Функция потерь (Loss Function, Cost Function, Error Function; J) – фрагмент программного кода, который используется для оптимизации Алгоритма (Algorithm) Машинного обучения (ML). Значение, вычисленное такой функцией, называется «потерей».
Функция (Function) потерь может дать бо́льшую практическую гибкость вашим Нейронным сетям (Neural Network) и будет определять, как именно выходные данные связаны с исходными.
Нейронные сети могут выполнять несколько задач: от прогнозирования непрерывных значений, таких как ежемесячные расходы, до Бинарной классификации (Binary Classification) на кошек и собак. Для каждой отдельной задачи потребуются разные типы функций, поскольку выходной формат индивидуален.
С очень упрощенной точки зрения Loss Function может быть определена как функция, которая принимает два параметра:
- Прогнозируемые выходные данные
- Истинные выходные данные

Эта функция, по сути, вычислит, насколько хорошо работает наша модель, сравнив то, что модель прогнозирует, с фактическим значением, которое она должна выдает. Если Ypred очень далеко от Yi, значение потерь будет очень высоким. Однако, если оба значения почти одинаковы, значение потерь будет очень низким. Следовательно, нам нужно сохранить функцию потерь, которая может эффективно наказывать модель, пока та обучается на Тренировочных данных (Train Data).
Этот сценарий в чем-то аналогичен подготовке к экзаменам. Если кто-то плохо сдает экзамен, мы можем сказать, что потеря очень высока, и этому человеку придется многое изменить внутри себя, чтобы в следующий раз получить лучшую оценку. Однако, если экзамен пройдет хорошо, студент может вести себя подобным образом и в следующий раз.
Теперь давайте рассмотрим классификацию как задачу и поймем, как в этом случае работает функция потерь.
Классификационные потери
Когда нейронная сеть пытается предсказать дискретное значение, мы рассматриваем это как модель классификации. Это может быть сеть, пытающаяся предсказать, какое животное присутствует на изображении, или является ли электронное письмо спамом. Сначала давайте посмотрим, как представлены выходные данные классификационной нейронной сети.

Количество узлов выходного слоя будет зависеть от количества классов, присутствующих в данных. Каждый узел будет представлять один класс. Значение каждого выходного узла по существу представляет вероятность того, что этот класс является правильным.
Как только мы получим вероятности всех различных классов, рассмотрим тот, что имеет наибольшую вероятность. Посмотрим, как выполняется двоичная классификация.
Бинарная классификация
В двоичной классификации на выходном слое будет только один узел. Чтобы получить результат в формате вероятности, нам нужно применить Функцию активации (Activation Function). Поскольку для вероятности требуется значение от 0 до 1, мы будем использовать Сигмоид (Sigmoid), которая приведет любое реальное значение к диапазону значений от 0 до 1.

По мере того, как входные реальные данные становятся больше и стремятся к плюс бесконечности, выходные данные сигмоида будут стремиться к единице. А когда на входе значения становятся меньше и стремятся к отрицательной бесконечности, на выходе числа будут стремиться к нулю. Теперь мы гарантированно получаем значение от 0 до 1, и это именно то, что нам нужно, поскольку нам нужны вероятности.
Если выход выше 0,5 (вероятность 50%), мы будем считать, что он попадает в положительный класс, а если он ниже 0,5, мы будем считать, что он попадает в отрицательный класс. Например, если мы обучаем нейросеть для классификации кошек и собак, мы можем назначить собакам положительный класс, и выходное значение в наборе данных для собак будет равно 1, аналогично кошкам будет назначен отрицательный класс, а выходное значение для кошек будет быть 0.
Функция потерь, которую мы используем для двоичной классификации, называется Двоичной перекрестной энтропией (BCE). Эта функция эффективно наказывает нейронную сеть за Ошибки (Error) двоичной классификации. Давайте посмотрим, как она выглядит.

Как видите, есть две отдельные функции, по одной для каждого значения Y. Когда нам нужно предсказать положительный класс (Y = 1), мы будем использовать следующую формулу:
$$Потеря = -log(Y_{pred})space{,}space{где}$$
$$Jspace{}{–}space{Потеря,}$$
$$Y_predspace{}{–}space{Предсказанные}space{значения}$$
И когда нам нужно предсказать отрицательный класс (Y = 0), мы будем использовать немного трансформированный аналог:
$$Потеря = -log(1 — Y_{pred})space{,}space{где}$$
$$Jspace{}{–}space{Потеря,}$$
$$Y_predspace{}{–}space{Предсказанные}space{значения}$$
Для первой функции, когда Ypred равно 1, потеря равна 0, что имеет смысл, потому что Ypred точно такое же, как Y. Когда значение Ypred становится ближе к 0, мы можем наблюдать, как значение потери сильно увеличивается. Когда же Ypred становится равным 0, потеря стремится к бесконечности. Это происходит, потому что с точки зрения классификации, 0 и 1 – полярные противоположности: каждый из них представляет совершенно разные классы. Поэтому, когда Ypred равно 0, а Y равно 1, потери должны быть очень высокими, чтобы сеть могла более эффективно распознавать свои ошибки.

Полиномиальная классификация
Полиномиальная классификация (Multiclass Classification) подходит, когда нам нужно, чтобы наша модель каждый раз предсказывала один возможный класс. Теперь, поскольку мы все еще имеем дело с вероятностями, имеет смысл просто применить сигмоид ко всем выходным узлам, чтобы мы получали значения от 0 до 1 для всех выходных значений, но здесь кроется проблема. Когда мы рассматриваем вероятности для нескольких классов, нам необходимо убедиться, что сумма всех индивидуальных вероятностей равна единице, поскольку именно так определяется вероятность. Применение сигмоида не гарантирует, что сумма всегда равна единице, поэтому нам нужно использовать другую функцию активации.
В данном случае мы используем функцию активации Softmax. Эта функция гарантирует, что все выходные узлы имеют значения от 0 до 1, а сумма всех значений выходных узлов всегда равна 1. Вычисляется с помощью формулы:
$$Softmax(y_i) = frac{e^{y_i}}{sum_{i = 0}^n e^{y_i}}space{,}space{где}$$
$$y_ispace{}{–}space{i-e}space{наблюдение}$$
Пример:

Как видите, мы просто передаем все значения в экспоненциальную функцию. После этого, чтобы убедиться, что все они находятся в диапазоне от 0 до 1 и сумма всех выходных значений равна 1, мы просто делим каждую экспоненту на сумму экспонент.
Итак, почему мы должны передавать каждое значение через экспоненту перед их нормализацией? Почему мы не можем просто нормализовать сами значения? Это связано с тем, что цель Softmax – убедиться, что одно значение очень высокое (близко к 1), а все остальные значения очень низкие (близко к 0). Softmax использует экспоненту, чтобы убедиться, что это произойдет. А затем мы нормализуем результат, потому что нам нужны вероятности.
Теперь, когда наши выходные данные имеют правильный формат, давайте посмотрим, как мы настраиваем для этого функцию потерь. Хорошо то, что функция потерь по сути такая же, как у двоичной классификации. Мы просто применим Логарифмическую потерю (Log Loss) к каждому выходному узлу по отношению к его соответствующему целевому значению, а затем найдем сумму этих значений по всем выходным узлам.

Эта потеря называется категориальной Кросс-энтропией (Cross Entropy). Теперь перейдем к частному случаю классификации, называемому многозначной классификацией.
Классификация по нескольким меткам
Классификация по нескольким меткам (MLC) выполняется, когда нашей модели необходимо предсказать несколько классов в качестве выходных данных. Например, мы тренируем нейронную сеть, чтобы предсказывать ингредиенты, присутствующие на изображении какой-то еды. Нам нужно будет предсказать несколько ингредиентов, поэтому в Y будет несколько единиц.
Для этого мы не можем использовать Softmax, потому что он всегда заставляет только один класс «становиться единицей», а другие классы приводит к нулю. Вместо этого мы можем просто сохранить сигмоид на всех значениях выходных узлов, поскольку пытаемся предсказать индивидуальную вероятность каждого класса.
Что касается потерь, мы можем напрямую использовать логарифмические потери на каждом узле и суммировать их, аналогично тому, что мы делали в мультиклассовой классификации.
Теперь, когда мы рассмотрели классификацию, перейдем к регрессии.
Потеря регрессии
В Регрессии (Regression) наша модель пытается предсказать непрерывное значение, например, цены на жилье или возраст человека. Наша нейронная сеть будет иметь один выходной узел для каждого непрерывного значения, которое мы пытаемся предсказать. Потери регрессии рассчитываются путем прямого сравнения выходного и истинного значения.
Самая популярная функция потерь, которую мы используем для регрессионных моделей, – это Среднеквадратическая ошибка (MSE). Здесь мы просто вычисляем квадрат разницы между Y и YPred и усредняем полученное значение.
Автор оригинальной статьи: deeplearningdemystified.com
Фото: @leni_eleni
 Здравствуйте, коллеги! Это блог открытой русскоговорящей дата саентологической ложи. Нас уже легион, точнее 2500+ человек в слаке. За полтора года мы нагенерили 800к+ сообщений (ради этого слак выделил нам корпоративный аккаунт). Наши люди есть везде и, может, даже в вашей организации. Если вы интересуетесь машинным обучением, но по каким-то причинам не знаете про Open Data Science, то возможно вы в курсе мероприятий, которые организовывает сообщество. Самым масштабным из них является DataFest, который проходил недавно в офисе Mail.Ru Group, за два дня его посетило 1700 человек. Мы растем, наши ложи открываются в городах России, а также в Нью-Йорке, Дубае и даже во Львове, да, мы не воюем, а иногда даже и употребляем горячительные напитки вместе. И да, мы некоммерческая организация, наша цель — просвещение. Мы делаем все ради искусства. (пс: на фотографии вы можете наблюдать заседание ложи в одном из тайных храмов в Москве).
Здравствуйте, коллеги! Это блог открытой русскоговорящей дата саентологической ложи. Нас уже легион, точнее 2500+ человек в слаке. За полтора года мы нагенерили 800к+ сообщений (ради этого слак выделил нам корпоративный аккаунт). Наши люди есть везде и, может, даже в вашей организации. Если вы интересуетесь машинным обучением, но по каким-то причинам не знаете про Open Data Science, то возможно вы в курсе мероприятий, которые организовывает сообщество. Самым масштабным из них является DataFest, который проходил недавно в офисе Mail.Ru Group, за два дня его посетило 1700 человек. Мы растем, наши ложи открываются в городах России, а также в Нью-Йорке, Дубае и даже во Львове, да, мы не воюем, а иногда даже и употребляем горячительные напитки вместе. И да, мы некоммерческая организация, наша цель — просвещение. Мы делаем все ради искусства. (пс: на фотографии вы можете наблюдать заседание ложи в одном из тайных храмов в Москве).
Мне выпала честь сделать первый пост, и я, пожалуй, отклонюсь от своей привычной нейросетевой тематики и сделаю пост о базовых понятиях машинного обучения на примере одной из самых простых и самых полезных моделей — линейной регрессии. Я буду использовать язык питон для демонстрации экспериментов и отрисовки графиков, все это вы с легкостью сможете повторить на своем компьютере. Поехали.
Формализмы
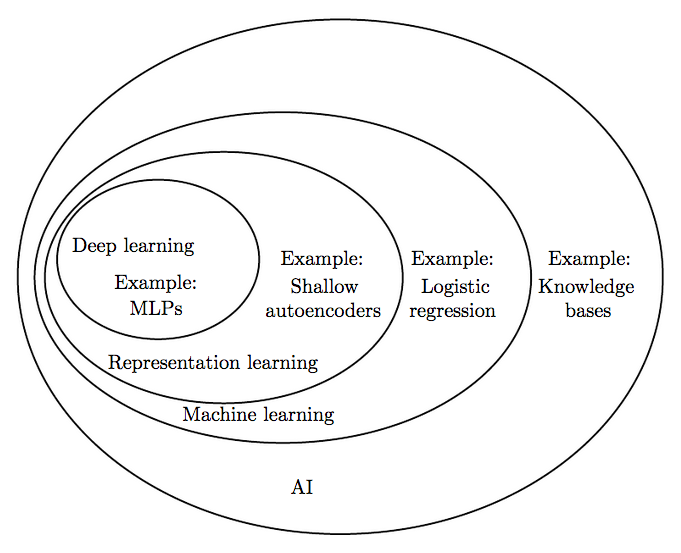
Машинное обучение — это подраздел искусственного интеллекта, в котором изучаются алгоритмы, способные обучаться без прямого программирования того, что нужно изучать. Линейная регрессия является типичным представителем алгоритмов машинного обучения. Для начала ответим на вопрос «а что вообще значит обучаться?». Ответ на этот вопрос мы возьмем из книги 1997 года (стоит отметить, что оглавление этой книги не сильно отличается от современных книг по машинному обучению).
Говорят, что программа обучается на опыте
относительно класса задач
в смысле меры качества
, если при решении задачи
Можно выделить следующие задачи , решаемые машинным обучением: обучение с учителем, обучение без учителя, обучение с подкреплением, активное обучение, трансфер знаний и т.д. Регрессия (как и классификация) относится к классу задач обучения с учителем, когда по заданному набору признаков наблюдаемого объекта необходимо спрогнозировать некоторую целевую переменную. Как правило, в задачах обучения с учителем, опыт представляется в виде множества пар признаков и целевых переменных:  . В случае линейной регрессии признаковое описание объекта — это действительный вектор
. В случае линейной регрессии признаковое описание объекта — это действительный вектор  , а целевая переменная — это скаляр
, а целевая переменная — это скаляр  . Самой простой мерой качества для задачи регрессии является
. Самой простой мерой качества для задачи регрессии является  , где
, где  — это наша оценка реального значения целевой переменной.
— это наша оценка реального значения целевой переменной.
У нас есть задача, данные и способ оценки программы/модели. Давайте определим, что такое модель, и что значит обучить модель. Предиктивная модель – это параметрическое семейство функций (семейство гипотез):

где
Таким образом, из большого семейства гипотез мы должны выбрать какую-то одну конкретную, которая с точки зрения меры является лучшей. Процесс такого выбора назовем алгоритмом обучения:

Получается, что алгоритм обучения — это отображение из набора данных в пространство гипотез. Обычно процесс обучения с учителем состоит из двух шагов:
- обучение:
 ;
; - применение:
 .
.
Часто для обучения модели пользуются принципом минимизации эмпирического риска. Риском гипотезы  называют ожидаемое значение функции стоимости :
называют ожидаемое значение функции стоимости :
![$Large begin{array}{rcl}Qleft(hright) &=& text{E}_{x, y sim Pleft(x, yright)}left[Lleft(hleft(xright), yright)right] \ &=& int Lleft(hleft(xright), yright) d Pleft(x, yright) end{array}$](https://habrastorage.org/getpro/habr/formulas/7bf/4e5/4d2/7bf4e54d2fec308d12eb64fc98c743b0.svg)
Но, к сожалению, такой интеграл не посчитать, т.к. распределение  неизвестно, иначе и задачи не было бы. Но мы можем посчитать эмпирическую оценку риска, как среднее значение функции стоимости:
неизвестно, иначе и задачи не было бы. Но мы можем посчитать эмпирическую оценку риска, как среднее значение функции стоимости:

Тогда, согласно принципу минимизации эмпирического риска, мы должны выбрать такую гипотезу  , которая минимизирует
, которая минимизирует  :
:

У данного принципа есть существенный недостаток, решения найденные таким путем будут склонны к переобучению. Мы говорим, что модель обладает обобщающей способностью, тогда, когда ошибка на новом (тестовом) наборе данных (взятом из того же распределения ) мала, или же предсказуема. Переобученная модель не обладает обобщающей способностью, т.е. на обучающем наборе данных ошибка мала, а на тестовом наборе данных ошибка существенно больше.
Линейная регрессия
Давайте ограничим пространство гипотез только линейными функциями от  аргумента, будем считать, что нулевой признак для всех объектов равен единице
аргумента, будем считать, что нулевой признак для всех объектов равен единице  :
:

Эмпирический риск (функция стоимости) принимает форму среднеквадратичной ошибки:

строки матрицы  — это признаковые описания наблюдаемых объектов. Один из алгоритмов обучения
— это признаковые описания наблюдаемых объектов. Один из алгоритмов обучения  такой модели — это метод наименьших квадратов. Вычислим производную функции стоимости:
такой модели — это метод наименьших квадратов. Вычислим производную функции стоимости:

приравняем к нулю и найдем решение в явном виде:

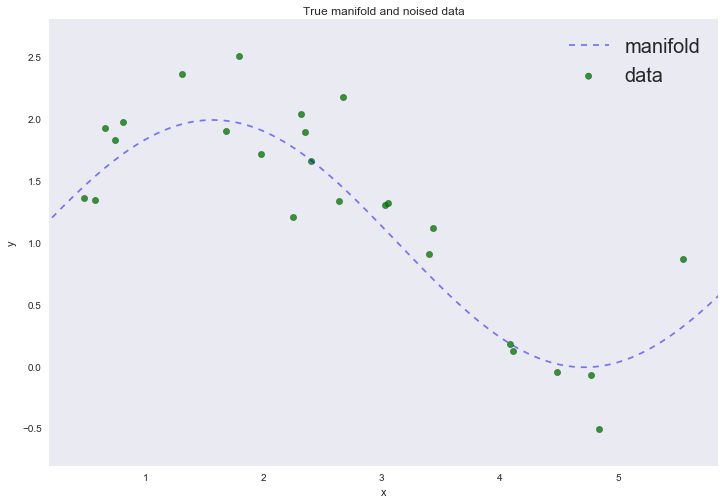
Поздравляю, дамы и господа, мы только что с вами вывели алгоритм машинного обучения. Реализуем же этот алгоритм. Начнем с датасета, состоящего всего из одного признака. Будем брать случайную точку на синусе и добавлять к ней шум — таким образом получим целевую переменную; признаком в этом случае будет координата  :
:
def generate_wave_set(n_support=1000, n_train=25, std=0.3):
data = {}
# выберем некоторое количество точек из промежутка от 0 до 2*pi
data['support'] = np.linspace(0, 2*np.pi, num=n_support)
# для каждой посчитаем значение sin(x) + 1
# это будет ground truth
data['values'] = np.sin(data['support']) + 1
# из support посемплируем некоторое количество точек с возвратом, это будут признаки
data['x_train'] = np.sort(np.random.choice(data['support'], size=n_train, replace=True))
# опять посчитаем sin(x) + 1 и добавим шум, получим целевую переменную
data['y_train'] = np.sin(data['x_train']) + 1 + np.random.normal(0, std, size=data['x_train'].shape[0])
return data
data = generate_wave_set(1000, 250)
Отрисовка графика
print 'Shape of X is', data['x_train'].shape
print 'Head of X is', data['x_train'][:10]
margin = 0.3
plt.plot(data['support'], data['values'], 'b--', alpha=0.5, label='manifold')
plt.scatter(data['x_train'], data['y_train'], 40, 'g', 'o', alpha=0.8, label='data')
plt.xlim(data['x_train'].min() - margin, data['x_train'].max() + margin)
plt.ylim(data['y_train'].min() - margin, data['y_train'].max() + margin)
plt.legend(loc='upper right', prop={'size': 20})
plt.title('True manifold and noised data')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
А теперь реализуем алгоритм обучения, используя магию NumPy:
# добавим колонку единиц к единственному столбцу признаков
X = np.array([np.ones(data['x_train'].shape[0]), data['x_train']]).T
# перепишем, полученную выше формулу, используя numpy
# шаг обучения - в этом шаге мы ищем лучшую гипотезу h
w = np.dot(np.dot(np.linalg.inv(np.dot(X.T, X)), X.T), data['y_train'])
# шаг применения: посчитаем прогноз
y_hat = np.dot(w, X.T)
Отрисовка графика
margin = 0.3
plt.plot(data['support'], data['values'], 'b--', alpha=0.5, label='manifold')
plt.scatter(data['x_train'], data['y_train'], 40, 'g', 'o', alpha=0.8, label='data')
plt.plot(data['x_train'], y_hat, 'r', alpha=0.8, label='fitted')
plt.xlim(data['x_train'].min() - margin, data['x_train'].max() + margin)
plt.ylim(data['y_train'].min() - margin, data['y_train'].max() + margin)
plt.legend(loc='upper right', prop={'size': 20})
plt.title('Fitted linear regression')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
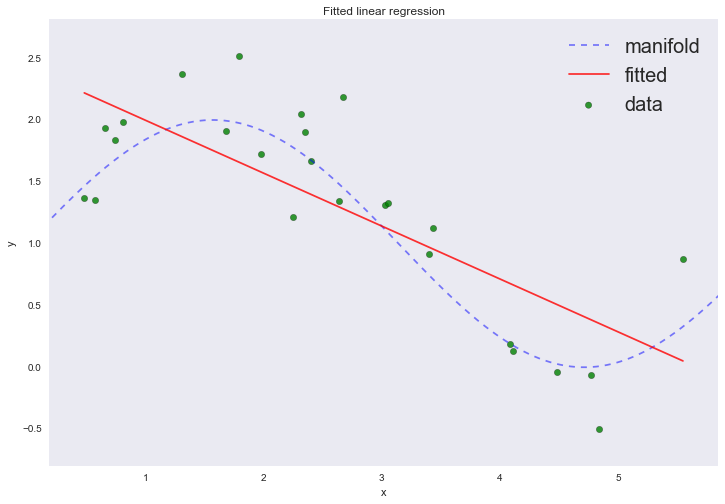
Как мы видим, линия не очень-то совпадает с настоящей кривой. Среднеквадратичная ошибка равна 0.26704 условных единиц. Очевидно, что если бы вместо линии мы использовали кривую третьего порядка, то результат был бы куда лучше. И, на самом деле, с помощью линейной регрессии мы можем обучать нелинейные модели.
Полиномиальная регрессия
В линейной регрессии мы ограничивали пространство гипотез только линейными функциями от признаков. Давайте теперь расширим пространство гипотез до всех полиномов степени  . Тогда в нашем случае, когда количество признаков равно одному
. Тогда в нашем случае, когда количество признаков равно одному  , пространство гипотез будет выглядеть следующим образом:
, пространство гипотез будет выглядеть следующим образом:

Если заранее предрассчитать все степени признаков, то задача опять сводится к описанному выше алгоритму — методу наименьших квадратов. Попробуем отрисовать графики нескольких полиномов разных степеней.
# список степеней p полиномов, который мы протестируем
degree_list = [1, 2, 3, 5, 7, 10, 13]
cmap = plt.get_cmap('jet')
colors = [cmap(i) for i in np.linspace(0, 1, len(degree_list))]
margin = 0.3
plt.plot(data['support'], data['values'], 'b--', alpha=0.5, label='manifold')
plt.scatter(data['x_train'], data['y_train'], 40, 'g', 'o', alpha=0.8, label='data')
w_list = []
err = []
for ix, degree in enumerate(degree_list):
# список с предрасчитанными степенями признака
dlist = [np.ones(data['x_train'].shape[0])] +
map(lambda n: data['x_train']**n, range(1, degree + 1))
X = np.array(dlist).T
w = np.dot(np.dot(np.linalg.inv(np.dot(X.T, X)), X.T), data['y_train'])
w_list.append((degree, w))
y_hat = np.dot(w, X.T)
err.append(np.mean((data['y_train'] - y_hat)**2))
plt.plot(data['x_train'], y_hat, color=colors[ix], label='poly degree: %i' % degree)
Отрисовка графика
plt.xlim(data['x_train'].min() - margin, data['x_train'].max() + margin)
plt.ylim(data['y_train'].min() - margin, data['y_train'].max() + margin)
plt.legend(loc='upper right', prop={'size': 20})
plt.title('Fitted polynomial regressions')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
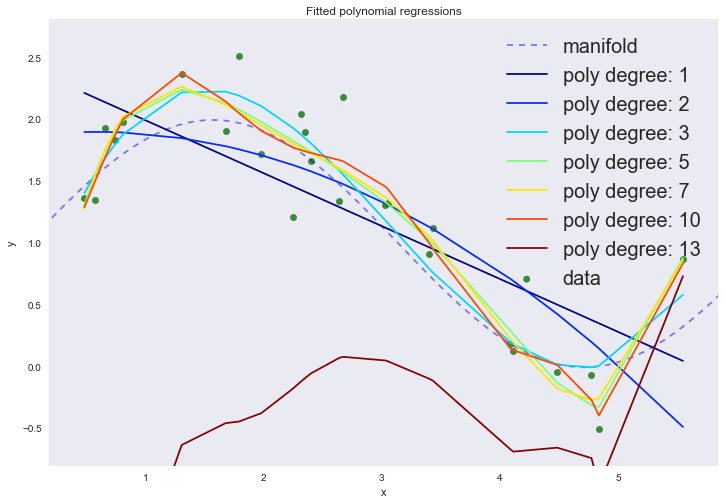
На графике мы можем наблюдать сразу два феномена. Пока не обращайте внимание на 13-ую степень полинома. При увеличении степени полинома, средняя ошибка продолжает уменьшаться, хотя мы вроде были уверены, что именно кубический полином должен лучше всего описывать наши данные.
| p | error |
|---|---|
| 1 | 0.26704 |
| 2 | 0.22495 |
| 3 | 0.08217 |
| 5 | 0.05862 |
| 7 | 0.05749 |
| 10 | 0.0532 |
| 13 | 5.76155 |
Это явный признак переобучения, который можно заметить по визуализации даже не используя тестовый набор данных: при увеличении степени полинома выше третьей модель начинает интерполировать данные, вместо экстраполяции. Другими словами, график функции проходит точно через точки из тренировочного набора данных, причем чем выше степень полинома, тем через большее количество точек он проходит. Степень полинома отражает сложность модели. Таким образом, сложные модели, у которых степеней свободы достаточно много, могут попросту запомнить весь тренировочный набор, полностью теряя обобщающую способность. Это и есть проявление негативной стороны принципа минимизации эмпирического риска.
Вернемся к полиному 13-ой степени, с ним явно что-то не так. По идее, мы ожидаем, что полином 13-ой степени будет описывать тренировочный набор данных еще лучше, но результат показывает, что это не так. Из курса линейной алгебры мы помним, что обратная матрица существует только для несингулярных матриц, т.е. тех, у которых нет линейной зависимости колонок или строк. В методе наименьших квадратов нам необходимо инвертировать следующую матрицу:  . Для тестирования на линейную зависимость или мультиколлинеарность можно использовать число обусловленности матрицы. Один из способов оценки этого числа для матриц — это отношение модуля максимального собственного числа матрицы к модулю минимального собственного числа. Большое число обусловленности матрицы, или же наличие одного или нескольких собственных чисел близких к нулю свидетельствует о наличии мультиколлинеарности (или нечеткой мультиколлиниарности, когда
. Для тестирования на линейную зависимость или мультиколлинеарность можно использовать число обусловленности матрицы. Один из способов оценки этого числа для матриц — это отношение модуля максимального собственного числа матрицы к модулю минимального собственного числа. Большое число обусловленности матрицы, или же наличие одного или нескольких собственных чисел близких к нулю свидетельствует о наличии мультиколлинеарности (или нечеткой мультиколлиниарности, когда  ). Такие матрицы называются слабо обусловленными, а задача — некорректно поставленной. При инвертировании такой матрицы, решения имеют большую дисперсию. Это проявляется в том, что при небольшом изменении начальной матрицы, инвертированные будут сильно отличаться друг от друга. На практике это всплывет тогда, когда к 1000 семплов, вы добавите всего один, а решение МНК будет совсем другим. Посмотрим на собственные числа полученной матрицы, нас там ждет сюрприз:
). Такие матрицы называются слабо обусловленными, а задача — некорректно поставленной. При инвертировании такой матрицы, решения имеют большую дисперсию. Это проявляется в том, что при небольшом изменении начальной матрицы, инвертированные будут сильно отличаться друг от друга. На практике это всплывет тогда, когда к 1000 семплов, вы добавите всего один, а решение МНК будет совсем другим. Посмотрим на собственные числа полученной матрицы, нас там ждет сюрприз:
np.linalg.eigvals(np.cov(X[:, 1:].T))
Out[10]:
array([
9.29965299e+17+0.j , 4.04567033e+13+0.j ,
5.44657111e+09+0.j , 3.54104756e+06+0.j ,
8.36745166e+03+0.j , 6.82745279e+01+0.j ,
8.88434986e-01+0.j , 2.42827315e-02+0.00830052j,
2.42827315e-02-0.00830052j, 1.17621840e-03+0.j ,
1.72254789e-04+0.j , -5.68384880e-06+0.j ,
2.39611454e-07+0.j ])

Все так, numpy вернул два комплекснозначных собственных значения, что идет вразрез с теорией. Для симметричных и положительно определенных матриц (каковой и является матрица  ) все собственные значения должны быть действительные. Возможно, это произошло из-за того, что при работе с большими числами матрица стала слегка несимметричной, но это не точно ¯_(ツ)_/¯. Если вы вдруг найдете причину такого поведения нумпая, пожалуйста, напишите в комменте.
) все собственные значения должны быть действительные. Возможно, это произошло из-за того, что при работе с большими числами матрица стала слегка несимметричной, но это не точно ¯_(ツ)_/¯. Если вы вдруг найдете причину такого поведения нумпая, пожалуйста, напишите в комменте.
UPDATE (один из членов ложи по имени Андрей Оськин, с ником в слаке skoffer, без аккаунта на хабре, подсказывает):
Есть только одно замечание — не надо пользоваться формулой `(X^T X^{-1}) X^T` для вычисления коэффициентов линейной регрессии. Проблема с расходящимися значениями хорошо известна и на практике используют `QR` или `SVD`.
Ну, то есть вот такой кусок кода даст вполне приличный результат:
degree = 13 dlist = [np.ones(data['x_train'].shape[0])] + list(map(lambda n: data['x_train']**n, range(1, degree + 1))) X = np.array(dlist).T q, r = np.linalg.qr(X) y_hat = np.dot(np.dot(q, q.T), data['y_train']) plt.plot(data['x_train'], y_hat, label='poly degree: %i' % degree)
Перед тем как перейти к следующему разделу, давайте посмотрим на амплитуду параметров полиномиальной регрессии. Мы увидим, что при увеличении степени полинома, размах значений коэффициентов растет чуть ли не экспоненциально. Да, они еще и скачут в разные стороны.
Визуализация коэффициентов
 Регуляризация
Регуляризация
Регуляризация — это способ уменьшить сложность модели чтобы предотвратить переобучение или исправить некорректно поставленную задачу. Обычно это достигается добавлением некоторой априорной информации к условию задачи. Например так:

На графиках мы увидели, что амплитуда значений коэффициентов слишком большая, попробуем ее уменьшить, добавив ограничение на норму вектора параметров.

Новая функция стоимости примет вид:

Вычислим производную по параметрам:

И найдем решение в явном виде:

- — единичная диагональна матрица
Такая регрессия называется гребневой регрессией (ridge regression). А гребнем является как раз диагональная матрица которую мы прибавляем к матрице с линейнозависимыми колонками, в результате получаемая матрица не сингулярна.

Для такой матрицы число обусловленности будет равно:  , где
, где  — это собственные числа матрицы. Таким образом, увеличивая параметр регуляризации мы уменьшаем число обусловленности, а обусловленность задачи улучшается.
— это собственные числа матрицы. Таким образом, увеличивая параметр регуляризации мы уменьшаем число обусловленности, а обусловленность задачи улучшается.
# define regularization parameter
lmbd = 0.1
degree_list = [1, 2, 3, 10, 12, 13]
cmap = plt.get_cmap('jet')
colors = [cmap(i) for i in np.linspace(0, 1, len(degree_list))]
margin = 0.3
plt.plot(data['support'], data['values'], 'b--', alpha=0.5, label='manifold')
plt.scatter(data['x_train'], data['y_train'], 40, 'g', 'o', alpha=0.8, label='data')
w_list_l2 = []
err = []
for ix, degree in enumerate(degree_list):
dlist = [[1]*data['x_train'].shape[0]] + map(lambda n: data['x_train']**n, range(1, degree + 1))
X = np.array(dlist).T
w = np.dot(np.dot(np.linalg.inv(np.dot(X.T, X) + lmbd*np.eye(X.shape[1])), X.T), data['y_train'])
w_list_l2.append((degree, w))
y_hat = np.dot(w, X.T)
plt.plot(data['x_train'], y_hat, color=colors[ix], label='poly degree: %i' % degree)
err.append(np.mean((data['y_train'] - y_hat)**2))
Отрисовка графика
plt.xlim(data['x_train'].min() - margin, data['x_train'].max() + margin)
plt.ylim(data['y_train'].min() - margin, data['y_train'].max() + margin)
plt.legend(loc='upper right', prop={'size': 20})
plt.title('Fitted polynomial regressions with L2 reg')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
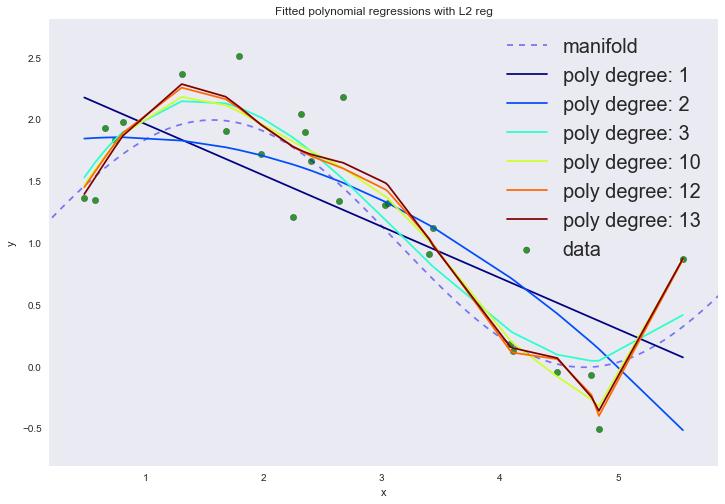
| p | error |
|---|---|
| 1 | 0.26748 |
| 2 | 0.22546 |
| 3 | 0.08803 |
| 10 | 0.05833 |
| 12 | 0.05585 |
| 13 | 0.05638 |
В результате даже 13-ая степень ведет себя так, как мы ожидаем. Графики немного сгладились, хотя мы все равно наблюдаем небольшое переобучение на степенях выше третьей, что выражается в интерполяции данных в правой части графика.
Визуализация коэффициентов
Амплитуда коэффициентов также изменилась, хотя скакать в разные стороны они не перестали. Мы помним, что полином третьей степени должен лучше всего описывать наши данные, хотелось бы, чтобы в результате регуляризации все коэффициенты при полиномиальных признаках степени выше третьей были равны нулю. И, оказывается, есть и такой регуляризатор.
 регуляризация
регуляризация
Попробуем теперь ограничить вектор параметров модели, используя норму:

Тогда задача примет вид:

Посчитаем производную по параметрам модели (надеюсь уважаемые господа не будут пинать меня, за то, что я вжух и взял производную по модулю):

К сожалению, такая задача не имеет решения в явном виде. Для поиска хорошего приближенного решения мы воспользуемся методом градиентного спуска, тогда формула обновления весов примет вид:

а в задаче появляется еще один гиперпараметр  , отвечающий за скорость спуска, его в машинном обучении называют скоростью обучения (learning rate).
, отвечающий за скорость спуска, его в машинном обучении называют скоростью обучения (learning rate).
Запрограммировать такой алгоритм не составит труда, но нас ждет еще один сюрприз:
lmbd = 1
degree = 13
dlist = [[1]*data['x_train'].shape[0]] + map(lambda n: data['x_train']**n, range(1, degree + 1))
X = np.array(dlist).T
# функция для вычисления среднеквадратичное ошибки
def mse(u, v):
return ((u - v)**2).sum()/u.shape[0]
# начальное приближение
w = np.array([-1.0] * X.shape[1])
# максимальное количество итераций
n_iter = 20
# сделаем скорость обучения очень маленькой, на всякий случай
lr = 0.00000001
loss = []
for ix in range(n_iter):
w -= lr*(np.dot(np.dot(X, w) - data['y_train'], X)/X.shape[0] + lmbd*np.sign(w))
y_hat = np.dot(X, w)
loss.append(mse(data['y_train'], y_hat))
print loss[-1]
Получим такую вот эволюцию ошибки:
1.3051230958e+38
1.21979102398e+58
1.14003816725e+78
1.06549974318e+98
9.95834819687e+117
9.30724755635e+137
8.69871743413e+157
8.12997446782e+177
7.59841727794e+197
7.10161456943e+217
6.63729401109e+237
6.20333184222e+257
5.79774315864e+277
5.41867283397e+297
inf
inf
inf
inf
inf
inf
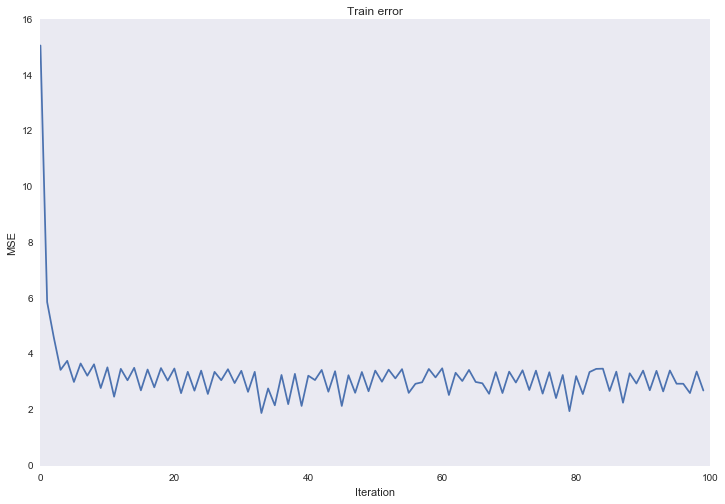
Даже при такой небольшой скорости обучения, ошибка все равно растет и очень даже стремительно. Причина в том, что каждый признак измеряется в разных масштабах, от небольших чисел у полиномиальных признаков 1-2 степени, до огромных при 12-13 степени. Для того чтобы итеративный процесс сошелся, необходимо либо выбрать экстремально мелкую скорость обучения, либо каким-то образом нормализовать признаки. Применим следующее преобразование к признакам и попробуем запустить процесс еще раз:


Такое преобразование называется стандартизацией, распределение каждого признака теперь имеет нулевое матожидание и единичную дисперсию.
lmbd = 1
degree = 13
dlist = [[1]*data['x_train'].shape[0]] + map(lambda n: data['x_train']**n, range(1, degree + 1))
X = np.array(dlist).T
# вычислим выборочное среднее каждого признака
x_mean = X.mean(axis=0)
# вычислим выборочное стандартное отклонение признаков
x_std = X.std(axis=0)
# применим преобразование
X = (X - x_mean)/x_std
X[:, 0] = 1.0
w = np.array([-1.0] * X.shape[1])
n_iter = 100
lr = 0.1
loss = []
for ix in range(n_iter):
w -= lr*(np.dot(np.dot(X, w) - data['y_train'], X)/X.shape[0] + lmbd*np.sign(w))
y_hat = np.dot(X, w)
loss.append(mse(data['y_train'], y_hat))
plt.plot(loss)
plt.title('Train error')
plt.xlabel('Iteration')
plt.ylabel('MSE')
plt.show()
Все стало сильно лучше.
Нарисуем теперь все графики:
degree_list = [1, 2, 3, 10, 12, 13]
cmap = plt.get_cmap('jet')
colors = [cmap(i) for i in np.linspace(0, 1, len(degree_list))]
margin = 0.3
plt.plot(data['support'], data['values'], 'b--', alpha=0.5, label='manifold')
plt.scatter(data['x_train'], data['y_train'], 40, 'g', 'o', alpha=0.8, label='data')
def mse(u, v):
return ((u - v)**2).sum()/u.shape[0]
def fit_lr_l1(X, y, lmbd, n_iter=100, lr=0.1):
w = np.array([-1.0] * X.shape[1])
loss = []
for ix_iter in range(n_iter):
w -= lr*(np.dot(np.dot(X, w) - y, X)/X.shape[0] +lmbd*np.sign(w))
y_hat = np.dot(X, w)
loss.append(mse(y, y_hat))
return w, y_hat, loss
w_list_l1 = []
for ix, degree in enumerate(degree_list):
dlist = [[1]*data['x_train'].shape[0]] + map(lambda n: data['x_train']**n, range(1, degree + 1))
X = np.array(dlist).T
x_mean = X.mean(axis=0)
x_std = X.std(axis=0)
X = (X - x_mean)/x_std
X[:, 0] = 1.0
w, y_hat, loss = fit_lr_l1(X, data['y_train'], lmbd=0.05)
w_list_l1.append((degree, w))
plt.plot(data['x_train'], y_hat, color=colors[ix], label='poly degree: %i' % degree)
Отрисовка графика
plt.xlim(data['x_train'].min() - margin, data['x_train'].max() + margin)
plt.ylim(data['y_train'].min() - margin, data['y_train'].max() + margin)
plt.legend(loc='upper right', prop={'size': 20})
plt.title('Fitted polynomial regressions with L1 reg')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
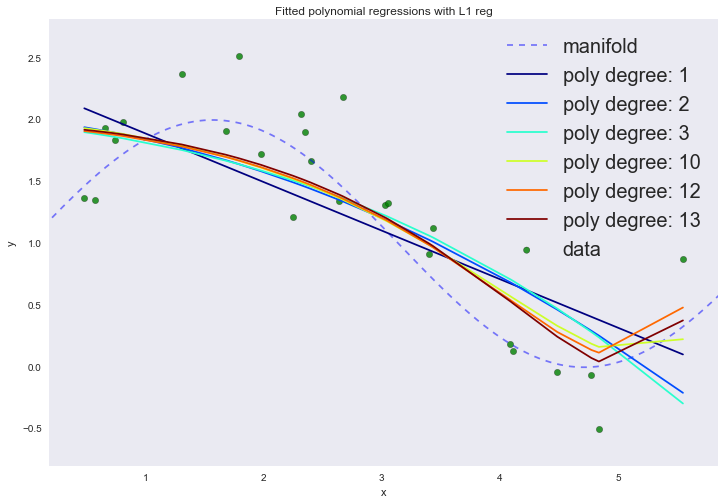
| p | error |
|---|---|
| 1 | 0.27204 |
| 2 | 0.23794 |
| 3 | 0.24118 |
| 10 | 0.18083 |
| 12 | 0.16069 |
| 13 | 0.15425 |
Если посмотреть на коэффициенты, мы увидим, что большая часть из них близка к нулю (то, что у 13-ой степени коэффициент совсем не нулевой, можно списать на шум и малое количество примеров в обучающей выборке; так же стоит помнить, что теперь все признаки измеряются в одинаковых шкалах).
Визуализация коэффициентов
Описанный способ построения регрессии называется LASSO регрессия. Очень хотелось бы думать, что дядька на коне бросает веревку и ворует коэффициенты, а на их месте остается нуль. Но нет, LASSO = least absolute shrinkage and selection operator.
Байесовская интерпретация линейной регрессии
Две вышеописанные регуляризации, да и сама лининейная регрессия с квадратичной функцией ошибки, могут показаться какими-то грязными эмпирическими трюками. Но, оказывается, если взглянуть на эту модель с другой точки зрения, с точки зрения байесовой статистики, то все становится по местам. Грязные эмпирические трюки станут априорными предположениями. В основе байесовой статистики находится формула Байеса:

В статистике обычно ищут точечную оценку максимума правдоподобия (ML = maximum likelihood):

В то время как в байесовом подходе интересуются апостериорным распределением:

Часто получается так, что интеграл, полученный в результате байесового вывода, крайне нетривиален (в случае линейной регрессии это, к счастью, не так), и тогда нужна точечная оценка. Тогда мы интересуемся максимумом апостериорного распределения (MAP = maximum a posteriori):

Давайте сравним ML и MAP гипотезы для линейной регрессии, это даст нам четкое понимание смысла регуляризаций. Будем считать, что все объекты из обучающей выборки были взяты из общей популяции независимо и равномерно распределенно. Это позволит нам записать совместную вероятность данных (правдоподобие) в виде:

А также будем считать, что целевая переменная подчиняется следующему закону:

или

Т.е. верное значение целевой переменной складывается из значения детерминированной линейной функции и некоторой непрогнозируемой случайной ошибки, с нулевым матожиданием и некоторой дисперсией. Тогда, мы можем записать правдоподобие данных как:

удобнее будет прологарифмировать это выражение:

И внезапно мы увидим, что оценка, полученная методом максимального правдоподобия, – это то же самое, что и оценка, полученная методом наименьших квадратов. Сгенерируем новый набор данных большего размера, найдем ML решение и визуализируем его.
data = generate_wave_set(1000, 100)
X = np.vstack((np.ones(data['x_train'].shape[0]), data['x_train'])).T
w = np.dot(np.dot(np.linalg.inv(np.dot(X.T, X)), X.T), data['y_train'])
Отрисовка графика
w0_support = np.linspace(-3, 3, 1000)
w1_support = np.linspace(-3, 3, 1000)
# create cartesian product of parameters
wx_space = list(it.product(w0_support, w1_support))
w0, w1 = zip(*wx_space)
# calculate MSE on dataset for each pairs of parameters
y = ((data['y_train'][:, np.newaxis] - np.dot(X, np.array(wx_space).T))**2).mean(axis=0)
plt.hexbin(w0, w1, C=y**(0.2), cmap=cm.jet_r, bins=None)
plt.axvline(0, color='black', linestyle='-', label='origin')
plt.axhline(0, color='black', linestyle='-')
plt.axvline(w[0], color='w', linestyle='--', label='ML solution')
plt.axhline(w[1], color='w', linestyle='--')
plt.axes().set_aspect('equal', 'datalim')
plt.title('ML solution')
plt.xlabel('w_0')
plt.ylabel('w_1')
plt.legend(loc='upper left', prop={'size': 20})
plt.show()
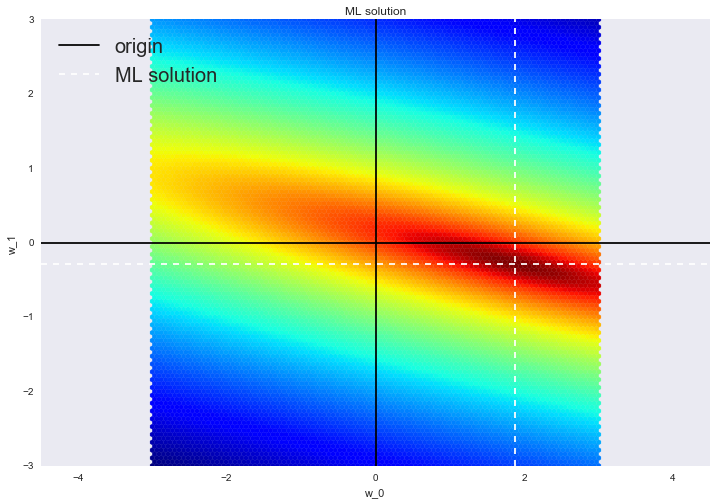
По оси абсцисс и ординат отложены различные значения всех двух параметров модели (решаем именно линейную регрессию, а не полиномиальную), цвет фона пропорционален значению правдоподобия в соответствующей точке значений параметров. ML решение находится на самом пике, где правдоподобие максимально.
Найдем MAP оценку параметров линейной регрессии, для этого придется задать какое-нибудь априорное распределение на параметры модели. Пусть для начала это будет опять нормальное распределение:  .
.
Нормальное распределение

x = np.linspace(-5, 5, 1000)
for scale in np.linspace(0.5, 1.4, 7):
plt.plot(x, norm.pdf(x, scale=scale), label='scale=%0.2f' % scale)
plt.legend(loc='upper right', prop={'size': 20})
plt.title('Normal distribution with different scale parameter')
plt.show()
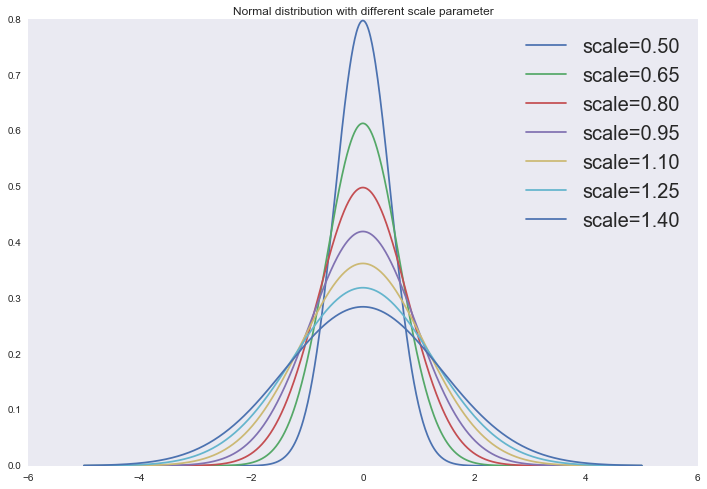
Тогда апостериорное распределение примет вид:

Если расписать логарифм этого выражения, то вы легко увидите, что добавление нормального априорного распределения — это то же самое, что и добавление нормы к функции стоимости. Попробуйте сделать это сами. Также станет ясно, что варьируя регуляризационный параметр, мы изменяем дисперсию априорного распределения:  .
.
Отрисовка графика
w = np.dot(np.dot(np.linalg.inv(np.dot(X.T, X)), X.T), data['y_train'])
# solve L2 problems for different values of
w_l2 = {}
lmbd_space = np.linspace(0.5, 1500, 500)
for lmbd in lmbd_space:
w_l2[lmbd] = np.dot(np.dot(np.linalg.inv(np.dot(X.T, X) + lmbd*np.eye(X.shape[1])), X.T), data['y_train'])
w0_support = np.linspace(-3, 3, 1000)
w1_support = np.linspace(-3, 3, 1000)
wx_space = list(it.product(w0_support, w1_support))
w0, w1 = zip(*wx_space)
y = ((data['y_train'][:, np.newaxis] - np.dot(X, np.array(wx_space).T))**2).mean(axis=0)
plt.hexbin(w0, w1, C=y**(0.2), cmap=cm.jet_r, bins=None)
plt.axvline(0, color='black', linestyle='-', label='origin')
plt.axhline(0, color='black', linestyle='-')
# plot prior distribution of parameters
for i in range(1, 6):
plt.gcf().gca().add_artist(plt.Circle((0, 0), i*0.3, color='black', linestyle='--', alpha=0.1))
plt.axvline(w[0], color='w', linestyle='--', label='ML solution')
plt.axhline(w[1], color='w', linestyle='--')
# plot MAP solutions
flag = True
for _, w_l2_solution in w_l2.items():
plt.plot(w_l2_solution[0], w_l2_solution[1], color='c', marker='.', mew=1, alpha=0.5,
label='MAP L2 solution' if flag else None)
flag = False
plt.axes().set_aspect('equal', 'datalim')
plt.title('ML and MAP L2 for different values of lambda')
plt.xlabel('w_0')
plt.ylabel('w_1')
plt.legend(loc='upper left', prop={'size': 20})
plt.show()
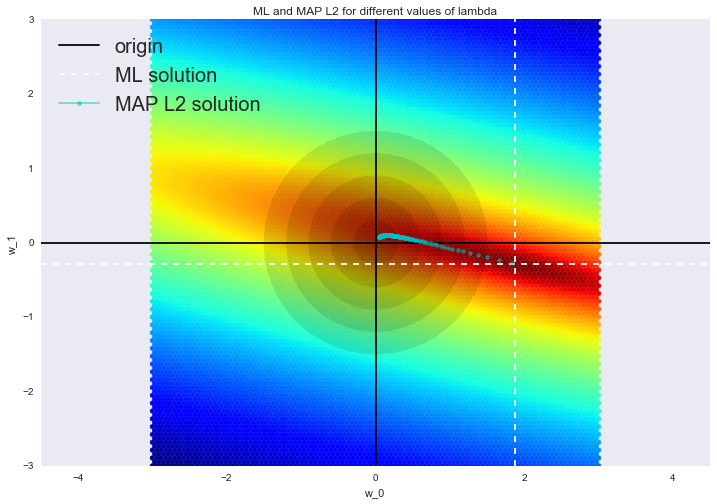
Теперь на график добавились круги, исходящие от центра — это плотность априорного распределения (круги, а не эллипсы из-за того, что матрица ковариации данного нормального распределения диагональна, а на диагонали находится одно и то же число). Точками обозначены различные решения MAP задачи. При увеличении параметра регуляризации (что эквивалентно уменьшению дисперсии), мы заставляем решение отдаляться от ML оценки и приближаться к центру априорного распределения. При большом значении параметра регуляризации, все параметры будут близки к нулю.
Естественно мы можем наложить и другое априорное распределение на параметры модели, например распределение Лапласа, тогда получим то же самое, что и при регуляризации.
Распределение Лапласа

from scipy.stats import laplace
x = np.linspace(-5, 5, 1000)
for scale in np.linspace(0.5, 1.4, 7):
plt.plot(x, laplace.pdf(x, scale=scale), label='scale=%0.2f' % scale)
plt.legend(loc='upper right', prop={'size': 20})
plt.title('Laplace distribution with different scale parameter')
plt.show()
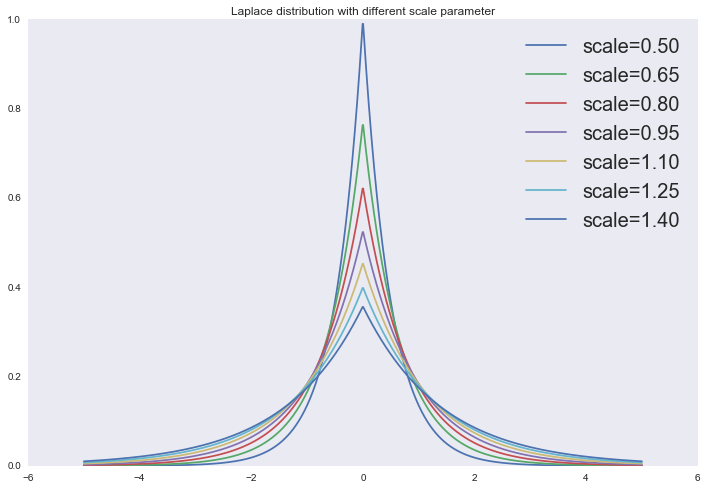
Тогда апостериорное распределение примет вид:

Отрисовка графика
w_l1 = {}
lmbd_space = np.linspace(0.001, 2, 200)
for lmbd in tqdm(lmbd_space):
w_l1[lmbd] = fit_lr_l1(X, data['y_train'], lmbd, n_iter=10000, lr=0.001)[0]
w0_support = np.linspace(-3, 3, 1000)
w1_support = np.linspace(-3, 3, 1000)
wx_space = list(it.product(w0_support, w1_support))
w0, w1 = zip(*wx_space)
y = ((data['y_train'][:, np.newaxis] - np.dot(X, np.array(wx_space).T))**2).mean(axis=0)
plt.hexbin(w0, w1, C=y**(0.2), cmap=cm.jet_r, bins=None)
plt.axvline(0, color='black', linestyle='-', label='origin')
plt.axhline(0, color='black', linestyle='-')
# function to plot rhomb
def plot_rhomb(cx=0, cy=0, r=0.5):
plt.gcf().gca().add_artist(plt.Rectangle((cx, cy - np.sqrt(2*r**2)), 2*r, 2*r, angle=45,
color='black', linestyle='--', alpha=0.1))
# plot Laplace distribution density
for i in range(1, 6):
plot_rhomb(r=0.2*i)
plt.axvline(w[0], color='w', linestyle='--', label='ML solution')
plt.axhline(w[1], color='w', linestyle='--')
# plot MAP solutions
flag = True
for _, w_l1_solution in w_l1.items():
plt.plot(w_l1_solution[0], w_l1_solution[1], color='c', marker='.', mew=1, alpha=0.5,
label='MAP L1 solution' if flag else None)
flag = False
plt.axes().set_aspect('equal', 'datalim')
plt.title('ML and MAP L1 for different values of lambda')
plt.xlabel('w_0')
plt.ylabel('w_1')
plt.legend(loc='upper left', prop={'size': 20})
plt.show()
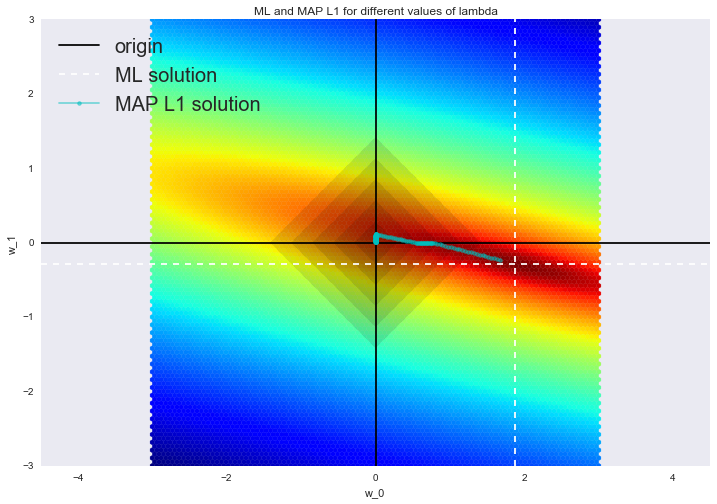
Глобальная динамика не изменилась: увеличиваем параметр регуляризации — решение приближается к центру априорного распределения. Также мы можем наблюдать, что такая регуляризация способствует нахождению разреженных решений: вы можете видеть два участка, на которых сначала один параметр равен нулю, затем второй параметр (в конце оба равны нулю).
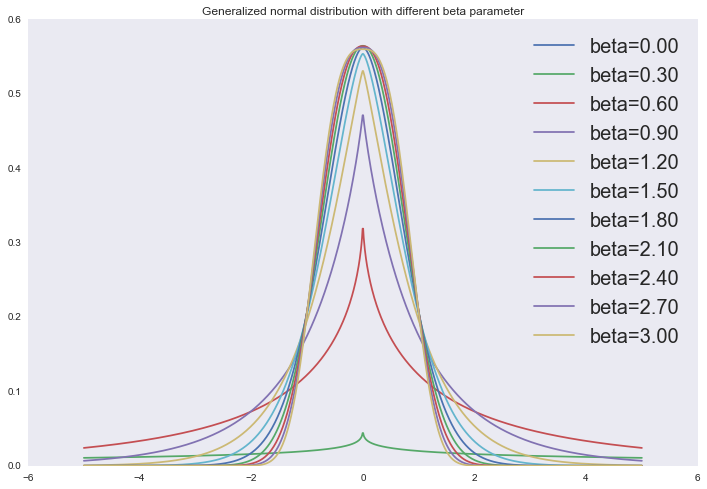
И на самом деле два описанных регуляризатора — это частные случаи наложения обобщенного нормального распределения в качестве априорного распределения на параметры линейной регрессии:

Отрисовка графика
from scipy.stats import gennorm
x = np.linspace(-5, 5, 1000)
for beta in np.linspace(0, 3, 11):
plt.plot(x, gennorm.pdf(x, beta=beta), label='beta=%0.2f' % beta)
plt.legend(loc='upper right', prop={'size': 20})
plt.title('Generalized normal distribution with different beta parameter')
plt.show()
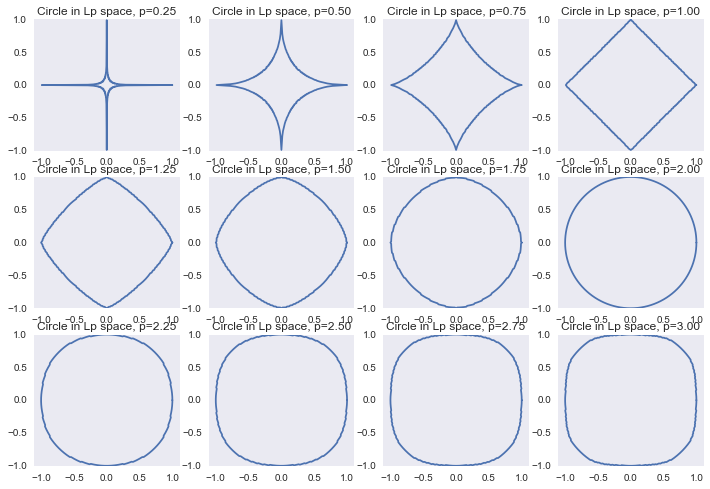
Или же мы можем смотреть на эти регуляризаторы с точки зрения ограничения  нормы, как в предыдущей части:
нормы, как в предыдущей части:

Отрисовка графика
f, ax = plt.subplots(3, 4)
ax = reduce(lambda a, b: a + b, ax.tolist())
a_list = np.linspace(0, 2*np.pi, 361)
r_list = np.linspace(0, 1.1, 100)
for ix, p in enumerate(np.linspace(0.25, 3, 12)):
points = []
for a in a_list:
r_inner = []
for r in r_list:
if np.linalg.norm([r*np.cos(a), r*np.sin(a)], p) > 1:
break
r_inner.append(r)
r = max(r_inner)
points.append([r*np.cos(a), r*np.sin(a)])
points = np.array(points)
ax[ix].plot(points[:, 0], points[:, 1])
ax[ix].set_aspect('equal', 'datalim')
ax[ix].set_title('Circle in Lp space, p=%0.2f' % p)
Заключение
Здесь вы найдете jupyter notebook со всем вышеописанным и несколькими бонусами. Отдельное спасибо тем, кто осилил этот текст до конца.
Желающим копнуть эту тему глубже, рекомендую:
- лекции Сергея Николенко, откуда позаимствована идея этого jupyter notebook’a;
- лекции Бориса Демешева по эконометрике (со 146ого видео), и его же курс на курсере.
Понимание линейной регрессии является ключом к пониманию более сложных моделей, вплоть до глубоких нейронных сетей. Если мы возьмем сигмойд от линейной функции — получим логистическую регрессию. Состекаем несколько логрегрессоров в один слой — получим softmax regression/max entropy regression. А если состекать несколько слоев — будет неронная сеть. Такие дела.
Вступайте в ods.ai, приходите на наши сходки, we will make ML great again!

Регрессия как задача машинного обучения
38 мин на чтение
(55.116 символов)
Постановка задачи регрессии

Источник: Analytics Vidhya.
Задача регрессии — это одна из основных задач машинного обучения. И хотя, большинство задач на практике относятся к другому типу — классификации, мы начнем знакомство с машинным обучением именно с регрессии. Регрессионные модели были известны задолго до появления машинного обучения как отрасли и активно применяются в статистике, эконометрике, математическом моделировании. Машинное обучение предлагает новый взгляд на уже известные модели. И этот новый взгляд позволит строить более сложные и мощные модели, чем классические математические дисциплины.
Задача регрессии относится к категории задач обучения с учителем. Это значит, что набор данных, который используется для обучения, должен иметь определенную структуру. Обычно, наборы данных для машинного обучения представляют собой таблицу, в которой по строкам перечислены разные объекты наблюдений или измерений. В столбцах — различные характеристики, или атрибуты, объектов. А на пересечении строк и столбцов — значение данной характеристики у данного объекта. Обычно один атрибут (или переменная) имеет особый характер — именно ее значение мы и хотим научиться предсказывать с помощью модели машинного обучения. Эта характеристика объекта называется целевая переменная. И если эта целевая переменная выражена числом (а точнее, некоторой непрерывной величиной) — то мы говорим о задаче регрессии.
Задачи регрессии на практике встречаются довольно часто. Например, предсказание цены объекта недвижимости — классическая регрессионная задача. В таких проблемах атрибутами выступают разные характеристики квартир или домов — площадь, этажность, расположение, расстояние до центра города, количество комнат, год постройки. В разных наборах данных собрана разная информация И, соответственно, модели тоже должны быть разные. Другой пример — предсказание цены акций или других финансовых активов. Или предсказание температуры завтрашним днем.
Во всех таких задачах нам нужно иметь данные, которые позволят осуществить такое предсказание. Да, “предсказание” — это условный термин, не всегда мы говорим о будущих событиях. Регрессионные модели используют информацию об объектах в обучающем наборе данных, чтобы сделать вывод о возможном значении целевой переменной. И для этого нужно, чтобы ее значение имело какую-то зависимость от имеющихся у нас атрибутов. Если построить модель предсказания цены акции, но на вход подать информацию о футбольных матчах — ничего не получится. Мы предполагаем, что в наборе данных собраны именно те атрибуты объектов, которые имеют влияние на на значение целевой переменной. И чем больше это предположение выполняется, тем точнее будет потенциально наша модель.
Немного поговорим о терминах. Набор данных который мы используем для обучения модели называют датасетом (dataset) или обучающей выборкой (training set). Объекты, которые описываются в датасете еще называют точками данных (data points). Целевую переменную еще называют на статистический манер зависимой переменной (dependent variable) или результативной, выходной (output), а остальные атрибуты — независимыми переменными (dependent variables), или признаками (features), или факторами, или входными переменными (input). Значения одного конкретного атрибута для всех объектов обучающей выборки часто представляют как вектор этого признака (feature vector). А всю таблицу всех атрибутов называют матрицей атрибутов (feature matrix). Соответственно, еще есть вектор целевой переменной, он не входит в матрицу атрибутов.
С точки зрения информатики, регрессионная модель — это функция, которая принимает на вход значения атрибутов какого-то конкретного объекта и выдает на выходе предполагаемое значение целевой переменной. В большинстве случаев мы предполагаем, что целевая переменная у нас одна. Если стоит задача предсказания нескольких характеристик, то их чаще воспринимают как несколько независимых задач регрессии на одних и тех же атрибутах.
Мы пока ничего не говорили о том, как изнутри устроена регрессионная модель. Это потому, что она может быть какой угодно. Это может быть математическое выражение, условный алгоритм, сложная программа со множеством ветвлений и циклов, нейронная сеть — все это можно представить регрессионной моделью. Единственное требование к модели машинного обучения — она должна быть параметрической. То есть иметь какие-то внутренние параметры, от которых тоже зависит результат вычисления. В простых случаях, чаще всего в качестве регрессионной модели используют аналитические функции. Таких функций бесконечное количество, но чаще всего используется самая простая функция, с которой мы и начнем изучение регрессии — линейная функция.
Так же надо сказать, что иногда регрессионные модели подразделяют на парную и множественную регрессии. Парная регрессия — это когда у нас всего один атрибут. Множественная — когда больше одного. Конечно, на практике парная регрессия почти не встречается, но на примере такой простой модели мы поймем основные концепции машинного обучения. Плюс, парную регрессию очень удобно и наглядно можно изобразить на графике. Когда у нас больше двух переменных, графики уже не особо построишь, и модели приходится визуализировать иначе, более косвенно.
Выводы:
- Регрессия — это задача машинного обучения с учителем, которая заключается в предсказании некоторой непрерывной величины.
- Для использования регрессионных моделей нужно, чтобы в датасете были характеристики объектов и “правильные” значения целевой переменной.
- Примеры регрессионных задач — предсказание цены акции, оценка цены объекта недвижимости.
- Задача регрессии основывается на предположении, что значение целевой переменной зависит от значения признаков.
- Регрессионная модель принимает набор значений и выдает предсказание значения целевой переменной.
- В качестве регрессионных моделей часто берут аналитические функции, например, линейную.
Линейная регрессия с одной переменной
Функция гипотезы

Напомним, что в задачах регрессии мы принимаем входные переменные и пытаемся получить более-менее достоверное значение целевой переменной. Любая функция, даже самая простая линейная может выдавать совершенно разные значения для одних и тех же входных данных, если в функции будут разные параметры. Поэтому, любая регрессионная модель — это не какая-то конкретная математическая функция, а целое семейство функций. И задача алгоритма обучения — подобрать значения параметров таким образом, чтобы для объектов обучающей выборки, для которых мы уже знаем правильные ответы, предсказанные (или теоретические, вычисленные из модели) значения были как можно ближе к тем, которые есть в датасете (эмпирические, истинные значения).
Парная, или одномерная (univariate) регрессия используется, когда вы хотите предсказать одно выходное значение (чаще всего обозначаемое $y$), зависящее от одного входного значения (обычно обозначается $x$). Сама функция называется функцией гипотезы или моделью. В качестве функции гипотезы для парной регрессии можно выбрать любую функцию, но мы пока потренируемся с самой простой функцией одной переменной — линейной функцией. Тогда нашу модель можно назвать парной линейной регрессией.
В случае парной линейной регрессии функция гипотезы имеет следующий общий вид:
[hat{y} = h_b (x) = b_0 + b_1 x]
Обратите внимание, что это похоже на уравнение прямой. Эта модель соответствует множеству всех возможных прямых на плоскости. Когда мы конкретизируем модель значениями параметров (в данном случае — $b_0$ и $b_1$), мы получаем конкретную прямую. И наша задача состоит в том, чтобы выбрать такую прямую, которая бы лучше всего “легла” в точки из нашей обучающей выборки.
В данном случае, мы пытаемся подобрать функцию h(x) таким образом, чтобы отобразить данные нам значения x в данные значения y.
Допустим, мы имеем следующий обучающий набор данных:
| входная переменная x | выходная переменная y |
| 0 | 4 |
| 1 | 7 |
| 2 | 7 |
| 3 | 8 |
Мы можем составить случайную гипотезу с параметрами $ b_0 = 2, b_1 = 2 $. Тогда для входного значения $ x=1 $ модель выдаст предсказание, что $ y=4 $, что на 3 меньше данного. Значение $y$б которое посчитала модель будем называть теоретическим или предсказанным (predicted), а значение, которое дано в наборе данных — эмпирическим или истинным (true). Задача регрессии состоит в нахождении таких параметров функции гипотезы, чтобы она отображала входные значения в выходные как можно более точно, или, другими словами, описывала линию, наиболее точно ложащуюся в данные точки на плоскости $(x, y)$.
Выводы:
- Модель машинного обучения — это параметрическая функция.
- Задача обучения состоит в том, чтобы подобрать параметры модели таким образом, чтобы она лучше всего описывала обучающие данные.
- Парная линейная регрессия работает, если есть всего одна входящая переменная.
- Парная линейная регрессия — одна из самых простых моделей машинного обучения.
- Парная линейная регрессия соответствует множеству всех прямых на плоскости. Из них мы выбираем одну, наиболее подходящую.
Функция ошибки
Как мы уже говорили, разные значения параметров дают разные модели. Для того, чтобы подобрать наилучшую модель, нам нужно средство измерения “точности” модели, некоторая функция, которая показывает, насколько модель хорошо или плохо соответствует имеющимся данным.

В простых случаях мы можем отличить хорошие модели от плохих, только взглянув на график. Но это затруднительно, если количество признаков очень велико, если модели лишь немного отличаются друг от друга. Да и для автоматизации процесса нужен способ формализовать наше общее представление о том, что модель “ложится” в точки данных.
Такая функция называется функцией ошибки (cost function). Она измеряет отклонения теоретических значений (то есть тех, которые предсказывает модель) от эмпирических (то есть тех, которые есть в данных). Чем выше значение функции ошибки, тем хуже модель соответствует имеющимся данным, хуже описывает их. Если модель полностью соответствует данным, то значение функции ошибки будет нулевым.

В задачах регрессии в качестве функции ошибки чаще всего берут среднеквадратичное отклонение теоретических значений от эмпирических. То есть сумму квадратов отклонений, деленную на удвоенное количество измерений.
[J(b_0, b_1)
= frac{1}{2m} sum_{i=1}^{m} (hat{y_i} — y_i)^2
= frac{1}{2m} sum_{i=1}^{m} (h_b(x_i) — y_i)^2]
Эту функцию называют «функцией квадрата ошибки» или «среднеквадратичной ошибкой» (mean squared error, MSE). Среднее значение уменьшено вдвое для удобства вычисления градиентного спуска, так как производная квадратичной функции будет отменять множитель 1/2. Вообще, функцию ошибки можно свободно домножить или разделить на любое число (положительное), ведь нам не важна конкретная величина этой функции. Нам важно, что какие-то модели (то есть наборы значений параметров модели) имеют низкую ошибку, они нам подходят больше, а какие-то — высокую ошибку, они подходят нам меньше.
Возведение в квадрат в этой формуле нужно для того, чтобы положительные отклонения не компенсировали отрицательные. Можно было бы для этого брать, например, абсолютное значение, но эта функция не везде дифференцируема, а это станет нам важно позднее.
Обратите внимание, что в качестве аргументов у функции ошибки выступают параметры нашей функции гипотезы. Ведь функция ошибки оценивает отклонение конкретной функции гипотезы (то есть набора значений параметров этой функции) от эмпирических значений, то есть ставит в соответствие каждому набору параметров модели число, характеризующее ошибку этого набора.
Давайте проследим формирование функции ошибки на еще более простом примере. Возьмем упрощенную форму линейной модели — прямую пропорциональность. Она выражается формулой:
[hat{y} = h_b (x) = b_1 x]
Эта модель поможет нам, так как у нее всего один параметр. И функцию ошибки можно будет изобразить на плоскости. Возьмем фиксированный набор точек и попробуем несколько значений параметра для вычисления функции ошибки. Слева на графике изображены точки данных и текущая функция гипотезы, а на правом графике бы будем отмечать значение использованного параметра (по горизонтали) и получившуюся величину функции ошибки (по вертикали):

При значении $b_1 = -1$ линия существенно отклоняется от точек. Отметим уровень ошибки (примерно 10) на правом графике.

Если взять значение $b_1 = 0$ линия гораздо ближе к точкам, но ошибка все еще есть. Отметим новое значение на правом графике в точке 0.

При значении $b_1 = 1$ график точно ложится в точки, таким образом ошибка становится равной нулю. Отмечаем ее так же.

При дальнейшем увеличении $b_1$ линия становится выше точек. Но функция ошибки все равно будет положительной. Теперь она опять станет расти.

На этом примере мы видим еще одно преимущество возведения в квадрат — это то, что такая функция в простых случаях имеет один глобальный минимум. На правом графике формируется точка за точкой некоторая функция, которая похожа очертаниями на параболу. Но мы не знаем аналитического вида этой параболы, мы можем лишь строить ее точка за точкой.
В нашем примере, в определенной точке функция ошибки обращается в ноль. Это соответствует “идеальной” функции гипотезы. То есть такой, когда она проходит четко через все точки. В нашем примере это стало возможно благодаря тому, что точки данных и так располагаются на одной прямой. В общем случае это не выполняется и функция ошибки, вообще говоря, не обязана иметь нули. Но она должна иметь глобальный минимум. Рассмотрим такой неидеальный случай:





Какое бы значение параметра мы не использовали, линейная функция неспособна идеально пройти через такие три точки, которые не лежат на одной прямой. Эта ситуация называется “недообучение”, об этом мы еще будем говорить дальше. Это значит, что наша модель слишком простая, чтобы идеально описать данные. Но зачастую, идеальная модель и не требуется. Важно лишь найти наилучшую модель из данного класса (например, линейных функций).
Выше мы рассмотрели упрощенный пример с функцией гипотезы с одним параметром. Но у парной линейной регрессии же два параметра. В таком случае, функция ошибки будет описывать не параболу, а параболоид:

Теперь мы можем конкретно измерить точность нашей предсказывающей функции по сравнению с правильными результатами, которые мы имеем, чтобы мы могли предсказать новые результаты, которых у нас нет.
Если мы попытаемся представить это наглядно, наш набор данных обучения будет разбросан по плоскости x-y. Мы пытаемся подобрать прямую линию, которая проходит через этот разбросанный набор данных. Наша цель — получить наилучшую возможную линию. Лучшая линия будет такой, чтобы средние квадраты вертикальных расстояний точек от линии были наименьшими. В лучшем случае линия должна проходить через все точки нашего набора данных обучения. В таком случае значение J будет равно 0.


В более сложных моделях параметров может быть еще больше, но это не важно, ведь нам не нужно строить функцию ошибки, нам нужно лишь оптимизировать ее.
Выводы:
- Функция ошибки нужна для того, чтобы отличать хорошие модели от плохих.
- Функция ошибки показывает численно, насколько модель хорошо описывает данные.
- Аргументами функции ошибки являются параметры модели, ошибка зависит от них.
- Само значение функции ошибки не несет никакого смысла, оно используется только в сравнении.
- Цель алгоритма машинного обучения — минимизировать функцию ошибки, то есть найти такой набор параметров модели, при которых ошибка минимальна.
- Чаще всего используется так называемая L2-ошибка — средний квадрат отклонений теоретических значений от эмпирических (метрика MSE).
Метод градиентного спуска
Таким образом, у нас есть функция гипотезы, и способ оценить, насколько хорошо конкретная гипотеза вписывается в данные. Теперь нам нужно подобрать параметры функции гипотезы. Вот где приходит на помощь метод градиентного спуска.
Это происходит при помощи производной функции ошибки. Необходимое условие минимума функции — обращение в ноль ее производной. А так как мы знаем, что квадратичная функция имеет один глобальный экстремум — минимум, то наша задача очень проста — вычислить производную функции ошибки и найти, где она равна нулю.
Давайте найдем производную среднеквадратической функции ошибки:
[J(b_0, b_1) = frac{1}{2m} sum_{i=1}^{m} (h_b(x_i) — y_i)^2]
[J(b_0, b_1) = frac{1}{2m} sum_{i=1}^{m} (h_b(x_i) — y_i)^2]
[frac{partial}{partial b_i} J =
frac{1}{m} sum_{i=1}^{m} (h_b(x_i) — y^{(i)}) cdot frac{partial}{partial b_i} h_b(x_i)]
[J(b_0, b_1) = frac{1}{2m} sum_{i=1}^{m} (b_0 + b_1 x_i — y_i)^2]
[frac{partial J}{partial b_0} =
frac{1}{m} sum (b_0 + b_1 x_i — y_i) =
frac{1}{m} sum (h_b(x_i) — y_i)]
[frac{partial J}{partial b_1} =
frac{1}{m} sum (b_0 + b_1 x_i — y_i) cdot x_i =
frac{1}{m} sum (h_b(x_i) — y_i) cdot x_i]
Проблема в том, что мы не можем просто решить эти уравнения аналитически. Ведь мы не знаем общий вид функции ошибки, не то, что ее производной. Ведь он зависит, от всех точек данных. Но мы можем вычислить эту функцию (и ее производную) в любой точке. А точка на этой функции — это конкретный набор значений параметров модели. Поэтому пришлось изобрести численный алгоритм. Он работает следующим образом.
Сначала, мы выбираем произвольное значение параметров модели. То есть, произвольную точку в области определения функции. Мы не знаем, является ли эта точка оптимальной (скорее нет), не знаем, насколько она далека от оптимума. Но мы можем вычислить направление к оптимуму. Ведь мы знаем наклон касательной к графику функции ошибки.

Наклон касательной является производной в этой точке, и это даст нам направление движения в сторону самого крутого уменьшения значения функции. Если представить себе функцию одной переменной (параболу), то там все очень просто. Если производная в точке отрицательна, значит функция убывает, значит, что оптимум находится справа от данной точки. То есть, чтобы приблизиться к оптимуму надо увеличить аргумент функции. Если же производная положительна, то все наоборот — функция возрастает, оптимум находится слева и нам нужно уменьшить значение аргумента. Причем, чем дальше от оптимума, тем быстрее возрастает или убывает функция. То есть значение производной дает нам не только направление, но и величину нужного шага. Сделав шаг, пропорциональный величине производной и в направлении, противоположном ей, можно повторить процесс и еще больше приблизиться к оптимуму. С каждой итерацией мы будем приближаться к минимуму ошибки и математически доказано, что мы можем приблизиться к ней произвольно близко. То есть, данный метод сходится в пределе.
В случае с функцией нескольких переменных все немного сложнее, но принцип остается прежним. Только мы оперируем не полной производной функции, а вектором частных производных по каждому параметру. Он задает нам направление максимального увеличения функции. Чтобы получить направление максимального спада функции нужно просто домножить этот вектор на -1. После этого нужно обновить значения каждого компонента вектора параметров модели на величину, пропорциональную соответствующему компоненту вектора градиента. Таким образом мы делаем шаги вниз по функции ошибки в направлении с самым крутым спуском, а размер каждого шага пропорционален определяется параметром $alpha$, который называется скоростью обучения.
Алгоритм градиентного спуска:
повторяйте до сходимости:
[b_j := b_j — alpha frac{partial}{partial b_j} J(b_0, b_1)]
где j=0,1 — представляет собой индекс номера признака.
Это общий алгоритм градиентного спуска. Она работает для любых моделей и для любых функций ошибки. Это итеративный алгоритм, который сходится в пределе. То есть, мы никогда не придем в сам оптимум, но можем приблизиться к нему сколь угодно близко. На практике нам не так уж важно получить точное решение, достаточно решения с определенной точностью.
Алгоритм градиентного спуска имеет один параметр — скорость обучения. Он влияет на то, как быстро мы будем приближаться к оптимуму. Кажется, что чем быстрее, тем лучше, но оказывается, что если значение данного параметра слишком велико, то мы буем постоянно промахиваться и алгоритм будет расходиться.

Алгоритм градиентного спуска для парной линейной регрессии:
повторяйте до сходимости:
[b_0 := b_0 — alpha frac{1}{m} sum_{i=1}^{m} (h_b(x^{(i)} )- y^{(i)})]
[b_1 := b_1 — alpha frac{1}{m} sum_{i=1}^{m} (h_b(x^{(i)}) — y^{(i)}) cdot x^{(i)}]
На практике “повторяйте до сходимости” означает, что мы повторяем алгоритм градиентного спуска до тех пор, пока значение функции ошибки не перестанет значимо изменяться. Это будет означать, что мы уже достаточно близко к минимуму и дальнейшие шаги градиентного спуска слишком малы, чтобы быть целесообразными. Конечно, это оценочное суждение, но на практике обычно, нескольких значащих цифр достаточно для практического применения моделей машинного обучения.
Алгоритм градиентного спуска имеет одну особенность, про которую нужно помнить. Он в состоянии находить только локальный минимум функции. Он в принципе, по своей природе, локален. Поэтому, если функция ошибки будет очень сложна и иметь несколько локальных оптимумов, то результат работы градиентного спуска будет зависеть от выбора начальной точки:


На практике эту проблему решают методом семплирования — запускают градиентный спуск из множества случайных точек и выбирают то минимум, который оказался меньше по значению функции ошибки. Но этот подход понадобится нам при рассмотрении более сложных и глубоких моделей машинного обучения. Для простых линейных, полиномиальных и других моделей метод градиентного спуска работает прекрасно. В настоящее время этот алгоритм — это основная рабочая лошадка классических моделей машинного обучения.
Выводы:
- Метод градиентного спуска нужен, чтобы найти минимум функции, если мы не можем ее вычислить аналитически.
- Это численный итеративный алгоритм локальной оптимизации.
- Для запуска градиентного спуска нужно знать частную производную функции ошибки.
- Для начала мы берем произвольные значения параметров, затем обновляем их по данной формуле.
- Доказано, что этот метод сходится к локальному минимуму.
- Если функция ошибки достаточно сложная, то разные начальные точки дадут разный результат.
- Метод градиентного спуска имеет свой параметр — скорость обучения. Обычно его подстаивают автоматически.
- Метод градиентного спуска повторяют много раз до тех пор, пока функция ошибки не перестанет значимо изменяться.
Регрессия с несколькими переменными
Множественная линейная регрессия

Парная регрессия, как мы увидели выше, имеет дело с объектами, которые характеризуются одним числовым признаком ($x$). На практике, конечно, объекты характеризуются несколькими признаками, а значит в модели должна быть не одна входящая переменная, а несколько (или, что то же самое, вектор). Линейная регрессия с несколькими переменными также известна как «множественная линейная регрессия». Введем обозначения для уравнений, где мы можем иметь любое количество входных переменных:
$ x^{(i)} $- вектор-столбец всех значений признаков i-го обучающего примера;
$ x_j^{(i)} $ — значение j-го признака i-го обучающего примера;
$ x_j $ — вектор j-го признака всех обучающих примеров;
m — количество примеров в обучающей выборке;
n — количество признаков;
X — матрица признаков;
b — вектор параметров регрессии.
Задачи множественной регрессии уже очень сложно представить на графике, ведь количество параметров каждого объекта обучающей выборки соответствует измерению, в котором находятся точки данных. Плюс нужно еще одно измерение для целевой переменной. И вместо того, чтобы подбирать оптимальную прямую, мы будем подбирать оптимальную гиперплоскость. Но в целом идея линейной регрессии остается неизменной.
Для удобства примем, что $ x_0^{(i)} = 1 $ для всех $i$. Другими словами, мы ведем некий суррогатный признак, для всех объектов равный единице. Это никак не сказывается на самой функции гипотезы, это лишь условность обозначения, но это сильно упростит математические выкладки, особенно в матричной форме.
Теперь определим множественную форму функции гипотезы следующим образом, используя несколько признаков. Она очень похожа на парную, но имеет больше входных переменных и, как следствие, больше параметров.
Общий вид модели множественной линейной регрессии:
[h_b(x) = b_0 + b_1 x_1 + b_2 x_2 + … + b_n x_n]
Или в матричной форме:
[h_b(x) = X cdot vec{b}]
Используя определение матричного умножения, наша многопараметрическая функция гипотезы может быть кратко представлена в виде: $h(x) = B X$.
Обратите внимание, что в любой модели линейной регрессии количество параметров на единицу больше количества входных переменных. Это верно для любой линейной модели машинного обучения. Вообще, всегда чем больше признаков, тем больше параметров. Это будет важно для нас позже, когда мы будем говорить о сложности моделей.
Теперь, когда мы знаем виды функции гипотезы, то есть нашей модели, мы можем переходить к следующему шагу: функции ошибки. Мы построим ее по аналогии с функцией ошибки для парной модели. Для множественной регрессии функция ошибки от вектора параметров b выглядит следующим образом:
Функция ошибки для множественной линейной регрессии:
[J(b) = frac{1}{2m} sum_{i=1}^{m} (h_b(x^{(i)}) — y^{(i)})^2]
Или в матричной форме:
[J(b) = frac{1}{2m} (X b — vec{y})^T (X b — vec{y})]
Обратите внимание, что мы специально не раскрываем выражение (h_b(x^{(i)})). Это нужно, чтобы подчеркнуть, что форма функции ошибки не зависит от функции гипотезы, она выражается через нее.
Теперь нам нужно взять производную этой функции ошибки. Здесь уже нужно знать производную самой функции гипотезы, так как:
[frac{partial}{partial b_i} J =
frac{1}{m} sum_{i=1}^{m} (h_b(x^{(i)}) — y^{(i)}) cdot frac{partial}{partial b_i} h_b(x^{(i)})]
В такой формулировке мы представляем частные производные функции ошибки (градиент) через частную производную функции гипотезы. Это так называемое моделенезависимое представление градиента. Ведь для этой формулы совершенно неважно, какой функцией будет наша гипотеза. Пока она является дифференцируемой, мы можем использовать градиент ее функции ошибки. Именно поэтому метод градиентного спуска работает с любыми аналитическими моделями, и нам не нужно каждый раз заново “переизобретать” математику градиентного спуска, адаптировать ее к каждой конкретной модели машинного обучения. Достаточно изучить этот метод один раз, в общей форме.
Метод градиентного спуска для множественной регрессии определяется следующими уравнениями:
повторять до сходимости:
[b_0 := b_0 — alpha frac{1}{m} sum_{i=1}^{m} (h_b(x^{(i)}) — y^{(i)}) cdot x_0^{(i)}]
[b_1 := b_1 — alpha frac{1}{m} sum_{i=1}^{m} (h_b(x^{(i)}) — y^{(i)}) cdot x_1^{(i)}]
[b_2 := b_2 — alpha frac{1}{m} sum_{i=1}^{m} (h_b(x^{(i)}) — y^{(i)}) cdot x_2^{(i)}]
[…]
Или в матричной форме:
[b := b — frac{alpha}{m} X^T (X b — vec{y})]
Выводы:
- Множественная регрессия очень похожа на парную, но с большим количеством признаков.
- Для удобства и однообразия, почти всегда обозначают $x_0 = 1$.
- Признаки образуют матрицу, поэтому уравнения множественной регрессии часто приводят в матричной форме, так короче.
- Алгоритм градиентного спуска для множественной регрессии точно такой же, как и для парной.
Нормализация признаков
Мы можем ускорить сходимость метода градиентного спуска, преобразовав входные данные таким образом, чтобы все атрибуты имели значения примерно в том же диапазоне. Это называется нормализация данных — приведение всех признаков к одной шкале. Это ускоряет сходимость градиентного спуска за счет эффекта масштаба. Дело в том, что зачастую значения разных признаков измеряются по шкалам с очень разным порядком величины. Например, $x_1$ измеряется в миллионах, а $x_2$ — в долях единицы.
В таком случае форма функции ошибки будет очень вытянутой. Это не проблема для математической формализации градиентного спуска — при достаточно малых $alpha$ метод все равно рано или поздно сходится. Проблема в практической реализации. Получается, что если выбрать скорость обучения выше определенного предела по самому компактному признаку, спуск разойдется. Значит, скорость обучения надо делать меньше. Но тогда в направлении второго признака спуск будет проходить слишком медленно. И получается, что градиентный спуск потребует гораздо больше итераций для завершения.
Эту проблему можно решить если изменить диапазоны входных данных, чтобы они выражались величинами примерно одного порядка. Это не позволит одному измерению численно доминировать над другим. На практике применяют несколько алгоритмов нормализации, самые распространенные из которых — минимаксная нормализация и стандартизация или z-оценки.
Минимаксная нормализация — это изменение входных данных по следующей формуле:
[x’ = frac{x — x_{min}}{x_{max} — x_{min}}]
После преобразования все значения будут лежать в диапазоне $x in [0; 1]$.
Z-оценки или стандартизация производится по формуле:
[x’ = frac{x — M[x]}{sigma_x}]
В таком случае данный признак приводится к стандартному распределению, то есть такому, у которого среднее 0, а дисперсия — 1.
У каждого из этих двух методов нормализации есть по два параметра. У минимаксной — минимальное и максимальное значение признака. У стандартизации — выборочные среднее и дисперсия. Параметры нормализации, конечно, вычисляются по каждому признаку (столбцу данных) отдельно. Причем, эти параметры надо запомнить, чтобы при использовании модели для предсказании использовать именно их (вычисленные по обучающей выборке). Даже если вы используете тестовую выборку, ее надо нормировать с использованием параметров, вычисленных по обучающей. Да, при этом может получиться, что при применении модели на данных, которых не было в обучающей выборке, могут получиться значения, например, меньше нуля или больше единицы (при использовании минимаксной нормализации). Это не страшно, главное, что будет соблюдена последовательность вычисления нормированных значений.
Целевая переменная не нормируется.
При использовании библиотечных моделей машинного обучения беспокоиться о нормализации входных данных вручную, как правило, не нужно. Большинство готовых реализаций моделей уже включают нормализацию как неотъемлемый этап подготовки данных. Более того, некоторые типы моделей обучения с учителем вовсе не нуждаются в нормализации. Но об этом пойдет речь в следующих главах.
Выводы:
- Нормализация нужна для ускорения метода градиентного спуска.
- Есть два основных метода нормализации — минимаксная и стандартизация.
- Параметры нормализации высчитываются по обучающей выборке.
- Нормализация встроена в большинство библиотечных методов.
- Некоторые методы более чувствительны к нормализации, чем другие.
- Нормализацию лучше сделать, чем не делать.
Полиномиальная регрессия

Функция гипотезы не обязательно должна быть линейной, если это не соответствует данным. На практике вы не всегда будете иметь данные, которые можно хорошо аппроксимировать линейной функцией. Наглядный пример вы видите на иллюстрации. Вполне очевидно, что в среднем увеличение целевой переменной замедляется с ростом входной переменной. Это значит, что данные демонстрируют нелинейную динамику. И это так же значит, что мы никак не сможем их хорошо приблизить линейной моделью.
Надо подчеркнуть, что это не свидетельствует о несовершенстве наших методов оптимизации. Мы действительно можем найти самую лучшую линейную функцию для данных точек, но проблема в том, что мы всегда выбираем лучшую функцию из некоторого класса функций, в данном случае — линейных. То есть проблема не в алгоритмах оптимизации, а в ограничении самого вида модели.
вполне логично предположить, что для описания таких нелинейных наборов данных следует использовать нелинейные же функции моделей. Но очень бы не хотелось, для каждого нового класса функций изобретать собственный метод оптимизации, поэтому мы постараемся максимально “переиспользовать” те подходы, которые описали выше. И механизм множественной регрессии в этом сильно поможет.
Мы можем изменить поведение или кривую нашей функции гипотезы, сделав ее квадратичной, кубической или любой другой формой.
Например, если наша функция гипотезы
$ hat{y} = h_b (x) = b_0 + b_1 x $,
то мы можем добавить еще один признак, основанный на $ x_1 $, получив квадратичную функцию
[hat{y} = h_b (x) = b_0 + b_1 x + b_2 x^2]
или кубическую функцию
[hat{y} = h_b (x) = b_0 + b_1 x + b_2 x^2 + b_3 x^3]
В кубической функции мы по сути ввели два новых признака:
$ x_2 = x^2, x_3 = x^3 $.
Точно таким же образом, мы можем создать, например, такую функцию:
[hat{y} = h_b (x) = b_0 + b_1 x + b_2 sqrt{x}]
В любом случае, мы из парной линейной функции сделали какую-то другую функцию. И к этой нелинейной функции можно относиться по разному. С одной стороны, это другой класс функций, который обладает нелинейным поведением, а следовательно, может описывать более сложные зависимости в данных. С другой стороны, это линейна функция от нескольких переменных. Только сами эти переменные оказываются в функциональной зависимости друг от друга. Но никто не говорил, что признаки должны быть независимы.
И вот такое представление нелинейной функции как множественной линейной позволяет нам без изменений воспользоваться алгоритмом градиентного спуска для множественной линейной регрессии. Только вместо $ x_2, x_3, … , x_n $ нам нужно будет подставить соответствующие функции от $ x_1 $.

Источник: Wikimedia.
Очевидно, что нелинейных функций можно придумать бесконечное количество. Поэтому встает вопрос, как выбрать нужный класс функций для решения конкретной задачи. В случае парной регрессии мы можем взглянув на график точек обучающей выборки сделать предположение о том, какой вид нелинейной зависимости связывает входную и целевую переменные. Но если у нас множество признаков, просто так проанализировать график нам не удастся. Поэтому по умолчанию используют полиномиальную регрессию, когда в модель добавляют входные переменные второго, третьего, четвертого и так далее порядков.
Порядок полиномиальной регрессии подбирается в качестве компромисса между качеством получаемой регрессии, и вычислительной сложностью. Ведь чем выше порядок полинома, тем более сложные зависимости он может аппроксимировать. И вообще, чем выше степень полинома, тем меньше будет ошибка при прочих равных. Если степень полинома на единицу меньше количества точек — ошибка будет нулевая. Но одновременно с этим, чем выше степень полинома, тем больше в модели параметров, тем она сложнее и занимает больше времени на обучение. Есть еще вопросы переобучения, но про это мы поговорим позднее.
А что делать, если изначально в модели было несколько признаков? Тогда обычно для определенной степени полинома берутся все возможные комбинации признаком соответствующей степени и ниже. Например:
Для регрессии с двумя признаками.
Линейная модель (полином степени 1):
[h_b (x) = b_0 + b_1 x_1 + b_2 x_2]
Квадратичная модель (полином степени 2):
[h_b (x) = b_0 + b_1 x + b_2 x_2 + b_3 x_1^2 + b_4 x_2^2 + b_5 x_1 x_2]
Кубическая модель (полином степени 3):
[hat{y} = h_b (x) = b_0 + b_1 x_1 + b_2 x_2 + b_3 x_1^2 + b_4 x_2^2 + b_5 x_1 x_2 + b_6 x_1^3 + b_7 x_2^3 + b_7 x_1^2 x_2 + b_8 x_1 x_2^2]
При этом количество признаков и, соответственно, количество параметров растет экспоненциально с ростом степени полинома. Поэтому полиномиальные модели обычно очень затратные в обучении при больших степенях. Но полиномы высоких степеней более универсальны и могут аппроксимировать более сложные данные лучше и точнее.
Выводы:
- Данные в датасете не всегда располагаются так, что их хорошо может описывать линейная функция.
- Для описания нелинейных зависимостей нужна более сложная, нелинейная модель.
- Чтобы не изобретать алгоритм обучения заново, можно просто ввести в модель суррогатные признаки.
- Суррогатный признак — это новый признак, который считается из существующих атрибутов.
- Чаще всего используют полиномиальную регрессию — это когда в модель вводят полиномиальные признаки — степени существующих атрибутов.
- Обычно берут все комбинации факторов до какой-то определенной степени полинома.
- Полиномиальная регрессия может аппроксимировать любую функцию, нужно только подобрать степень полинома.
- Чем больше степень полиномиальной регрессии, тем она сложнее и универсальнее, но вычислительно сложнее (экспоненциально).
Практическое построение регрессии
В данном разделе мы посмотрим, как можно реализовать методы линейной регрессии на практике. Сначала мы попробуем создать алгоритм регрессии с нуля, а затем воспользуемся библиотечной функцией. Это поможет нам более полно понять, как работают модели машинного обучения в целом и в библиотеке sckikit-learn (самом популярном инструменте для создания и обучения моделей на языке программирования Python) в частности.
Для понимания данного раздела предполагаем, что читатель знаком с основами языка программирования Python. Нам понадобится знание его базового синтаксиса, немного — объектно-ориентированного программирования, немного — использования стандартных библиотек и модулей. Никаких продвинутых возможностей языка (типа метапрограммирования или декораторов) мы использовать не будем.
Как должны быть представлены данные для машинного обучения?
Применение любых моделей машинного обучения начинается с подготовки данных в необходимом формате. Для этого очень удобными для нас будут библиотеки numpy и pandas. Они практически всегда используются совместно с библиотекой sckikit-learn и другими инструментами машинного обучения. В первую очередь мы будем использовать numpy для создания массивов и операций с векторами и матрицами. Pandas нам понадобится для работы с табличными структурами — датасетами.
Если вы хотите самостоятельно задать в явном виде данные обучающей выборки, то нет ничего лучше использования обычных массивов ndarray. Обычно в одном массиве хранятся значения атрибутов — x, а в другом — значения целевой переменной — y.
1
2
3
4
5
6
7
8
9
10
11
import numpy as np
x = np.array([1.46, 1.13, -2.30, 1.74, 0.04,
-0.61, 0.32, -0.76, 0.58, -1.10,
0.87, 1.62, -0.53, -0.25, -1.07,
-0.38, -0.17, -0.32, -2.06, -0.88, ])
y = np.array([101.16, 78.44, -159.24, 120.72, 2.92,
-42.33, 22.07, -52.67, 40.32, -76.10,
59.88, 112.38, -36.54, -17.25, -74.24,
-26.57, -11.93, -22.31, -142.54, -60.74,])
Если мы имеем дело с задачей множественной регрессии, то в массиве атрибутов будет уже двумерный массив, состоящий из нескольких векторов атрибутов, вот так:
1
2
3
4
5
x = np.array([
[0, 1, 2, 3, 4],
[5, 4, 9, 6, 3],
[7.8, -0.1, 0.0, -2.14, 10.7],
])
Важно следить за тем, чтобы в массиве атрибутов в каждом вложенном массиве количество элементов было одинаковым и в свою очередь совпадало с количеством элементов в массиве целевой переменной. Это называется соблюдение размерности задачи. Если размерность не соблюдается, то модели машинного обучения будут работать неправильно. А библиотечные функции чаще всего будут выдавать ошибку, связанную с формой массива (shape).
Но чаще всего вы не будете задавать исходные данные явно. Практически всегда их приходится читать из каких-либо входных файлов. Удобнее всего это сделать при помощи библиотеки pandas вот так:
1
2
3
4
import pandas as pd
x = pd.read_csv('x.csv', index_col=0)
y = pd.read_csv('y.csv', index_col=0)
Или, если данные лежат в одном файле в общей таблице (что происходит чаще всего), тогда его читают в один датафрейм, а затем выделяют целевую переменную, и факторные переменные:
1
2
3
4
5
6
7
8
import pandas as pd
data = pd.read_csv('data.csv', index_col=0)
y = data.Y
y = data["Y"]
x = data.drop(["Y"])
Обратите внимание, что матрицу атрибутов проще всего сформировать, удалив из полной таблицы целевую переменную. Но, если вы хотите выбрать только конкретные столбцы, тогда можно использовать более явный вид, через перечисление выбранных колонок.
Если вы используете pandas или numpy для формирования массивов данных, то получившиеся переменные будут разных типов — DataFrame или ndarray, соответственно. Но на дальнейшую работу это не повлияет, так как интерфейс работы с этими структурами данных очень похож. Например, неважно, какие именно массивы мы используем, их можно изобразить на графике вот так:
1
2
3
4
5
import maiplotlib.pyplot as plt
plt.figure()
plt.scatter(x, y)
plt.show()
Конечно, такая визуализация будет работать только в случае задачи парной регрессии. Если x многомерно, то простой график использовать не получится.
Давайте соберем весь наш код вместе:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import numpy as np
import pandas as pd
import maiplotlib.pyplot as plt
# x = pd.read_csv('x.csv', index_col=0)
x = np.array([1.46, 1.13, -2.30, 1.74, 0.04,
-0.61, 0.32, -0.76, 0.58, -1.10,
0.87, 1.62, -0.53, -0.25, -1.07,
-0.38, -0.17, -0.32, -2.06, -0.88, ])
# y = pd.read_csv('y.csv', index_col=0)
y = np.array([101.16, 78.44, -159.24, 120.72, 2.92,
-42.33, 22.07, -52.67, 40.32, -76.10,
59.88, 112.38, -36.54, -17.25, -74.24,
-26.57, -11.93, -22.31, -142.54, -60.74,])
plt.figure()
plt.scatter(x, y)
plt.show()
Это код генерирует вот такой вот график:

Как работает метод машинного обучения “на пальцах”?
Для того, чтобы более полно понимать, как работает метод градиентного спуска для линейной регрессии, давайте реализуем его самостоятельно, не обращаясь к библиотечным методам. На этом примере мы проследим все шаги обучения модели.
Мы будем использовать объектно-ориентированный подход, так как именно он используется в современных библиотеках. Начнем строить класс, который будет реализовывать метод парной линейной регрессии:
1
2
3
4
5
class hypothesis(object):
"""Модель парной линейной регрессии"""
def __init__(self):
self.b0 = 0
self.b1 = 0
Здесь мы определили конструктор класса, который запоминает в полях экземпляра параметры регрессии. Начальные значения этих параметров не очень важны, так как градиентный спуск сойдется из любой точки. В данном случае мы выбрали нулевые, но можно задать любые другие начальные значения.
Реализуем метод, который принимает значение входной переменной и возвращает теоретическое значение выходной — это прямое действие нашей регрессии — метод предсказания результата по факторам (в случае парной регрессии — по одному фактору):
1
2
def predict(self, x):
return self.b0 + self.b1 * x
Название выбрано не случайно, именно так этот метод называется и работает в большинстве библиотечных классов.
Теперь зададим функцию ошибки:
1
2
def error(self, X, Y):
return sum((self.predict(X) - Y)**2) / (2 * len(X))
В данном случае мы используем простую функцию ошибки — среднеквадратическое отклонение (mean squared error, MSE). Можно использовать и другие функции ошибки. Именно вид функции ошибки будет определять то, какой вид регрессии мы реализуем. Существует много разных вариаций простого алгоритма регрессии. О большинстве распространенных методах регрессии можно почитать в официальной документации sklearn.
Теперь реализуем метод градиентного спуска. Он должен принимать массив X и массив Y и обновлять параметры регрессии в соответствии в формулами градиентного спуска:
1
2
3
4
5
6
def BGD(self, X, Y):
alpha = 0.5
dJ0 = sum(self.predict(X) - Y) /len(X)
dJ1 = sum((self.predict(X) - Y) * X) /len(X)
self.b0 -= alpha * dJ0
self.b1 -= alpha * dJ1
О выборе конкретного значения alpha мы говорить пока не будем,на практике его довольно просто подбирают, мы же возьмем нейтральное значение.
Давайте создадим объект регрессии и проверим начальное значение ошибки. В примерах приведены значения на модельном наборе данных, но этот метод можно использовать на любых данных, которые подходят по формату — x и y должны быть одномерными массивами чисел.
1
2
3
4
5
6
7
8
hyp = hypothesis()
print(hyp.predict(0))
print(hyp.predict(100))
J = hyp.error(x, y)
print("initial error:", J)
0
0
initial error: 36271.58344889084
Как мы видим, для начала оба параметра регрессии равны нулю. Конечно, такая модель не дает надежных предсказаний, но в этом и состоит суть метода градиентного спуска: начиная с любого решения мы постепенно его улучшаем и приходим к оптимальному решению.
Теперь все готово к запуску градиентного спуска.
1
2
3
4
5
6
7
8
9
10
hyp.BGD(x, y)
J = hyp.error(x, y)
print("error after gradient descent:", J)
error after gradient descent: 6734.135540194945
X0 = np.linspace(60, 180, 100)
Y0 = hyp.predict(X0)
plt.figure()
plt.scatter(x, y)
plt.plot(X0, Y0, 'r')
plt.show()
Как мы видим, численное значение ошибки значительно уменьшилось. Да и линия на графике существенно приблизилась к точкам. Конечно, наша модель еще далека от совершенства. Мы прошли всего лишь одну итерацию градиентного спуска. Модифицируем метод так, чтобы он запускался в цикле пока ошибка не перестанет меняться существенно:
1
2
3
4
5
6
7
8
9
10
11
12
13
def BGD(self, X, Y, alpha=0.5, accuracy=0.01, max_steps=5000):
step = 0
old_err = hyp.error(X, Y)
new_err = hyp.error(X, Y)
dJ = 1
while (dJ > accuracy) and (step < max_steps):
dJ0 = sum(self.predict(X) - Y) /len(X)
dJ1 = sum((self.predict(X) - Y) * X) /len(X)
self.b0 -= alpha * dJ0
self.b1 -= alpha * dJ1
old_err = new_err
new_err = hyp.error(X, Y)
dJ = abs(old_err - new_err)
Заодно мы проверяем, насколько изменилось значение функции ошибки. Если оно изменилось на величину, меньшую, чем заранее заданная точность, мы завершаем спуск. Таким образом, мы реализовали два стоп-механизма — по количеству итераций и по стабилизации ошибки. Вы можете выбрать любой или использовать оба в связке.
Запустим наш градиентный спуск:
1
2
3
4
5
hyp = hypothesis()
hyp.BGD(x, y)
J = hyp.error(x, y)
print("error after gradient descent:", J)
error after gradient descent: 298.76881676471504
Как мы видим, теперь ошибка снизилась гораздо больше. Однако, она все еще не достигла нуля. Заметим, что нулевая ошибка не всегда возможна в принципе из-за того, что точки данных не всегда будут располагаться на одной линии. Нужно стремиться не к нулевой, а к минимально возможной ошибке.
Посмотрим, как теперь наша регрессия выглядит на графике:
1
2
3
4
5
6
X0 = np.linspace(60, 180, 100)
Y0 = hyp.predict(X0)
plt.figure()
plt.scatter(x, y)
plt.plot(X0, Y0, 'r')
plt.show()

Уже значительно лучше. Линия регрессии довольно похожа на оптимальную. Так ли это на самом деле, глядя на график, сказать сложно, для этого нужно проанализировать, как ошибка регрессии менялась со временем:
Как оценить качество регрессионной модели?
В простых случаях качество модели можно оценить визуально на графике. Но если у вас многомерная задача, это уже не представляется возможным. Кроме того, если ошибка и сама модель меняется незначительно, то очень сложно определить, стало хуже или лучше. Поэтому для диагностики моделей машинного обучения используют кривые.
Самая простая кривая обучения — зависимость ошибки от времени (итерации градиентного спуска). Для того, чтобы построить эту кривую, нам нужно немного модифицировать наш метод обучения так, чтобы он возвращал нужную нам информацию:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
def BGD(self, X, Y, alpha=0.1, accuracy=0.01, max_steps=1000):
steps, errors = [], []
step = 0
old_err = hyp.error(X, Y)
new_err = hyp.error(X, Y) - 1
dJ = 1
while (dJ > accuracy) and (step < max_steps):
dJ0 = sum(self.predict(X) - Y) /len(X)
dJ1 = sum((self.predict(X) - Y) * X) /len(X)
self.b0 -= alpha * dJ0
self.b1 -= alpha * dJ1
old_err = new_err
new_err = hyp.error(X, Y)
dJ = abs(old_err - new_err)
step += 1
steps.append(step)
errors.append(new_err)
return steps, errors
Мы просто запоминаем в массивах на номер шаа и ошибку на каждом шаге. Получив эти данные можно легко построить их на графике:
1
2
3
4
5
6
hyp = hypothesis()
steps, errors = hyp.BGD(x, y)
plt.figure()
plt.plot(steps, errors, 'g')
plt.show()

На этом графике наглядно видно, что в начале обучения ошибка падала быстро, но в ходе градиентного спуска она вышла на плато. Учитывая, что мы используем гладкую функцию ошибки второго порядка, это свидетельствует о том, что мы достигли локального оптимума и дальнейшее повторение алгоритма не принесет улучшения модели.
Если бы мы наблюдали на графике обучения ситуацию, когда по достижении конца обучения ошибка все еще заметно снижалась, это значит, что мы рано прекратили обучение, и нужно продолжить его еще на какое-то количество итераций.
При анализе графиков с библиотечными моделями не получится таких гладких графиков, они больше напоминают случайные колебания. Это из-за того, что в готовых реализациях используется очень оптимизированный вариант метода градиентного спуска. А он может работать с произвольными флуктуациями. В любом случае, нас интересует общий вид этой кривой.
Как подбирать скорость обучения?
В нашей реализации метода градиентного спуска есть один параметр — скорость обучения — который нам приходится так же подбирать руками. Какой смысл автоматизировать подбор параметров линейной регрессии, если все равно приходится вручную подбирать какой-то другой параметр?
На самом деле подобрать скорость обучения гораздо легче. Нужно использовать тот факт, что при превышении определенного порогового значения ошибка начинает возрастать. Кроме того, мы знаем, что скорость обучения должна быть положительна, но меньше единицы. Вся проблема в этом пороговом значении, которое сильно зависит от размерности задачи. При одних данных хорошо работает $ alpha = 0.5 $, а при каких-то приходится уменьшать ее на несколько порядков, например, $ alpha = 0.00000001 $.
Мы еще не говорили о нормализации данных, которая тоже практически всегда применяется при обучении. Она “благотворно” влияет на возможный диапазон значений скорости обучения. При использовании нормализации меньше вероятность, что скорость обучения нужно будет уменьшать очень сильно.
Подбирать скорость обучения можно по следующему алгоритму. Сначала мы выбираем $ alpha $ близкое к 1, скажем, $ alpha = 0.7 $. Производим одну итерацию градиентного спуска и оцениваем, как изменилась ошибка. Если она уменьшилась, то ничего не надо менять, продолжаем спуск как обычно. Если же ошибка увеличилась, то скорость обучения нужно уменьшить. Например, раа в два. После чего мы повторяем первый шаг градиентного спуска. Таким образом мы не начинаем спуск, пока скорость обучения не снизится настолько, чтобы он начал сходиться.
Как применять регрессию с использованием scikit-learn?
Для серьезной работы, все-таки рекомендуется использовать готовые библиотечные решения. Они работаю гораздо быстрее, надежнее и гораздо проще, чем написанные самостоятельно. Мы будем использовать библиотеку scikit-learn для языка программирования Python как наш основной инструмент реализации простых моделей. Сегодня это одна их самых популярных библиотек для машинного обучения. Мы не будем повторять официальную документацию этой библиотеки, которая на редкость подробная и понятная. Наша задача — на примере этих инструментов понять, как работают и как применяются модели машинного обучения.
В библиотеке scikit-learn существует огромное количество моделей машинного обучения и других функций, которые могут понадобиться для их работы. Поэтому внутри самой библиотеки есть много разных пакетов. Все простые модели, например, модель линейной регрессии, собраны в пакете linear_models. Подключить его можно так:
1
from sklearn import linear_model
Надо помнить, что все модели машинного обучения из это библиотеки имеют одинаковый интерфейс. Это очень удобно и универсально. Но это значит, в частности, что все модели предполагают, что массив входных переменных — двумерный, а массивы целевых переменных — одномерный. Отдельного класса для парной регрессии не существует. Поэтому надо убедиться, что наш массив имеет нужную форму. Проще всего для преобразования формы массива использовать метод reshape, например, вот так:
Если вы используете DataFrame, то они обычно всегда настроены правильно, поэтому этого шага может не потребоваться. Важно запомнить, что все методы библиотечных моделей машинного обучения предполагают, что в x будет двумерный массив или DataFrame, а в y, соответственно, одномерный массив или Series.
Эта строка преобразует любой массив в вектор-столбец. Это если у вас один признак, то есть парная регрессия. Если признаков несколько, то вместо 1 следует указать число признаков. -1 на первой позиции означает, что по нулевому измерению будет столько элементов, сколько останется в массиве.
Само использование модели машинного обучения в этой библиотеке очень просто и сводится к трем действиям: создание экземпляра модели, обучение модели методом fit(), получение предсказаний методом predict(). Это общее поведение для любых моделей библиотеки. Для модели парной линейной регрессии нам понадобится класс LinearRegression.
1
2
3
4
5
6
reg = linear_model.LinearRegression()
reg.fit(x, y)
y_pred = reg.predict(x)
print(reg.score(x, y))
print("Коэффициенты: n", reg.coef_)
В этом классе кроме уже упомянутых методов fit() и predict(), которые есть в любой модели, есть большое количество методов и полей для получения дополнительной информации о моделях. Так, практически в каждой модели есть встроенный метод score(), который оценивает качество полученной модели. А поле coef_ содержит коэффициенты модели.
Обратите внимание, что в большинстве моделей коэффициентами считаются именно параметры при входящих переменных, то есть $ b_1, b_2, …, b_n $. Коэффициент $b_0$ считается особым и хранится отдельно в поле intercept_
Так как мы работаем с парной линейной регрессией, результат можно нарисовать на графике:
1
2
3
4
plt.figure(figsize=(12, 9))
plt.scatter(x, y, color="black")
plt.plot(x, y_pred, color="blue", linewidth=3)
plt.show()
Как мы видим, результат ничем не отличается от модели, которую мы обучили сами, вручную:

Соберем код вместе и получим пример довольно реалистичного фрагмента работы с моделью машинного обучение. Примерно такой код можно встретить и в промышленных проектах по интеллектуальному анализу данных:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
from sklearn.linear_model import LinearRegression
x = x.reshape((-1, 1))
reg = LinearRegression()
reg.fit(x, y)
print(reg.score(x, y))
from sklearn.metrics import mean_squared_error, r2_score
y_pred = reg.predict(x)
print("Коэффициенты: n", reg.coef_)
print("Среднеквадратичная ошибка: %.2f" % mean_squared_error(y, y_pred))
print("Коэффициент детерминации: %.2f" % r2_score(y, y_pred))
plt.figure(figsize=(12, 9))
plt.scatter(x, y, color="black")
plt.plot(x, y_pred, color="blue", linewidth=3)
plt.show()