Обработка ошибок, «try..catch»
Неважно, насколько мы хороши в программировании, иногда наши скрипты содержат ошибки. Они могут возникать из-за наших промахов, неожиданного ввода пользователя, неправильного ответа сервера и по тысяче других причин.
Обычно скрипт в случае ошибки «падает» (сразу же останавливается), с выводом ошибки в консоль.
Но есть синтаксическая конструкция try..catch, которая позволяет «ловить» ошибки и вместо падения делать что-то более осмысленное.
Синтаксис «try..catch»
Конструкция try..catch состоит из двух основных блоков: try, и затем catch:
try { // код... } catch (err) { // обработка ошибки }
Работает она так:
- Сначала выполняется код внутри блока
try {...}. - Если в нём нет ошибок, то блок
catch(err)игнорируется: выполнение доходит до концаtryи потом далее, полностью пропускаяcatch. - Если же в нём возникает ошибка, то выполнение
tryпрерывается, и поток управления переходит в началоcatch(err). Переменнаяerr(можно использовать любое имя) содержит объект ошибки с подробной информацией о произошедшем.

Таким образом, при ошибке в блоке try {…} скрипт не «падает», и мы получаем возможность обработать ошибку внутри catch.
Давайте рассмотрим примеры.
-
Пример без ошибок: выведет
alert(1)и(2):try { alert('Начало блока try'); // *!*(1) <--*/!* // ...код без ошибок alert('Конец блока try'); // *!*(2) <--*/!* } catch(err) { alert('Catch игнорируется, так как нет ошибок'); // (3) }
-
Пример с ошибками: выведет
(1)и(3):try { alert('Начало блока try'); // *!*(1) <--*/!* *!* lalala; // ошибка, переменная не определена! */!* alert('Конец блока try (никогда не выполнится)'); // (2) } catch(err) { alert(`Возникла ошибка!`); // *!*(3) <--*/!* }
««warn header=»try..catch работает только для ошибок, возникающих во время выполнения кода»
Чтобы `try..catch` работал, код должен быть выполнимым. Другими словами, это должен быть корректный JavaScript-код.
Он не сработает, если код синтаксически неверен, например, содержит несовпадающее количество фигурных скобок:
try { {{{{{{{{{{{{ } catch(e) { alert("Движок не может понять этот код, он некорректен"); }
JavaScript-движок сначала читает код, а затем исполняет его. Ошибки, которые возникают во время фазы чтения, называются ошибками парсинга. Их нельзя обработать (изнутри этого кода), потому что движок не понимает код.
Таким образом, try..catch может обрабатывать только ошибки, которые возникают в корректном коде. Такие ошибки называют «ошибками во время выполнения», а иногда «исключениями».
````warn header="`try..catch` работает синхронно"
Исключение, которое произойдёт в коде, запланированном "на будущее", например в `setTimeout`, `try..catch` не поймает:
```js run
try {
setTimeout(function() {
noSuchVariable; // скрипт упадёт тут
}, 1000);
} catch (e) {
alert( "не сработает" );
}
```
Это потому, что функция выполняется позже, когда движок уже покинул конструкцию `try..catch`.
Чтобы поймать исключение внутри запланированной функции, `try..catch` должен находиться внутри самой этой функции:
```js run
setTimeout(function() {
try {
noSuchVariable; // try..catch обрабатывает ошибку!
} catch {
alert( "ошибка поймана!" );
}
}, 1000);
```
Объект ошибки
Когда возникает ошибка, JavaScript генерирует объект, содержащий её детали. Затем этот объект передаётся как аргумент в блок catch:
try { // ... } catch(err) { // <-- объект ошибки, можно использовать другое название вместо err // ... }
Для всех встроенных ошибок этот объект имеет два основных свойства:
name
: Имя ошибки. Например, для неопределённой переменной это "ReferenceError".
message
: Текстовое сообщение о деталях ошибки.
В большинстве окружений доступны и другие, нестандартные свойства. Одно из самых широко используемых и поддерживаемых — это:
stack
: Текущий стек вызова: строка, содержащая информацию о последовательности вложенных вызовов, которые привели к ошибке. Используется в целях отладки.
Например:
try { *!* lalala; // ошибка, переменная не определена! */!* } catch(err) { alert(err.name); // ReferenceError alert(err.message); // lalala is not defined alert(err.stack); // ReferenceError: lalala is not defined at (...стек вызовов) // Можем также просто вывести ошибку целиком // Ошибка приводится к строке вида "name: message" alert(err); // ReferenceError: lalala is not defined }
Блок «catch» без переменной
[recent browser=new]
Если нам не нужны детали ошибки, в catch можно её пропустить:
try { // ... } catch { // <-- без (err) // ... }
Использование «try..catch»
Давайте рассмотрим реальные случаи использования try..catch.
Как мы уже знаем, JavaScript поддерживает метод JSON.parse(str) для чтения JSON.
Обычно он используется для декодирования данных, полученных по сети, от сервера или из другого источника.
Мы получаем их и вызываем JSON.parse вот так:
let json = '{"name":"John", "age": 30}'; // данные с сервера *!* let user = JSON.parse(json); // преобразовали текстовое представление в JS-объект */!* // теперь user - объект со свойствами из строки alert( user.name ); // John alert( user.age ); // 30
Вы можете найти более детальную информацию о JSON в главе info:json.
Если json некорректен, JSON.parse генерирует ошибку, то есть скрипт «падает».
Устроит ли нас такое поведение? Конечно нет!
Получается, что если вдруг что-то не так с данными, то посетитель никогда (если, конечно, не откроет консоль) об этом не узнает. А люди очень не любят, когда что-то «просто падает» без всякого сообщения об ошибке.
Давайте используем try..catch для обработки ошибки:
let json = "{ некорректный JSON }"; try { *!* let user = JSON.parse(json); // <-- тут возникает ошибка... */!* alert( user.name ); // не сработает } catch (e) { *!* // ...выполнение прыгает сюда alert( "Извините, в данных ошибка, мы попробуем получить их ещё раз." ); alert( e.name ); alert( e.message ); */!* }
Здесь мы используем блок catch только для вывода сообщения, но мы также можем сделать гораздо больше: отправить новый сетевой запрос, предложить посетителю альтернативный способ, отослать информацию об ошибке на сервер для логирования, … Всё лучше, чем просто «падение».
Генерация собственных ошибок
Что если json синтаксически корректен, но не содержит необходимого свойства name?
Например, так:
let json = '{ "age": 30 }'; // данные неполны try { let user = JSON.parse(json); // <-- выполнится без ошибок *!* alert( user.name ); // нет свойства name! */!* } catch (e) { alert( "не выполнится" ); }
Здесь JSON.parse выполнится без ошибок, но на самом деле отсутствие свойства name для нас ошибка.
Для того, чтобы унифицировать обработку ошибок, мы воспользуемся оператором throw.
Оператор «throw»
Оператор throw генерирует ошибку.
Синтаксис:
Технически в качестве объекта ошибки можно передать что угодно. Это может быть даже примитив, число или строка, но всё же лучше, чтобы это был объект, желательно со свойствами name и message (для совместимости со встроенными ошибками).
В JavaScript есть множество встроенных конструкторов для стандартных ошибок: Error, SyntaxError, ReferenceError, TypeError и другие. Можно использовать и их для создания объектов ошибки.
Их синтаксис:
let error = new Error(message); // или let error = new SyntaxError(message); let error = new ReferenceError(message); // ...
Для встроенных ошибок (не для любых объектов, только для ошибок), свойство name — это в точности имя конструктора. А свойство message берётся из аргумента.
Например:
let error = new Error(" Ого, ошибка! o_O"); alert(error.name); // Error alert(error.message); // Ого, ошибка! o_O
Давайте посмотрим, какую ошибку генерирует JSON.parse:
try { JSON.parse("{ bad json o_O }"); } catch(e) { *!* alert(e.name); // SyntaxError */!* alert(e.message); // Unexpected token b in JSON at position 2 }
Как мы видим, это SyntaxError.
В нашем случае отсутствие свойства name — это ошибка, ведь пользователи должны иметь имена.
Сгенерируем её:
let json = '{ "age": 30 }'; // данные неполны try { let user = JSON.parse(json); // <-- выполнится без ошибок if (!user.name) { *!* throw new SyntaxError("Данные неполны: нет имени"); // (*) */!* } alert( user.name ); } catch(e) { alert( "JSON Error: " + e.message ); // JSON Error: Данные неполны: нет имени }
В строке (*) оператор throw генерирует ошибку SyntaxError с сообщением message. Точно такого же вида, как генерирует сам JavaScript. Выполнение блока try немедленно останавливается, и поток управления прыгает в catch.
Теперь блок catch становится единственным местом для обработки всех ошибок: и для JSON.parse и для других случаев.
Проброс исключения
В примере выше мы использовали try..catch для обработки некорректных данных. А что, если в блоке try {...} возникнет другая неожиданная ошибка? Например, программная (неопределённая переменная) или какая-то ещё, а не ошибка, связанная с некорректными данными.
Пример:
let json = '{ "age": 30 }'; // данные неполны try { user = JSON.parse(json); // <-- забыл добавить "let" перед user // ... } catch(err) { alert("JSON Error: " + err); // JSON Error: ReferenceError: user is not defined // (не JSON ошибка на самом деле) }
Конечно, возможно все! Программисты совершают ошибки. Даже в утилитах с открытым исходным кодом, используемых миллионами людей на протяжении десятилетий — вдруг может быть обнаружена ошибка, которая приводит к ужасным взломам.
В нашем случае try..catch предназначен для выявления ошибок, связанных с некорректными данными. Но по своей природе catch получает все свои ошибки из try. Здесь он получает неожиданную ошибку, но всё также показывает то же самое сообщение "JSON Error". Это неправильно и затрудняет отладку кода.
К счастью, мы можем выяснить, какую ошибку мы получили, например, по её свойству name:
try { user = { /*...*/ }; } catch(e) { *!* alert(e.name); // "ReferenceError" из-за неопределённой переменной */!* }
Есть простое правило:
Блок catch должен обрабатывать только те ошибки, которые ему известны, и «пробрасывать» все остальные.
Техника «проброс исключения» выглядит так:
- Блок
catchполучает все ошибки. - В блоке
catch(err) {...}мы анализируем объект ошибкиerr. - Если мы не знаем как её обработать, тогда делаем
throw err.
В коде ниже мы используем проброс исключения, catch обрабатывает только SyntaxError:
let json = '{ "age": 30 }'; // данные неполны try { let user = JSON.parse(json); if (!user.name) { throw new SyntaxError("Данные неполны: нет имени"); } *!* blabla(); // неожиданная ошибка */!* alert( user.name ); } catch(e) { *!* if (e.name == "SyntaxError") { alert( "JSON Error: " + e.message ); } else { throw e; // проброс (*) } */!* }
Ошибка в строке (*) из блока catch «выпадает наружу» и может быть поймана другой внешней конструкцией try..catch (если есть), или «убьёт» скрипт.
Таким образом, блок catch фактически обрабатывает только те ошибки, с которыми он знает, как справляться, и пропускает остальные.
Пример ниже демонстрирует, как такие ошибки могут быть пойманы с помощью ещё одного уровня try..catch:
function readData() { let json = '{ "age": 30 }'; try { // ... *!* blabla(); // ошибка! */!* } catch (e) { // ... if (e.name != 'SyntaxError') { *!* throw e; // проброс исключения (не знаю как это обработать) */!* } } } try { readData(); } catch (e) { *!* alert( "Внешний catch поймал: " + e ); // поймал! */!* }
Здесь readData знает только, как обработать SyntaxError, тогда как внешний блок try..catch знает, как обработать всё.
try..catch..finally
Подождите, это ещё не всё.
Конструкция try..catch может содержать ещё одну секцию: finally.
Если секция есть, то она выполняется в любом случае:
- после
try, если не было ошибок, - после
catch, если ошибки были.
Расширенный синтаксис выглядит следующим образом:
*!*try*/!* { ... пробуем выполнить код... } *!*catch*/!*(e) { ... обрабатываем ошибки ... } *!*finally*/!* { ... выполняем всегда ... }
Попробуйте запустить такой код:
try { alert( 'try' ); if (confirm('Сгенерировать ошибку?')) BAD_CODE(); } catch (e) { alert( 'catch' ); } finally { alert( 'finally' ); }
У кода есть два пути выполнения:
- Если вы ответите на вопрос «Сгенерировать ошибку?» утвердительно, то
try -> catch -> finally. - Если ответите отрицательно, то
try -> finally.
Секцию finally часто используют, когда мы начали что-то делать и хотим завершить это вне зависимости от того, будет ошибка или нет.
Например, мы хотим измерить время, которое занимает функция чисел Фибоначчи fib(n). Естественно, мы можем начать измерения до того, как функция начнёт выполняться и закончить после. Но что делать, если при вызове функции возникла ошибка? В частности, реализация fib(n) в коде ниже возвращает ошибку для отрицательных и для нецелых чисел.
Секция finally отлично подходит для завершения измерений несмотря ни на что.
Здесь finally гарантирует, что время будет измерено корректно в обеих ситуациях — и в случае успешного завершения fib и в случае ошибки:
let num = +prompt("Введите положительное целое число?", 35) let diff, result; function fib(n) { if (n < 0 || Math.trunc(n) != n) { throw new Error("Должно быть целое неотрицательное число"); } return n <= 1 ? n : fib(n - 1) + fib(n - 2); } let start = Date.now(); try { result = fib(num); } catch (e) { result = 0; *!* } finally { diff = Date.now() - start; } */!* alert(result || "возникла ошибка"); alert( `Выполнение заняло ${diff}ms` );
Вы можете это проверить, запустив этот код и введя 35 в prompt — код завершится нормально, finally выполнится после try. А затем введите -1 — незамедлительно произойдёт ошибка, выполнение займёт 0ms. Оба измерения выполняются корректно.
Другими словами, неважно как завершилась функция: через return или throw. Секция finally срабатывает в обоих случаях.
«`smart header=»Переменные внутри try..catch..finally локальны»
Обратите внимание, что переменные `result` и `diff` в коде выше объявлены до `try..catch`.
Если переменную объявить в блоке, например, в try, то она не будет доступна после него.
````smart header="`finally` и `return`"
Блок `finally` срабатывает при *любом* выходе из `try..catch`, в том числе и `return`.
В примере ниже из `try` происходит `return`, но `finally` получает управление до того, как контроль возвращается во внешний код.
```js run
function func() {
try {
*!*
return 1;
*/!*
} catch (e) {
/* ... */
} finally {
*!*
alert( 'finally' );
*/!*
}
}
alert( func() ); // сначала срабатывает alert из finally, а затем этот код
````smart header="`try..finally`"
Конструкция `try..finally` без секции `catch` также полезна. Мы применяем её, когда не хотим здесь обрабатывать ошибки (пусть выпадут), но хотим быть уверены, что начатые процессы завершились.
```js
function func() {
// начать делать что-то, что требует завершения (например, измерения)
try {
// ...
} finally {
// завершить это, даже если все упадёт
}
}
```
В приведённом выше коде ошибка всегда выпадает наружу, потому что тут нет блока `catch`. Но `finally` отрабатывает до того, как поток управления выйдет из функции.
Глобальный catch
Информация из данной секции не является частью языка JavaScript.
Давайте представим, что произошла фатальная ошибка (программная или что-то ещё ужасное) снаружи try..catch, и скрипт упал.
Существует ли способ отреагировать на такие ситуации? Мы можем захотеть залогировать ошибку, показать что-то пользователю (обычно они не видят сообщение об ошибке) и т.д.
Такого способа нет в спецификации, но обычно окружения предоставляют его, потому что это весьма полезно. Например, в Node.js для этого есть process.on("uncaughtException"). А в браузере мы можем присвоить функцию специальному свойству window.onerror, которая будет вызвана в случае необработанной ошибки.
Синтаксис:
window.onerror = function(message, url, line, col, error) { // ... };
message
: Сообщение об ошибке.
url
: URL скрипта, в котором произошла ошибка.
line, col
: Номера строки и столбца, в которых произошла ошибка.
error
: Объект ошибки.
Пример:
<script> *!* window.onerror = function(message, url, line, col, error) { alert(`${message}n В ${line}:${col} на ${url}`); }; */!* function readData() { badFunc(); // Ой, что-то пошло не так! } readData(); </script>
Роль глобального обработчика window.onerror обычно заключается не в восстановлении выполнения скрипта — это скорее всего невозможно в случае программной ошибки, а в отправке сообщения об ошибке разработчикам.
Существуют также веб-сервисы, которые предоставляют логирование ошибок для таких случаев, такие как https://errorception.com или http://www.muscula.com.
Они работают так:
- Мы регистрируемся в сервисе и получаем небольшой JS-скрипт (или URL скрипта) от них для вставки на страницы.
- Этот JS-скрипт ставит свою функцию
window.onerror. - Когда возникает ошибка, она выполняется и отправляет сетевой запрос с информацией о ней в сервис.
- Мы можем войти в веб-интерфейс сервиса и увидеть ошибки.
Итого
Конструкция try..catch позволяет обрабатывать ошибки во время исполнения кода. Она позволяет запустить код и перехватить ошибки, которые могут в нём возникнуть.
Синтаксис:
try { // исполняем код } catch(err) { // если случилась ошибка, прыгаем сюда // err - это объект ошибки } finally { // выполняется всегда после try/catch }
Секций catch или finally может не быть, то есть более короткие конструкции try..catch и try..finally также корректны.
Объекты ошибок содержат следующие свойства:
message— понятное человеку сообщение.name— строка с именем ошибки (имя конструктора ошибки).stack(нестандартное, но хорошо поддерживается) — стек на момент ошибки.
Если объект ошибки не нужен, мы можем пропустить его, используя catch { вместо catch(err) {.
Мы можем также генерировать собственные ошибки, используя оператор throw. Аргументом throw может быть что угодно, но обычно это объект ошибки, наследуемый от встроенного класса Error. Подробнее о расширении ошибок см. в следующей главе.
Проброс исключения — это очень важный приём обработки ошибок: блок catch обычно ожидает и знает, как обработать определённый тип ошибок, поэтому он должен пробрасывать дальше ошибки, о которых он не знает.
Даже если у нас нет try..catch, большинство сред позволяют настроить «глобальный» обработчик ошибок, чтобы ловить ошибки, которые «выпадают наружу». В браузере это window.onerror.
Ошибки — это хорошо. Автор материала, перевод которого мы сегодня публикуем, говорит, что уверен в том, что эта идея известна всем. На первый взгляд ошибки кажутся чем-то страшным. Им могут сопутствовать какие-то потери. Ошибка, сделанная на публике, вредит авторитету того, кто её совершил. Но, совершая ошибки, мы на них учимся, а значит, попадая в следующий раз в ситуацию, в которой раньше вели себя неправильно, делаем всё как нужно.

Выше мы говорили об ошибках, которые люди совершают в обычной жизни. Ошибки в программировании — это нечто иное. Сообщения об ошибках помогают нам улучшать код, они позволяют сообщать пользователям наших проектов о том, что что-то пошло не так, и, возможно, рассказывают пользователям о том, как нужно вести себя для того, чтобы ошибок больше не возникало.
Этот материал, посвящённый обработке ошибок в JavaScript, разбит на три части. Сначала мы сделаем общий обзор системы обработки ошибок в JavaScript и поговорим об объектах ошибок. После этого мы поищем ответ на вопрос о том, что делать с ошибками, возникающими в серверном коде (в частности, при использовании связки Node.js + Express.js). Далее — обсудим обработку ошибок в React.js. Фреймворки, которые будут здесь рассматриваться, выбраны по причине их огромной популярности. Однако рассматриваемые здесь принципы работы с ошибками универсальны, поэтому вы, даже если не пользуетесь Express и React, без труда сможете применить то, что узнали, к тем инструментам, с которыми работаете.
Код демонстрационного проекта, используемого в данном материале, можно найти в этом репозитории.
1. Ошибки в JavaScript и универсальные способы работы с ними
Если в вашем коде что-то пошло не так, вы можете воспользоваться следующей конструкцией.
throw new Error('something went wrong')В ходе выполнения этой команды будет создан экземпляр объекта Error и будет сгенерировано (или, как говорят, «выброшено») исключение с этим объектом. Инструкция throw может генерировать исключения, содержащие произвольные выражения. При этом выполнение скрипта остановится в том случае, если не были предприняты меры по обработке ошибки.
Начинающие JS-программисты обычно не используют инструкцию throw. Они, как правило, сталкиваются с исключениями, выдаваемыми либо средой выполнения языка, либо сторонними библиотеками. Когда это происходит — в консоль попадает нечто вроде ReferenceError: fs is not defined и выполнение программы останавливается.
▍Объект Error
У экземпляров объекта Error есть несколько свойств, которыми мы можем пользоваться. Первое интересующее нас свойство — message. Именно сюда попадает та строка, которую можно передать конструктору ошибки в качестве аргумента. Например, ниже показано создание экземпляра объекта Error и вывод в консоль переданной конструктором строки через обращение к его свойству message.
const myError = new Error('please improve your code')
console.log(myError.message) // please improve your code
Второе свойство объекта, очень важное, представляет собой трассировку стека ошибки. Это — свойство stack. Обратившись к нему можно просмотреть стек вызовов (историю ошибки), который показывает последовательность операций, приведшую к неправильной работе программы. В частности, это позволяет понять — в каком именно файле содержится сбойный код, и увидеть, какая последовательность вызовов функций привела к ошибке. Вот пример того, что можно увидеть, обратившись к свойству stack.
Error: please improve your code
at Object.<anonymous> (/Users/gisderdube/Documents/_projects/hacking.nosync/error-handling/src/general.js:1:79)
at Module._compile (internal/modules/cjs/loader.js:689:30)
at Object.Module._extensions..js (internal/modules/cjs/loader.js:700:10)
at Module.load (internal/modules/cjs/loader.js:599:32)
at tryModuleLoad (internal/modules/cjs/loader.js:538:12)
at Function.Module._load (internal/modules/cjs/loader.js:530:3)
at Function.Module.runMain (internal/modules/cjs/loader.js:742:12)
at startup (internal/bootstrap/node.js:266:19)
at bootstrapNodeJSCore (internal/bootstrap/node.js:596:3)Здесь, в верхней части, находится сообщение об ошибке, затем следует указание на тот участок кода, выполнение которого вызвало ошибку, потом описывается то место, откуда был вызван этот сбойный участок. Это продолжается до самого «дальнего» по отношению к ошибке фрагмента кода.
▍Генерирование и обработка ошибок
Создание экземпляра объекта Error, то есть, выполнение команды вида new Error(), ни к каким особым последствиям не приводит. Интересные вещи начинают происходить после применения оператора throw, который генерирует ошибку. Как уже было сказано, если такую ошибку не обработать, выполнение скрипта остановится. При этом нет никакой разницы — был ли оператор throw использован самим программистом, произошла ли ошибка в некоей библиотеке или в среде выполнения языка (в браузере или в Node.js). Поговорим о различных сценариях обработки ошибок.
▍Конструкция try…catch
Блок try...catch представляет собой самый простой способ обработки ошибок, о котором часто забывают. В наши дни, правда, он используется гораздо интенсивнее чем раньше, благодаря тому, что его можно применять для обработки ошибок в конструкциях async/await.
Этот блок можно использовать для обработки любых ошибок, происходящих в синхронном коде. Рассмотрим пример.
const a = 5
try {
console.log(b) // переменная b не объявлена - возникает ошибка
} catch (err) {
console.error(err) // в консоль попадает сообщение об ошибке и стек ошибки
}
console.log(a) // выполнение скрипта не останавливается, данная команда выполняется
Если бы в этом примере мы не заключили бы сбойную команду console.log(b) в блок try...catch, то выполнение скрипта было бы остановлено.
▍Блок finally
Иногда случается так, что некий код нужно выполнить независимо от того, произошла ошибка или нет. Для этого можно, в конструкции try...catch, использовать третий, необязательный, блок — finally. Часто его использование эквивалентно некоему коду, который идёт сразу после try...catch, но в некоторых ситуациях он может пригодиться. Вот пример его использования.
const a = 5
try {
console.log(b) // переменная b не объявлена - возникает ошибка
} catch (err) {
console.error(err) // в консоль попадает сообщение об ошибке и стек ошибки
} finally {
console.log(a) // этот код будет выполнен в любом случае
}▍Асинхронные механизмы — коллбэки
Программируя на JavaScript всегда стоит обращать внимание на участки кода, выполняющиеся асинхронно. Если у вас имеется асинхронная функция и в ней возникает ошибка, скрипт продолжит выполняться. Когда асинхронные механизмы в JS реализуются с использованием коллбэков (кстати, делать так не рекомендуется), соответствующий коллбэк (функция обратного вызова) обычно получает два параметра. Это нечто вроде параметра err, который может содержать ошибку, и result — с результатами выполнения асинхронной операции. Выглядит это примерно так:
myAsyncFunc(someInput, (err, result) => {
if(err) return console.error(err) // порядок работы с объектом ошибки мы рассмотрим позже
console.log(result)
})
Если в коллбэк попадает ошибка, она видна там в виде параметра err. В противном случае в этот параметр попадёт значение undefined или null. Если оказалось, что в err что-то есть, важно отреагировать на это, либо так как в нашем примере, воспользовавшись командой return, либо воспользовавшись конструкцией if...else и поместив в блок else команды для работы с результатом выполнения асинхронной операции. Речь идёт о том, чтобы, в том случае, если произошла ошибка, исключить возможность работы с результатом, параметром result, который в таком случае может иметь значение undefined. Работа с таким значением, если предполагается, например, что оно содержит объект, сама может вызвать ошибку. Скажем, это произойдёт при попытке использовать конструкцию result.data или подобную ей.
▍Асинхронные механизмы — промисы
Для выполнения асинхронных операций в JavaScript лучше использовать не коллбэки а промисы. Тут, в дополнение к улучшенной читабельности кода, имеются и более совершенные механизмы обработки ошибок. А именно, возиться с объектом ошибки, который может попасть в функцию обратного вызова, при использовании промисов не нужно. Здесь для этой цели предусмотрен специальный блок catch. Он перехватывает все ошибки, произошедшие в промисах, которые находятся до него, или все ошибки, которые произошли в коде после предыдущего блока catch. Обратите внимание на то, что если в промисе произошла ошибка, для обработки которой нет блока catch, это не остановит выполнение скрипта, но сообщение об ошибке будет не особенно удобочитаемым.
(node:7741) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1): Error: something went wrong
(node:7741) DeprecationWarning: Unhandled promise rejections are deprecated. In the future, promise rejections that are not handled will terminate the Node.js process with a non-zero exit code. */
В результате можно порекомендовать всегда, при работе с промисами, использовать блок catch. Взглянем на пример.
Promise.resolve(1)
.then(res => {
console.log(res) // 1
throw new Error('something went wrong')
return Promise.resolve(2)
})
.then(res => {
console.log(res) // этот блок выполнен не будет
})
.catch(err => {
console.error(err) // о том, что делать с этой ошибкой, поговорим позже
return Promise.resolve(3)
})
.then(res => {
console.log(res) // 3
})
.catch(err => {
// этот блок тут на тот случай, если в предыдущем блоке возникнет какая-нибудь ошибка
console.error(err)
})▍Асинхронные механизмы и try…catch
После того, как в JavaScript появилась конструкция async/await, мы вернулись к классическому способу обработки ошибок — к try...catch...finally. Обрабатывать ошибки при таком подходе оказывается очень легко и удобно. Рассмотрим пример.
;(async function() {
try {
await someFuncThatThrowsAnError()
} catch (err) {
console.error(err) // об этом поговорим позже
}
console.log('Easy!') // будет выполнено
})()
При таком подходе ошибки в асинхронном коде обрабатываются так же, как в синхронном. В результате теперь, при необходимости, в одном блоке catch можно обрабатывать более широкий диапазон ошибок.
2. Генерирование и обработка ошибок в серверном коде
Теперь, когда у нас есть инструменты для работы с ошибками, посмотрим на то, что мы можем с ними делать в реальных ситуациях. Генерирование и правильная обработка ошибок — это важнейший аспект серверного программирования. Существуют разные подходы к работе с ошибками. Здесь будет продемонстрирован подход с использованием собственного конструктора для экземпляров объекта Error и кодов ошибок, которые удобно передавать во фронтенд или любым механизмам, использующим серверные API. Как структурирован бэкенд конкретного проекта — особого значения не имеет, так как при любом подходе можно использовать одни и те же идеи, касающиеся работы с ошибками.
В качестве серверного фреймворка, отвечающего за маршрутизацию, мы будем использовать Express.js. Подумаем о том, какая структура нам нужна для организации эффективной системы обработки ошибок. Итак, вот что нам нужно:
- Универсальная обработка ошибок — некий базовый механизм, подходящий для обработки любых ошибок, в ходе работы которого просто выдаётся сообщение наподобие
Something went wrong, please try again or contact us, предлагающее пользователю попробовать выполнить операцию, давшую сбой, ещё раз или связаться с владельцем сервера. Эта система не отличается особой интеллектуальностью, но она, по крайней мере, способна сообщить пользователю о том, что что-то пошло не так. Подобное сообщение гораздо лучше, чем «бесконечная загрузка» или нечто подобное. - Обработка конкретных ошибок — механизм, позволяющий сообщить пользователю подробные сведения о причинах неправильного поведения системы и дать ему конкретные советы по борьбе с неполадкой. Например, это может касаться отсутствия неких важных данных в запросе, который пользователь отправляет на сервер, или в том, что в базе данных уже существует некая запись, которую он пытается добавить ещё раз, и так далее.
▍Разработка собственного конструктора объектов ошибок
Здесь мы воспользуемся стандартным классом Error и расширим его. Пользоваться механизмами наследования в JavaScript — дело рискованное, но в данном случае эти механизмы оказываются весьма полезными. Зачем нам наследование? Дело в том, что нам, для того, чтобы код удобно было бы отлаживать, нужны сведения о трассировке стека ошибки. Расширяя стандартный класс Error, мы, без дополнительных усилий, получаем возможности по трассировке стека. Мы добавляем в наш собственный объект ошибки два свойства. Первое — это свойство code, доступ к которому можно будет получить с помощью конструкции вида err.code. Второе — свойство status. В него будет записываться код состояния HTTP, который планируется передавать клиентской части приложения.
Вот как выглядит класс CustomError, код которого оформлен в виде модуля.
class CustomError extends Error {
constructor(code = 'GENERIC', status = 500, ...params) {
super(...params)
if (Error.captureStackTrace) {
Error.captureStackTrace(this, CustomError)
}
this.code = code
this.status = status
}
}
module.exports = CustomError▍Маршрутизация
Теперь, когда наш объект ошибки готов к использованию, нужно настроить структуру маршрутов. Как было сказано выше, нам требуется реализовать унифицированный подход к обработке ошибок, позволяющий одинаково обрабатывать ошибки для всех маршрутов. По умолчанию фреймворк Express.js не вполне поддерживает такую схему работы. Дело в том, что все его маршруты инкапсулированы.
Для того чтобы справиться с этой проблемой, мы можем реализовать собственный обработчик маршрутов и определять логику маршрутов в виде обычных функций. Благодаря такому подходу, если функция маршрута (или любая другая функция) выбрасывает ошибку, она попадёт в обработчик маршрутов, который затем может передать её клиентской части приложения. При возникновении ошибки на сервере мы планируем передавать её во фронтенд в следующем формате, полагая, что для этого будет применяться JSON-API:
{
error: 'SOME_ERROR_CODE',
description: 'Something bad happened. Please try again or contact support.'
}Если на данном этапе происходящие кажется вам непонятным — не беспокойтесь — просто продолжайте читать, пробуйте работать с тем, о чём идёт речь, и постепенно вы во всём разберётесь. На самом деле, если говорить о компьютерном обучении, здесь применяется подход «сверху-вниз», когда сначала обсуждаются общие идеи, а потом осуществляется переход к частностям.
Вот как выглядит код обработчика маршрутов.
const express = require('express')
const router = express.Router()
const CustomError = require('../CustomError')
router.use(async (req, res) => {
try {
const route = require(`.${req.path}`)[req.method]
try {
const result = route(req) // Передаём запрос функции route
res.send(result) // Передаём клиенту то, что получено от функции route
} catch (err) {
/*
Сюда мы попадаем в том случае, если в функции route произойдёт ошибка
*/
if (err instanceof CustomError) {
/*
Если ошибка уже обработана - трансформируем её в
возвращаемый объект
*/
return res.status(err.status).send({
error: err.code,
description: err.message,
})
} else {
console.error(err) // Для отладочных целей
// Общая ошибка - вернём универсальный объект ошибки
return res.status(500).send({
error: 'GENERIC',
description: 'Something went wrong. Please try again or contact support.',
})
}
}
} catch (err) {
/*
Сюда мы попадём, если запрос окажется неудачным, то есть,
либо не будет найдено файла, соответствующего пути, переданному
в запросе, либо не будет экспортированной функции с заданным
методом запроса
*/
res.status(404).send({
error: 'NOT_FOUND',
description: 'The resource you tried to access does not exist.',
})
}
})
module.exports = routerПолагаем, комментарии в коде достаточно хорошо его поясняют. Надеемся, читать их удобнее, чем объяснения подобного кода, данные после него.
Теперь взглянем на файл маршрутов.
const CustomError = require('../CustomError')
const GET = req => {
// пример успешного выполнения запроса
return { name: 'Rio de Janeiro' }
}
const POST = req => {
// пример ошибки общего характера
throw new Error('Some unexpected error, may also be thrown by a library or the runtime.')
}
const DELETE = req => {
// пример ошибки, обрабатываемой особым образом
throw new CustomError('CITY_NOT_FOUND', 404, 'The city you are trying to delete could not be found.')
}
const PATCH = req => {
// пример перехвата ошибок и использования CustomError
try {
// тут случилось что-то нехорошее
throw new Error('Some internal error')
} catch (err) {
console.error(err) // принимаем решение о том, что нам тут делать
throw new CustomError(
'CITY_NOT_EDITABLE',
400,
'The city you are trying to edit is not editable.'
)
}
}
module.exports = {
GET,
POST,
DELETE,
PATCH,
}
В этих примерах с самими запросами ничего не делается. Тут просто рассматриваются разные сценарии возникновения ошибок. Итак, например, запрос GET /city попадёт в функцию const GET = req =>..., запрос POST /city попадёт в функцию const POST = req =>... и так далее. Эта схема работает и при использовании параметров запросов. Например — для запроса вида GET /city?startsWith=R. В целом, здесь продемонстрировано, что при обработке ошибок, во фронтенд может попасть либо общая ошибка, содержащая лишь предложение попробовать снова или связаться с владельцем сервера, либо ошибка, сформированная с использованием конструктора CustomError, которая содержит подробные сведения о проблеме.
Данные общей ошибки придут в клиентскую часть приложения в таком виде:
{
error: 'GENERIC',
description: 'Something went wrong. Please try again or contact support.'
}
Конструктор CustomError используется так:
throw new CustomError('MY_CODE', 400, 'Error description')Это даёт следующий JSON-код, передаваемый во фронтенд:
{
error: 'MY_CODE',
description: 'Error description'
}Теперь, когда мы основательно потрудились над серверной частью приложения, в клиентскую часть больше не попадают бесполезные логи ошибок. Вместо этого клиент получает полезные сведения о том, что пошло не так.
Не забудьте о том, что здесь лежит репозиторий с рассматриваемым здесь кодом. Можете его загрузить, поэкспериментировать с ним, и, если надо, адаптировать под нужды вашего проекта.
3. Работа с ошибками на клиенте
Теперь пришла пора описать третью часть нашей системы обработки ошибок, касающуюся фронтенда. Тут нужно будет, во-первых, обрабатывать ошибки, возникающие в клиентской части приложения, а во-вторых, понадобится оповещать пользователя об ошибках, возникающих на сервере. Разберёмся сначала с показом сведений о серверных ошибках. Как уже было сказано, в этом примере будет использована библиотека React.
▍Сохранение сведений об ошибках в состоянии приложения
Как и любые другие данные, ошибки и сообщения об ошибках могут меняться, поэтому их имеет смысл помещать в состояние компонентов. При монтировании компонента данные об ошибке сбрасываются, поэтому, когда пользователь впервые видит страницу, там сообщений об ошибках не будет.
Следующее, с чем надо разобраться, заключается в том, что ошибки одного типа нужно показывать в одном стиле. По аналогии с сервером, здесь можно выделить 3 типа ошибок.
- Глобальные ошибки — в эту категорию попадают сообщения об ошибках общего характера, приходящие с сервера, или ошибки, которые, например, возникают в том случае, если пользователь не вошёл в систему и в других подобных ситуациях.
- Специфические ошибки, выдаваемые серверной частью приложения — сюда относятся ошибки, сведения о которых приходят с сервера. Например, подобная ошибка возникает, если пользователь попытался войти в систему и отправил на сервер имя и пароль, а сервер сообщил ему о том, что пароль неправильный. Подобные вещи в клиентской части приложения не проверяются, поэтому сообщения о таких ошибках должны приходить с сервера.
- Специфические ошибки, выдаваемые клиентской частью приложения. Пример такой ошибки — сообщение о некорректном адресе электронной почты, введённом в соответствующее поле.
Ошибки второго и третьего типов очень похожи, работать с ними можно, используя хранилище состояния компонентов одного уровня. Их главное различие заключается в том, что они исходят из разных источников. Ниже, анализируя код, мы посмотрим на работу с ними.
Здесь будет использоваться встроенная в React система управления состоянием приложения, но, при необходимости, вы можете воспользоваться и специализированными решениями для управления состоянием — такими, как MobX или Redux.
▍Глобальные ошибки
Обычно сообщения о таких ошибках сохраняются в компоненте наиболее высокого уровня, имеющем состояние. Они выводятся в статическом элементе пользовательского интерфейса. Это может быть красное поле в верхней части экрана, модальное окно или что угодно другое. Реализация зависит от конкретного проекта. Вот как выглядит сообщение о такой ошибке.
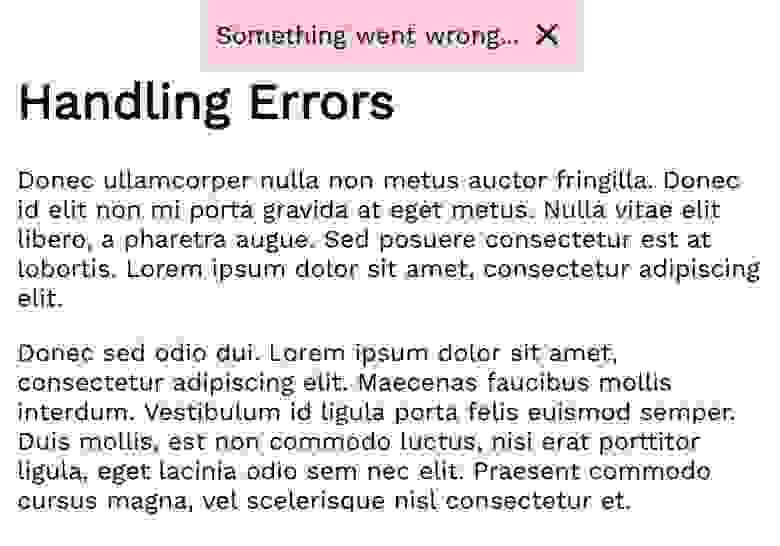
Сообщение о глобальной ошибке
Теперь взглянем на код, который хранится в файле Application.js.
import React, { Component } from 'react'
import GlobalError from './GlobalError'
class Application extends Component {
constructor(props) {
super(props)
this.state = {
error: '',
}
this._resetError = this._resetError.bind(this)
this._setError = this._setError.bind(this)
}
render() {
return (
<div className="container">
<GlobalError error={this.state.error} resetError={this._resetError} />
<h1>Handling Errors</h1>
</div>
)
}
_resetError() {
this.setState({ error: '' })
}
_setError(newError) {
this.setState({ error: newError })
}
}
export default Application
Как видно, в состоянии, в Application.js, имеется место для хранения данных ошибки. Кроме того, тут предусмотрены методы для сброса этих данных и для их изменения.
Ошибка и метод для сброса ошибки передаётся компоненту GlobalError, который отвечает за вывод сообщения об ошибке на экран и за сброс ошибки после нажатия на значок x в поле, где выводится сообщение. Вот код компонента GlobalError (файл GlobalError.js).
import React, { Component } from 'react'
class GlobalError extends Component {
render() {
if (!this.props.error) return null
return (
<div
style={{
position: 'fixed',
top: 0,
left: '50%',
transform: 'translateX(-50%)',
padding: 10,
backgroundColor: '#ffcccc',
boxShadow: '0 3px 25px -10px rgba(0,0,0,0.5)',
display: 'flex',
alignItems: 'center',
}}
>
{this.props.error}
<i
className="material-icons"
style={{ cursor: 'pointer' }}
onClick={this.props.resetError}
>
close
</font></i>
</div>
)
}
}
export default GlobalError
Обратите внимание на строку if (!this.props.error) return null. Она указывает на то, что при отсутствии ошибки компонент ничего не выводит. Это предотвращает постоянный показ красного прямоугольника на странице. Конечно, вы, при желании, можете поменять внешний вид и поведение этого компонента. Например, вместо того, чтобы сбрасывать ошибку по нажатию на x, можно задать тайм-аут в пару секунд, по истечении которого состояние ошибки сбрасывается автоматически.
Теперь, когда всё готово для работы с глобальными ошибками, для задания глобальной ошибки достаточно воспользоваться _setError из Application.js. Например, это можно сделать в том случае, если сервер, после обращения к нему, вернул сообщение об общей ошибке (error: 'GENERIC'). Рассмотрим пример (файл GenericErrorReq.js).
import React, { Component } from 'react'
import axios from 'axios'
class GenericErrorReq extends Component {
constructor(props) {
super(props)
this._callBackend = this._callBackend.bind(this)
}
render() {
return (
<div>
<button onClick={this._callBackend}>Click me to call the backend</button>
</div>
)
}
_callBackend() {
axios
.post('/api/city')
.then(result => {
// сделать что-нибудь с результатом в том случае, если запрос оказался успешным
})
.catch(err => {
if (err.response.data.error === 'GENERIC') {
this.props.setError(err.response.data.description)
}
})
}
}
export default GenericErrorReqНа самом деле, на этом наш разговор об обработке ошибок можно было бы и закончить. Даже если в проекте нужно оповещать пользователя о специфических ошибках, никто не мешает просто поменять глобальное состояние, хранящее ошибку и вывести соответствующее сообщение поверх страницы. Однако тут мы не остановимся и поговорим о специфических ошибках. Во-первых, это руководство по обработке ошибок иначе было бы неполным, а во-вторых, с точки зрения UX-специалистов, неправильно будет показывать сообщения обо всех ошибках так, будто все они — глобальные.
▍Обработка специфических ошибок, возникающих при выполнении запросов
Вот пример специфического сообщения об ошибке, выводимого в том случае, если пользователь пытается удалить из базы данных город, которого там нет.

Сообщение о специфической ошибке
Тут используется тот же принцип, который мы применяли при работе с глобальными ошибками. Только сведения о таких ошибках хранятся в локальном состоянии соответствующих компонентов. Работа с ними очень похожа на работу с глобальными ошибками. Вот код файла SpecificErrorReq.js.
import React, { Component } from 'react'
import axios from 'axios'
import InlineError from './InlineError'
class SpecificErrorRequest extends Component {
constructor(props) {
super(props)
this.state = {
error: '',
}
this._callBackend = this._callBackend.bind(this)
}
render() {
return (
<div>
<button onClick={this._callBackend}>Delete your city</button>
<InlineError error={this.state.error} />
</div>
)
}
_callBackend() {
this.setState({
error: '',
})
axios
.delete('/api/city')
.then(result => {
// сделать что-нибудь с результатом в том случае, если запрос оказался успешным
})
.catch(err => {
if (err.response.data.error === 'GENERIC') {
this.props.setError(err.response.data.description)
} else {
this.setState({
error: err.response.data.description,
})
}
})
}
}
export default SpecificErrorRequest
Тут стоит отметить, что для сброса специфических ошибок недостаточно, например, просто нажать на некую кнопку x. То, что пользователь прочёл сообщение об ошибке и закрыл его, не помогает такую ошибку исправить. Исправить её можно, правильно сформировав запрос к серверу, например — введя в ситуации, показанной на предыдущем рисунке, имя города, который есть в базе. В результате очищать сообщение об ошибке имеет смысл, например, после выполнения нового запроса. Сбросить ошибку можно и в том случае, если пользователь внёс изменения в то, что будет использоваться при формировании нового запроса, то есть — при изменении содержимого поля ввода.
▍Ошибки, возникающие в клиентской части приложения
Как уже было сказано, для хранения данных о таких ошибках можно использовать состояние тех же компонентов, которое используется для хранения данных по специфическим ошибкам, поступающим с сервера. Предположим, мы позволяем пользователю отправить на сервер запрос на удаление города из базы только в том случае, если в соответствующем поле ввода есть какой-то текст. Отсутствие или наличие текста в поле можно проверить средствами клиентской части приложения.

В поле ничего нет, мы сообщаем об этом пользователю
Вот код файла SpecificErrorFrontend.js, реализующий вышеописанный функционал.
import React, { Component } from 'react'
import axios from 'axios'
import InlineError from './InlineError'
class SpecificErrorRequest extends Component {
constructor(props) {
super(props)
this.state = {
error: '',
city: '',
}
this._callBackend = this._callBackend.bind(this)
this._changeCity = this._changeCity.bind(this)
}
render() {
return (
<div>
<input
type="text"
value={this.state.city}
style={{ marginRight: 15 }}
onChange={this._changeCity}
/>
<button onClick={this._callBackend}>Delete your city</button>
<InlineError error={this.state.error} />
</div>
)
}
_changeCity(e) {
this.setState({
error: '',
city: e.target.value,
})
}
_validate() {
if (!this.state.city.length) throw new Error('Please provide a city name.')
}
_callBackend() {
this.setState({
error: '',
})
try {
this._validate()
} catch (err) {
return this.setState({ error: err.message })
}
axios
.delete('/api/city')
.then(result => {
// сделать что-нибудь с результатом в том случае, если запрос оказался успешным
})
.catch(err => {
if (err.response.data.error === 'GENERIC') {
this.props.setError(err.response.data.description)
} else {
this.setState({
error: err.response.data.description,
})
}
})
}
}
export default SpecificErrorRequest▍Интернационализация сообщений об ошибках с использованием кодов ошибок
Возможно, сейчас вы задаётесь вопросом о том, зачем нам нужны коды ошибок (наподобие GENERIC), если мы показываем пользователю только сообщения об ошибках, полученных с сервера. Дело в том, что, по мере роста и развития приложения, оно, вполне возможно, выйдет на мировой рынок, а это означает, что настанет время, когда создателям приложения нужно будет задуматься о поддержке им нескольких языков. Коды ошибок позволяют отличать их друг от друга и выводить сообщения о них на языке пользователя сайта.
Итоги
Надеемся, теперь у вас сформировалось понимание того, как можно работать с ошибками в веб-приложениях. Нечто вроде console.error(err) следует использовать только в отладочных целях, в продакшн подобные вещи, забытые программистом, проникать не должны. Упрощает решение задачи логирования использование какой-нибудь подходящей библиотеки наподобие loglevel.
Уважаемые читатели! Как вы обрабатываете ошибки в своих проектах?

Порядок выполнения и обработка ошибок
- « Предыдущая статья
- Следующая статья »
JavaScript поддерживает компактный набор инструкций, особенно управляющих инструкций, которые вы можете использовать, чтобы реализовать интерактивность в вашем приложении. В данной главе даётся обзор этих инструкций.
Более подробная информация об инструкциях, рассмотренных в данной главе, содержится в справочнике по JavaScript. Точка с запятой (;) используется для разделения инструкций в коде.
Любое выражение (expression) в JavaScript является также инструкцией (statement). Чтобы получить более подробную информацию о выражениях, прочитайте Выражения и операторы.
Инструкция block
Инструкция block является фундаментальной и используется для группировки других инструкций. Блок ограничивается фигурными скобками:
{ statement_1; statement_2; ... statement_n; }
Блок обычно используется с управляющими инструкциями (например, if, for, while).
В вышеприведённом примере { x++; } является блоком.
Обратите внимание: в JavaScript отсутствует область видимости блока до ECMAScript2015. Переменные, объявленные внутри блока, имеют область видимости функции (или скрипта), в которой находится данный блок, вследствие чего они сохранят свои значения при выходе за пределы блока. Другими словами, блок не создаёт новую область видимости. «Автономные» (standalone) блоки в JavaScript могут продуцировать полностью отличающийся результат, от результата в языках C или Java. Например:
var x = 1;
{
var x = 2;
}
console.log(x); // выведет 2
В вышеприведённом примере инструкция var x внутри блока находится в той же области видимости, что и инструкция var x перед блоком. В C или Java эквивалентный код выведет значение 1.
Начиная с ECMAScript 6, оператор let позволяет объявить переменную в области видимости блока. Чтобы получить более подробную информацию, прочитайте let.
Условные инструкции
Условная инструкция — это набор команд, которые выполняются, если указанное условие является истинным. JavaScript поддерживает две условные инструкции: if...else и switch.
Инструкция if…else
Используйте оператор if для выполнения инструкции, если логическое условия истинно. Используйте опциональный else, для выполнения инструкции, если условие ложно. Оператор if выглядит так:
if (condition) {
statement_1;
} else {
statement_2;
}
Здесь condition может быть любым выражением, вычисляемым как истинное (true) или ложное (false). Чтобы получить более подробную информацию о значениях true и false, прочитайте Boolean. Если условие оценивается как true, то выполняется statement_1, в противном случае — statement_2. Блоки statement_1 и statement_2 могут быть любыми блоками, включая также вложенные инструкции if.
Также вы можете объединить несколько инструкций, пользуясь else if для получения последовательности проверок условий:
if (condition_1) { statement_1;} else if (condition_2) { statement_2;} else if (condition_n) { statement_n; } else { statement_last;}
В случае нескольких условий только первое логическое условие, которое вычислится истинным (true), будет выполнено. Используйте блок ({ ... }) для группировки нескольких инструкций. Применение блоков является хорошей практикой, особенно когда используются вложенные инструкции if:
if (condition) {
statement_1_runs_if_condition_is_true;
statement_2_runs_if_condition_is_true;
} else {
statement_3_runs_if_condition_is_false;
statement_4_runs_if_condition_is_false;
}
Нежелательно использовать простые присваивания в условном выражении, т.к. присваивание может быть спутано с равенством при быстром просмотре кода. Например, не используйте следующий код:
Если вам нужно использовать присваивание в условном выражении, то распространённой практикой является заключение операции присваивания в дополнительные скобки. Например:
if ( (x = y) ) { /* ... */ }
Ложные значения
Следующие значения являются ложными:
falseundefinednull0NaN- пустая строка (
"")
Все остальные значения, включая все объекты, будут восприняты как истина при передаче в условное выражение.
Не путайте примитивные логические значения true и false со значениями true и false объекта Boolean. Например:
var b = new Boolean(false);
if (b) // это условие true
if (b == true) // это условие false
В следующем примере функция checkData возвращает true, если число символов в объекте Text равно трём; в противном случае функция отображает окно alert и возвращает false.
function checkData() {
if (document.form1.threeChar.value.length == 3) {
return true;
} else {
alert("Enter exactly three characters. " +
document.form1.threeChar.value + " is not valid.");
return false;
}
}
Инструкция switch
Инструкция switch позволяет сравнить значение выражения с различными вариантами и при совпадении выполнить соответствующий код. Инструкция имеет следующий вид:
switch (expression) {
case label_1:
statements_1
[break;]
case label_2:
statements_2
[break;]
...
default:
statements_default
[break;]
}
Сначала производится поиск ветви case с меткой label, совпадающей со значением выражения expression. Если совпадение найдено, то соответствующий данной ветви код выполняется до оператора break, который прекращает выполнение switch и передаёт управление дальше. В противном случае управление передаётся необязательной ветви default и выполняется соответствующий ей код. Если ветвь default не найдена, то программа продолжит выполняться со строчки, следующей за инструкцией switch. По соглашению ветвь default является последней ветвью, но следовать этому соглашению необязательно.
Если оператор break отсутствует, то после выполнения кода, который соответствует выбранной ветви, начнётся выполнение кода, который следует за ней.
В следующем примере если fruittype имеет значение "Bananas", то будет выведено сообщение "Bananas are $0.48 a pound." и оператор break прекратит выполнение switch. Если бы оператор break отсутствовал, то был бы также выполнен код, соответствующий ветви "Cherries", т.е. выведено сообщение "Cherries are $3.00 a pound.".
switch (fruittype) {
case "Oranges":
console.log("Oranges are $0.59 a pound.");
break;
case "Apples":
console.log("Apples are $0.32 a pound.");
break;
case "Bananas":
console.log("Bananas are $0.48 a pound.");
break;
case "Cherries":
console.log("Cherries are $3.00 a pound.");
break;
case "Mangoes":
console.log("Mangoes are $0.56 a pound.");
break;
case "Papayas":
console.log("Mangoes and papayas are $2.79 a pound.");
break;
default:
console.log("Sorry, we are out of " + fruittype + ".");
}
console.log("Is there anything else you'd like?");
Инструкции обработки исключений
Инструкция throw используется, чтобы выбросить исключение, а инструкция try...catch, чтобы его обработать.
Типы исключений
Практически любой объект может быть выброшен как исключение. Тем не менее, не все выброшенные объекты создаются равными. Обычно числа или строки выбрасываются как исключения, но часто более эффективным является использование одного из типов исключений, специально созданных для этой цели:
- Исключения ECMAScript
DOMException(en-US) иDOMError(en-US)
Инструкция throw
Используйте инструкцию throw, чтобы выбросить исключение. При выбросе исключения нужно указать выражение, содержащее значение, которое будет выброшено:
throw expression;
Вы можете выбросить любое выражение, а не только выражения определённого типа. В следующем примере выбрасываются исключения различных типов:
throw "Error2"; // string
throw 42; // number
throw true; // boolean
throw { toString: function() { return "I'm an object!"; } }; // object
Примечание: Вы можете выбросить объект как исключение. Вы можете обращаться к свойствам данного объекта в блоке catch.
Примечание: В следующем примере объект UserException выбрасывается как исключение:
function UserException (message) {
this.message = message;
this.name = "UserException";
}
UserException.prototype.toString = function () {
return this.name + ': "' + this.message + '"';
}
throw new UserException("Value too high");
Инструкция try…catch
Инструкция try...catch состоит из блока try, который содержит одну или несколько инструкций, и блок catch, которые содержит инструкции, определяющие порядок действий при выбросе исключения в блоке try. Иными словами, если в блоке try будет выброшено исключение, то управление будет передано в блок catch. Если в блоке try не возникнет исключений, то блок catch будет пропущен. Блок finally будет выполнен после окончания работы блоков try и catch, вне зависимости от того, было ли выброшено исключение.
В следующем примере вызывается функция getMonthName, которая возвращает название месяца по его номеру. Если месяца с указанным номером не существует, то функция выбросит исключение "InvalidMonthNo", которое будет перехвачено в блоке catch:
function getMonthName(mo) {
mo = mo - 1; // Adjust month number for array index (1 = Jan, 12 = Dec)
var months = ["Jan","Feb","Mar","Apr","May","Jun","Jul",
"Aug","Sep","Oct","Nov","Dec"];
if (months[mo]) {
return months[mo];
} else {
throw "InvalidMonthNo"; //throw keyword is used here
}
}
try { // statements to try
monthName = getMonthName(myMonth); // function could throw exception
}
catch (e) {
monthName = "unknown";
logMyErrors(e); // pass exception object to error handler -> your own
}
Блок catch
Используйте блок catch, чтобы обработать исключения, сгенерированные в блоке try.
catch (catchID) { statements }
JavaScript создаёт идентификатор catchID, которому присваивается перехваченное исключение, при входе в блок catch; данный идентификатор доступен только в пределах блока catch и уничтожается при выходе из него.
В следующем примере выбрасывается исключение, которое перехватывается в блоке catch:
try {
throw "myException"
} catch (e) {
console.error(e);
}
Блок finally
Блок finally содержит код, который будет выполнен после окончания работы блоков try и catch, но до того, как будет выполнен код, который следует за инструкцией try...catch. Блок finally выполняется вне зависимости от того, было ли выброшено исключение. Блок finally выполняется даже в том случае, если исключение не перехватывается в блоке catch.
В следующем примере открывается файл, затем в блоке try происходит вызов функции writeMyFile, который может выбросить исключение. Если возникает исключение, то оно обрабатывается в блоке catch. В любом случае файл будет закрыт функцией closeMyFile, вызов которой находится в блоке finally.
openMyFile();
try {
writeMyFile(theData);
} catch(e) {
handleError(e);
} finally {
closeMyFile();
}
Если блок finally возвращает значение, то данное значение становится возвращаемым значением всей связки try-catch-finally. Значения, возвращаемые блоками try и catch, будут проигнорированы.
function f() {
try {
console.log(0);
throw "bogus";
} catch(e) {
console.log(1);
return true; // приостанавливается до завершения блока `finally`
console.log(2); // не выполняется
} finally {
console.log(3);
return false; // заменяет предыдущий `return`
console.log(4); // не выполняется
}
// `return false` выполняется сейчас
console.log(5); // не выполняется
}
f(); // отображает 0, 1, 3 и возвращает `false`
Замена возвращаемых значений блоком finally распространяется в том числе и на исключения, которые выбрасываются или перевыбрасываются в блоке catch:
function f() {
try {
throw "bogus";
} catch(e) {
console.log('caught inner "bogus"');
throw e; // приостанавливается до завершения блока `finally`
} finally {
return false; // заменяет предыдущий `throw`
}
// `return false` выполняется сейчас
}
try {
f();
} catch(e) {
// Не выполняется, т.к. `throw` в `catch `заменяется на `return` в `finally`
console.log('caught outer "bogus"');
}
// В результате отображается сообщение caught inner "bogus"
// и возвращается значение `false`
Вложенные инструкции try...catch
Вы можете вкладывать инструкции try...catch друг в друга. Если внутренняя инструкция try...catch не имеет блока catch, то она должна иметь блок finally, кроме того исключение будет перехвачено во внешнем блоке catch. Для получения большей информации ознакомьтесь с вложенными try-блоками.
Использование объекта Error
В зависимости от типа ошибки вы можете использовать свойства name и message, чтобы получить более подробную информацию. Свойство name содержит название ошибки (например, DOMException или Error), свойство message — описание ошибки.
Если вы выбрасываете собственные исключения, то чтобы получить преимущество, которое предоставляют эти свойства (например, если ваш блок catch не делает различий между вашими исключениями и системными), используйте конструктор Error. Например:
function doSomethingErrorProne () {
if ( ourCodeMakesAMistake() ) {
throw ( new Error('The message') );
} else {
doSomethingToGetAJavascriptError();
}
}
try {
doSomethingErrorProne();
} catch (e) {
console.log(e.name); // 'Error'
console.log(e.message); // 'The message' или JavaScript error message
}
Объект Promise
Начиная с ECMAScript2015, JavaScript поддерживает объект Promise, который используется для отложенных и асинхронных операций.
Объект Promise может находиться в следующих состояниях:
- ожидание (pending): начальное состояние, не выполнено и не отклонено.
- выполнено (fulfilled): операция завершена успешно.
- отклонено (rejected): операция завершена с ошибкой.
- заданный (settled): промис выполнен или отклонен, но не находится в состоянии ожидания.

Загрузка изображения при помощи XHR
Простой пример использования объектов Promise и XMLHttpRequest для загрузки изображения доступен в репозитории MDN promise-test на GitHub. Вы также можете посмотреть его в действии. Каждый шаг прокомментирован, что позволяет вам разобраться в архитектуре Promise и XHR. Здесь приводится версия без комментариев:
function imgLoad(url) {
return new Promise(function(resolve, reject) {
var request = new XMLHttpRequest();
request.open('GET', url);
request.responseType = 'blob';
request.onload = function() {
if (request.status === 200) {
resolve(request.response);
} else {
reject(Error('Image didn't load successfully; error code:'
+ request.statusText));
}
};
request.onerror = function() {
reject(Error('There was a network error.'));
};
request.send();
});
}
- « Предыдущая статья
- Следующая статья »
Из этой статьи вы узнаете:
- как пробросить исключение наверх;
- когда и зачем это делать;
- о checked- и unchecked-исключениях;
- о хоткеях, ускоряющих обработку исключений.
А сперва советуем перечитать первую часть.
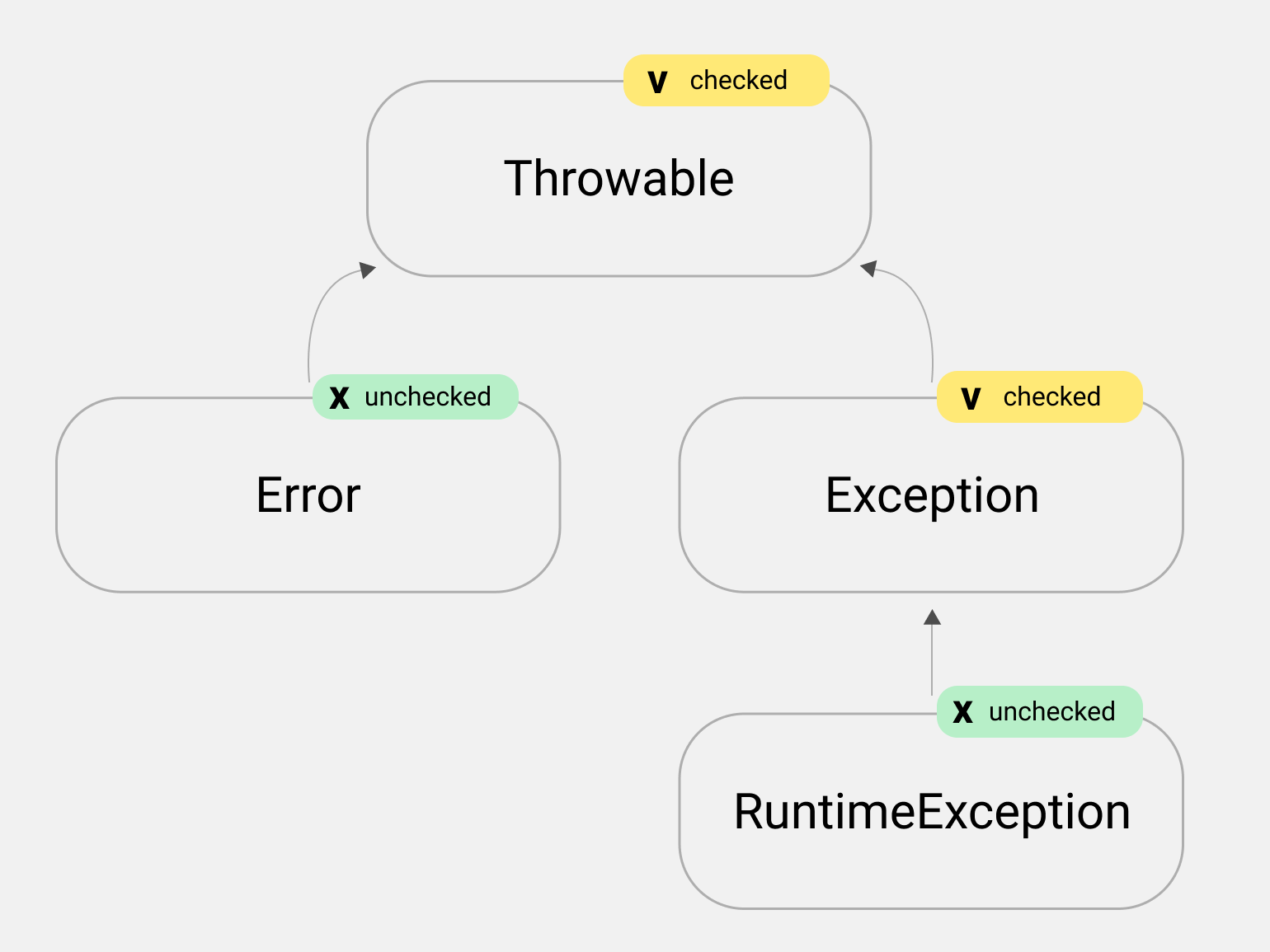
Ранее мы рассказали, что все исключения в Java — это классы, наследники Throwable и Exception; мельком взглянули на класс Error, от которого наследуются ошибки уровня Java-машины.
Сегодня поговорим только про семейство Exception.
В Java много встроенных исключений. На каждом останавливаться не будем: вы и так познакомитесь с ними на практике. Сейчас важнее до конца уяснить, как с исключениями работать.
Напомню, что есть три способа обойтись с исключением:
- Ничего не делать.
- Обработать в конструкции try-catch.
- Пробросить наверх.
С первыми двумя мы разбирались здесь. Остался проброс исключений наверх.
Наверх — это куда? Это выше по стеку вызовов. То есть если метод A вызвал метод B, метод B вызвал метод C, а методC пробросил исключение наверх, то оно всплывёт до метода B — и станет его проблемой.
Как пробросить исключение?
Проще простого.
Вернёмся к примеру из предыдущей статьи. Помните, там был метод hereWillBeTrouble, который мог вызвать исключение ArithmeticException?
Чтобы пробросить это исключение, достаточно добавить в сигнатуру метода hereWillBeTrouble ключевое слово throws, а после него — название класса пробрасываемого исключения.
Вот так:
public static void main(String[] args) { hereWillBeTrouble(); } private static void hereWillBeTrouble() throws ArithmeticException { System.out.println("Всё, что было до..."); int oops = 42 / 0; System.out.println("Всё, что будет после..."); }
Теперь метод hereWillBeTrouble объявляет всему миру, что может кинуть исключение ArithmeticException.
Посмотрим, что произойдёт, если он исполнит эту угрозу.
Изначально исключение возникнет напротив стрелки 1. Но throws передаст его в строку, на которую указывает стрелка 2.

Исключение передалось как эстафетная палочка. И теперь источником исключения является не только строка int oops = 42 / 0, но и строка hereWillBeTrouble();.
Что нам дал проброс исключения?
- Так мы говорим разработчику, который вызывает метод hereWillBeTrouble, что в нём может возникнуть исключение типа ArithmeticException.
- В вызывающем метод hereWillBeTrouble коде это исключение можно обработать с помощью конструкции try-catch.
public static void main(String[] args) { try { hereWillBeTrouble(); } catch (ArithmeticException ex) { System.out.println("Да, это случилось"); } } private static void hereWillBeTrouble() throws ArithmeticException { System.out.println("Всё, что было до..."); int oops = 42 / 0; System.out.println("Всё, что будет после..."); }
Вернёмся к первому блоку кода (в котором нет конструкции try-catch).
Вы наверняка заметили, что и без throws код работал точно так же. Стектрейс (разбирали его здесь) не изменился, исключение в итоге бросалось пользователю.
Но теперь разработчики, которые используют метод hereWillBeTrouble, предупреждены и, если нужно, обезопасят свой код с помощью try-catch.
И это всё, что дало слово throws?
В случае с непроверяемыми исключениями — да. Но вот в случае с проверяемыми… пристегнитесь, нас ждёт новый поворот в деле об исключениях!
Все исключения в Java делятся на две группы. Зовутся они checked и unchecked («проверяемые» и «непроверяемые»). Иногда их также называют «обрабатываемые» и «необрабатываемые».
Запомните! Проверяемые исключения обязательно нужно обрабатывать либо пробрасывать. Непроверяемые — по желанию.
Как понять, проверяемое исключение или нет?
Разработчики языка Java решили так: исключения, которые наследуются от RuntimeException, — непроверяемые, а все остальные — проверяемые.
Исследуем различия на практике
Раз ArithmeticException — непроверяемое исключение, то его можно обрабатывать, а можно и не обрабатывать. Мы обрабатывали.
Когда при выполнении кода возникало исключение — программа вылетала, это само собой. Но заметьте: программа компилировалась и запускалась даже с риском возникновения исключения.
Без проблем компилируется и код, в котором кидают исключение явно:
private static void hereWillBeTrouble(int a, int b) { if (b == 0) { throw new ArithmeticException("Ты опять делишь на ноль?"); } int oops = a / b; System.out.println(oops); }
Компиляция успешна только потому, что исключение непроверяемое.
А теперь проделаем то же самое с проверяемым исключением:
public static void main(String[] args) { hereWillBeTrouble(); } private static void hereWillBeTrouble() { throw new CloneNotSupportedException(); }
Вжух — и наш код перестал компилироваться!
Вот мы и подтвердили разницу между проверяемыми и непроверяемыми исключениями: нельзя скомпилировать и запустить программу, если в ней есть проверяемое исключение, которое кинули, но не обработали и не пробросили.
Итак, вариантов у нас два:
- обработать исключение с помощью try-catch;
- пробросить исключение выше.
Оборачивать код конструкцией try-catch вы уже умеете. Рассмотрим второй вариант:
public static void main(String[] args) { hereWillBeTrouble(); } private static void hereWillBeTrouble() throws CloneNotSupportedException { throw new CloneNotSupportedException(); }
А код всё ещё не компилируется. Но если в первом случае ошибка компиляции возникала в методе hereWillBeTrouble — в строке, где кидалось проверяемое, но при этом необработанное исключение, то теперь ошибка будет в методе main, потому что проверяемое и необработанное исключение поднялось до него.
Теперь исключение возникает в строке, где вызывается метод hereWillBeTrouble. Повторимся, так происходит потому, что этот метод кидает проверяемое исключение (он продекларировал это с помощью ключевого слова throws).
И теперь методу main тоже нужно что-то с исключением делать: либо обработать его с помощью try-catch, либо пробросить ещё выше.
Первый вариант, try-catch:
public static void main(String[] args) { try { hereWillBeTrouble(); } catch (CloneNotSupportedException e) { e.printStackTrace(); } }
Второй вариант, проброс выше:
public static void main(String[] args) throws CloneNotSupportedException {
hereWillBeTrouble();
}
Несмотря на то что метод main запускается первым, ему тоже разрешено кидать исключения.
Что мы выяснили про проброс исключения наверх?
В случае с непроверяемыми исключениями это способ передать свою проблему тем, кто будет вызывать наш метод.
Наш метод теперь компилируется, а вот вызывающий — нет. Так будет до тех пор, пока в нём не сделают что-то с исключением (возможно, передадут его ещё выше по стеку вызовов).
Интересный момент. Если метод способен кинуть проверяемое исключение, то компилятор не будет перепроверять: ему всё равно, что происходит внутри этого метода. Для него главное, что метод о такой возможности заявил.
Убедитесь, что следующий код не скомпилируется:
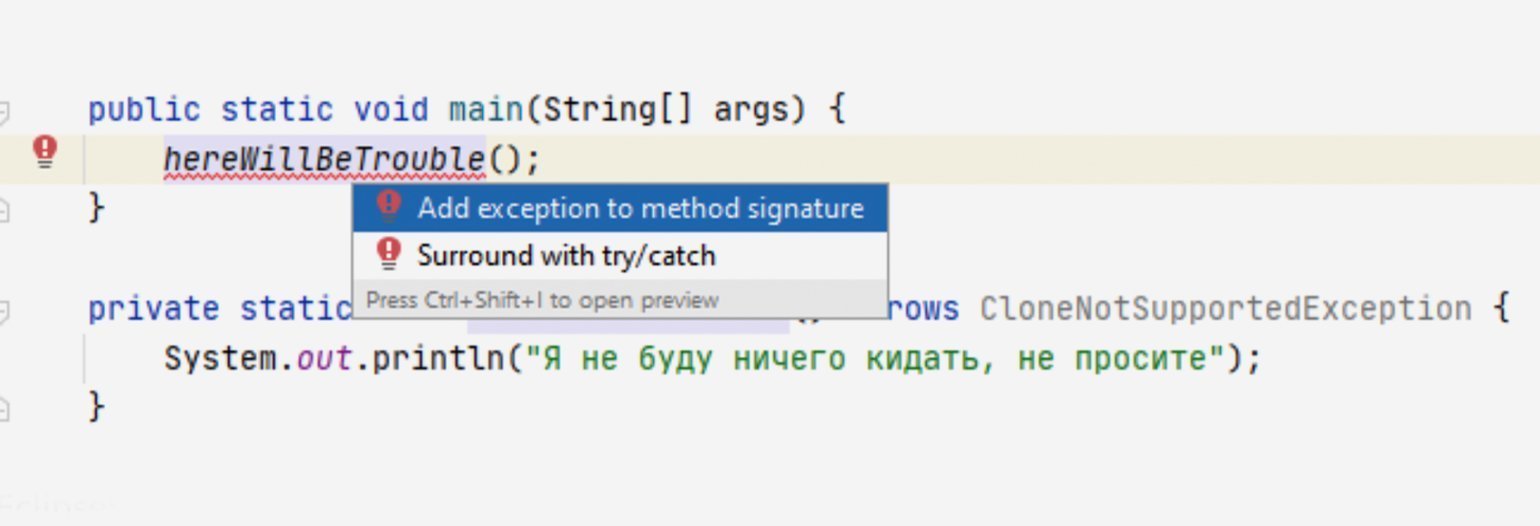
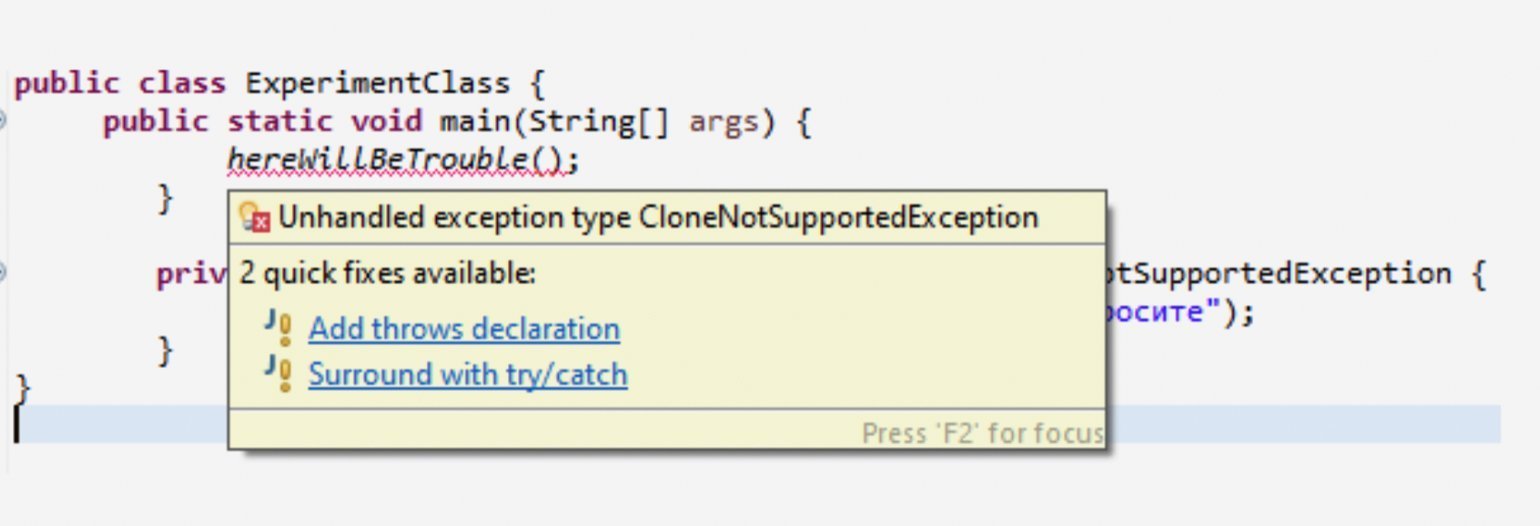
public static void main(String[] args) { hereWillBeTrouble(); } private static void hereWillBeTrouble() throws CloneNotSupportedException { System.out.println("Я не буду ничего кидать, не просите"); }
Напоследок — небольшая подсказка.
Среда разработки стремится упростить нам жизнь: когда в коде обнаруживается проверяемое исключение — она предлагает реализовать его обработку.
Нам остаётся только выбрать, чего мы хотим: обработать исключение с помощью try-catch или пробросить выше.
Горячие клавиши, которые позволяют это сделать:
- в среде IntelliJ IDEA — Alt + Enter / ⌥Enter,
- для среды разработки Eclipse — F2.
Например:
IntelliJ IDEA:
Eclipse:
В следующей статье я расскажу обо всей мощи конструкции try-catch.
Ещё больше хитростей, дженериков и других особенностей Java — на курсе «Профессия Java-разработчик». Научим программировать на самом востребованном языке и поможем устроиться на работу.