Есть способ передавать данные, теряя часть по пути, но так, чтобы потерянное можно было вернуть по прибытии. Это третья, завершающая часть моего простого изложения алгоритма избыточного кодирования по Риду-Соломону. Реализовать это в коде не прочитав первую, или хотя бы вторую часть на эту тему будет проблематично, но чтобы понять для себя что можно сделать с использованием кодировки Рида-Соломона, можно ограничиться прочтением этой статьи.
Что может этот код?
И так, что из себя представляет избыточный код Рида-Соломона с практической точки зрения? Допустим, есть у нас сообщение – «DON’T PANIC». Если добавить к нему несколько избыточных байт, допустим 6 штук: «rrrrrrDON’T PANIC» (каждый r – это рассчитанный по алгоритму байт), а затем передать через какую-нибудь среду с помехами, или сохранить там, где данные могут понемногу портиться, то по окончании передачи или хранения у нас может остаться такое, например: «rrrrrrDON’AAAAAAA» (6 байт оказались с ошибкой). Если мы знаем номера байтов, где вместо букв, которые были при создании кода, вдруг оказались какие-нибудь «A», то мы можем полностью восстановить сообщение в исходное «rrrrrrDON’T PANIC». После этого можно для красоты убрать избыточные символы. Теперь текст можно печатать на обложку.
Вообще, избыточных символов к сообщению мы можем добавить сколько угодно. Количество избыточных символов равно количеству исправляемых ошибок (это верно лишь в том случае, когда нам известны номера позиций ошибок). Как правило, ошибки, положение которых известно, называют erasures. Благозвучного перевода найти не могу («стирание» мне не кажется благозвучным), так что в дальнейшем я буду применять термин «опечатки» и ставить его в кавычки (прекрасно понимаю, что этот термин обычно несёт похожий, но другой смысл). Исправление «опечаток» полезно, например, при восстановлении блоков QR кода, которые по какой-либо причине не удалось прочитать.
Также код Рида-Соломона позволяет исправлять ошибки, положение которых неизвестно, но тогда на каждую одну исправляемую ошибку должно приходиться 2 избыточных символа. «rrrrrrDON’T PANIC», принятые как «rrrrrrDO___ PANIC» легко будут исправлены без дополнительной информации. Неправильно принятый байт, положение которого неизвестно, в дальнейшем я буду называть «ошибкой» и тоже брать в кавычки.
Можно комбинировать исправление «ошибок» и «опечаток». Если, например, есть 3 избыточных символа, то можно исправить одну «ошибку» и одну «опечатку». Ещё раз обращу внимание на то, что чтобы исправить «опечатку», нужно каким-то образом (не связанным с алгоритмом Рида-Соломона) узнать номер байта «опечатки». Что важно, и «ошибки» и «опечатки» могут быть исправлены алгоритмом и в избыточных байтах тоже.
Стоит отметить, что если количество переданных и принятых байт отличается, то здесь код Рида-Соломона практически бессилен. То есть, если на расшифровку попадёт такое: «rrrrrrDO’AIC», то ничего сделать не получится, если, конечно, неизвестно какие позиции у пропавших букв.
Как закодировать сообщение?
Здесь уже не обойтись без понимания арифметики с полиномами в полях Галуа. Ранее мы научились представлять сообщения в виде полиномов и проводить операции сложения, умножения и деления над ними. Уже этого почти достаточно, чтобы создать код Рида-Соломона из сообщения. Единственно, для того, чтобы это сделать понадобится ещё полином-генератор. Это результат такого произведения:

Где  – это примитивный член поля (как правило, выбирают 2), а
– это примитивный член поля (как правило, выбирают 2), а  – это количество избыточных символов. То есть, прежде чем создавать код Рида-Соломона из сообщения, нужно определиться с количеством избыточных символов, которое мы считаем достаточным, затем перемножить биномы вида
– это количество избыточных символов. То есть, прежде чем создавать код Рида-Соломона из сообщения, нужно определиться с количеством избыточных символов, которое мы считаем достаточным, затем перемножить биномы вида  в количестве
в количестве  штук по правилам перемножения полиномов. Для любого сообщения можно использовать один и тот же полином-генератор, и любое сообщение в таком случае будет закодировано с одним и тем же количеством избыточных символов.
штук по правилам перемножения полиномов. Для любого сообщения можно использовать один и тот же полином-генератор, и любое сообщение в таком случае будет закодировано с одним и тем же количеством избыточных символов.
Пример: Мы решили использовать 4 избыточных символа, тогда нужно составить такое выражение:
![]()
Так как мы работаем с полем Галуа, то вместо минуса можно смело писать плюс, не боясь никаких последствий. Жаль, что это не работает с количеством денег после похода в магазин. И так, возводим в степень, и перемножаем (по правилам поля Галуа GF[256], порождающий полином 285):
![]()
Необязательное дополнение
Легко заметить (правда легко – надо лишь взглянуть на произведение биномов), что корнями получившегося полинома будут как раз степени примитивного члена: 2, 4, 8, 16. Что самое интересное, если взять какой-нибудь другой полином, умножить его на  (4 – в данном случае это количество избыточных символов), получится тот же самый полином, только с нулями в коэффициентах перед первыми 4 младшими степенями, а затем разделить его на полином-генератор, и прибавить остаток от деления к нашему полиному с 4 нулями, то его корнями также будут эти 4 числа (2, 4, 8, 16).
(4 – в данном случае это количество избыточных символов), получится тот же самый полином, только с нулями в коэффициентах перед первыми 4 младшими степенями, а затем разделить его на полином-генератор, и прибавить остаток от деления к нашему полиному с 4 нулями, то его корнями также будут эти 4 числа (2, 4, 8, 16).
Выражение выше есть полином-генератор, который необходим для того, чтобы закодировать сообщение любой длины, добавив к нему 4 избыточных символа, которые позволят скорректировать 2 «ошибки» или 4 «опечатки».
Прежде чем приводить пример кодирования, нужно договориться об обозначениях. Полиномы, записанные «по-математически» с иксами и степенями выглядят довольно-таки громоздко. На самом деле, при написании программы достаточно знать коэффициенты полинома, а степени  можно узнать из положения этих коэффициентов. Таким образом полученный в примере выше полином-генератор можно записать так: {116, 167, 224, 30, 1}. Также, для ещё большей компактности, можно опустить скобки и запятые и записать всё в шестнадцатеричном представлении: 74 E7 D8 1E 01. Выходит в 2 раза короче. Надо отметить, что если в «математической» записи мы не пишем члены, коэффициенты которых равны нулю, то при принятой здесь шестнадцатеричной записи они обязательны, и, например,
можно узнать из положения этих коэффициентов. Таким образом полученный в примере выше полином-генератор можно записать так: {116, 167, 224, 30, 1}. Также, для ещё большей компактности, можно опустить скобки и запятые и записать всё в шестнадцатеричном представлении: 74 E7 D8 1E 01. Выходит в 2 раза короче. Надо отметить, что если в «математической» записи мы не пишем члены, коэффициенты которых равны нулю, то при принятой здесь шестнадцатеричной записи они обязательны, и, например,  нужно записывать так:
нужно записывать так:  или 00 00 00 00 0A. Там, где «математическая» запись позволит более понятно объяснить суть, я буду прибегать к ней.
или 00 00 00 00 0A. Там, где «математическая» запись позволит более понятно объяснить суть, я буду прибегать к ней.
И так, чтобы представить сообщение «DON’T PANIC» в полиномиальной форме, с учётом соглашения выше достаточно просто записать его байты:
44 4F 4E 27 54 20 50 41 4E 49 43.
Чтобы создать код Рида-Соломона с 4 избыточными символами, сдвигаем полином вправо на 4 позиции (что эквивалентно умножению его на  ):
):
00 00 00 00 44 4F 4E 27 54 20 50 41 4E 49 43
Теперь делим полученный полином на полином-генератор (74 E7 D8 1E 01), берём остаток от деления (DB 22 58 5C) и записываем вместо нулей к полиному, который мы делили. (это эквивалентно операции сложения):
DB 22 58 5C 44 4F 4E 27 54 20 50 41 4E 49 43
Вот эта строка как раз и будет кодом Рида-Соломона для сообщения «DON’T PANIC» с 4 избыточными символами.
Некоторые пояснения
Порядок записи степеней при представлении сообщения в виде полинома имеет значение, ведь полином  не эквивалентен полиному
не эквивалентен полиному  , поэтому следует определиться с этим порядком один раз и его придерживаться. Ещё раз: когда мы преобразуем:
, поэтому следует определиться с этим порядком один раз и его придерживаться. Ещё раз: когда мы преобразуем:
сообщение -> полином, порядок имеет значение.
Так как избыточные символы подставляются именно в младшие степени при кодировании, то от выбора порядка степеней при представлении сообщения зависит положение избыточных символов – в начале или в конце закодированного сообщения.
Изменение порядка записи никоим образом не влияет на арифметику с полиномами, ведь как полином не запиши другим он не становится.  . Это очевидно, но при составлении алгоритма легко запутаться.
. Это очевидно, но при составлении алгоритма легко запутаться.
В некоторых статьях полином-генератор начинается не с первой степени, как здесь:  , а с нулевой:
, а с нулевой:  . Это не эквивалентные записи одного и того же, последующие вычисления будут отличаться в зависимости от этого выбора.
. Это не эквивалентные записи одного и того же, последующие вычисления будут отличаться в зависимости от этого выбора.
Также при создании кода можно не делить на полином-генератор, получая остаток, а умножать на него. Это слегка другая разновидность кода Рида-Соломона, в которой в закодированном сообщении не содержится в явном виде исходное.
Как раскодировать сообщение?
Здесь всё посложнее будет. Ненамного, но всё же. Вопрос про раскодировать, собственно «не вопрос!» – убираем избыточные символы и остаётся исходное сообщение. Вопрос в том, как узнать, были ли ошибки при передаче, и если были, то как их исправить.
В первую очередь нужно отметить, что при проверке на наличие ошибок нужно знать количество избыточных символов. А во-вторую – надо научиться считать значение полинома при определённом  . Про количество избыточных символов нам должен заранее сообщить тот, кто кодировал сообщение, а вот чтобы вычислить значение полинома нужно написать ещё одну функцию для работы с полиномами. Это элементарщина – просто вместо
. Про количество избыточных символов нам должен заранее сообщить тот, кто кодировал сообщение, а вот чтобы вычислить значение полинома нужно написать ещё одну функцию для работы с полиномами. Это элементарщина – просто вместо  подставляется нужное значение. Но пример, всё же, никогда не помешает.
подставляется нужное значение. Но пример, всё же, никогда не помешает.
Пример: Нужно вычислить полином при
при  . Подставляем, возводим в степень:
. Подставляем, возводим в степень:  , перемножаем,
, перемножаем,  , складываем и получаем число
, складываем и получаем число  . Сложение, умножение и возведение в степень здесь по правилам поля Галуа GF[256] (порождающий полином 285)
. Сложение, умножение и возведение в степень здесь по правилам поля Галуа GF[256] (порождающий полином 285)
Код приводить не буду, оставлю ссылку на гитхаб: https://github.com/AV-86/Reed-Solomon-Demo/releases Там всё что я описывал в этой и предыдущих статьях реализовано на C#, в виде демо-приложения (собирается под win в VS2019, бинарник тоже выложен). Можно посмотреть как работает арифметика в поле Галуа, а также посмотреть, как работает кодирование Рида-Соломона.
И так, прежде чем исправлять «ошибки» или «опечатки» нужно узнать есть ли они. Элементарно. Нужно вычислить полином принятого сообщения с избыточными символами при  равном степеням примитивного члена. Это те же числа, которые мы использовали при составлении полинома-генератора:
равном степеням примитивного члена. Это те же числа, которые мы использовали при составлении полинома-генератора:  ,
,  – количество избыточных символов,
– количество избыточных символов,  – примитивный член. Если ошибок нет, то все вычисленные значения будут равны нулю. Закодированное ранее сообщение «DON’T PANIC» с 4 избыточными символами, в виде полинома в шестнадцатеричном представлении:
– примитивный член. Если ошибок нет, то все вычисленные значения будут равны нулю. Закодированное ранее сообщение «DON’T PANIC» с 4 избыточными символами, в виде полинома в шестнадцатеричном представлении:
DB 22 58 5C 44 4F 4E 27 54 20 50 41 4E 49 43,
если вычислить этот полином при  равном 2, 4, 8, 16, то получатся значения: 0, 0, 0, 0, ведь здесь сообщение точно в таком же виде, в котором оно и было закодировано. Если изменить хотя бы один байт, например, последний символ сделаем более правильным: 42 вместо 43:
равном 2, 4, 8, 16, то получатся значения: 0, 0, 0, 0, ведь здесь сообщение точно в таком же виде, в котором оно и было закодировано. Если изменить хотя бы один байт, например, последний символ сделаем более правильным: 42 вместо 43:
DB 22 58 5C 44 4F 4E 27 54 20 50 41 4E 49 42,
то результат такого же вычисления станет равным 13, 18, B5, 5D. Эти значения называются синдромами. Их тоже можно принять за полином. Тогда это будет полином синдромов.
И так, чтобы узнать есть ли ошибки в принятом сообщении, нужно посчитать полином синдромов. Если он состоит из одних нулей (также можно говорить, что он равен нулю), то ошибок нет.
Важное, но совсем занудное дополнение
Может случиться так, что сообщение с ошибками будет иметь синдром равным нулю. Это случится в том случае, когда полином амплитуд ошибок (о нём будет ниже) кратен полиному-генератору. Так что проверку ошибок по полиному синдромов кода Рида-Соломона нельзя считать 100% гарантией отсутствия ошибок. Можно даже посчитать вероятность такого случая.
Допустим мы кодируем сообщение из 4 символов четырьмя же избыточными символами, то есть передаём 8 байт. Также возьмём для примера вероятность ошибки при передаче одного символа в 10%. То есть, в среднем на каждые 10 символов приходится один, который передался как случайное число от 00 до FF. Это, конечно же совсем синтетическая ситуация, которая вряд ли будет в реальности, но здесь можно точно вычислить вероятности.
Для рассчёта я рассуждаю так: Полиномы, кратные полиному-генератору получаются умножением генератора на другие полиномы. Пятизначный кратный полином — получается умножением на константу от 1 до 255. Шестизначный — умножением на бином первой степени а их, без нулей ровно  Те же рассуждения для 7 и 8 -значных полиномов, кратных генератору. Затем надо найти вероятности выпадения 5, 6, 7 и 8 ошибок подряд, и для каждой из них вычислить вероятность, что такая случайная последовательность ошибок окажется кратной полиному-генератору. Сложить их, и тогда мы получим вероятность того, что при передаче 4 байт с 4 избыточными символами, при вероятности ошибки при передаче одного символа 10% получится не обнаруживаемая кодом Рида-Соломона ошибочная передача. Рассчёт в маткаде:
Те же рассуждения для 7 и 8 -значных полиномов, кратных генератору. Затем надо найти вероятности выпадения 5, 6, 7 и 8 ошибок подряд, и для каждой из них вычислить вероятность, что такая случайная последовательность ошибок окажется кратной полиному-генератору. Сложить их, и тогда мы получим вероятность того, что при передаче 4 байт с 4 избыточными символами, при вероятности ошибки при передаче одного символа 10% получится не обнаруживаемая кодом Рида-Соломона ошибочная передача. Рассчёт в маткаде:

Итого, на каждые ~500 Тб при такой передаче окажется один блок из 4 ошибочных символов, которые алгоритм посчитает корректными. Цифры большие, но вероятность не 0. При вероятности ошибки в 1% речь идёт об эксабайтах. Рассчёт, конечно не эталон, может быть даже с ошибками, но даёт понять об порядках чисел.
Что же делать, если синдром не равен нулю? Конечно же исправлять ошибки! Для начала рассмотрим случай с «опечатками», когда мы точно знаем номера позиций некорректно принятых байт. Ошибёмся намеренно в нашем закодированном сообщении 4 раза, столько же, сколько у нас избыточных символов:
DB 22 58 5C 44 4F 4E 27 54 20 41 41 41 41 41
41 – это буква A, поэтому их 5 подряд получилось. Позиции ошибок считаются слева направо, начиная с 0. Для удобства используем шестнадцатеричную систему при нумерации:
00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E
DB 22 58 5C 44 4F 4E 27 54 20 50 41 4E 49 43
DB 22 58 5C 44 4F 4E 27 54 20 41 41 41 41 41
Позиции ошибок: 0A 0C 0D 0E.
И так, если мы находимся на стороне приёмника, то у нас есть следующая информация:
-
Сообщение с 4 избыточными символами;
-
само сообщение: DB 22 58 5C 44 4F 4E 27 54 20 41 41 41 41 41;
-
В сообщении есть ошибки в позициях 0A 0C 0D 0E.
Этого достаточно, чтобы восстановить сообщение в исходное состояние. Но обо всём по порядку.
Для продолжения необходимо разучить ещё одну операцию с полиномами в полях Галуа — взятие формальной производной от полинома. Формальная производная полинома в поле Галуа похожа на обычную производную. Формальной она называется потому, что в полях вроде GF[256] нет дробных чисел, и соответственно нельзя определить производную, как отношение бесконечно малых величин. Вычисляется похоже на обычную производную, но с особенностями. Если при обычном дифференцировании  , то для формальной производной в поле Галуа с основанием 2, формула для дифференцирования члена такая:
, то для формальной производной в поле Галуа с основанием 2, формула для дифференцирования члена такая:  . Это значит, что достаточно просто переписать полином, начиная с первой степени (нулевая выкидывается) и у оставшегося убрать (обнулить, извиняюсь) члены с нечётными степенями. Пример:
. Это значит, что достаточно просто переписать полином, начиная с первой степени (нулевая выкидывается) и у оставшегося убрать (обнулить, извиняюсь) члены с нечётными степенями. Пример:
Необходимо найти производную
![]()
(Это рандомный полином, не связан с примером). Производная суммы равна сумме производных, соответственно применяем формулу для производной члена и получаем:
![]()
Или, если записывать в шестнадцатеричном виде, то это же самое выглядит так:
(01 2D A5 C6 8C DF )’ = 2D 00 C6 00 DF .
Думаю, что из примера в шестнадцатеричном виде проще всего составить алгоритм нахождения формальной производной.
Теперь можно уже исправить «опечатки»? Как бы не так! Нужно ещё два полинома. Полином-локатор и полином ошибок.
Полином-локатор – это полином, корнями которого являются числа обратные примитивному члену в степени позиции ошибки. Сложно? Можно проще. Полином-локатор это произведение вида
![]()
где  – это примитивный член,
– это примитивный член,  и так далее – это позиции ошибок.
и так далее – это позиции ошибок.
Пример: у нас есть позиции ошибок 10, 12, 13, 14; примитивный член  тогда полином локатор будет таким:
тогда полином локатор будет таким:
![]()
Перемножаем и получаем полином-локатор для позиций ошибок 10, 12, 13, 14:
![]()
Или в шестнадцатеричной записи: 01 2D A5 C6 8C.
Про полином-локатор нужно понять следующее: из него можно получить позиции ошибок, и наоборот – из позиций ошибок можно получить полином-локатор. По сути, это две разные записи одного и того же – позиций ошибок.
Полином ошибок – его по-разному называют в разных статьях, он не так уж и сложен. Представляет из себя произведение полинома синдромов и полином-локатора, с отброшенными старшими степенями. Продолжая пример, найдём полином ошибок для искажённого сообщения:
DB 22 58 5C 44 4F 4E 27 54 20 41 41 41 41 41
Полином синдромов: 72 BD 22 5B
Произведение полинома синдромов и полинома-локатора не буду расписывать в «математическом» виде, напишу так:
(72 BD 22 5B)(01 2D A5 C6 8C) = 72 4B 10 22 D9 C0 57 15
У результата оставляем количество младших членов, равное количеству избыточных символов, в нашем случае их 4, старшие степени просто выбрасываем, они не нужны. Остаётся
72 4B 10 22
Это и есть полином ошибок.
Осталось посчитать амплитуды ошибок. Звучит угрожающе, но на деле это просто значения, которые нужно прибавить к искажённым символам сообщения чтобы получились неискажённые символы. Для этого воспользуемся алгоритмом Форни. Здесь придётся привести фрагмент кода, словами расписать так, чтобы было понятно, очень сложно.
Функция принимает на входе
-
полином синдромов (Syndromes),
-
полином, в котором члены – позиции ошибок (ErrPos),
-
количество избыточных символов (NumOfErCorrSymbs).
Класс GF_Byte — это просто байт, для которого переопределены арифметические операции так, чтобы они выполнялись по правилам поля Галуа GF[256], класс GF_Poly – Это полином в поле Галуа. По сути, массив GF_Byte. Для него также переопределны арифметические операции так, чтобы они выполнялись по правилам арифметики с полиномами в полях Галуа.
public static GF_Poly FindMagnitudesFromErrPos(
GF_Poly Syndromes,
GF_Poly ErrPos,
uint NumOfErCorrSymbs)
{
//Вычисление локатора из позиций ошибок
GF_Poly Locator = CalcLocatorPoly(ErrPos);
//Произведение для вычисления полинома ошибок
GF_Poly Product = Syndromes * Locator;
//Полином ошибок. DiscardHiDeg оставляет указаное количество младших степеней
GF_Poly ErrPoly = Product.DiscardHiDeg(NumOfErCorrSymbs);
//Производная локатора
GF_Poly LocatorDer = Locator.FormalDerivative();
//Здесь будут амплитуды ошибок. Количество членов - это самая большая позиция ошибки
GF_Poly Magnitudes = new GF_Poly(ErrPos.GetMaxCoef());
//Перебор каждой заданной позиции ошибки
for (uint i = 0; i < ErrPos.Len; i++) {
//число обратное примитивному члену в степени позиции ошибки
GF_Byte Xi = 1 / GF_Byte.Pow_a(ErrPos[i]);
//значение полинома ошибок при x = Xi
GF_Byte W = ErrPoly.Eval(Xi);
//значение производной локатора при x = Xi
GF_Byte L = LocatorDer.Eval(Xi);
//Это как раз и будет найденное значение ошибки,
//которое надо вычесть из ошибочного символа, чтобы он стал не ошибочным
GF_Byte Magnitude = W / L;
//запоминаем найденную амплитуду в текущей позиции ошибки
Magnitudes[ErrPos[i]] = Magnitude;
}
return Magnitudes;
}Если скормить функции следующие параметры:
-
полином синдромов 72 BD 22 5B
-
полином, в котором члены — позиции ошибок 0A 0C 0D 0E
-
количество символов коррекции ошибок 4,
то на выходе она даст полином амплитуд ошибок:
00 00 00 00 00 00 00 00 00 00 11 00 0F 08 02.
Теперь можно прибавить полученное к искажённому сообщению
DB 22 58 5C 44 4F 4E 27 54 20 41 41 41 41 41
(по правилам сложения полиномов, конечно же), и на выходе получится исходное сообщение:
DB 22 58 5C 44 4F 4E 27 54 20 50 41 4E 49 43.
Первые 4 байта — это избыточные символы. Если бы в них оказались «опечатки», то разницы никакой для алгоритма нет, разве что они нам не нужны после исправления. Можно их просто отбросить:
44 4F 4E 27 54 20 50 41 4E 49 43 Это исходное сообщение «DON’T PANIC».
Здесь должно быть понятно, как исправлять ошибки, положение которых известно. Само по себе уже это может нести практическую пользу. В QR кодах на обшарпанных стенах могут стереться некоторые квадратики, и программа, которая их расшифровывает сможет определить в каких именно местах находятся байты, которые не удалось прочитать, которые «стёрлись» – erasures, или как мы договорились писать по-русски «опечатки». Но нам этого, конечно же недостаточно. Мы хотим уметь выявлять испорченные байты без дополнительной информации, чтобы передавать их по радио, или по лазерному лучу, или записывать на диски (кого я обманываю? CD давно мертвы), может быть, захотим реализовать передачу через ультразвук под водой, чтобы управлять моделью подводной лодки, а какие-нибудь неблагодарные дельфины будут портить случайные данные своими песнями. Для всего этого нам понадобится уметь выявлять, в каких именно байтах при передаче попортились биты.
Как найти позиции ошибок?
Вспомним про полином-локатор. Его можно составить из заранее известных позиций ошибок, а ещё его можно вычислить из полинома-синдромов и количества избыточных символов. Есть не один алгоритм, который позволяет это сделать. Здесь будет алгоритм алгоритм Берлекэмпа-Мэсси. Если хочется много математики, то гугл с википедией на неё не скупятся. Я, если честно, не вник до конца в циклические полиномы и прочее-прочее-прочее. Стыдно, немножко, конечно, но я взял реализацию этого алгоритма с сайта Wikiversity переписал его на C#, и постарался сделать его более доходчивым и читаемым:
public static GF_Poly CalcLocatorPoly(GF_Poly Syndromes, uint NumOfErCorrSymbs) {
//Алгоритм Берлекэмпа-Мэсси
GF_Poly Locator;
GF_Poly Locator_old;
//Присваиваем локатору инициализирующее значение (1*X^0)
Locator = new GF_Poly(new byte[] { 1 });
Locator_old = new GF_Poly(Locator);
uint Synd_Shift = 0;
for (uint i = 0; i < NumOfErCorrSymbs; i++) {
uint K = i + Synd_Shift;
GF_Byte Delta = Syndromes[K];
for (uint j = 1; j < Locator.Len; j++) {
Delta += Locator[j] * Syndromes[K - j];
}
//Умножение полинома на икс (эквивалентно сдвигу вправо на 1 байт)
Locator_old = Locator_old.MultiplyByXPower(1);
if (Delta.val != 0) {
if (Locator_old.Len > Locator.Len) {
GF_Poly Locator_new = Locator_old.Scale(Delta);
Locator_old = Locator.Scale(Delta.Inverse());
Locator = Locator_new;
}
//Scale – умножение на константу. Можно было бы
//вместо использования Scale
//умножить на полином нулевой степени. Разницы нет, но так короче:
Locator += Locator_old.Scale(Delta);
}
}
return Locator;
}Пояснения по коду
Приведённый алгоритм считает локатор. Если количество «ошибок» больше, чем количество избыточных символов, поделённое на 2, то алгоритм не сработает правильно.
Если в сообщении, которое мы используем для примера –
DB 22 58 5C 44 4F 4E 27 54 20 50 41 4E 49 43,
ошибиться в нулевом и последнем символе (2 «ошибки», мы притворяемся, что не знаем в каких позициях ошиблись), получится такой полином:
02 22 58 5C 44 4F 4E 27 54 20 50 41 4E 49 01,
Полином синдромов для него 4B A7 E8 BD. Если выполнить функцию, приведённую выше с параметрами 4B A7 E8 BD, и 4 (количество избыточных символов), то она вернёт нам такой полином: 01 12 13. Это не похоже на позиции ошибок, которые мы ожидаем, но полином-локатор содержит в себе информацию о позициях ошибок, ведь это «полином, корнями которого являются числа обратные примитивному члену в степени позиции ошибки». Из этого, если немного поскрипеть мозгами или ручкой по бумаге следует, что позиция ошибки – это логарифм числа по основанию примитивного члена, обратного корню полинома.
![]()
E – позиция ошибки, a – примитивный член (2, как правило), R – корень полинома.
Что-ж, будем искать корни в поле. Поиск корней полинома в поле Галуа занятие лёгкое и непыльное. В GF[256] может быть 256 числел всего, так что иксу негде разгуляться. Просто считаем полином 256 раз, подставляя вместо x число, и если полином посчитался как нуль, то записываем к массиву с корнями текущее значение x. Дальше считаем по формуле и получаем позиции ошибок 00 и 0E, именно там где они и были допущены. Теперь эти значения вместе с синдромами и цифрой 4 можно скармливать алгоритму Форни, чтобы он исправил «ошибки» также, как он исправлял «опечатки».
Ещё пара пояснений
-
Существуют более эффективные алгоритмы поиска корней полинома в поле Галуа. Перебор просто самый наглядный.
-
В позиции 00 в текущем примере находится избыточный символ. Алгоритмам Берлекэмпа-Месси и Форни это абсолютно неважно.
Если у нас есть 4 избыточных символа, при этом мы знаем что есть 2 «опечатки» в известных позициях, то алгоритм Берлекэмпа-Мэсси сможет найти ещё одну «ошибку». Но для этого его нужно будет совсем немного модифицировать. Всего то надо там где мы писали
//Присваиваем локатору инициализирующее значение (1*X^0)
Locator = new GF_Poly(new byte[] { 1 });нужно локатор инициализировать не единичным полиномом, а полиномом-локатором, рассчитанным из известных позиций ошибок. И ещё изменить пару строчек. Весь код, напомню, есть на гитхабе: https://github.com/AV-86/Reed-Solomon-Demo/releases
Надеюсь материал в этой статье поможет тем, кто захочет в каком-нибудь своём проекте реализовать избыточное кодирование без сторонних библиотек. Просьба: Если что-то не понятно, не стесняйтесь комментировать. Постараюсь ответить на вопросы, или внести правки в статью.
4.2. Введение в коды Рида-Соломона: принципы, архитектура и реализация
Коды Рида-Соломона были предложены в 1960 году Ирвином Ридом (Irving S. Reed) и Густавом Соломоном (Gustave Solomon), являвшимися сотрудниками Линкольнской лаборатории МТИ. Ключом к использованию этой технологии стало изобретение эффективного алгоритма декодирования Элвином Беликамфом (Elwyn Berlekamp; http://en.wikipedia.org/wiki/Berlekamp-Massey_algorithm), профессором Калифорнийского университета (Беркли). Коды Рида-Соломона (см. также http://www.4i2i.com/reed_solomon_codes.htm) базируются на блочном принципе коррекции ошибок и используются в огромном числе приложений в сфере цифровых телекоммуникаций и при построении запоминающих устройств. Коды Рида-Соломона применяются для исправления ошибок во многих системах:
- устройствах памяти (включая магнитные ленты, CD, DVD, штриховые коды, и т.д.);
- беспроводных или мобильных коммуникациях (включая сотовые телефоны, микроволновые каналы и т.д.);
- спутниковых коммуникациях;
- цифровом телевидении / DVB (digital video broadcast);
- скоростных модемах, таких как ADSL, xDSL и т.д.
На
рис.
4.3 показаны практические приложения (дальние космические проекты) коррекции ошибок с использованием различных алгоритмов (Хэмминга, кодов свертки, Рида-Соломона и пр.). Данные и сам рисунок взяты из http://en.wikipedia.org/wiki/Reed-Solomon_error_correction.
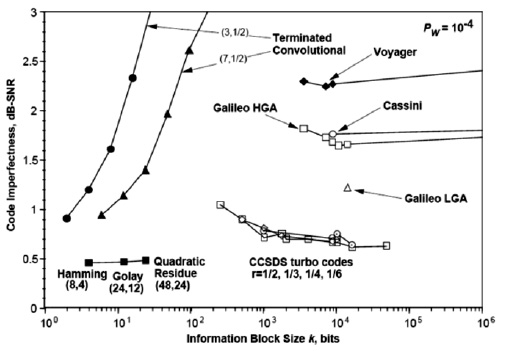
Рис.
4.3.
Несовершенство кода, как функция размера информационного блока для разных задач и алгоритмов
Типовая система представлена ниже (см. http://www.4i2i.com/reed_solomon_codes.htm)

Рис.
4.4.
Схема коррекции ошибок Рида-Соломона
Кодировщик Рида-Соломона берет блок цифровых данных и добавляет дополнительные «избыточные» биты. Ошибки происходят при передаче по каналам связи или по разным причинам при запоминании (например, из-за шума или наводок, царапин на CD и т.д.). Декодер Рида-Соломона обрабатывает каждый блок, пытается исправить ошибки и восстановить исходные данные. Число и типы ошибок, которые могут быть исправлены, зависят от характеристик кода Рида-Соломона.
Свойства кодов Рида-Соломона
Коды Рида-Соломона являются субнабором кодов BCH и представляют собой линейные блочные коды. Код Рида-Соломона специфицируются как RS(n,k) s -битных символов.
Это означает, что кодировщик воспринимает k информационных символов по s битов каждый и добавляет символы четности для формирования n символьного кодового слова. Имеется nk символов четности по s битов каждый. Декодер Рида-Соломона может корректировать до t символов, которые содержат ошибки в кодовом слове, где 2t = n–k.
Диаграмма, представленная ниже, показывает типовое кодовое слово Рида-Соломона:
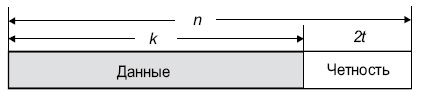
Рис.
4.5.
Структура кодового слова R-S
Пример. Популярным кодом Рида-Соломона является RS(255, 223) с 8-битными символами. Каждое кодовое слово содержит 255 байт, из которых 223 являются информационными и 32 байтами четности. Для этого кода
n = 255, k = 223, s = 8
2t = 32, t = 16
Декодер может исправить любые 16 символов с ошибками в кодовом слове: то есть ошибки могут быть исправлены, если число искаженных байт не превышает 16.
При размере символа s, максимальная длина кодового слова ( n ) для кода Рида-Соломона равна n = 2s – 1.
Например, максимальная длина кода с 8-битными символами ( s = 8 ) равна 255 байтам.
Коды Рида-Соломона могут быть в принципе укорочены путем обнуления некоторого числа информационных символов на входе кодировщика (передавать их в этом случае не нужно). При передаче данных декодеру эти нули снова вводятся в массив.
Пример. Код (255, 223), описанный выше, может быть укорочен до (200, 168). Кодировщик будет работать с блоком данных 168 байт, добавит 55 нулевых байт, сформирует кодовое слово (255, 223) и передаст только 168 информационных байт и 32 байта четности.
Объем вычислительной мощности, необходимой для кодирования и декодирования кодов Рида-Соломона, зависит от числа символов четности. Большое значение t означает, что большее число ошибок может быть исправлено, но это потребует большей вычислительной мощности по сравнению с вариантом при меньшем t.
Ошибки в символах
Одна ошибка в символе происходит, когда 1 бит символа оказывается неверным или когда все биты неверны.
Пример. Код RS(255,223) может исправить до 16 ошибок в символах. В худшем случае, могут иметь место 16 битовых ошибок в разных символах (байтах). В лучшем случае, корректируются 16 полностью неверных байт, при этом исправляется 16 x 8 = 128 битовых ошибок.
Коды Рида-Соломона особенно хорошо подходят для корректировки кластеров ошибок (когда неверными оказываются большие группы бит кодового слова, следующие подряд).
Декодирование
Алгебраические процедуры декодирования Рида-Соломона могут исправлять ошибки и потери. Потерей считается случай, когда положение неверного символа известно. Декодер может исправить до t ошибок или до 2t потерь. Данные о потере (стирании) могут быть получены от демодулятора цифровой коммуникационной системы, т.е. демодулятор помечает полученные символы, которые вероятно содержат ошибки.
Когда кодовое слово декодируется, возможны три варианта.
- Если 2s + r < 2t ( s ошибок, r потерь), тогда исходное переданное кодовое слово всегда будет восстановлено. В противном случае
- Декодер детектирует ситуацию, когда он не может восстановить исходное кодовое слово. или
- Декодер некорректно декодирует и неверно восстановит кодовое слово без какого-либо указания на этот факт.
Вероятность каждого из этих вариантов зависит от типа используемого кода Рида-Соломона, а также от числа и распределения ошибок.
8.1.1. Вероятность появления ошибок для кодов Рида-Соломона
8.1.2. Почему коды Рида-Соломона эффективны при борьбе c импульсными помехами
8.1.3. Рабочие характеристики кода Рида-Соломона как функция размера, избыточности и степени кодирования
8.1.4. Конечные поля
8.1.4.1.Операция сложения в поле расширения GF(2m)
8.1.4.2. Описание конечного поля с помощью примитивного полинома
8.1.4.3. Поле расширения GF(23)
8.1.4.4. Простой тест для проверки полинома на примитивность
8.1.5. Кодирование Рида-Соломона
8.1.5.1. Кодирование в систематической форме
8.1.5.2. Систематическое кодирование с помощью (n-k)-разрядного регистра сдвига
8.1.6. Декодирование Рида-Соломона
8.1.6.1. Вычисление синдрома
8.1.6.2. Локализация ошибки
8.1.6.3. Значения ошибок
8.1.6.4. Исправление принятого полинома с помощью найденного полинома ошибок
Коды Рида-Соломона (Reed-Solomon code, R-S code) — это недвоичные циклические коды, символы которых представляют собой m-битовые последовательности, где т—положительное целое число, большее 2. Код (n, K) определен на m-битовых символах при всех п и k, для которых
![]() (8.1)
(8.1)
где k — число информационных битов, подлежащих кодированию, а n — число кодовых символов в кодируемом блоке. Для большинства сверточных кодов Рида-Соломона (n,k)
![]() (8.2)
(8.2)
где t — количество ошибочных битов в символе, которые может исправить код, а и ![]() — число контрольных символов. Расширенный код Рида-Соломона можно получить при
— число контрольных символов. Расширенный код Рида-Соломона можно получить при ![]() , но не более того.
, но не более того.
Код Рида-Соломона обладает наибольшим минимальным расстоянием, возможным для линейного кода с одинаковой длиной входных и выходных блоков кодера. Для недвоичных кодов расстояние между двумя кодовыми словами определяется (по аналогии с расстоянием Хэмминга) как число символов, которыми отличаются последовательности. Для кодов Рида-Соломона минимальное расстояние определяется следующим образом [1].
![]() (8.3)
(8.3)
Код, который исправляет все искаженные символы, содержащие ошибку в t или меньшем числе бит, где t приведено в уравнении (6.44), можно выразить следующим образом.
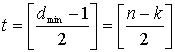 (8.4)
(8.4)
Здесь [x] означает наибольшее целое, не превышающее х. Из уравнения (8.4) видно, что коды Рида-Соломона, исправляющие t символьных ошибок, требуют не более 2t контрольных символов. Из уравнения (8.4) следует, что декодер имеет п-k «используемых» избыточных символов, количество которых вдвое превышает количество исправляемых ошибок. Для каждой ошибки один избыточный символ используется для обнаружения ошибки и один — для определения правильного значения. Способность кода к коррекции стираний выражается следующим образом.
![]() (8.5)
(8.5)
Возможность одновременной коррекции ошибок и стираний можно выразить как требование.
![]() (8.6)
(8.6)
Здесь ![]() — число символьных ошибочных комбинаций, которые можно исправить, а
— число символьных ошибочных комбинаций, которые можно исправить, а ![]() — количество комбинаций символьных стираний, которые могут быть исправлены. Преимущества недвоичных кодов, подобных кодам Рида-Соломона, можно увидеть в следующем сравнении. Рассмотрим двоичный код (п, k) = (7, 3). Полное пространство n-кортежей содержит
— количество комбинаций символьных стираний, которые могут быть исправлены. Преимущества недвоичных кодов, подобных кодам Рида-Соломона, можно увидеть в следующем сравнении. Рассмотрим двоичный код (п, k) = (7, 3). Полное пространство n-кортежей содержит ![]() n-кортежей, из которых
n-кортежей, из которых ![]() (или 1/16 часть всех n-кортежей) являются кодовыми словами. Затем рассмотрим недвоичный код (n, k)=(7, 3), где каждый символ состоит из т = 3 бит. Пространство n-кортежей содержит
(или 1/16 часть всех n-кортежей) являются кодовыми словами. Затем рассмотрим недвоичный код (n, k)=(7, 3), где каждый символ состоит из т = 3 бит. Пространство n-кортежей содержит ![]() 2 097 152 n-кортежа, из которых
2 097 152 n-кортежа, из которых ![]() (или 1/4096 часть всех n-кортежей) являются кодовыми словами. Если операции производятся над недвоичными символами, каждый из которых образован т битами, то только незначительная часть (т.е.
(или 1/4096 часть всех n-кортежей) являются кодовыми словами. Если операции производятся над недвоичными символами, каждый из которых образован т битами, то только незначительная часть (т.е. ![]() из большого числа
из большого числа ![]() ) возможных n-кортежей является кодовыми словами. Эта часть уменьшается с ростом т. Здесь важным является то, что если в качестве кодовых слов используется незначительная часть пространства n-кортежей, то можно достичь большего
) возможных n-кортежей является кодовыми словами. Эта часть уменьшается с ростом т. Здесь важным является то, что если в качестве кодовых слов используется незначительная часть пространства n-кортежей, то можно достичь большего ![]() .
.
Любой линейный код дает возможность исправить n—k комбинаций символьных стираний, если все n—k стертых символов приходятся на контрольные символы. Однако коды Рида-Соломона имеют замечательное свойство, выражающееся в том, что они могут исправить любой набор п-k символов стираний в блоке. Можно сконструировать коды с любой избыточностью. Впрочем, с увеличением избыточности растет сложность ее высокоскоростной реализации. Поэтому наиболее привлекательные коды Рида-Соломона обладают высокой степенью кодирования (низкой избыточностью).
8.1.1. Вероятность появления ошибок для кодов Рида-Соломона
Коды Рида-Соломона чрезвычайно эффективны для исправления пакетов ошибок, т.е. они оказываются эффективными в каналах с памятью. Также они хорошо зарекомендовали себя в каналах с большим набором входных символов. Особенностью кода Рида-Соломона является, то, что к коду длины n можно добавить два информационных символа, не уменьшая при этом минимального расстояния. Такой расширенный код имеет длину п + 2 и то же количество символов контроля четности, что и исходный код. Из уравнения (6.46) вероятность появления ошибки в декодированном символе, РЕ, можно записать через вероятность появления ошибки в канальном символе, ![]() .
.
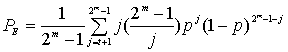 (8.7)
(8.7)
Здесь t — количество ошибочных битов в символе, которые может исправить код, а символы содержат т битов каждый.
Для некоторых типов модуляции вероятность битовой ошибки можно ограничить сверху вероятностью символьной ошибки. Для модуляции MFSK с М=![]() связь РВи РЕвыражается формулой (4.112).
связь РВи РЕвыражается формулой (4.112).
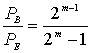 (8.8)
(8.8)
На рис. 8.1 показана зависимость ![]() от вероятности появления ошибки в канальном символе p, полученная из уравнений (8,7) и (8.8) для различных ортогональных 32-ричных кодов Рида-Соломона с возможностью коррекции t ошибочных бит в символе и n = 31 (тридцать один 5-битовый символ в кодовом блоке). На рис.8.2 показана зависимость
от вероятности появления ошибки в канальном символе p, полученная из уравнений (8,7) и (8.8) для различных ортогональных 32-ричных кодов Рида-Соломона с возможностью коррекции t ошибочных бит в символе и n = 31 (тридцать один 5-битовый символ в кодовом блоке). На рис.8.2 показана зависимость ![]() от
от ![]() /N0 для таких систем кодирования при использовании модуляции MFSK и некогерентной демодуляции в канале AWGN [2]. Для кодов Рида-Соломона вероятность появления ошибок является убывающей степенной функцией длины блока, n, а сложность декодирования пропорциональна небольшой степени длины блока [1]. Иногда коды Рида-Соломона применяются в каскадных схемах. В таких системах внутренний сверточный декодер сначала осуществляет некоторую защиту от ошибок за счет мягкой схемы решений на выходе демодулятора; затем сверточный декодер передает данные, оформленные согласно жесткой схеме, на внешний декодер Рида-Соломона, что снижает вероятность появления ошибок. В разделах 8.2.3 и 8.3 мы рассмотрим каскадное декодирование и декодирование Рида-Соломона на примере системы цифровой записи данных на аудиокомпакт-дисках (compact disc — CD).
/N0 для таких систем кодирования при использовании модуляции MFSK и некогерентной демодуляции в канале AWGN [2]. Для кодов Рида-Соломона вероятность появления ошибок является убывающей степенной функцией длины блока, n, а сложность декодирования пропорциональна небольшой степени длины блока [1]. Иногда коды Рида-Соломона применяются в каскадных схемах. В таких системах внутренний сверточный декодер сначала осуществляет некоторую защиту от ошибок за счет мягкой схемы решений на выходе демодулятора; затем сверточный декодер передает данные, оформленные согласно жесткой схеме, на внешний декодер Рида-Соломона, что снижает вероятность появления ошибок. В разделах 8.2.3 и 8.3 мы рассмотрим каскадное декодирование и декодирование Рида-Соломона на примере системы цифровой записи данных на аудиокомпакт-дисках (compact disc — CD).
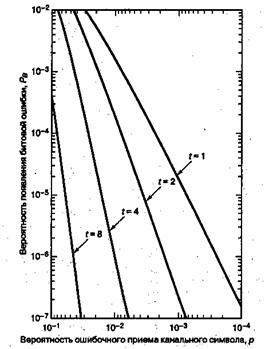
Рис. 8.1. Зависимость Рв от р для различных ортогональных 32-ринных кодов Рида-Соломона с возможностью коррекции t бит в символе и п = 31.(Перепечатано с разрешения автора из Data Communications, Network, and Systems, ed. Thomas C, Bartee, Howard W. Sams Company,Indianapolis,Ind., 1985, p. 311. Ранее публиковалось в J. P. Odenwalder, Error Control Coding Handbook, M/A-COM LINKABIT, Inc., San Diego, Calif., . ./ — . July,15, 1976,p.
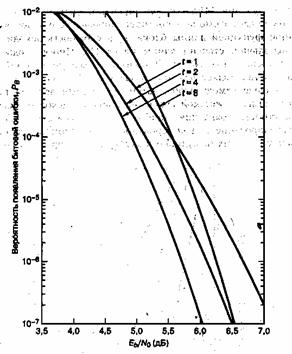
Рис. 8.2. Зависимость рв от Et/NQ для различных ортогональных кодов Рида-Соломона с возможностью коррекции t бит в символе и п = 31, при 32-ринной модуляции MFSK в канале AWGN. (Перепечатано с разрешения автора из Data Communications, Network, and Systems, ed. Thomas C. Bartee, Howard W. Sams Company, Indianapolis, Ind.f 1985, p. 312. Ранее публиковалось в J. P. Odenwalder, Error Control Coding Handbook, M/A-COM LINKABIT, Inc., San Diego, Calif., July, 15, 1976, p. 92.)
8.1.2. Почему коды Рида-Соломона эффективны при борьбе с импульсными помехами
Давайте рассмотрим код (n, k) = (255, 247), в котором каждый символ состоит из т = 8 бит (такие символы принято называть байтами). Поскольку п-k=8, из уравнения (8.4) можно видеть, что этот код может исправлять любые 4-символьные ошибки в блоке длиной до 255. Пусть блок длительностью 25 бит в ходе передачи поражается помехами, как показано на рис. 8.3. В этом примере пакет шума, который попадает на 25 последовательных битов, исказит точно 4 символа. Декодер для кода (255, 247) исправит любые 4-символьные ошибки без учета характера повреждений, причиненных символу. Другими словами, если декодер исправляет байт (заменяет неправильный правильным), то ошибка может быть вызвана искажением одного или всех восьми битов. Поэтому, если символ неправильный, он может быть искажен на всех двоичных позициях. Это дает коду Рида-Соломона огромное преимущество при наличии импульсных помех по сравнению с двоичными кодами (даже при использовании в двоичном коде чередования). В этом примере, если наблюдается 25-битовая случайная помеха, ясно, что искаженными могут оказаться более чем 4 символа (искаженными могут оказаться до 25 символов). Конечно, исправление такого числа ошибок окажется вне возможностей кода (255, 247).
8.1.3. Рабочие характеристики кода Рида-Соломона как функция размера, избыточности и степени кодирования
Для того чтобы код успешно противостоял шумовым эффектам, длительность помех должна составлять относительно небольшой процент от количества кодовых слов. Чтобы быть уверенным, что так будет большую часть времени, принятый шум необходимо усреднить за большой промежуток времени, что снизит эффект от неожиданной или необычной полосы плохого приема. Следовательно, можно предвидеть, что код с коррекцией ошибок будет более эффективен (повысится надежность передачи) при увеличении размера передаваемого блока, что делает код Рида-Соломона более привлекательным, если желательна большая длина блока [3]. Это можно оценить по семейству кривых, показанному на рис. 8.4, где степей кодирования взята равной 7/8, при этом длина блока возрастает с n = 32 символов (при w = 5 бит на символ) до n=256 символов (при n=8 бит на символ). Таким образом, размер блока возрастает с 160 бит до 2048 бит.
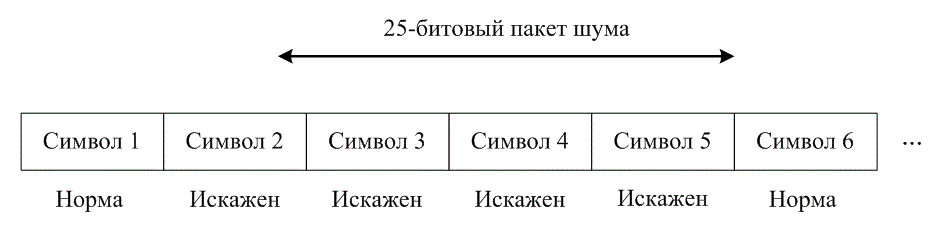
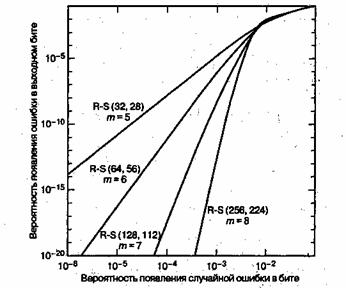
Рис. 8.4. Характеристики декодера Рида-Соломона как функция размера символов (степень кодирования = 7/8)
По мере увеличения избыточности кода (и снижения его степени кодирования), сложность реализации этого кода повышается (особенно для высокоскоростных устройств). При этом для систем связи реального времени должна увеличиться ширина полосы пропускания. Увеличение избыточности, например увеличение размера символа, приводит к уменьшению вероятности появления битовых ошибок, как можно видеть на рис. 8.5, еще кодовая длина п равна постоянному значению 64 при снижении числа символов данных с k = 60 до k = 4 (избыточность возрастает с 4 до 60символов).
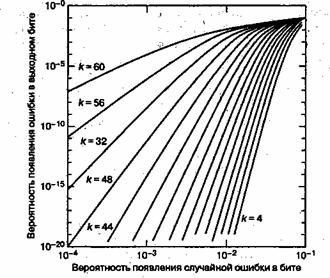
Рис. 8.5. Характеристики декодера Рида-Соломона (64, k) как функция избыточности
На рис. 8.5 показана передаточная функция (выходная вероятность появлений битовой ошибки, зависящая от входной вероятности появления символьной ошибки) гипотетических декодеров. Поскольку здесь не имеется в виду определенная система или канал (лишь вход-выход декодера), можно заключить, что надежность передачи является монотонной функцией избыточности и будет неуклонно возрастать с приближением степени кодирования к нулю. Однако это не так для кодов, используемых в системах связи реального времени. По мере изменения степени кодирования кода от максимального значения до минимального (от 0 до 1), интересно было бы понаблюдать за эффектами, показанными на рис. 8.6. Здесь кривые рабочих характеристик показаны при модуляции BPSK и кодах (31, к) для разных типов каналов. На рис. 8.6 показаны системы связи реального времени, в которых за кодирование с коррекцией ошибок приходится платить расширением полосы пропускания, пропорциональным величине, равной обратной степени кодирования. Приведенные кривые показывают четкий оптимум степени кодирования, минимизирующий требуемое значение ![]() [4]. Для гауссова канала оптимальное значение степени кодирования находится где-то между 0,6 и 0,7, для канала с райсовским замиранием — около 0,5 (с отношением мощности прямого сигнала к мощности отраженного К = 7 дБ) и 0,3 — для канала с релеевским замиранием. (Каналы с замиранием будут рассматриваться в главе 15.) Почему здесь как при очень высоких степенях кодирования (малой избыточности), так и при очень низких (значительной избыточности) наблюдается ухудшение
[4]. Для гауссова канала оптимальное значение степени кодирования находится где-то между 0,6 и 0,7, для канала с райсовским замиранием — около 0,5 (с отношением мощности прямого сигнала к мощности отраженного К = 7 дБ) и 0,3 — для канала с релеевским замиранием. (Каналы с замиранием будут рассматриваться в главе 15.) Почему здесь как при очень высоких степенях кодирования (малой избыточности), так и при очень низких (значительной избыточности) наблюдается ухудшение ![]() ? Для высоких степеней кодирования это легко объяснить, сравнивая высокие степени кодирования с оптимальной степенью кодирования. Любой код в целом обеспечивает все преимущества кодирования; следовательно, как только степень кодирования приближается к единице (нет кодирования), система проигрывает в надежности передачи. Ухудшение характеристик при низких степенях кодирования является более тонким вопросом, поскольку в системах связи реального времени используется и модуляция, и кодирование, т.е. работает два механизма. Один механизм направлен на снижение вероятности появления ошибок, другой повышает ее. Механизм, снижающий вероятность появления ошибки, — это кодирование; чем больше избыточность, тем больше возможности кода в коррекции ошибок. Механизм, повышающий эту вероятность, — это снижение энергии, приходящейся на канальный символ (по сравнению с информационным символом), что следует из увеличения избыточности (и более быстрой передачи сигналов в системах связи реального времени). Уменьшенная энергия символа вынуждает демодулятор совершать больше ошибок. В конечном счете второй механизм подавляет первый, поэтому очень низкие степени кодирования вызывают ухудшение характеристик кода.
? Для высоких степеней кодирования это легко объяснить, сравнивая высокие степени кодирования с оптимальной степенью кодирования. Любой код в целом обеспечивает все преимущества кодирования; следовательно, как только степень кодирования приближается к единице (нет кодирования), система проигрывает в надежности передачи. Ухудшение характеристик при низких степенях кодирования является более тонким вопросом, поскольку в системах связи реального времени используется и модуляция, и кодирование, т.е. работает два механизма. Один механизм направлен на снижение вероятности появления ошибок, другой повышает ее. Механизм, снижающий вероятность появления ошибки, — это кодирование; чем больше избыточность, тем больше возможности кода в коррекции ошибок. Механизм, повышающий эту вероятность, — это снижение энергии, приходящейся на канальный символ (по сравнению с информационным символом), что следует из увеличения избыточности (и более быстрой передачи сигналов в системах связи реального времени). Уменьшенная энергия символа вынуждает демодулятор совершать больше ошибок. В конечном счете второй механизм подавляет первый, поэтому очень низкие степени кодирования вызывают ухудшение характеристик кода.
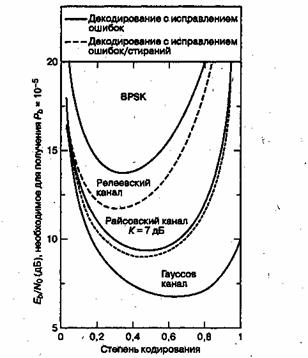
Рис. 8.6. Характеристики декодера Рида-Соломона (31, k) как функция степени кодирования (модуляция BPSK)
Давайте попробуем подтвердить зависимость вероятности появления ошибок от степени кодирования, показанную на рис. 8.6, с помощью кривых, изображенных на рис. 8.2. Непосредственно сравнить рисунки не удастся, поскольку на рис. 8.6 применяется модуляция BPSK, а на рис. 8.2 — 32-ричная модуляция MFSK. Однако, пожалуй, нам удастся показать, что зависимость характеристик кода Рида-Соломона от его степени кодирования выглядит одинаково как при BPSK, так и при MFSK. На рис. 8.2 вероятность появления ошибки в канале AWGN снижается при увеличении способности кода t к коррекции символьных ошибок с t = 1 до t = 4; случаи t = 1 и t = 4 относятся к кодам (31, 29) и (31,23) со степенями кодирования 0,94 и 0,74. Хотя при t = 8, что отвечает коду (31,15) со степенью кодирования 0,48, достоверность передачи ![]() достигается при примерно на 0,5 дБ большем отношении
достигается при примерно на 0,5 дБ большем отношении ![]() , по сравнению со случаем t = 4. Из рис. 8.2 можно сделать вывод, что если нарисовать график зависимости достоверности передачи от степени кодирования кода, то кривая будет иметь вид, подобный приведенному на рис. 8.6. Заметим, что это утверждение нельзя получить из рис. 8.1, поскольку там представлена передаточная функция декодера, которая несет в себе сведения о канале и демодуляции. Поэтому из двух механизмов, работающих в канале, передаточная функция (рис. 8.1) представляет только выгоды, которые проявляются на входе/выходе декодера, и ничего не говорит о потерях энергии как функции низкой степени кодирования.
, по сравнению со случаем t = 4. Из рис. 8.2 можно сделать вывод, что если нарисовать график зависимости достоверности передачи от степени кодирования кода, то кривая будет иметь вид, подобный приведенному на рис. 8.6. Заметим, что это утверждение нельзя получить из рис. 8.1, поскольку там представлена передаточная функция декодера, которая несет в себе сведения о канале и демодуляции. Поэтому из двух механизмов, работающих в канале, передаточная функция (рис. 8.1) представляет только выгоды, которые проявляются на входе/выходе декодера, и ничего не говорит о потерях энергии как функции низкой степени кодирования.
8.1.4. Конечные поля
Для понимания принципов кодирования и декодирования недвоичных кодов, таких как коды Рида-Соломона, нужно сделать экскурс в понятие конечных полей, известных как поля Галуа (Galois fields — GF). Для любого простого числа p существует конечное поле, которое обозначается GF(p) и содержит p элементов. Понятие GF(p) можно обобщить на поле из ![]() элементов, именуемое полем расширения GF(p); это поле обозначается GF(
элементов, именуемое полем расширения GF(p); это поле обозначается GF(![]() ), где т — положительное целое число. Заметим, что GF(
), где т — положительное целое число. Заметим, что GF(![]() ) содержит в качестве подмножества все элементы GF(p). Символы из поля расширения GF(
) содержит в качестве подмножества все элементы GF(p). Символы из поля расширения GF(
) используются при построении кодов Рида-Соломона.
Двоичное поле GF(2) является подполем поля расширения GF(![]() ), точно так же как поле вещественных чисел является подполем поля комплексных чисел. Кроме чисел 0 и 1, в поле расширения существуют дополнительные однозначные элементы, которые будут представлены новым символом а. Каждый ненулевой элемент в GF(
), точно так же как поле вещественных чисел является подполем поля комплексных чисел. Кроме чисел 0 и 1, в поле расширения существуют дополнительные однозначные элементы, которые будут представлены новым символом а. Каждый ненулевой элемент в GF(![]() ) можно представить как степень
) можно представить как степень ![]() . Бесконечное множество элементов, F, образуется из стартового множества
. Бесконечное множество элементов, F, образуется из стартового множества ![]() и генерируется дополнительными элементами путем последовательного умножения последней записи на
и генерируется дополнительными элементами путем последовательного умножения последней записи на ![]() .
.
![]() (8.9)
(8.9)
Для вычисления из F конечного множества элементов GF(![]() ) на F нужно наложить условия: оно может содержать только
) на F нужно наложить условия: оно может содержать только ![]() элемента и быть замкнутым относительно операции умножения. Условие замыкания множества элементов поля по отношению к операции умножения имеет вид неприводимого полинома.
элемента и быть замкнутым относительно операции умножения. Условие замыкания множества элементов поля по отношению к операции умножения имеет вид неприводимого полинома.
![]() (8.9)
(8.9)
или, что тоже самое,
![]() (8.10)
(8.10)
С помощью полиномиального ограничения любой элемент со степенью, большей или равной ![]() , можно следующим образом понизить до элемента со степенью, меньшей
, можно следующим образом понизить до элемента со степенью, меньшей ![]() .
.
![]() (8.11)
(8.11)
Таким образом, как показано ниже, уравнение (8.10) можно использовать для формирования конечной последовательности F* из бесконечной последовательности F.
![]() (8.12)
(8.12)
Следовательно, из уравнения (8.12) можно видеть, что элементы конечного поля GF(![]() ) даются следующим выражением.
) даются следующим выражением.
![]() (8.13)
(8.13)
8.1.4.1. Операция сложения в поле расширения GF(2m)
Каждый из ![]() элементов конечного поля GF(
элементов конечного поля GF(![]() ) можно представить как отдельный полином степени от m-1 или меньше. Степенью полинома называется степень члена максимального порядка. Обозначим каждый ненулевой элемент GF(
) можно представить как отдельный полином степени от m-1 или меньше. Степенью полинома называется степень члена максимального порядка. Обозначим каждый ненулевой элемент GF(![]() ) полиномом
) полиномом ![]() , в котором последние т коэффициентов
, в котором последние т коэффициентов ![]() нулевые. Для
нулевые. Для ![]() ,
,
![]() (8.14)
(8.14)
Рассмотрим случай m = 3, в котором конечное поле обозначается GF(23). На рис. 8.7 показано отображение семи элементов {![]() } и нулевого элемента в слагаемые базисных элементов
} и нулевого элемента в слагаемые базисных элементов ![]() , описываемых уравнением (8.14). Поскольку из уравнения (8.10)
, описываемых уравнением (8.14). Поскольку из уравнения (8.10) ![]() , в этом поле имеется семь ненулевых элементов или всего восемь элементов. Каждая строка на рис. 8.7 содержит последовательность двоичных величин, представляющих коэффициенты
, в этом поле имеется семь ненулевых элементов или всего восемь элементов. Каждая строка на рис. 8.7 содержит последовательность двоичных величин, представляющих коэффициенты ![]() ,
, ![]() и
и ![]() из уравнения (8.14). Одним из преимуществ использования элементов
из уравнения (8.14). Одним из преимуществ использования элементов ![]() поля расширения, вместо двоичных элементов, является компактность записи, что оказывается удобным при математическом описании процессов недвоичного кодирования и декодирования. Сложение двух элементов конечного поля, следовательно, определяется как суммирование по модулю 2 всех коэффициентов при элементах одинаковых степеней.
поля расширения, вместо двоичных элементов, является компактность записи, что оказывается удобным при математическом описании процессов недвоичного кодирования и декодирования. Сложение двух элементов конечного поля, следовательно, определяется как суммирование по модулю 2 всех коэффициентов при элементах одинаковых степеней.
![]() (8.15)
(8.15)
8.1.4.2. Описание конечного поля с помощью примитивного полинома
Класс полиномов, называемых примитивными полиномами, интересует нас, поскольку такие объекты определяют конечные поля GF(![]() ), которые, в свою очередь, нужны для описания кодов Рида-Соломона. Следующее утверждение является необходимым и достаточным условием примитивности полинома. Неприводимый полином f(X) порядка т будет примитивным, если наименьшим положительным целым числом п, для которого
), которые, в свою очередь, нужны для описания кодов Рида-Соломона. Следующее утверждение является необходимым и достаточным условием примитивности полинома. Неприводимый полином f(X) порядка т будет примитивным, если наименьшим положительным целым числом п, для которого ![]() делится на f(X), будет
делится на f(X), будет ![]() . Заметим, что неприводимый полином — это такой полином, который нельзя представить в виде произведения полиномов меньшего порядка; делимость А на В означает, что А делится на В с нулевым остатком и ненулевым частным. Обычно полином записывают в порядке возрастания степеней. Иногда более удобным является обратный формат записи (например, при выполнении полиномиального деления).
. Заметим, что неприводимый полином — это такой полином, который нельзя представить в виде произведения полиномов меньшего порядка; делимость А на В означает, что А делится на В с нулевым остатком и ненулевым частным. Обычно полином записывают в порядке возрастания степеней. Иногда более удобным является обратный формат записи (например, при выполнении полиномиального деления).
|
Образующие элементы |
||||
|
Элементы поля |
|
|
|
|
|
0 |
0 |
0 |
0 |
|
|
|
1 |
0 |
0 |
|
|
|
0 |
1 |
0 |
|
|
|
0 |
0 |
1 |
|
|
|
1 |
1 |
0 |
|
|
|
0 |
1 |
1 |
|
|
|
1 |
1 |
1 |
|
|
|
1 |
0 |
1 |
|
|
|
1 |
0 |
0 |
Рис. 8.7. Отображение элементов поля в базисные элементы GF(8) с помощью ![]()
Пример 8.1. Проверка полинома на примитивность
Основываясь на предыдущем определении примитивного полинома, укажите, какие из следующих неприводимых полиномов будут примитивными.
а) ![]()
б) ![]()
Решение
а) Мы можем проверить этот полином порядка т = 4, определив, будет ли он делителем ![]() для значений п из диапазона 1 < n < 15. Нетрудно убедиться, что
для значений п из диапазона 1 < n < 15. Нетрудно убедиться, что ![]() + 1 делится на
+ 1 делится на ![]() (см. раздел 6.8.1), и после повторения вычислений можно проверить, что при любых значениях п из диапазона 1<n<15 полином
(см. раздел 6.8.1), и после повторения вычислений можно проверить, что при любых значениях п из диапазона 1<n<15 полином ![]() +1 не делится на
+1 не делится на ![]() . Следовательно,
. Следовательно, ![]() является примитивным полиномом.
является примитивным полиномом.
б) Легко проверить, что полином является делителем ![]() . Проверив, делится ли
. Проверив, делится ли ![]() на
на ![]() , для значений n, меньших 15, можно также видеть, что указанный полином является делителем Xs+1. Следовательно, несмотря на то что полином
, для значений n, меньших 15, можно также видеть, что указанный полином является делителем Xs+1. Следовательно, несмотря на то что полином ![]() является неприводимым, он не будет примитивным.
является неприводимым, он не будет примитивным.
8.1.4.3. Поле расширения GF(23)
Рассмотрим пример, в котором будут задействованы примитивный полином и конечное поле, которое он определяет. В табл. 8.1 содержатся примеры некоторых примитивных полиномов. Мы выберем первый из указанных там полиномов, ![]() , который определяет конечное поле GF(
, который определяет конечное поле GF(![]() ), где степень полинома т=3. Таким образом, в поле, определяемом полиномом f(Х), имеется 2m = 23 = 8 элементов. Поиск корней полинома f(Х) — это поиск таких значений X, при которых
), где степень полинома т=3. Таким образом, в поле, определяемом полиномом f(Х), имеется 2m = 23 = 8 элементов. Поиск корней полинома f(Х) — это поиск таких значений X, при которых ![]() . Привычные нам двоичные элементы 0 и 1 не подходят полиному
. Привычные нам двоичные элементы 0 и 1 не подходят полиному ![]() (они не являются корнями), поскольку
(они не являются корнями), поскольку ![]() (в рамках операции по модулю 2). Кроме того, основная теорема алгебры утверждает, что полином порядка m должен иметь в точности m корней. Следовательно, в этом примере выражение
(в рамках операции по модулю 2). Кроме того, основная теорема алгебры утверждает, что полином порядка m должен иметь в точности m корней. Следовательно, в этом примере выражение ![]() должно иметь 3 корня. Возникает определенная проблема, поскольку 3 корня не лежат в одном конечном поле, что и коэффициенты f(X). А если они находятся где-то еще, то, наверняка, в поле расширения
должно иметь 3 корня. Возникает определенная проблема, поскольку 3 корня не лежат в одном конечном поле, что и коэффициенты f(X). А если они находятся где-то еще, то, наверняка, в поле расширения ![]() . Пусть,
. Пусть, ![]() , элемент поля расширения, определяется как корень полинома f(X). Следовательно, можно записать следующее.
, элемент поля расширения, определяется как корень полинома f(X). Следовательно, можно записать следующее.
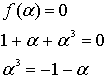 (8.16)
(8.16)
Поскольку при операциях над двоичным полем +1=-1, то ![]() можно представить следующим образом.
можно представить следующим образом.
![]() (8.17)
(8.17)
Таблица 8.1. Некоторые примитивные полиномы
|
m |
m |
||
|
3 |
|
14 |
|
|
4 |
|
15 |
|
|
5 |
|
16 |
|
|
6 |
|
17 |
|
|
7 |
|
18 |
|
|
8 |
|
19 |
|
|
9 |
|
20 |
|
|
10 |
|
21 |
|
|
11 |
|
22 |
|
|
12 |
|
23 |
|
|
13 |
|
24 |
|
Таким образом, ![]() представляется в виде взвешенной суммы всех
представляется в виде взвешенной суммы всех ![]() — членов более низкого порядка. Фактически так можно представить все степени
— членов более низкого порядка. Фактически так можно представить все степени ![]() . Например, рассмотрим следующее.
. Например, рассмотрим следующее.
![]() (8.18,а)
(8.18,а)
А теперь взглянем на следующий случай.
![]() (8.18,б)
(8.18,б)
Из уравнений (8.17) и (8.18), получаем следующее.
Из уравнений (8.17) и (8.18), получаем следующее.
![]() (8.18,в)
(8.18,в)
Из уравнений (8.17) и (8.18), получаем следующее.
![]() (8.18,г)
(8.18,г)
А теперь из уравнения (8.18,г) вычисляем
![]() (8.18,д)
(8.18,д)
Заметим, что ![]() и, следовательно, восьмью элементами конечного поля GF(
и, следовательно, восьмью элементами конечного поля GF(![]() ) ,будут
) ,будут
![]() (8.19)
(8.19)
Отображение элементов поля в базисные элементы, короче описывается уравнением (8.14), можно проиллюстрировать с помощью схемы линейного регистра сдвига с обратной связью (linear feedback shift register – LFSR) (рис 8.8). Схема генерирует (при m = 3) ![]() ненулевых элементов поля и, таким образом, обобщает процедуры, описанные в уравнениях (8.17) – (8.19). Следует отметить, что показанная на рис. 8.8. обратная связь соответствует коэффициентам полинома
ненулевых элементов поля и, таким образом, обобщает процедуры, описанные в уравнениях (8.17) – (8.19). Следует отметить, что показанная на рис. 8.8. обратная связь соответствует коэффициентам полинома ![]() , как и в случае двоичных циклических кодов (см. раздел 6.7.5.). Пусть вначале схема находится в некотором состоянии, например 1 0 0; при выполнении правого сдвига на один такт можно убедиться, что каждый из элементов поля (за исключением нулевого), показанных на рис.8.7, циклически будет появляться в разрядах регистра сдвига. На данном конечном поле GF(
, как и в случае двоичных циклических кодов (см. раздел 6.7.5.). Пусть вначале схема находится в некотором состоянии, например 1 0 0; при выполнении правого сдвига на один такт можно убедиться, что каждый из элементов поля (за исключением нулевого), показанных на рис.8.7, циклически будет появляться в разрядах регистра сдвига. На данном конечном поле GF(![]() ) можно определить две арифметические операции – сложение и умножение. В таб. 8.2. показана операция сложения, а в таб. 8.3. – операция умножения, но только для ненулевых элементов. Правила суммирования следуют из уравнений (8.17) и (8.18,д); и их можно рассчитать путем сложения (по модулю 2) соответствующих коэффициентов из базисных элементов. Правила умножения, указанные в табл. 8.3, следуют из обычной процедуры, в которой произведение элементов поля вычисляются путем сложения по модулю
) можно определить две арифметические операции – сложение и умножение. В таб. 8.2. показана операция сложения, а в таб. 8.3. – операция умножения, но только для ненулевых элементов. Правила суммирования следуют из уравнений (8.17) и (8.18,д); и их можно рассчитать путем сложения (по модулю 2) соответствующих коэффициентов из базисных элементов. Правила умножения, указанные в табл. 8.3, следуют из обычной процедуры, в которой произведение элементов поля вычисляются путем сложения по модулю ![]() их показателей степеней или, для данного случая, по модулю 7.
их показателей степеней или, для данного случая, по модулю 7.
Таблица 8.2. Таблица сложения для GF(8) при ![]()
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
0 |
Таблица 8.3. Таблица умножения для GF(8) при ![]()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
8.1.4.4. Простой тест для проверки полинома на примитивность
Существует еще один, чрезвычайно простой способ проверки, является ли полином примитивным. У неприводимого полинома, который является примитивным, по крайней мере, хотя бы один из корней должен быть примитивным элементом. Примитивным элементом называется такой элемент поля, который, будучи возведенным в более высокие степени, даст ненулевые элементы поля. Поскольку данное поле является конечным, количество таких элементов также конечно.
Пример 8.2. Примитивный полином должен иметь, по крайней мере, хотя бы один примитивный элемент.
Найдите m = 3 корня полинома ![]() и определите, примитивен ли полином. Для этого проверьте, имеется ли среди корней полинома хотя бы один примитивный элемент. Каковы корни полинома? Какие из них примитивны?
и определите, примитивен ли полином. Для этого проверьте, имеется ли среди корней полинома хотя бы один примитивный элемент. Каковы корни полинома? Какие из них примитивны?
Решение
Корни будут найдены прямым перебором. Итак, ![]() не будет корнем, поскольку
не будет корнем, поскольку ![]() .Теперь, чтобы проверить, является ли корнем
.Теперь, чтобы проверить, является ли корнем ![]() , воспользуемся табл. 8.2. Поскольку
, воспользуемся табл. 8.2. Поскольку ![]() , значит,
, значит, ![]() будет корнем полинома. Далее проверим, будет ли корнем
будет корнем полинома. Далее проверим, будет ли корнем ![]() .
.![]() Значит, и
Значит, и ![]() также будет корнем полинома. Теперь проверим
также будет корнем полинома. Теперь проверим ![]() .
. ![]() Следовательно,
Следовательно, ![]() корнем полинома не является. Будет ли корнем
корнем полинома не является. Будет ли корнем ![]() ?
? ![]() Да,
Да, ![]() будет корнем полинома. Значит, корнями полинома
будет корнем полинома. Значит, корнями полинома ![]() будут
будут ![]() . Нетрудно убедиться, что, последовательно возводя в степень любой из этих корней, можно получить все 7 ненулевых элементов поля. Таким образом, все корни будут примитивными элементами. Поскольку в определении требуется, чтобы по крайней мере один из корней был примитивным, полином является примитивным.
. Нетрудно убедиться, что, последовательно возводя в степень любой из этих корней, можно получить все 7 ненулевых элементов поля. Таким образом, все корни будут примитивными элементами. Поскольку в определении требуется, чтобы по крайней мере один из корней был примитивным, полином является примитивным.
В этом примере описан относительно простой метод проверки полинома на примитивность. Для проверяемого полинома нужно составить регистр LFSR с контуром обратной связи, соответствующий коэффициентам полинома, как показана на рис. 8.8. Затем в схему регистра следует загрузить любое ненулевое состояние и выполнить за каждый такт правый сдвиг. Если за один период схема сгенерирует все ненулевые элементы поля, то данный полином с полем GF(![]() ) будет примитивным.
) будет примитивным.
8.1.5. Кодирование Рида-Соломона
В уравнении (8.2) представлена наиболее распространенная форма кодов Рида-Соломона через параметры n, k, t и некоторое положительное число m > 2. Приведем это уравнение повторно.
![]() (8.20)
(8.20)
Здесь ![]() — число контрольных символов, а t – количество ошибочных битов в символе, которые может исправить код. Генерирующий полином для кода Рида-Соломона имеет следующий вид.
— число контрольных символов, а t – количество ошибочных битов в символе, которые может исправить код. Генерирующий полином для кода Рида-Соломона имеет следующий вид.
![]() (8.21)
(8.21)
Степень полиномиального генератора равна числу контролируемых символов. Коды Рида-Соломона являются подмножеством кодов БЧХ, которые обсуждались в разделе 6.8.3. и показаны в табл. 6.4. Поэтому связь между степенью полиномиального генератора и числом контрольных символов, как и в кодах БЧХ, не должна оказаться неожиданностью. В этом можно убедиться, подвергнув проверке любой генератор из табл. 6.4. Поскольку полиномиальный генератор имеет порядок 2t, мы должны иметь в точности 2t последовательные степени ![]() , которые являются корнями полинома. Обозначим корни
, которые являются корнями полинома. Обозначим корни ![]() как:
как: ![]() . Нет необходимости начинать именно с корня
. Нет необходимости начинать именно с корня ![]() , это можно сделать с помощью любой степени
, это можно сделать с помощью любой степени ![]() . Возьмем, к примеру, код (7,3) с возможностью коррекции двухсимвольных ошибок. Мы выразим полиномиальный генератор через
. Возьмем, к примеру, код (7,3) с возможностью коррекции двухсимвольных ошибок. Мы выразим полиномиальный генератор через ![]() корня следующим образом.
корня следующим образом.
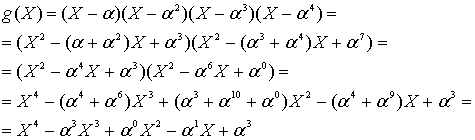
8.1.5.1. Кодирование в систематической форме
Так как код Рида-Соломона является циклическим, кодирование в систематической форме аналогично процедуре двоичного кодирования, разработанной в разделе 6.7.3. Мы можем осуществить сдвиг полинома сообщения m(X) в крайние правые k разряды регистра кодового слова и провести последующее прибавление полинома четности p(X) в крайние левые n – k разряды. Поэтому мы умножаем m(X) на ![]() , проделав алгебраическую операцию таким образом, что m(X) оказывается сдвинутым вправо на n – k позиций. В главе 6 это показано в уравнении (6.61) на примере двоичного кодирования. Далее мы делим
, проделав алгебраическую операцию таким образом, что m(X) оказывается сдвинутым вправо на n – k позиций. В главе 6 это показано в уравнении (6.61) на примере двоичного кодирования. Далее мы делим ![]() на полиномиальный генератор g(X), что можно записать следующим образом.
на полиномиальный генератор g(X), что можно записать следующим образом.
![]()
![]()
Здесь q(X) и p(X) – это частное и остаток от полиномиального деления. Как и в случае двоичного кодирования, остаток будет четным. Уравнение (8.23) можно представить следующим образом.
![]() (8.24)
(8.24)
Результирующий полином кодового слова U(X), показанный в уравнении (6.64), можно переписать следующим образом.
![]() (8.25)
(8.25)
Продемонстрируем шаги, подразумеваемые уравнениями (8.24) и (8.25), закодировав сообщение из трех символов
![]()
с помощью кода (7,3), генератор которого определяется уравнением (8.22). Сначала мы умножаем (сдвиг вверх) полином сообщения ![]() , что дает
, что дает ![]() Далее мы делим такой сдвинутый вверх полином сообщения на полиномиальный генератор из уравнения (8.22),
Далее мы делим такой сдвинутый вверх полином сообщения на полиномиальный генератор из уравнения (8.22), ![]() Полиномиальное деление недвоичных коэффициентов – это еще более утомительная процедура, чем ее двоичный аналог (см. пример 6.9), поскольку операции сложения (вычитания) и умножения (деления) выполняются согласно табл. 8.2 и 8.3. Мы оставим числителю в качестве вспомогательного упражнения проверку того, что полиномиальное деление даст в результате следующей полиномиальный остаток (полином четности).
Полиномиальное деление недвоичных коэффициентов – это еще более утомительная процедура, чем ее двоичный аналог (см. пример 6.9), поскольку операции сложения (вычитания) и умножения (деления) выполняются согласно табл. 8.2 и 8.3. Мы оставим числителю в качестве вспомогательного упражнения проверку того, что полиномиальное деление даст в результате следующей полиномиальный остаток (полином четности).
![]()
Заметим, из уравнения (8.25), полином кодового слова можно записать следующим образом.
![]()
8.1.5.2. Систематическое кодирование с помощью (n-k)-разрядного регистра сдвига
Как показано на рис. 8.9, кодирование последовательности из 3 символов в систематической форме на основе кода (7,3), определяемого генератором g(X) из уравнения (8.22), требует реализации регистра LFSR. Нетрудно убедиться, что элементы умножителя на рис. 8.9, взятые справа налево, соответствуют коэффициентам полинома в уравнении (8.22). Этот процесс кодирования является недвоичным аналогом циклического кодирования, которое описывалась в разделе 6.7.5. Здесь, в соответствии с уравнением (8.20), ненулевые кодовые слова образованы ![]() символами, и каждый символ состоит из m = 3 бит.
символами, и каждый символ состоит из m = 3 бит.
Следует отметить сходство между рис. 8.9, 6.18 и 6.19. Во всех трех случаях количество разрядов в регистре равно n – k. Рисунки в главе 6 отображают пример двоичного кодирования, где каждый разряд содержит 1 бит. В данной главе приведен пример двоичного кодирования, так что каждый разряд регистра сдвига, изображенного на рис. 8.9, содержит 3-битовый символ. На рис. 6.18 коэффициенты, обозначенные ![]() являются двоичными. Поэтому они принимают одно из значений 0 или 1, просто указывая на наличие или отсутствие связи в LFSR. На рис. 8.9 каждый коэффициент является 3-битовым, так что они могут принимать одно из 8 значений.
являются двоичными. Поэтому они принимают одно из значений 0 или 1, просто указывая на наличие или отсутствие связи в LFSR. На рис. 8.9 каждый коэффициент является 3-битовым, так что они могут принимать одно из 8 значений.
Недвоичные операции, осуществляемые кодером, показанным на рис. 8.9, создают кодовые слова в систематической форме, так же как и в двоичном случае. Эти операции определяются следующими шагами.
1. Переключатель 1 в течение первых k тактовых импульсов закрыт, для того чтобы подавать символы сообщения в (n — k)-разрядный регистр сдвига.
2. В течение первых k тактовых импульсов переключатель 2 находится в нижнем положении, что обеспечивает одновременную процедуру всех символов сообщения непосредственно на регистр выхода (на рис. 8.9 не показан).
3. После передачи k-го символа на регистр выхода, переключатель 1 открывается, а переключатель 2 переходит в верхнее положение.
4. Остальные (n—k) тактовых импульсов очищают контрольные символы, содержащиеся в регистре, подавая из на регистр выхода.
5. Общее число тактовых импульсов равно n, и содержимое регистра выхода является полиномом кодового слова ![]() , где p(X) представляет собой кодовые символы, а m(X) – символы сообщения в полиномиальной форме.
, где p(X) представляет собой кодовые символы, а m(X) – символы сообщения в полиномиальной форме.
Для проверки возьмем те же последовательность символов, что и в разделе 8.1.5.1.
![]()
Здесь крайний правый символ является самым первым и крайний правый бит также является самым первым. Последовательность действий в течение первых k = 3 сдвигов в цепи кодирования на рис. 8.9 будет иметь следующий вид.
Очередь ввода Такт Содержимое регистра обратная связь
|
|
|
|
0 |
0 |
0 |
0 |
0 |
|
|
|
|
1 |
|
|
|
|
|
|
|
|
2 |
|
0 |
|
|
|
||
|
— |
3 |
|
|
|
|
— |
Как можно видеть, после третьего такта регистр содержит 4 контрольных символа, ![]() . Затем переключатель 1 переходит в верхнее положение, и контрольные символы, содержащиеся в регистре, подаются на выход. Поэтому выходное слово, записанное в полиномиальной форме, можно представить в следующим виде.
. Затем переключатель 1 переходит в верхнее положение, и контрольные символы, содержащиеся в регистре, подаются на выход. Поэтому выходное слово, записанное в полиномиальной форме, можно представить в следующим виде.
![]()
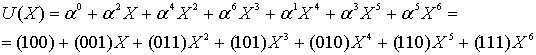 (8.26)
(8.26)
Процесс проверки содержимого регистра во время разных тактов несколько сложнее, чем в случае бинарного кодирования. Здесь сложение и умножение элементов поля должны выполняться согласно табл. 8.2 и 8.3.
Корни полиномиального генератора g(X) должны быть и корнями кодового слова, генерируемого g(X), поскольку правильное кодовое слово имеет следующий вид.
![]() (8.27)
(8.27)
Следовательно, произвольное кодовое слово, выражаемое через корень генератора g(X), должно давать нуль. Представляется интересным, действительно ли полином кодового слова в уравнении (8.26) дает нуль, когда он выражается через какой-либо из четырех корней g(X). Иными словами, это означает проверку следующего.
![]()
Независимо выполнив вычисления для разных корней, получим следующее.
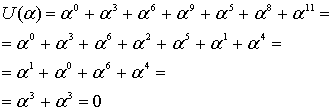
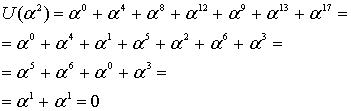
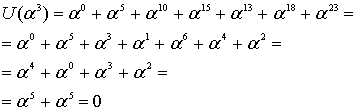
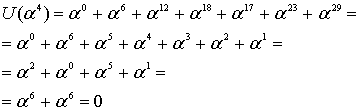
Эти вычисления показывают, что, как и ожидалось, кодовое слово, выражаемое через любой корень генератора g(X), должно давать нуль.
8.1.6. Декодирование Рида-Соломона
В разделе 8.1.5 тестовое сообщение кодируется в систематической форме с помощью кода (7,3), что дает в результате полином кодового слова, описываемый уравнением (8.26). Допустим, что в ходе передачи это кодовое слово подверглось искажению: 2 символа были приняты с ошибкой. (Такое количество ошибок соответствует максимальной способности кода к коррекции ошибок.) При использовании 7-символьного кодового слова ошибочную комбинацию можно представить в полиномиальной форме следующим образом.
![]() (8.28)
(8.28)
Пусть двухсимвольная ошибка будет такой, что
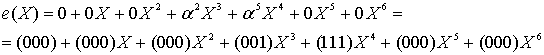 (8.29)
(8.29)
Другими словами, контрольный символ искажен 1-битовой ошибкой (представленной как ![]() ), а символ сообщения — 3-битовой ошибкой (представленной как
), а символ сообщения — 3-битовой ошибкой (представленной как ![]() ). В данном случае принятый полином поврежденного кодового слова r(Х) представляется в виде суммы полинома переданного кодового слова и полинома ошибочной комбинации, как показано ниже.
). В данном случае принятый полином поврежденного кодового слова r(Х) представляется в виде суммы полинома переданного кодового слова и полинома ошибочной комбинации, как показано ниже.
![]()
![]() (8.30)
(8.30)
Следуя уравнению (8.30), мы суммируем U(X) из уравнения (8.26) и e(Х) из уравнения (8.29) и имеем следующее.
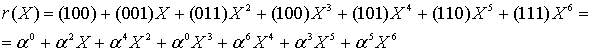 (8.31)
(8.31)
В данном примере исправления 2-символьной ошибки имеется четыре неизвестных — два относятся к расположению ошибки, а два касаются ошибочных значений. Отметим важное различие между недвоичным декодированием r(Х), которое мы показали в уравнении (8.31), и двоичным, которое описывалось в главе 6. При двоичном декодировании декодеру нужно знать лишь расположение ошибки. Если известно, где находится ошибка, бит нужно поменять с 1 на 0 или наоборот. Но здесь недвоичные символы требуют, чтобы мы не только узнали расположение ошибки, но и определили правильное значение символа, расположенного на этой позиции. Поскольку в данном примере у нас имеется четыре неизвестных, нам нужно четыре уравнения, чтобы найти их.
8.1.6.1. Вычисление синдрома
Вернемся к разделу 6.4.7 и напомним, что синдром — это результат проверки четности, выполняемой над r, чтобы определить, принадлежит ли r набору кодовых слов. Если r является членом набора, то синдром S имеет значение, равное 0. Любое ненулевое значение S означает наличие ошибок. Точно так же, как и в двоичном случае, синдром S состоит из n—k символов, ![]()
![]() . Таким образом, для нашего кода (7, 3) имеется по четыре символа в каждом векторе синдрома; их значения можно рассчитать из принятого полинома r(Х). Заметим, кдк облегчаются вычисления благодаря самой структуре кода, определяемой уравнением (8.27).
. Таким образом, для нашего кода (7, 3) имеется по четыре символа в каждом векторе синдрома; их значения можно рассчитать из принятого полинома r(Х). Заметим, кдк облегчаются вычисления благодаря самой структуре кода, определяемой уравнением (8.27).
![]()
Из этой структуры можно видеть, что каждый правильный полином кодового слова U(X) является кратным полиномиальному генератору g(X). Следовательно, корни g(X) также должны быть корнями U(X). Поскольку ![]() , то r(Х), вычисляемый с каждым корнем g(X), должен давать нуль, только если r(Х) будет правильным кодовым словом. Любые ошибки приведут в итоге к ненулевому результату в одном (или более) случае. Вычисления символов синдрома можно записать следующим образом.
, то r(Х), вычисляемый с каждым корнем g(X), должен давать нуль, только если r(Х) будет правильным кодовым словом. Любые ошибки приведут в итоге к ненулевому результату в одном (или более) случае. Вычисления символов синдрома можно записать следующим образом.
![]() (8.32)
(8.32)
Здесь, как было показано в уравнении (8.29), r(Х) содержит 2-символьные ошибки. Если r(Х) окажется правильным кодовым словом, то это приведет к тому, что все символы синдрома ![]() будут равны нулю. В данном примере четыре символа синдрома находятся следующим образом.
будут равны нулю. В данном примере четыре символа синдрома находятся следующим образом.
![]()
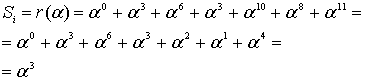 (8.33)
(8.33)
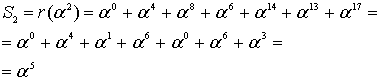 (8.34)
(8.34)
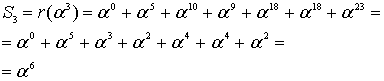 (8.35)
(8.35)
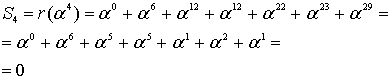 (8.36)
(8.36)
Результат подтверждает, что принятое кодовое слово содержит ошибку (введенную нами), поскольку ![]() .
.
Пример 8.3. Повторная проверка значений синдрома
Для рассматриваемого кода (7, 3) ошибочная комбинация известна, поскольку мы выбрали ее заранее. Вспомним свойство кодов, обсуждаемое в разделе 6.4.8.1, когда была введена нормальная матрица. Все элементы класса смежности (строка) нормальной матрицы имеют один и тот же синдром. Нужно показать, что это свойство справедливо и для кода Рида-Соломона, путем вычисления полинома ошибок e(Х) со значениями корней g(X). Это должно дать те же значения синдрома, что и вычисление r(Х) со значениями корней g(X). Другими словами, это должно дать те же значения, которые были получены в уравнениях (8.33)-(8.36).
Решение
![]()
![]()
![]()
Из уравнения (8.29) следует, что ![]() , поэтому
, поэтому
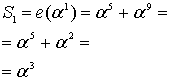
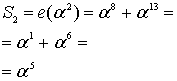
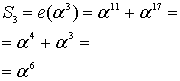
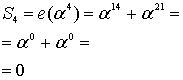
Из этих результатов можно заключить, что значения синдрома одинаковы — как полученные путем вычисления e(Х) со значениями корней g(X), так и полученные путем вычисления r(Х) с теми же значениями корней g(X).
8.1.6.2. Локализация ошибки
Допустим, в кодовом слове имеется ![]() ошибок, расположенных на позициях
ошибок, расположенных на позициях ![]() . Тогда полином ошибок, определяемый уравнениями (8.28) и (8.29), можно записать следующим образом.
. Тогда полином ошибок, определяемый уравнениями (8.28) и (8.29), можно записать следующим образом.
![]() (8.37)
(8.37)
Индексы 1, 2, …, ![]() обозначают 1-ю, 2-ю, …,
обозначают 1-ю, 2-ю, …, ![]() -ю ошибки, а индекс
-ю ошибки, а индекс ![]() — расположение ошибки. Для коррекции искаженного кодового слова нужно определить каждое значение ошибки
— расположение ошибки. Для коррекции искаженного кодового слова нужно определить каждое значение ошибки ![]() и ее расположение
и ее расположение ![]() , где
, где ![]() . Обозначим номер локатора ошибки как
. Обозначим номер локатора ошибки как ![]() . Далее вычисляем
. Далее вычисляем ![]() символа синдрома, подставляя
символа синдрома, подставляя ![]() в принятый полином при
в принятый полином при ![]() .
.
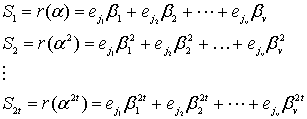 (8.38)
(8.38)
У нас имеется 2t неизвестных (t значений ошибок и t расположений) и система 2t уравнений. Впрочем, эту систему 2t уравнений нельзя решить обычным путем, поскольку уравнения в ней нелинейны (некоторые неизвестные входят в уравнение в степени). Методика, позволяющая решить эту систему уравнений, называется алгоритмом декодирования Рида-Соломона.
Если вычислен ненулевой вектор синдрома (один или более его символов не равны нулю), это означает, что была принята ошибка. Далее нужно узнать расположение ошибки (или ошибок). Полином локатора ошибок можно определить следующим образом.
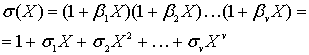 (8.39)
(8.39)
Корнями ![]() будут
будут ![]() . Величины, обратные корням
. Величины, обратные корням ![]() , будут представлять номера расположений ошибочной комбинации e(Х). Тогда, воспользовавшись авторегрессионной техникой моделирования [5], мы составим из синдромов матрицу, в которой первые t синдромов будут использоваться для предсказания следующего синдрома.
, будут представлять номера расположений ошибочной комбинации e(Х). Тогда, воспользовавшись авторегрессионной техникой моделирования [5], мы составим из синдромов матрицу, в которой первые t синдромов будут использоваться для предсказания следующего синдрома.
 (8.40)
(8.40)
Мы воспользовались авторегрессионной моделью уравнения (8.40), взяв матрицу наибольшей размерности с ненулевым определителем. Для кода (7, 3) с коррекцией двухсимвольных ошибок матрица будет иметь размерность ![]() , и модель запишется следующим образом.
, и модель запишется следующим образом.
 (8.41)
(8.41)
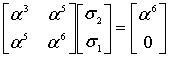 (8.42)
(8.42)
Чтобы найти коэффициенты ![]() и
и ![]() полинома локатора ошибок
полинома локатора ошибок ![]() ,. сначала необходимо вычислить обратную матрицу для уравнения (8.42). Обратная матрица для матрицы [А] определяется следующим образом.
,. сначала необходимо вычислить обратную матрицу для уравнения (8.42). Обратная матрица для матрицы [А] определяется следующим образом.
Следовательно,
det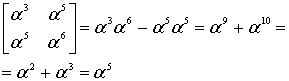 (8.43)
(8.43)
 (8.44)
(8.44)
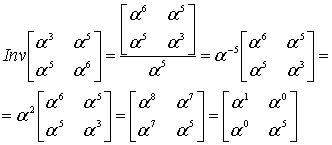 (8.45)
(8.45)
Проверка надежности
Если обратная матрица вычислена правильно, то произведение исходной и обратной матрицы должно дать единичную матрицу.
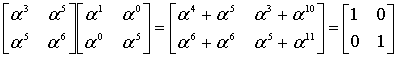 (8.46)
(8.46)
С помощью уравнения (8.42) начнем поиск положений ошибок с вычисления коэффициентов полинома локатора ошибок ![]() , как показано далее.
, как показано далее.
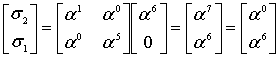 (8.47)
(8.47)
Из уравнений (8.39) и (8.47)
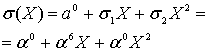 (8.48)
(8.48)
Корни ![]() являются обратными числами к положениям ошибок. После того как эти корни найдены, мы знаем расположение ошибок. Вообще, корни
являются обратными числами к положениям ошибок. После того как эти корни найдены, мы знаем расположение ошибок. Вообще, корни ![]() могут быть одним или несколькими элементами поля. Определим эти корни путем полной проверки полинома
могут быть одним или несколькими элементами поля. Определим эти корни путем полной проверки полинома ![]() со всеми элементами поля, как будет показано ниже. Любой элемент X, который дает
со всеми элементами поля, как будет показано ниже. Любой элемент X, который дает ![]() , является корнем, что позволяет нам определить расположение ошибки.
, является корнем, что позволяет нам определить расположение ошибки.
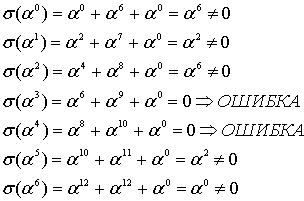
Как видно из уравнения (8.39), расположение ошибок является обратной величиной к корням полинома. А значит, ![]() означает, что один корень получается при
означает, что один корень получается при ![]() . Отсюда
. Отсюда ![]() . Аналогично
. Аналогично ![]() означает, что другой корень появляется при
означает, что другой корень появляется при ![]() , где (в данном примере)
, где (в данном примере) ![]() и
и ![]() обозначают 1-ю и 2-ю ошибки. Поскольку мы имеем дело с 2-символьными ошибками, полином ошибок можно записать следующим образом.
обозначают 1-ю и 2-ю ошибки. Поскольку мы имеем дело с 2-символьными ошибками, полином ошибок можно записать следующим образом.
![]() (8.49)
(8.49)
Здесь были найдены две ошибки на позициях ![]() и
и ![]() . Заметим, что индексация номеров расположения ошибок является сугубо произвольной. Итак, в этом примере мы обозначили величины
. Заметим, что индексация номеров расположения ошибок является сугубо произвольной. Итак, в этом примере мы обозначили величины ![]() как
как ![]()
![]() и
и ![]() .
.
8.1.6.3. Значения ошибок
Мы обозначили ошибки ![]() , где индекс j обозначает расположение ошибки, а индекс l — l-ю ошибку. Поскольку каждое значение ошибки связано с конкретным меcторасположением, систему обозначений можно упростить, обозначив
, где индекс j обозначает расположение ошибки, а индекс l — l-ю ошибку. Поскольку каждое значение ошибки связано с конкретным меcторасположением, систему обозначений можно упростить, обозначив ![]() просто как
просто как ![]() . Теперь, приготовившись к нахождению значений ошибок
. Теперь, приготовившись к нахождению значений ошибок ![]() и
и ![]() , связанных с позициями
, связанных с позициями ![]() и
и ![]() можно использовать любое из четырех синдромных уравнений. Выразим из уравнения (8.38)
можно использовать любое из четырех синдромных уравнений. Выразим из уравнения (8.38) ![]() , и
, и ![]() .
.
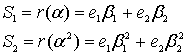 (8.50)
(8.50)
Эти уравнения можно переписать в матричной форме следующим образом.
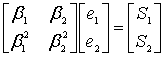 (8.51)
(8.51)
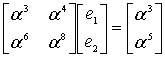 (8.52)
(8.52)
Чтобы найти значения ошибок ![]() и
и ![]() , нужно, как обычно, выполнить поиск обратной матрицы для уравнения (8.52).
, нужно, как обычно, выполнить поиск обратной матрицы для уравнения (8.52).
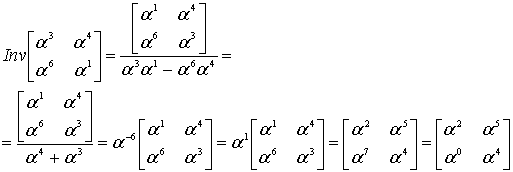 (853)
(853)
Теперь мы можем найти из уравнения (8.52) значения ошибок.
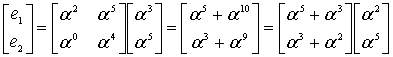 (8.54)
(8.54)
8.1.6.4. Исправление принятого полинома с помощью найденного полинома ошибок
Из уравнений (8.49) и (8.54) мы находим полином ошибок.
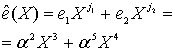 (8.55)
(8.55)
Показанный алгоритм восстанавливает принятый полином, выдавая в итоге предполагаемое переданное кодовое слово и, в конечном счете, декодированное сообщение.
![]() (8.56)
(8.56)
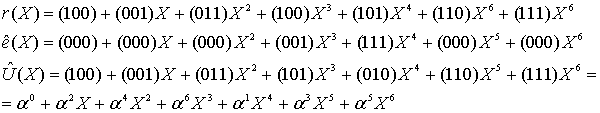 (8.57)
(8.57)
Поскольку символы сообщения содержатся в крайних правых k = 3 символах, декодированным будет следующее сообщение.
![]()
![]()
![]()
Это сообщение в точности соответствует тому, которое было выбрано для этого примера в разделе 8.1.5. (Для более детального знакомства с кодированием Рида-Соломона обратитесь к работе [6].)
В современных
системах цифрового телевидения для
обеспечения помехоустойчивой передачи
цифровых телевизионных сигналов по
радиоканалу используются наиболее
совершенные коды Рида-Соломона(Reed-Solomon),требующие добавления двух проверочных
символов в расчете на одну исправляемую
ошибку. Коды Рида-Соломона обладают
высокими корректирующими свойствами,
для них разработаны относительно
простые и конструктивные методы
кодирования. Коды Рида-Соломона не
являются двоичными. Это надо понимать
в том смысле, что символами кодовых
слов являются не двоичные знаки, а
элементы множества чисел, состоящего
более чем из двух знаков (хотя, конечно,
при передаче каждый символ заменяется
соответствующей двоичной комбинацией).
Коды Рида-Соломона,
относящиеся к классу циклических
кодов, образуют подгруппублоковых
кодов. Они получаются из любой
разрешенной комбинации путем циклического
сдвига ее разрядов. Кодирование и
декодирование, обнаруживающее и
исправляющее ошибки, – это вычислительные
процедуры, которые для циклических
кодов удобно выполнять как действия с
многочленами и реализацию в виде
цифровых устройств на базе регистров
сдвига с обратными связями.
Чтобы получить
более детальное представление о кодах
Рида-Соломона посмотрим, какое место
они занимают в классификации корректирующих
кодов (рис. 4.4).
Корректирующие
коды разделяются на блочные и сверточные
(непрерывные). Блочные кодыоснованы на перекодировании исходной
кодовой комбинации (блока), содержащейkинформационных
символов, в передаваемую кодовую
комбинацию, содержащуюn>kсимволов.
Дополнительныер = n – kсимволов зависят только отkсимволов исходной кодовой комбинации.
Следовательно, кодирование и
декодирование осуществляются всегда
в пределах одной кодовой комбинации
(блока). В противоположность этому всверточных кодахкодирование и
декодирование осуществляются непрерывно
над последовательностью двоичных
символов.
Блочные коды
бывают разделимые и неразделимые. В
разделимых кодахможно в каждой
кодовой комбинации указать, какие
символы являются информационными,
а какие проверочными. Внеразделимых
кодахтакая возможность отсутствует.
Следующая ступень
классификации – систематические
коды. Они отличаются тем, что в них
проверочные символы формируются из
информационных символов по определенным
правилам, выражаемым математическими
соотношениями. Например, каждый
проверочный символхpjполучается как линейная комбинация
информационных символов

Рис. 4.4.Место
кодов Рида-Соломона в классификации
корректирующих кодов
![]() ,
,
где
![]() – коэффициенты, принимающие значения
– коэффициенты, принимающие значения
0 или 1;![]() .
.
Соотношение для формирования
контрольного бита проверки на четность
является частным случаем .
Перейдем к более
подробному знакомству с циклическими
кодами.
В первую очередь
введем запись кодовой комбинации или,
как часто называют ее в литературе,
кодового вектора в виде полинома. Пусть
имеется кодовая комбинация
a0a1a2…an–1,
гдеа0– младший разряд кода,an–1– старший разряд кода. Соответствующий
ей полином имеет вид
![]() ,
,
где х–
формальная переменная, вводимая только
для получения записи кодовой
комбинации в виде полинома.
Над полиномами,
представляющими кодовые комбинации,
определена математическая операция
умножения. Особенность этой операции
по сравнению с общепринятой заключается
в том, что коэффициенты при хвсех
степеней суммируются по модулю 2, а
показатели степенихпри перемножении
суммируются по модулюn,
поэтомухn= 1.
Далее
введем понятие производящего
полинома.
Производящим
полиномом порядка (n – k)
может быть
полином со старшей степенью х,
равной (n – k),
на который без
остатка делится двучлен (1 + хn).
Разрешенные кодовые комбинации
получаются перемножением полиномов
порядка k – 1,
выражающих исходные кодовые комбинации,
на производящий полином.
Циклические коды
имеют следующее основное свойство.
Если кодовая комбинация a0a1a2…an–1является разрешенной, то получаемая
из нее путем циклического сдвига
кодовая комбинацияan–1a0a1…an–2также является разрешенной в данном
коде. При записи в виде полиномов
операция циклического сдвига кодового
слова сводится к умножению соответствующего
полинома нахс учетом приведенных
ранее правил выполнения операции
умножения.
Циклический код
с производящим полиномом
![]() строится следующим образом.
строится следующим образом.
1. Берутся
полиномы
![]() ,
,![]() ,
,![]() ,
,
…,![]() .
.
2. Кодовые
комбинации, соответствующие этим
полиномам, записывают в виде строк
матрицы G, называемойпроизводящей матрицей.
3. Формируется
набор разрешенных кодовых комбинаций
кода. В него входит нулевая кодовая
комбинация, k
кодовых комбинаций, указанных в п. 1,
а также суммы их всевозможных сочетаний.
Суммирование осуществляется поразрядно,
причем каждый
разряд суммируется по модулю 2.
Общее число полученных таким образом
разрешенных кодовых комбинаций равно
2k,
что соответствует числу информационных
разрядов кода.
Для построения
декодера в первую очередь получают
производящий полином
![]() порядкаkдля построенияисправляющей матрицыН:
порядкаkдля построенияисправляющей матрицыН:
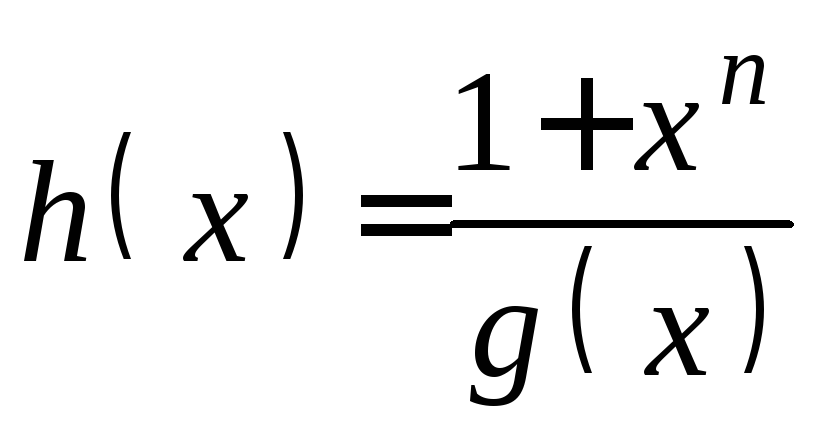 .
.
Строками исправляющей
матрицы Нбудут кодовые комбинации,
определяемые полиномами![]() ,
,![]() ,
,
…,![]() ,
,
где![]() – это записанный в обратном порядке
– это записанный в обратном порядке
полином![]() .
.
Исправляющая матрица имеетnстолбцов иn – kстрок.
При декодировании
принятая кодовая комбинация a0a1a2…an–1скалярно умножается на каждую строку
исправляющей матрицы. Эта операция
может быть записана в виде соотношения:
![]() ,
,
где hji– элементыj-той
строки матрицыН. Полученныеn – kчиселcjобразуютисправляющий векторилисиндром. Если ошибок нет, то всеcj= 0. Если же при передаче данной кодовой
комбинации возникла ошибка, то некоторые
из чиселcjне равны 0. По тому, какие именно элементы
исправляющего вектора отличны от нуля,
можно сделать вывод о том, в каких
разрядах принятой кодовой комбинации
есть ошибка и, следовательно, исправить
эти ошибки.
Рассмотрим пример,
часто встречающийся в литературе.
Построим циклический код с n= 7;k= 4. Для этого
представим двучлен 1 +х7в
виде произведения [4]:
![]() .
.
В
обычной алгебре это равенство, конечно,
не выполняется, но если использовать
для приведения подобных вместо обычного
сложения операцию суммирования по
модулю 2, а при сложении показателей
степеней –
операцию суммирования по модулю 7, то
равенство окажется справедливым.
В качестве
производящего многочлена возьмем 1 + х+х3. Умножаем его нах,х2их3и получаем многочленых+х2+х4;х2+х3+х5;х3+х4+х6. Затем
записываем производящую матрицуG,
причем в каждой строке матрицы младший
разряд кодовой комбинации расположен
первым слева.
 .
.
Далее формируем
набор из 15 допустимых кодовых комбинаций:
00000000, 1101000, 0110100, 0011010, 0001101, 1011100, 0101110,
0010111, 1000110, 0100011, 1111111, 1010001, 1000110, 0100011,
1001011. В этих записях младшие биты
слева, а старшие – справа.
Перемножив первые
два сомножителя в , получаем производящий
многочлен для исправляющей матрицы:
1 + х+х+х4. Затем
умножаем его нахих2и
получаем еще две строки этой матрицы,
которая в результате имеет такой вид
(в отличие от матрицыGздесь младшие разряды соответствующих
полиномов расположены справа):
 .
.
Пусть принята
кодовая комбинация 0001101, входящая в
набор допустимых. Найдем скалярные
произведения этой кодовой комбинации
со всеми строками матрицы Н:

Пусть теперь
принята кодовая комбинация 0001100, в
которой последний (старший) бит содержит
ошибку. Скалярные произведения принятой
кодовой комбинации на строки исправляющей
матрицы имеют вид:

Таким образом,
получен синдром (1, 0, 0). Если ошибка
оказывается в другом бите кодовой
комбинации, то получается другой
синдром.
Одним из важных
достоинств циклических кодов является
возможность построения кодирующих и
декодирующих устройств в виде сдвиговых
регистров с обратными связями через
сумматоры по модулю 2.
Различные виды
циклических кодов получаются с помощью
различных производящих полиномов.
Существует развитая математическая
теория этого вопроса [15]. Среди
большого количества циклических кодов
к числу наиболее эффективных и широко
используемых относятся коды
Бозе-Чоудхури-Хоквингема (ВСН-коды –
по первым буквам фамилий Bose,Chaudhuri,Hockwinhamили в русскоязычной записи БЧХ-коды),
являющиесяобобщением кодов Хеммингана случай направления нескольких
ошибок. Они образуют наилучший среди
известных класснеслучайных кодовдля каналов, в которых ошибки в
последовательных символах возникают
независимо. Например, БЧХ-код (63, 44),
используемый в системе спутникового
цифрового радиовещания, позволяет
исправить 2 или 3 ошибки, обнаружить 4
или 5 ошибок на каждый блок из 63 символов.
Относительная скорость такого кода
равнаR= 44/63 = 0,698.
Одним
из видов ВСН-кодов являются коды
Рида-Соломона. Эти коды относятся к
недвоичным
кодам,
так как символами в них могут быть
многоразрядные двоичные числа,
например, целые байты. В Европейском
стандарте цифрового телевидения
DVB
используется код Рида-Соломона,
записываемый как (204, 188, 8), где 188 –
количество информационных байт в пакете
транспортного потока MPEG-2,
204 – количество байт в пакете после
добавления проверочных символов, 8 –
минимальное кодовое расстояние между
допустимыми кодовыми комбинациями.
Таким образом, в качестве кодовых
комбинаций берутся целые пакеты
транспортного потока, содержащие 1888
= 1504 информационных бита, а добавляемые
проверочные символы содержат 168
= 128 бит. Относительная скорость такого
кода равна 0,92. Этот код Рида-Соломона
позволяет эффективно исправлять до 8
принятых с ошибками байт в каждом
транспортном пакете.
Отметим также,
что используемый в цифровом телевизионном
вещании код Рида-Соломона часто называют
укороченным. Смысл этого термина
состоит в следующем. Из теории кодов
Рида-Соломона следует, что если символом
кода является байт, то полная длина
кодового слова должна составлять 255
байт (239 информационных и 16 проверочных).
Однако, пакет транспортного потокаMPEG-2 содержит 188 байт.
Чтобы согласовать размер пакета с
параметрами кода, перед кодированием
в начало каждого транспортного пакета
добавляют 51 нулевой информационный
байт, а после кодирования эти
дополнительные нулевые байты
отбрасывают.
В приемнике для
каждого принятого транспортного пакета,
содержащего 204 байта, вычисляются
синдромы и находятся два полинома:
«локатор», корни которого показывают
положение ошибок, и «корректор»
(evaluator), дающий значение
ошибок. Ошибки корректируются, если
это возможно. Если же коррекция невозможна
(например, ошибочных байт более 8) данные
в пакете не изменяются, а сам пакет
помечается путем установки флага
(первый бит после синхробайта), как
содержащий неустранимые ошибки. В обоих
случаях 16 избыточных байт удаляются,
и после декодирования длина транспортного
пакета становится равной 188 байт.