При проведении регрессионного анализа, основанного на методе наименьших квадратов, на практике следует обратить серьезное внимание на проблемы, связанные с выполнимостью свойств случайных отклонений моделей. Как мы отмечали ранее, свойства оценок коэффициентов регрессии напрямую зависят от свойств случайного члена в уравнении регрессии. Для получения качественных оценок необходимо следить за выполнимостью предпосылок МНК (условий Гаусса− Маркова), т. к. при их нарушении МНК может давать оценки с плохими статистическими свойствами. При этом существуют другие методы определения более точных оценок. Одной из ключевых предпосылок МНК является условие постоянства дисперсий случайных отклонений (см. параграф 5.1, предпосылка 20):
дисперсия случайных отклонений εi постоянна. D(εi)=D(εj) = σ2 для любых наблюдений i и j.
Выполнимость данной предпосылки называется гомоскедастич-
ностью (постоянством дисперсии отклонений). Невыполнимость данной предпосылки называется гетероскедастичностью (непостоянством дисперсий отклонений).
В данной главе мы подробно проанализируем суть гетероскедастичности, ее причины и последствия, а также приведем несколько способов смягчения этих последствий.
8.1. Суть гетероскедастичности
При рассмотрении выборочных данных требование постоянства дисперсии случайных отклонений может вызвать определенное недоумение в силу того, что при каждом i-м наблюдении имеется единственное значение εi. Откуда же появляется разброс? Дело в том, что при рассмотрении выборочных данных мы имеем дело с конкретными реализациями зависимой переменной yi и соответственно c определенными случайными отклонениями εi, i = 1, 2, …, n. Но до осуществления выборки эти показатели априори могли принимать произвольные значения на основе некоторых вероятностных распределений. Одним из требований к этим распределениям является равенство дисперсий. Данное условие подразумевает, что несмотря на то что при каждом конкретном наблюдении случайное отклонение может быть большим либо маленьким, положительным либо отрицательным, не должно быть некой априорной причины, вызывающей большую
209
ошибку (отклонение) при одних наблюдениях и меньшую − при других.
Однако на практике гетероскедастичность не так уж и редка. Зачастую есть основания считать, что вероятностные распределения случайных отклонений εi при различных наблюдениях будут различными. Это не означает, что случайные отклонения обязательно будут большими при определенных наблюдениях и малыми − при других, но это означает, что априорная вероятность этого велика. Поэтому важно понимать суть этого явления и его последствия.
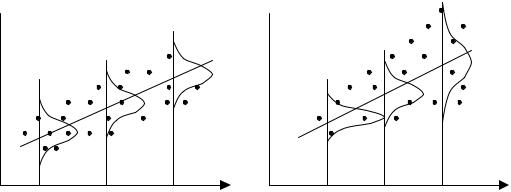
На рис. 8.1 приведены два примера линейной регрессии − зависимости потребления С от дохода I: C = β0 + β1I + ε.
C C
C
|
I1 |
Ik |
In |
I |
I1 |
Ik |
In |
I |
|
а |
б |
Рис. 8.1
В обоих случаях с ростом дохода растет среднее значение потребления. Но если на рис. 8.1, а дисперсия потребления остается одной и той же для различных уровней дохода, то на рис. 8.1, б при аналогичной зависимости среднего потребления от дохода дисперсия потребления не остается постоянной, а увеличивается с ростом дохода. Фактически это означает, что во втором случае субъекты с большим доходом в среднем потребляют больше, чем субъекты с меньшим доходом, и, кроме того, разброс в их потреблении более существенен для большего уровня дохода. Фактически люди с большими доходами имеют больший простор для распределения своего дохода. Реалистичность данной ситуации не вызывает сомнений. Разброс значений потребления вызывает разброс точек наблюдения относительно линии регрессии, что и определяет дисперсию случайных отклонений. Динамика изменения дисперсий (распределений) отклонений для данного примера проиллюстрирована на рис. 8.2. При гомоскедастичности
210
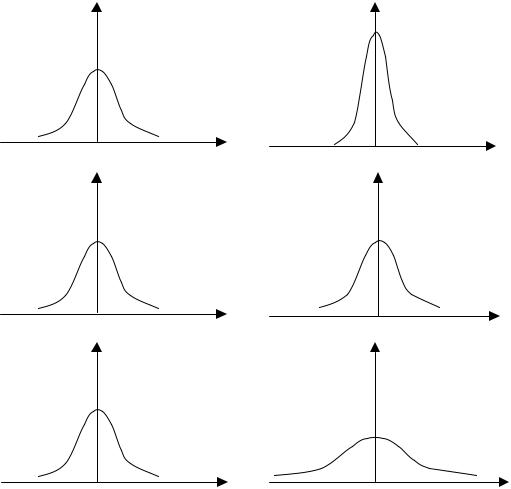
(рис. 8.2, а) дисперсии εi постоянны, а при гетероскедастичности (рис. 8.2, б) дисперсии εi изменяются (в нашем примере − увеличиваются).
|
а − гомоскедастичность |
б − гетероскедастичность |
|
Рис. 8.2 |
Проблема гетероскедастичности в большей степени характерна для перекрестных данных и довольно редко встречается при рассмотрении временных рядов. Это можно объяснить следующим образом. При перекрестных данных учитываются экономические субъекты (потребители, домохозяйства, фирмы, отрасли, страны и т. п.), имеющие различные доходы, размеры, потребности и т. д. Но в этом случае возможны проблемы, связанные с эффектом масштаба. Во временных рядах обычно рассматриваются одни и те же показатели в различные моменты времени (например, ВНП, чистый экспорт, темпы инфляции
211
и т. д. в определенном регионе за определенный период времени). Однако при увеличении (уменьшении) рассматриваемых показателей с течением времени может возникнуть проблема гетероскедастичности.
8.2. Последствия гетероскедастичности
Как отмечалось в разделе 5.1, при рассмотрении классической линейной регрессионной модели МНК дает наилучшие линейные несмещенные оценки (BLUE-оценки) лишь при выполнении ряда предпосылок, одной из которых является постоянство дисперсии отклонений (гомоскедастичность): σ2(εi) = σ2 для всех наблюдений i, i = 1, 2, …, n.
При невыполнимости данной предпосылки (при гетероскедастичности) последствия применения МНК будут следующими.
1.Оценки коэффициентов по-прежнему остаются несмещенными и линейными.
2.Оценки не будут эффективными (т. е. они не будут иметь наименьшую дисперсию по сравнению с другими оценками данного параметра). Они не будут даже асимптотически эффективными. Увеличение дисперсии оценок снижает вероятность получения максимально точных оценок.
3.Дисперсии оценок будут рассчитываться со смещением. Смещенность появляется вследствие того, что необъясненная уравнением
|
2 |
∑ ei2 |
|||
|
регрессии дисперсия S |
= |
(m − число объясняющих пере- |
||
|
n − m − 1 |
менных), которая используется при вычислении оценок дисперсий всех коэффициентов (см. параграф 6.2, (6.23)), не является более несмещенной.
4.Вследствие вышесказанного все выводы, получаемые на основе соответствующих t- и F-статистик, а также интервальные оценки будут ненадежными. Следовательно, статистические выводы, получаемые при стандартных проверках качества оценок, могут быть ошибочными и приводить к неверным заключениям по построенной модели. Вполне вероятно, что стандартные ошибки коэффициентов будут занижены, а следовательно, t-статистики будут завышены. Это может привести к признанию статистически значимыми коэффициентов, таковыми на самом деле не являющимися.
Причину неэффективности оценок МНК при гетероскедастичности легко пояснить следующим примером парной регрессии.
212
y
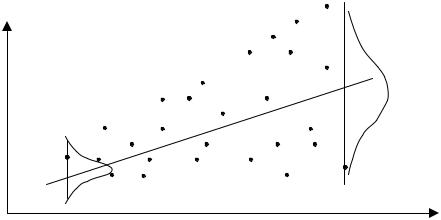
Из рис. 8.3 видно, что для каждого конкретного значения хi СВ Х переменная Y принимает значение уi из некоторого множества, имеющего свое распределение, отличное одно от другого в силу непостоянства дисперсий (сравните распределения для значений у1 и уn).
По МНК минимизируется сумма квадратов отклонений
∑ei2 = ∑(yi − b0 − b1xi )2.
Но в этом случае каждое конкретное значение ei2 в данной сумме имеет одинаковый “вес” вне зависимости от того, получено оно из распределения с маленькой дисперсией (например, e12 ) или с большой (например, e2n ). Но это противоречит логике, т. к. точка, полученная
из распределения с меньшей дисперсией, более точно определяет направление линии регрессии. Поэтому она должна иметь больший “вес”, чем точка из распределения с большей дисперсией. Следовательно, методы оценивания, учитывающие “веса” точек наблюдений, позволяют получать более точные (эффективные) оценки. Учет “весов” точек характерен, например, для метода взвешенных наименьших квадратов, рассмотренного ниже.
8.3.Обнаружение гетероскедастичности
Вряде случаев на базе знаний характера данных появление проблемы гетероскедастичности можно предвидеть и попытаться устранить этот недостаток еще на этапе спецификации. Однако значительно чаще эту проблему приходится решать после построения уравнения регрессии.
213
Обнаружение гетероскедастичности в каждом конкретном случае является довольно сложной задачей, т. к. для знания дисперсий отклонений σ2(еi) необходимо знать распределение СВ Y, соответствующее выбранному значению хi СВ Х. На практике зачастую для каждого конкретного значения хi определяется единственное значение уi , что не позволяет оценить дисперсию СВ Y для данного хi .
Естественно, не существует какого-либо однозначного метода определения гетероскедастичности. Однако к настоящему времени для такой проверки разработано довольно большое число тестов и критериев для них. Рассмотрим наиболее популярные и наглядные: графический анализ отклонений, тест ранговой корреляции Спирмена, тест Парка, тест Глейзера, тест Голдфелда−Квандта.
8.3.1. Графический анализ остатков
Использование графического представления отклонений позволяет определиться с наличием гетероскедастичности. В этом случае по оси абсцисс откладывается объясняющая переменная Х (либо линейная комбинация объясняющих переменных Y = b0 + b1X1 + … +
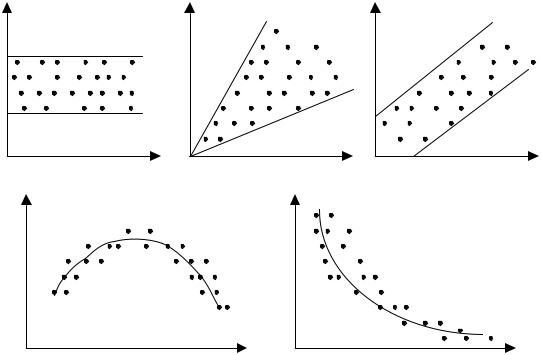
+ bmXm), а по оси ординат либо отклонения еi, либо их квадраты ei2 . Примеры таких графиков приведены на рис. 8.4.
|
а |
xi |
б |
xi |
xi |
|
в |
||||
|
ei2 |
ei2 |
214
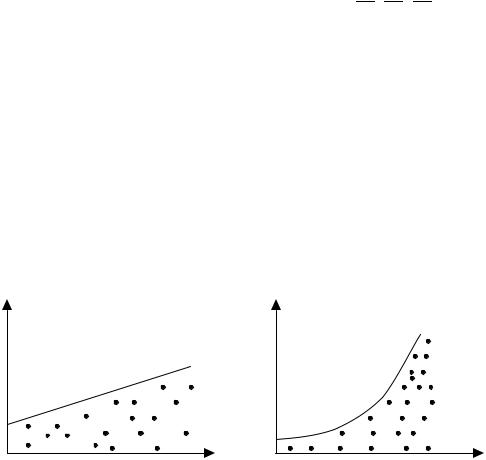
На рис. 8.4, а все отклонения ei2 находятся внутри полуполосы постоянной ширины, параллельной оси абсцисс. Это говорит о независимости дисперсий ei2 от значений переменной Х и их постоянстве, т.е. в этом случае мы находимся в условиях гомоскедастичности.
На рис. 8.4, б − г наблюдаются некие систематические изменения в соотношениях между значениями xi переменной Х и квадратами от-
клонений ei2 . Рис. 8.4, б соответствует примеру из параграфа 8.1. На
рис. 8.4, в отражена линейная; 8.4, г − квадратичная; 8.4, д − гиперболическая зависимости между квадратами отклонений и значениями объясняющей переменной Х. Другими словами, ситуации, представленные на рис. 8.4, б − д, отражают большую вероятность наличия гетероскедастичности для рассматриваемых статистических данных.
Отметим, что графический анализ отклонений является удобным и достаточно надежным в случае парной регрессии. При множественной регрессии графический анализ возможен для каждой из объясняющих переменных Хj , j = 1, 2, …, m отдельно. Чаще же вместо объясняющих переменных Хj по оси абсцисс откладывают значения yi ,
получаемые из эмпирического уравнения регрессии. Поскольку по уравнению множественной линейной регрессии yi является линейной
комбинацией хij , j = 1, 2, … , m, то график, отражающий зависимость ei2 от yi , может указать на наличие гетероскедастичности аналогично
ситуациям на рис. 8.4, б − д. Такой анализ наиболее целесообразен при большом количестве объясняющих переменных.
8.3.2. Тест ранговой корреляции Спирмена
При использовании данного теста предполагается, что дисперсия отклонения будет либо увеличиваться, либо уменьшаться с увеличением значения Х. Поэтому для регрессии, построенной по МНК, абсолютные величины отклонений еi и значения хi СВ Х будут коррелированы. Значения хi и еi ранжируются (упорядочиваются по величинам). Затем определяется коэффициент ранговой корреляции:
|
rx,e = 1− 6 |
∑di2 |
, |
(8.1) |
|
|
n(n2 |
−1) |
|||
где di − разность между рангами хi и ei , i = 1, 2, … , n; n − число наблюдений.
Например, если х20 является 25-м по величине среди всех наблюдений Х; а е20 − является 32-м, то di = 25 − 32= −7.
215
Доказано, что если коэффициент корреляции ρх,е для генеральной совокупности равен нулю, то статистика
|
t = |
rx,e n − 2 |
(8.2) |
|
|
1 − r2 |
|||
|
x,e |
имеет распределение Стьюдента с числом степеней свободы ν = n − 2. Следовательно, если наблюдаемое значение t-статистики, вычисленное по формуле (8.2), превышает tкр. = tα,n−2 (определяемое по таблице критических точек распределения Стьюдента), то необходимо отклонить гипотезу о равенстве нулю коэффициента корреляции ρх,е, а следовательно, и об отсутствии гетероскедастичности. В противном
случае гипотеза об отсутствии гетероскедастичности принимается. Если в модели регрессии больше чем одна объясняющая пере-
менная, то проверка гипотезы может осуществляться с помощью t- статистики для каждой из них отдельно.
8.3.3. Тест Парка
Р. Парк предложил критерий определения гетероскедастичности, дополняющий графический метод некоторыми формальными зависимостями. Предполагается, что дисперсия σi2 = σ2(ei ) является функцией i-го значения хi объясняющей переменной. Парк предложил следующую функциональную зависимость
|
уi2 = у2xвi ev i . |
(8.3) |
|
Прологарифмировав (8.4), получим: |
|
|
lnуi2 = lnу2 + вlnxi + vi . |
(8.4) |
Так как дисперсии уi2 обычно неизвестны, то их заменяют оценками квадратов отклонений ei2 .
|
Критерий Парка включает следующие этапы: |
||
|
1. |
Строится уравнение регрессии yi = b0 + b1xi + еi. |
|
|
2. |
Для каждого наблюдения определяются lnei2 |
) |
|
= ln(yi − yi )2 . |
||
|
3. |
Строится регрессия |
|
|
ln ei2 = α + βlnxi + vi , |
(8.5) |
|
|
где α = lnσ2. |
В случае множественной регрессии зависимость (8.5) строится для каждой объясняющей переменной.
216

4. Проверяется статистическая значимость коэффициента β уравнения
(8.5) на основе t-статистики t = в . Если коэффициент β статисти- Sв
чески значим, то это означает наличие связи между lnei2 и lnxi, т. е. гетероскедастичности в статистических данных.
Отметим, что использование в критерии Парка конкретной функциональной зависимости (8.5) может привести к необоснованным выводам (например, коэффициент β статистически незначим, а гетероскедастичность имеет место). Возможна еще одна проблема. Для случайного отклонения vi в свою очередь может иметь место гетероскедастичность. Поэтому критерий Парка дополняется другими тестами.
8.3.4. Тест Глейзера
Тест Глейзера по своей сути аналогичен тесту Парка и дополняет его анализом других (возможно, более подходящих) зависимостей между дисперсиями отклонений σi и значениями переменной хi. По данному методу оценивается регрессионная зависимость модулей отклонений ei (тесно связанных с σi2) от хi. При этом рассматриваемая зависимость моделируется следующим уравнением регрессии:
|
| ei |= α + βхik + vi . |
(8.6) |
Изменяя значения k, можно построить различные регрессии. Обычно k = …, −1, −0.5, 0.5, 1, … Статистическая значимость коэффициента β в каждом конкретном случае фактически означает наличие гетероскедастичности. Если для нескольких регрессий (8.6) коэффициент β оказывается статистически значимым, то при определении характера зависимости обычно ориентируются на лучшую из них.
Отметим, что так же, как и в тесте Парка, в тесте Глейзера для отклонений vi может нарушаться условие гомоскедастичности. Однако во многих случаях предложенные модели являются достаточно хорошими для определения гетероскедастичности.
8.3.5.Тест Голдфелда−Квандта
Вданном случае также предполагается, что стандартное отклонение σi = σ(εi) пропорционально значению хi переменной Х в этом
наблюдении, т. е. уi2 = у2 xi2 . Предполагается, что εi имеет нормальное распределение и отсутствует автокорреляция остатков.
Тест Голдфелда−Квандта состоит в следующем:
217
1.Все n наблюдений упорядочиваются по величине Х.
2.Вся упорядоченная выборка после этого разбивается на три подвыборки размерностей k, (n − 2k), k соответственно.
3.Оцениваются отдельные регрессии для первой подвыборки (k первых наблюдений) и для третьей подвыборки (k последних наблюдений). Если предположение о пропорциональности дисперсий от-
клонений значениям Х верно, то дисперсия регрессии (сумма квад-
k
ратов отклонений S1 = ∑ei2 ) по первой подвыборке будет сущест-
i=1
венно меньше дисперсии регрессии (суммы квадратов отклонений
n
S3 = ∑ei2 ) по третьей подвыборке.
i=n-k
4.Для сравнения соответствующих дисперсий строится следующая F-статистика:
|
F = |
S3/(k − m − 1) |
= |
S3 . |
(8.7) |
|
S /(k − m − 1) |
S |
|||
|
1 |
1 |
Здесь (k − m − 1) − число степеней свободы соответствующих выборочных дисперсий (m − количество объясняющих переменных в уравнении регрессии).
При сделанных предположениях относительно случайных отклонений построенная F-статистика имеет распределение Фишера с числами степеней свободы ν1 = ν2 = k − m − 1.
|
5. Если Fнабл.= |
S3 |
> Fкр.= F |
, то гипотеза об отсутствии гетероскеда- |
|
|
S1 |
б;н ;н |
|||
|
1 |
2 |
|||
стичности отклоняется (здесь α − выбранный уровень значимости).
Естественным является вопрос, какими должны быть размеры подвыборок для принятия обоснованных решений. Для парной регрессии Голфелд и Квандт предлагают следующие пропорции: n = 30, k = 11; n = 60, k = 22.
Для множественной регрессии данный тест обычно проводится для той объясняющей переменной, которая в наибольшей степени связана с σi. При этом k должно быть больше, чем (m + 1). Если нет уверенности относительно выбора переменной Xj, то данный тест может осуществляться для каждой из объясняющих переменных.
Этот же тест может быть использован при предположении об обратной пропорциональности между σi и значениями объясняющей переменной. При этом статистика Фишера примет вид: F = S1/S3.
218
![]()
8.4. Методы смягчения проблемы гетероскедастичности
Как отмечалось в разделе 8.2, гетероскедастичность приводит к неэффективности оценок, несмотря на их несмещенность. Это может привести к необоснованным выводам по качеству модели. Поэтому при установлении гетероскедастичности возникает необходимость преобразования модели с целью устранения данного недостатка. Вид преобразования зависит от того, известны или нет дисперсии σi2 отклонений εi .
8.4.1. Метод взвешенных наименьших квадратов (ВНК)
Данный метод применяется при известных для каждого наблюдения значениях σi2. В этом случае можно устранить гетероскедастичность, разделив каждое наблюдаемое значение на соответствующее ему значение дисперсии. В этом суть метода взвешенных наименьших квадратов.
Для простоты изложения опишем ВНК на примере парной ре-
|
грессии: |
||||||||||||||||
|
yi = β0 + β1xi + εi . |
(8.8) |
|||||||||||||||
|
Разделим обе части (9.7) на известное σi |
= |
уi2 |
: |
|||||||||||||
|
yi |
= в0 |
1 |
+ в1 |
xi + |
еi |
. |
(8.9) |
|||||||||
|
уi |
уi |
уi |
||||||||||||||
|
уi |
||||||||||||||||
|
Положив |
yi |
= уi* , |
xi |
= |
xi*, |
ei |
= vi, |
1 |
= zi, получим уравнение |
|||||||
|
уi |
||||||||||||||||
|
уi |
уi |
уi |
регрессии без свободного члена, но с дополнительной объясняющей переменной Z и с “преобразованным” отклонением v:
|
уi* =β0zi + β1xi* + vi. |
(8.10) |
При этом для vi выполняется условие гомоскедастичности. Действительно,
уi2 (vi ) = M(vi − M(vi ))2 = M(vi2 ) − M2 (vi ) .
|
Так как по предпосылке 10 МНК M(ei) = 0, то M(vi ) = |
1 |
M(ei ) = 0, и |
||||||||
|
уi2 |
||||||||||
|
тогда уi2 (vi ) = M(vi2 ) = |
||||||||||
|
= M( |
ei2 |
) = |
1 |
M(ei2 ) = |
1 |
M(ei − M(ei ))2 = |
1 |
уi2 = 1 = const. |
||
|
уi2 |
уi2 |
|||||||||
|
уi2 |
уi2 |
219
Следовательно, для преобразованной модели (8.10) выполняются предпосылки 10 − 50 МНК. В этом случае оценки, полученные по МНК, будут наилучшими линейными несмещенными оценками.
Таким образом, метод взвешенных наименьших квадратов включает следующие этапы:
1.Каждую из пар наблюдений (хi , уi) делят на известную величину σi . Тем самым наблюдениям с наименьшими дисперсиями придаются наибольшие “веса”, а с максимальными дисперсиями − наименьшие “веса”. Действительно, наблюдения с меньшими дисперсиями отклонений будут более значимыми при оценке коэффициентов регрессии, чем наблюдения с большими дисперсиями. Учет этого факта увеличивает вероятность получения более точных оценок.
1 2. По МНК для преобразованных значений
уi
уравнение регрессии без свободного члена с гарантированными качествами оценок.
8.4.2. Дисперсии отклонений не известны
Для применения ВНК необходимо знать фактические значения дисперсий уi2 отклонений. На практике такие значения известны крайне редко. Следовательно, чтобы применить ВНК, необходимо сделать реалистические предположения о значениях уi2 .
Например, может оказаться целесообразным предположить, что дисперсии уi2 отклонений εi пропорциональны значениям хi (рис.8.5, а) или значениям хi2 (рис. 8.5, б).
Рис. 8.5
1. Дисперсии σ i2 пропорциональны хi (рис. 8.5, а).
уi2 = σ2 хi (σ2 − коэффициент пропорциональности).
220
Тогда уравнение (8.9) преобразуется делением его левой и правой частей на xi :
|
yi |
= |
a |
+ b |
xi |
+ |
ei |
yi = a |
1 + b xi + vi . |
(8.11) |
|||
|
xi |
||||||||||||
|
xi |
xi |
xi |
xi |
xi |
||||||||
|
Несложно показать, что для случайных отклонений vi = |
ei |
выпол- |
||||||||||
|
xi |
||||||||||||
няется условие гомоскедастичности. Следовательно, для регрессии (8.11) применим обычный МНК. Действительно, в силу выполнимо-
сти предпосылки уi2 = σ2 (εi) = σ2 хi имеем:
|
у2 (vi ) = у2 ( |
еi |
) = |
1 у2 (еi ) = |
1 у2 xi = у2 = const. |
|
xi |
xi |
xi |
Таким образом, оценив для (8.11) по МНК коэффициенты β0 и β1, затем возвращаются к исходному уравнению регрессии (8.8).
Если в уравнении регрессии присутствует несколько объясняющих переменных, можно поступить следующим образом. Вместо кон-
кретной объясняющей переменной Xj используетсяY исходного уравнения множественной линейной регрессии Y = b0 + b1X1 + … + bmXm ,
т. е. фактически линейная комбинация объясняющих переменных. В этом случае получают следующую регрессию:
|
yi |
1 |
xi1 |
xim |
еi |
||||||
|
= в0 |
) |
+ в1 |
) |
+ … + вm |
) |
+ |
. |
(8.12) |
||
|
) |
) |
|||||||||
|
yi |
yi |
yi |
yi |
yi |
Иногда из всех объясняющих переменных выбирается наиболее подходящая, исходя из графического представления (рис. 8.4).
2. Дисперсия σi2 пропорциональна хi2 (рис. 8.4, б).
В случае, если зависимость σi2 от хi целесообразнее выразить не линейной функцией, а квадратичной, то соответствующим преобразованием будет деление уравнения регрессии (8.8) на хi:
|
yi |
= в0 |
1 |
+ в1 + |
еi |
yi |
= в0 |
1 |
+ в1 + vi |
, где vi = |
еi |
. (8.13) |
|
|
xi |
xi |
|||||||||||
|
xi |
xi |
xi |
xi |
По аналогии с вышеизложенным несложно показать, что для отклонений vi будет выполняться условие гомоскедастичности. После определения по МНК оценок коэффициентов β0 и β1 для уравнения (8.13) возвращаются к исходному уравнению (8.8).
221
Отметим, что для применения описанных выше преобразований существенную роль играют знания об истинных значениях дисперсий отклонений σi2, либо предположения, какими эти дисперсии могут быть. Во многих случаях дисперсии отклонений зависят не от включенных в уравнение регрессии объясняющих переменных, а от тех, которые не включены в модель, но играют существенную роль в исследуемой зависимости. В этом случае они должны быть включены в модель. В ряде случаев для устранения гетероскедастичности необходимо изменить спецификацию модели (например, линейную на логлинейную, мультипликативную на аддитивную и т. п.).
В заключение отметим, что наличие гетероскедастичности не позволяет получить эффективные оценки, что зачастую приводит к необоснованным выводам по их качеству. Обнаружение гетероскедастичности — достаточно трудоемкая проблема и для ее решения разработано несколько методов (тестов). В случае установления наличия гетероскедастичности ее корректировка также представляет довольно серьезную проблему. Одним из возможных решений является метод взвешенных наименьших квадратов (при этом необходима определенная информация либо обоснованные предположения о величинах дисперсий отклонений). На практике имеет смысл попробовать несколько методов определения гетероскедастичности и способов ее корректировки (преобразований, стабилизирующих дисперсию).
Вопросы для самопроверки
1.В чем суть гетероскедастичности?
2.Какое из следующих утверждений верно, ложно или не определено:
а) вследствие гетероскедастичности оценки перестают быть эффективными и состоятельными; б) оценки и дисперсии оценок остаются несмещенными;
в) выводы по t- и F-статистикам являются ненадежными;
г) при наличии гетероскедастичности стандартные ошибки оценок будут заниженными; д) гетероскедастичность проявляется через низкое значение статистики Дар-
бина−Уотсона DW;
е) не существует общего теста для анализа гетероскедастичности;
ж) тест ранговой корреляции Спирмена основан на использовании t- статистики; з) тест Парка является частным случаем теста Глейзера;
и) использование метода взвешенных наименьших квадратов носит ограниченный характер, т. к. для его использования необходимо знать дисперсии отклонений;
222
к) если в парной регрессии дисперсия случайных отклонений пропорциональна величине объясняющей переменной (х), то для получения эффективных оценок необходимо все наблюдаемые значения поделить на х.
3.Приведите аргументы в пользу графического теста, теста Парка и теста Глейзера.
4.Приведите схему теста Голдфелда−Квандта.
5.В чем суть метода взвешенных наименьших квадратов (ВНК)?
6.Объясните кратко, почему при наличии гетероскедастичности ВНК позволяет получить более эффективные оценки, чем обычный МНК.
7.Есть основание считать, что в регрессии, построенной по квартальным данным, случайные отклонения в первых кварталах больше, нежели отклонения в других кварталах. Как это можно проверить?
Упражнения и задачи
1.Пусть зависимость заработной платы (Y) от стажа работы (X) сотрудника выражена следующим уравнением регрессии:
Y = β0 + β1X + γD + ε,
где D − фиктивная переменная, отражающая пол сотрудника. Как можно проверить предположение о том, что пол сотрудника не влияет на дисперсию случайных отклонений εi?
2.Приведены данные в условных единицах по доходам (Х) и расходам на непродовольственные товары (Y) для тридцати домохозяйств:
|
X |
26.2 |
33.1 |
42.5 |
47.0 |
48.5 |
49.0 |
49.1 |
50.9 |
52.4 |
53.2 |
|
|
Y |
10.0 |
11.2 |
15.0 |
20.5 |
21.2 |
19.5 |
23.0 |
19.0 |
19.5 |
18.0 |
|
|
Х |
54.0 |
54.8 |
59.0 |
61.3 |
62.5 |
63.1 |
64.0 |
66.2 |
70.0 |
71.5 |
|
|
Y |
24.5 |
21.5 |
35.4 |
25.0 |
17.3 |
21.6 |
15.3 |
32.6 |
34.0 |
23.8 |
|
|
Х |
73.2 |
75.4 |
76.0 |
80.6 |
81.2 |
83.3 |
92.0 |
95.5 |
103.2 |
110.4 |
|
|
Y |
22.5 |
27.4 |
40.0 |
23.5 |
20.0 |
40.1 |
15.5 |
39.0 |
47.4 |
21.3 |
а) Определите по МНК оценки парного уравнения регрессии yi = b0+ b1xi+ ei. б) Оцените качество построенного уравнения.
в) Проведите графический анализ остатков.
г) Примените для указанных статистических данных ВНК предположение,
что σ2(ei) = σ2xi2.
д) Примените к полученным в п. а) результатам тест ранговой корреляции Спирмена и тест Парка.
е) Определите, существенно ли повлияла гетероскедастичность на качество оценок в уравнении, построенном по МНК.
223
|
3. |
Для предприятий некоторой отрасли анализируют зависимость заработной |
||||||||
|
платы (Y) сотрудников в зависимости от масштаба (от количества сотрудни- |
|||||||||
|
ков) предприятия (Х). Наблюдения по тридцати случайно отобранным пред- |
|||||||||
|
приятиям представлены следующей таблицей: |
|||||||||
|
Y |
X |
||||||||
|
75.5 |
75.5 |
77.5 |
78.5 |
80.0 |
81.0 |
100 |
|||
|
80.5 |
82.0 |
84.5 |
85.0 |
85.5 |
86.5 |
200 |
|||
|
85.5 |
88.5 |
90.0 |
91.0 |
95.0 |
96.0 |
300 |
|||
|
93.0 |
93.5 |
97.5 |
99.0 |
102.5 |
105.0 |
400 |
|||
|
102.0 |
105.5 |
107.0 |
110.5 |
115.0 |
118.5 |
500 |
а) Постройте уравнение регрессии Y на Х и оцените его качество.
б) Можно ли ожидать наличие гетероскедастичности в данном случае. Ответ поясните.
в) Проверьте наличие гетероскедастичности, используя тест Голдфелда− Квандта. Рекомендуется использовать разбиение, при котором k = 12.
г) Если предположить, что гетероскедастичность имеет место, и дисперсии отклонений пропорциональны значениям Х, то какое преобразование вы предложите, чтобы получить несмещенные, эффективные и состоятельные оценки.
д) Постройте новое уравнение регрессии на основе преобразования, осуществленного в предыдущем пункте, и оцените его качество.
е) Сравните результаты, полученные в пунктах а) и д).
4. Пусть для эмпирического уравнения парной регрессии Y = b0 + b1X + e име-
ет место следующее соотношение M(ei2) = σ2xi. Какое преобразование можно предложить, чтобы устранить проблему гетероскедастичности. Опишите поэтапно предложенную схему.
5. Пусть для регрессии Y = b0 + b1X1 + b2X2 + e, оцениваемой по ежегодным данным (1971−1998), получены следующие результаты: сумма квадратов от-
клонений для данных 1971−1980 гг. равна S1 = ∑ei2 = 15, для данных 1981−
1998 гг. эта сумма равна S2 = ∑ei2 = 50. С помощью теста Голдфелда−Квандта проверьте предположение о том, что дисперсия отклонений не постоянна (в частности, что дисперсия претерпела изменение где-то в 1981 г.).
6. Анализируется объем инвестиций для вымышленной страны. По данным с 1961 по 1990 г. построены два уравнения регрессии:
|
1) |
it = |
52.5 + 0.275gnpt |
− 0.63ct , |
R2 = 0.98. |
|||||||
|
(t) = (12.5) (10.2) |
(6.4) |
||||||||||
|
2) |
it |
= 50.7 |
1 |
+ |
0.27 − |
0.62 |
ct |
, |
|||
|
gnpt |
gnpt |
gnpt |
|||||||||
|
R2 = 0.87, |
|||||||||||
|
(t) |
(13.3) |
(9.3) |
(6.9) |
224
где GNP − валовой национальный продукт; С − совокупное частное потребление; I − объем инвестиций; gnpt, ct, it − значения соответствующих показателей в момент времени t.
а) Что могло послужить причиной преобразования первого уравнения во второе?
б) Если причиной преобразования являлась гетероскедастичность, то какое предположение о дисперсии отклонений являлось основанием для данного преобразования?
в) Можно ли сравнить качества обоих уравнений на основе коэффициентов детерминации? Ответ поясните.
г) Должно ли преобразованное уравнение проходить через начало координат?
7.Выдвигается предположение, что средняя заработная плата наемных рабочих пропорциональна их стажу. Для анализа данного утверждения обследуются по 20 рабочих восьми категорий стажа. Получены следующие статистические данные:
|
Стаж |
[0, 5) [5, 10) [10, 15) [15, 20) [20, 25) [25, 30) [30, 35) [35, 40] |
|
З/п |
10000 12500 14300 18700 25400 29000 32000 34300 |
а) Постройте эмпирическое уравнение регрессии, в котором заработная плата является зависимой переменной, а стаж работы − объясняющей переменной (уравнение строится в предположение, что дисперсии отклонений постоянны).
б) Оцените качество построенной регрессии.
в) Есть ли основания считать, что для данной регрессионной модели весьма вероятна гетероскедастичность? Если да, то почему?
г) Предполагая, что дисперсия отклонений пропорциональна трудовому стажу, постройте на основании тех же данных уравнение по методу взвешенных наименьших квадратов (ВНК).
д) Предполагая, что дисперсия отклонений пропорциональна квадрату величины трудового стажа, постройте по ВНК соответствующее уравнение регрессии.
е) Какое из трех предположений относительно дисперсии отклонений наиболее реалистично с вашей точки зрения?
8.Исследуется зависимость между доходом (Х) домохозяйства и его расходом
(Y) на продукты питания. Выборочные данные по 40 домохозяйствам представлены ниже.
|
X |
25.5 |
26.5 |
27.2 |
29.6 |
35.7 |
38.6 |
39.0 |
39.3 |
40.0 |
41.9 |
42.5 |
44.2 |
44.8 |
45.5 |
|
Y |
14.5 |
11.3 |
14.7 |
10.2 |
13.5 |
9.9 |
12.4 |
8.6 |
10.3 |
13.9 |
14.9 |
11.6 |
21.5 |
10.8 |
|
Х |
45.5 |
48.3 |
49.5 |
52.3 |
55.7 |
59.0 |
61.0 |
61.7 |
62.5 |
64.7 |
69.7 |
71.2 |
73.8 |
74.7 |
|
Y |
13.8 |
16.0 |
18.2 |
19.1 16.3 |
17.5 |
10.9 |
16.1 |
10.5 |
10.6 |
29.0 |
8.2 |
14.3 |
21.8 |
225

Х 75.8 76.9 79.2 81.5 82.4 82.8 83.0 85.9 86.4 86.9 88.3 89.0
Y 26.1 20.0 19.8 21.2 29.0 17.3 23.5 22.0 18.3 13.7 14.5 27.3
а) Постройте эмпирическое уравнение регрессии Y на Х. б) Вычислите отклонения ei.
в) Проведите анализ модели на гетероскедастичность по тесту ранговой корреляции Спирмена.
г) Проведите графический анализ отклонений и выдвиньте предположение о зависимости дисперсии отклонений от значений Х.
д) На основании предыдущего пункта постройте новое уравнение регрессии, используя для этого ВНК.
9.Проводится анализ зависимости средней заработной платы от средней производительности на предприятиях различного масштаба. Проведенное обследование нашло отражение в следующей таблице.
|
Количество сотрудников |
Средняя |
Средняя |
Стандартное |
|
|
предприятия, |
производительность, |
з/п, |
отклонение з/п, |
|
|
n |
X ($) |
Y ($) |
σi ($) |
|
|
1 |
− 4 |
9320 |
3320 |
740 |
|
4 |
− 9 |
8630 |
3640 |
850 |
|
10 |
− 19 |
8050 |
3900 |
730 |
|
20 |
− 49 |
8320 |
4120 |
820 |
|
50 |
− 99 |
8600 |
4090 |
950 |
|
100 |
− 199 |
9120 |
4200 |
1100 |
|
200 |
− 499 |
9540 |
4380 |
1250 |
|
500 |
− 999 |
9730 |
4500 |
1290 |
|
1000 |
− 1999 |
10120 |
4610 |
1350 |
|
2000 |
− 4999 |
10740 |
4800 |
1100 |
|
> 5000 |
11200 |
5000 |
1520 |
а) Постройте уравнение регрессии yi МНК.
б) Постройте уравнение регрессии yi
уi
= b0 + b1xi + ei, используя обычный
|
= b |
1 |
+ b xi |
+ |
ei |
. |
|
|
уi |
||||||
|
0 |
1 уi |
уi |
в) Сравните полученные результаты. Какое из уравнений вы предпочтете и почему?
226
Соседние файлы в папке ЭКОНОМЕТРИКА и математическая экономика
- #
- #
- #
- #
- #
- #
20.04.20152.55 Mб65Кобелев Н.Б. Практика применения экономико-математических методов и моделей. 2000.djvu
- #
- #
[c.85]
Основные положения теории Шарпа. Коэффициенты регрессии. Измерение ожидаемой доходности и риска портфеля. Дисперсия ошибок. Определение весов ценных бумаг в модели Шарпа. Нахождение оптимального портфеля. Сравнительный анализ методов Г. Марковица и В. Шарпа.
[c.335]
Наиболее хорошо изучены линейные регрессионные модели, удовлетворяющие условиям (1.6), (1.7) и свойству постоянства дисперсии ошибок регрессии, — они называются классическими моделями.
[c.19]
Очевидно, для продвижения к этой цели необходимы некоторые дополнительные предположения относительно характера гетероскедастичности. В самом деле, без подобных предположений, очевидно, невозможно было бы оценить п параметров (п дисперсий ошибок регрессии а ) с помощью п наблюдений.
[c.161]
Решение. Предположим, что дисперсии ошибок о, связаны уравнением регрессии
[c.163]
Вспомним, что наиболее часто употребляемые процедуры устранения гетероскедастичности так или иначе были основаны на предположении, что дисперсия ошибок регрессии ст2 является функцией от каких-то регрессоров. Если а2 существенно зависит от регрессора Z, а при спецификации модели регрессор Z не был включен в модель, стандартные процедуры могут не привести к устранению гетероскедастичности.
[c.250]
В случае постоянства дисперсии ошибок МНК необъясненная дисперсия для меньших значений X должна быть приблизительно равна необъясненной дисперсии для больших значений X, то есть должно быть справедливым следующее равенство [c.125]
Чем ближе к единице отношение / S2, тем больше оснований рассчитывать на то, что дисперсия ошибок МНК постоянна. Случайная величина F = Sl / S2 подчиняется F -распределению
[c.125]
Непостоянство дисперсии ошибок МНК возникает как правило в том случае, если неправильно выбран вид математической модели зависимости фактора X и отклика 7. Например, если нелинейную зависимость пытаются аппроксимировать линейной функцией.
[c.126]
Пятая часть полностью посвящена приложению матричного дифференциального исчисления к линейной регрессионной модели. Она содержит исчерпывающее изложение проблемы оценивания, связанной с неслучайной частью модели при различных предположениях о рангах и других ограничениях. Кроме того, она содержит ряд параграфов, связанных со стохастической частью модели, например оценивание дисперсии ошибок и прогноз ошибок. Включен также небольшой параграф, посвященный анализу чувствительности. Вводная глава содержит необходимые предварительные сведения из теории вероятностей и математической статистики.
[c.16]
Дисперсия ошибок прогноза в задаче (3.6) — (3.7) достигает минимума в точке , являющейся основанием перпендикуляра, опущенного из точки т] на подпространство Q, определяемое равенством (3.7). Соотношение (3.10) эквивалентно равенству
[c.309]
Ограничение (а) не вызывает претензий. Условие (б) также естественно. Ясно, что механизм сглаживания и прогноза, при котором математическое ожидание или дисперсия ошибок фильтрации или интенсивность искусственного рассеивания достаточно велики, вряд ли рационален и тем более не может быть признан оптимальным.
[c.320]
Задача прогнозирования по минимуму дисперсии ошибок при различных статистических характеристиках входных случайных процессов и ошибок измерений подробно обсуждалась в литературе. Имеются и стандартные аналоговые устройства и программы для ЦВМ, реализующие соответствующие схемы. Экстремальная задача, к которой сводится вычисление характеристик генераторов случайных шумов, несомненно, проще исходной вариационной задачи.
[c.334]
Матрица корреляции k j R регулируемых ошибок прогноза, оптимального в смысле показателя качества R( k ), может быть получена из корреляционной матрицы kff a ошибок прогноза, оптимальных в смысле минимума дисперсии ошибок в каждой координате в каждый момент времени, по следующей формуле [c.339]
Из (1.14), в частности, следует, что коэффициент корреляции признаков, на которые наложены ошибки измерения, всегда меньше по абсолютной величине, чем коэффициент корреляции исходных признаков. Другими словами, ошибки измерения всегда ослабляют исследуемую корреляционную связь между исходными переменными, и это искажение тем меньше, чем меньше отношения дисперсий ошибок к дисперсиям самих исходных переменных. Формула (1.14) позволяет скорректировать искаженное значение коэффициента корреляции для этого нужно либо знать разрешающие характеристики измерительных приборов (и, следовательно, величины дисперсий ошибок а и а ), либо провести дополнительное исследование по их выявлению.
[c.73]
Пример 7.4 ]. Известно, что дисперсия о2, вызванная ошибками измерения, при некоторых видах количественного анализа составляет 0,5. Если заменить измерительный прибор и произвести 10-кратное измерение одного и того же стандартного образца, а затем подсчитать дисперсию, то она составит s2 = 0,25. Может показаться, что дисперсия ошибок измерения изменилась, превысив 5%-ный уровень значимости. Так ли это [c.128]
Теорема Гаусса-Маркова. Оценка дисперсии ошибок сг2
[c.41]
Оценка дисперсии ошибок а2
[c.43]
Формулы (2.11), (2.13) дают дисперсии оценок о, Ь коэффициентов регрессии в том случае, если а2 известно. На практике, как правило, дисперсия ошибок а2 неизвестна и оценивается по наблюдениям одновременно с коэффициентами регрессии а, Ь. В этом случае вместо дисперсий оценок о, b мы можем получить лишь оценки дисперсий о, 6, заменив а2 на s2 из (2.15) в (2.11), (2.13), (2.14) [c.45]
Распределение оценки дисперсии ошибок s2
[c.47]
Так как оценка дисперсии ошибок s2 является функцией от остатков регрессии et, то для того чтобы доказать независимость s2 и (2,6), достаточно доказать независимость et и (2,6). Оценки 2, 6 так же, как и остатки регрессии et, являются линейными функциями ошибок t (см. (2.4а), (2.46), (2.20)) и поэтому имеют совместное нормальное распределение. Известно (приложение МС, п. 4, N4), что два случайных вектора, имеющие совместное нормальное распределение, независимы тогда и только тогда, когда они некоррелированы. Таким образом, чтобы доказать независимость s2 и (а, 6), нам достаточно доказать некоррелированность et и (2,6).
[c.48]
Значение Д2 увеличилось по сравнению с первой регрессией. Переход к удельным данным приводит к уменьшению дисперсии ошибок модели.
[c.58]
Пусть SML = Y et/ n и OLS — ] et/ (n — 1 — оценки методов максимального правдоподобия и наименьших квадратов для дисперсии ошибок <т2 в классической модели парной регрессии Yt =
[c.62]
Оценка дисперсии ошибок а1. Распределение s2
[c.72]
Сумма квадратов остатков е2 = е е является естественным кандидатом на оценку дисперсии ошибок а1 (конечно, с некоторым поправочным коэффициентом, зависящим от числа степеней свободы) [c.73]
Тест ранговой корреляции Спирмена использует наиболее общие предположения о зависимости дисперсий ошибок регрессии от значений регрессоров [c.158]
Тест Уайта. Тест ранговой корреляции Спирмена и тест Голдфелда—Квандта позволяют обнаружить лишь само наличие гетероскедастичности, но они не дают возможности проследить количественный характер зависимости дисперсий ошибок регрессии от значений регрессоров и, следовательно, не представляют каких-либо способов устранения гетероскедастичности.
[c.161]
Наиболее простой и часто употребляемый тест на гетероске-дастичность — тест Уайта. При использовании этого теста предполагается, что дисперсии ошибок регрессии представляют собой одну и ту же функцию от наблюдаемых значений регрессоров, т.е.
[c.161]
Другим недостатком тестов Уайта и Глейзера является то, что факт невыявления ими гетероскедастичности, вообще говоря, не означает ее отсутствия. В самом деле, принимая гипотезу Щ, мы принимаем лишь тот факт, что отсутствует определенного вида зависимость дисперсий ошибок регрессии от значений регрессоров.
[c.166]
Построенные экологометрические модели требуют оценки их достоверности. При выполнении статистических исследований полученные данные тщательно анализируются на предмет удовлетворения их предположения о независимости случайных наблюдений, симметричности распределения, из которого получена выборка, равенства дисперсии ошибок, одинаковости распределения нескольких случайных величин и т.д. Все эти предположения могут рассматриваться как гипотезы, которые необходимо проверить.
[c.57]
Доказано (см., например, [37]), что приведенную задачу оптимального стохастического управления можно разделить на две задачу сглаживания и лрогноза по минимуму дисперсии ошибок и задачу оптимального детерминированного управления. При более сложном критерии качества управления и при дополнительных ограничениях на переменные состояния и управляющие параметры такое разделение не всегда удается я, его, по-видимому, не всегда целесообразно производить.
[c.44]
Здесь Paaa(tt, » ) — система функций веса, минимизирующих дисперсию ошибок За(/г-) прогноза W (ti, т) — тождественно не равные нулю функ-22 339
[c.339]
В ходе анализа финансовых данных любой ряд динамики, будь то процентные ставки или цены на финансовые активы, можно разбить на две компоненты, одна из которых изменяется случайным образом, а другая подчиняется определенному закону. Колебания финансовых переменных значительно изменяются во времени бурные периоды с высокой волатильностью переменных сменяют спокойные периоды и наоборот. В некоторых случаях вола-тильность играет ключевую роль в ценообразовании на финансовые активы. В частности, курсы акций напрямую зависят от ожидаемой волатильности доходов корпораций. Все финансовые учреждения без исключения стремятся адекватно оценить волатильность в целях успешного управления рисками. В свое время Трюгве Хаавельмо, нобелевский лауреат по экономике 1989 г., предложил рассматривать изменение экономических переменных как однородный стохастический (случайный) процесс. Вплоть до 1980-х гг. экономисты для анализа финансовых рынков применяли статистические методы, предполагавшие постоянную волатильность во времени. В 1982 г. Роберт Ингл развил новую эконометрическую концепцию, позволяющую анализировать периоды с разной волатильностью. Он ввел кластеризацию данных и условную дисперсию ошибок, которая завесит от времени. Свою разработку Ингл назвал авторегрессионной гетероскедастической моделью , с ее помощью можно точно описать множество временных рядов, встречающихся в экономике. Метод Ингла сегодня применяется финансовыми аналитиками в целях оценки финансовых активов и портфельных рисков.
[c.197]
Отметим, что оценки максимального правдоподобия параметров а, 6 совпадают с оценками метода наименьших квадратов OML = SOLS, ML OLS- Это легко видеть из того, что уравнения (2.37а) и (2.376) совпадают с соответствующими уравнениями метода наименьших квадратов (2.2). Оценка максимального правдоподобия для <т2 не совпадает с
несмещенной оценкой дисперсии ошибок. Таким образом, с = ((п — 2)/n)<7OLS является смещенной, но тем не менее состоятельной оценкой <т2.
[c.57]
В этом разделе мы рассмотрим частный случай обобщенной регрессионной модели, а именно, модель с гетероскедастичностъю, Это означает, что ошибки некоррелированы, но имеют непостоянные дисперсии. (Классическая модель с постоянными дисперсиями ошибок называется гомоскедастичной.) Как уже отмечалось, Гетероскедастичность довольно часто возникает, если анализируемые объекты, говоря нестрого, неоднородны. Например, если исследуется зависимость прибыли предприятия от каких-либо факторов, скажем, от размера основного фонда, то естественно ожидать, что для больших предприятий колебание прибыли будет выше, чем для малых.
[c.168]
It depends on which results and what you mean by valid/invalid.
The coefficients are still a measure of a line going through the center of the data, so the line itself is still meaningful.
The relationship between the mean square error and the variance of the residuals becomes more complicated since there is not a single value that is the variance. But if you can model the variance then you can get a meaningful relationship using weighted regression.
Standard prediction intervals (based on ordinary least squares, not weighted least squares) will be too narrow in some areas and too wide in other areas, so would probably not be considered valid.
Tests and confidence intervals based on the standard assumptions are not going to be exact any more so p-values and confidence intervals will be approximate, whether that approximation is close enough to consider them valid, or potentially bad enough to consider them invalid will depend on the amount the variance varies and your personal preferences. Proper use of weighted least squares (or other methodologies) will help here as well.
It depends on which results and what you mean by valid/invalid.
The coefficients are still a measure of a line going through the center of the data, so the line itself is still meaningful.
The relationship between the mean square error and the variance of the residuals becomes more complicated since there is not a single value that is the variance. But if you can model the variance then you can get a meaningful relationship using weighted regression.
Standard prediction intervals (based on ordinary least squares, not weighted least squares) will be too narrow in some areas and too wide in other areas, so would probably not be considered valid.
Tests and confidence intervals based on the standard assumptions are not going to be exact any more so p-values and confidence intervals will be approximate, whether that approximation is close enough to consider them valid, or potentially bad enough to consider them invalid will depend on the amount the variance varies and your personal preferences. Proper use of weighted least squares (or other methodologies) will help here as well.