![]()
Загрузить PDF
![]()
Загрузить PDF
Абсолютная ошибка – это разность между измеренным значением и фактическим значением.[1]
Эта ошибка характеризует точность измерений. Если вам известны фактическое и измеренное значения, можно с легкостью вычислить абсолютную ошибку. Но иногда фактическое значение не дано, поэтому в качестве абсолютной ошибки пользуются максимально возможной ошибкой.[2]
Если даны фактическое значение и относительная ошибка, можно вычислить абсолютную ошибку.
-

1
Запишите формулу для вычисления абсолютной ошибки. Формула:
, где
– абсолютная ошибка (разность между измеренным и фактическим значениями),
– измеренное значение,
– фактическое значение.[3]
-

2
Подставьте в формулу фактическое значение. Фактическое значение должно быть дано; в противном случае используйте принятое опорное значение. Фактическое значение подставьте вместо
- Например, нужно измерить длину футбольного поля. Фактическая длина (принятая опорная длина) футбольного поля равна 105 м (именно такое значение рекомендуется FIFA). Таким образом, фактическое значение равно 105 м:
.
- Например, нужно измерить длину футбольного поля. Фактическая длина (принятая опорная длина) футбольного поля равна 105 м (именно такое значение рекомендуется FIFA). Таким образом, фактическое значение равно 105 м:
-

3
Подставьте в формулу измеренное значение. Оно будет дано; в противном случае измерьте величину (длину или ширину и так далее). Измеренное значение подставьте вместо
- Например, вы измерили длину футбольного поля и получили значение 104 м. Таким образом, измеренное значение равно 104 м:
.
- Например, вы измерили длину футбольного поля и получили значение 104 м. Таким образом, измеренное значение равно 104 м:
-

4
Вычтите фактическое значение из измеренного значения. Так как абсолютная ошибка всегда положительна, возьмите абсолютное значение этой разницы, то есть не учитывайте знак «минус».[4]
Так вы вычислите абсолютную ошибку.- В нашем примере:
, то есть абсолютная ошибка измерения равна 1 м.
Реклама
- В нашем примере:
-

1
Запишите формулу для вычисления относительной ошибки. Формула:
, где
– относительная ошибка (отношение абсолютной ошибки к фактическому значению),
-

2
Подставьте в формулу относительную ошибку. Скорее всего, она будет дана в виде десятичной дроби. Относительную ошибку подставьте вместо
- Например, если относительная ошибка равна 0,02, формула запишется так:
.
- Например, если относительная ошибка равна 0,02, формула запишется так:
-

3
Подставьте в формулу фактическое значение. Оно будет дано. Фактическое значение подставьте вместо
- Например, если фактическое значение равно 105 м, формула запишется так:
.
- Например, если фактическое значение равно 105 м, формула запишется так:
-

4
Умножьте обе стороны уравнения на фактическое значение. Так вы избавитесь от дроби.
-

5
Прибавьте фактическое значение к каждой стороне уравнения. Так вы найдете
-

6
Вычтите фактическое значение из измеренного значения. Так как абсолютная ошибка всегда положительна, возьмите абсолютное значение этой разницы, то есть не учитывайте знак «минус».[6]
Так вы вычислите абсолютную ошибку.- Например, если измеренное значение равно 107,1 м, а фактическое значение равно 105 м, вычисления запишутся так:
. Таким образом, абсолютная ошибка равна 2,1 м.
Реклама
- Например, если измеренное значение равно 107,1 м, а фактическое значение равно 105 м, вычисления запишутся так:
-

1
Определите единицу измерения. То есть выясните, было ли значение измерено с точностью до сантиметра, метра и так далее. Возможно, эта информация будет дана (например, «длина поля измерена с точностью до метра»). Чтобы определить единицу измерения, посмотрите на то, как округлено данное значение.[7]
- Например, если измеренная длина поля равна 106 м, значение было округлено до метров. Таким образом, единица измерения равна 1 м.
-

2
-

3
Используйте максимально возможную ошибку в качестве абсолютной ошибки.[9]
Так как абсолютная ошибка всегда положительна, возьмите абсолютное значение этой разницы, то есть не учитывайте знак «минус».[10]
Так вы вычислите абсолютную ошибку.- Например, если измеренная длина поля равна
м, то есть абсолютная ошибка равна 0,5 м.
Реклама
- Например, если измеренная длина поля равна
Советы
- Если фактическое значение не указано, найдите принятое опорное или теоретическое значение.
Реклама
Об этой статье
Эту страницу просматривали 24 549 раз.
Была ли эта статья полезной?
Абсолютная погрешность
- Причины возникновения погрешности измерения
- Систематическая и случайная погрешности
- Определение абсолютной погрешности
- Алгоритм оценки абсолютной погрешности в серии прямых измерений
- Значащие цифры и правила округления результатов измерений
- Примеры
Причины возникновения погрешности измерения
Погрешность измерения – это отклонение измеренного значения величины от её истинного (действительного) значения.
Обычно «истинное» значение неизвестно, и можно только оценить погрешность, приняв в качестве «истинного» среднее значение, полученное в серии измерений. Таким образом, процесс оценки проводится статистическими методами.
Виды погрешности измерений
Причины
Инструментальная погрешность
Определяется погрешностью инструментов и приборов, используемых для измерений (принципом действия, точностью шкалы и т.п.)
Погрешность метода
Определяется несовершенством методов и допущениями в методике.
Теоретическая погрешность
Определяется теоретическими упрощениями, степенью соответствия теоретической модели и реальности.
Погрешность оператора
Определяется субъективным фактором, ошибками экспериментатора.
Систематическая и случайная погрешности
Систематической погрешностью называют погрешность, которая остаётся постоянной или изменяется закономерно во времени при повторных измерениях одной и той же величины.
Систематическая погрешность всегда имеет знак «+» или «-», т.е. говорят о систематическом завышении или занижении результатов измерений.
Систематическую погрешность можно легко определить, если известно эталонное (табличное) значение измеряемой величины. Для других случаев разработаны эффективные статистические методы выявления систематических погрешностей. Причиной систематической погрешности может быть неправильная настройка приборов или неправильная оценка параметров (завышенная или заниженная) в расчётных формулах.
Случайной погрешностью называют погрешность, которая не имеет постоянного значения при повторных измерениях одной и той же величины.
Случайные погрешности неизбежны и всегда присутствуют при измерениях.
Определение абсолютной погрешности
Абсолютная погрешность измерения – это модуль разности между измеренным и истинным значением измеряемой величины:
$$ Delta x = |x_{изм}-x_{ист} | $$
Например:
При пяти взвешиваниях гири с маркировкой 100 г были получены различные значения массы. Если принять маркировку за истинное значение, то получаем следующие значения абсолютной погрешности:
$m_i,г$
98,4
99,2
98,1
100,3
98,5
$Delta m_i, г$
1,6
0,8
1,9
0,3
1,5
Граница абсолютной погрешности – это величина h: $ |x-x_{ист}| le h $
Для оценки границы абсолютной погрешности на практике используются статистические методы.
Алгоритм оценки абсолютной погрешности в серии прямых измерений
Шаг 1. Проводим серию из N измерений, в каждом из которых получаем значение измеряемой величины $x_i, i = overline{1, N}$.
Шаг 2. Находим оценку истинного значения x как среднее арифметическое данной серии измерений:
$$ a = x_{cp} = frac{x_1+x_2+ cdots +x_N}{N} = frac{1}{N} sum_{i = 1}^N x_i $$
Шаг 3. Рассчитываем абсолютные погрешности для каждого измерения:
$$ Delta x_i = |x_i-a| $$
Шаг 4. Находим среднее арифметическое абсолютных погрешностей:
$$ Delta x_{cp} = frac{Delta x_1+ Delta x_2+ cdots + Delta x_N}{N} = frac{1}{N} sum_{i = 1}^N Delta x_i $$
Шаг 5. Определяем инструментальную погрешность при измерении как цену деления прибора (инструмента) d.
Шаг 6. Проводим оценку границы абсолютной погрешности серии измерений, выбирая большую из двух величин:
$$ h = max {d; Delta x_{cp} } $$
Шаг 7. Округляем и записываем результаты измерений в виде:
$$ a-h le x le a+h или x = a pm h $$
Значащие цифры и правила округления результатов измерений
Значащими цифрами – называют все верные цифры числа, кроме нулей слева. Результаты измерений записывают только значащими цифрами.
Например:
0,00501 — три значащие цифры 5,0 и 1.
5,01 — три значащие цифры.
5,0100 – пять значащих цифр; такая запись означает, что величина измерена с точностью 0,0001.
Внимание!
Правила округления.
Погрешность измерения округляют до первой значащей цифры, всегда увеличивая ее на единицу (округление по избытку, “ceiling”).
Округлять результаты измерений и вычислений нужно так, чтобы последняя значащая цифра находилась в том же десятичном разряде, что и абсолютная погрешность измеряемой величины.
Например: если при расчетах по результатам серии измерений получена оценка истинного значения a=1,725, а оценка абсолютной погрешности h = 0,11, то результат записывается так:
$$ a approx 1,7; h approx ↑0,2; 1,5 le x le 1,9 или x = 1,7 pm 0,2 $$
Примеры
Пример 1. При измерении температура воды оказалась в пределах от 11,55 ℃ до 11,63 ℃. Какова абсолютная погрешность этих измерений?
По условию $11,55 le t le 11,63$. Получаем систему уравнений:
$$ {left{ begin{array}{c} a-h = 11,55 \ a+h = 11,63 end{array} right.} Rightarrow {left{ begin{array}{c} 2a = 11,55+11,63 = 23,18 \ 2h = 11,63-11,55 = 0,08 end{array} right.} Rightarrow {left{ begin{array}{c} a = 11,59 \ h = 0,04end{array} right.} $$
$$ t = 11,59 pm 0,04 ℃ $$
Ответ: 0,04 ℃
Пример 2. По результатам измерений найдите границы измеряемой величины. Инструментальная погрешность d = 0,1.
$x_i$
15,3
16,4
15,3
15,8
15,7
16,2
15,9
Находим среднее арифметическое:
$$ a = x_{ср} = frac{15,3+16,4+ cdots +15,9}{7} = 15,8 $$
Находим абсолютные погрешности:
$$ Delta x_i = |x_i-a| $$
$ Delta x_i$
0,5
0,6
0,5
0
0,1
0,4
0,1
Находим среднее арифметическое:
$$ Delta x_{ср} = frac{0,5+0,6+ cdots + 0,1}{7} approx 0,31 gt d $$
Выбираем большую величину:
$$ h = max {d; Delta x_{ср} } = max {0,1; 0,31} = 0,31 $$
Округляем по правилам округления по избытку: $h approx ↑0,4$.
Получаем: x = 15, $8 pm 0,4$
Границы: $15,4 le x le 16,2$
Ответ: $15,4 le x le 16,2$
Пример 3*. В первой серии экспериментов было получено значение $x = a pm 0,3$. Во второй серии экспериментов было получено более точное значение $x = 5,631 pm 0,001$. Найдите оценку средней a согласно полученным значениям x.
Более точное значение определяет более узкий интервал для x. По условию:
$$ {left{ begin{array}{c} a-0,3 le x le a+0,3 \ 5,630 le x le 5,632 end{array} right.} Rightarrow a-0,3 le 5,630 le x le 5,632 le a+0,3 Rightarrow $$
$$ Rightarrow {left{ begin{array}{c} a-0,3 le 5,630 \ 5,632 le a+0,3 end{array} right.} Rightarrow {left{ begin{array}{c} a le 5,930 \ 5,332 le a end{array} right.} Rightarrow 5,332 le a le 5,930 $$
Т.к. a получено в серии экспериментов с погрешностью h=0,3, следует округлить полученные границы до десятых:
$$ 5,3 le a le 5,9 $$
Ответ: $ 5,3 le a le 5,9 $
Абсолютная и относительная погрешности (ошибки).
Пусть некоторая
величина x
измерена n
раз. В результате получен ряд значений
этой величины: x1,
x2,
x3,
…, xn
Величиной, наиболее
близкой к действительному значению,
является среднее арифметическое этих
результатов:
![]()
Отсюда следует,
что каждое физическое измерение должно
быть повторено несколько раз.
Разность между
средним значением
![]() измеряемой
измеряемой
величины и значением отдельного измерения
называется абсолютной
погрешностью отдельного измерения:
![]()
(13)
Абсолютная
погрешность может быть как положительной,
так и отрицательной и измеряется в тех
же единицах, что и измеряемая величина.
Средняя абсолютная
ошибка результата — это среднее
арифметическое значений абсолютных
погрешностей отдельных измерений,
взятых по абсолютной величине (модулю):
![]()
(14)
Отношения
![]()
называются относительными погрешностями
(ошибками) отдельных измерений.
Отношение средней
абсолютной погрешности результата
![]()
к среднему арифметическому значению
![]()
измеряемой величины называют относительной
ошибкой результата и выражают в процентах:
![]()
Относительная
ошибка характеризует точность измерения.
Законы распределения случайных величин.
Результат измерения
физической величины зависит от многих
факторов, влияние которых заранее учесть
невозможно. Поэтому значения, полученные
в результате прямых измерений какого
— либо параметра, являются случайными,
обычно не совпадающие между собой.
Следовательно, случайные
величины —
это такие величины, которые в зависимости
от обстоятельств могут принимать те
или иные значения. Если случайная
величина принимает только определенные
числовые значения, то она называется
дискретной.
Например,
количество заболеваний в данном регионе
за год, оценка, полученная студентом на
экзамене, энергия электрона в атоме и
т.д.
Непрерывная
случайная величина принимает любые
значения в данном интервале.
Например: температура
тела человека, мгновенные скорости
теплового движения молекул, содержание
кислорода в воздухе и т.д.
Под событием
понимается всякий результат или исход
испытания. В теории вероятностей
рассматриваются события, которые при
выполнение некоторых условий могут
произойти, а могут не произойти. Такие
события называются
случайными.
Например, событие, состоящее в появлении
цифры 1 при выполнении условия — бросания
игральной кости, может произойти, а
может не произойти.
Если событие
неизбежно происходит в результате
каждого испытания, то оно называется
достоверным.
Событие называется невозможным,
если оно вообще не происходит ни при
каких условиях.
Два события,
одновременное появление которых
невозможно, называются несовместными.
Пусть случайное
событие А в серии из n
независимых испытаний произошло m
раз, тогда отношение:
![]()
называется
относительной частотой события А. Для
каждой относительной частоты выполняется
неравенство:
![]()
При небольшом
числе опытов относительная частота
событий в значительной мере имеет
случайный характер и может заметно
изменяться от одной группы опытов к
другой. Однако при увеличении числа
опытов частота событий все более теряет
свой случайный характер и приближается
к некоторому постоянному положительному
числу, которое является количественной
мерой возможности реализации случайного
события А. Предел, к которому стремится
относительная частота событий при
неограниченном увеличении числа
испытаний, называется статистической
вероятностью события:
![]()
Например, при
многократном бросании монеты частота
выпадения герба будет лишь незначительно
отличаться от ½. Для достоверного события
вероятность Р(А) равна единице. Если
Р=0, то событие невозможно.
Математическим
ожиданием
дискретной случайной величины называется
сумма произведений всех ее возможных
значений хi
на вероятность этих значений рi:
![]()
Статистическим
аналогом математического ожидания
является среднее арифметическое значений
![]() :
:
![]() ,
,
где mi
— число дискретных случайных величин,
имеющих значение хi.
Для непрерывной
случайной величины математическим
ожиданием служит интеграл:
![]() ,
,
где р(х) — плотность
вероятности.
Отдельные значения
случайной величины группируются около
математического ожидания. Отклонение
случайной величины от ее математического
ожидания (среднего значения) характеризуется
дисперсией,
которая для дискретной случайной
величины определяется формулой:
![]()
(15)

(16)
Дисперсия имеет
размерность случайной величины. Для
того, чтобы оценивать рассеяние
(отклонение) случайной величины в
единицах той же размерности, введено
понятие среднего
квадратичного отклонения
σ(Х), которое
равно корню квадратному из дисперсии:
![]()
(17)
Вместо среднего
квадратичного отклонения иногда
используется термин «стандартное
отклонение».
Всякое отношение,
устанавливающее связь между всеми
возможными значениями случайной величины
и соответствующими им вероятностями,
называется законом
распределения случайной величины.
Формы задания закона распределения
могут быть разными:
а) ряд распределения
(для дискретных величин);
б) функция
распределения;
в) кривая распределения
(для непрерывных величин).
Существует
относительно много законов распределения
случайных величин.
Нормальный
закон распределения случайных
величин (закон
Гаусса).
Случайная величина
![]()
распределена по
нормальному закону, если ее плотность
вероятности f(x)
определяется формулой:

(18),
где <x>
— математическое ожидание (среднее
значение) случайной величины <x>
= M
(X);
![]() —
—
среднее квадратичное отклонение;
![]() —
—
основание натурального логарифма
(неперово число);
f
(x)
– плотность вероятности (функция
распределения вероятностей).
Многие случайные
величины (в том числе все случайные
погрешности) подчиняются нормальному
закону распределения (закону Гаусса).
Для этого распределения наиболее
вероятным значением
измеряемой
величины
является
её среднее
арифметическое
значение.
График нормального
закона распределения изображен на
рисунке (колоколообразная кривая).

Кривая симметрична
относительно прямой х=<x>=α,
следовательно, отклонения случайной
величины вправо и влево от <x>=α
равновероятны. При х=<x>±
кривая асимптотически приближается к
оси абсцисс. Если х=<x>,
то функция распределения вероятностей
f(x)
максимальна и принимает вид:
![]()
(19)
Таким образом,
максимальное значение функции fmax(x)
зависит от величины среднего квадратичного
отклонения. На рисунке изображены 3
кривые распределения. Для кривых 1 и 2
<x>
= α = 0 соответствующие значения среднего
квадратичного отклонения различны, при
этом 2>1.
(При увеличении
кривая распределения становится более
пологой, а при уменьшении
– вытягивается вверх). Для кривой 3 <x>
= α ≠ 0 и 3
= 2.
Закон
распределения
молекул в газах по скоростям называется
распределением
Максвелла.
Функция плотности вероятности попадания
скоростей молекул в определенный
интервал
![]()
теоретически была определена в 1860 году
английским физиком Максвеллом

. На рисунке
распределение Максвелла представлено
графически. Распределение движется
вправо или влево в зависимости от
температуры газа (на рисунке Т1
< Т2).
Закон распределения Максвелла определяется
формулой:
![]()
(20),
где mо
– масса молекулы, k
– постоянная Больцмана, Т – абсолютная
температура газа,
![]() —
—
скорость молекулы.
Распределение
концентрации молекул газа в атмосфере
Земли (т.е.
в силовом поле) в зависимости от высоты
было дано австрийским физиком Больцманом
и называется
распределением
Больцмана:

(21)
Где n(h)
– концентрация молекул газа на высоте
h,
n0
– концентрация у поверхности Земли, g
– ускорение свободного падения, m
– масса молекулы.

Распределение
Больцмана.
Совокупность всех
значений случайной величины называется
простым
статистическим рядом.
Так как простой статистический ряд
оказывается большим, то его преобразуют
в вариационный
статистический
ряд или интервальный
статистический ряд. По интервальному
статистическому ряду для оценки вида
функции распределения вероятностей по
экспериментальным данным строят
гистограмму
– столбчатую
диаграмму. (Гистограмма – от греческих
слов “histos”–
столб и “gramma”–
запись).
n

-
h
Гистограмма
распределения Больцмана.
Для построения
гистограммы интервал, содержащий
полученные значения случайной величины
делят на несколько интервалов xi
одинаковой ширины. Для каждого интервала
подсчитывают число mi
значений случайной величины, попавших
в этот интервал. После этого вычисляют
плотность частоты случайной величины
![]()
для каждого интервала xi
и среднее значение случайной величины
<xi
> в каждом интервале.
Затем по оси абсцисс
откладывают интервалы xi,
являющиеся основаниями прямоугольников,
высота которых равна
![]() (или
(или
высотой
![]()
– плотностью относительной частоты
![]() ).
).
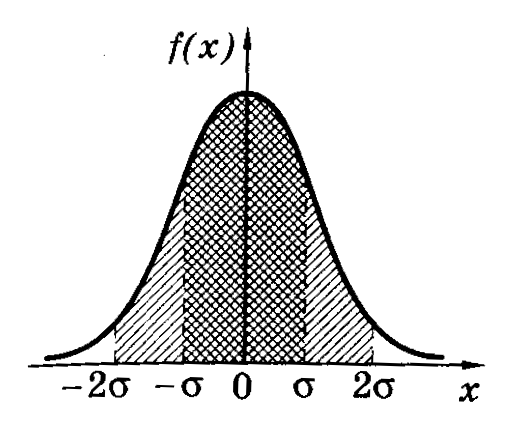
Расчетами показано,
что вероятность попадания нормально
распределенной случайной величины в
интервале значений от <x>–
до <x>+
в среднем равна 68%. В границах вдвое
более широких (<x>–2;
<x>+2)
размещается в среднем 95% всех значений
измерений, а в интервале (<x>–3;<x>+3)
– уже 99,7%. Таким образом, вероятность
того, что отклонение значений нормально
распределенной случайной величины
превысит 3
(
– среднее квадратичное отклонение)
чрезвычайно мала (~0,003). Такое событие
можно считать практически невозможным.
Поэтому границы <x>–3
и <x>+3
принимаются за границы практически
возможных значений нормально распределенной
случайной величины («правило трех
сигм»).
Если число измерений
(объем выборки) невелико (n<30),
дисперсия вычисляется по формуле:
![]()
(22)
Уточненное среднее
квадратичное отклонение отдельного
измерения вычисляется по формуле:

(23)
Напомним, что для
эмпирического распределения по выборке
аналогом математического ожидания
является среднее арифметическое значение
<x>
измеряемой величины.
Чтобы дать
представление о точности и надежности
оценки измеряемой величины, используют
понятия доверительного интервала и
доверительной вероятности.
Доверительным
интервалом
называется интервал (<x>–x,
<x>+x),
в который по определению попадает с
заданной вероятностью действительное
(истинное) значение измеряемой величины.
Доверительный интервал характеризует
точность полученного результата: чем
уже доверительный интервал, тем меньше
погрешность.
Доверительной
вероятностью
(надежностью)
результата серии измерений называется
вероятность того, что истинное значение
измеряемой величины попадает в данный
доверительный интервал (<x>±x).
Чем больше величина доверительного
интервала, т.е. чем больше x,
тем с большей надежностью величина <x>
попадает в этот интервал. Надежность
выбирается самим исследователем
самостоятельно, например, =0,95;
0,98. В медицинских и биологических
исследованиях, как правило, доверительную
вероятность (надежность) принимают
равной 0,95.
Если величина х
подчиняется нормальному закону
распределения Гаусса, а <x>
и <>
оцениваются по выборке (числу измерений)
и если объем выборки невелик (n<30),
то интервал (<x>
– t,n<>,
<x>
+ t,n<>)
будет доверительным интервалом для
известного параметра х с доверительной
вероятностью .
Коэффициент t,n
называется коэффициентом
Стьюдента
(этот коэффициент был предложен в 1908 г.
английским математиком и химиком В.С.
Госсетом, публиковавшим свои работы
под псевдонимом «Стьюдент» – студент).
Значении коэффициента
Стьюдента t,n
зависит от доверительной вероятности
и числа измерений n
(объема выборки). Некоторые значения
коэффициента Стьюдента приведены в
таблице 1.
Таблица 1
|
n |
|
||||||
|
0,6 |
0,7 |
0,8 |
0,9 |
0,95 |
0,98 |
0,99 |
|
|
2 |
1,38 |
2,0 |
3,1 |
6,3 |
12,7 |
31,8 |
63,7 |
|
3 |
1,06 |
1,3 |
1,9 |
2,9 |
4,3 |
7,0 |
9,9 |
|
4 |
0,98 |
1,3 |
1,6 |
2,4 |
3,2 |
4,5 |
5,8 |
|
5 |
0,94 |
1,2 |
1,5 |
2,1 |
2,8 |
3,7 |
4,6 |
|
6 |
0,92 |
1,2 |
1,5 |
2,0 |
2,6 |
3,4 |
4,0 |
|
7 |
0,90 |
1,1 |
1,4 |
1,9 |
2,4 |
3,1 |
3,7 |
|
8 |
0,90 |
1,1 |
1,4 |
1,9 |
2,4 |
3,0 |
3,5 |
|
9 |
0,90 |
1,1 |
1,4 |
1,9 |
2,3 |
2,9 |
3,4 |
|
10 |
0,88 |
1,1 |
1,4 |
1,9 |
2,3 |
2,8 |
3,3 |
В таблице 1 в верхней
строке заданы значения доверительной
вероятности
от 0,6 до 0,99, в левом столбце – значение
n.
Коэффициент Стьюдента следует искать
на пересечении соответствующих строки
и столбца.
Окончательный
результат измерений записывается в
виде:
![]()
(25)
Где
![]()
– полуширина доверительного интервала.
Результат серии
измерений оценивается относительной
погрешностью:

(26)
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
From Wikipedia, the free encyclopedia
In statistics, mean absolute error (MAE) is a measure of errors between paired observations expressing the same phenomenon. Examples of Y versus X include comparisons of predicted versus observed, subsequent time versus initial time, and one technique of measurement versus an alternative technique of measurement. MAE is calculated as the sum of absolute errors divided by the sample size:[1]

It is thus an arithmetic average of the absolute errors 


Quantity disagreement and allocation disagreement[edit]
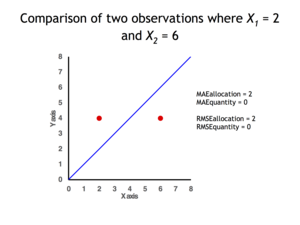
2 data points for which Quantity Disagreement is 0 and Allocation Disagreement is 2 for both MAE and RMSE
It is possible to express MAE as the sum of two components: Quantity Disagreement and Allocation Disagreement. Quantity Disagreement is the absolute value of the Mean Error given by:[4]

Allocation Disagreement is MAE minus Quantity Disagreement.
It is also possible to identify the types of difference by looking at an 
[edit]
The mean absolute error is one of a number of ways of comparing forecasts with their eventual outcomes. Well-established alternatives are the mean absolute scaled error (MASE) and the mean squared error. These all summarize performance in ways that disregard the direction of over- or under- prediction; a measure that does place emphasis on this is the mean signed difference.
Where a prediction model is to be fitted using a selected performance measure, in the sense that the least squares approach is related to the mean squared error, the equivalent for mean absolute error is least absolute deviations.
MAE is not identical to root-mean square error (RMSE), although some researchers report and interpret it that way. MAE is conceptually simpler and also easier to interpret than RMSE: it is simply the average absolute vertical or horizontal distance between each point in a scatter plot and the Y=X line. In other words, MAE is the average absolute difference between X and Y. Furthermore, each error contributes to MAE in proportion to the absolute value of the error. This is in contrast to RMSE which involves squaring the differences, so that a few large differences will increase the RMSE to a greater degree than the MAE.[4] See the example above for an illustration of these differences.
Optimality property[edit]
The mean absolute error of a real variable c with respect to the random variable X is

Provided that the probability distribution of X is such that the above expectation exists, then m is a median of X if and only if m is a minimizer of the mean absolute error with respect to X.[6] In particular, m is a sample median if and only if m minimizes the arithmetic mean of the absolute deviations.[7]
More generally, a median is defined as a minimum of

as discussed at Multivariate median (and specifically at Spatial median).
This optimization-based definition of the median is useful in statistical data-analysis, for example, in k-medians clustering.
Proof of optimality[edit]
Statement: The classifier minimising 

Proof:
The Loss functions for classification is
![{displaystyle {begin{aligned}L&=mathbb {E} [|y-a||X=x]\&=int _{-infty }^{infty }|y-a|f_{Y|X}(y),dy\&=int _{-infty }^{a}(a-y)f_{Y|X}(y),dy+int _{a}^{infty }(y-a)f_{Y|X}(y),dy\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7e953e54457072620a7c2764db0801f69c4e883d)
Differentiating with respect to a gives

This means

Hence

See also[edit]
- Least absolute deviations
- Mean absolute percentage error
- Mean percentage error
- Symmetric mean absolute percentage error
References[edit]
- ^ Willmott, Cort J.; Matsuura, Kenji (December 19, 2005). «Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance». Climate Research. 30: 79–82. doi:10.3354/cr030079.
- ^ «2.5 Evaluating forecast accuracy | OTexts». www.otexts.org. Retrieved 2016-05-18.
- ^ Hyndman, R. and Koehler A. (2005). «Another look at measures of forecast accuracy» [1]
- ^ a b c Pontius Jr., Robert Gilmore; Thontteh, Olufunmilayo; Chen, Hao (2008). «Components of information for multiple resolution comparison between maps that share a real variable». Environmental and Ecological Statistics. 15 (2): 111–142. doi:10.1007/s10651-007-0043-y. S2CID 21427573.
- ^ Willmott, C. J.; Matsuura, K. (January 2006). «On the use of dimensioned measures of error to evaluate the performance of spatial interpolators». International Journal of Geographical Information Science. 20: 89–102. doi:10.1080/13658810500286976. S2CID 15407960.
- ^ Stroock, Daniel (2011). Probability Theory. Cambridge University Press. pp. 43. ISBN 978-0-521-13250-3.
- ^ Nicolas, André (2012-02-25). «The Median Minimizes the Sum of Absolute Deviations (The $ {L}_{1} $ Norm)». StackExchange.
From Wikipedia, the free encyclopedia
In statistics, mean absolute error (MAE) is a measure of errors between paired observations expressing the same phenomenon. Examples of Y versus X include comparisons of predicted versus observed, subsequent time versus initial time, and one technique of measurement versus an alternative technique of measurement. MAE is calculated as the sum of absolute errors divided by the sample size:[1]
It is thus an arithmetic average of the absolute errors
Quantity disagreement and allocation disagreement[edit]
2 data points for which Quantity Disagreement is 0 and Allocation Disagreement is 2 for both MAE and RMSE
It is possible to express MAE as the sum of two components: Quantity Disagreement and Allocation Disagreement. Quantity Disagreement is the absolute value of the Mean Error given by:[4]
Allocation Disagreement is MAE minus Quantity Disagreement.
It is also possible to identify the types of difference by looking at an
[edit]
The mean absolute error is one of a number of ways of comparing forecasts with their eventual outcomes. Well-established alternatives are the mean absolute scaled error (MASE) and the mean squared error. These all summarize performance in ways that disregard the direction of over- or under- prediction; a measure that does place emphasis on this is the mean signed difference.
Where a prediction model is to be fitted using a selected performance measure, in the sense that the least squares approach is related to the mean squared error, the equivalent for mean absolute error is least absolute deviations.
MAE is not identical to root-mean square error (RMSE), although some researchers report and interpret it that way. MAE is conceptually simpler and also easier to interpret than RMSE: it is simply the average absolute vertical or horizontal distance between each point in a scatter plot and the Y=X line. In other words, MAE is the average absolute difference between X and Y. Furthermore, each error contributes to MAE in proportion to the absolute value of the error. This is in contrast to RMSE which involves squaring the differences, so that a few large differences will increase the RMSE to a greater degree than the MAE.[4] See the example above for an illustration of these differences.
Optimality property[edit]
The mean absolute error of a real variable c with respect to the random variable X is
Provided that the probability distribution of X is such that the above expectation exists, then m is a median of X if and only if m is a minimizer of the mean absolute error with respect to X.[6] In particular, m is a sample median if and only if m minimizes the arithmetic mean of the absolute deviations.[7]
More generally, a median is defined as a minimum of
as discussed at Multivariate median (and specifically at Spatial median).
This optimization-based definition of the median is useful in statistical data-analysis, for example, in k-medians clustering.
Proof of optimality[edit]
Statement: The classifier minimising
Proof:
The Loss functions for classification is
Differentiating with respect to a gives
This means
Hence
See also[edit]
- Least absolute deviations
- Mean absolute percentage error
- Mean percentage error
- Symmetric mean absolute percentage error
References[edit]
- ^ Willmott, Cort J.; Matsuura, Kenji (December 19, 2005). «Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance». Climate Research. 30: 79–82. doi:10.3354/cr030079.
- ^ «2.5 Evaluating forecast accuracy | OTexts». www.otexts.org. Retrieved 2016-05-18.
- ^ Hyndman, R. and Koehler A. (2005). «Another look at measures of forecast accuracy» [1]
- ^ a b c Pontius Jr., Robert Gilmore; Thontteh, Olufunmilayo; Chen, Hao (2008). «Components of information for multiple resolution comparison between maps that share a real variable». Environmental and Ecological Statistics. 15 (2): 111–142. doi:10.1007/s10651-007-0043-y. S2CID 21427573.
- ^ Willmott, C. J.; Matsuura, K. (January 2006). «On the use of dimensioned measures of error to evaluate the performance of spatial interpolators». International Journal of Geographical Information Science. 20: 89–102. doi:10.1080/13658810500286976. S2CID 15407960.
- ^ Stroock, Daniel (2011). Probability Theory. Cambridge University Press. pp. 43. ISBN 978-0-521-13250-3.
- ^ Nicolas, André (2012-02-25). «The Median Minimizes the Sum of Absolute Deviations (The $ {L}_{1} $ Norm)». StackExchange.
17 авг. 2022 г.
читать 1 мин
В статистике средняя абсолютная ошибка (MAE) — это способ измерения точности данной модели. Он рассчитывается как:
MAE = (1/n) * Σ|y i – x i |
куда:
- Σ: греческий символ, означающий «сумма».
- y i : Наблюдаемое значение для i -го наблюдения
- x i : Прогнозируемое значение для i -го наблюдения
- n: общее количество наблюдений
В следующем пошаговом примере показано, как рассчитать среднюю абсолютную ошибку в Excel.
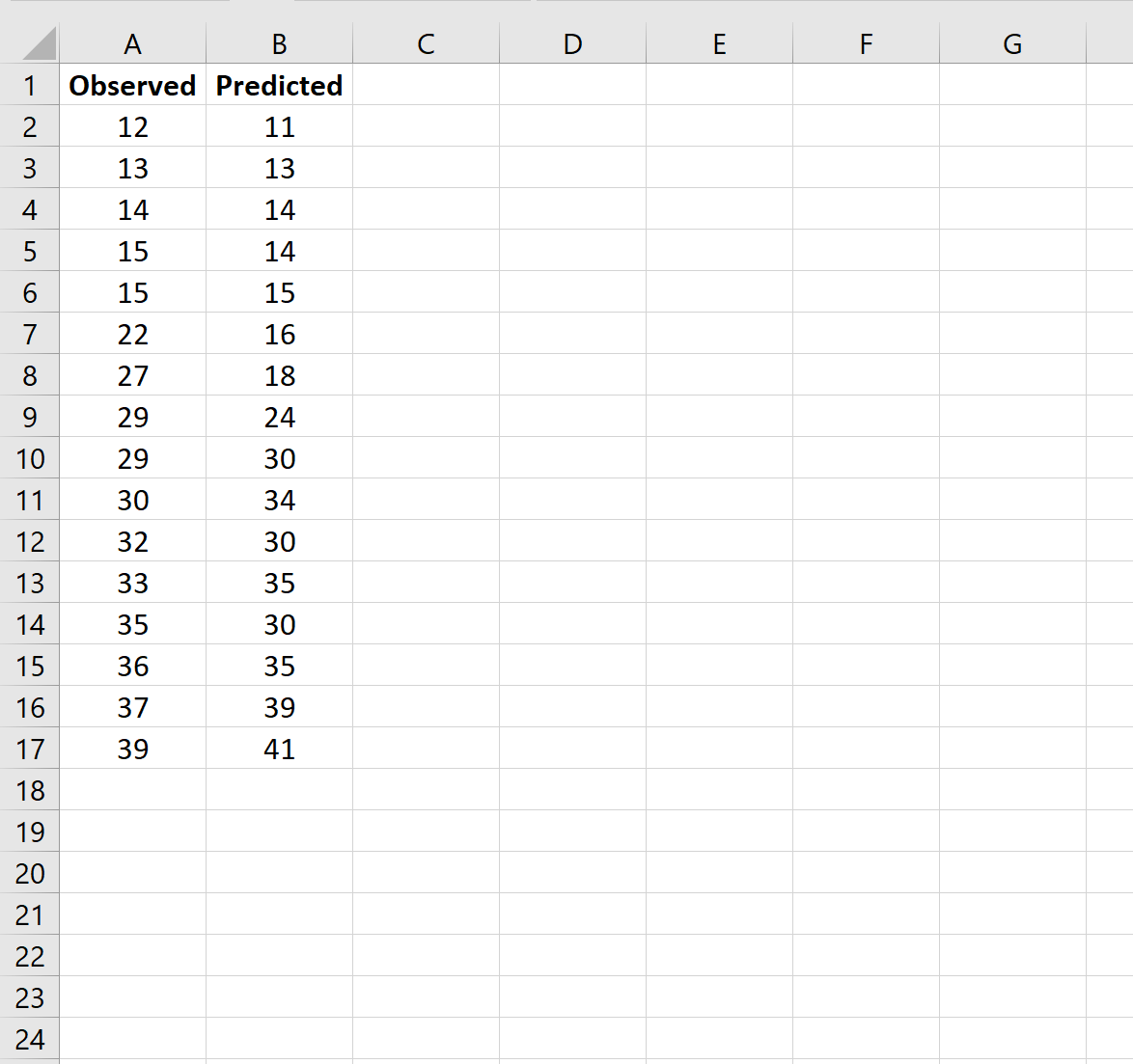
Шаг 1: введите данные
Во-первых, давайте введем список наблюдаемых и прогнозируемых значений в два отдельных столбца:
Примечание. Используйте это руководство , если вам нужно научиться использовать модель регрессии для расчета прогнозируемых значений.
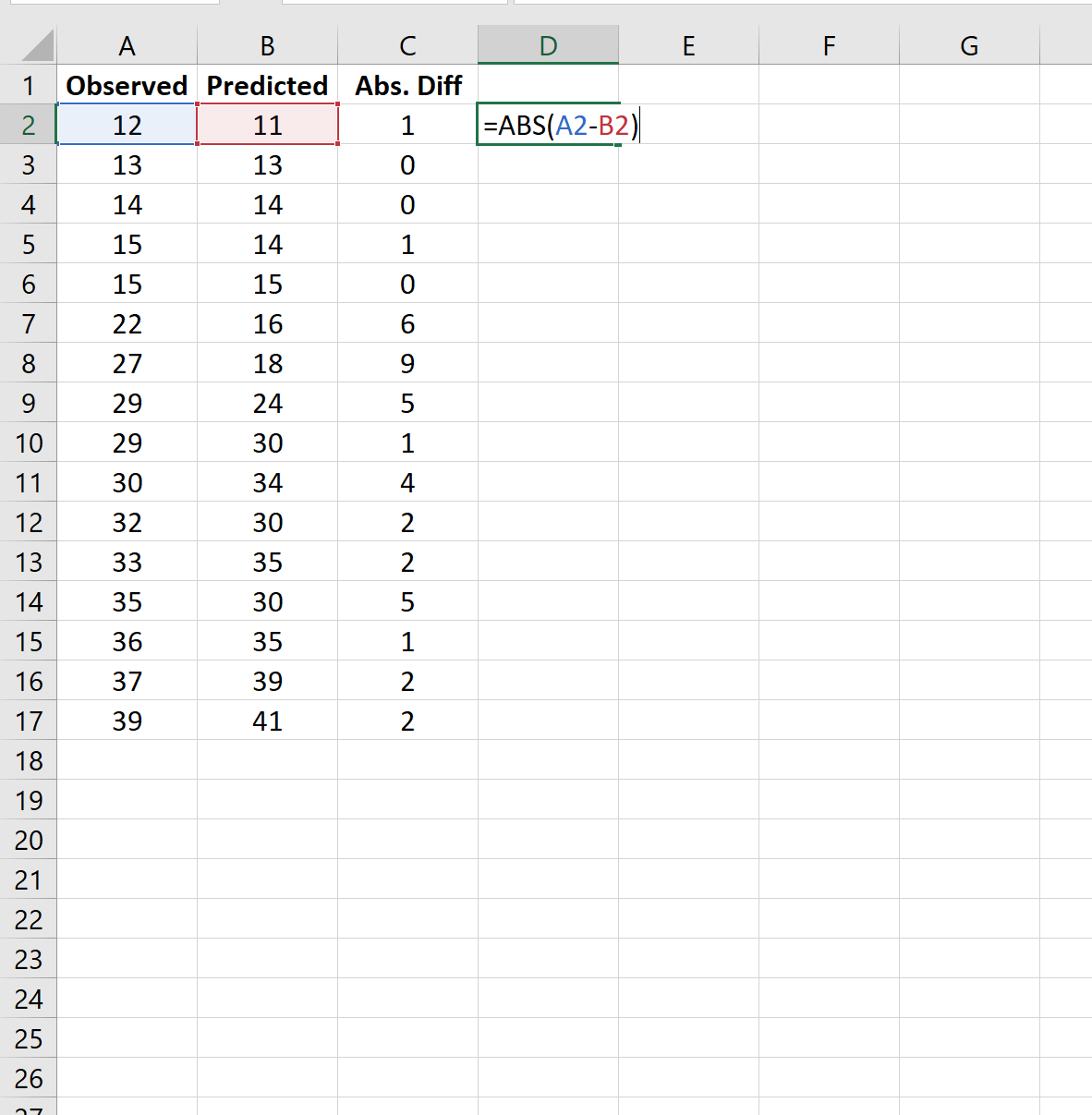
Шаг 2: Рассчитайте абсолютные разницы
Далее мы будем использовать следующую формулу для расчета абсолютных различий между наблюдаемыми и прогнозируемыми значениями:
Шаг 3: Рассчитайте MAE
Далее мы будем использовать следующую формулу для расчета средней абсолютной ошибки:
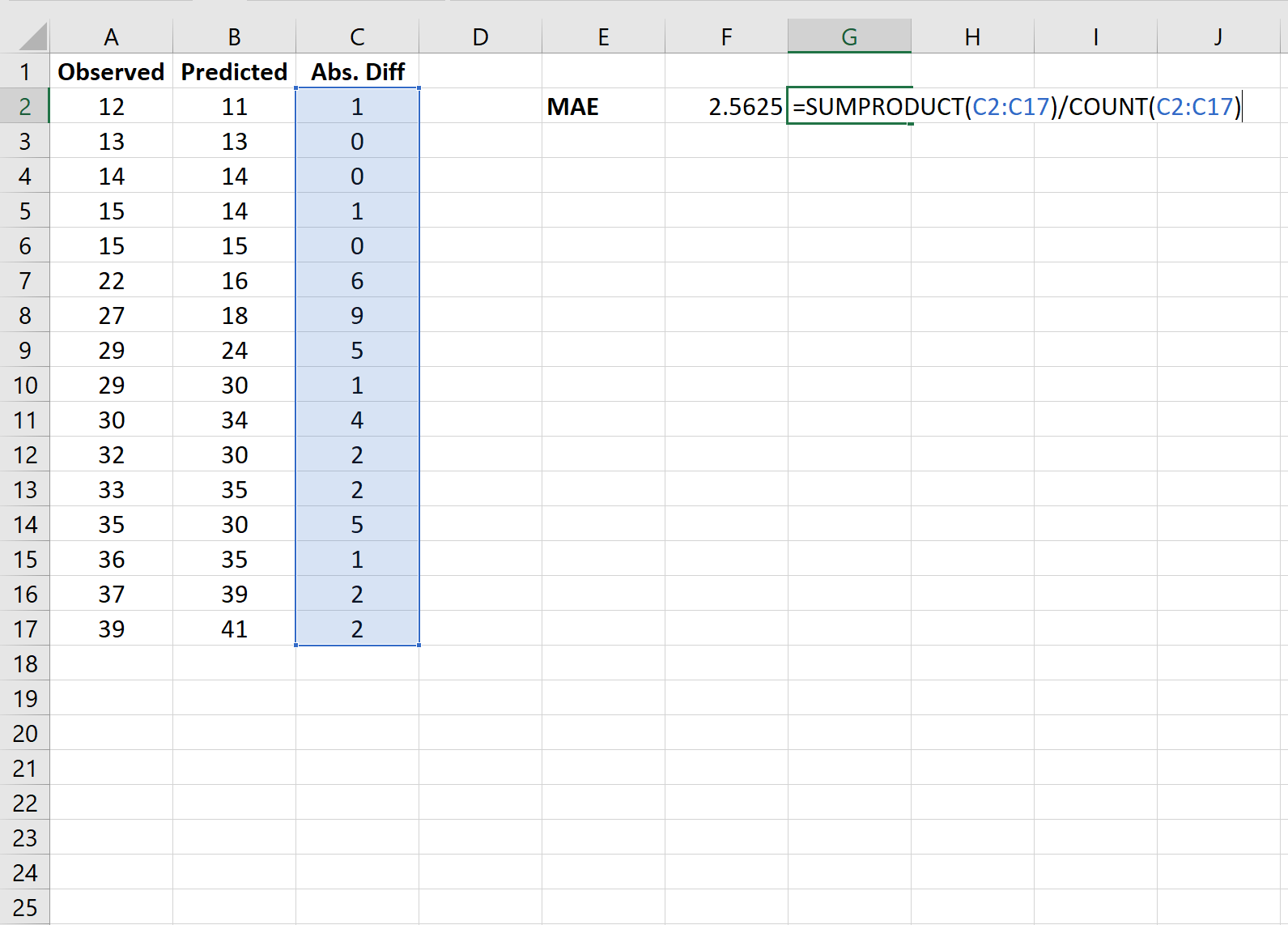
Средняя абсолютная ошибка (MAE) оказывается равной 2,5625 .
Это говорит нам о том, что средняя абсолютная разница между наблюдаемыми значениями и предсказанными значениями составляет 2,5625.
Как правило, чем ниже значение MAE, тем лучше модель соответствует набору данных. При сравнении двух разных моделей мы можем сравнить MAE каждой модели, чтобы узнать, какая из них лучше подходит для набора данных.
Бонус: не стесняйтесь использовать этот Калькулятор средней абсолютной ошибки для автоматического расчета MAE для списка наблюдаемых и прогнозируемых значений.
Дополнительные ресурсы
Как рассчитать MAPE в Excel
Как рассчитать SMAPE в Excel
Написано
![]()
Замечательно! Вы успешно подписались.
Добро пожаловать обратно! Вы успешно вошли
Вы успешно подписались на кодкамп.
Срок действия вашей ссылки истек.
Ура! Проверьте свою электронную почту на наличие волшебной ссылки для входа.
Успех! Ваша платежная информация обновлена.
Ваша платежная информация не была обновлена.
Абсолютная и относительная погрешность

4.2
Средняя оценка: 4.2
Всего получено оценок: 2108.
4.2
Средняя оценка: 4.2
Всего получено оценок: 2108.
Абсолютную и относительную погрешность используют для оценки неточности в производимых расчетах с высокой сложностью. Также они используются в различных измерениях и для округления результатов вычислений. Рассмотрим, как определить абсолютную и относительную погрешность.

Опыт работы учителем математики — более 33 лет.
Абсолютная погрешность
Абсолютной погрешностью числа называют разницу между этим числом и его точным значением.
Рассмотрим пример: в школе учится 374 ученика. Если округлить это число до 400, то абсолютная погрешность измерения равна 400-374=26.
Для подсчета абсолютной погрешности необходимо из большего числа вычитать меньшее.
Существует формула абсолютной погрешности. Обозначим точное число буквой А, а буквой а – приближение к точному числу. Приближенное число – это число, которое незначительно отличается от точного и обычно заменяет его в вычислениях. Тогда формула будет выглядеть следующим образом:
Δа=А-а. Как найти абсолютную погрешность по формуле, мы рассмотрели выше.
На практике абсолютной погрешности недостаточно для точной оценки измерения. Редко когда можно точно знать значение измеряемой величины, чтобы рассчитать абсолютную погрешность. Измеряя книгу в 20 см длиной и допустив погрешность в 1 см, можно считать измерение с большой ошибкой. Но если погрешность в 1 см была допущена при измерении стены в 20 метров, это измерение можно считать максимально точным. Поэтому в практике более важное значение имеет определение относительной погрешности измерения.
Записывают абсолютную погрешность числа, используя знак ±. Например, длина рулона обоев составляет 30 м ± 3 см. Границу абсолютной погрешности называют предельной абсолютной погрешностью.
Относительная погрешность
Относительной погрешностью называют отношение абсолютной погрешности числа к самому этому числу. Чтобы рассчитать относительную погрешность в примере с учениками, разделим 26 на 374.
Получим число 0,0695, переведем в проценты и получим 7 %. Относительную погрешность обозначают процентами, потому что это безразмерная величина. Относительная погрешность – это точная оценка ошибки измерений. Если взять абсолютную погрешность в 1 см при измерении длины отрезков 10 см и 10 м, то относительные погрешности будут соответственно равны 10 % и 0,1 %. Для отрезка длиной в 10 см погрешность в 1 см очень велика, это ошибка в 10 %. А для десятиметрового отрезка 1 см не имеет значения, всего 0,1 %.
Различают систематические и случайные погрешности. Систематической называют ту погрешность, которая остается неизменной при повторных измерениях. Случайная погрешность возникает в результате воздействия на процесс измерения внешних факторов и может изменять свое значение.
Правила подсчета погрешностей
Для номинальной оценки погрешностей существует несколько правил:
- при сложении и вычитании чисел необходимо складывать их абсолютные погрешности;
- при делении и умножении чисел требуется сложить относительные погрешности;
- при возведении в степень относительную погрешность умножают на показатель степени.
Приближенные и точные числа записываются при помощи десятичных дробей. Берется только среднее значение, поскольку точное может быть бесконечно длинным. Чтобы понять, как записывать эти числа, необходимо узнать о верных и сомнительных цифрах.
Верными называются такие цифры, разряд которых превосходит абсолютную погрешность числа. Если же разряд цифры меньше абсолютной погрешности, она называется сомнительной. Например, для дроби 3,6714 с погрешностью 0,002 верными будут цифры 3,6,7, а сомнительными – 1 и 4. В записи приближенного числа оставляют только верные цифры. Дробь в этом случае будет выглядеть таким образом – 3,67.

Что мы узнали?
Абсолютные и относительные погрешности используются для оценки точности измерений. Абсолютной погрешностью называют разницу между точным и приближенным числом. Относительная погрешность – это отношение абсолютной погрешности числа к самому числу. На практике используют относительную погрешность, так как она является более точной.
Тест по теме
Доска почёта
Чтобы попасть сюда — пройдите тест.
-

Светлана Лобанова-Асямолова
10/10
-

Валерий Соломин
10/10
-

Анастасия Юшкова
10/10
-

Ксюша Пономарева
7/10
-

Паша Кривов
10/10
-

Евгений Холопик
9/10
-

Guzel Murtazina
10/10
-

Максим Аполонов
10/10
-

Olga Bimbirene
9/10
-

Света Колодий
10/10
Оценка статьи
4.2
Средняя оценка: 4.2
Всего получено оценок: 2108.
А какая ваша оценка?