 RAID-массивы давно и прочно вошли в повседневную деятельность администраторов даже небольших предприятий. Трудно найти того, кто никогда не использовал хотя бы «зеркало», но тем не менее очень и очень многие с завидной периодичностью теряют данные или испытывают иные сложности при эксплуатации массивов. Не говоря уже о распространенных мифах, которые продолжают витать вокруг вроде бы давно избитой темы. Кроме того, современные условия вносят свои коррективы и то, чтобы было оптимальным еще несколько лет назад сегодня утратило свою актуальность или стало нежелательным к применению.
RAID-массивы давно и прочно вошли в повседневную деятельность администраторов даже небольших предприятий. Трудно найти того, кто никогда не использовал хотя бы «зеркало», но тем не менее очень и очень многие с завидной периодичностью теряют данные или испытывают иные сложности при эксплуатации массивов. Не говоря уже о распространенных мифах, которые продолжают витать вокруг вроде бы давно избитой темы. Кроме того, современные условия вносят свои коррективы и то, чтобы было оптимальным еще несколько лет назад сегодня утратило свою актуальность или стало нежелательным к применению.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Чем является и чем не является RAID-массив
Наиболее популярен миф, что RAID предназначен для защиты данных, многие настолько верят в это, что забывают про резервное копирование. Но это не так. RAID-массив никоим образом не защищает пользовательские данные, если вы захотите их удалить, зашифровать, отформатировать — наличие или отсутствие RAID вам абсолютно не помешает. Две основных задачи RIAD-массивов — это защита дисковой подсистемы от выхода из строя одного или нескольких дисков и / или улучшение ее параметров по сравнению с одиночным диском (получение более высокой скорости обмена с дисками, большего количества IOPS и т.д.).
Здесь может возникнуть некоторая путаница, ведь сначала мы сказали, что RAID не защищает, а потом выяснилось, что все-таки защищает, но никакой путаницы нет. Основную ценность для пользователя представляют данные, причем не некоторые абстрактные нули-единицы, кластеры и блоки, а вполне «осязаемые» файлы, которые содержат необходимую нам информацию, иногда очень дорогостоящую. Мы будем в последствии называть это пользовательскими данными или просто данными.
RAID-контроллер о данных ничего не знает, он оперирует с блочными устройствами ввода-вывода. И все что поступает к нему от драйвера — это просто поток байтов, который нужно определенным образом разместить на устройствах хранения. Сам набор блочных устройств объединенных некоторым образом отдается системе в виде некоторой виртуальной сущности, которую принято называть массивом, а в терминологии контроллера — LUN, для системы это выглядит как самый обычный диск, с которым мы можем делать все что угодно: размечать, форматировать, записывать данные.
Как видим, работа RAID-контроллера закончилась на формировании LUN и предоставлении его системе, поэтому защита контроллера распространяется только на этот самый LUN — т.е. логическая структура массива, которую система видит как жесткий диск, должна уцелеть при отказе одного или нескольких дисков составляющих этот массив. Ни более, ни менее. Все что находится выше уровнем: файловая система, пользовательские данные — на это «защита» контроллера не распространяется.
Простой пример. Из «зеркала» вылетает один из дисков, со второго система отказывается грузиться, так как часть данных оказалась повреждена (скажем BAD-блок). Сразу возникает масса «претензий» к RAID, но все они беспочвенны. Главную задачу контроллер выполнил — сохранил работоспособность массива. А в том, что размещенная на нем файловая система оказалась повреждена — это вина администратора, не уделившего должного внимания системе.
Поэтому следует запомнить — RAID-массив защищает от выхода из строя одного или нескольких дисков только самого себя, точнее тот диск, который вы видите в системе, но никак ни его содержимое.
BAD-блоки и неисправимые ошибки чтения
Раз мы коснулись содержимого, то самое время разобраться, что же с ним может быть «не так». Начнем с привычного зла, BAD-блоков. Есть мнение, что если на диске появился сбойный сектор — то диск «посыпался» и его надо менять. Но это не так. Сбойные сектора могут появляться на абсолютно исправных дисках, просто в силу технологии, и ничего страшного в этом нет, обнаружив такой сектор контроллер просто заменит его в LBA-таблице блоком из резервной области и продолжит нормально работать дальше.
Дальше простая статистика, чем выше объем диска — тем больше физических секторов он содержит, тем меньше их физический размер и тем выше вероятность появления сбойных секторов. Грубо говоря, если взять произведенные по одной технологии диски объемом в 1ТБ и 4 ТБ, то у последнего вероятность появления BAD-блока в четыре раза выше.
К чему это может привести? Про ситуацию, когда администратор не контролирует SMART и у диска давно закончилась резервная область мы всерьез говорить не будем, тут и так все понятно. Это как раз тот случай, когда диск реально посыпался и его нужно менять. Большую опасность представляет иная ситуация. Согласно исследованиям, достаточно большие объемы данных составляют т.н. cold data — холодные или замороженные данные — это массивы данных доступ к которым крайне редок. Этом могут быть какие-нибудь архивы, домашние фото и видеоколлекции и т.д. и т.п., они могут месяцами и годами лежать не тронутыми никем, даже антивирусом.
Если в этой области данных возникнет сбойный сектор, то он вполне себе может остаться необнаруженным до момента реконструкции (ребилда) массива или попыток слить данные с массива с отказавшей избыточностью. В зависимости от типа массива такой сектор может привести от невозможности выполнить ребилд до полной потери массива во время его реконструкции. По факту невозможность считать данные с еще одного диска в массиве без избыточности можно рассматривать как отказ еще одного диска со всеми вытекающими.
Кроме физически поврежденных секторов на диске могут быть логические ошибки. Чаще всего они возникают, когда контроллер без резервной батарейки использует кеширование записи на диск. При неожиданной потере питания может выйти, что контроллер уже сообщил системе о завершении записи, но сам не успел физически записать данные, либо сделал это некорректно. Попав в область с холодными данными, такая ошибка тоже может жить очень долго, проявив себя в аварийной ситуации.
Ну и наконец самое интересное: неисправимые ошибки чтения — URE (Unrecoverable Read Error) или BER (Bit Error Ratio) — величина, показывающая вероятность сбоя на количество прочитанных головками диска бит. На первый взляд это очень большая величина, скажем для бытовых дисков типичное значение 10^14 (10 в 14 степени), но если перевести ее в привычные нам единицы измерения, то получим примерно следующее:
- HDD массовых серий — 10^14 — 12,5 ТБ
- HDD корпоративных серий — 10^15 — 125 ТБ
- SSD массовых серий — 10^16 — 1,25 ПБ
- SSD корпоративных серий — 10^17 — 12,5 ПБ
В данном случае в качестве единицы измерения мы использовали десятичные единицы измерения объема, т.е. те, что написаны на этикетке диска, исходя из того, что 1 КБ = 1000 Б.
Что это значит? Это значит, что для массовых дисков вероятность появления ошибки чтения стремится к единице на каждые прочитанные 12,5 ТБ, что по сегодняшним меркам не так уж и много. Если такая ошибка будет получена во время ребилда — это, как и в случае со сбойным сектором, эквивалентно отказу еще одного диска и может привести к самым печальным последствиям.
MTBF — наработка на отказ
Еще один важный параметр, который очень многими трактуется неправильно. Если мы возьмем значение наработки на отказ для современного массового диска, скажем Seagate Barracuda 2 Тб ST2000DM008, то это будет 1 млн. часов, для диска корпоративной серии Seagate Enterprise Capacity 3.5 2 Тб ST2000NM0008 — 2 млн. часов. На первый взгляд какие-то запредельные цифры и судя по ним диски никогда не должны ломаться. Однако этот показатель определяет не срок службы устройства, а среднее вермя между отказами — MTBF ( Mean time between failures ) — а в качестве времени подразумевается время работы устройства.
Если у вас есть 1000 дисков, то при MTBF в 1 млн. часов вы будете получать в среднем один отказ на 1000 часов. Т.е. большие значения оказываются не такими уж и большими. Для оценки вероятности отказа применяется иной показатель — AFR (Annual failure rate) — годовая частота отказов. Ее несложно рассчитать по формуле, где n — количество дисков:
AFR = 1 - exp(-8750*n/MTBF)Так для одиночного диска массовой серии годовая частота отказов составит 0,87%, а для корпоративных дисков 0,44%, вроде бы немного, но если сделать расчет для массива из 5 дисков, то мы получим уже 4,28% / 2,16%. Согласитесь, что вероятность отказа в 5% достаточно велика, чтобы сбрасывать ее со счетов. В тоже время такое знание позволяет обоснованно подходить к закупке комплектующих, теперь вы можете не просто апеллировать к тому, что вам нужны корпоративные диски, потому что они «энтерпрайз и все такое…», а грамотно обосновать свое мнение с цифрами в руках.
Но в реальной жизни не все так просто, годовая величина отказов не является статичной величиной, а подчиняется законам статистики, учитывающим совокупность реальных факторов. Не углубляясь в теорию мы приведем классическую кривую интенсивности отказов:
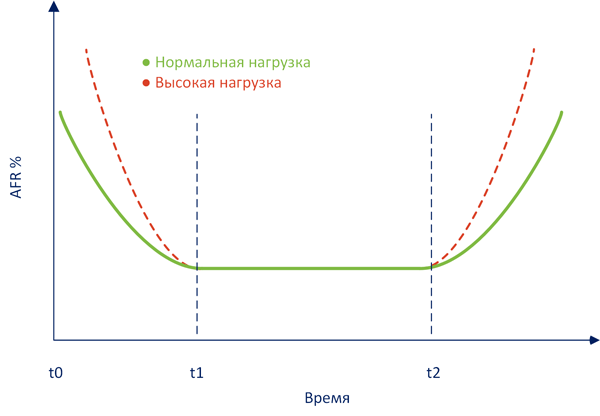 Как можно видеть, в самом начале эксплуатации вероятность отказов наиболее велика, постепенно снижаясь. Этот период, обозначенный на графике t0 — t1, называется периодом приработки. В этот момент вскрывается производственный брак, ошибки в планировании системы, неверные режимы и условия эксплуатации. Повышенная нагрузка увеличивает вероятность отказов, так как позволяет быстрее выявить брак и ошибки эксплуатации.
Как можно видеть, в самом начале эксплуатации вероятность отказов наиболее велика, постепенно снижаясь. Этот период, обозначенный на графике t0 — t1, называется периодом приработки. В этот момент вскрывается производственный брак, ошибки в планировании системы, неверные режимы и условия эксплуатации. Повышенная нагрузка увеличивает вероятность отказов, так как позволяет быстрее выявить брак и ошибки эксплуатации.
За ним следует период нормальной эксплуатации t1-t2, вероятность отказов в котором невелика и соответствует расчетным значениям (т.е. тем показателям, которые мы вычислили выше).
Правее отметки t2 на графике начинается период износовых отказов, когда оборудование начинает выходить из строя выработав свой ресурс, повышенная нагрузка будет только усугублять этот показатель. Также обратите внимание, что функция износа изменяется не линейно, по отношении ко времени, а по логарифмической функции. Т.е. в периоде износа отказы будут увеличиваться постепенно, а не сразу, но, с какого-то момента стремительно.
К чему это может привести? Скажем, если вы эксплуатируете массив, находящийся в периоде износовых отказов и у него выходит из строя один из дисков, то повышенная нагрузка во время ребилда способна привести к новым отказам, что чревато полной потерей массива и данных.
Для жестких дисков и SSD, согласно имеющейся статистики, период приработки где-то равен 3-6 месяцам. А период износовых отказов следует начинать отсчитывать с момента окончания срока гарантии производителя. Для большинства дисков это два года. Это хорошо укладывается в ту же статистику, которая фиксирует увеличение количества отказов на 3-4 году эксплуатации.
Мы не будем сейчас делать выводы и давать советы, приведенных нами теоретических данных вполне достаточно, чтобы каждый мог самостоятельно оценить собственные риски.
Немного терминологии
Прежде чем двигаться дальше — следует определиться с используемыми терминами, тем более что с ними не все так однозначно. Путаницу вносят сами производители, используя различные термины для обозначения одних и тех же вещей, а перевод на русский часто добавляет неопределенности. Мы не претендуем на истину в последней инстанции, но в дальнейшем будем придерживаться описанной ниже системы.
Весь входящий поток данных разбивается контроллером на блоки определенного размера, которые последовательно записываются на диски массива. Каждый такой блок является минимальной единицей данных, с которой оперирует RAID-контроллер. На схеме ниже мы схематично представили массив из трех дисков (RAID 5).
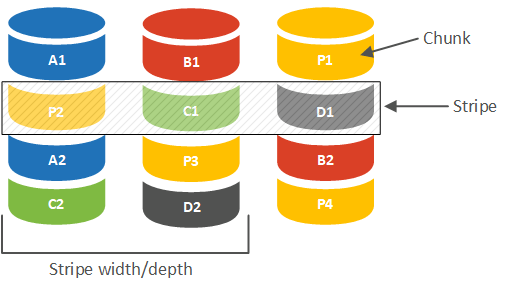 Каждая шайба на схеме представляет один такой блок, для обозначения которого используют термины: Strip, Stripe Unit, Stripe Size или Chunk, Сhunk Size. В русскоязычной терминологии это может быть блок, «страйп», «чанк». Мы, во избежание путаницы с другой сущностью, предпочитаем использовать для его обозначения термин Chunk (чанк, блок), в тоже время встроенный во многие материнские платы Intel RAID использует термин Stripe Size.
Каждая шайба на схеме представляет один такой блок, для обозначения которого используют термины: Strip, Stripe Unit, Stripe Size или Chunk, Сhunk Size. В русскоязычной терминологии это может быть блок, «страйп», «чанк». Мы, во избежание путаницы с другой сущностью, предпочитаем использовать для его обозначения термин Chunk (чанк, блок), в тоже время встроенный во многие материнские платы Intel RAID использует термин Stripe Size.
Группа блоков (чанков) расположенная по одинаковым адресам на всех дисках массива обозначается в русскоязычных терминах как лента или полоса. В англоязычной снова используется Stripe, а также «страйп» в переводах, что в ряде случаев способно внести путаницу, поэтому при трактовании термина всегда следует учитывать контекст его употребления.
Каждая полоса содержит либо набор данных, либо данные и их контрольные суммы, которые вычисляются на основе данных каждой такой полосы. Глубиной или шириной полосы (Stripe width/depth) называется объем данных, содержащийся в каждой полосе.
Так если размер чанка равен 64 КБ (типовое значение для многих контроллеров), то вычислить ширину полосы мы можем, умножив это значение на количество дисков с данными в массиве. Для RAID 5 из трех дисков — это два, поэтому ширина полосы будет 128 КБ, для RAID 10 из четырех дисков — это четыре и ширина полосы будет 256 КБ.
RAID 0
Перейдем, наконец от теории, к разбору конкретных реализаций RAID. Из всех вариантов RAID 0 — единственный тип массива, который не содержит избыточности, также его еще называют чередующимся массивом или страйпом (Stripe).
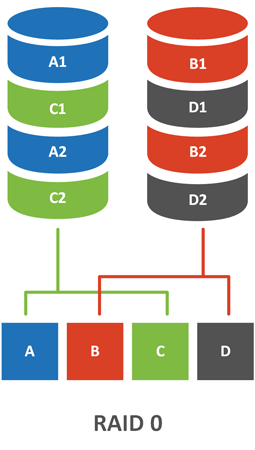 Принцип работы чередующегося массива прост — поток данных делится на блоки (чанки), которые по очереди записываются на все диски массива. При этом ни один диск массива не содержит полной копии данных, зато за счет одновременных операций чтения / записи достигается практически кратный количеству дисков прирост скорости. Объем массива равен сумме объема всех дисков.
Принцип работы чередующегося массива прост — поток данных делится на блоки (чанки), которые по очереди записываются на все диски массива. При этом ни один диск массива не содержит полной копии данных, зато за счет одновременных операций чтения / записи достигается практически кратный количеству дисков прирост скорости. Объем массива равен сумме объема всех дисков.
Несложно заменить, что отказ даже одного диска будет для массива фатальным, поэтому в чистом виде он практически не используется, разве что в тех случаях, когда на первый взгляд выходит быстродействие, при низких требованиях к сохранности данных. Например, рабочие станции, которые размещают на таких массивах только рабочий набор данных, который обрабатывается в текущий момент.
RAID 1
Один из самых популярных видов массивов, знакомый, пожалуй, каждому. RAID 1, он же зеркало (Mirror), состоит обычно из двух дисков, данные на которых дублируют друг друга.
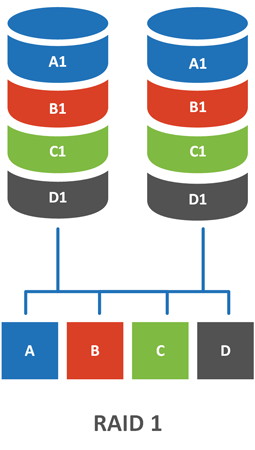 Входящие данные также разбиваются на блоки и каждый блок записывается на все диски массива, тем самым обеспечивая избыточность. При отказе одного из дисков на втором у нас остается полная копия данных. Дополнительный плюс в том, что для восстановления таких данных не требуется никаких дополнительных операций, вы можете просто присоединить диск к любому ПК и выполнить с него чтение, что важно, если ребилд массива по какой-либо причине сделать не удастся.
Входящие данные также разбиваются на блоки и каждый блок записывается на все диски массива, тем самым обеспечивая избыточность. При отказе одного из дисков на втором у нас остается полная копия данных. Дополнительный плюс в том, что для восстановления таких данных не требуется никаких дополнительных операций, вы можете просто присоединить диск к любому ПК и выполнить с него чтение, что важно, если ребилд массива по какой-либо причине сделать не удастся.
Но за это приходится платить большими потерями емкости — емкость массива равна емкости одного диска, поэтому зеркала с более чем двумя дисками на практике не используют. Также это негативно сказывается на быстродействии. Вспомним, что еще одной причиной объединения дисков в массивы является увеличение быстродействия, при этом важна не линейная скорость записи / чтения, а количество операций ввода вывода в секунду — IOPS — которые может предоставить диск.
В первом приближении общее количество IOPS массива — это суммарное количество IOPS его дисков, но на практике оно будет меньше за счет накладных расходов в самом массиве. В RAID 1 для выполнения одной операции записи массив производит две записи данных, по одной на каждый диск. Этот параметр называется RAID-пенальти и показывает сколько операций ввода вывода делает массив для обеспечения одной операции записи. Операции чтения не подвержены пенальти.
Для RAID 1 пенальти равно двум. Поэтому его производительность на запись не отличается от производительности одиночного жесткого диска. На чтение, теоретически, можно достичь двойной производительности за счет одновременного чтения с разных дисков, но на практике такая функция в контроллерах не реализуется. Поэтому чтение с зеркала также не отличается по производительности от одиночного диска.
Как видим, RAID 0 предоставляет нам высокую производительность при отсутствии надежности, а RAID 1 — высокую надежность без увеличения производительности. Поэтому существуют комбинированные уровни RAID, сочетающие достоинства нескольких типов массивов.
RAID 01 (0+1)
Этот тип массива часто путают с RAID 10, но это неверно, первым числом в наименовании массива всегда указывается вложенный массив, а вторым — внешний. Таким образом RAID 01 — зеркало из страйпов, а RAID 10 — страйп из зеркал. Какая разница? А вот сейчас и посмотрим.
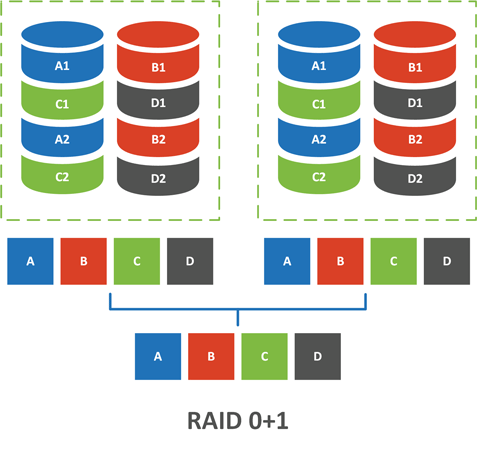 Так как внешним массивом является RAID 1 — зеркало, то на оба вложенных чередующихся массива подается одинаковый набор данных, который распределяется без избыточности по дискам массива. В итоге получаем два одинаковых RAID 0 массива, которые собраны в зеркало.
Так как внешним массивом является RAID 1 — зеркало, то на оба вложенных чередующихся массива подается одинаковый набор данных, который распределяется без избыточности по дискам массива. В итоге получаем два одинаковых RAID 0 массива, которые собраны в зеркало.
Что случится при отказе одного диска? Ничего страшного, массив выдерживает такой отказ. А если выйдут из строя два? В этом случае возможны варианты:
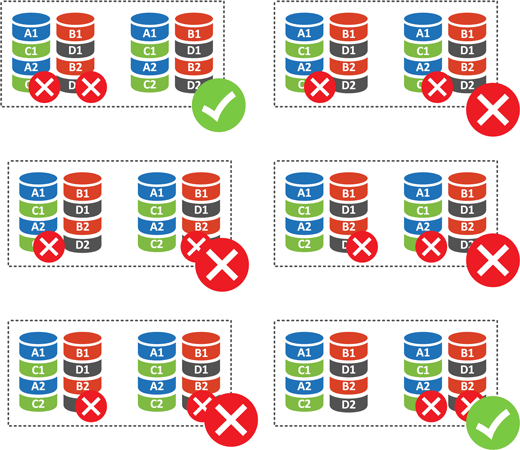
Для массива из четырех дисков (а это минимальное количество для этого уровня RAID) у нас есть шесть вариантов отказа двух дисков. Исходя из того, что отказ из любого диска RAID 0 является для него фатальным, то получаем 4 отказа из 6 или 66,67%. Т.е. при потере двух дисков вы потеряете свои данные с вероятностью 66,67%, что довольно-таки много.
RAID 10
«Десятка» также собирается минимум из 4 дисков, но внутренняя структуре ее зеркально отличается от 0+1:
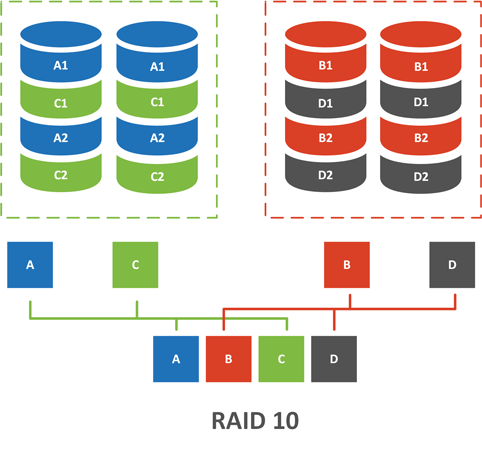 Массив верхнего уровня RAID 0 — делит входящие данные и распределяет их между низлежащими массивами RAID 1. В итоге получаем чередующийся массив из нескольких зеркал. В чем тут принципиальная разница с предыдущим массивом? А вот в чем, снова рассмотрим ситуацию отказа сразу двух дисков:
Массив верхнего уровня RAID 0 — делит входящие данные и распределяет их между низлежащими массивами RAID 1. В итоге получаем чередующийся массив из нескольких зеркал. В чем тут принципиальная разница с предыдущим массивом? А вот в чем, снова рассмотрим ситуацию отказа сразу двух дисков:
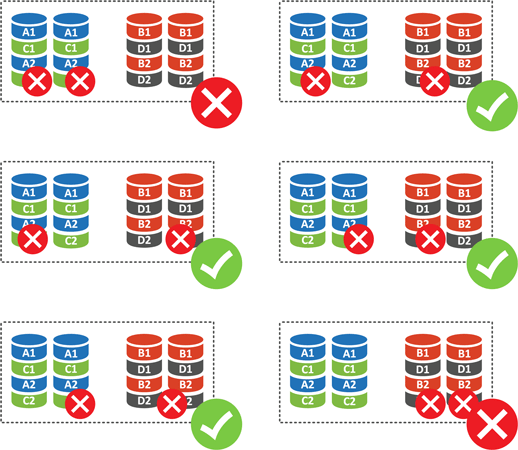 В отличие от страйпа, для отказа зеркала нужен выход из строя обоих диском массива и только эта ситуация приведет к полному отказу RAID 10, из 6 вариантов это произойдет только в двух случаях, т.е. вероятность потери данных при отказе двух дисков в RAID 10 равна 33,33%. А теперь сравните это с 66,77% у RAID 0+1, поэтому в настоящее время применяется исключительно RAID 10, так как при одинаковых показателях производительности обеспечивает гораздо более высокую надежность.
В отличие от страйпа, для отказа зеркала нужен выход из строя обоих диском массива и только эта ситуация приведет к полному отказу RAID 10, из 6 вариантов это произойдет только в двух случаях, т.е. вероятность потери данных при отказе двух дисков в RAID 10 равна 33,33%. А теперь сравните это с 66,77% у RAID 0+1, поэтому в настоящее время применяется исключительно RAID 10, так как при одинаковых показателях производительности обеспечивает гораздо более высокую надежность.
Пенальти RAID 10, также, как и RAID 1 равно двум, но за счет наличия четырех дисков он обеспечивает скоростные показатели аналогичные RAID 0 при надежности сопоставимой с RAID 1, емкость массива равна емкости половины его дисков.
На сегодня RAID 10 — наиболее производительный RAID-массив с высокой надежностью, его единственный и довольно существенный недостаток — высокие накладные расходы — 50% (половина дисков используется для создания избыточности).
RAID 5
Существует распространенное заблуждение, что RAID 5 (и RAID 6) — это более «крутые» уровни RAID, правда редко кто при этом может пояснить чем они «круче», но миф продолжает жить и очень часто администраторы выбирают уровень RAID исходя из таких вот заблуждений, а не реальных показателей.
Устройство RAID 5 более сложно, чем у «младших» уровней RAID и здесь появляется понятие контрольной суммы, на же Рarity, четность. В основу алгоритма положена логическая функция XOR (исключающее ИЛИ), так для трех переменных будет справедливо равенство:
a XOR b XOR c = pГде p — контрольная сумма или четность. При этом мы всегда можем вычислить любую из переменных зная четность и остальные значения, т.е.:
a = p XOR b XOR c
b = a XOR p XOR c
c = a XOR b XOR pДанные формулы остаются справедливы для любого количества переменных, позволяя обходится единственным значением четности. Таким образом минимальное количество дисков в RAID 5 будет равно трем: два диска для данных и один диск для четности. Раньше существовали реализации RAID 3 и 4, которые использовали для хранения блоков четности отдельный диск, что приводило к высокой нагрузке на него, в RAID 5 поступили иначе.
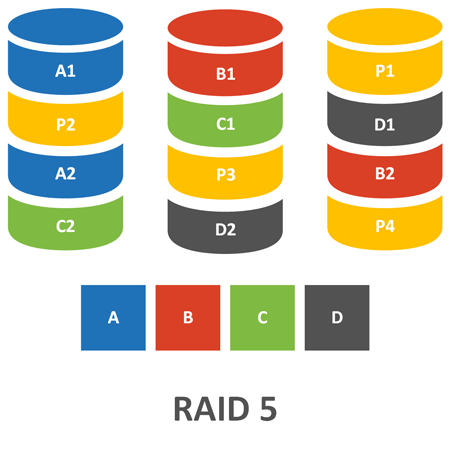 Здесь данные точно также разбиваются на блоки и распределяются по дискам, как в RAID 0, но появляется еще и понятие полосы, для каждой полосы данных вычисляется контрольная сумма и записывается в той же полосе на отдельном диске, т.е. один из дисков полосы выполняет роль диска для хранения четности. В следующей полосе происходит чередование дисков, теперь два других диска будут хранить данные, а третий четность. Таким образом достигается равномерное использование всех дисков, что снижает нагрузку на диски и повышает производительность массива в целом.
Здесь данные точно также разбиваются на блоки и распределяются по дискам, как в RAID 0, но появляется еще и понятие полосы, для каждой полосы данных вычисляется контрольная сумма и записывается в той же полосе на отдельном диске, т.е. один из дисков полосы выполняет роль диска для хранения четности. В следующей полосе происходит чередование дисков, теперь два других диска будут хранить данные, а третий четность. Таким образом достигается равномерное использование всех дисков, что снижает нагрузку на диски и повышает производительность массива в целом.
Основным стимулом создания RAID 5 было более оптимальное использование дисков в массиве, так в массиве из 3 дисков накладные расходы RAID 5 составят 33%, из 4 дисков — 25 %, из 6 дисков — 16%. Но при этом вырастает пенальти, в RAID 5 на одну операцию записи приходятся операции: чтение данных, чтение четности, запись новых данных, запись четности. Таким образом пенальти для RAID 5 составляет четыре.
Это означает, что производительность на запись массивов из небольшого числа дисков (менее 5) будет ниже, чем у одиночного диска, но производительность чтения будет сравнима с RAID 0. При этом массив допускает отказ любого одного диска.
В этом месте мы подходим к развенчанию одного из мифов, что RAID 5 «круче», нет, он не «круче», а по производительности даже уступает тому же RAID 10 (а иногда даже и зеркалу). Но по соотношению производительности, накладных расходов и надежности данный уровень RAID представлял наиболее разумный компромисс, что и обеспечило его популярность.
Внимательный читатель заметит, что в прошлом абзаце мы высказались о преимуществах RAID 5 в прошедшем времени, действительно это так, но, чтобы понять почему, следует поговорить о недостатках, которые наиболее ярко проявляются при выходе из строя одного из дисков.
В отличие от RAID 1 / 10 при отказе диска RAID 5 не будет содержать полной копии данных, только их часть плюс контрольные суммы. Это означает что у нас появится пенальти на чтение — для чтения недостающего фрагмента данных нам потребуется полностью считать полосу и провести ряд вычислений для восстановления отсутствующих значений. Это резко снижает производительность массива и увеличивает нагрузку на него, что может привести к выходу из строя оставшихся дисков.
При отказе одного диска массив переходит в режим деградации, при этом по его надежность начинает соответствовать RAID 0, т.е. отказ еще одного диска, BAD-блок или ошибка URE могут стать для него фатальными. При замене неисправного диска массив переходит в режим реконструкции (ребилда), который сопряжен с высокой нагрузкой на оборудование, так как для восстановления контроллер должен прочитать весь объем данных массива. Любой сбой в процессе ребилда также может привести к полному разрушению массива.
А теперь вспомним значение URE для современных массовых дисков — 10^14, что это значит в нашем случае? А то, что собрав RAID 5 из четырех дисков на 4 ТБ (с объемом данных 12 ТБ) вы с вероятностью очень близкой к 100% получите невосстановимую ошибку чтения при ребилде и потеряете массив полностью.
Но это не значит, что RAID 5 изначально имел столь критические недостатки. Вернемся на 10 лет назад, основной объем ходовых моделей дисков тогда составлял 250-500 ГБ, URE для популярной тогда серии Barracuda 7200.10 был теми же 10^14, а MTBF был немного ниже — 700 тыс. часов.
Допустим мы собрали тогда массив из 4 дисков по 750 ГБ (топовые диски на тот момент), объем данных такого массива составит 2,25 ТБ, вероятность получить URE будет в районе 18%. В общем и целом — немного, большинство успешно реконструировало массив, а голоса тех, кому не повезло, тонули в общем хоре тех, у кого все было хорошо.
Но сегодня RAID 5 в принципе неприменим с массовыми сериями дисков, и с определенными оглядками применим на корпоративных сериях. Не смотря на более высокое значение URE последних, не будем забывать о возможных сбойных областях в зоне холодных данных, а чем больше объем дисков, тем больше секторов, тем больше вероятность сбоя в одном из них.
Также это хорошая иллюстрация пагубности мифов, так как собрав сегодня «крутой» массив RAID 5 вы с очень большой вероятностью просто угробите все свои данные при отказе одного из дисков.
RAID 5E
Как мы уже успели выяснить, ситуация с отказом одного из дисков является для RAID 5 критической — массив переходит в режим деградации с серьезным падением производительности и существенным ростом нагрузки на диски, а его надежность падает до уровня RAID 0 и любая ошибка способна полностью разрушить массив с полной потерей данных. Поэтому чем быстрее мы заменим сбойный диск — тем скорее выведем массив из зоны риска.
Первоначально этот вопрос решался, да и решается до сих пор, выделением диска горячей замены. Такой диск может быть выделенным, т.е. привязанным к указанному массиву, или разделяемым, тогда в случае отказа он будет использован одним из отказавших массивов. Но у этого подхода есть серьезный недостаток — фактически мы никак не используем резервный диск, а так как отказы происходят не каждый день, то его ресурс просто тратится впустую.
RAID 5E предлагает иной подход, пространство резервного диска разделяется между остальными дисками и остается неразмеченным в конце каждого диска массива.
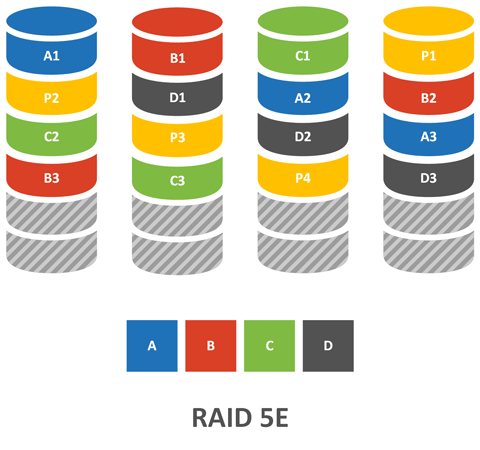 Такой подход связан с некоторыми ограничениями, а именно — один раздел на один массив. Из плюсов — более высокая производительность за счет использования дополнительного диска. Что происходит при отказе? Массив автоматически начинает реконструкцию размещая данные в неразмеченной области (производит сжатие), после чего массив фактически превращается в простой RAID 5 и способен выдержать отказ еще одного диска (но не во время перестроения).
Такой подход связан с некоторыми ограничениями, а именно — один раздел на один массив. Из плюсов — более высокая производительность за счет использования дополнительного диска. Что происходит при отказе? Массив автоматически начинает реконструкцию размещая данные в неразмеченной области (производит сжатие), после чего массив фактически превращается в простой RAID 5 и способен выдержать отказ еще одного диска (но не во время перестроения).
При замене неисправного диска массив переносит данные из резервной области на новый диск и снова начинает работать как RAID 5E (производит развертывание), при этом операция развертывания не сопряжена с дополнительными рисками, отказ диска или ошибка в данной ситуации не будут фатальными.
RAID 5EE
Дальнейшее развитие RAID 5E, в котором отказались из за размещения резервной области в конце диска (самая медленная его часть), а разбили ее на блоки и также как и блоки четности начали чередовать между дисками. Основное преимущество такого подхода — это более быстрый процесс реконструкции, а так как в этом состоянии массив особо уязвим, то уменьшение времени ребилда — это повышение надежности всего массива.
 Кроме того, такой подход позволяет выровнять нагрузку по дискам, что должно положительно сказываться на надежности. Ограничения остались те же — один раздел на один массив.
Кроме того, такой подход позволяет выровнять нагрузку по дискам, что должно положительно сказываться на надежности. Ограничения остались те же — один раздел на один массив.
Также ни RAID 5E, ни RAID 5EE не лишились недостатка простого RAID 5 — на современных объемах массивов вероятность успешного ребилда такого массива очень невелика.
RAID 6
В отличие от RAID 5 этот массив использует две контрольные суммы и два диска четности, поэтому для него понадобятся 4 диска, при этом допускается выход из строя двух из них. Также, как и у RAID 5 алгоритм позволяет использовать всего две контрольные суммы вне зависимости от ширины полосы и общий объем массива всегда будет равен объему всех дисков за вычетом двух. При отказе одного диска RAID 6 выдерживает отказ еще одного, либо ошибку чтения без фатальных последствий.

Казалось бы, вот он — новый компромисс, замена RAID 5 в современных условиях и т.д. и т.п., но за все надо платить. Одна операция записи на такой массив требует большего количества операций внутри массива: чтение данных, чтение четности 1, чтение четности 2, запись данных, запись четности 1, запись четности 2 — итого 6 операций, таким образом пенальти RAID 6 равен шести.
В общем, повысив надежность, данный массив существенно потерял в производительности настолько, что многие поставщики не рекомендуют его использование кроме как для хранения холодных данных.
И снова вернемся к мифам: RAID 6 это «круто»? Может быть, во всяком случае за свои данные можно не беспокоиться. А почему так медленно? Так это плата за надежность…
RAID 6E
По сути, тоже самое, что и RAID 5E. Резервный диск точно также распределяется в виде неразмеченного пространства в конце дисков, с теми же самыми ограничениями — один раздел на один массив. Ну и добавьте еще один диск в минимальное количество для массива, для RAID 5E это было 4, для RAID 6E — 5.
RAID 50 и RAID 60
Комбинированные массивы, аналогичные RAID 10, только вместо зеркала используется чередование нескольких массивов RAID 5 или RAID 6. Основная цель при создании таких массивов — более высокая производительность, надежность их в минимальном варианте соответствует надежности внутреннего массива, но в зависимости от ситуации может выдерживать отказ и большего количества дисков.
Заключение
Данная статья в первую очередь предназначена для исключения пробелов в знаниях и не претендует на какие-либо рекомендации. Тем не менее кое какие выводы можно сделать. RAID 5 в современных условиях применять не следует, скорее всего вы потеряете свои данные в любой нештатной ситуации.
RAID 10 остается наиболее производительным массивом, но имеет большие накладные расходы — 50%.
RAID 6 имеет наиболее разумное сочетание надежности и накладных расходов, но его производительность оставляет желать лучшего.
При этом мы оставили за кадром многие технологии, скажем RAID DP — реализацию RAID 6 от производителя систем хранения NetApp, которая предлагает все достоинства RAID 6 вкупе в высокой производительностью, на уровне RAID 0. Или RAID-Z — систем на основе ZFS, которые являются программными реализациями и для обзора которых потребуется отдельная статья.
Также мы надеемся, что данный материал поможет вам в осознанном выборе уровня RAID-массива согласно вашим требованиям.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
2
4
Вылетел сегодня ночью винт из RAID массива 5 уровня.
Массив состоял из 3-х дисков Western Digital по 2ТБ каждый.
Вначале начали сыпаться ошибки типа:
ata2.00 input/outpur error
ata2.00: exception emask
ata2.00: failed command: MULTIREAD
После чего сервер зависал, интернет и диски отваливались.
Сам сервер состоит из 4-х дисков. Один под систему, другие 3 - это вышеуказанный массив. ОС Ubuntu.
SMART показывает, что все диски живы.
При попытке пересобрать массив, пишет:
raid5: cannot start dirty degraded array for md0
raid5: failed to run raid set md0
md: pers->run() failed ...
mdadm: failed to RUN_ARRAY /dev/md0: Input/output error
http://i68.fastpic.ru/big/2014/0831/95/1d54bab199a150bf73a879a207bf2495.jpg
http://i68.fastpic.ru/big/2014/0831/61/8507d5212bc7f7652cc1afd05a472661.jpg
Говорит, что массив dirty и не дает его собрать. В интернетах пишут, что статус dirty можно убрать на свой страх и риск:
echo "clean" > /sys/block/md0/md/array_state
http://www.devinzuczek.com/2010/09/raid5-cannot-start-dirty-degraded-array-fo…
Еще проблема упоминается здесь:
http://www.tampabaycomputing.com/blog/raid5-cannot-start-dirty-degraded-array…
Не могу понять, почему нельзя пересобрать массив и почему он развалился. Системный блок сильно запылился, может контроллер материнки сглюкнул. Сейчас буду чистить и менять шлейфы винтов на запасные.
Подскажите, пожалуйста, как пересобрать массив, как с этими статусами dirty degraded быть?
На рынке доступно большое количество накопителей различных скоростей, различных производителей. Далеко не все четко понимают, какой диск лучше приобрести и для какой задачи и зачем порой лучше заплатить больше, а когда можно сэкономить. В этой статье я постараюсь прояснить основные моменты и сделать проблему выбора более простой. Статья будет полезна не только тем, кто хочет купить/арендовать выделенный сервер, но и тем, кто хочет получить надежное хранилище информации дома. После прочтения материала станет понятным, почему не всегда целесообразно арендовать desktop-решения в low-cost дата-центрах и лучше остановить выбор на более надежном, серверном железе.
Начнем с того, что все имеющиеся на рынке накопители, можно четко разделить на классы:
— диски для обычных desktop-ов (применяются в домашних ПК, в ноутбуках и в desktop-серверах low-cost дата-центров);
— серверные диски со скоростью 7200 оборотов в минуту (RPM);
— Enterprise-диски со скорость 10 000 и 15 000 RPM;
— твердотельные накопители.
Особенности выбора твердотельных накопителей мы, пожалуй, рассмотрим в отдельной статье, а сейчас остановимся преимущественно на жестких дисках и рассмотрим какой диск где и когда целесообразно применять.
Начнем с обычных дисков для PC. Это отличные диски с довольно большой емкостью и хорошей производительностью, но их главный недостаток в том, что они не рассчитаны на работу в RAID-массиве в силу своих конструктивных особенностей. В этих дисках вибрации, вызываемые вращением шпинделя, практически никак не компенсируются. Конечно эти вибрации минимальны и в случае применения 1-2 дисков в домашних условиях они не являются проблемой. Однако, если рассматривать серверный случай, когда дисков много, влияние вибраций может быть довольно существенным, так как возникают взаимные вибрации, резонанс усиливает эффект. Так, когда в корпусе установлено сразу 12 дисков, да еще и работают довольно мощные серверные вентиляторы по 5000-9000 оборотов в минуту — уровень вибрации нарастает довольно значительно, а с ними и % ошибок, потерь, что и оказывает негативное влияние на производительность. Производительность дисков десктопного типа падает в этих случаях в разы, так как они испытывают значительные трудности с позиционированием головок, теряют дорожку. Это хорошо можно видеть из популярного графика зависимости производительности от вибрационной нагрузки:
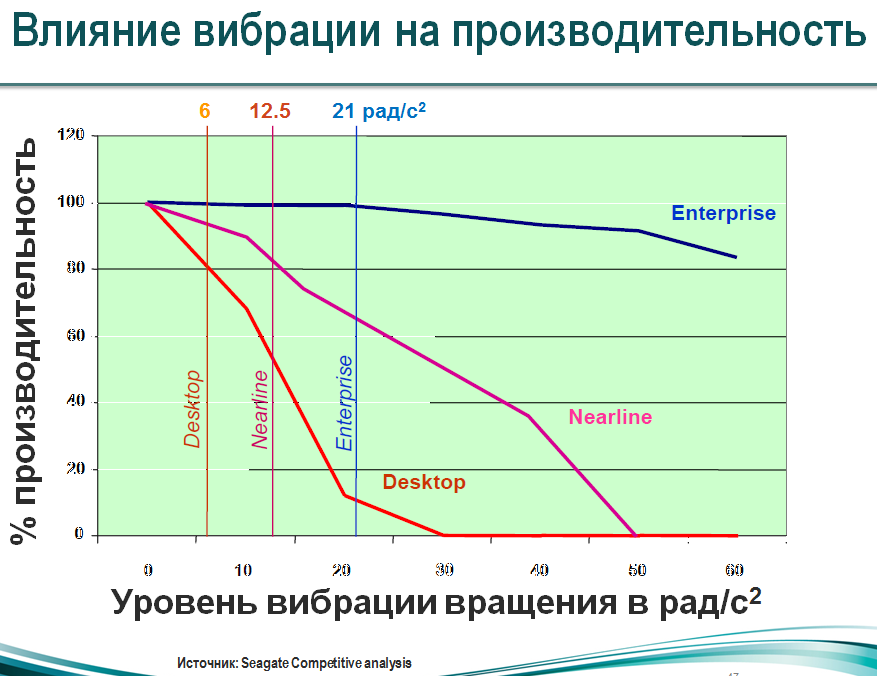
Другое дело диски SATA RE (RAID Edition) или же серверные диски со скоростью 7200 RPM. Они менее подвержены вибрациям и в меньшей степени зависят от них. Как видим из графика — вероятность возникновения ошибки в результате вибраций на 50% ниже для них.
Но не только вибрации являются проблемой, другая основная проблема всех дисков — уровень невозобновимых ошибок. Что это означает на практике?
Для SATA PC дисков уровень невозобновимых ошибок 1 ошибка на 1014 бит, или 1 ошибка на 12,5 ТБ данных. Диск на 1ТБ имеет 1000/12500х1014 бит. 5 дисков имеют емкость 5х(1000/12500х1014) бит, а вероятность возникновения ошибки при работе этих дисков в массиве RAID5 будет составлять (5х(1000/12500х1014))/1014x100% = 40%.
Как видим, использовать 5 PC-дисков в RAID5 просто нельзя, так как вероятность возникновения невосстановимой ошибки при ребилде очень высока и ребилд завершится скорее неудачно. Таким образом мы получим массив, который заведомо выйдет из строя в случае ребилда и данные будут утеряны. Ранее я не знал об этой особенности и в 2008-м году, когда собирал свой первый сервер еще на PC-шных накопителях, построил именно RAID5-массив, с целью экономии дискового пространства и денег, и менее, чем через месяц, данные были потеряны. Сейчас мне удивительно, что массив прожил так долго 🙂
Конечно, можно применять более надежные уровни RAID, такие, как RAID10 или в крайнем случае RAID6, но при большом количестве дисков мы также будем получать довольно высокую степень вероятности возникновения невосстановимой ошибки во время ребилда.
Другое дело серверные диски со скоростью 7200 оборотов в минуту (RPM) SATA RE или диски Near Line (NL) SAS. Вероятность невосстановимой ошибки для них на порядок меньше уже за счет их технических особенностей, 1 ошибка возникает на 1015 бит данных. Тем не менее, при использовании не только большого количества накопителей, но и накопителей большого объема — этого может быть уже недостаточным и в таких случаях все же придется применять SAS-накопители Enterprise класса, степень надежности которых 1 невосстановимая ошибка на 1016 бит данных.
Стоит также отметить, что на самом деле для дисков SATA RE, Near Line (NL) SAS и дисков SAS Enterprise-класса, по сути дисков, которые умеют эффективно взаимодействовать с RAID-контроллером, вероятность возникновения невосстановимой ошибки еще значительно меньше, как раз за счет этой способности. Так, при работе с нагруженным массивом (базы данных, с которыми работают сразу много пользователей, активная запись и считывание данных) начинают играть роль уже восстановимые ошибки, с которыми обычные диски работают неэффективно. Они пытаются перечитать проблему многократно — в тех же Western Digital значение установлено на 64 прохода головки с разными параметрами высоты, угла, только после чего головка переходит к обработке других задач. За счет этого сильно возрастает время ожидания, которое RAID не терпит и непременно сочтет диск потерянным и попытается восстанавливать диск, в результате чего нагрузка на массив приобретет критичный характер, так как одновременно с рабочей нагрузкой будет идти еще и ребилд. Результат предсказуем — крах всего массива.
Диски, которые умеют работать с RAID, могут сообщить RAID-контроллеру, что есть проблема с чтением блока данных, запросить этот блок с других дисков и в это время обрабатывать другие запросы, а получив блок — перезаписать его в другом месте проблемного диска. За счет этого никакого падения производительности RAID-массива не происходит и вероятность потери данных снижается значительно. Однако следует отметить, что не все софтовые рейд-контроллеры, установленные на чипсетах, умеют «понимать» такие диски, потому порой недостаточно иметь диски RE для надежного массива, а все же требуется применение аппаратного контроллера или другой платформы, которая корректно работает с RAID.
Тем не мене, если есть желание собрать более надежное хранилище, нежели хранилище на PC-накопителях, можно купить более дешевые диски, нежели диски RE, к примеру Constellation CS, которые предназначены для работы исключительно с софтовыми рейдами и лишены недостатка десктопных (попыток многократного перечитывания данных в ущерб другим задачам), при этом полноценно, само собой, с контроллерами они не взаимодействуют, так что cбои RAID полностью не исключены.
Вне зависимости от того, какой накопитель Вы применяете, Вы также должны помнить о том, что у дисков есть кеш — 32, 64 МБ и более. Что это значит для RAID-массива? С точки зрения производительности кеш является плюсом, как для чтения, так и для записи. Однако с точки зрения надежности записи — это минус. Используя кеш, рейд-контроллер будет думать, что уже записал данные на массив, но на самом деле они могут быть только в кеше, а на диск записаны быть позднее. В зависимости от размера массива растет и размер общего кеша, и в случае 12 накопителей кеш составляет уже почти гигабайт. Что произойдет с данными при отключении питания? Правильно. Они будут утеряны. И если речь идет о файлопомойке, тут, наверное, не на столько критично, но если же речь идет о базах данных — будет весело. Потому рекомендуется для данных особой критичности, такие, как базы данных, все же отключать кеш на запись. Это снизит производительность диска на 8-15% в режиме баз данных, однако в значительной степени увеличит надежность. По этой причине, если Вы приобретаете хранилище данных большой емкости, крупные производители отключают там кеш по умолчанию и включить его невозможно. Применяя же диски в серверах, особенно в low-сost дата-центре, где питание к серверу не резервировано, нужно помнить об этом риске и учитывать его.
Также отметим еще одну ключевую особенность дисков SAS Enterprise-класса, на них данные хранятся еще более надежно, так как минимальный размер кластера составляет 520 байт, а не 512, добавляется еще 8 байт для проверки четности. Применяется большое количество алгоритмов восстановления данных без участия контроллера. Именно по этой причине объем этих дисков не бывает очень большой.
К слову на счет объема, крайняя рекомендация, если у Вас есть задача хранить данные надежно, не пытайтесь использовать диски большего объема, нежели это необходимо, так как в случае ребилда восстановление будет занимать больше времени. Как правило контроллеры не анализируют то, сколько реально занято на диске и восстанавливают весь диск в целом, потому разница во времени восстановления между 1 ТБ и 6 ТБ накопителем будет более, чем в 6 раз.
Подведем итоги. Исходя из вышеизложенного понятно, что для небольшого RAID-массива, применение самых дорогостоящих дисков Enterprise класса не принципиально и не дает никаких преимуществ в надежности. Тем не менее, применение серверных дисков весьма желательно, так как в этом варианте на порядок большая вероятность того, что ребилд завершится успешно. Не следует применять диски большего объема, чем это необходимо, за исключением случаев, когда нужно обеспечить более высокую производительность по IOPS (в некоторых дисках большего объема все же может быть выигрыш по скорости за счет большего количества головок и пластин). В случаях, когда необходим большой объем и много дисков и при этом достаточный уровень надежности — можно смотреть в сторону SAS NL, которые по сути являются модифицированным вариантом накопителей SATA RE за счет интерфейса SAS, однако имеют все те же 7200 RPM. Для повышения уровня надежности целесообразно применять RAID более высокого уровня. Когда же объем массива не принципиален и требуется максимальная надежность, нужно однозначно применять SAS 15000 RPM Enterprise.
Теперь, выбирая в аренду сервер в Нидерландах, у нас на площадке Switch, при помощи конфигуратора, расположенного в нижней части страницы http://www.ua-hosting.company/servers, либо, модифицируя одно из спец. предложений:



Приходит понимание того, какие диски и какой из серверов лучше использовать и для каких задач, когда лучше использовать диски в RAID, а когда по отдельности, распределяя файлы софтом в зависимости от популярности (скрипт балансера в зависимости от нагрузки). Почему 4 диска большего объема, в плане надежности, может быть лучше, чем 12 меньшего, но хуже в плане времени восстановления в случае ребилда. Ну и самое важное — почему наше предложение реально крутое для серверного сегмента и мы реально приблизили цену к desktop-площадкам, при этом сохранив на порядок более высокую надежность без преувеличений! Так что если Вам, либо Вашим знакомым нужен хороший сервер — welcome, распродажа некоторых конфигураций из списка ниже ограничена, очень скоро цены на эти конфигурации будут выше, мы хоть и щедры, но не безгранично :):




Да, если у кого-то есть реальный опыт применения тех или других накопителей для определенных задач — не стесняйтесь делиться им в комментариях. Интересно все, вплоть до статистики отказов. На эту тему, как и по поводу проблематики выбора SSD-накопителя, мы постараемся опубликовать материал позднее.
Toggle the table of contents
From Wikipedia, the free encyclopedia
(Redirected from S.M.A.R.T.)
![]()
Look up smart or SMART in Wiktionary, the free dictionary.
Smart, SMART or S.M.A.R.T. may refer to:
Arts and entertainment[edit]
- Smart (Hey! Say! JUMP album), 2014
- Smart (Hotels.com), former mascot of Hotels.com
- Smart (Sleeper album), 1995 debut album by Sleeper
- SMart, a children’s television series about art on CBBC
Businesses and brands[edit]
- S-Mart, a Mexican grocery store chain
- Smart (advertising agency), an Australian company
- SmartCell, a network operator in Nepal
- Smart Communications, a cellular service provider in the Philippines
- Smart Technologies, a company providing group collaboration tools
- Smart Telecom, a network operator in the Republic of Ireland
- Smart (cigarette), an Austrian brand
- Smart (drink), a brand of fruit-flavored soda produced by The Coca-Cola Company for Mainland China
Computing[edit]
- Smart device, an electronic device connected to other devices or networks wirelessly
- Self-Monitoring, Analysis, and Reporting Technology (S.M.A.R.T.), a standard used in computer storage devices
- SMART Information Retrieval System, an information retrieval system developed at Cornell University in the 1960s
- Smart Package Manager, a planned successor to the APT-RPM package management utility
Grants[edit]
- Small firms’ Merit Award for Research and Technology, run by the UK Department of Trade and Industry in the 1980s and 1990s
- Smart Scotland
- National Science & Mathematics Access to Retain Talent Grant, a former US federal grant
- SMART Defense Scholarship Program, a US Department of Defense workforce development program
Transport[edit]
- Smart (marque), a car manufacturer co-owned by Mercedes-Benz and Geely
- SMART Tunnel, the Stormwater Management and Road Tunnel in Kuala Lumpur, Malaysia
- Scandinavian Multi Access Reservations for Travel Agents, a computerized system for ticket reservation
United States[edit]
- Sonoma–Marin Area Rail Transit, in the northern San Francisco Bay Area, California
- South Metro Area Regional Transit in Wilsonville, Oregon
- Starkville MSU Area Rapid Transit, a public transportation system in Starkville, Mississippi, and Mississippi State University
- Suburban Mobility Authority for Regional Transportation, the transit authority for suburban Detroit, Michigan
Other uses[edit]
- Smart (surname), a surname (including a list of people with the name)
- Smart Museum of Art, a museum in Chicago
- Simple Modular Architecture Research Tool, a biological database used in the identification and analysis of protein domains within protein sequences
- SMART (Malaysia), a disaster relief and rescue task force
- International Association of Sheet Metal, Air, Rail and Transportation Workers (SMART), a North American labor union
- Sikh Mediawatch and Resource Task Force, the former name of the Sikh American Legal Defense and Education Fund
- Start Making A Reader Today, an Oregon-based volunteer literacy program for at-risk PreK-3 readers
- Studies in Medieval and Renaissance Teaching, or SMART, a peer-reviewed journal
- SMArt 155, a German artillery shell that uses anti-armour submunitions
- Smart #1, an upcoming electric crossover SUV
- SMART criteria (specific, measurable, assignable, realistic, time-related), a mnemonic used to set goals or objectives and evaluate performance
- SMART Recovery (Self Management and Recovery Training), addiction recovery based on REBT principles
- SMART-1 (Small Missions for Advanced Research in Technology), a series of European Space Agency space missions
- SMART-R, the Shared Mobile Atmospheric Research and Teaching Radar
- Intelligence
See also[edit]
- Smartt (disambiguation)
- Snart (disambiguation)
- Smarts (disambiguation)
- All pages with titles beginning with smart
Toggle the table of contents
From Wikipedia, the free encyclopedia
(Redirected from S.M.A.R.T.)
![]()
Look up smart or SMART in Wiktionary, the free dictionary.
Smart, SMART or S.M.A.R.T. may refer to:
Arts and entertainment[edit]
- Smart (Hey! Say! JUMP album), 2014
- Smart (Hotels.com), former mascot of Hotels.com
- Smart (Sleeper album), 1995 debut album by Sleeper
- SMart, a children’s television series about art on CBBC
Businesses and brands[edit]
- S-Mart, a Mexican grocery store chain
- Smart (advertising agency), an Australian company
- SmartCell, a network operator in Nepal
- Smart Communications, a cellular service provider in the Philippines
- Smart Technologies, a company providing group collaboration tools
- Smart Telecom, a network operator in the Republic of Ireland
- Smart (cigarette), an Austrian brand
- Smart (drink), a brand of fruit-flavored soda produced by The Coca-Cola Company for Mainland China
Computing[edit]
- Smart device, an electronic device connected to other devices or networks wirelessly
- Self-Monitoring, Analysis, and Reporting Technology (S.M.A.R.T.), a standard used in computer storage devices
- SMART Information Retrieval System, an information retrieval system developed at Cornell University in the 1960s
- Smart Package Manager, a planned successor to the APT-RPM package management utility
Grants[edit]
- Small firms’ Merit Award for Research and Technology, run by the UK Department of Trade and Industry in the 1980s and 1990s
- Smart Scotland
- National Science & Mathematics Access to Retain Talent Grant, a former US federal grant
- SMART Defense Scholarship Program, a US Department of Defense workforce development program
Transport[edit]
- Smart (marque), a car manufacturer co-owned by Mercedes-Benz and Geely
- SMART Tunnel, the Stormwater Management and Road Tunnel in Kuala Lumpur, Malaysia
- Scandinavian Multi Access Reservations for Travel Agents, a computerized system for ticket reservation
United States[edit]
- Sonoma–Marin Area Rail Transit, in the northern San Francisco Bay Area, California
- South Metro Area Regional Transit in Wilsonville, Oregon
- Starkville MSU Area Rapid Transit, a public transportation system in Starkville, Mississippi, and Mississippi State University
- Suburban Mobility Authority for Regional Transportation, the transit authority for suburban Detroit, Michigan
Other uses[edit]
- Smart (surname), a surname (including a list of people with the name)
- Smart Museum of Art, a museum in Chicago
- Simple Modular Architecture Research Tool, a biological database used in the identification and analysis of protein domains within protein sequences
- SMART (Malaysia), a disaster relief and rescue task force
- International Association of Sheet Metal, Air, Rail and Transportation Workers (SMART), a North American labor union
- Sikh Mediawatch and Resource Task Force, the former name of the Sikh American Legal Defense and Education Fund
- Start Making A Reader Today, an Oregon-based volunteer literacy program for at-risk PreK-3 readers
- Studies in Medieval and Renaissance Teaching, or SMART, a peer-reviewed journal
- SMArt 155, a German artillery shell that uses anti-armour submunitions
- Smart #1, an upcoming electric crossover SUV
- SMART criteria (specific, measurable, assignable, realistic, time-related), a mnemonic used to set goals or objectives and evaluate performance
- SMART Recovery (Self Management and Recovery Training), addiction recovery based on REBT principles
- SMART-1 (Small Missions for Advanced Research in Technology), a series of European Space Agency space missions
- SMART-R, the Shared Mobile Atmospheric Research and Teaching Radar
- Intelligence
See also[edit]
- Smartt (disambiguation)
- Snart (disambiguation)
- Smarts (disambiguation)
- All pages with titles beginning with smart
Новый HDD S.M.A.R.T. «Частота появления ошибок чтения»
Тема в разделе «Компьютеры», создана пользователем Токито, 15.05.21.
-
Всем добра. На новом винте эта характеристика сразу была не нулевой и растет при любом чтении, хотя читается и пишется все без ошибок. Кто может подсказать что происходит?
Вложения:
-
@Токито,
Атрибут: 01 Raw Read Error Rate.
Тип: текущий, может быть накапливающим для WD и старых Hitachi.
Описание: содержит частоту возникновения ошибок при чтении с пластин.
Для всех дисков Seagate, Samsung (начиная с семейства SpinPoint F1 (включительно)) и Fujitsu 2.5”, характерны огромные числа в этих полях.
Для остальных дисков Samsung и всех дисков WD характерен в этом поле 0.
Для дисков Hitachi в этом поле характерен 0 либо периодическое изменение поля в пределах от 0 до нескольких единиц.
Такие отличия обусловлены тем, что все жёсткие диски Seagate, некоторые Samsung и Fujitsu считают значения этих параметров не так, как WD, Hitachi и другие Samsung. При работе любого винчестера всегда возникают ошибки такого рода, и он преодолевает их самостоятельно, это нормально, просто на дисках, которые в этом поле содержат 0 или небольшое число, производитель не счёл нужным указывать истинное количество этих ошибок.
Таким образом, ненулевой параметр на дисках WD и Samsung до SpinPoint F1 (не включительно), и большой параметр на дисках Hitachi могут указывать на аппаратные проблемы с диском. Впрочем, могут и на софтовые: при наличие на диске бэд-блоков при обращении к ним могут происходить ошибки чтения, из-за которых и будет расти этот атрибут.
Необходимо учитывать, что утилиты могут отображать несколько значений, содержащихся в поле RAW этого атрибута, как одно, и оно будет выглядеть весьма большим, хоть это и будет неверно (подробности см. ниже).
На дисках Seagate, Samsung (SpinPoint F1 и новее) и Fujitsu на этот атрибут можно не обращать внимания.Объявления — Вопросы знатокам o S.M.A.R.T. — Конференция iXBT.com
Последнее редактирование: 15.05.21 -
Спасибо добрый человек, успокоили, это Seagate IronWolf 5900rpm 64MB Bulk
- Закрыть Меню
-
Волгоградский форум
- Поиск сообщений
- Последние сообщения
-
Пользователи
- Выдающиеся пользователи
- Зарегистрированные пользователи
- Сейчас на форуме
- Поиск
Система мониторинга в дисках компьютера
SMART (Технология самоконтроля, анализа и отчетности ; часто обозначается как SMART ) — система мониторинга, включенная в компьютер жесткие диски (HDD), твердотельные диски (SSD) и eMMC накопители. Его основная функция — обнаруживать и сообщать о различных показателях надежности привода с целью предвидеть неминуемые отказы оборудования.
Когда S.M.A.R.T. Данные указывают на возможный неизбежный сбой диска, программное обеспечение, работающее в хост-системе, может уведомить пользователя, чтобы можно было предпринять превентивные меры для предотвращения потери данных, а неисправный диск можно было заменить и сохранить целостность данных.
Содержание
- 1 Предпосылки
- 1.1 Точность
- 2 История и предшественники
- 3 Предоставленная информация
- 4 Стандарты и реализация
- 4.1 Отсутствие единой интерпретации
- 4.2 Доступность для хост-систем
- 5 Доступ
- 6 ATA SMART атрибуты
- 6.1 Известный ATA S.M.A.R.T. атрибуты
- 6.2 Превышение порога Условие
- 7 Самотестирование
- 8 См. также
- 9 Ссылки
- 10 Дополнительная литература
- 11 Внешние ссылки
Фон
Жесткий диск и другие накопители подвержены сбоям (см. отказ жесткого диска ), которые можно разделить на два основных класса:
- Прогнозируемые отказы, возникающие в результате медленных процессов, таких как механический износ и постепенная деградация поверхностей хранения. Мониторинг может определить, когда такие отказы становятся более вероятными.
- Непредсказуемые отказы, которые происходят без предупреждения из-за чего-либо, от выхода электронных компонентов до внезапного механического отказа, включая отказы, связанные с неправильным обращением.
Учет механических отказов около 60% всех отказов дисков. Хотя возможный отказ может быть катастрофическим, большинство механических отказов возникает в результате постепенного износа, и обычно есть определенные признаки того, что отказ неизбежен. Они могут включать повышенную тепловую мощность, повышенный уровень шума, проблемы с чтением и записью данных или увеличение количества поврежденных секторов диска.
Страница PCTechGuide на S.M.A.R.T. (2003) комментирует, что технология прошла три фазы:
В своем первоначальном воплощении S.M.A.R.T. обеспечивает прогнозирование сбоев путем отслеживания определенных действий жесткого диска в Интернете.
Последующая версия стандарта улучшила прогнозирование сбоев, добавив автоматическое автономное сканирование чтения для отслеживания дополнительных операций. онлайн-атрибуты всегда обновляются, а офлайн-атрибуты обновляются, когда жесткий диск не в рабочем состоянии. Если есть немедленная необходимость обновить автономные атрибуты, жесткий диск замедляется, и автономные атрибуты обновляются. Последний «S.M.A.R.T.» Технология не только отслеживает активность жесткого диска, но и добавляет средства предотвращения сбоев, пытаясь обнаружить и исправить ошибки секторов.
Кроме того, в то время как более ранние версии технологии отслеживали активность жесткого диска только на предмет данных, полученных операционной системой, последняя версия S.M.A.R.T. проверяет все данные и все сектора диска, используя «автономный сбор данных», чтобы подтвердить работоспособность диска в периоды бездействия.
Точность
Полевое исследование в Google, охватывающее более 100 000 дисков потребительского класса с декабря 2005 г. по август 2006 г. обнаружили корреляцию между некоторыми SMART информация и среднегодовая частота отказов:
- В течение 60 дней после первой неисправимой ошибки на диске (атрибут SMART 0xC6 или 198), обнаруженной в результате автономного сканирования, в среднем диск был Вероятность отказа в 39 раз выше, чем у аналогичного диска, для которого такой ошибки не было.
- Первые ошибки при перераспределении, автономном перераспределении (атрибуты SMART 0xC4 и 0x05 или 196 и 5) и пробных подсчетах (Атрибут SMART 0xC5 или 197) также сильно коррелировали с более высокой вероятностью отказа.
- И наоборот, была обнаружена небольшая корреляция для повышенной температуры и отсутствие корреляции для уровня использования. Однако исследование показало, что большая часть (56%) отказавших дисков вышла из строя без учета каких-либо подсчетов в «четырех сильных предупреждениях SMART», идентифицированных как ошибки сканирования, подсчет перераспределения, перераспределение в автономном режиме и пробный подсчет.
- Кроме того, 36% неисправных дисков сделали это без записи SMART. ошибка вообще, кроме температуры, а это означает, что S.M.A.R.T. одни только данные имели ограниченную полезность для прогнозирования сбоев.
История и предшественники
Ранняя технология мониторинга жесткого диска была представлена IBM в 1992 году в ее дисковых массивах для AS / 400 серверов с дисками IBM 0662 SCSI-2. Позже она была названа технологией Predictive Failure Analysis (PFA). Он измерял несколько ключевых параметров состояния устройства и оценивал их во встроенном ПО накопителя. Связь между физическим блоком и программным обеспечением для мониторинга была ограничена двоичным результатом: либо «устройство в порядке», либо «скорее всего, скоро произойдет сбой привода».
Позже другой вариант, названный IntelliSafe, был создан производителем компьютеров Compaq и производителями дисководов Seagate, Quantum и Коннер. Дисковые накопители будут измерять «параметры состояния» диска, и эти значения будут переданы в операционную систему и программное обеспечение для мониторинга пользовательского пространства. Каждый производитель дисковых накопителей мог свободно решать, какие параметры должны быть включены в мониторинг и каковы должны быть их пороговые значения. Унификация происходила на уровне протокола с хостом.
Compaq представила IntelliSafe комитету по малому форм-фактору (SFF) для стандартизации в начале 1995 года. Он поддерживался IBM, партнерами Compaq по разработке — Seagate, Quantum и Conner, а также Western Digital, в которой в то время не было системы прогнозирования отказов. Комитет выбрал подход IntelliSafe, поскольку он обеспечивает большую гибкость. Compaq разместила IntelliSafe в открытом доступе 12 мая 1995 года. Получившийся в результате совместно разработанный стандарт получил название SMART.
Этот стандарт SFF описывал протокол связи для хоста ATA для использования и управления мониторингом и анализом на жестком диске., но не указал каких-либо конкретных показателей или методов анализа. Позже «S.M.A.R.T.» стало пониматься (хотя и без какой-либо формальной спецификации) как относящееся к множеству конкретных показателей и методов и применимое к протоколам, не связанным с ATA, для передачи тех же вещей.
Предоставленная информация
Техническая документация для S.M.A.R.T. соответствует стандарту AT Attachment (ATA). Впервые представленный в 2004 году, он подвергался регулярным изменениям, последняя из которых — в 2011 году. Стандартизация аналогичных функций на SCSI более редка и не упоминается как таковая в стандартах, хотя поставщики и потребители в равной степени ссылаются на эти аналогичные функции на S.M.A.R.T. тоже.
Самая основная информация, которую S.M.A.R.T. обеспечивает S.M.A.R.T. положение дел. Он предоставляет только два значения: «порог не превышен» и «порог превышен». Часто они представлены как «диск в норме» или «сбой диска» соответственно. Значение «превышено пороговое значение» предназначено для обозначения того, что существует относительно высокая вероятность того, что диск не сможет соблюдать свои спецификации в будущем: то есть диск «вот-вот выйдет из строя». Прогнозируемый сбой может быть катастрофическим или может быть чем-то столь же незаметным, как невозможность записи в определенные секторы, или, возможно, более низкая производительность, чем заявленный производителем минимум.
S.M.A.R.T. Статус не обязательно указывает на надежность привода в прошлом или настоящем. Если диск уже катастрофически отказал, S.M.A.R.T. статус может быть недоступен. В качестве альтернативы, если накопитель испытывал проблемы в прошлом, но датчики больше не обнаруживают такие проблемы, S.M.A.R.T. Состояние может, в зависимости от программирования производителя, указывать на исправность накопителя.
Невозможность чтения некоторых секторов не всегда указывает на то, что диск вот-вот выйдет из строя. Один из способов создания нечитаемых секторов, даже если диск работает в соответствии со спецификацией, — это внезапный сбой питания во время записи. Кроме того, даже если физический диск поврежден в одном месте, так что определенный сектор не читается, диск может использовать свободное пространство для замены поврежденной области, чтобы этот сектор мог быть перезаписан.
Более подробную информацию о состоянии накопителя можно получить, изучив SMART. Атрибуты. УМНАЯ. Атрибуты были включены в некоторые проекты стандарта ATA, но были удалены до того, как стандарт стал окончательным. Значение и интерпретация атрибутов различаются у разных производителей и иногда считаются коммерческой тайной того или иного производителя. Атрибуты подробнее рассматриваются ниже.
Диски с S.M.A.R.T. может по желанию вести несколько «журналов». В журнал ошибок записывается информация о самых последних ошибках, о которых накопитель сообщил главному компьютеру. Изучение этого журнала может помочь определить, связаны ли проблемы с компьютером с диском или вызваны чем-то другим (временные метки журнала ошибок могут «зацикливаться» через 2 мс = 49,71 дня)
Диск, который реализует SMART может дополнительно реализовать ряд процедур самотестирования или обслуживания, а результаты тестов сохраняются в журнале самотестирования. Процедуры самотестирования могут использоваться для обнаружения любых нечитаемых секторов на диске, чтобы их можно было восстановить из резервных источников (например, с других дисков в RAID ). Это помогает снизить риск безвозвратной потери данных.
Стандарты и реализация
Отсутствие общепринятой интерпретации
Многие материнские платы отображают предупреждающее сообщение, когда диск приближается к отказу. Хотя отраслевой стандарт существует среди большинства основных производителей жестких дисков, проблемы остаются из-за атрибутов, намеренно оставленных недокументированными для общественности, чтобы различать модели между производителями. С юридической точки зрения термин «S.M.A.R.T.» относится только к методу передачи сигналов между электромеханическими датчиками внутреннего диска и главным компьютером. Из-за этого спецификации S.M.A.R.T. полностью зависят от поставщика, и, хотя многие из этих атрибутов были стандартизированы поставщиками накопителей, другие по-прежнему зависят от поставщика. УМНАЯ. реализации по-прежнему различаются и в некоторых случаях могут не иметь «общих» или ожидаемых функций, таких как датчик температуры, или включать только несколько избранных атрибутов, при этом позволяя производителю рекламировать продукт как «совместимый с SMART».
Доступность для хост-системы
В зависимости от типа используемого интерфейса некоторые материнские платы с поддержкой SMART и соответствующее программное обеспечение могут не взаимодействовать с определенными накопителями с поддержкой SMART. Например, несколько внешних накопителей, подключенных через USB и FireWire, правильно отправляют S.M.A.R.T. данные по этим интерфейсам. С таким большим количеством способов подключения жесткого диска (SCSI, Fibre Channel, ATA, SATA, SAS, SSA и т. Д.), Трудно предсказать, будет ли SMART отчеты будут правильно работать в данной системе.
Даже с жестким диском и интерфейсом, реализующим спецификацию, операционная система компьютера может не распознавать S.M.A.R.T. информация, потому что диск и интерфейс инкапсулированы на нижнем уровне. Например, они могут быть частью подсистемы RAID, в которой контроллер RAID видит диск с поддержкой S.M.A.R.T., но главный компьютер видит только логический том, созданный контроллером RAID.
На платформе Windows множество программ, предназначенных для мониторинга и создания отчетов о S.M.A.R.T. информация будет работать только под учетной записью администратора .
Доступ
Для списка различных программ, которые позволяют читать S.M.A.R.T. Данные см. Сравнение S.M.A.R.T. инструменты.
ATA S.M.A.R.T. атрибуты
Каждый производитель накопителя определяет набор атрибутов и устанавливает пороговые значения, за которыми атрибуты не должны проходить при нормальной работе. Каждый атрибут имеет необработанное значение, которое может быть десятичным или шестнадцатеричным, значение которого полностью зависит от производителя привода (но часто соответствует количеству или физической единице, такой как градусы Цельсия или секунды), нормализованное значение, которое варьируется от 1 до 253 (где 1 представляет наихудший случай, а 253 — лучший) и наихудшее значение, которое представляет наименьшее записанное нормализованное значение. Начальное значение атрибутов по умолчанию — 100, но может варьироваться в зависимости от производителя.
Производители, которые внедрили хотя бы один S.M.A.R.T. атрибут в различных продуктах, включая Samsung, Seagate, IBM (Hitachi ), Fujitsu, Maxtor, Toshiba, Intel, sTec, Inc., Western Digital и ExcelStor Technology.
Известный ATA УМНАЯ атрибуты
В следующей таблице перечислены некоторые S.M.A.R.T. атрибуты и типичное значение их сырых значений. Нормализованные значения обычно отображаются таким образом, что более высокие значения лучше (исключения включают температуру привода, количество циклов загрузки / разгрузки головки), но более высокие необработанные значения атрибутов могут быть лучше или хуже в зависимости от атрибута и производителя. Например, нормализованное значение атрибута «Счетчик перераспределенных секторов» уменьшается по мере увеличения количества перераспределенных секторов. В этом случае необработанное значение атрибута часто указывает фактическое количество секторов, которые были перераспределены, хотя от поставщиков никоим образом не требуется соблюдать это соглашение.
Поскольку производители не обязательно согласовывают точные определения атрибутов и единицы измерения, следующий список атрибутов является только общим руководством.
Накопители не поддерживают все коды атрибутов (иногда в таблицах сокращенно обозначаются как «ID» для «идентификатора»). Некоторые коды относятся к конкретным типам накопителей (магнитный диск, флэш-память, SSD). Приводы могут использовать разные коды для одного и того же параметра, например, см. Коды 193 и 225.
| ID | 193. 0xC1 | Код атрибута в десятичном формате и. шестнадцатеричное представление |
|---|---|---|
| Идеально | Чем выше исходное значение, тем лучше | |
| Низкое |
Чем меньше исходное значение, тем лучше | |
| !. (Критическое) | Обозначает критический атрибут.. Конкретные значения может предсказать отказ диска |
| ID | Имя атрибута | Идеально | ! | Описание |
|---|---|---|---|---|
| 01. 0x01 | Частота ошибок чтения | Низкая |
(исходное значение, зависящее от производителя). Сохраняет данные, относящиеся к скорости аппаратных ошибок чтения, возникших при чтении данных с поверхности диска. Необработанное значение имеет разную структуру для разных поставщиков и часто не имеет смысла в виде десятичного числа. | |
| 02. 0x02 | Пропускная способность | Общая (общая) пропускная способность жесткого диска. Если значение этого атрибута уменьшается, велика вероятность того, что проблема с диском. | ||
| 03. 0x03 | Время раскрутки | Низкое |
Среднее время раскрутки шпинделя (от нулевого об / мин до полного рабочего состояния [миллисекунды]). | |
| 04. 0x04 | Счетчик пуска / останова | Счетчик циклов пуска / останова шпинделя. Шпиндель включается, и, следовательно, счет увеличивается как при включении жесткого диска после того, как он был полностью выключен (отсоединен от источника питания), так и при возврате жесткого диска из состояния, ранее переведенного в спящий режим. | ||
| 05. 0x05 | Счетчик перераспределенных секторов | Младший |
. |
Счетчик перераспределенных секторов. Необработанное значение представляет собой количество сбойных секторов, которые были обнаружены и переназначены. Таким образом, чем выше значение атрибута, тем больше секторов пришлось перераспределить накопителю. Это значение в основном используется как показатель ожидаемого срока службы накопителя; привод, который вообще перераспределял, значительно чаще выходит из строя в ближайшие месяцы. |
| 06. 0x06 | Read Channel Margin | Запас канала при чтении данных. Функция этого атрибута не указана. | ||
| 07. 0x07 | Частота ошибок поиска | Варьируется | (необработанное значение, зависящее от производителя). Частота ошибок поиска магнитных головок. При частичном выходе из строя механической системы позиционирования возникнут ошибки поиска. Такой сбой может быть вызван множеством факторов, таких как повреждение сервопривода или тепловое расширение жесткого диска. Необработанное значение имеет разную структуру для разных поставщиков и часто не имеет смысла в виде десятичного числа. | |
| 08. 0x08 | Время поиска | Средняя производительность операций поиска магнитных головок. Если этот атрибут уменьшается, это признак проблем в механической подсистеме. | ||
| 09. 0x09 | Power-On Hours | Счетчик часов в состоянии включения. Необработанное значение этого атрибута показывает общее количество часов (или минут, или секунд, в зависимости от производителя) в состоянии включения.
«По умолчанию общий ожидаемый срок службы жесткого диска в идеальном состоянии определяется как 5 лет (работает каждый день и каждую ночь во все дни). Это равно 1825 дням в режиме 24/7 или 43800 часам «. На некоторых накопителях до 2005 года это исходное значение может увеличиваться неравномерно и / или «циклический переход» (периодически сбрасывается в ноль). |
||
| 10. 0x0A | Счетчик повторных попыток вращения | Низкий |
. |
Счетчик повторных попыток запуска вращения. В этом атрибуте хранится общее количество попыток запуска вращения для достижения полной рабочей скорости (при условии, что первая попытка была неудачной). Повышение значения этого атрибута свидетельствует о проблемах в механической подсистеме жесткого диска. |
| 11. 0x0B | Повторные попытки калибровки или Счетчик повторных попыток калибровки | Низкий |
Этот атрибут указывает счетчик, по которому была запрошена повторная калибровка (при условии, что первая попытка была неудачной). Повышение значения этого атрибута свидетельствует о проблемах в механической подсистеме жесткого диска. | |
| 12. 0x0C | Счетчик циклов питания | Этот атрибут указывает количество циклов полного включения / выключения жесткого диска. | ||
| 13. 0x0D | Частота ошибок мягкого чтения | Низкая |
Неисправленные ошибки чтения сообщаются операционной системе. | |
| 22. 0x16 | Текущий уровень гелия | Специфично для приводов He8 от HGST. Это значение измеряет содержание гелия внутри накопителя данного производителя. Это атрибут перед отказом, который срабатывает, когда привод обнаруживает, что внутренняя среда не соответствует спецификации. | ||
| 170. 0xAA | Доступное зарезервированное пространство | См. Атрибут E8. | ||
| 171. 0xAB | Счетчик сбоев программы SSD | (Kingston) Общее количество сбоев при выполнении программы флэш-памяти с момента развертывания диска. Идентичен атрибуту 181. | ||
| 172. 0xAC | Счетчик сбоев при стирании SSD | (Kingston) Подсчитывает количество сбоев при стирании флэш-памяти. Этот атрибут возвращает общее количество сбоев операции стирания флэш-памяти с момента развертывания диска. Этот атрибут идентичен атрибуту 182. | ||
| 173. 0xAD | Счетчик выравнивания износа SSD | Подсчитывает максимальное наихудшее количество стирания для любого блока. | ||
| 174. 0xAE | Счетчик непредвиденных потерь питания | Также известен как «Счетчик отвода при отключении питания» в традиционной терминологии жестких дисков. Необработанное значение сообщает о количестве нечистых отключений, кумулятивном за весь срок службы SSD, где «нечистое отключение» — это отключение питания без STANDBY IMMEDIATE в качестве последней команды (независимо от активности PLI с использованием мощности конденсатора). Нормализованное значение всегда равно 100. | ||
| 175. 0xAF | Сбой защиты от потери питания | Результат последнего теста в микросекундах до разрядки крышки, насыщенный при максимальном значении. Также регистрируются минуты с момента последнего теста и количество тестов за весь срок службы. Необработанное значение содержит следующие данные:
Нормализованное значение устанавливается на единицу при неудачном завершении теста или на 11, если конденсатор был испытан в условиях чрезмерной температуры, в противном случае — на 100. |
||
| 176. 0xB0 | Erase Fail Count | УМНАЯ параметр указывает количество ошибок команды стирания флэш-памяти. | ||
| 177. 0xB1 | Дельта диапазона износа | Дельта между наиболее изношенными и наименее изношенными блоками флэш-памяти. Он описывает, насколько хорошо / плохо работает выравнивание износа SSD с более технической точки зрения. | ||
| 179. 0xB3 | Общее количество зарезервированных блоков | Атрибут «до отказа», используемый, по крайней мере, в устройствах Samsung. | ||
| 180. 0xB4 | Общее количество неиспользованных зарезервированных блоков | Атрибут «до отказа», используемый по крайней мере в устройствах HP. | ||
| 181. 0xB5 | Общее количество сбоев программы или Счетчик доступа без согласования 4K | Низкое |
Общее количество сбоев при выполнении программы Flash с момента развертывания диска.. Количество обращений к пользовательским данным (как чтение, так и запись), когда LBA не выровнены на 4 КиБ (LBA% 8! = 0) или где размер не равен модулю 4 КиБ (количество блоков! = 8), предполагая размер логического блока (LBS) = 512 Б. | |
| 182. 0xB6 | Счетчик сбоев стирания | Атрибут «до сбоя», используемый по крайней мере в устройствах Samsung. | ||
| 183. 0xB7 | Счетчик ошибок понижения передачи SATA или Плохой блок времени выполнения | Низкий |
Атрибут Western Digital, Samsung или Seagate: либо количество понижений скорости соединения (например, от 6 Гбит / с до 3 Гбит / с) или общее количество блоков данных с обнаруженными неисправимыми ошибками, обнаруженными во время нормальной работы. Хотя ухудшение этого параметра может быть индикатором старения привода и / или потенциальных электромеханических проблем, оно не указывает напрямую на неизбежный отказ привода. | |
| 184. 0xB8 | Сквозная ошибка / IOEDC | Низкий |
. |
Этот атрибут является частью технологии SMART IV Hewlett-Packard, а также частью схем обнаружения и исправления ошибок ввода-вывода других поставщиков и содержит количество возникающих ошибок четности. в пути данных к носителю через кэш-память диска. |
| 185. 0xB9 | Head Stability | атрибут Western Digital. | ||
| 186. 0xBA | Обнаружение индуцированной операционной вибрации | Атрибут Western Digital. | ||
| 187. 0xBB | Зарегистрированные неисправимые ошибки | Низкий |
. |
Количество ошибок, которые не удалось исправить с помощью аппаратного ECC (см. Атрибут 195). |
| 188. 0xBC | Command Timeout | Low |
. |
Количество прерванных операций из-за тайм-аута жесткого диска. Обычно значение этого атрибута должно быть равно нулю. |
| 189. 0xBD | High Fly Writes | Low |
Производители жестких дисков реализуют датчик высоты полета, который пытается обеспечить дополнительную защиту для операций записи путем определения, когда записывающая головка выходит за пределы своего нормального рабочего диапазона. Если встречается небезопасное условие высоты полета, процесс записи останавливается, и информация перезаписывается или перераспределяется в безопасную область жесткого диска. Этот атрибут указывает количество этих ошибок, обнаруженных за время жизни накопителя.
Эта функция реализована в большинстве современных накопителей Seagate и некоторых накопителях Western Digital, начиная с жестких дисков WD Enterprise WDE18300 и WDE9180 Ultra2 SCSI, и будет включена во все будущие продукты WD Enterprise. |
|
| 190. 0xBE | Разница температур или Температура воздушного потока | Варьируется | Значение равно (100-темп. ° C), что позволяет производителю установить минимальный порог, который соответствует максимальной температуре. Это также следует соглашению о том, что 100 является наилучшим значением, а более низкие значения нежелательны. Однако некоторые старые диски могут вместо этого сообщать необработанную температуру (идентичную 0xC2) или температуру минус 50 здесь. | |
| 191. 0xBF | Коэффициент ошибок G-sense | Низкий |
Количество ошибок, возникших в результате внешних ударов и вибрации. | |
| 192. 0xC0 | Счетчик отвода при отключении питания, Счетчик циклов аварийного отвода (Fujitsu) или Счетчик небезопасного отключения | Низкий |
Количество циклы отключения питания или аварийного втягивания. | |
| 193. 0xC1 | Счетчик циклов нагрузки или Счетчик циклов нагрузки / разгрузки (Fujitsu) | Низкий |
Счетчик нагрузки / разгрузить циклы в положение зоны посадки головы. Некоторые диски вместо этого используют 225 (0xE1) для счетчика циклов загрузки.
Western Digital оценивает свои диски VelociRaptor на 600 000 циклов загрузки / выгрузки и диски WD Green на 300 000 циклов; последние предназначены для частой разгрузки голов в целях экономии энергии. С другой стороны, WD3000GLFS (накопитель для настольных ПК) рассчитан только на 50 000 циклов загрузки / выгрузки. Некоторые накопители для портативных компьютеров и жесткие диски для настольных ПК запрограммированы на выгрузку головок, когда их не было. активность в течение короткого периода для экономии энергии. Операционные системы часто обращаются к файловой системе несколько раз в минуту в фоновом режиме, вызывая 100 или более циклов загрузки в час, если головки выгружаются: номинальный цикл загрузки может быть превышен менее чем за год. Существуют программы для большинства операционных систем, которые отключают функции Advanced Power Management (APM) и Автоматическое управление звуком (AAM), вызывающие частые циклы загрузки. |
|
| 194. 0xC2 | Температура или Температура Цельсия | Низкая |
Указывает температуру устройства, если установлен соответствующий датчик. Самый младший байт необработанного значения содержит точное значение температуры (градусы Цельсия). | |
| 195. 0xC3 | Аппаратный ECC восстановлен | Различный | (исходное значение, зависящее от производителя). Необработанное значение имеет другое структура для разных поставщиков и часто не имеет смысла как десятичное число. | |
| 196. 0xC4 | Счетчик событий перераспределения | Низкий |
. |
Счетчик операций перераспределения. Необработанное значение этого атрибута показывает общее количество попыток передачи данных из перераспределенных секторов в резервную область. Подсчитываются как успешные, так и неудачные попытки. |
| 197. 0xC5 | Текущее количество ожидающих секторов | Низкое |
. |
Количество «нестабильных» секторов (ожидающих переназначения из-за неисправимых ошибок чтения). Если впоследствии будет успешно прочитан нестабильный сектор, сектор будет повторно отображен, и это значение будет уменьшено. Ошибки чтения в секторе не будут повторно отображать сектор немедленно (поскольку правильное значение не может быть прочитано и поэтому значение для переназначения неизвестно, а также оно может стать доступным для чтения позже); вместо этого микропрограмма накопителя запоминает, что сектор необходимо переназначить, и будет переназначать его в следующий раз при записи.
Однако некоторые накопители не будут немедленно переназначать такие сектора при записи; вместо этого диск сначала попытается записать в проблемный сектор, и если операция записи прошла успешно, сектор будет помечен как хороший (в этом случае «Счетчик событий перераспределения» (0xC4) не будет увеличиваться). Это серьезный недостаток, поскольку, если такой диск содержит маргинальные секторы, которые постоянно выходят из строя только по прошествии некоторого времени после успешной операции записи, диск никогда не будет повторно отображать эти проблемные сектора. |
| 198. 0xC6 | (Offline) Счетчик неисправимых секторов | Низкий |
. |
Общее количество неисправимых ошибок при чтении / записи сектора. Повышение значения этого атрибута указывает на дефекты поверхности диска и / или проблемы в механической подсистеме. |
| 199. 0xC7 | Счетчик ошибок CRC UltraDMA | Низкий |
Количество ошибок в передача данных через интерфейсный кабель, как это определено МККК (проверка циклическим резервированием интерфейса). | |
| 200. 0xC8 | Частота ошибок в нескольких зонах | Низкая |
Количество ошибок, обнаруженных при записи сектора. Чем выше значение, тем хуже механическое состояние диска. | |
| 200. 0xC8 | Уровень ошибок записи (Fujitsu) | Низкий |
Общее количество ошибок при записи сектора. | |
| 201. 0xC9 | Мягкое чтение Частота ошибок or. Обнаружен счетчик TA | Низкий |
. |
Счетчик указывает количество неисправимых программных ошибок чтения. |
| 202. 0xCA | Ошибки метки адреса данных or. Увеличенный счетчик TA | Низкий |
Количество ошибок метки адреса данных (или зависит от производителя). | |
| 203. 0xCB | Отмена выхода из строя | Низкий |
Количество ошибок, вызванных неправильной контрольной суммой во время исправления ошибок. | |
| 204. 0xCC | Мягкая коррекция ECC | Низкий |
Количество ошибок, исправленных с помощью внутреннего программного обеспечения для исправления ошибок. | |
| 205. 0xCD | Коэффициент термической неровности | Низкий |
Количество ошибок из-за высокой температуры. | |
| 206. 0xCE | Высота полета | Высота головок над поверхностью диска. Если слишком низко, более вероятно падение головы; если слишком высокий, вероятнее всего будут ошибки чтения / записи. | ||
| 207. 0xCF | Spin High Current | Low |
Величина импульсного тока, используемого для раскрутки привода. | |
| 208. 0xD0 | Spin Buzz | Количество подпрограмм, необходимых для раскрутки диска из-за недостаточной мощности. | ||
| 209. 0xD1 | Offline Seek Performance | Поиск диска производительность во время внутренних тестов. | ||
| 210. 0xD2 | Вибрация во время записи | Обнаружено в Maxtor 6B200M0 200GB и Maxtor 2R015H1 15GB. | ||
| 211. 0xD3 | Вибрация во время записи | Запись вибрации, возникшей во время операций записи. | ||
| 212. 0xD4 | Удар во время записи | Запись сотрясения, возникшего во время операции записи. | ||
| 220. 0xDC | Disk Shift | Low |
Расстояние, на которое диск сместился относительно шпинделя (обычно из-за удара или температуры). Единица измерения неизвестна. | |
| 221. 0xDD | Коэффициент ошибок G-Sense | Низкий |
Количество ошибок, вызванных внешними ударами и вибрацией. | |
| 222. 0xDE | Часы под нагрузкой | Время, затрачиваемое на работу при загрузке данных (движение якоря магнитной головки). | ||
| 223. 0xDF | Счетчик повторных попыток загрузки / выгрузки | Счетчик | ||
| 224. 0xE0 | Трение нагрузки | Низкое |
Сопротивление, вызванное трением в механических частях во время работы. | |
| 225. 0xE1 | Нагрузка / Разгрузка Счетчик циклов | Младший |
Общее количество циклов нагрузки Некоторые приводы вместо этого используют 193 (0xC1) для счетчика циклов нагрузки. См. Описание 193, чтобы узнать о значении этого числа. | |
| 226. 0xE2 | Load ‘In’-time | Общее время нагрузки на привод магнитных головок (время, не находящееся в зоне парковки). | ||
| 227. 0xE3 | Крутящий момент Amplification Count | Low |
Количество попыток компенсации колебаний скорости диска. | |
| 228. 0xE4 | Power-Off Retract Cycle | Low |
Количество циклов выключения, которые подсчитываются всякий раз, когда происходит «событие втягивания» и головки загружаются с носителя, например, когда машина выключена, переведена в спящий режим или простаивает. | |
| 230. 0xE6 | GMR Head Amplitude (магнитные жесткие диски), Статус защиты срока службы диска (твердотельные накопители) | Амплитуда «перебоев» (повторяющиеся движения головки между операциями).
В твердотельных накопителях указывает, используется ли траектория опережает ожидаемую кривую срока службы |
||
| 231. 0xE7 | Оставшийся срок службы (твердотельные накопители) или Температура | Указывает приблизительный оставшийся срок службы твердотельного накопителя с точки зрения циклов программирования / стирания или доступных зарезервированные блоки. Нормализованное значение 100 соответствует новому диску, а пороговое значение 10 указывает на необходимость замены. Значение 0 может означать, что диск работает в режиме только для чтения, что позволяет восстановить данные.
Ранее (до 2010 г.) иногда использовалось для температуры диска (чаще сообщалось как 0xC2). |
||
| 232. 0xE8 | Оставшийся ресурс или Доступное зарезервированное пространство | Количество циклов физического стирания, выполненных на SSD, в процентах от максимального количества циклов физического стирания, на которое рассчитан накопитель..
SSD-накопители Intel сообщают о доступном зарезервированном пространстве как процент от начального зарезервированного пространства. |
||
| 233. 0xE9 | Индикатор износа носителя (SSD) или Время включения | SSD-накопители Intel сообщают нормализованное значение от 100 (новый диск) до минимум 1. Он уменьшается, когда количество циклов стирания NAND увеличивается от 0 до максимального номинального значения.
Ранее (до 2010 г.) время от времени использовалось для определения часов работы (чаще указывается в 0x09). |
||
| 234. 0xEA | Среднее количество стирания И Максимальное количество стирания | Расшифровывается как: байт 0-1-2 = средний счетчик стирания (прямой порядок байтов) и байт 3-4-5 = максимальное количество стирания ( с обратным порядком байтов). | ||
| 235. 0xEB | Счетчик правильных блоков И системный (свободный) счетчик блоков | Декодируется как: байт 0-1-2 = количество правильных блоков (прямой порядок байтов) и байты 3-4 = количество системных (свободных) блоков. | ||
| 240. 0xF0 | Наработка головок или «Частота ошибок передачи» (Fujitsu) | Время, затраченное на позиционирование головок дисковода. Некоторые приводы Fujitsu сообщают количество сбросов каналов во время передачи данных. | ||
| 241. 0xF1 | Всего записано LBA | Общее количество записанных LBA. | ||
| 242. 0xF2 | Общее количество прочитанных LBA | Общее количество прочитанных LBA.. Некоторые S.M.A.R.T. утилиты сообщат отрицательное число для необработанного значения, поскольку на самом деле оно имеет 48 бит, а не 32. | ||
| 243. 0xF3 | Общее количество записанных расширенных LBA | Старшие 5 байтов 12-байтового общего числа LBA, записанных на устройство. Младшее 7-байтовое значение расположено в атрибуте 0xF1. | ||
| 244. 0xF4 | Всего расширенных LBA, прочитанных | Старшие 5 байтов из 12-байтового общего числа LBA, прочитанных с устройства. Младшее 7-байтовое значение находится в атрибуте 0xF2. | ||
| 249. 0xF9 | Записей в NAND (1 ГБ) | Всего записей в NAND. Необработанное значение сообщает о количестве операций записи в NAND с шагом 1 ГБ. | ||
| 250. 0xFA | Частота повторения ошибки чтения | Низкая |
Количество ошибок при чтении с диска. | |
| 251. 0xFB | Minimum Spares Remaining | Атрибут Minimum Spares Remaining указывает количество оставшихся запасных блоков в процентах от общего количества доступных запасных блоков. | ||
| 252. 0xFC | Newly Added Bad Флэш-блок | Атрибут Newly Added Bad Flash Block указывает общее количество плохих флеш-блоков, обнаруженных накопителем с момента его первой инициализации при производстве. | ||
| 254. 0xFE | Защита от свободного падения | Низкий |
Количество обнаруженных «событий свободного падения». |
Условие превышения порога
Условие превышения порога (TEC) — это расчетная дата, когда критический атрибут статистики привода достигнет своего порогового значения. Когда программное обеспечение Drive Health сообщает «Ближайший T.E.C.», это следует рассматривать как «дату отказа». Иногда дата не указывается, и можно ожидать, что диск будет работать без ошибок.
Чтобы предсказать дату, диск отслеживает скорость, с которой изменяется атрибут. Обратите внимание, что даты TEC являются приблизительными; жесткие диски могут выйти из строя намного раньше или намного позже, чем дата TEC.
Самотестирование
S.M.A.R.T. накопители могут предлагать ряд самопроверок:
- Короткое
- Проверяет электрические и механические характеристики, а также скорость чтения с диска. Электрические испытания могут включать в себя проверку буферной RAM, проверку схемы чтения / записи или проверку элементов головки чтения / записи. Механический тест включает поиск и сервопривод на дорожках данных. Сканирует небольшие части поверхности диска (область зависит от производителя, и время проведения теста ограничено). Проверяет список ожидающих секторов, которые могут иметь ошибки чтения, и обычно это занимает менее двух минут.
- Длинный / расширенный
- Более длинная и более полная версия короткой самопроверки, сканирование всей поверхности диска без ограничения по времени. Этот тест обычно занимает несколько часов, в зависимости от скорости чтения / записи накопителя и его размера.
- Транспортировка
- Предназначен как быстрый тест для выявления повреждений, полученных во время транспортировки устройства от производителя накопителя в производитель компьютера. Доступно только на дисках ATA, и обычно Это занимает несколько минут.
- Выборочный
- Некоторые диски позволяют выборочное самотестирование только части поверхности.
Журналы самотестирования для дисков SCSI и ATA немного отличаются. Длинный тест может пройти, даже если короткий тест не пройден.
Журнал самопроверки накопителя может содержать до 21 записи, доступной только для чтения. При заполнении журнала старые записи удаляются.
См. Также
- Сравнение S.M.A.R.T. инструменты
- Очистка данных
- Дисковая утилита
- Список программного обеспечения для разбиения диска
- Прогнозный анализ сбоев
- Системный монитор
- Оптический диск § Сканирование поверхностных ошибок
Ссылки
Дополнительно чтение
- Стивенс, Кертис Э., изд. (22 июня 2011 г.), «Набор команд ATA / ATAPI — 2 (ACS-2)» (PDF), Набор команд ATA 2 (рабочий проект) (7-е изд.), ANSI INCITS, стр. 73.
- «Значение атрибута S.M.A.R.T.». siguardian.com. Архивировано из оригинала 26 февраля 2011 г. Получено 3 февраля 2006 г.
- Хлондовски, Збигнев. «Сайт S.M.A.R.T.: справочная таблица атрибутов». УМНАЯ. Linux. Получено 17 января 2007 г.
- «Атрибуты S.M.A.R.T. означают». Ариолик. 2007. Проверено 26 октября 2007 г.
- «Можем ли мы верить SMART?». H.D.S. Венгрия. 2007. Проверено 4 июня 2008 г.
- Аллен, Брюс (2004). «Мониторинг жестких дисков с помощью SMART». Linux Journal. Проверено 8 августа 2010 г.
Внешние ссылки
- Калифорнийский университет в Санта-Круз и Quantum release S.M.A.R.T. программное обеспечение для Linux, Майкл Корнуэлл.
- UCSC SMART suite, SourceForge от: Cornwell.
- Чем smartmontools отличается от smartsuite?, SourceForge.
- СМАРТ Инструменты мониторинга, SourceForge от: ballen4705.
- smartmontools smartsuite, smartmontools.org.
- GSmartControl — это GUI для smartctl (часть smartmontools) от Александр Шадури
- Как SMART ваш жесткий диск?, UK : pc-king.co.uk.
- Как предсказать сбой жесткого диска (отчет SMART), 2010-05-19 с помощью Palimpsest (первоначально Red Hat)
- KB251: Общие сведения о SMART и S.M.A.R.T. отказы и ошибки, Western Digital.
- Каким образом S.M.A.R.T. функция жестких дисков Work?.
- Hard Drive SMART Stats, крупномасштабный полевой отчет
- Seagate SMART Attribute Specification
- Normal SATA SMART Attribute Behavior (Seagate)
- Большая коллекция S.M.A.R.T. сообщает
25.08.2012, 03:11. Показов 584454. Ответов 2

В первую очередь хочу сказать спасибо Charles Kludge и nonym4uk за помощь в написании этой статьи.
Итак, S.M.A.R.T. (от англ. self-monitoring, analysis and reporting technology — технология самоконтроля, анализа и отчётности) — технология оценки состояния жёсткого диска встроенной аппаратурой самодиагностики, а также механизм предсказания времени выхода его из строя.
Много пользователей знает что такое S.M.A.R.T., немного меньше даже знают как его получить… Но когда встает вопрос проанализировать полученную таблицу, обычно дело стопорится. В этой статье я приведу основные значения и их расшифровку
Для любознательных
SMART производит наблюдение за основными характеристиками накопителя, каждая из которых получает оценку. Характеристики можно разбить на две группы:
параметры, отражающие процесс естественного старения жёсткого диска (число оборотов шпинделя, число премещений головок, количество циклов включения-выключения);
текущие параметры накопителя (высота головок над поверхностью диска, число переназначенных секторов, время поиска дорожки и количество ошибок поиска).
Данные хранятся в шестнадцатеричном виде, называемом «raw value», а потом пересчитываются в «value» — значение, символизирующее надёжность относительно некоторого эталонного значения. Обычно «value» располагается в диапазоне от 0 до 100 (некоторые атрибуты имеют значения от 0 до 200 и от 0 до 253).
Высокая оценка говорит об отсутствии изменений данного параметра или медленном его ухудшении. Низкая говорит о возможном скором сбое.
Значение, меньшее, чем минимальное, при котором производителем гарантируется безотказная работа накопителя, означает выход узла из строя.
Технология SMART позволяет осуществлять:
мониторинг параметров состояния;
сканирование поверхности;
сканирование поверхности с автоматической заменой сомнительных секторов на надёжные.
Следует заметить, что технология SMART позволяет предсказывать выход устройства из строя в результате механических неисправностей, что составляет около 60 % причин, по которым винчестеры выходят из строя.
Предсказать последствия скачка напряжения или повреждения накопителя в результате удара SMART не способна.
Следует отметить, что накопители НЕ МОГУТ сами сообщать о своём состоянии посредством технологии SMART, для этого существуют специальные программы.
Любая программа, показывающая S.M.A.R.T. для каждого атрибута имеет несколько значений, разберемся сначала с ними — ID, Value, Worst, Threshold и RAW. Итак:
ID (Number) — собственно, сам индикатор атрибута. Номера стандартны для значений атрибутов, но например,из-за кривизны перевода один и тот же атрибут может называться по-разному, проще орентироваться по ID, логично?
Value
(Current) — текущее значение атрибута в условных единицах, никому наверное неведомых . В процессе работы винчестера оно может уменьшаться, увеличиваться и оставаться неизменным. По показателю Value нельзя судить о «здоровье» атрибута, не сравнивая его со значением Threshold этого же атрибута. Как правило, чем меньше Value, тем хуже состояние атрибута (изначально все классы значений, кроме RAW, на новом диске имеют максимальное из возможных значение, например 100).
Worst — наихудшее значение, которого достигало значение Value за всю жизнь винчестера. Измеряется тоже в уе. В процессе работы оно может уменьшаться либо оставаться неизменным. По нему тоже нельзя однозначно судить о здоровье атрибута, нужно сравнивать его с Threshold.
Threshold — значение в (сюрприз!!!) уе, которого должен достигнуть Value этого же атрибута, чтобы состояние атрибута было признано критическим. Проще говоря, Threshold — это порог: если Value больше Threshold — атрибут в порядке; если меньше либо равен — с атрибутом проблемы. Именно по такому критерию утилиты, читающие S.M.A.R.T., выдают отчёт о состоянии диска либо отдельного атрибута вроде «Good» или «Bad». При этом они не учитывают, что даже при Value, большем Threshold, диск на самом деле уже может быть умирающим с точки зрения пользователя, а то и вовсе ходячим мертвецом, поэтому при оценке здоровья диска смотреть стоит всё-таки на другой класс атрибута, а именно — RAW. Однако именно значение Value, опустившееся ниже Threshold, может стать легитимным поводом для замены диска по гарантии (для самих гарантийщиков, конечно же) — кто же яснее скажет о здоровье диска, как не он сам, демонстрируя текущее значение атрибута хуже критического порога? Т. е. при значении Value, большем Threshold, сам диск считает, что атрибут здоров, а при меньшем либо равном — что болен. Очевидно, что при Threshold=0 состояние атрибута не будет признано критическим никогда. Threshold — постоянный параметр, зашитый производителем в диске.
RAW (Data) — самый интересный, важный и нужный для оценки показатель. В большинстве случаев он содержит в себе не уе, а реальные значения, выражаемые в различных единицах измерения, напрямую говорящие о текущем состоянии диска. Основываясь именно на этом показателе, формируется значение Value (а вот по какому алгоритму оно формируется — это уже тайна производителя, покрытая мраком). Именно умение читать и анализировать поле RAW даёт возможность объективно оценить состояние винчестера.
Теперь перейдем непосредственно к самим атрибутам.
01 (01) Raw Read Error Rate — Частота ошибок при чтении данных с диска, происхождение которых обусловлено аппаратной частью диска. Для всех дисков Seagate, Samsung (семейства F1 и более новые) и Fujitsu 2,5″ это — число внутренних коррекций данных, проведенных до выдачи в интерфейс, следовательно, на пугающе огромные цифры можно реагировать спокойно.
02 (02) Throughput Performance — Общая производительность диска. Если значение атрибута уменьшается, то велика вероятность, что с диском есть проблемы.
03 (03) Spin-Up Time — Время раскрутки пакета дисков из состояния покоя до рабочей скорости. Растет при износе механики (повышенное трение в подшипнике и т. п.), также может свидетельствовать о некачественном питании (например, просадке напряжения при старте диска).
04 (04) Start/Stop Count — Полное число циклов запуск-остановка шпинделя. У дисков некоторых производителей (например, Seagate) — счётчик включения режима энергосбережения. В поле raw value хранится общее количество запусков/остановок диска.
05 (05) Reallocated Sectors Count — Число операций переназначения секторов. Когда диск обнаруживает ошибку чтения/записи, он помечает сектор «переназначенным» и переносит данные в специально отведённую резервную область. Вот почему на современных жёстких дисках нельзя увидеть bad-блоки — все они спрятаны в переназначенных секторах. Этот процесс называют remapping, а переназначенный сектор — remap. Чем больше значение, тем хуже состояние поверхности дисков. Поле raw value содержит общее количество переназначенных секторов. Рост значения этого атрибута может свидетельствовать об ухудшении состояния поверхности блинов диска.
06 (06) Read Channel Margin — Запас канала чтения. Назначение этого атрибута не документировано. В современных накопителях не используется.
07 (07) Seek Error Rate — Частота ошибок при позиционировании блока магнитных головок. Чем их больше, тем хуже состояние механики и/или поверхности жёсткого диска. Также на значение параметра может повлиять перегрев и внешние вибрации (например, от соседних дисков в корзине).
08 (08) Seek Time Performance — Средняя производительность операции позиционирования магнитными головками. Если значение атрибута уменьшается (замедление позиционирования), то велика вероятность проблем с механической частью привода головок.
09 (09) Power-On Hours (POH) — Число часов (минут, секунд — в зависимости от производителя), проведённых во включенном состоянии. В качестве порогового значения для него выбирается паспортное время наработки на отказ (MTBF — mean time between failure).
10 (0А) Spin-Up Retry Count — Число повторных попыток раскрутки дисков до рабочей скорости в случае, если первая попытка была неудачной. Если значение атрибута увеличивается, то велика вероятность неполадок с механической частью.
11 (0В) Recalibration Retries — Количество повторов запросов рекалибровки в случае, если первая попытка была неудачной. Если значение атрибута увеличивается, то велика вероятность проблем с механической частью.
12 (0С) Device Power Cycle Count — Количество полных циклов включения-выключения диска.
13 (0D) Soft Read Error Rate — Число ошибок при чтении, по вине программного обеспечения, которые не поддались исправлению. Все ошибки имеют
не механическую
природу и указывают лишь на неправильную размётку/взаимодействие с диском программ или операционной системы.
100(64) Erase/Program Cycles (для SSD) Общее количество циклов стирания/программирования для всей флэш-памяти за всё время ее существования. Твердотельный накопитель имеет ограничение на количество записей в него. Точные значения (ресурс) зависят от установленных микросхем флэш-памяти.
В накопителях Kingston — объём стёртого в гигабайтах.
103(67) Translation Table Rebuild (для SSD) Количество событий, когда внутренние таблицы адресов блоков были повреждены и впоследствии восстановлены. Raw-значение этого атрибута указывает фактическое количество событий.
170(AA) Reserved Block Count (для SSD) Состояние пула резервных блоков. Значение атрибута показывает процент оставшегося пула. Иногда raw-значение содержит фактическое количество использованных резервных блоков.
170 атрибут связан с атрибутом 5, числом использованных резервных блоков.
171(AB) Program Fail Count (для SSD) Число попыток, когда запись во флэш-память не удалась. Raw-значение показывает фактическое количество отказов. Процесс записи технически называется «программирование флэш-памяти» — отсюда и название атрибута. Когда флэш-память изношена, она больше не может быть записана и становится доступной только для чтения.
Значение обычно идентично атрибуту 181.
172(AC) Erase Fail Count (для SSD) Количество сбоев операции стирания на флэш-памяти. Raw-значение показывает фактическое количество отказов. Полный цикл записи флэш-памяти состоит из двух этапов. Сначала необходимо удалить память, а затем данные должны быть записаны («запрограммированы») в память. Когда флэш-память изношена, она больше не может быть записана и становится доступной только для чтения.
Идентичен атрибуту 182.
173(AD) Wear Leveller Worst Case Erase Count (для SSD) Максимальное количество операций стирания, выполняемых для одного блока флэш-памяти.
174(AE) Unexpected Power Loss (для SSD) Число неожиданных отключений питания, когда питание было потеряно до получения команды на отключение диска. На жестком диске срок службы при таких отключениях намного меньше, чем при обычном отключении. На SSD существует риск потери внутренней таблицы состояний при неожиданном завершении работы.
175(AF) Program Fail Count (для SSD) Число попыток, когда запись во флэш-память не удалась. Raw-значение показывает фактическое количество отказов. Процесс записи технически называется «программирование флэш-памяти», отсюда и название атрибута. Когда флэш-память изношена, она больше не может быть записана и становится доступной только для чтения.
176(B0) Erase Fail Count (для SSD) Количество сбоев операции стирания на флэш-памяти. Raw-значение показывает фактическое количество отказов. Полный цикл записи флэш-памяти состоит из двух этапов. Сначала необходимо удалить память, а затем данные должны быть записаны («запрограммированы») в память. Когда флэш-память изношена, она больше не может быть записана и становится доступной только для чтения.
177(B1) Wear Leveling Count (для SSD)
Wear Range Delta В зависимости от производителя, максимальное количество операций стирания, выполняемых для одного блока флэш-памяти[источник не указан 269 дней] или разница между максималоьно изношенными (больше всего раз записанными) и минимально изношенными (записанными наименьшее число раз) блоками[4].
178(B2) Used Reserved Block Count (для SSD) Состояние пула резервных блоков. Значение атрибута показывает процент оставшегося пула. Raw-значение этого атрибута иногда содержит фактическое количество использованных резервных блоков.
179(B3) Used Reserved Block Count (для SSD) Состояние пула резервных блоков. Значение атрибута показывает процент оставшегося пула. Raw-значение этого атрибута иногда содержит фактическое количество использованных резервных блоков.
180(B4) Unused Reserved Block Count (для SSD) Состояние пула резервных блоков. Значение атрибута показывает процент оставшегося пула. Raw-значение этого атрибута иногда содержит фактическое количество неиспользованных резервных блоков.
181(B5) Program Fail Count (для SSD) Число попыток, когда запись во флэш-память не удалась. Raw-значение показывает фактическое количество отказов.
182(B6) Erase Fail Count (для SSD) Количество сбоев операции стирания на флэш-памяти. Raw-значение показывает фактическое количество отказов.
183(B7) SATA Downshifts (для SSD) Указывает, как часто требовалось снизить скорость передачи данных SATA (с 6 Гбит/с до 3 или 1,5 Гбит/с или с 3 Гбит/с до 1,5 Гбит/с) для успешной передачи данных. Если значение атрибута уменьшается, попробуйте заменить кабель SATA.
Суть в том, что винчестер, работающий в режимах SATA 3 Гбит/с или 6 Гбит/с (и что там дальше будет в будущем), по какой-то причине (например, из-за ошибок) может попытаться «договориться» с дисковым контроллером о менее скоростном режиме (например, SATA 1.5 Гбит/с или 3 Гбит/с соответственно). В случае «отказа» контроллера изменять режим диск увеличивает значение атрибута (Western Digital und Samsung).
184 (B8) End-to-End error — Назначение зависит от производителя.
У HP (часть технологии HP SMART IV) увеличивается в случае, когда после передачи данных через кэш-память чётность данных между хостом и жёстким диском не совпадает.
У Kinston это количество ошибок чтения из флэш-памяти.
185 (B9) Head Stability Стабильность головок (Western Digital).
187 (BB) Reported UNC Errors — Количество ошибок, которое накопитель сообщил хосту (интерфейсу компьютера) при любых операциях, обычно это ошибки данных на диске, которые не исправлены средствами ECC
188 (BC) Command Timeout — содержит количество операций, выполнение которых было отменено из–за превышения максимально допустимого времени ожидания отклика.Такие ошибки могут возникать из-за плохого качества кабелей, контактов, используемых переходников, удлинителей и т.д., несовместимости диска с конкретным контроллером SATA/РАТА на материнской плате и т.д. Из-за ошибок такого рода возможны BSOD в Windows.
Ненулевое значение атрибута говорит о потенциальной «болезни» диска.
189 (BD) High Fly Writes — содержит количество зафиксированных случаев записи при высоте «полета» головки выше рассчитанной, скорее всего, из-за внешних воздействий, например, вибрации.
Для того, чтобы сказать, почему происходят такие случаи, нужно уметь анализировать логи S.M.A.R.T., которые содержат специфичную для каждого производителя информацию
190 (BE) Airflow Temperature (WDC) — Температура воздуха внутри корпуса жёсткого диска. Для дисков Seagate рассчитывается по формуле (100 — HDA temperature). Для дисков
Western Digital
— (125 — HDA).
191 (BF) G-sense error rate — Количество ошибок, возникающих в результате ударных нагрузок. Атрибут хранит показания встроенного акселерометра, который
фиксирует все удары, толчки, падения и даже неаккуратную установку диска в корпус компьютера.
Актуален для мобильных винчестеров. На дисках Samsung на него часто можно не обращать внимания, т.к. они могут иметь очень чувствительный датчик, который, образно говоря, реагирует чуть ли не на движение воздуха от крыльев пролетающей в одном помещении с диском мухой.
Вообще срабатывание датчика не является признаком удара. Может расти даже от позиционирования БМГ самим диском, особенно, если его не закрепить. Основное назначение датчика – прекратить операцию записи при вибрациях, чтобы избежать ошибок.
75