Контроль четности и коды коррекции ошибок (ECC).
Ошибки при хранении информации в памяти неизбежны. Они обычно классифицируются как отказы и нерегулярные ошибки (сбои). Если нормально функционирующая микросхема вследствие, например, физического повреждения начинает работать неправильно, то все происходящее и называется постоянным отказом. Чтобы устранить этот тип отказа, обычно требуется заменить некоторую часть аппаратных средств памяти, например неисправную микросхему памяти.
Другой, более коварный тип отказа — нерегулярная ошибка (сбой). Это непостоянный отказ, который не происходит при повторении условий функционирования или через регулярные интервалы.
Приблизительно 20 лет назад сотрудники Intel установили, что причиной сбоев являются альфа-частицы. Поскольку альфа-частицы не могут проникнуть даже через тонкий лист бумаги, выяснилось, что их источником служит вещество, используемое в полупроводниках. При исследовании были обнаружены частицы тория и урана в пластмассовых и керамических корпусах микросхем, применявшихся в те годы. Изменив технологический процесс, производители памяти избавились от этих примесей.
В настоящее время производители памяти почти полностью устранили источники альфачастиц. И многие стали думать, что проверка четности не нужна вовсе. Например, сбои в памяти емкостью 16 Мбайт из-за альфа-частиц случаются в среднем только один раз за 16 лет! Однако сбои памяти происходят значительно чаще.
Сегодня самая главная причина нерегулярных ошибок — космические лучи. Поскольку они имеют очень большую проникающую способность, от них практически нельзя защититься с помощью экранирования.
Эксперимент, проверяющий степень влияния космических лучей на появление ошибок в работе микросхем, показал, что соотношение “сигнал–ошибка” (signal-to-error ratio — SER) для некоторых модулей DRAM составило 5950 единиц интенсивности отказов (failure units — FU) на миллиард часов наработки для каждой микросхемы. Измерения проводились в условиях, приближенных к реальной жизни, с учетом длительности в несколько миллионов машиночасов. В среднестатистическом компьютере это означало бы появление программной ошибки памяти примерно каждые шесть месяцев. В серверных системах или мощных рабочих станциях с большим объемом установленной оперативной памяти подобная статистика указывает на одну ошибку (или даже более) в работе памяти каждый месяц! Когда тестовая система с теми же модулями DIMM была размещена в надежном убежище на глубине более 15 метров каменной породы, что полностью устраняет влияние космических лучей, программные ошибки в работе памяти вообще не были зафиксированы. Эксперимент продемонстрировал не только опасность влияния космических лучей, но и доказал, насколько эффективно устранять влияние альфалучей и радиоактивных примесей в оболочках модулей памяти.
К сожалению, производители ПК не признали это причиной погрешностей памяти; случайную природу сбоя намного легче оправдать разрядом электростатического электричества, большими выбросами мощности или неустойчивой работой программного обеспечения (например, использованием новой версии операционной системы или большой прикладной программы). Исследования показали, что для систем ECC доля программных ошибок в 30 раз больше, чем аппаратных. Это неудивительно, учитывая вредное влияние космических лучей. Количество ошибок зависит от числа установленных модулей памяти и их объема. Программные ошибки могут случаться и раз в месяц, и несколько раз в неделю, и даже чаще!
Хотя космические лучи и радиация являются причиной большинства программных ошибок памяти, существуют и другие факторы:
1. Скачки в энергопотреблении или шум на линии. Причиной может быть неисправный блок питания или настенная розетка.
2. Использование неверного типа или параметра быстродействия памяти. Тип памяти
должен поддерживаться конкретным набором микросхем и обладать определенной
этим набором скоростью доступа.
3. Электромагнитные помехи. Возникают при расположении радиопередатчиков рядом с
компьютером, что иногда приводит к генерированию паразитных электрических сигна-
лов в монтажных соединениях и схемах компьютера. Имейте в виду, что беспроводные
сети, мыши и клавиатуры увеличивают риск появления электромагнитных помех.
4. Статические разряды. Вызывают моментальные скачки в энергоснабжении, что может
повлиять на целостность данных.
5. Ошибки синхронизации. Не поступившие своевременно данные могут стать причиной
появления программных ошибок. Зачастую причина заключается в неверных парамет-
рах BIOS, оперативной памяти, быстродействие которой ниже, чем требуется систе-
мой, “разогнанных” процессорах и прочих системных компонентах.
Большинство описанных проблем не приводят к прекращению работы микросхем памяти (хотя некачественное энергоснабжение или статическое электричество могут физически повредить микросхемы), однако могут повлиять на хранимые данные.
Игнорирование сбоев, конечно, не лучший способ борьбы с ними. К сожалению, именно этот способ сегодня выбрали многие производители компьютеров. Лучше было бы повысить отказоустойчивость систем. Для этого необходимы механизмы определения и, возможно, исправления ошибок в памяти ПК. В основном для повышения отказоустойчивости в современных компьютерах применяются следующие методы:
— контроль четности;
— коды коррекции ошибок (ECC).
Системы без контроля четности вообще не обеспечивают отказоустойчивости данных. Единственная причина, по которой они используются, — их минимальная базовая стоимость. При этом, в отличие от других технологий (ECC и контроль четности), не требуется дополнительная оперативная память.
Байт данных с контролем четности включает в себя 9, а не 8 бит, поэтому стоимость памяти с контролем четности выше примерно на 12,5%. Кроме того, контроллеры памяти, не требующие логических мостов для подсчета данных четности или ECC, обладают упрощенной внутренней архитектурой. Портативные системы, для которых вопрос минимального энергопотребления особенно важен, выигрывают от уменьшенного энергопотребления памяти благодаря использованию меньшего количества микросхем DRAM. И наконец, шина данных памяти без контроля четности имеет меньшую разрядность, что выражается в сокращении количества буферов данных. Статистическая вероятность возникновения ошибок памяти в современных настольных компьютерах составляет примерно одну ошибку в несколько месяцев. При этом количество ошибок зависит от объема и типа используемой памяти. Подобный уровень ошибок может быть приемлемым для обычных компьютеров, не используемых для работы с важными приложениями. В этом случае цена играет основную роль, а дополнительная стоимость модулей памяти с поддержкой контроля четности и кода ECC себя не оправдывает.
Применение не отказоустойчивых к ошибкам компьютеров рискованно и предполагает отсутствие ошибок памяти при эксплуатации систем. При этом также учитывается, что совокупная стоимость потерь, вызванная ошибками в работе памяти, будет меньше, чем затраты на приобретение дополнительных аппаратных устройств для определения таковых ошибок.
Тем не менее ошибки памяти вполне могут стать причиной серьезных проблем: например, представьте себе указание неверного значения суммы в банковском чеке. Ошибки в работе оперативной памяти серверных систем зачастую приводят к “зависанию” последних и отключению всех клиентских компьютеров, соединенных с серверами по локальной сети. Наконец, отследить причину возникновения проблем в компьютерах, не поддерживающих контроль четности или код ECC, крайне сложно. Последние технологии по крайней мере однозначно укажут на оперативную память как на источник проблемы, тем самым экономя время и усилия системных администраторов.
Контроль четности
Это один из стандартов, введенных IBM, в соответствии с которым информация в банках памяти хранится фрагментами по девять битов, причем восемь из них (составляющих один байт) предназначены собственно для данных, а девятый является битом четности (parity). Использование девятого бита позволяет схемам управления памятью на аппаратном уровне контролировать целостность каждого байта данных. Если обнаруживается ошибка, работа компьютера останавливается и на экран выводится сообщение о неисправности.
Технология контроля четности не позволяет исправлять системные ошибки, однако дает возможность их обнаружить пользователю компьютера, что имеет следующие преимущества:
— контроль четности оберегает от последствий проведения неверных вычислений на базе некорректных данных;
— контроль четности точно указывает на источник возникновения ошибок, помогая разобраться с проблемой и улучшая степень эксплутационной надежности компьютера.
Для реализации поддержки памяти с контролем четности или без него не требуется особых усилий. В частности, внедрить поддержку контроля четности для системной платы не составит никакого труда. Основная стоимость внедрения относится к цене самих модулей памяти с контролем четности. Если покупатели нуждаются в контроле четности для работы с определенными приложениями, поставщики компьютеров могут без проблем предложить соответствующие системы.
Компания Intel и прочие производители наборов микросхем системной логики внедрили поддержку контроля четности и кода ECC в большинстве своих продуктов (особенно в наборах микросхем, ориентированных на рынок высокопроизводительных серверов). В то же время наборы микросхем низшей ценовой категории, как правило, не поддерживают эти технологии. Пользователям, требовательным к надежности выполняемых приложений, следует обращать особое внимание на поддержку контроля четности и ECC.
Код коррекции ошибок
Коды коррекции ошибок (Error Correcting Code — ECC) позволяют не только обнаружить ошибку, но и исправить ее в одном разряде. Поэтому компьютер, в котором используются подобные коды, в случае ошибки в одном разряде может работать без прерывания, причем данные не будут искажены. Коды коррекции ошибок в большинстве ПК позволяют только обнаруживать, но не исправлять ошибки в двух разрядах. Но приблизительно 98% сбоев памяти вызвано именно ошибкой в одном разряде, т.е. она успешно исправляется с помощью данного типа кодов. Данный тип ECC получил название SEC)DED (single-bit error-correction double-bit error detection — одноразрядная коррекция, двухразрядное обнаружение ошибок). В кодах коррекции ошибок этого типа для каждых 32 бит требуется дополнительно семь контрольных разрядов при 4-байтовой и восемь — при 8-байтовой организации (64-разрядные процессоры Athlon/Pentium). Реализация кода коррекции ошибок при 4-байтовой организации, очевидно, дороже реализации проверки нечетности или четности, но при 8-байтовой организации стоимость реализации кода коррекции ошибок не превышает стоимости реализации проверки четности.
Для использования кодов коррекции ошибок необходим контроллер памяти, вычисляющий контрольные разряды при операции записи в память. При чтении из памяти такой контроллер сравнивает прочитанные и вычисленные значения контрольных разрядов и при необходимости исправляет испорченный бит (или биты). Стоимость дополнительных логических схем для реализации кода коррекции ошибок в контроллере памяти не очень высока, но это может значительно снизить быстродействие памяти при операциях записи. Это происходит потому, что при операциях записи и чтения необходимо ждать, когда завершится вычисление контрольных разрядов. При записи части слова вначале следует прочитать полное слово, затем перезаписать изменяемые байты и только после этого — новые вычисленные контрольные разряды.
В большинстве случаев сбой памяти происходит в одном разряде, и потому такие ошибки успешно исправляются кодом коррекции ошибок. Использование отказоустойчивой памяти обеспечивает высокую надежность компьютера. Память с кодом ECC предназначена для серверов, рабочих станций или приложений, для которых последствия потенциальных ошибок памяти менее желательны, чем дополнительные затраты на приобретение добавочных модулей памяти и вычислительные затраты на коррекцию ошибок. Если данные имеют особое значение и компьютеры применяются для решения важных задач, без памяти ECC не обойтись. По сути, ни один уважающий себя системный инженер не будет использовать сервер, даже самый неприхотливый, без памяти ECC.
Пользователи имеют выбор между системами без контроля четности, с контролем четности и с ECC, т.е. между желательным уровнем отказоустойчивости компьютера и степенью ценности используемых данных.
Современный жёсткий диск — уникальный компонент компьютера. Он уникален тем, что хранит в себе служебную информацию, изучая которую, можно оценить «здоровье» диска. Эта информация содержит в себе историю изменения множества параметров, отслеживаемых винчестером в процессе функционирования. Больше ни один компонент системного блока не предоставляет владельцу статистику своей работы! Вкупе с тем, что HDD является одним из самых ненадёжных компонентов компьютера, такая статистика может быть весьма полезной и помочь его владельцу избежать нервотрёпки и потери денег и времени.
Информация о состоянии диска доступна благодаря комплексу технологий, называемых общим именем S.M.A.R.T. (Self-Monitoring, Analisys and Reporting Technology, т. е. технология самомониторинга, анализа и отчёта). Этот комплекс довольно обширен, но мы поговорим о тех его аспектах, которые позволяют посмотреть на атрибуты S.M.A.R.T., отображаемые в какой-либо программе по тестированию винчестера, и понять, что творится с диском.
Отмечу, что нижесказанное относится к дискам с интерфейсами SATA и РАТА. У дисков SAS, SCSI и других серверных дисков тоже есть S.M.A.R.T., но его представление сильно отличается от SATA/PATA. Да и мониторит серверные диски обычно не человек, а RAID-контроллер, потому про них мы говорить не будем.
Итак, если мы откроем S.M.A.R.T. в какой-либо из многочисленных программ, то увидим приблизительно следующую картину (на скриншоте приведён S.M.A.R.T. диска Hitachi Deskstar 7К1000.С HDS721010CLA332 в HDDScan 3.3):
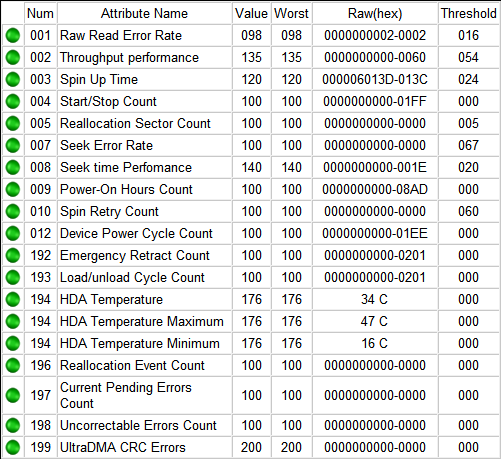
S.M.A.R.T. в HDDScan 3.3
В каждой строке отображается отдельный атрибут S.M.A.R.T. Атрибуты имеют более-менее стандартизованные названия и определённый номер, которые не зависят от модели и производителя диска.
Каждый атрибут S.M.A.R.T. имеет несколько полей. Каждое поле относится к определённому классу из следующих: ID, Value, Worst, Threshold и RAW. Рассмотрим каждый из классов.
- ID (может также именоваться Number) — идентификатор, номер атрибута в технологии S.M.A.R.T. Название одного и того же атрибута программами может выдаваться по-разному, а вот идентификатор всегда однозначно определяет атрибут. Особенно это полезно в случае программ, которые переводят общепринятое название атрибута с английского языка на русский. Иногда получается такая белиберда, что понять, что же это за параметр, можно только по его идентификатору.
- Value (Current) — текущее значение атрибута в попугаях (т. е. в величинах неизвестной размерности). В процессе работы винчестера оно может уменьшаться, увеличиваться и оставаться неизменным. По показателю Value нельзя судить о «здоровье» атрибута, не сравнивая его со значением Threshold этого же атрибута. Как правило, чем меньше Value, тем хуже состояние атрибута (изначально все классы значений, кроме RAW, на новом диске имеют максимальное из возможных значение, например 100).
- Worst — наихудшее значение, которого достигало значение Value за всю жизнь винчестера. Измеряется тоже в «попугаях». В процессе работы оно может уменьшаться либо оставаться неизменным. По нему тоже нельзя однозначно судить о здоровье атрибута, нужно сравнивать его с Threshold.
- Threshold — значение в «попугаях», которого должен достигнуть Value этого же атрибута, чтобы состояние атрибута было признано критическим. Проще говоря, Threshold — это порог: если Value больше Threshold — атрибут в порядке; если меньше либо равен — с атрибутом проблемы. Именно по такому критерию утилиты, читающие S.M.A.R.T., выдают отчёт о состоянии диска либо отдельного атрибута вроде «Good» или «Bad». При этом они не учитывают, что даже при Value, большем Threshold, диск на самом деле уже может быть умирающим с точки зрения пользователя, а то и вовсе ходячим мертвецом, поэтому при оценке здоровья диска смотреть стоит всё-таки на другой класс атрибута, а именно — RAW. Однако именно значение Value, опустившееся ниже Threshold, может стать легитимным поводом для замены диска по гарантии (для самих гарантийщиков, конечно же) — кто же яснее скажет о здоровье диска, как не он сам, демонстрируя текущее значение атрибута хуже критического порога? Т. е. при значении Value, большем Threshold, сам диск считает, что атрибут здоров, а при меньшем либо равном — что болен. Очевидно, что при Threshold=0 состояние атрибута не будет признано критическим никогда. Threshold — постоянный параметр, зашитый производителем в диске.
- RAW (Data) — самый интересный, важный и нужный для оценки показатель. В большинстве случаев он содержит в себе не «попугаи», а реальные значения, выражаемые в различных единицах измерения, напрямую говорящие о текущем состоянии диска. Основываясь именно на этом показателе, формируется значение Value (а вот по какому алгоритму оно формируется — это уже тайна производителя, покрытая мраком). Именно умение читать и анализировать поле RAW даёт возможность объективно оценить состояние винчестера.
Этим мы сейчас и займёмся — разберём все наиболее используемые атрибуты S.M.A.R.T., посмотрим, о чём они говорят и что нужно делать, если они не в порядке.
| Аттрибуты S.M.A.R.T. | |||||||||||||||||
| 01 | 02 | 03 | 04 | 05 | 07 | 08 | 09 | 10 | 11 | 12 | 183 | 184 | 187 | 188 | 189 | 190 | |
| 0x | 01 | 02 | 03 | 04 | 05 | 07 | 08 | 09 | 0A | 0B | 0C | B7 | B8 | BB | BC | BD | BE |
| 191 | 192 | 193 | 194 | 195 | 196 | 197 | 198 | 199 | 200 | 201 | 202 | 203 | 220 | 240 | 254 | ||
| 0x | BF | С0 | С1 | С2 | С3 | С4 | С5 | С6 | С7 | С8 | С9 | СА | CB | DC | F0 | FE |
Перед тем как описывать атрибуты и допустимые значения их поля RAW, уточню, что атрибуты могут иметь поле RAW разного типа: текущее и накапливающее. Текущее поле содержит значение атрибута в настоящий момент, для него свойственно периодическое изменение (для одних атрибутов — изредка, для других — много раз за секунду; другое дело, что в программах чтения S.M.A.R.T. такое быстрое изменение не отображается). Накапливающее поле — содержит статистику, обычно в нём содержится количество возникновений конкретного события со времени первого запуска диска.
Текущий тип характерен для атрибутов, для которых нет смысла суммировать их предыдущие показания. Например, показатель температуры диска является текущим: его цель — в демонстрации температуры в настоящий момент, а не суммы всех предыдущих температур. Накапливающий тип свойственен атрибутам, для которых весь их смысл заключается в предоставлении информации за весь период «жизни» винчестера. Например, атрибут, характеризующий время работы диска, является накапливающим, т. е. содержит количество единиц времени, отработанных накопителем за всю его историю.
Приступим к рассмотрению атрибутов и их RAW-полей.
Атрибут: 01 Raw Read Error Rate
| Тип | текущий, может быть накапливающим для WD и старых Hitachi |
| Описание | содержит частоту возникновения ошибок при чтении с пластин |
Для всех дисков Seagate, Samsung (начиная с семейства SpinPoint F1 (включительно)) и Fujitsu 2,5″ характерны огромные числа в этих полях.
Для остальных дисков Samsung и всех дисков WD в этом поле характерен 0.
Для дисков Hitachi в этом поле характерен 0 либо периодическое изменение поля в пределах от 0 до нескольких единиц.
Такие отличия обусловлены тем, что все жёсткие диски Seagate, некоторые Samsung и Fujitsu считают значения этих параметров не так, как WD, Hitachi и другие Samsung. При работе любого винчестера всегда возникают ошибки такого рода, и он преодолевает их самостоятельно, это нормально, просто на дисках, которые в этом поле содержат 0 или небольшое число, производитель не счёл нужным указывать истинное количество этих ошибок.
Таким образом, ненулевой параметр на дисках WD и Samsung до SpinPoint F1 (не включительно) и большое значение параметра на дисках Hitachi могут указывать на аппаратные проблемы с диском. Необходимо учитывать, что утилиты могут отображать несколько значений, содержащихся в поле RAW этого атрибута, как одно, и оно будет выглядеть весьма большим, хоть это и будет неверно (подробности см. ниже).
На дисках Seagate, Samsung (SpinPoint F1 и новее) и Fujitsu на этот атрибут можно не обращать внимания.
Атрибут: 02 Throughput Performance
| Тип | текущий |
| Описание | содержит значение средней производительности диска и измеряется в каких-то «попугаях». Обычно его ненулевое значение отмечается на винчестерах Hitachi. На них он может изменяться после изменения параметров ААМ, а может и сам по себе по неизвестному алгоритму |
Параметр не даёт никакой информации пользователю и не говорит ни о какой опасности при любом своём значении.
Атрибут: 03 Spin-Up Time
| Тип | текущий |
| Описание | содержит время, за которое шпиндель диска в последний раз разогнался из состояния покоя до номинальной скорости. Может содержать два значения — последнее и, например, минимальное время раскрутки. Может измеряться в миллисекундах, десятках миллисекунд и т. п. — это зависит от производителя и модели диска |
Время разгона может различаться у разных дисков (причём у дисков одного производителя тоже) в зависимости от тока раскрутки, массы блинов, номинальной скорости шпинделя и т. п.
Кстати, винчестеры Fujitsu всегда имеют единицу в этом поле в случае отсутствия проблем с раскруткой шпинделя.
Практически ничего не говорит о здоровье диска, поэтому при оценке состояния винчестера на параметр можно не обращать внимания.
Атрибут: 04 Number of Spin-Up Times (Start/Stop Count)
| Тип | накапливающий |
| Описание | содержит количество раз включения диска. Бывает ненулевым на только что купленном диске, находившемся в запаянной упаковке, что может говорить о тестировании диска на заводе. Или ещё о чём-то, мне не известном 🙂 |
При оценке здоровья не обращайте на атрибут внимания.
Атрибут: 05 Reallocated Sector Count
| Тип | накапливающий |
| Описание | содержит количество секторов, переназначенных винчестером в резервную область. Практически ключевой параметр в оценке состояния |
Поясним, что вообще такое «переназначенный сектор». Когда диск в процессе работы натыкается на нечитаемый/плохо читаемый/незаписываемый/плохо записываемый сектор, он может посчитать его невосполнимо повреждённым. Специально для таких случаев производитель предусматривает на каждом диске (на каких-то моделях — в центре (логическом конце) диска, на каких-то — в конце каждого трека и т. д.) резервную область. При наличии повреждённого сектора диск помечает его как нечитаемый и использует вместо него сектор в резервной области, сделав соответствующие пометки в специальном списке дефектов поверхности — G-list. Такая операция по назначению нового сектора на роль старого называется remap (ремап) либо переназначение, а используемый вместо повреждённого сектор — переназначенным. Новый сектор получает логический номер LBA старого, и теперь при обращении ПО к сектору с этим номером (программы же не знают ни о каких переназначениях!) запрос будет перенаправляться в резервную область.
Таким образом, хоть сектор и вышел из строя, объём диска не изменяется. Понятно, что не изменяется он до поры до времени, т. к. объём резервной области не бесконечен. Однако резервная область вполне может содержать несколько тысяч секторов, и допустить, чтобы она закончилась, будет весьма безответственно — диск нужно будет заменить задолго до этого.
Кстати, ремонтники говорят, что диски Samsung очень часто ни в какую не хотят выполнять переназначение секторов.
На счёт этого атрибута мнения разнятся. Лично я считаю, что если он достиг 10, диск нужно обязательно менять — ведь это означает прогрессирующий процесс деградации состояния поверхности либо блинов, либо головок, либо чего-то ещё аппаратного, и остановить этот процесс возможности уже нет. Кстати, по сведениям лиц, приближенных к Hitachi, сама Hitachi считает диск подлежащим замене, когда на нём находится уже 5 переназначенных секторов. Другой вопрос, официальная ли эта информация, и следуют ли этому мнению сервис-центры. Что-то мне подсказывает, что нет 🙂
Другое дело, что сотрудники сервис-центров могут отказываться признавать диск неисправным, если фирменная утилита производителя диска пишет что-то вроде «S.M.A.R.T. Status: Good» или значения Value либо Worst атрибута будут больше Threshold (собственно, по такому критерию может оценивать и сама утилита производителя). И формально они будут правы. Но кому нужен диск с постоянным ухудшением его аппаратных компонентов, даже если такое ухудшение соответствует природе винчестера, а технология производства жёстких дисков старается минимизировать его последствия, выделяя, например, резервную область?
Атрибут: 07 Seek Error Rate
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок при позиционировании блока магнитных головок (БМГ) |
Описание формирования этого атрибута почти полностью совпадает с описанием для атрибута 01 Raw Read Error Rate, за исключением того, что для винчестеров Hitachi нормальным значением поля RAW является только 0.
Таким образом, на атрибут на дисках Seagate, Samsung SpinPoint F1 и новее и Fujitsu 2,5″ не обращайте внимания, на остальных моделях Samsung, а также на всех WD и Hitachi ненулевое значение свидетельствует о проблемах, например, с подшипником и т. п.
Атрибут: 08 Seek Time Performance
| Тип | текущий |
| Описание | содержит среднюю производительность операций позиционирования головок, измеряется в «попугаях». Как и параметр 02 Throughput Performance, ненулевое значение обычно отмечается на дисках Hitachi и может изменяться после изменения параметров ААМ, а может и само по себе по неизвестному алгоритму |
Не даёт никакой информации пользователю и не говорит ни о какой опасности при любом своём значении.
Атрибут: 09 Power On Hours Count (Power-on Time)
| Тип | накапливающий |
| Описание | содержит количество часов, в течение которых винчестер был включён |
Ничего не говорит о здоровье диска.
Атрибут: 10 (0А — в шестнадцатеричной системе счисления) Spin Retry Count
| Тип | накапливающий |
| Описание | содержит количество повторов запуска шпинделя, если первая попытка оказалась неудачной |
О здоровье диска чаще всего не говорит.
Основные причины увеличения параметра — плохой контакт диска с БП или невозможность БП выдать нужный ток в линию питания диска.
В идеале должен быть равен 0. При значении атрибута, равном 1-2, внимания можно не обращать. Если значение больше, в первую очередь следует обратить пристальное внимание на состояние блока питания, его качество, нагрузку на него, проверить контакт винчестера с кабелем питания, проверить сам кабель питания.
Наверняка диск может стартовать не сразу из-за проблем с ним самим, но такое бывает очень редко, и такую возможность нужно рассматривать в последнюю очередь.
Атрибут: 11 (0B) Calibration Retry Count (Recalibration Retries)
| Тип | накапливающий |
| Описание | содержит количество повторных попыток сброса накопителя (установки БМГ на нулевую дорожку) при неудачной первой попытке |
Ненулевое, а особенно растущее значение параметра может означать проблемы с диском.
Атрибут: 12 (0C) Power Cycle Count
| Тип | накапливающий |
| Описание | содержит количество полных циклов «включение-отключение» диска |
Не связан с состоянием диска.
Атрибут: 183 (B7) SATA Downshift Error Count
| Тип | накапливающий |
| Описание | содержит количество неудачных попыток понижения режима SATA. Суть в том, что винчестер, работающий в режимах SATA 3 Гбит/с или 6 Гбит/с (и что там дальше будет в будущем), по какой-то причине (например, из-за ошибок) может попытаться «договориться» с дисковым контроллером о менее скоростном режиме (например, SATA 1,5 Гбит/с или 3 Гбит/с соответственно). В случае «отказа» контроллера изменять режим диск увеличивает значение атрибута |
Не говорит о здоровье накопителя.
Атрибут: 184 (B8) End-to-End Error
| Тип | накапливающий |
| Описание | содержит количество ошибок, возникших при передаче данных через кэш винчестера |
Ненулевое значение указывает на проблемы с диском.
Атрибут: 187 (BB) Reported Uncorrected Sector Count (UNC Error)
| Тип | накапливающий |
| Описание | содержит количество секторов, которые были признаны кандидатами на переназначение (см. атрибут 197) за всю историю жизни диска. Причём если сектор становится кандидатом повторно, значение атрибута тоже увеличивается |
Ненулевое значение атрибута явно указывает на ненормальное состояние диска (в сочетании с ненулевым значением атрибута 197) или на то, что оно было таковым ранее (в сочетании с нулевым значением 197).
Атрибут: 188 (BC) Command Timeout
| Тип | накапливающий |
| Описание | содержит количество операций, выполнение которых было отменено из-за превышения максимально допустимого времени ожидания отклика |
Такие ошибки могут возникать из-за плохого качества кабелей, контактов, используемых переходников, удлинителей и т. д., а также из-за несовместимости диска с конкретным контроллером SATA/РАТА на материнской плате (либо дискретным). Из-за ошибок такого рода возможны BSOD в Windows.
Ненулевое значение атрибута говорит о потенциальной «болезни» диска.
Атрибут: 189 (BD) High Fly Writes
| Тип | накапливающий |
| Описание | содержит количество зафиксированных случаев записи при высоте полета головки выше рассчитанной — скорее всего, из-за внешних воздействий, например вибрации |
Для того чтобы сказать, почему происходят такие случаи, нужно уметь анализировать логи S.M.A.R.T., которые содержат специфичную для каждого производителя информацию, что на сегодняшний день не реализовано в общедоступном ПО — следовательно, на атрибут можно не обращать внимания.
Атрибут: 190 (BE) Airflow Temperature
| Тип | текущий |
| Описание | содержит температуру винчестера для дисков Hitachi, Samsung, WD и значение «100 − [RAW-значение атрибута 194]» для Seagate |
Не говорит о состоянии диска.
Атрибут: 191 (BF) G-Sensor Shock Count (Mechanical Shock)
| Тип | накапливающий |
| Описание | содержит количество критических ускорений, зафиксированных электроникой диска, которым подвергался накопитель и которые превышали допустимые. Обычно это происходит при ударах, падениях и т. п. |
Актуален для мобильных винчестеров. На дисках Samsung на него часто можно не обращать внимания, т. к. они могут иметь очень чувствительный датчик, который, образно говоря, реагирует чуть ли не на движение воздуха от крыльев пролетающей в одном помещении с диском мухи.
Вообще срабатывание датчика не является признаком удара. Может расти даже от позиционирования БМГ самим диском, особенно если его не закрепить. Основное назначение датчика — прекратить операцию записи при вибрациях, чтобы избежать ошибок.
Не говорит о здоровье диска.
Атрибут: 192 (С0) Power Off Retract Count (Emergency Retry Count)
| Тип | накапливающий |
| Описание | для разных винчестеров может содержать одну из следующих двух характеристик: либо суммарное количество парковок БМГ диска в аварийных ситуациях (по сигналу от вибродатчика, обрыву/понижению питания и т. п.), либо суммарное количество циклов включения/выключения питания диска (характерно для современных WD и Hitachi) |
Не позволяет судить о состоянии диска.
Атрибут: 193 (С1) Load/Unload Cycle Count
| Тип | накапливающий |
| Описание | содержит количество полных циклов парковки/распарковки БМГ. Анализ этого атрибута — один из способов определить, включена ли на диске функция автоматической парковки (столь любимая, например, компанией Western Digital): если его содержимое превосходит (обычно — многократно) содержимое атрибута 09 — счётчик отработанных часов, — то парковка включена |
Не говорит о здоровье диска.
Атрибут: 194 (С2) Temperature (HDA Temperature, HDD Temperature)
| Тип | текущий/накапливающий |
| Описание | содержит текущую температуру диска. Температура считывается с датчика, который на разных моделях может располагаться в разных местах. Поле вместе с текущей также может содержать максимальную и минимальную температуры, зафиксированные за всё время эксплуатации винчестера |
О состоянии диска атрибут не говорит, но позволяет контролировать один из важнейших параметров. Моё мнение: при работе старайтесь не допускать повышения температуры винчестера выше 50 градусов, хоть производителем обычно и декларируется максимальный предел температуры в 55-60 градусов.
Атрибут: 195 (С3) Hardware ECC Recovered
| Тип | накапливающий |
| Описание | содержит количество ошибок, которые были скорректированы аппаратными средствами ECC диска |
Особенности, присущие этому атрибуту на разных дисках, полностью соответствуют таковым атрибутов 01 и 07.
Атрибут: 196 (С4) Reallocated Event Count
| Тип | накапливающий |
| Описание | содержит количество операций переназначения секторов |
Косвенно говорит о здоровье диска. Чем больше значение — тем хуже. Однако нельзя однозначно судить о здоровье диска по этому параметру, не рассматривая другие атрибуты.
Этот атрибут непосредственно связан с атрибутом 05. При росте 196 чаще всего растёт и 05. Если при росте атрибута 196 атрибут 05 не растёт, значит, при попытке ремапа кандидат в бэд-блоки оказался софт-бэдом (подробности см. ниже), и диск исправил его, так что сектор был признан здоровым, и в переназначении не было необходимости.
Если атрибут 196 меньше атрибута 05, значит, во время некоторых операций переназначения выполнялся перенос нескольких повреждённых секторов за один приём.
Если атрибут 196 больше атрибута 05, значит, при некоторых операциях переназначения были обнаружены исправленные впоследствии софт-бэды.
Атрибут: 197 (С5) Current Pending Sector Count
| Тип | текущий |
| Описание | содержит количество секторов-кандидатов на переназначение в резервную область |
Натыкаясь в процессе работы на «нехороший» сектор (например, контрольная сумма сектора не соответствует данным в нём), диск помечает его как кандидат на переназначение, заносит его в специальный внутренний список и увеличивает параметр 197. Из этого следует, что на диске могут быть повреждённые секторы, о которых он ещё не знает — ведь на пластинах вполне могут быть области, которые винчестер какое-то время не использует.
При попытке записи в сектор диск сначала проверяет, не находится ли этот сектор в списке кандидатов. Если сектор там не найден, запись проходит обычным порядком. Если же найден, проводится тестирование этого сектора записью-чтением. Если все тестовые операции проходят нормально, то диск считает, что сектор исправен. (Т. е. был т. н. «софт-бэд» — ошибочный сектор возник не по вине диска, а по иным причинам: например, в момент записи информации отключилось электричество, и диск прервал запись, запарковав БМГ. В итоге данные в секторе окажутся недописанными, а контрольная сумма сектора, зависящая от данных в нём, вообще останется старой. Налицо будет расхождение между нею и данными в секторе.) В таком случае диск проводит изначально запрошенную запись и удаляет сектор из списка кандидатов. При этом атрибут 197 уменьшается, также возможно увеличение атрибута 196.
Если же тестирование заканчивается неудачей, диск выполняет операцию переназначения, уменьшая атрибут 197, увеличивая 196 и 05, а также делает пометки в G-list.
Итак, ненулевое значение параметра говорит о неполадках (правда, не может сказать о том, в само́м ли диске проблема).
При ненулевом значении нужно обязательно запустить в программах Victoria или MHDD последовательное чтение всей поверхности с опцией remap. Тогда при сканировании диск обязательно наткнётся на плохой сектор и попытается произвести запись в него (в случае Victoria 3.5 и опции Advanced remap — диск будет пытаться записать сектор до 10 раз). Таким образом программа спровоцирует «лечение» сектора, и в итоге сектор будет либо исправлен, либо переназначен.
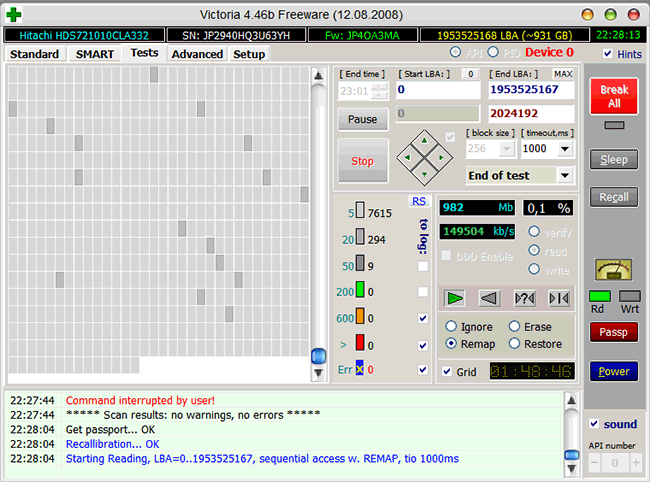
Идёт последовательное чтение с ремапом в Victoria 4.46b
В случае неудачи чтения как с remap, так и с Advanced remap, стоит попробовать запустить последовательную запись в тех же Victoria или MHDD. Учитывайте, что операция записи стирает данные, поэтому перед её применением обязательно делайте бэкап!
Запуск последовательной записи в Victoria 4.46b
Иногда от невыполнения ремапа могут помочь следующие манипуляции: снимите плату электроники диска и почистите контакты гермоблока винчестера, соединяющие его с платой — они могут быть окислены. Будь аккуратны при выполнении этой процедуры — из-за неё можно лишиться гарантии!
Невозможность ремапа может быть обусловлена ещё одной причиной — диск исчерпал резервную область, и ему просто некуда переназначать секторы.
Если же значение атрибута 197 никакими манипуляциями не снижается до 0, следует думать о замене диска.
Атрибут: 198 (С6) Offline Uncorrectable Sector Count (Uncorrectable Sector Count)
| Тип | текущий |
| Описание | означает то же самое, что и атрибут 197, но отличие в том, что данный атрибут содержит количество секторов-кандидатов, обнаруженных при одном из видов самотестирования диска — оффлайн-тестировании, которое диск запускает в простое в соответствии с параметрами, заданными прошивкой |
Параметр этот изменяется только под воздействием оффлайн-тестирования, никакие сканирования программами на него не влияют. При операциях во время самотестирования поведение атрибута такое же, как и атрибута 197.
Ненулевое значение говорит о неполадках на диске (точно так же, как и 197, не конкретизируя, кто виноват).
Атрибут: 199 (С7) UltraDMA CRC Error Count
| Тип | накапливающий |
| Описание | содержит количество ошибок, возникших при передаче по интерфейсному кабелю в режиме UltraDMA (или его эмуляции винчестерами SATA) от материнской платы или дискретного контроллера контроллеру диска |
В подавляющем большинстве случаев причинами ошибок становятся некачественный шлейф передачи данных, разгон шин PCI/PCI-E компьютера либо плохой контакт в SATA-разъёме на диске или на материнской плате/контроллере.
Ошибки при передаче по интерфейсу и, как следствие, растущее значение атрибута могут приводить к переключению операционной системой режима работы канала, на котором находится накопитель, в режим PIO, что влечёт резкое падение скорости чтения/записи при работе с ним и загрузку процессора до 100% (видно в Диспетчере задач Windows).
В случае винчестеров Hitachi серий Deskstar 7К3000 и 5К3000 растущий атрибут может говорить о несовместимости диска и SATA-контроллера. Чтобы исправить ситуацию, нужно принудительно переключить такой диск в режим SATA 3 Гбит/с.
Моё мнение: при наличии ошибок — переподключите кабель с обоих концов; если их количество растёт и оно больше 10 — выбрасывайте шлейф и ставьте вместо него новый или снимайте разгон.
Можно считать, что о здоровье диска атрибут не говорит.
Атрибут: 200 (С8) Write Error Rate (MultiZone Error Rate)
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок при записи |
Ненулевое значение говорит о проблемах с диском — в частности, у дисков WD большие цифры могут означать «умирающие» головки.
Атрибут: 201 (С9) Soft Read Error Rate
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок чтения, произошедших по вине программного обеспечения |
Влияние на здоровье неизвестно.
Атрибут: 202 (СА) Data Address Mark Error
| Тип | неизвестно |
| Описание | содержание атрибута — загадка, но проанализировав различные диски, могу констатировать, что ненулевое значение — это плохо |
Атрибут: 203 (CB) Run Out Cancel
| Тип | текущий |
| Описание | содержит количество ошибок ECC |
Влияние на здоровье неизвестно.
Атрибут: 220 (DC) Disk Shift
| Тип | текущий |
| Описание | содержит измеренный в неизвестных единицах сдвиг пластин диска относительно оси шпинделя |
Влияние на здоровье неизвестно.
Атрибут: 240 (F0) Head Flying Hours
| Тип | накапливающий |
| Описание | содержит время, затраченное на позиционирование БМГ. Счётчик может содержать несколько значений в одном поле |
Влияние на здоровье неизвестно.
Атрибут: 254 (FE) Free Fall Event Count
| Тип | накапливающий |
| Описание | содержит зафиксированное электроникой количество ускорений свободного падения диска, которым он подвергался, т. е., проще говоря, показывает, сколько раз диск падал |
Влияние на здоровье неизвестно.
Подытожим описание атрибутов. Ненулевые значения:
- атрибутов 01, 07, 195 — вызывают подозрения в «болезни» у некоторых моделей дисков;
- атрибутов 10, 11, 188, 196, 199, 202 — вызывают подозрения у всех дисков;
- и, наконец, атрибутов 05, 184, 187, 197, 198, 200 — прямо говорят о неполадках.
При анализе атрибутов учитывайте, что в некоторых параметрах S.M.A.R.T. могут храниться несколько значений этого параметра: например, для предпоследнего запуска диска и для последнего. Такие параметры длиной в несколько байт логически состоят из нескольких значений длиной в меньшее количество байт — например, параметр, хранящий два значения для двух последних запусков, под каждый из которых отводится 2 байта, будет иметь длину 4 байта. Программы, интерпретирующие S.M.A.R.T., часто не знают об этом, и показывают этот параметр как одно число, а не два, что иногда приводит к путанице и волнению владельца диска. Например, «Raw Read Error Rate», хранящий предпоследнее значение «1» и последнее значение «0», будет выглядеть как 65536.
Надо отметить, что не все программы умеют правильно отображать такие атрибуты. Многие как раз и переводят атрибут с несколькими значениями в десятичную систему счисления как одно огромное число. Правильно же отображать такое содержимое — либо с разбиением по значениям (тогда атрибут будет состоять из нескольких отдельных чисел), либо в шестнадцатеричной системе счисления (тогда атрибут будет выглядеть как одно число, но его составляющие будут легко различимы с первого взгляда), либо и то, и другое одновременно. Примерами правильных программ служат HDDScan, CrystalDiskInfo, Hard Disk Sentinel.
Продемонстрируем отличия на практике. Вот так выглядит мгновенное значение атрибута 01 на одном из моих Hitachi HDS721010CLA332 в неучитывающей особенности этого атрибута Victoria 4.46b:
![]()
Атрибут 01 в Victoria 4.46b
А так выглядит он же в «правильной» HDDScan 3.3:
![]()
Атрибут 01 в HDDScan 3.3
Плюсы HDDScan в данном контексте очевидны, не правда ли?
Если анализировать S.M.A.R.T. на разных дисках, то можно заметить, что одни и те же атрибуты могут вести себя по-разному. Например, некоторые параметры S.M.A.R.T. винчестеров Hitachi после определённого периода неактивности диска обнуляются; параметр 01 имеет особенности на дисках Hitachi, Seagate, Samsung и Fujitsu, 03 — на Fujitsu. Также известно, что после перепрошивки диска некоторые параметры могут установиться в 0 (например, 199). Однако подобное принудительное обнуление атрибута ни в коем случае не будет говорить о том, что проблемы с диском решены (если таковые были). Ведь растущий критичный атрибут — это следствие неполадок, а не причина.
При анализе множества массивов данных S.M.A.R.T. становится очевидным, что набор атрибутов у дисков разных производителей и даже у разных моделей одного производителя может отличаться. Связано это с так называемыми специфичными для конкретного вендора (vendor specific) атрибутами (т. е. атрибутами, используемыми для мониторинга своих дисков определённым производителем) и не должно являться поводом для волнения. Если ПО мониторинга умеет читать такие атрибуты (например, Victoria 4.46b), то на дисках, для которых они не предназначены, они могут иметь «страшные» (огромные) значения, и на них просто не нужно обращать внимания. Вот так, например, Victoria 4.46b отображает RAW-значения атрибутов, не предназначенных для мониторинга у Hitachi HDS721010CLA332:
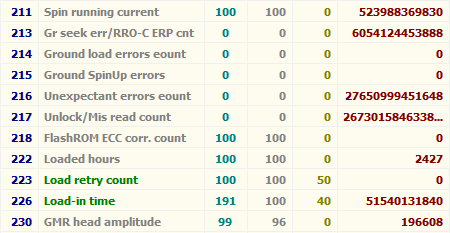
«Страшные» значения в Victoria 4.46b
Нередко встречается проблема, когда программы не могут считать S.M.A.R.T. диска. В случае исправного винчестера это может быть вызвано несколькими факторами. Например, очень часто не отображается S.M.A.R.T. при подключении диска в режиме AHCI. В таких случаях стоит попробовать разные программы, в частности HDD Scan, которая обладает умением работать в таком режиме, хоть у неё и не всегда это получается, либо же стоит временно переключить диск в режим совместимости с IDE, если есть такая возможность. Далее, на многих материнских платах контроллеры, к которым подключаются винчестеры, бывают не встроенными в чипсет или южный мост, а реализованы отдельными микросхемами. В таком случае DOS-версия Victoria, например, не увидит подключённый к контроллеру жёсткий диск, и ей нужно будет принудительно указывать его, нажав клавишу [Р] и введя номер канала с диском. Часто не читаются S.M.A.R.T. у USB-дисков, что объясняется тем, что USB-контроллер просто не пропускает команды для чтения S.M.A.R.T. Практически никогда не читается S.M.A.R.T. у дисков, функционирующих в составе RAID-массива. Здесь тоже есть смысл попробовать разные программы, но в случае аппаратных RAID-контроллеров это бесполезно.
Если после покупки и установки нового винчестера какие-либо программы (HDD Life, Hard Drive Inspector и иже с ними) показывают, что: диску осталось жить 2 часа; его производительность — 27%; здоровье — 19,155% (выберите по вкусу) — то паниковать не стоит. Поймите следующее. Во-первых, нужно смотреть на показатели S.M.A.R.T., а не на непонятно откуда взявшиеся числа здоровья и производительности (впрочем, принцип их подсчёта понятен: берётся наихудший показатель). Во-вторых, любая программа при оценке параметров S.M.A.R.T. смотрит на отклонение значений разных атрибутов от предыдущих показаний. При первых запусках нового диска параметры непостоянны, необходимо некоторое время на их стабилизацию. Программа, оценивающая S.M.A.R.T., видит, что атрибуты изменяются, производит расчёты, у неё получается, что при их изменении такими темпами накопитель скоро выйдет из строя, и она начинает сигнализировать: «Спасайте данные!» Пройдёт некоторое время (до пары месяцев), атрибуты стабилизируются (если с диском действительно всё в порядке), утилита наберёт данных для статистики, и сроки кончины диска по мере стабилизации S.M.A.R.T. будут переноситься всё дальше и дальше в будущее. Оценка программами дисков Seagate и Samsung — вообще отдельный разговор. Из-за особенностей атрибутов 1, 7, 195 программы даже для абсолютно здорового диска обычно выдают заключение, что он завернулся в простыню и ползёт на кладбище.
Обратите внимание, что возможна следующая ситуация: все атрибуты S.M.A.R.T. — в норме, однако на самом деле диск — с проблемами, хоть этого пока ни по чему не заметно. Объясняется это тем, что технология S.M.A.R.T. работает только «по факту», т. е. атрибуты меняются только тогда, когда диск в процессе работы встречает проблемные места. А пока он на них не наткнулся, то и не знает о них и, следовательно, в S.M.A.R.T. ему фиксировать нечего.
Таким образом, S.M.A.R.T. — это полезная технология, но пользоваться ею нужно с умом. Кроме того, даже если S.M.A.R.T. вашего диска идеален, и вы постоянно устраиваете диску проверки — не полагайтесь на то, что ваш диск будет «жить» ещё долгие годы. Винчестерам свойственно ломаться так быстро, что S.M.A.R.T. просто не успевает отобразить его изменившееся состояние, а бывает и так, что с диском — явные нелады, но в S.M.A.R.T. — всё в порядке. Можно сказать, что хороший S.M.A.R.T. не гарантирует, что с накопителем всё хорошо, но плохой S.M.A.R.T. гарантированно свидетельствует о проблемах. При этом даже с плохим S.M.A.R.T. утилиты могут показывать, что состояние диска — «здоров», из-за того, что критичными атрибутами не достигнуты пороговые значения. Поэтому очень важно анализировать S.M.A.R.T. самому, не полагаясь на «словесную» оценку программ.
Хоть технология S.M.A.R.T. и работает, винчестеры и понятие «надёжность» настолько несовместимы, что принято считать их просто расходным материалом. Ну, как картриджи в принтере. Поэтому во избежание потери ценных данных делайте их периодическое резервное копирование на другой носитель (например, другой винчестер). Оптимально делать две резервные копии на двух разных носителях, не считая винчестера с оригинальными данными. Да, это ведёт к дополнительным затратам, но поверьте: затраты на восстановление информации со сломавшегося HDD обойдутся вам в разы — если не на порядок-другой — дороже. А ведь данные далеко не всегда могут восстановить даже профессионалы. Т. е. единственная возможность обеспечить надёжное хранение ваших данных — это делать их бэкап.
Напоследок упомяну некоторые программы, которые хорошо подходят для анализа S.M.A.R.T. и тестирования винчестеров: HDDScan (работает в Windows, бесплатная), CrystalDiskInfo (Windows, бесплатная), Hard Disk Sentinel (платная для Windows, бесплатная для DOS), HD Tune (Windows, платная, есть бесплатная старая версия).
И наконец, мощнейшие программы для тестирования: Victoria (Windows, DOS, бесплатная), MHDD (DOS, бесплатная).
Содержание:
- Что такое SMART и что он показывает?
- Ошибки S.M.A.R.T.
- Примеры ошибок SMART.
- Как исправить SMART ошибку?
- Как отключить проверку SMART?
- Что делать если данные были утеряны?
Средство S.M.A.R.T., показывающее ошибки жесткого диска (HDD или SSD) является сигналом того, что с накопителем случились какие-то неполадки, влияющие на стабильность и работу компьютера.
Помимо этого, такая ошибка – серьезный повод задуматься о сохранности своих важных данных, поскольку из-за проблемного накопителя можно попросту лишиться всей информации, которую практически невозможно восстановить.
Как правило, система тестирования жестких дисков SMART работает незаметно, как бы за кулисами. Если она обнаруживает серьезную проблему, то загрузка компьютера может быть приостановлена, чтобы отобразить предупреждение. Операционная система Windows не включает инструмент для ручного мониторинга или тестирования вашего диска с помощью SMART, но некоторые производители компьютеров, например Toshiba, Dell или HP предустанавливают небольшую диагностическую утилиту, которая проверяет уровни контролируемых атрибутов SMART, обеспечивая надзор за здоровьем привода. Если на вашем компьютере нет подобной утилиты тестирования и вы хотите проверить здоровье своего харда — загрузите тестовую программу, например DiskSmartView, SpeedFan или Smartmontools.
Что такое SMART и что он показывает?
«S.M.A.R.T.» расшифровывается как «self-monitoring, analysis and reporting technology», что в переводе означает «технология самодиагностики, анализа и отчетности».
Каждый жесткий диск, подключённый через интерфейс SATA или ATA, имеет встроенную систему S.M.A.R.T., которая позволяет выполнять следующие функции:
- Проводить анализ накопителя.
- Исправлять программные проблемы с HDD.
- Сканировать поверхность жесткого диска.
- Проводить программное исправление, очистку или замену поврежденных блоков.
- Выставлять оценки жизненноважным характеристикам диска.
- Вести отчётность о всех параметрах жесткого диска.
Система S.M.A.R.T. позволяет давать пользователю полную информацию о физическом состоянии жесткого диска методом выставления оценок, при помощи которых можно рассчитать примерное время выхода HDD из строя. С данной системой можно лично ознакомиться, воспользовавшись программой Victoria или другими аналогами.
С тем, как работать, проверять и исправлять ошибки жесткого диска в программе Victoria, Вы можете ознакомиться в статье «Как протестировать и исправить жесткий диск используя бесплатную программу Victoria».
Центр компьютерной помощи «1 2 3»
S.M.A.R.T. (от англ. self-monitoring, analysis and reporting technology — технология самоконтроля, анализа и отчётности) — технология оценки состояния жёсткого диска встроенной аппаратурой самодиагностики, а также механизм предсказания времени выхода его из строя.
SMART производит наблюдение за основными характеристиками накопителя, каждая из которых получает оценку. Характеристики можно разбить на 2 основные группы:
- параметры, отражающие процесс естественного старения жёсткого диска (число оборотов шпинделя, число перемещений головок, количество циклов включения-выключения);
- текущие параметры накопителя (высота головок над поверхностью диска, число переназначенных секторов, время поиска дорожки и количество ошибок поиска).
Данные хранятся в шестнадцатеричном виде, называемом «raw value», а потом пересчитываются в обычное десятичное «value» — значение, символизирующее надёжность относительно некоторого эталонного значения. Обычно «value» располагается в диапазоне от 0 до 100 (некоторые атрибуты имеют значения от 0 до 200 или до 253).
Высокая оценка говорит об отсутствии изменений данного параметра или медленном его ухудшении. Низкая говорит о возможном скором сбое. Значение, меньшее, чем минимальное, при котором производителем гарантируется безотказная работа накопителя, означает выход узла из строя.
В таблице ниже перечислены основные параметры S.M.A.R.T. и их расшифровка. Красным цветом выделены наиболее важные и критичные для оптимального функционирования винчестера параметры.
| # | hex | атрибут | оптимально | описание |
| 1 | 1 | Raw Read Error Rate | Частота ошибок при чтении данных с пластин диска по вине аппаратной части накопителя. Для всех дисков Seagate, Samsung (начиная с семейства SpinPoint F1 включительно) и Fujitsu 2,5″ это — число внутренних коррекций данных, проведенных до выдачи в интерфейс. Таким образом, ненулевой параметр на дисках WD и Samsung до SpinPoint F1 (невключительно) и большое значение параметра на дисках Hitachi могут указывать на аппаратные проблемы с диском. На дисках Seagate, Samsung (SpinPoint F1 и новее) и Fujitsu на этот атрибут можно не обращать внимания. | |
| 2 | 2 | Throughput Performance | Общая (средняя) производительность диска. Параметр не даёт никакой информации пользователю и не говорит ни о какой опасности при любом своём значении. | |
| 3 | 3 | Spin-Up Time | Время раскрутки шпинделя диска из состояния покоя до номинальной рабочей скорости. Практически ничего не говорит о здоровье диска. Время разгона может различаться у разных дисков (даже одного и того же производителя) в зависимости от тока раскрутки, массы блинов, номинальной скорости шпинделя и т.п. Винчестеры Fujitsu всегда имеют 1 в этом поле в случае отсутствия проблем с раскруткой шпинделя. | |
| 4 | 4 | Number of Spin-Up Times Start/Stop Count | Полное число циклов включения диска (запуска-остановки шпинделя). У дисков некоторых производителей (например, Seagate) — счётчик включения режима энергосбережения. При оценке здоровья можно не обращать на этот атрибут значительного внимания. | |
| 5 | 5 | Reallocated Sectors Count | Количество секторов, переназначенных в случае обнаружения винчестером ошибки чтения/записи в резервную область. Поэтому на современных жёстких дисках нельзя увидеть bad-блоки — все они спрятаны в переназначенных секторах. Чем больше это значение, тем хуже состояние поверхности дисков. При достижении определённого порогового значения (например, 10 ремапов) диск нужно обязательно менять, ведь это означает прогрессирующую деградацию состояния поверхности блинов, головок или другие аппаратные проблемы. | |
| 6 | 6 | Read Channel Margin | Запас канала чтения. Назначение этого атрибута не документировано — в современных накопителях не используется. | |
| 7 | 7 | Seek Error Rate | Частота появления ошибок позиционирования блока магнитных головок. Чем их больше, тем хуже состояние механики и/или поверхности жёсткого диска. Также на значение параметра может повлиять перегрев и внешние вибрации (например, от соседних дисков в корзине). На дисках Seagate, Samsung SpinPoint F1 и новее и Fujitsu 2,5″ на значение атрибута можно не обращать внимание, на остальных моделях Samsung, а также на всех WD и Hitachi ненулевое значение свидетельствует об аппаратных проблемах. Для винчестеров Hitachi нормальным значением является только 0. | |
| 8 | 8 | Seek Time Performance | Средняя производительность операций позиционирования магнитных головок. Не даёт никакой информации пользователю и не говорит ни о какой опасности при любом своём значении. | |
| 9 | 9 | Power On Hours Count Power-on Time |
Число часов (минут, секунд — в зависимости от производителя), проведённых винчестером во включенном состоянии. В качестве порогового значения для него выбирается паспортное время наработки на отказ (MTBF — mean time between failure). Ничего не говорит о здоровье диска как таковом. | |
| 10 | 0A | Spin-Up Retry Count | Число повторных попыток раскрутки шпинделя диска до рабочей скорости в случае, если первая попытка оказалась неудачной. О здоровье диска чаще всего не говорит. Если значение атрибута увеличивается, то велика вероятность неполадок с механической частью. Основные причины увеличения параметра — плохой контакт диска с БП или невозможность БП выдать нужный ток в линию питания диска. В идеале должен быть равен 0. При значении атрибута, равном 1-2, внимания можно не обращать. Если значение больше, в первую очередь следует обратить пристальное внимание на состояние блока питания, его качество, нагрузку на него, проверить контакт винчестера с кабелем питания, проверить сам кабель питания. | |
| 11 | 0B | Calibration Retry Count Recalibration Retries |
Количество повторов запросов сброса накопителя (рекалибровки) в случае, если первая попытка была неудачной. Ненулевое, а особенно растущее значение параметра может означать проблемы с диском. | |
| 12 | 0C | Power Cycle Count | Количество полных циклов включения-выключения диска. Не связан с состоянием диска. | |
| 13 | 0D | Soft Read Error Rate | Число ошибок при чтении, по вине программного обеспечения, которые не поддались исправлению. Все ошибки имеют не механическую природу и указывают лишь на неправильную размётку/взаимодействие с диском программ или операционной системы. | |
| 183 | B7 | SATA Downshift Error Count | Количество неудачных попыток понижения режима SATA. Суть в том, что винчестер, работающий в режимах SATA 3 Гбит/с или 6 Гбит/с, по какой-то причине (например, из-за ошибок) может попытаться понизить скоростной режим (например, SATA 1,5 Гбит/с или 3 Гбит/с соответственно). В случае отказа контроллера изменять режим диск увеличивает значение этого атрибута. Не говорит о здоровье накопителя. | |
| 184 | B8 | End-to-End Error | Количество ошибок, возникших при передаче данных через кэш винчестера в случае, если паритет данных между хостом и жестким диском не совпадает. Ненулевое значение указывает на проблемы с диском. | |
| 187 | BB | Reported Uncorrected Sector Count UNC Error |
Количество секторов, которые были признаны кандидатами на переназначение за всю историю жизни диска. Причём если сектор становится кандидатом повторно — значение атрибута также увеличивается. Ненулевое значение атрибута явно указывает на ненормальное состояние диска или на то, что оно было таковым ранее (в сочетании с нулевым значением 197). | |
| 188 | BC | Command Timeout | Количество операций, выполнение которых было отменено из-за превышения максимально допустимого времени ожидания отклика. Такие ошибки могут возникать из-за плохого качества кабелей, контактов, используемых переходников, удлинителей и т.д., а также из-за несовместимости диска с конкретным контроллером SATA/РАТА. Из-за ошибок такого рода возможны «синие экраны смерти» в Windows. Ненулевое значение атрибута говорит о потенциальной «болезни» диска. | |
| 189 | BD | High Fly Writes | Количество зафиксированных случаев записи при высоте полета головки выше рассчитанной (скорее всего, из-за внешних воздействий, например вибрации). Для того, чтобы сказать, почему происходят такие случаи, нужно уметь анализировать логи SMART, которые содержат специфичную для каждого производителя информацию, что на сегодняшний день не реализовано в общедоступном ПО. | |
| 190 | BE | Airflow Temperature | Температура воздуха внутри корпуса жёсткого диска. Для дисков Seagate рассчитывается по формуле (100 — HDA Temperature). Для дисков Western Digital — (125 — HDA Temperature). | |
| 191 | BF | G-Sensor Shock Count Mechanical Shock |
Количество критических ускорений (ударных нагрузок), зафиксированных электроникой диска, которым подвергался накопитель и которые превышали допустимые. Обычно это происходит при ударах, падениях и т. п. Атрибут хранит показания встроенного акселерометра, который фиксирует все удары, толчки, падения и даже неаккуратную установку диска в корпус компьютера. Актуален для мобильных винчестеров. На дисках Samsung на него часто можно не обращать внимания, т.к. они могут иметь очень чувствительный датчик, который, образно говоря, реагирует чуть ли не на движение воздуха от крыльев пролетающей в одном помещении с диском мухи. | |
| 192 | C0 | Power Off Retract Count Emergency Retry Count |
Для разных винчестеров может содержать одну из следующих двух характеристик: либо суммарное количество парковок диска в аварийных ситуациях (по сигналу от вибродатчика, обрыву/понижению питания и т.п.), либо суммарное количество циклов включения/выключения питания диска (характерно для современных WD и Hitachi). | |
| 193 | C1 | Load/Unload Cycle Count | Количество полных циклов парковки/распарковки магнитных головок диска. Анализ этого атрибута — один из способов определить, включена ли на диске функция автоматической парковки (например, у дисков Western Digital). Если значение атрибута превосходит (обычно — многократно) значение атрибута 09 (счётчик отработанных часов), то парковка включена. | |
| 194 | C2 | Temperature HDA Temperature HDD Temperature |
Текущая температура диска, считываемая с датчика, который на разных моделях может располагаться в разных местах. Поле вместе с текущей также может содержать максимальную и минимальную температуры, зафиксированные за всё время эксплуатации винчестера. При работе старайтесь не допускать повышения температуры винчестера выше 50 градусов. | |
| 195 | C3 | Hardware ECC Recovered | Число коррекции ошибок аппаратной частью диска (чтение, позиционирование, передача по внешнему интерфейсу). На дисках с SATA-интерфейсом значение нередко ухудшается при повышении частоты системной шины — SATA очень чувствителен к разгону. Особенности, присущие этому атрибуту на разных дисках, полностью соответствуют таковым атрибутов 01 и 07. | |
| 196 | C4 | Reallocation Event Count | Количество операций переназначения секторов. В поле «raw value» атрибута хранится общее число попыток переноса информации с переназначенных секторов в резервную область. Учитываются как успешные, так и неуспешные попытки. Косвенно говорит о здоровье диска. Чем больше значение — тем хуже. Однако нельзя однозначно судить о здоровье диска по этому параметру, не рассматривая другие атрибуты. | |
| 197 | C5 | Current Pending Sector Count | Количество секторов, являющихся кандидатами на переназначение в резервную область. Они не были ещё определены как плохие, но скорость считывания с них отличается от чтения стабильного сектора (это так называемые подозрительные или нестабильные секторы). В случае успешного последующего прочтения сектора он исключается из числа кандидатов. В случае повторных ошибочных чтений накопитель пытается восстановить его и выполняет операцию переназначения. Рост значения этого атрибута может свидетельствовать о физической деградации жёсткого диска. При ненулевом значении нужно обязательно запустить в программах Victoria или MHDD последовательное чтение всей поверхности с опцией remap. Тогда при сканировании диск обязательно наткнётся на плохой сектор и попытается произвести запись в него (в случае Victoria 3.5 и опции Advanced remap диск будет пытаться записать сектор до 10 раз). Таким образом программа спровоцирует «лечение» сектора, и в итоге он будет либо исправлен, либо переназначен. | |
| 198 | C6 | (Offline) Uncorrectable Sector Count | Количество секторов-кандидатов на переназначение, обнаруженных при одном из видов самотестирования диска — оффлайн-тестировании, которое диск запускает в простое в соответствии с параметрами, заданными прошивкой. Ненулевое значение говорит о неполадках на диске (точно так же, как и с параметром 197). | |
| 199 | C7 | UltraDMA CRC Error Count | Число ошибок, возникающих при передаче данных по по интерфейсному кабелю в режиме UltraDMA или его эмуляции винчестерами SATA (нарушения целостности пакетов и т. п.). В подавляющем большинстве случаев причинами ошибок становятся некачественный шлейф передачи данных, разгон шин PCI/PCI-E либо плохой контакт в SATA-разъёме на диске или на материнской плате/контроллере. Для Hitachi серий Deskstar 7К3000 и 5К3000 растущий атрибут может говорить о несовместимости диска и SATA-контроллера. Чтобы исправить ситуацию, нужно принудительно переключить такой диск в режим SATA 3 Гбит/с. | |
| 200 | C8 | Write Error Rate Multi-Zone Error Rate |
Частота возникновения ошибок записи. Ненулевое значение говорит о проблемах с диском — в частности, у дисков WD большие цифры могут означать деградирующие головки. | |
| 201 | C9 | Soft Read Error Rate | Частота появления ошибок чтения по вине программного обеспечения. | |
| 202 | CA | Data Address Mark Errors | Число ошибок Data Address Mark (DAM). Ненулевое значение — это плохо | |
| 203 | CB | Run Out Cancel | Количество ошибок ECC. | |
| 204 | CC | Soft ECC Correction | Количество ошибок ECC, скорректированных программным способом. | |
| 205 | CD | Thermal Asperity Rate (TAR) | Number of thermal asperity errors. | |
| 206 | CE | Flying Height | Высота между головкой и поверхностью диска. | |
| 207 | CF | Spin High Current | Величина силы тока при раскрутке диска. | |
| 208 | D0 | Spin Buzz | Number of buzz routines to spin up the drive. | |
| 209 | D1 | Offline Seek Performance | Производительность поиска во время оффлайновых операций. | |
| 220 | DC | Disk Shift | Дистанция смещения блока пластин диска относительно оси шпинделя. В основном возникает из-за удара или падения. Единица измерения неизвестна. При увеличении атрибута диск быстро становится неработоспособным. | |
| 221 | DD | G-Sense Error Rate | Число ошибок, возникших из-за внешних нагрузок и ударов. Атрибут хранит показания встроенного датчика удара. | |
| 222 | DE | Loaded Hours | Время, проведённое блоком магнитных головок между выгрузкой из парковочной области в рабочую область диска и загрузкой блока обратно в парковочную область. | |
| 223 | DF | Load/Unload Retry Count | Количество новых попыток выгрузок/загрузок блока магнитных головок в/из парковочной области после неудачной попытки. | |
| 224 | E0 | Load Friction | Величина силы трения блока магнитных головок при его выгрузке из парковочной области. | |
| 225 | E1 | Load Cycle Count | Количество циклов перемещения блока магнитных головок в парковочную область. | |
| 226 | E2 | Load ‘In’-time | Время, за которое привод выгружает магнитные головки из парковочной области на рабочую поверхность диска. | |
| 227 | E3 | Torque Amplification Count | Количество попыток скомпенсировать вращающий момент. | |
| 228 | E4 | Power-Off Retract Cycle | Количество повторов автоматической парковки блока магнитных головок в результате выключения питания. | |
| 230 | E6 | GMR Head Amplitude | Амплитуда дрожания (расстояние повторяющегося перемещения блока магнитных головок). | |
| 231 | E7 | Temperature | Температура жёсткого диска. | |
| 240 | F0 | Head Flying Hours | Время, затраченное на позиционирования головки. Счётчик может содержать несколько значений в одном поле. | |
| 250 | FA | Read Error Retry Rate | Число ошибок во время чтения жёсткого диска. | |
| 254 | FF | Free Fall Event Count | Количество ускорений свободного падения диска, которым он подвергался (проще говоря, показывает, сколько раз диск падал). |
Ошибки S.M.A.R.T.
Как правило, в нормально работающем накопителе система S.M.A.R.T. не выдает никаких ошибок даже при невысоких оценках. Это обусловлено тем, что появление ошибок является сигналом возможной скорой поломки диска.
Ошибки S.M.A.R.T. всегда свидетельствуют о какой-либо неисправности или о том, что некоторые элементы диска практически исчерпали свой ресурс. Если пользователю стали демонстрироваться подобные сообщения, следует задуматься о сохранности своих данных, поскольку теперь они могут исчезнуть в любой момент!
Топ 20 бесплатных инструментов мониторинга дисков
В посте собран перечень 20 лучших бесплатных инструментов разбивки, диагностики, шифрования, восстановления, клонирования, форматирования дисков. Вообщем практически все что нужно для базовой работы с ними.
TestDisk
TestDisk позволяет восстанавливать загрузочные разделы, удаленные разделы, фиксировать поврежденные таблицы разделов и восстанавливать данные, а также создавать копии файлов с удаленных/недоступных разделов.
Примечание: PhotoRec ето связанное с TestDisk приложением. С его помощью возможно восстановить данные в памяти цифровой камеры на жестких дисках и компакт-дисках. Кроме того можно восстановить основные форматы изображений, аудиофайлы, текстовые документы, HTML-файлы и различные архивы.

При запуске TestDisk предоставляется список разделов жесткого диска, с которыми можно работать. Выбор доступных действий, осуществляемых в разделах, включает: анализ для корректировки структуры (и последующее восстановление, в случае обнаружения проблемы); изменение дисковой геометрии; удаление всех данных в таблице разделов; восстановление загрузочного раздела; перечисление и копирование файлов; восстановление удаленных файлов; создание снапшота раздела.
EaseUS Partition Master
EaseUS Partition Master — инструмент для работы с разделами жесткого диска. Он позволяет создавать, перемещать, объединять, разделять, форматировать, изменяя их размер и расположение без потери данных. Также помогает восстанавливать удаленные или потерянные данные, проверять разделы, перемещать ОС на другой HDD/SSD и т.д.

Слева представлен перечень операций, которые можно выполнить с выбранным разделом.
WinDirStat
Бесплатная программа WinDirStat проводит анализ использованного места на диске. Демонстрирует, как данные распределяются и какие из них занимают больше места.
Клик по полю в диаграмме выведет на экран рассматриваемый файл в структурном виде.

После загрузки WinDirStat и выбора дисков для анализа, программа сканирует дерево каталога и предоставляет статистику в таких вариантах: список каталогов; карта каталогов; список расширений.
Clonezilla
Clonezilla создает образ диска с инструментом клонирования, который также упакован с Parted Magic и первоначально доступен, как автономный инструмент. Представлен в двух версиях: Clonezilla Live и Clonezilla SE (Server Edition).

Clonezilla Live является загрузочным дистрибутивом Linux, позволяющим клонировать отдельные устройства. Clonezilla SE — это пакет, который устанавливается на дистрибутиве Linux. Он используется для одновременного клонирования множества компьютеров по сети.
OSFMount
Использование данной утилиты дает возможность монтировать ранее сделанные образы дисков и представлять их в виде виртуальных приводов, непосредственно просмотривая сами данные. OSFMount поддерживает файлы образов, такие как: DD, ISO, BIN, IMG, DD, 00n, NRG, SDI, AFF, AFM, AFD и VMDK.

Дополнительная функция OSFMount — создание RAM-дисков, находящихся в оперативной памяти компьютера, что существенно ускоряет работу с ними. Для запуска процесса нужно перейти в File > Mount new virtual disk.
Ошибка «SMART failure predicted»

В данном случае S.M.A.R.T. оповещает пользователя о скором выходе диска из строя. Важно: если Вы увидели такое сообщение на своем компьютере, срочно скопируйте всю важную информацию и файлы на другой носитель, поскольку данный жесткий диск может прийти в негодность в любой момент!
Сколько записывается на SSD
В следующей таблице я свел данные об использовании SSD, до которых дотянулись руки. Они эксплуатируются в одном настольном ПК и трех разных ноутбуках. Никто их не бережет и не жалеет, файлы подкачки не отключает, временные файлы не переносит. Оба 840 Pro служат системными дисками и хранят личные файлы (кроме видео), Kingston – это полигон для виртуальных машин и второй файл подкачки, а Crucial выступал даже хранилищем фильмов.
| Samsung 840 Pro 256GB | Samsung 840 Pro 256GB | Samsung 840 EVO 120GB | Kingston Hyper-X 3K 120GB | Crucial MX100 256GB | PLEXTOR 128M5Pro 128GB | |
| Текущий срок службы диска (лет) | 2.25 | 2.25 | 2 | 3.25 | 1.25 | 2.25 |
| Применено мифов | 0 | 0 | 0 | 0 | 0 | 0 |
| Запись всего | 7.3TB | 5.0TB | 1.6TB | 5.5TB | 4.1TB | 5.7TB |
| Запись в год | 3.2TB | 2.2TB | 0.8TB | 1.7TB | 3.3TB | 2.5TB |
| Запись в день | 9GB | 6GB | 2GB | 5GB | 9GB | 7GB |
| Ресурс NAND диска (лет) | 22.8 | 33.2 | — | 45.3 | 21.8 | — |
Износ флэш-памяти – это последнее, от чего умрут диски из таблицы. Им гарантируется 20-40GB записи в день, но ни один даже до 10GB не дотягивает! А ведь у современных SSD гарантийные объемы еще выше.
Как исправить SMART ошибку?
Ошибки S.M.A.R.T. свидетельствуют о скорой поломке жесткого диска, поэтому исправление ошибок, как правило, не приносит должного результата, и ошибка остается. Помимо критических ошибок, существуют еще и другие проблемы, которые могут вызывать сообщения такого рода. Одной из таких проблем является повышенная температура носителя.
Ее можно посмотреть в программе Victoria во вкладке SMART под пунктом 190 «Airflow temperature» для HDD. Или под пунктом 194 «Controller temperature» для SDD.
Если данный показатель будет завышен, следует принять меры по охлаждению системного блока:
- Проверить работоспособность кулеров.
- Очистить пыль.
- Поставить дополнительный кулер для лучшей вентиляции.
Другим способом исправления ошибок SMART является проверка накопителя на наличие ошибок.
Это можно сделать, зайдя в папку «Мой компьютер», кликнув правой клавишей мыши по диску или его разделу, выбрав пункт «Сервис» и запустив проверку.
Если ошибка не была исправлена в ходе проверки, следует прибегнуть к дефрагментации диска.
Чтобы это сделать, находясь в свойствах диска, следует нажать на кнопку «Оптимизировать», выбрать необходимый диск и нажать «Оптимизировать».
Если ошибка не пропадет после этого, скорее всего, диск просто исчерпал свой ресурс, и в скором времени он станет нечитаемым, а пользователю останется только приобрести новый HDD или SSD.
Ошибки позиционирования
Seek Error Rate
Жесткий диск постоянно находится в движении — его головки скользят по поверхности в поисках данных. Иногда этот процесс сбоит и блок магнитных головок оказывается не в том месте — это ошибка позиционирования. При их наличии имеются повреждения сервометок, возможны проблемы с охлаждением и механической частью (шпендель)
Жесткий диск контролирует правильность установки головок на требуемую дорожку поверхности для считывания данных. В случае, когда установка выполнилась неверно, фиксируется ошибка и операция повторяется. Для данного накопителя причиной большого числа ошибок явился перегрев. Как и в случае с Raw Read Error Rate, «Значение» не должно опуститься ниже «Порога». А в столбце «Данные» (RAW) должен быть (в идеале) ноль.
Как отключить проверку SMART?
Диск с ошибкой S.M.A.R.T. может выйти из строя в любой момент, но это не означает, что им нельзя продолжать пользоваться.
Стоит понимать, что использование такого диска не должно подразумевать в себе хранение на нем сколько-либо стоящей информации. Зная это, можно провести сброс smart настроек, которые помогут замаскировать надоедливые ошибки.
Для этого:
Шаг 1. Заходим в BIOS или UEFI (кнопка F2 или Delete во время загрузки), переходим в пункт «Advanced», выбираем строку «IDE Configuration» и нажимаем Enter. Для навигации следует использовать стрелочки на клавиатуре.
Шаг 2. На открывшемся экране следует найти свой диск и нажать Enter (жесткие диски подписаны «Hard Disc»).
Шаг 3. Опускаемся вниз списка и выбираем параметр SMART, нажимаем Enter и выбираем пункт «Disabled».

Шаг 4. Выходим из BIOS, применяя и сохраняя настройки.
Стоит отметить, на некоторых системах данная процедура может выполняться немного по-другому, но сам принцип отключения остается прежним.
После отключения SMART ошибки перестанут появляться, и система будет загружаться в штатном порядке до тех пор, пока HDD окончательно не выйдет из строя. В некоторых ситуациях ошибки могут показываться в самой ОС, тогда достаточно несколько раз отклонить их, после чего появится кнопка «Больше не показывать».
Расшифровка результатов
Система сохраняет информацию в шестнадцатеричном виде, именуемом как raw value («сырые значения»). Данные форматируются в параметр value, отображающий надежность винчестера в соответствии с эталоном.
Оценка производится, в основном, по шкале от 0 до 100, но некоторые пункты измеряются в диапазоне от 0 до 253. Высокая цифра указывает на нормальное состояние, а низкая — на возможность скорой поломки. Если результат меньше минимума, при котором изготовитель винта гарантирует его безотказную работу, значит, узел вышел из строя.
Как это выглядит?
Программа выдает результаты в виде таблицы, разделенной на несколько обязательных полей:
- ID (Num) — идентификационный номер параметра;
- Name — его описание;
- VAL — цифра, отображающая состояние диска (о чем говорилось выше);
- Wrst (Worst) — худшее значение value за всю историю вашего харда;
- Thresh (Threshold) — число, достигнув которого винт выйдет из строя.

Что делать если данные были утеряны?
При случайном форматировании, удалении вирусами или утере любых важных данных следует быстро вернуть утерянную информацию самым эффективным методом.
Одним из таких методов является программа для восстановления данных RS Partition Recovery. Данная утилита сможет быстро вернуть удаленные фотографии, видеофайлы, звуковые дорожки, картинки, документы и любые другие файлы, которые исчезли с накопителя по различным причинам. RS Partition Recovery имеет продвинутую систему сканирования и поиска удаленной информации, что позволяет находить и восстанавливать даже те файлы, которые были удавлены достаточно давно. Детальнее с возможностями и главными особенностями RS Partition Recovery можно ознакомиться на официальном сайте производителя
Что означают данные SMART, связанные со сроком службы SSD
Фирменные и сторонние утилиты выводят упрощенные сведения, и зачастую этого достаточно.

Но у SMART много интересных атрибутов, поэтому давайте разбираться. Чтобы не гадать, нужно сверяться с документацией, которая идет в комплекте с фирменной утилитой в справке или прилагается в PDF, либо выложена в разделе поддержки на сайте изготовителя. Конечно, там все на английском, поэтому использую только английские название атрибутов, несмотря на локализацию CDI.
Список ссылок на документацию SMART производителей SSD
Добавляйте в комментариях
ссылки на описание атрибутов ваших дисков.
- Samsung (справка к утилите Magician, веб-сайт)
- Kingston (SandForce)
- Crucial (M5xx, M600, MXxxx)
Атрибуты объема записи в NAND
Давайте посмотрим, как определяют ключевой параметр разные изготовители.
Total LBAs Written / Total Host Sector Writes
Некоторые изготовители считают количество блоков LBA (Samsung, Crucial). Чтобы получить значение в байтах, надо умножить на 512. На Samsung 840 Pro записано 7.3TB.
Здесь попутно указывается текущее значение [в процентах], поэтому можно грубо оценить износ накопителя. Но для оценки срока жизни есть специальные атрибуты, которые мы рассмотрим ниже.
Lifetime Writes from Host
Этот атрибут используется в дисках на SF. Указывается значение в гигабайтах или в байтах, по количеству цифр понятно. На Kingston Hyper-X 3K записано 5.5TB
Заметьте, что здесь процент износа оценить невозможно.
Атрибуты износа и срока службы NAND
В SMART всех дисков есть конкретный показатель износа или процент оставшегося здоровья SSD.
Percent Lifetime Remaining / SSD Life Left
Оставшийся процент жизни SSD. 5.5TB – ничто.
Wear Leveling Count / Media Wearout Indicator
Износ NAND. У Samsung (на картинке) и Intel соответственно этот атрибут отражает количество пройденных циклов перезаписи (RAW Values) и текущий уровень жизни SSD в процентах.
Ниже с помощью этого показателя мы определим ресурс NAND в 840 Pro и 840 EVO.
Used Reserved Block Count (total) и Reallocated Sector Count
Количества использованных резервных блоков и переназначенных секторов. Чтобы здесь испортить идеальные показатели, нужно очень
много записывать. Так, победитель эксперимента над шестью SSD 840 Pro начал заметно использовать резервные блоки только после записи 600TB. Обратите внимание, что WLC опустился до нуля на 500TB.

А вот так на картинках хорошо видна связь количества использованных резервных блоков и переназначенных секторов.

Вычисляем ресурс NAND (количество циклов перезаписи)
Зная число пройденных циклов и процент износа, можно подсчитать количество циклов P/E, которые выдерживает память. По науке, надо последовательно записать терабайт десять, сопоставляя каждое падение счетчика WLC на единицу с объемом записанных данных. Но можно прикинуть, усреднив значения двух 840 Pro с MLC NAND, которые у нас с братом из одной партии. Для сравнения с ними добавлены два 840 EVO 120GB с самым большим износом из комментариев
| Модель Samsung | Износ (WLC) | Записано | Пройдено циклов P/E | Ресурс циклов P/E | Ресурс записи в NAND |
| 840 Pro | 3% | 7.3TB | 86 | Среднее: 3058 | Среднее: 250TB |
| 840 Pro | 2% | 5.2TB | 65 | ||
| 840 EVO | 7% | 10.3TB | 75 | Среднее: 1123 | Среднее: 160TB |
| 840 EVO | 8% | 14TB | 94 |
Таблица высвечивает пару любопытных особенностей:
- Samsung не озвучивала выносливость флэш-памяти 840 Pro в циклах P/E, в отличие от Kingston. Но ресурс NAND у обоих накопителей одинаковый – 3 000 циклов или 3K.
- У 840 EVO ресурс памяти соответствует TLC NAND — 1 000 циклов. Ожидаемо, расчетный ресурс записи в терабайтах ниже, чем у 840 PRO, но не в три раза.
Из результатов эксперимента выше видно, что даже израсходовав ресурс, во флэш-память можно записать очень много данных. Но на практике при нуле процентов жизни диск надо срочно менять.
Вычисляем мультипликатор увеличения записи
Вы уже видели эти показатели выше глазами CDI в контексте срока жизни SSD, но сейчас я хочу обратить ваше внимание на атрибуты без описаний, причем в фирменной утилите.
Kingston HyperX 3K | Атрибуты 233 и 234 не описаны даже в документации
О назначении параметров я догадался сам, а потом нашел подтверждения в сети (это как раз тот случай, когда легче искать информацию по десятичному номеру атрибута утилиты изготовителя). Обратите внимание, что значения атрибутов 234 и 241 совпадают, т.е. 234 – это тоже объем записи на диск. Значение 233 меньше, а диск – SandForce, главной особенностью которого является сжатие данных контроллером. Все сходится!
Атрибут 233 – это NAND Writes
!
Если диск выводит объем записи во флэш-память, можно вычислить соотношение физической записи в NAND к логической записи ОС — мультипликатор .
Для накопителя Kingston WA=4567/5512=0.8
. Он меньше 1, т.е. сжатие действительно экономит ресурс SSD. В презентациях SandForce заявляла 0.5, впрочем.
Давайте теперь посмотрим на диск без сжатия – типичный для 2015-2016 годов накопитель на MLC NAND 16nm с контроллером Marvell на примере Crucial MX100. В отсутствие сжатия идеальное значение WA равно 1. У Crucial мультипликатор вычисляется немного сложнее.
| ИД | Атрибут | RAW-значение |
| 247 | Host program page count | 277655968 |
| 248 | Background program page count | 2665992986 |
ИД 247 – это операции программирования ячеек, исходящие от ОС, т.е. аналог Host Writes. ИД 248 – это операции контроллера в дополнение
к записям ОС. Поэтому NAND Writes = ИД 247 + ИД 248. В документации формула дается после упрощения дроби: WA=1+(ИД 248/ИД 247).
Даже без вычислений видно, что физических операций на порядок больше логических записей ОС. Точный WA= (277655968+2665992986)/277655968=10.6
. Это многовато, на форумах Crucial я не видел WA>6. Скорее всего, такой большой мультипликатор связан с условиями эксплуатации диска – он регулярно забивался скачанными фильмами на протяжении большей части службы. Но, думаю, сценарий “один диск SSD 256GB в ноутбуке” достаточно распространен.
3 года назад, опираясь на характеристики HyperX 3K при записи «один объем диска в день», я оценивал срок службы накопителя в 8 лет. Тогда я брал WA=10, а фактический мультипликатор оказался в 12 раз меньше. Однако для более нового SSD Crucial десятикратное увеличение объема записи в NAND оказалось реальностью. Переходим к объемам записи.
Код исправления ошибок (Error Correction Code или ECC) добавляется к передаваемому сигналу и позволяет не только выявить ошибки при передаче, но и при необходимости исправить их (что в общем-то очевидно из названия), без повторного запроса данных у передатчика. Такой алгоритм работы позволяет передавать данные с постоянной скоростью, что может быть важно во многих случаях. Например, когда вы смотрите цифровое телевидение — смотреть на застывшую картинку, ожидая, пока осуществляются многократные повторные запросы данных, было бы весьма неинтересно.

В 1948 году Клод Шеннон опубликовал свою знаменитую работу о передаче информации, в которой, помимо прочего, была сформулирована теорема о передаче информации по каналу с помехами. После публикации, было разработано немало алгоритмов исправления ошибок с помощью некоторого увеличения объема передаваемых данных, но одним из часто встречающихся семейств алгоритмов, являются алгоритмы, основанные на коде с малой плотностью проверок на четность (Low-density parity-check code, LDPC-code, низкоплотностный код), получившие сейчас распространение за счет простоты реализации.

Клод Шеннон
LDPC был впервые представлен миру в стенах MIT Робертом Греем Галлагером (Robert Gray Gallager), выдающимся специалистом в области коммуникационных сетей. Произошло это в 1960 году, и LDPC опередил свое время. Компьютеры на вакуумных лампах, распространенные в то время, редко обладали мощностью достаточной, для эффективной работы с LDPC. Компьютер, способный обрабатывать такие данные в реальном времени, в те годы занимал площадь почти в 200 квадратных метров, и это автоматически делало все алгоритмы, основанные на LDPC экономически невыгодными. Поэтому, на протяжении почти 40 лет использовались более простые коды, а LDPC оставался скорее изящным теоретическим построением.

Роберт Галлагер
В середине 90-х, инженеры, работающие над алгоритмами спутниковой передачи цифрового телевидения, «стряхнули пыль» с LDPC и стали его использовать, поскольку компьютеры к тому времени стали и мощней, и меньше. К началу 2000-х годов, LDPC получает повсеместное распространение, поскольку он позволяет с большой эффективностью исправлять ошибки при высокоскоростной передаче данных в условиях высоких помех (например при сильных электромагнитных наводках). Так же распространению способствовало появление специализированных систем на чипах, использующихся в WiFi технике, жестких дисках, контроллерах SCSI и т.д., такие SoC оптимизируются под задачи, и для них вычисления, связанные с LDPC вообще не представляют проблемы. В 2003 году LDPC-код, вытеснил технологию турбо-кода, и стал частью стандарта спутниковой передачи данных для цифрового телевидения DVB-S2. Аналогичная замена произошла и в стандарте DVB-T2 для цифрового «эфирного» телевидения.
Стоит сказать, что на базе LDPC строятся очень разные решения, нет «единственно правильной» эталонной реализации. Часто решения, основанные на LDPC несовместимы между собой и код, разработанный, например, для спутникового телевидения, не может быть портирован и использован в жестких дисках. Хотя чаще всего, объединение усилий инженеров разных областей дает массу преимуществ, и LDPC «в целом» является технологией не запатентованной, разные ноу-хау и проприетарные технологии вместе с корпоративными интересами встают на пути. Чаще всего, подобное сотрудничество возможно только в пределах одной компании. В качестве примера можно привести решение для канала чтения HDD от LSI под названием TrueStore®, которое компания предлагает на протяжении уже 3 лет. После приобретения компании SandForce, инженеры LSI стали работать над алгоритмами исправления ошибок SHIELD™ для SSD контроллеров (основанными на LDPC), не существовало портов алгоритмов для работы с SSD, но знания инженерной команды, работавшей над решениями для HDD очень помогли в разработке новых алгоритмов.
Тут, разумеется, у большинства читателей возникнет вопрос: чем алгоритмы, каждый алгоритм LDPC отличается от остальных? Большинство решений LDPC начинаются как декодеры с жестким решением, то есть такой декодер работает с жестко ограниченным набором данных (чаще всего 0 и 1) и использует код коррекции ошибок при малейших отклонениях от нормы. Такое решение, конечно, позволяет эффективно обнаруживать ошибки в передаваемых данных и исправлять их, но в случае высокого уровня ошибок, что иногда случается при работе с SSD, такие алгоритмы перестают справляться с ними. Как вы помните из наших предыдущих статей, любая флеш-память подвержена росту количества ошибок в процессе эксплуатации. Этот неизбежный процесс стоит учитыавть при разработке алгоритмов корреции ошибок для SSD накопителей. Что же делать в случае роста числа ошибок?
Тут на помощь приходят LDPC с мягким решением, являющиеся по сути «более аналоговыми». Подобные алгоритмы «смотрят» глубже, чем «жесткие», и, обладают большим набором возможностей. Примером самого простого такого решения может быть попытка прочитать данные снова, используя другое напряжение, так же как мы часто просим собеседника повторить фразу погромче. Продолжая метафоры с общением людей, можно привести пример более сложных алгоритмов коррекции. Представьте, что вы общаетесь на английском с человеком, говорящим с сильнейшим акцентом. В данном случае сильный акцент выступает в роли помехи. Ваш собеседник произнес некую длинную фразу, которую вы не поняли. В роли LDPC с мягким решением в данном случае будут выступать несколько коротких наводящих вопросов, которые вы можете задать и прояснить весь смысл фразы, которую вы изначально не поняли. Подобные мягкие решения часто используют так же сложные статистические алгоритмы, позволяющие исключить ложнопозитивные срабатывания. В общем, как вы уже поняли, такие решения заметно сложней в реализации, но они чаще всего показывают куда лучшие результаты по сравнению с «жексткими».
В 2013 году, на саммите, посвященном флэш-памяти, проходившем в Санта-Кларе, Калифорния, LSI представили свою технологию расширенной коррекции ошибок SHIELD. Комбинируя подходы с мягким и жестким решением, DSP SHIELD предлагает ряд уникальных оптимизаций для будущих технологий Flash-памяти. Например, технология Adaptive Code Rate, позволяет менять объем, отведенный под ECC так, чтоб он занимал как можно меньше места изначально, и динамически увеличивался по мере неизбежного роста количества ошибок, характерных для SSD.
Как видите, различные решения LDPC работают очень по-разному, и предлагают разные фунции и возможности, от которых во многом будет зависеть и качество работы финального продукта.
Таким образом, ненулевой параметр на дисках WD и Samsung до SpinPoint F1 (невключительно) и большое значение параметра на дисках Hitachi могут указывать на аппаратные проблемы с диском. На дисках Seagate, Samsung (SpinPoint F1 и новее) и Fujitsu на этот атрибут можно не обращать внимания.
Практически ничего не говорит о здоровье диска. Время разгона может различаться у разных дисков (даже одного и того же производителя) в зависимости от тока раскрутки, массы блинов, номинальной скорости шпинделя и т.п. Винчестеры Fujitsu всегда имеют 1 в этом поле в случае отсутствия проблем с раскруткой шпинделя.
Start/Stop Count
Чем больше это значение, тем хуже состояние поверхности дисков. При достижении определённого порогового значения (например, 10 ремапов) диск нужно обязательно менять, ведь это означает прогрессирующую деградацию состояния поверхности блинов, головок или другие аппаратные проблемы.
Чем их больше, тем хуже состояние механики и/или поверхности жёсткого диска. Также на значение параметра может повлиять перегрев и внешние вибрации (например, от соседних дисков в корзине).
На дисках Seagate, Samsung SpinPoint F1 и новее и Fujitsu 2,5″ на значение атрибута можно не обращать внимание, на остальных моделях Samsung, а также на всех WD и Hitachi ненулевое значение свидетельствует об аппаратных проблемах. Для винчестеров Hitachi нормальным значением является только 0.
Power-on Time
В идеале должен быть равен 0. При значении атрибута, равном 1-2, внимания можно не обращать. Если значение больше, в первую очередь следует обратить пристальное внимание на состояние блока питания, его качество, нагрузку на него, проверить контакт винчестера с кабелем питания, проверить сам кабель питания.
Recalibration Retries
UNC Error
Такие ошибки могут возникать из-за плохого качества кабелей, контактов, используемых переходников, удлинителей и т.д., а также из-за несовместимости диска с конкретным контроллером SATA/РАТА. Из-за ошибок такого рода возможны «синие экраны смерти» в Windows. Ненулевое значение атрибута говорит о потенциальной «болезни» диска.
Для того, чтобы сказать, почему происходят такие случаи, нужно уметь анализировать логи SMART, которые содержат специфичную для каждого производителя информацию, что на сегодняшний день не реализовано в общедоступном ПО.
Mechanical Shock
Актуален для мобильных винчестеров. На дисках Samsung на него часто можно не обращать внимания, т.к. они могут иметь очень чувствительный датчик, который, образно говоря, реагирует чуть ли не на движение воздуха от крыльев пролетающей в одном помещении с диском мухи.
Emergency Retry Count
HDA Temperature
HDD Temperature
Косвенно говорит о здоровье диска. Чем больше значение — тем хуже. Однако нельзя однозначно судить о здоровье диска по этому параметру, не рассматривая другие атрибуты.
При ненулевом значении нужно обязательно запустить в программах Victoria или MHDD последовательное чтение всей поверхности с опцией remap. Тогда при сканировании диск обязательно наткнётся на плохой сектор и попытается произвести запись в него (в случае Victoria 3.5 и опции Advanced remap диск будет пытаться записать сектор до 10 раз). Таким образом программа спровоцирует «лечение» сектора, и в итоге он будет либо исправлен, либо переназначен.
В подавляющем большинстве случаев причинами ошибок становятся некачественный шлейф передачи данных, разгон шин PCI/PCI-E либо плохой контакт в SATA-разъёме на диске или на материнской плате/контроллере. Для Hitachi серий Deskstar 7К3000 и 5К3000 растущий атрибут может говорить о несовместимости диска и SATA-контроллера. Чтобы исправить ситуацию, нужно принудительно переключить такой диск в режим SATA 3 Гбит/с.
Multi-Zone Error Rate
 Маленький рассказ об S.M.A.R.T. атрибутах, их важности и понимании. В статье пойдет речь об расшифровке всех smart атрибутов ATA дисков. В предыдущих статьях речь шла об мониторинге BBU и жестких SCSI дисков и их атрибутов под Megaraid контроллером. Теперь хочу немного описать атрибуты обычных АТА дисков на примере Seagate Barracuda ES.2 (ST31000340NS). Так же определим самые важные атрибуты, на которые нужно обращать внимание при мониторинге дисков используя smartctl. Для начала, можно убедиться, что наш диск поддерживает смарт
Маленький рассказ об S.M.A.R.T. атрибутах, их важности и понимании. В статье пойдет речь об расшифровке всех smart атрибутов ATA дисков. В предыдущих статьях речь шла об мониторинге BBU и жестких SCSI дисков и их атрибутов под Megaraid контроллером. Теперь хочу немного описать атрибуты обычных АТА дисков на примере Seagate Barracuda ES.2 (ST31000340NS). Так же определим самые важные атрибуты, на которые нужно обращать внимание при мониторинге дисков используя smartctl. Для начала, можно убедиться, что наш диск поддерживает смарт
root@ s01:~# smartctl -i /dev/sda smartctl 5.41 2011-06-09 r3365 [x86_64-linux-3.8.0-29-generic] (local build) Copyright (C) 2002-11 by Bruce Allen, http://smartmontools.sourceforge.net === START OF INFORMATION SECTION === Model Family: Seagate Barracuda ES.2 Device Model: ST31000340NS Serial Number: 9QJ2ADVC … ATA Version is: 8 ATA Standard is: ATA-8-ACS revision 4 Local Time is: Fri Feb 21 16:18:35 2014 CET … SMART support is: Available - device has SMART capability. SMART support is: Enabled
Две последние строки свидетельствуют о том, что диск поддерживает smart и можно посмотреть значение всех его атрибутов и их интерпретация будет корректной(интерпретация RAW_VALUE) . В данном случаи тип интерфейса (устройства) не указывался явно (не было указанно атрибут «-d»), по этому smartctl автоматически определил тип устройства и сказал, что «SMART support is: Enabled». Но если используются, к примеру массивы дисков (RAID контроллер), то smartctl может сказать, что смарт не поддерживается:
root@s06:~# smartctl -i /dev/sda smartctl 5.41 2011-06-09 r3365 [x86_64-linux-3.8.0-26-generic] (local build) Copyright (C) 2002-11 by Bruce Allen, http://smartmontools.sourceforge.net Vendor: SMC Product: SMC2108 Revision: 2.90 User Capacity: 2,996,997,980,160 bytes [2.99 TB] Logical block size: 512 bytes Logical Unit id: 0x600304800086531015527e0b0664df74 Serial number: 0074df64060b7e521510538600800403 Device type: disk Local Time is: Fri Feb 21 17:32:27 2014 IST Device does not support SMART
Но на самом деле, нужно просто знать (или подбирать) какие дисковые массивы используются, и тогда можно получить желаемый результат явно указав тип устройства:
root@s06:~# smartctl -d megaraid,14 -i /dev/sda smartctl 5.41 2011-06-09 r3365 [x86_64-linux-3.8.0-26-generic] (local build) Copyright (C) 2002-11 by Bruce Allen, http://smartmontools.sourceforge.net Vendor: SEAGATE Product: ST1000NM0001 Revision: 0002 User Capacity: 1,000,204,886,016 bytes [1.00 TB] Logical block size: 512 bytes Logical Unit id: 0x5000c50041080343 Serial number: Z1N0TV980000C2157TYR Device type: disk Transport protocol: SAS Local Time is: Fri Feb 21 17:34:45 2014 IST Device supports SMART and is Enabled Temperature Warning Enabled
Также может быть проблема в версии smartctl ибо не все жесткие диски добавляются в базу SMART сразу после выхода в мир нового HDD или RAID контроллера. Или же в BIOS отключено поддержку (нужно включить). Так же может быть проблема в прошивке (firmware) самого жесткого диска. Можете также стоит для начала попытаться включить SMART командой:
root@s01:~# smartctl -s on /dev/sda smartctl 5.41 2011-06-09 r3365 [x86_64-linux-3.8.0-26-generic] (local build) Copyright (C) 2002-11 by Bruce Allen, http://smartmontools.sourceforge.net === START OF ENABLE/DISABLE COMMANDS SECTION === SMART Enabled.
Следующая, интересующая нас часть вывода покажет суммарный результат проверки статуса здоровья диска (Если не Passed – нужно проводить замену диска). Так же выводится дополнительные характеристики диска и предполагаемое время выполнения коротких и длинных тестов.
root@s01:~# smartctl -Hc /dev/sda
smartctl 5.41 2011-06-09 r3365 [x86_64-linux-3.8.0-29-generic] (local build)
Copyright (C) 2002-11 by Bruce Allen, http://smartmontools.sourceforge.net
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x82) Offline data collection activity
was completed without error.
Auto Offline Data Collection: Enabled.
Self-test execution status: ( 41) The self-test routine was interrupted
by the host with a hard or soft reset.
Total time to complete Offline
data collection: ( 634) seconds.
Offline data collection
capabilities: (0x7b) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 1) minutes.
Extended self-test routine
recommended polling time: ( 226) minutes.
Conveyance self-test routine
recommended polling time: ( 2) minutes.
SCT capabilities: (0x003d) SCT Status supported.
SCT Error Recovery Control supported.
SCT Feature Control supported.
SCT Data Table supported.
В нашем случаи тип устройства определился автоматически и теперь можно вывести самое интересное — список атрибутов.
root@s01:~# smartctl -A /dev/sda smartctl 5.41 2011-06-09 r3365 [x86_64-linux-3.8.0-29-generic] (local build) Copyright (C) 2002-11 by Bruce Allen, http://smartmontools.sourceforge.net === START OF READ SMART DATA SECTION === SMART Attributes Data Structure revision number: 10 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x000f 068 059 044 Pre-fail Always - 130449727 3 Spin_Up_Time 0x0003 099 099 000 Pre-fail Always - 0 4 Start_Stop_Count 0x0032 100 100 020 Old_age Always - 23 5 Reallocated_Sector_Ct 0x0033 100 100 036 Pre-fail Always - 4 7 Seek_Error_Rate 0x000f 063 039 030 Pre-fail Always - 549998464474 9 Power_On_Hours 0x0032 052 052 000 Old_age Always - 42335 10 Spin_Retry_Count 0x0013 100 100 097 Pre-fail Always - 0 12 Power_Cycle_Count 0x0032 100 037 020 Old_age Always - 63 184 End-to-End_Error 0x0032 100 100 099 Old_age Always - 0 187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0 188 Command_Timeout 0x0032 100 093 000 Old_age Always - 4295032870 189 High_Fly_Writes 0x003a 100 100 000 Old_age Always - 0 190 Airflow_Temperature_Cel 0x0022 076 049 045 Old_age Always - 24 (Min/Max 18/26) 194 Temperature_Celsius 0x0022 024 051 000 Old_age Always - 24 (0 17 0 0) 195 Hardware_ECC_Recovered 0x001a 041 021 000 Old_age Always - 130449727 197 Current_Pending_Sector 0x0012 100 100 000 Old_age Always - 0 198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0 199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age Always - 0
Используя SMART можно предугадать с довольно большой вероятностью проблемы связанные с:
- Магнитными головками диска
- Физическими повреждениями диска
- Логическими ошибками
- Механическими проблемами (проблемы привода, системы позиционирования)
- Подачей питания (платы)
- Температурой
Расшифруем полученный вывод.

Каждый атрибут имеет группу значений:
- ID# — идентификационный номер атрибуты (детали здесь). Каждый атрибуты имеет свой уникальный ID, который должен быть одинаковым для всех фирм производителей дисков.
- ATTRIBUTE_NAME – название атрибута. Так как разные фирмы производители дисков могут называть атрибуты по своему (сокращать, синонимы), лучше всего ориентироваться по ID атрибута.
- FLAG (Status flag) – каждый атрибут имеет определенный флаг, назначенный фирмой разработчиком диска. В ОС с графическим интерфейсом значения этого флага предоставляется в виде набора буквенных обозначений – w,p,r,c,o,s (расшифровка ниже). И эти наборы предоставляются в виде шестнадцатеричного числа которые вы видели выше.
- Warranty: Указывает на жизненно важный атрибут диска и покрывается гарантией. Если этот флаг установлен и значение атрибута с этим флагом достигнет порогового (threshold) значения, в то время, когда диск еще на гарантии, то фирма должна будет заменить диск бесплатно.
- Performance: Указывает на атрибут, который представляет показатель производительности диска – не критический.
- Error Rate: Атрибут с частотой ошибок.
- Count of occurrences: Атрибут-счетчик происшествий.
- Online test: Атрибут, который обновляет значения только через on-line тесты. Если не указан, то обновляется через off-line тесты.
- Self preserving: Указывает на атрибут который может собирать и сохранять данные о диска, даже если S.M.A.R.T. отключен.
- Value – Текущее значение атрибута(оценка атрибута диска на основе Raw_value). Низкое значение говорит о быстрой деградации диска или о возможном скором сбое. т.е. чем выше значение Value атрибута, тем лучше. Это значение атрибута нужно сравнивать с пороговым (threshold) значением. Если это критический атрибут и значение ниже порогового — нужно проводить замену диска.
- Worst – Самое низкое значение атрибута за жизненный цикл диска. Значение может изменяться на протяжении жизни диска, и не должно быть ниже или равным пороговому значению (threshold).
- Thresh (Threshold) – Пороговое значения атрибута назначенное создателем диска. Значение не меняется за жизненный цикл диска. Если значение Value атрибута станет равным или меньше порогового – появиться уведомление в колонке WHEN_FAILED. И диск нужно заменить.
- Type – тип атрибута. Может быть критическим (pre-fail), который указывает на предстоящий отказ диска из-за ошибок или не критический, указывающий на достижение конца жизненного цикла диска.
- Raw_value – Объективное значения атрибута, которое показывается в десятичном формате (вычисляется firmware диска) и известных только производителю единицах (имеет связь с Value, Threshold и Worst значениями).
- WHEN_FAILED – Указывает на проблемы с атрибутом.
Атрибут диска примет значение failed, в случаи:
Value = f(Raw_value) <= Threshold
Здесь:
- f(Raw_value) – функция вычисления деградации (уменьшения) значения параметра Value в зависимости от значения Raw_value.
Недостатки такого подхода к вычислению деградации диска:
- Для каждого производителя дисков и даже модели диска функция f(Raw_value) вычисляется по-разному.
- Оценка каждого атрибута подсчитывается независимо друг от друга – т.е. игнорируются связи между атрибутами.
Теперь хочу представить таблицу с перечисленными всех атрибутов. Те атрибуты, которые выделены розовым — относятся к атрибутам критическим. К тому же, указано тип параметра в зависимости от величины значения. Т.е. чем больше значение параметра, тем лучше состояние здоровья диска или наоборот.
|
↑ |
Чем выше значение Value, тем лучше состояние диска. |
|---|---|
|
↓ |
Чем ниже значение Value, тем лучше состояние диска. |
| Критический атрибут | В ближайшие время диск выйдет из строя — нужна смена диска |
Теперь приступим к атрибутам:
| #ID | HEX | Имя атрибута | Лучше если… | Описание |
|---|---|---|---|---|
| 01 | 01 | Raw Read Error Rate |
↓ |
Частота ошибок при чтении данных с жёсткого диска. Происхождение их обусловлено аппаратной частью винчестера. |
| 02 | 02 | Throughput Performance |
↑ |
Общая производительность накопителя. Если значение атрибута уменьшается перманентно, то велика вероятность проблем с винчестером. |
| 03 | 03 | Spin-Up Time |
↓ |
Время раскрутки шпинделя из состояния покоя (0 rpm) до рабочей скорости. В поле Raw_value содержится время в миллисекундах/секундах в зависимости от производителя |
| 04 | 04 | Start/Stop Count | * | Полное число запусков, остановок шпинделя. Иногда в том числе количество включений режима энергосбережения. В поле raw value хранится общее количество запусков/остановок жёсткого диска. |
| 05 | 05 | Reallocated Sectors Count |
↓ |
Число операций переназначения секторов. При обнаружении повреждённого сектора на винчестере, информация из него помечается и переносится в специально отведённую зону, происходит утилизация bad блоков, с последующим консервированием этих мест на диске. Этот процесс называют remapping. Чем больше значение Reallocated Sectors Count, тем хуже состояние поверхности дисков — физический износ поверхности. Поле raw value содержит общее количество переназначенных секторов. |
| 07 | 07 | Seek Error Rate |
↓ |
Частота ошибок при позиционировании блока магнитных головок. Чем больше значение, тем хуже состояние механики, или поверхности жёсткого диска. |
| 08 | 08 | Seek Time Performance |
↑ |
Средняя производительность операции позиционирования. Если значение атрибута уменьшается, то велика вероятность проблем с механической частью. |
| 09 | 09 | Power-On Hours (POH) |
↓ |
Время, проведённое устройством, во включенном состоянии. В качестве порогового значения для него выбирается паспортное время наработки на отказ. |
| 10 | 0A | Spin-Up Retry Count |
↓ |
Число повторных попыток раскрутки дисков до рабочей скорости в случае, если первая попытка была неудачной. |
| 11 | 0B | Recalibration Retries |
↓ |
Количество повторов рекалибровки в случае, если первая попытка была неудачной. |
| 12 | 0C | Device Power Cycle Count | Число циклов включения-выключения винчестера. | |
| 13 | 0D | Soft Read Error Rate |
↓ |
Число ошибок при чтении, по вине программного обеспечения, которые не поддались исправлению. |
| 187 | BB | Reported UNC Errors |
↓ |
Неустранимые аппаратные ошибки. |
| 190 | BE | Airflow Temperature |
↓ |
Температура воздуха внутри корпуса жёсткого диска. Целое значение, либо значение по формуле 100 — Airflow Temperature |
| 191 | BF | G-sense error rate |
↓ |
Количество ошибок, возникающих в результате ударов. |
| 192 | C0 | Power-off retract count |
↓ |
Число циклов аварийных выключений. |
| 193 | C1 | Load/Unload Cycle |
↓ |
Количество циклов перемещения блока головок в парковочную зону. |
| 194 | C2 | HDA temperature |
↓ |
Показания встроенного термодатчика накопителя. |
| 195 | C3 | Hardware ECC Recovered |
↓ |
Число коррекции ошибок аппаратной частью диска (ошибок чтения, ошибок позиционирования, ошибок передачи по внешнему интерфейсу). |
| 196 | C4 | Reallocation Event Count |
↓ |
Число операций переназначения в резервную область, успешные и неудавшиеся попытки. |
| 197 | C5 | Current Pending Sector Count |
↓ |
Число секторов- кандидатов на перенос в резервную зону. Помечены как не надёжные. При последующих корректных операциях атрибут может быть снят. |
| 198 | C6 | Uncorrectable Sector Count |
↓ |
Число некорректируемых ошибок при обращении к сектору. |
| 199 | C7 | UltraDMA CRC Error Count |
↓ |
Число ошибок при передаче данных по внешнему интерфейсу. |
| 200 | C8 | Write Error Rate /Multi-Zone Error Rate |
↓ |
Общее количество ошибок при заполнения сектора информацией. Показатель качества накопителя. |
| 201 | C9 | Soft read error rate |
↓ |
Частота появления «программных» ошибок при чтении данных с диска, а не аппаратной части HDD. |
| 202 | Ca | Data Address Mark errors |
↓ |
Число ошибок адресно помеченной информации (Data Address Mark (DAM)).Если автоматически не корректируется — заменить устройство. |
| 203 | CB | Run out cancel |
↓ |
Количество ошибок ECC данных, присоединяемые к передаваемому сигналу, позволяющие принимающей стороне определить факт сбоя или исправить несущественную ошибку. |
| 204 | CC | Soft ECC correction |
↓ |
Количество ошибок ECC, скорректированных программным способом. |
| 205 | CD | Thermal asperity rate (TAR) |
↓ |
Число ошибок в следствии температурных колебаний. |
| 206 | CE | Flying height | * | Высота между головкой и поверхностью диска компьютера. |
| 209 | D1 | Offline seek performance | * | Drive’s seek performance during offline operations. |
| 220 | DC | Disk Shift |
↓ |
Дистанция смещения блока дисков относительно шпинделя. В основном возникает из-за удара или падения. |
| 221 | DD | G-Sense Error Rate |
↓ |
Число ошибок, возникших из-за внешних нагрузок и ударов. Атрибут хранит показания встроенного crash датчика. |
| 222 | DE | Loaded Hours | * | Время, проведённое блоком магнитных головок между выгрузкой из парковочной области в рабочую область диска и загрузкой блока обратно в парковочную область. |
| 223 | DF | Load/Unload Retry Count | * | Количество новых попыток выгрузок/загрузок блока магнитных головок винчестера в/из парковочной области после неудачной попытки. |
| 224 | E0 | Load Friction |
↓ |
Величина силы трения блока магнитных головок при его выгрузке из парковочной области. |
| 225 | E1 | Load Cycle Count |
↓ |
Число циклов вход-выход в парковочную зону. |
| 226 | E2 | Load ‘In’-time | * | Время, за которое привод выгружает магнитные головки из парковочной области на рабочую поверхность диска. |
| 227 | E3 | Torque Amplification Count |
↓ |
Количество попыток скомпенсировать вращающий момент. |
| 228 | E4 | Power-Off Retract Cycle |
↓ |
Количество повторов автоматической парковки блока магнитных головок в результате выключения питания. |
| 230 | E6 | GMR Head Amplitude | * | Амплитуда «дрожания» (расстояние повторяющегося перемещения блока магнитных головок). |
| 231 | E7 | Temperature |
↓ |
Температура жёсткого диска. |
| 240 | F0 | Head flying hours | * | Время позиционирования головки. |
| 250 | FA | Read error retry rate |
↓ |
Число ошибок во время чтения жёсткого диска. |
Атрибуты дисков нужно смотреть в целом и самостоятельно прогнозировать замену, не только опираясь на smart атрибуты. Нужно дополнительно проводить тесты на бедблоки и запускать fscheck и smart тесты, о которых пойдет речь в следующих статьях.

Современные жесткие диски и SSD снабжены технологией S.M.A.R.T. (self monitoring analysis and reporting technology), которая используется для их диагностики.
Ребята, делайте бекапы и ваша жизнь будет прекрасной! Технология RAID, горячий или холодный резерв дисков не дадут Вам полной защиты от потери данных. Следите за состоянием дисков и меняйте их ДО выхода из строя или существенной деградации сервиса.
👉 Заказать диагностику сервера прямо сейчас: 📞 8-800-511-24-07 📩 support@gotoADM.ru 👍 Telegram
С момента производства дисковый накопитель начинает считывать свое текущее состояние, определяя его с помощью специальных параметров или атрибутов. Они располагаются в служебной зоне накопителя, доступ к которой имеет лишь встроенная программа. Просмотреть параметры позволяет отдельное ПО (например, Victoria, MHDD), а также утилиты от разработчиков конкретного жесткого диска. Через них в накопитель подаются вводные, после чего в журнале статистики появится информация о текущем состоянии диска.
Ниже представлена таблица атрибутов S.M.A.R.T и комментарий к ней:
|
↑ |
Чем выше значение Value, тем лучше состояние диска. |
|---|---|
|
↓ |
Чем ниже значение Value, тем лучше состояние диска. |
| Критический атрибут | В ближайшие время диск выйдет из строя — нужна смена диска |
| #ID | HEX | Имя атрибута | Лучше если… | Описание |
|---|---|---|---|---|
| 01 | 01 | Raw Read Error Rate |
↓ |
Частота ошибок при чтении данных с жёсткого диска. Происхождение их обусловлено аппаратной частью винчестера. |
| 02 | 02 | Throughput Performance |
↑ |
Общая производительность накопителя. Если значение атрибута уменьшается перманентно, то велика вероятность проблем с винчестером. |
| 03 | 03 | Spin-Up Time |
↓ |
Время раскрутки шпинделя из состояния покоя (0 rpm) до рабочей скорости. В поле Raw_value содержится время в миллисекундах/секундах в зависимости от производителя |
| 04 | 04 | Start/Stop Count | * | Полное число запусков, остановок шпинделя. Иногда в том числе количество включений режима энергосбережения. В поле raw value хранится общее количество запусков/остановок жёсткого диска. |
| 05 | 05 | Reallocated Sectors Count |
↓ |
Число операций переназначения секторов. При обнаружении повреждённого сектора на винчестере, информация из него помечается и переносится в специально отведённую зону, происходит утилизация bad блоков, с последующим консервированием этих мест на диске. Этот процесс называют remapping. Чем больше значение Reallocated Sectors Count, тем хуже состояние поверхности дисков — физический износ поверхности. Поле raw value содержит общее количество переназначенных секторов. |
| 07 | 07 | Seek Error Rate |
↓ |
Частота ошибок при позиционировании блока магнитных головок. Чем больше значение, тем хуже состояние механики, или поверхности жёсткого диска. |
| 08 | 08 | Seek Time Performance |
↑ |
Средняя производительность операции позиционирования. Если значение атрибута уменьшается, то велика вероятность проблем с механической частью. |
| 09 | 09 | Power-On Hours (POH) |
↓ |
Время, проведённое устройством, во включенном состоянии. В качестве порогового значения для него выбирается паспортное время наработки на отказ. |
| 10 | 0A | Spin-Up Retry Count |
↓ |
Число повторных попыток раскрутки дисков до рабочей скорости в случае, если первая попытка была неудачной. |
| 11 | 0B | Recalibration Retries |
↓ |
Количество повторов рекалибровки в случае, если первая попытка была неудачной. |
| 12 | 0C | Device Power Cycle Count | Число циклов включения-выключения винчестера. | |
| 13 | 0D | Soft Read Error Rate |
↓ |
Число ошибок при чтении, по вине программного обеспечения, которые не поддались исправлению. |
| 187 | BB | Reported UNC Errors |
↓ |
Неустранимые аппаратные ошибки. |
| 190 | BE | Airflow Temperature |
↓ |
Температура воздуха внутри корпуса жёсткого диска. Целое значение, либо значение по формуле 100 — Airflow Temperature |
| 191 | BF | G-sense error rate |
↓ |
Количество ошибок, возникающих в результате ударов. |
| 192 | C0 | Power-off retract count |
↓ |
Число циклов аварийных выключений. |
| 193 | C1 | Load/Unload Cycle |
↓ |
Количество циклов перемещения блока головок в парковочную зону. |
| 194 | C2 | HDA temperature |
↓ |
Показания встроенного термодатчика накопителя. |
| 195 | C3 | Hardware ECC Recovered |
↓ |
Число коррекции ошибок аппаратной частью диска (ошибок чтения, ошибок позиционирования, ошибок передачи по внешнему интерфейсу). |
| 196 | C4 | Reallocation Event Count |
↓ |
Число операций переназначения в резервную область, успешные и неудавшиеся попытки. |
| 197 | C5 | Current Pending Sector Count |
↓ |
Число секторов- кандидатов на перенос в резервную зону. Помечены как не надёжные. При последующих корректных операциях атрибут может быть снят. |
| 198 | C6 | Uncorrectable Sector Count |
↓ |
Число некорректируемых ошибок при обращении к сектору. |
| 199 | C7 | UltraDMA CRC Error Count |
↓ |
Число ошибок при передаче данных по внешнему интерфейсу. |
| 200 | C8 | Write Error Rate /Multi-Zone Error Rate |
↓ |
Общее количество ошибок при заполнения сектора информацией. Показатель качества накопителя. |
| 201 | C9 | Soft read error rate |
↓ |
Частота появления «программных» ошибок при чтении данных с диска, а не аппаратной части HDD. |
| 202 | Ca | Data Address Mark errors |
↓ |
Число ошибок адресно помеченной информации (Data Address Mark (DAM)).Если автоматически не корректируется — заменить устройство. |
| 203 | CB | Run out cancel |
↓ |
Количество ошибок ECC данных, присоединяемые к передаваемому сигналу, позволяющие принимающей стороне определить факт сбоя или исправить несущественную ошибку. |
| 204 | CC | Soft ECC correction |
↓ |
Количество ошибок ECC, скорректированных программным способом. |
| 205 | CD | Thermal asperity rate (TAR) |
↓ |
Число ошибок в следствии температурных колебаний. |
| 206 | CE | Flying height | * | Высота между головкой и поверхностью диска компьютера. |
| 209 | D1 | Offline seek performance | * | Drive’s seek performance during offline operations. |
| 220 | DC | Disk Shift |
↓ |
Дистанция смещения блока дисков относительно шпинделя. В основном возникает из-за удара или падения. |
| 221 | DD | G-Sense Error Rate |
↓ |
Число ошибок, возникших из-за внешних нагрузок и ударов. Атрибут хранит показания встроенного crash датчика. |
| 222 | DE | Loaded Hours | * | Время, проведённое блоком магнитных головок между выгрузкой из парковочной области в рабочую область диска и загрузкой блока обратно в парковочную область. |
| 223 | DF | Load/Unload Retry Count | * | Количество новых попыток выгрузок/загрузок блока магнитных головок винчестера в/из парковочной области после неудачной попытки. |
| 224 | E0 | Load Friction |
↓ |
Величина силы трения блока магнитных головок при его выгрузке из парковочной области. |
| 225 | E1 | Load Cycle Count |
↓ |
Число циклов вход-выход в парковочную зону. |
| 226 | E2 | Load ‘In’-time | * | Время, за которое привод выгружает магнитные головки из парковочной области на рабочую поверхность диска. |
| 227 | E3 | Torque Amplification Count |
↓ |
Количество попыток скомпенсировать вращающий момент. |
| 228 | E4 | Power-Off Retract Cycle |
↓ |
Количество повторов автоматической парковки блока магнитных головок в результате выключения питания. |
| 230 | E6 | GMR Head Amplitude | * | Амплитуда «дрожания» (расстояние повторяющегося перемещения блока магнитных головок). |
| 231 | E7 | Temperature |
↓ |
Температура жёсткого диска. |
| 240 | F0 | Head flying hours | * | Время позиционирования головки. |
| 250 | FA | Read error retry rate |
↓ |
Число ошибок во время чтения жёсткого диска. |
Остались вопросы? Пиши комментарии!
Нашли ошибку в тексте? Выделите фрагмент текста и нажмите Ctrl+Enter
Каждому устройству, использующему флэш-память NAND, необходим код с исправлением случайных битов (известный как «мягкая» ошибка). Это потому что много электрический шум производится внутри чипа NAND, а уровни сигналов битов, проходящих через цепочку чипов NAND, очень слабые.

Один из способов, которым NAND память стали самый дешевый всего, потому что это требует, чтобы исправление ошибок было выполнено от элемента вне самого чипа NAND; В случае SSD, ECC выполняется на контроллере .
Такое же исправление ошибок также помогает исправить битовые ошибки из-за носить на Память сами клетки , Истощение может вызвать «застревание» битов в том или ином состоянии (известное как «жесткая» ошибка или жесткая ошибка) и может увеличить частоту «мягких» ошибок.
Хотя это понятие не является слишком широким, сопротивление флэш-памяти является мерой того, сколько циклов стирания / записи может выдержать блок флэш-памяти, прежде чем начнут появляться «серьезные» ошибки. Очень часто эти сбои происходят только в отдельных битах, и очень редко происходит сбой всего блока. При достаточно высоком числе стирания / записи «мягкая» частота ошибок также увеличивается из-за ряда других механизмов в самом SSD.
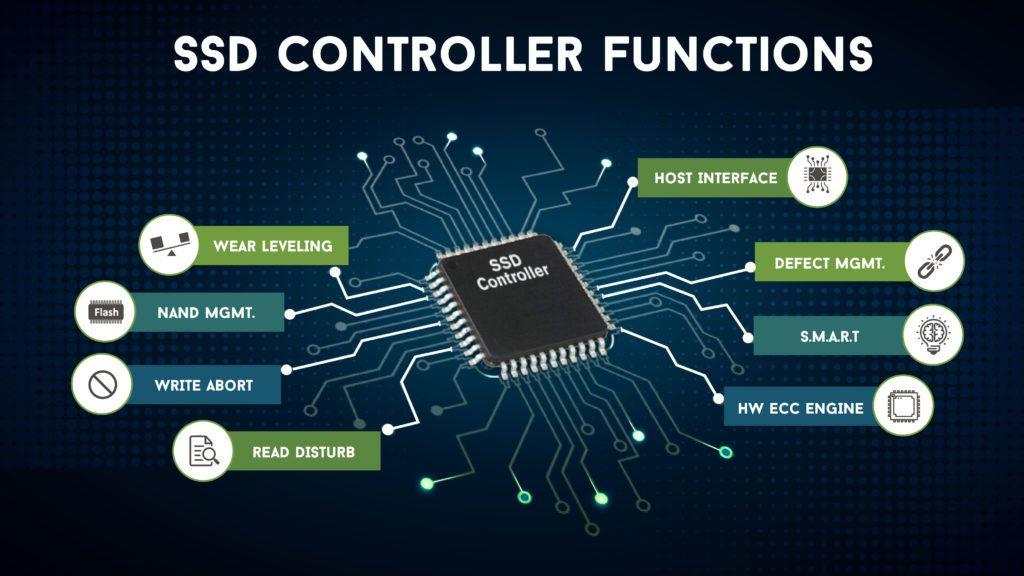
If ECC может быть используемый чтобы исправить эти «жесткие» ошибки, а «мягкие» ошибки не увеличиваются, срок службы всего блока значительно удлиняется, что значительно превышает сопротивление, указанное производителем.
Давайте рассмотрим пример: допустим, что неиспользуемый чип NAND имеет достаточно «мягких» ошибок, чтобы требовать 8 бит ECC, то есть при каждом считывании страницы может быть до 8 бит, которые были случайно повреждены (обычно из-за электрических помех, которые мы говорили о). вначале). ECC, используемый в этом чипе, может исправлять 12-битные ошибки, так что ECC не может решить эту проблему мы должны найти 8 «мягких» ошибок, связанных с электрическим шумом, плюс еще 5 «мягких» из-за износа.
Теперь производители флэш-памяти гарантируют, что первый из этих 5 сбоев произойдет через некоторое время после спецификации прочности SSD. Это означает, что ни один бит не выйдет из строя из-за износа, пока не будут превышены циклы стирания / записи, указанные производителем. Теперь имейте в виду, что спецификации не достаточно точны, чтобы предсказать, когда следующий бит выйдет из строя, и на самом деле это может занять несколько тысяч циклов стирания / записи выше спецификации, чтобы это произошло; помните, что производитель гарантирует, что это не произойдет до X циклов, но не тогда, когда это произойдет после их превышения.

Это означает, что это может занять много времени, прежде чем блок становится настолько коррумпированным что его необходимо удалить из службы (а также для этого на SSD обычно есть «дополнительные» блоки для замены поврежденных), что, в свою очередь, означает, что сопротивление исправлен от ошибок блок может быть во много раз больше указанного сопротивления, в зависимости от количества избыточных ошибок, которые ECC предназначен для исправления.
Какое влияние оказывает код исправления ошибок на SSD?
Как мы объясняли ранее, флэш-память настолько дешева, потому что она не включает в себя ECC в самих чипах, но интегрирована в другое внешнее оборудование, и, как вы предположите, это имеет свою цену. Более сложный ECC требует большей вычислительной мощности на контроллере и может быть медленнее, если алгоритмы не очень современные. Кроме того, количество ошибок, которые могут быть исправлены, будет зависеть от того, насколько большой сектор памяти исправляется, поэтому контроллер SSD со сложным алгоритмом ECC, вероятно, будет использовать много ресурсов, снижение общий SSD производительность , Эти улучшения также делают контроллер дороже .

Алгоритмы ECC имеют свое собственное математическое состояние в зависимости от контроллера (другими словами, нет никакого стандарта), и даже самые базовые кодировки ECC (Рида-Соломона и LDPC) довольно сложны для понимания. Когда кто-то говорит о пределе Шеннона (максимальное количество битов, которое может быть исправлено), это величина, которую, как вы не знаете от производителя в технических характеристиках, чрезвычайно сложно вычислить.
Просто придерживайтесь этого: большее количество корректирующих битов увеличивает срок службы SSD, но также оказывает некоторое влияние на производительность или даже цену продукта, так как требует более мощный контроллер.