таких тестовых скриптов оператор гарантирующий возникновение ошибки нам совершенно необходим — иначе как нам «свалиться» в блок CATCH? Разумеется, банальный SELECT 1/0 поможет нам в нашей «беде», но:
- иногда нам, что бы исключить все вопросы о ходе исполнения тестового скрипта, требуется ошибка сопровождающаяся нашим собственным текстовым сообщением, а не стандартизированным сообщением от сервера;
- что гораздо важнее, ошибки в SQL Server бывают множества уровней серьезности (severity level) и значение этого уровня категорически влияет на то, как именно такая ошибка будет обработана блоками TRY/CATCH. «Подгонять» же под каждый из возможных уровней оператор «реальный», вроде показанного чуть выше SELECT-а, занятие не очень практичное, нам нужен способ более удобный и универсальный.
И такое универсальное решение — есть! Инструкция RAISERROR дает нам требуемое и позволяет сделать изучение обработки ошибок в языке T-SQL делом значительно более простым и приятным.
SQL Server версии 2012 предлагает альтернативу для достижения той же цели — инструкцию THROW. Более того, прямо рекомендуется пользоваться последним, а не RAISERROR. С учетом того, что в большинстве высокоуровневых языков ошибки кидаются одноименным ключевым словом причины такой рекомендации совершенно понятны — T-SQL перенимает все больше и больше элементов и конструкций этих самых языков. Однако у THROW есть существенный недостаток перед RAISERROR: первый не умеет определять серьезность бросаемой ошибки, каковая будет равна 16 без всяких вариантов. Вообще-то, при написании реального, промышленного кода указанный недостаток не столь и существенен, уровень 16 вполне достаточен что бы ошибка с таким уровнем выполнила свое главное назначение — будучи вброшенной в блоке CATCH достичь клиента. Однако для целей учебно-демонстрационных различные уровни серьезности совершенно необходимы, дабы полностью разобраться в механике функционирования описываемых блоков. А поэтому автор будет все свои ошибки «кидать» с помощью RAISERROR, уж тем более, что тогда показываемые им скрипты можно будет запускать на сервере любой версии начиная с 2005-й.
В отличии от предполагаемого, синтаксис инструкции RAISERROR оказывается неожиданно весьма «развесист», хотя самых главных ее аргументов всего три:
- msg_str — текст сопровождающий ошибку;
- severity — тот самый уровень серьезности, о конкретных значениях которого речь впереди;
- state — состояние, целое число от 0 до 255. Если мы в нескольких точках своего кода «бросаем» совершенно идентичные ошибки, у которых совпадает и msg_str, и severity, то этот параметр позволит отделить одну такую точку кода от другой. Это, конечно, если таковое разделение нам вообще требуется. А необходимость в этом случается не часто. Например, во всех скриптах данной статьи автор указывает данному параметру значение 1.
Указанные аргументы просто перечисляются через запятую. Допустим, вот как можно в блоке CATCH реализовать сценарий самый прямолинейный: вернуть клиенту совершенно ту же ошибку, которая привела к передаче управления в этот блок, ничего не приукрашивая и не подменяя:
|
1 |
… |
По крайней мере такой подход рекомендован BOL. И в принципе показанный код вполне рабочий, только автор заменил бы переменную @ErrorState константой, той же единицей, к примеру. Случаев когда значение данного параметра имеет хоть какой-то смысл очень немного, так что константа почти никогда ничего не испортит. Если же вы уверены, что вам нужно именно состояние, то уж, по крайней мере, проверяйте значение того же параметра на то, что оно не меньше нуля и не больше 255-ти, перед тем как вызвать RAISERROR. А иначе клиент получит сообщение не об ошибке приведшей код в блок CATCH, а сообщение о неверных параметрах самой инструкции RAISERROR. Программисты-перфекционисты могут еще и значение параметра @ErrorSeverity проверять на вхождение в диапазон 0…25, но это замечание гораздо менее актуальное чем предыдущее. Дело в том, что если значение @ErrorSeverity будет меньше нуля, движок «засчитает» его за 0. А если больше 25-ти — то за 25. И клиент все-равно получит сообщение о нужной ошибке, а не сообщение об ошибочности синтаксиса. Но вот с @ErrorState я б подстраховался.
Итак, с помощью только что описанной инструкции мы готовы на практических примерах рассмотреть некоторые из тонких моментов механизма перехвата и обработки ошибок реализованного в SQL Server.
- Другие части статьи:
- 1
- 2
- 3
- вперед »
Summary: in this tutorial, you will learn how to use the SQL Server TRY CATCH construct to handle exceptions in stored procedures.
SQL Server TRY CATCH overview
The TRY CATCH construct allows you to gracefully handle exceptions in SQL Server. To use the TRY CATCH construct, you first place a group of Transact-SQL statements that could cause an exception in a BEGIN TRY...END TRY block as follows:
Code language: SQL (Structured Query Language) (sql)
BEGIN TRY -- statements that may cause exceptions END TRY
Then you use a BEGIN CATCH...END CATCH block immediately after the TRY block:
Code language: SQL (Structured Query Language) (sql)
BEGIN CATCH -- statements that handle exception END CATCH
The following illustrates a complete TRY CATCH construct:
Code language: SQL (Structured Query Language) (sql)
BEGIN TRY -- statements that may cause exceptions END TRY BEGIN CATCH -- statements that handle exception END CATCH
If the statements between the TRY block complete without an error, the statements between the CATCH block will not execute. However, if any statement inside the TRY block causes an exception, the control transfers to the statements in the CATCH block.
The CATCH block functions
Inside the CATCH block, you can use the following functions to get the detailed information on the error that occurred:
ERROR_LINE()returns the line number on which the exception occurred.ERROR_MESSAGE()returns the complete text of the generated error message.ERROR_PROCEDURE()returns the name of the stored procedure or trigger where the error occurred.ERROR_NUMBER()returns the number of the error that occurred.ERROR_SEVERITY()returns the severity level of the error that occurred.ERROR_STATE()returns the state number of the error that occurred.
Note that you only use these functions in the CATCH block. If you use them outside of the CATCH block, all of these functions will return NULL.
Nested TRY CATCH constructs
You can nest TRY CATCH construct inside another TRY CATCH construct. However, either a TRY block or a CATCH block can contain a nested TRY CATCH, for example:
Code language: SQL (Structured Query Language) (sql)
BEGIN TRY --- statements that may cause exceptions END TRY BEGIN CATCH -- statements to handle exception BEGIN TRY --- nested TRY block END TRY BEGIN CATCH --- nested CATCH block END CATCH END CATCH
SQL Server TRY CATCH examples
First, create a stored procedure named usp_divide that divides two numbers:
Code language: SQL (Structured Query Language) (sql)
CREATE PROC usp_divide( @a decimal, @b decimal, @c decimal output ) AS BEGIN BEGIN TRY SET @c = @a / @b; END TRY BEGIN CATCH SELECT ERROR_NUMBER() AS ErrorNumber ,ERROR_SEVERITY() AS ErrorSeverity ,ERROR_STATE() AS ErrorState ,ERROR_PROCEDURE() AS ErrorProcedure ,ERROR_LINE() AS ErrorLine ,ERROR_MESSAGE() AS ErrorMessage; END CATCH END; GO
In this stored procedure, we placed the formula inside the TRY block and called the CATCH block functions ERROR_* inside the CATCH block.
Second, call the usp_divide stored procedure to divide 10 by 2:
Code language: SQL (Structured Query Language) (sql)
DECLARE @r decimal; EXEC usp_divide 10, 2, @r output; PRINT @r;
Here is the output
Code language: SQL (Structured Query Language) (sql)
5
Because no exception occurred in the TRY block, the stored procedure completed at the TRY block.
Third, attempt to divide 20 by zero by calling the usp_divide stored procedure:
Code language: SQL (Structured Query Language) (sql)
DECLARE @r2 decimal; EXEC usp_divide 10, 0, @r2 output; PRINT @r2;
The following picture shows the output:
![]()
Because of division by zero error which was caused by the formula, the control was passed to the statement inside the CATCH block which returned the error’s detailed information.
SQL Serer TRY CATCH with transactions
Inside a CATCH block, you can test the state of transactions by using the XACT_STATE() function.
- If the
XACT_STATE()function returns -1, it means that an uncommittable transaction is pending, you should issue aROLLBACK TRANSACTIONstatement. - In case the
XACT_STATE()function returns 1, it means that a committable transaction is pending. You can issue aCOMMIT TRANSACTIONstatement in this case. - If the
XACT_STATE()function return 0, it means no transaction is pending, therefore, you don’t need to take any action.
It is a good practice to test your transaction state before issuing a COMMIT TRANSACTION or ROLLBACK TRANSACTION statement in a CATCH block to ensure consistency.
Using TRY CATCH with transactions example
First, set up two new tables sales.persons and sales.deals for demonstration:
Code language: SQL (Structured Query Language) (sql)
CREATE TABLE sales.persons ( person_id INT PRIMARY KEY IDENTITY, first_name NVARCHAR(100) NOT NULL, last_name NVARCHAR(100) NOT NULL ); CREATE TABLE sales.deals ( deal_id INT PRIMARY KEY IDENTITY, person_id INT NOT NULL, deal_note NVARCHAR(100), FOREIGN KEY(person_id) REFERENCES sales.persons( person_id) ); insert into sales.persons(first_name, last_name) values ('John','Doe'), ('Jane','Doe'); insert into sales.deals(person_id, deal_note) values (1,'Deal for John Doe');
Next, create a new stored procedure named usp_report_error that will be used in a CATCH block to report the detailed information of an error:
Code language: SQL (Structured Query Language) (sql)
CREATE PROC usp_report_error AS SELECT ERROR_NUMBER() AS ErrorNumber ,ERROR_SEVERITY() AS ErrorSeverity ,ERROR_STATE() AS ErrorState ,ERROR_LINE () AS ErrorLine ,ERROR_PROCEDURE() AS ErrorProcedure ,ERROR_MESSAGE() AS ErrorMessage; GO
Then, develop a new stored procedure that deletes a row from the sales.persons table:
Code language: SQL (Structured Query Language) (sql)
CREATE PROC usp_delete_person( @person_id INT ) AS BEGIN BEGIN TRY BEGIN TRANSACTION; -- delete the person DELETE FROM sales.persons WHERE person_id = @person_id; -- if DELETE succeeds, commit the transaction COMMIT TRANSACTION; END TRY BEGIN CATCH -- report exception EXEC usp_report_error; -- Test if the transaction is uncommittable. IF (XACT_STATE()) = -1 BEGIN PRINT N'The transaction is in an uncommittable state.' + 'Rolling back transaction.' ROLLBACK TRANSACTION; END; -- Test if the transaction is committable. IF (XACT_STATE()) = 1 BEGIN PRINT N'The transaction is committable.' + 'Committing transaction.' COMMIT TRANSACTION; END; END CATCH END; GO
In this stored procedure, we used the XACT_STATE() function to check the state of the transaction before performing COMMIT TRANSACTION or ROLLBACK TRANSACTION inside the CATCH block.
After that, call the usp_delete_person stored procedure to delete the person id 2:
Code language: SQL (Structured Query Language) (sql)
EXEC usp_delete_person 2;
There was no exception occurred.
Finally, call the stored procedure usp_delete_person to delete person id 1:
Code language: SQL (Structured Query Language) (sql)
EXEC usp_delete_person 1;
The following error occurred:
![]()
In this tutorial, you have learned how to use the SQL Server TRY CATCH construct to handle exceptions in stored procedures.
На чтение 3 мин. Просмотров 83 Опубликовано 12.08.2019
Содержание
- Выявить ошибки, не прерывая выполнение
- Представляем TRY … CATCH
- Пример TRY … CATCH
- Учиться больше
Выявить ошибки, не прерывая выполнение
Оператор TRY… CATCH в Transact-SQL обнаруживает и обрабатывает ошибки в приложениях базы данных. Это утверждение является краеугольным камнем обработки ошибок SQL Server и является важной частью разработки надежных приложений баз данных. TRY … CATCH применяется к SQL Server, начиная с 2008 года, базе данных SQL Azure, хранилищу данных SQL Azure и хранилищу параллельных данных.
Представляем TRY … CATCH
TRY … CATCH позволяет указать две инструкции Transact-SQL: одну, которую вы хотите “попробовать”, а другую, чтобы “перехватить” любые ошибки, которые могут возникнуть. Когда SQL Server встречает оператор TRY … CATCH, он немедленно выполняет оператор, включенный в предложение TRY. Если инструкция TRY выполняется успешно, SQL Server продолжает работу. Однако если инструкция TRY генерирует ошибку, SQL Server выполняет инструкцию CATCH, чтобы корректно обработать ошибку.
Основной синтаксис принимает эту форму:
НАЧАТЬ ИСПЫТАТЬ
sql_statement
END TRY
НАЧАЛО ЗАПИСИ
[ Statement_block]
END CATCH
[; ]
Пример TRY … CATCH
Легко понять использование этого утверждения на примере. Представьте, что вы являетесь администратором базы данных персонала, которая содержит таблицу с именем «Сотрудники», в которой содержится информация о каждом из сотрудников вашей организации. В этой таблице в качестве первичного ключа используется целочисленный идентификационный номер сотрудника. Вы можете попытаться использовать приведенное ниже утверждение, чтобы вставить нового сотрудника в вашу базу данных:
INSERT INTO сотрудников (идентификатор, имя, фамилия, расширение)
VALUES (12497, «Майк», «Chapple», 4201)
В обычных условиях этот оператор добавляет строку в таблицу «Сотрудники». Однако, если сотрудник с идентификатором 12497 уже существует в базе данных, вставка строки нарушит ограничение первичного ключа и приведет к следующей ошибке:
Сообщение 2627, уровень 14, состояние 1, строка 1
Нарушение ограничения PRIMARY KEY 'PK_employee_id'. Невозможно вставить повторяющийся ключ в объект "dbo.employees".
Оператор завершен.
Хотя эта ошибка предоставляет вам информацию, необходимую для устранения проблемы, с ней связаны две проблемы. Во-первых, сообщение загадочное. Он включает коды ошибок, номера строк и другую информацию, которая непонятна среднему пользователю. Во-вторых, и что более важно, это приводит к прерыванию оператора и может вызвать сбой приложения.
Альтернативой является завершение оператора в оператор TRY… CATCH, как показано здесь:
НАЧАТЬ ИСПЫТАТЬ
ВСТАВИТЬ В сотрудников (идентификатор, имя, фамилия, добавочный номер)
ЦЕННОСТИ (12497, «Майк», «Чаппель», 4201)
НАКОНЕЦ НАЧАТЬ
НАЧАТЬ CATCH
ПЕЧАТЬ 'ОШИБКА:' + ERROR_MESSAGE ();
EXEC msdb.dbo.sp_send_dbmail
@profile_name = 'Почта сотрудника',
@recipients ='hr@foo.com ',
@body =' Произошла ошибка при создании новой записи сотрудника. ',
@subject =' Ошибка дублирования идентификатора сотрудника ';
END CATCH
В этом примере обо всех возникающих ошибках сообщается как пользователю, выполняющему команду, так и адресу электронной почты hr@foo.com. Ошибка, отображаемая пользователю:
Ошибка: нарушение ограничения PRIMARY KEY 'PK_employee_id'.
Невозможно вставить дубликат ключа в объект «dbo.employees».
Почта в очереди.
Выполнение приложения продолжается в обычном режиме, что позволяет программисту обработать ошибку. Использование оператора TRY … CATCH – это элегантный способ упреждающего обнаружения и обработки ошибок, возникающих в приложениях базы данных SQL Server.
Учиться больше
Если вы хотите узнать больше о языке структурированных запросов, ознакомьтесь с разделом Введение в SQL.