Различие между остатками регрессии и ошибками
1)
![]() ,
,
здесь
![]()
— ошибки.
2)
![]() ,
,
e
– остатки.
В
силу случайности
![]()
и
![]() ,
,
e
является случайным вектором. Обычно
говорят, что e
является оценкой
![]() .
.
При этом, ошибки являются ненаблюдаемой
величиной, а остатки – наблюдаемой.
Мультиколлинеарность
Рассмотрим
модель регрессии:
![]()
X
– матрица данных, Y
– столбец,
![]()
— вектор случайных значений. Тогда оценка
коэффициентов регрессии:
![]() ,
,
точность
оценки рассчитывается по формуле:
![]() .
.
При
описании модели различают два вида
мультиколлинеарности:
-
чистая
или полная мультиколлинеарность: ранг
матрицы X
не полный по столбцам, т.е. меньше k,
или
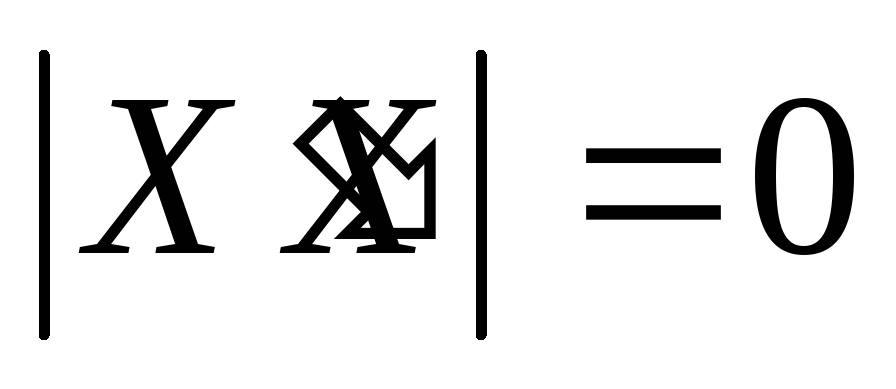 .
.
В этом случае по свойству определителей
имеем чистую линейную зависимость
между строками или столбцами. -
Частичная
или практическая мультиколлинеарность,
т.е. матрица слабо обусловлена, т.е.
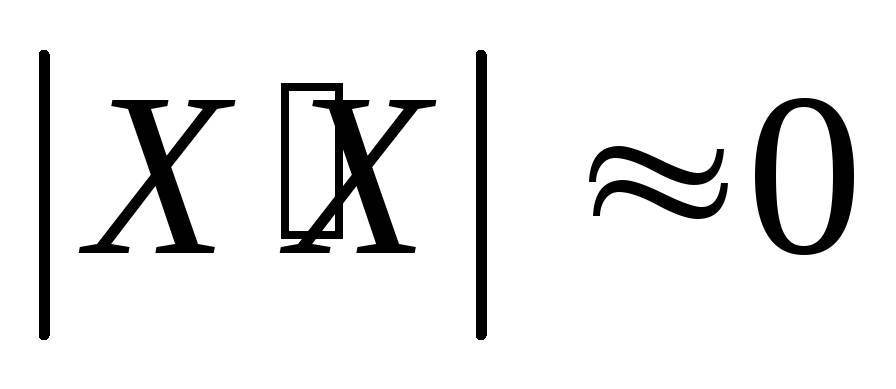 ,
,
таким образом, определитель соизмерим
с ошибкой измерения.
Возможны
домодельные и постмодельные признаки
мультиколлинераности:
|
домодельные |
(i) |
|
(ii) |
|
|
(iii) |
|
|
(i4) |
|
|
постмодельные |
(i5) |
Например,
если модель имеет вид:
![]() ,
,
и
![]() ,
,
между переменными почти линейная связь.
Тогда модель можно записать в одном из
видов:
![]() ,
,
![]() .
.
Итак,
эти три модели одинаковы («неустойчивость»).
По
этой модели возможно прогнозирование,
но точность оценки «расползается». А в
структурном плане, т.е. экономической
интерпретации доверять нельзя.
Одно
из направлений борьбы с мультиколлинеарностью
— переход к смещенному оцениванию
(регуляризация).
Примером
могут служить ridge-оценки
(гребневые оценки). Т.е. оценку параметра
регрессии заменяем оценкой вида:
![]()
Идея
отказа от несмещенности состоит в
следующем:
Если
между факторами существует высокая
корреляция, то нельзя определить их
изолированное влияние на результативный
показатель и параметры уравнения
регрессии оказываются не интерпретируемыми.
Пример.
Рассмотрим регрессию себестоимости
единицы продукции (руб., y)
от заработной платы работника (руб., x)
и производительности его труда (единиц
в час, z):
![]() .
.
Коэффициент
регрессии при переменной z
показывает, что с ростом производительности
труда на 1 ед. себестоимость единицы
продукции снижается в среднем на 10 руб.
при постоянном уровне оплаты труда.
Вместе с тем параметр при x
нельзя интерпретировать как снижение
себестоимости единицы продукции за
счет роста заработной платы. Отрицательное
значение коэффициента регрессии при
переменной x
в данном случае обусловлено высокой
корреляцией между x
и z
(![]() ).
).
Поэтому роста заработной платы при
неизменности производительности труда
не может быть (если не учитывать инфляцию).
Насыщение
модели лишними факторами не только не
снижает величину остаточной дисперсии
и не увеличивает величину остаточной
дисперсии и не увеличивает показатель
детерминации, но и приводит к статистической
незначимости параметров регрессии по
t-критерию
Стьюдента.
Таким
образом, хотя теоретически регрессионная
модель позволяет учесть любое число
факторов, практически в этом нет
необходимости. Отбор факторов обычно
осуществляется в две стадии: на первой
подбираются факторы исходя из сущности
проблемы; на второй – на основе матрицы
показателей корреляции определяют
t—статистики
для параметров регрессии.
Коэффициенты
интеркорреляции (т.е. корреляции между
объясняющими переменными) позволяют
исключать из модели дублирующие факторы.
Считается, что две переменные явно
коллинеарны, т.е. находятся между собой
в линейной зависимости, если
![]() .
.
По
величине парных коэффициентов корреляции
обнаруживается лишь явная коллинеарность
факторов. Наибольшие трудности в
использовании аппарата множественной
регрессии возникают при наличии
мультиколлинеарности факторов, когда
более чем два фактора связаны между
собой линейной зависимостью, т.е. имеет
место совокупное воздействие факторов
друг на друга. В этом случае вариация в
исходных данных перестает быть полностью
независимой, и нельзя оценить воздействие
каждого фактора в отдельности. Чем
сильнее мультиколлинеарность факторов,
тем менее надежна оценка распределения
суммы объясненной вариации по отдельным
факторам с помощью метода наименьших
квадратов.
Включение
в модель мультиколлинеарных факторов
нежелательно в силу следующих причин:
-
затрудняется
интерпретация параметров множественной
регрессии как характеристик действия
факторов в чистом виде, ибо факторы
коррелированны; параметры линейной
регрессии теряют экономический смысл; -
оценки
параметров ненадежны, обнаруживают
большие стандартные ошибки и меняются
с изменением объема наблюдений (не
только по величине, но и по знаку), что
делает модель непригодной для анализа
и прогнозирования.
Мультиколлинеарность
может возникать в силу различных причин.
Например, несколько независимых
переменных могут иметь общий временной
тренд, относительно которого они
совершают малые колебания.
Выделим
некоторые наиболее характерные признаки
мультиколлинеарности:
-
Небольшое
изменение исходных данных (например,
добавление новых наблюдений) приводит
к существенному изменению оценок
коэффициентов модели. -
Оценки
имеют большие стандартные ошибки, малую
значимость, в то время как модель в
целом является значимой (высокой
значение коэффициента детерминации и
соответствующей статистики Фишера). -
Оценки
коэффициентов имеют неправильные с
точки зрения теории знаки или неоправданно
большие значения.
При
столкновении с проблемой мультиколлинеарности
возникает желание отбросить «лишние»
независимые переменные, которые,
возможно, служат ее причиной. Однако,
во-первых, далеко не всегда ясно, какие
переменные являются лишними в указанном
смысле. Во-вторых, во многих ситуациях
удаление какой-либо независимой
переменной может значительно отразится
на содержательном смысле модели.
В-третьих, отбрасывание существенных
переменных, которые реально влияют на
изучаемую зависимую переменную, приводит
к смещенности оценок.
По
такой модели удобно прогнозировать, но
точность прогнозов невысокая.
Итак,
рассмотрим классическую модель в тех
же предположения, что и для парной
регрессии.
![]() .
.
Если
![]() ,
,
то
![]()
— константа.
Все
условия, налагаемее на
![]()
— те же, что и для парной регрессии. Для
вычисления оценок удобно перейти к
матрицам. Будем считать, что в задаче
имеется k
регрессоров.
Направления
борьбы с мультиколлинеарностью:
(а)
переход к смещенному оцениванию
(регуляризация). Например, ridge
– оценки (гребневые оценки). Происходит
замена исходной оценки на следующую:
![]() .
.
Идея,
на которой основан
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
From Wikipedia, the free encyclopedia
In statistics and optimization, errors and residuals are two closely related and easily confused measures of the deviation of an observed value of an element of a statistical sample from its «true value» (not necessarily observable). The error of an observation is the deviation of the observed value from the true value of a quantity of interest (for example, a population mean). The residual is the difference between the observed value and the estimated value of the quantity of interest (for example, a sample mean). The distinction is most important in regression analysis, where the concepts are sometimes called the regression errors and regression residuals and where they lead to the concept of studentized residuals.
In econometrics, «errors» are also called disturbances.[1][2][3]
Introduction[edit]
Suppose there is a series of observations from a univariate distribution and we want to estimate the mean of that distribution (the so-called location model). In this case, the errors are the deviations of the observations from the population mean, while the residuals are the deviations of the observations from the sample mean.
A statistical error (or disturbance) is the amount by which an observation differs from its expected value, the latter being based on the whole population from which the statistical unit was chosen randomly. For example, if the mean height in a population of 21-year-old men is 1.75 meters, and one randomly chosen man is 1.80 meters tall, then the «error» is 0.05 meters; if the randomly chosen man is 1.70 meters tall, then the «error» is −0.05 meters. The expected value, being the mean of the entire population, is typically unobservable, and hence the statistical error cannot be observed either.
A residual (or fitting deviation), on the other hand, is an observable estimate of the unobservable statistical error. Consider the previous example with men’s heights and suppose we have a random sample of n people. The sample mean could serve as a good estimator of the population mean. Then we have:
- The difference between the height of each man in the sample and the unobservable population mean is a statistical error, whereas
- The difference between the height of each man in the sample and the observable sample mean is a residual.
Note that, because of the definition of the sample mean, the sum of the residuals within a random sample is necessarily zero, and thus the residuals are necessarily not independent. The statistical errors, on the other hand, are independent, and their sum within the random sample is almost surely not zero.
One can standardize statistical errors (especially of a normal distribution) in a z-score (or «standard score»), and standardize residuals in a t-statistic, or more generally studentized residuals.
In univariate distributions[edit]
If we assume a normally distributed population with mean μ and standard deviation σ, and choose individuals independently, then we have

and the sample mean

is a random variable distributed such that:

The statistical errors are then

with expected values of zero,[4] whereas the residuals are

The sum of squares of the statistical errors, divided by σ2, has a chi-squared distribution with n degrees of freedom:

However, this quantity is not observable as the population mean is unknown. The sum of squares of the residuals, on the other hand, is observable. The quotient of that sum by σ2 has a chi-squared distribution with only n − 1 degrees of freedom:

This difference between n and n − 1 degrees of freedom results in Bessel’s correction for the estimation of sample variance of a population with unknown mean and unknown variance. No correction is necessary if the population mean is known.
[edit]
It is remarkable that the sum of squares of the residuals and the sample mean can be shown to be independent of each other, using, e.g. Basu’s theorem. That fact, and the normal and chi-squared distributions given above form the basis of calculations involving the t-statistic:

where 



The probability distributions of the numerator and the denominator separately depend on the value of the unobservable population standard deviation σ, but σ appears in both the numerator and the denominator and cancels. That is fortunate because it means that even though we do not know σ, we know the probability distribution of this quotient: it has a Student’s t-distribution with n − 1 degrees of freedom. We can therefore use this quotient to find a confidence interval for μ. This t-statistic can be interpreted as «the number of standard errors away from the regression line.»[6]
Regressions[edit]
In regression analysis, the distinction between errors and residuals is subtle and important, and leads to the concept of studentized residuals. Given an unobservable function that relates the independent variable to the dependent variable – say, a line – the deviations of the dependent variable observations from this function are the unobservable errors. If one runs a regression on some data, then the deviations of the dependent variable observations from the fitted function are the residuals. If the linear model is applicable, a scatterplot of residuals plotted against the independent variable should be random about zero with no trend to the residuals.[5] If the data exhibit a trend, the regression model is likely incorrect; for example, the true function may be a quadratic or higher order polynomial. If they are random, or have no trend, but «fan out» — they exhibit a phenomenon called heteroscedasticity. If all of the residuals are equal, or do not fan out, they exhibit homoscedasticity.
However, a terminological difference arises in the expression mean squared error (MSE). The mean squared error of a regression is a number computed from the sum of squares of the computed residuals, and not of the unobservable errors. If that sum of squares is divided by n, the number of observations, the result is the mean of the squared residuals. Since this is a biased estimate of the variance of the unobserved errors, the bias is removed by dividing the sum of the squared residuals by df = n − p − 1, instead of n, where df is the number of degrees of freedom (n minus the number of parameters (excluding the intercept) p being estimated — 1). This forms an unbiased estimate of the variance of the unobserved errors, and is called the mean squared error.[7]
Another method to calculate the mean square of error when analyzing the variance of linear regression using a technique like that used in ANOVA (they are the same because ANOVA is a type of regression), the sum of squares of the residuals (aka sum of squares of the error) is divided by the degrees of freedom (where the degrees of freedom equal n − p − 1, where p is the number of parameters estimated in the model (one for each variable in the regression equation, not including the intercept)). One can then also calculate the mean square of the model by dividing the sum of squares of the model minus the degrees of freedom, which is just the number of parameters. Then the F value can be calculated by dividing the mean square of the model by the mean square of the error, and we can then determine significance (which is why you want the mean squares to begin with.).[8]
However, because of the behavior of the process of regression, the distributions of residuals at different data points (of the input variable) may vary even if the errors themselves are identically distributed. Concretely, in a linear regression where the errors are identically distributed, the variability of residuals of inputs in the middle of the domain will be higher than the variability of residuals at the ends of the domain:[9] linear regressions fit endpoints better than the middle. This is also reflected in the influence functions of various data points on the regression coefficients: endpoints have more influence.
Thus to compare residuals at different inputs, one needs to adjust the residuals by the expected variability of residuals, which is called studentizing. This is particularly important in the case of detecting outliers, where the case in question is somehow different than the other’s in a dataset. For example, a large residual may be expected in the middle of the domain, but considered an outlier at the end of the domain.
Other uses of the word «error» in statistics[edit]
The use of the term «error» as discussed in the sections above is in the sense of a deviation of a value from a hypothetical unobserved value. At least two other uses also occur in statistics, both referring to observable prediction errors:
The mean squared error (MSE) refers to the amount by which the values predicted by an estimator differ from the quantities being estimated (typically outside the sample from which the model was estimated).
The root mean square error (RMSE) is the square-root of MSE.
The sum of squares of errors (SSE) is the MSE multiplied by the sample size.
Sum of squares of residuals (SSR) is the sum of the squares of the deviations of the actual values from the predicted values, within the sample used for estimation. This is the basis for the least squares estimate, where the regression coefficients are chosen such that the SSR is minimal (i.e. its derivative is zero).
Likewise, the sum of absolute errors (SAE) is the sum of the absolute values of the residuals, which is minimized in the least absolute deviations approach to regression.
The mean error (ME) is the bias.
The mean residual (MR) is always zero for least-squares estimators.
See also[edit]
- Absolute deviation
- Consensus forecasts
- Error detection and correction
- Explained sum of squares
- Innovation (signal processing)
- Lack-of-fit sum of squares
- Margin of error
- Mean absolute error
- Observational error
- Propagation of error
- Probable error
- Random and systematic errors
- Reduced chi-squared statistic
- Regression dilution
- Root mean square deviation
- Sampling error
- Standard error
- Studentized residual
- Type I and type II errors
References[edit]
- ^ Kennedy, P. (2008). A Guide to Econometrics. Wiley. p. 576. ISBN 978-1-4051-8257-7. Retrieved 2022-05-13.
- ^ Wooldridge, J.M. (2019). Introductory Econometrics: A Modern Approach. Cengage Learning. p. 57. ISBN 978-1-337-67133-0. Retrieved 2022-05-13.
- ^ Das, P. (2019). Econometrics in Theory and Practice: Analysis of Cross Section, Time Series and Panel Data with Stata 15.1. Springer Singapore. p. 7. ISBN 978-981-329-019-8. Retrieved 2022-05-13.
- ^ Wetherill, G. Barrie. (1981). Intermediate statistical methods. London: Chapman and Hall. ISBN 0-412-16440-X. OCLC 7779780.
- ^ a b A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ Bruce, Peter C., 1953- (2017-05-10). Practical statistics for data scientists : 50 essential concepts. Bruce, Andrew, 1958- (First ed.). Sebastopol, CA. ISBN 978-1-4919-5293-1. OCLC 987251007.
{{cite book}}: CS1 maint: multiple names: authors list (link) - ^ Steel, Robert G. D.; Torrie, James H. (1960). Principles and Procedures of Statistics, with Special Reference to Biological Sciences. McGraw-Hill. p. 288.
- ^ Zelterman, Daniel (2010). Applied linear models with SAS ([Online-Ausg.]. ed.). Cambridge: Cambridge University Press. ISBN 9780521761598.
- ^ «7.3: Types of Outliers in Linear Regression». Statistics LibreTexts. 2013-11-21. Retrieved 2019-11-22.
- Cook, R. Dennis; Weisberg, Sanford (1982). Residuals and Influence in Regression (Repr. ed.). New York: Chapman and Hall. ISBN 041224280X. Retrieved 23 February 2013.
- Cox, David R.; Snell, E. Joyce (1968). «A general definition of residuals». Journal of the Royal Statistical Society, Series B. 30 (2): 248–275. JSTOR 2984505.
- Weisberg, Sanford (1985). Applied Linear Regression (2nd ed.). New York: Wiley. ISBN 9780471879572. Retrieved 23 February 2013.
- «Errors, theory of», Encyclopedia of Mathematics, EMS Press, 2001 [1994]
External links[edit]
 Media related to Errors and residuals at Wikimedia Commons
Media related to Errors and residuals at Wikimedia Commons
From Wikipedia, the free encyclopedia
In statistics and optimization, errors and residuals are two closely related and easily confused measures of the deviation of an observed value of an element of a statistical sample from its «true value» (not necessarily observable). The error of an observation is the deviation of the observed value from the true value of a quantity of interest (for example, a population mean). The residual is the difference between the observed value and the estimated value of the quantity of interest (for example, a sample mean). The distinction is most important in regression analysis, where the concepts are sometimes called the regression errors and regression residuals and where they lead to the concept of studentized residuals.
In econometrics, «errors» are also called disturbances.[1][2][3]
Introduction[edit]
Suppose there is a series of observations from a univariate distribution and we want to estimate the mean of that distribution (the so-called location model). In this case, the errors are the deviations of the observations from the population mean, while the residuals are the deviations of the observations from the sample mean.
A statistical error (or disturbance) is the amount by which an observation differs from its expected value, the latter being based on the whole population from which the statistical unit was chosen randomly. For example, if the mean height in a population of 21-year-old men is 1.75 meters, and one randomly chosen man is 1.80 meters tall, then the «error» is 0.05 meters; if the randomly chosen man is 1.70 meters tall, then the «error» is −0.05 meters. The expected value, being the mean of the entire population, is typically unobservable, and hence the statistical error cannot be observed either.
A residual (or fitting deviation), on the other hand, is an observable estimate of the unobservable statistical error. Consider the previous example with men’s heights and suppose we have a random sample of n people. The sample mean could serve as a good estimator of the population mean. Then we have:
- The difference between the height of each man in the sample and the unobservable population mean is a statistical error, whereas
- The difference between the height of each man in the sample and the observable sample mean is a residual.
Note that, because of the definition of the sample mean, the sum of the residuals within a random sample is necessarily zero, and thus the residuals are necessarily not independent. The statistical errors, on the other hand, are independent, and their sum within the random sample is almost surely not zero.
One can standardize statistical errors (especially of a normal distribution) in a z-score (or «standard score»), and standardize residuals in a t-statistic, or more generally studentized residuals.
In univariate distributions[edit]
If we assume a normally distributed population with mean μ and standard deviation σ, and choose individuals independently, then we have
and the sample mean
is a random variable distributed such that:
The statistical errors are then
with expected values of zero,[4] whereas the residuals are
The sum of squares of the statistical errors, divided by σ2, has a chi-squared distribution with n degrees of freedom:
However, this quantity is not observable as the population mean is unknown. The sum of squares of the residuals, on the other hand, is observable. The quotient of that sum by σ2 has a chi-squared distribution with only n − 1 degrees of freedom:
This difference between n and n − 1 degrees of freedom results in Bessel’s correction for the estimation of sample variance of a population with unknown mean and unknown variance. No correction is necessary if the population mean is known.
[edit]
It is remarkable that the sum of squares of the residuals and the sample mean can be shown to be independent of each other, using, e.g. Basu’s theorem. That fact, and the normal and chi-squared distributions given above form the basis of calculations involving the t-statistic:
where
The probability distributions of the numerator and the denominator separately depend on the value of the unobservable population standard deviation σ, but σ appears in both the numerator and the denominator and cancels. That is fortunate because it means that even though we do not know σ, we know the probability distribution of this quotient: it has a Student’s t-distribution with n − 1 degrees of freedom. We can therefore use this quotient to find a confidence interval for μ. This t-statistic can be interpreted as «the number of standard errors away from the regression line.»[6]
Regressions[edit]
In regression analysis, the distinction between errors and residuals is subtle and important, and leads to the concept of studentized residuals. Given an unobservable function that relates the independent variable to the dependent variable – say, a line – the deviations of the dependent variable observations from this function are the unobservable errors. If one runs a regression on some data, then the deviations of the dependent variable observations from the fitted function are the residuals. If the linear model is applicable, a scatterplot of residuals plotted against the independent variable should be random about zero with no trend to the residuals.[5] If the data exhibit a trend, the regression model is likely incorrect; for example, the true function may be a quadratic or higher order polynomial. If they are random, or have no trend, but «fan out» — they exhibit a phenomenon called heteroscedasticity. If all of the residuals are equal, or do not fan out, they exhibit homoscedasticity.
However, a terminological difference arises in the expression mean squared error (MSE). The mean squared error of a regression is a number computed from the sum of squares of the computed residuals, and not of the unobservable errors. If that sum of squares is divided by n, the number of observations, the result is the mean of the squared residuals. Since this is a biased estimate of the variance of the unobserved errors, the bias is removed by dividing the sum of the squared residuals by df = n − p − 1, instead of n, where df is the number of degrees of freedom (n minus the number of parameters (excluding the intercept) p being estimated — 1). This forms an unbiased estimate of the variance of the unobserved errors, and is called the mean squared error.[7]
Another method to calculate the mean square of error when analyzing the variance of linear regression using a technique like that used in ANOVA (they are the same because ANOVA is a type of regression), the sum of squares of the residuals (aka sum of squares of the error) is divided by the degrees of freedom (where the degrees of freedom equal n − p − 1, where p is the number of parameters estimated in the model (one for each variable in the regression equation, not including the intercept)). One can then also calculate the mean square of the model by dividing the sum of squares of the model minus the degrees of freedom, which is just the number of parameters. Then the F value can be calculated by dividing the mean square of the model by the mean square of the error, and we can then determine significance (which is why you want the mean squares to begin with.).[8]
However, because of the behavior of the process of regression, the distributions of residuals at different data points (of the input variable) may vary even if the errors themselves are identically distributed. Concretely, in a linear regression where the errors are identically distributed, the variability of residuals of inputs in the middle of the domain will be higher than the variability of residuals at the ends of the domain:[9] linear regressions fit endpoints better than the middle. This is also reflected in the influence functions of various data points on the regression coefficients: endpoints have more influence.
Thus to compare residuals at different inputs, one needs to adjust the residuals by the expected variability of residuals, which is called studentizing. This is particularly important in the case of detecting outliers, where the case in question is somehow different than the other’s in a dataset. For example, a large residual may be expected in the middle of the domain, but considered an outlier at the end of the domain.
Other uses of the word «error» in statistics[edit]
The use of the term «error» as discussed in the sections above is in the sense of a deviation of a value from a hypothetical unobserved value. At least two other uses also occur in statistics, both referring to observable prediction errors:
The mean squared error (MSE) refers to the amount by which the values predicted by an estimator differ from the quantities being estimated (typically outside the sample from which the model was estimated).
The root mean square error (RMSE) is the square-root of MSE.
The sum of squares of errors (SSE) is the MSE multiplied by the sample size.
Sum of squares of residuals (SSR) is the sum of the squares of the deviations of the actual values from the predicted values, within the sample used for estimation. This is the basis for the least squares estimate, where the regression coefficients are chosen such that the SSR is minimal (i.e. its derivative is zero).
Likewise, the sum of absolute errors (SAE) is the sum of the absolute values of the residuals, which is minimized in the least absolute deviations approach to regression.
The mean error (ME) is the bias.
The mean residual (MR) is always zero for least-squares estimators.
See also[edit]
- Absolute deviation
- Consensus forecasts
- Error detection and correction
- Explained sum of squares
- Innovation (signal processing)
- Lack-of-fit sum of squares
- Margin of error
- Mean absolute error
- Observational error
- Propagation of error
- Probable error
- Random and systematic errors
- Reduced chi-squared statistic
- Regression dilution
- Root mean square deviation
- Sampling error
- Standard error
- Studentized residual
- Type I and type II errors
References[edit]
- ^ Kennedy, P. (2008). A Guide to Econometrics. Wiley. p. 576. ISBN 978-1-4051-8257-7. Retrieved 2022-05-13.
- ^ Wooldridge, J.M. (2019). Introductory Econometrics: A Modern Approach. Cengage Learning. p. 57. ISBN 978-1-337-67133-0. Retrieved 2022-05-13.
- ^ Das, P. (2019). Econometrics in Theory and Practice: Analysis of Cross Section, Time Series and Panel Data with Stata 15.1. Springer Singapore. p. 7. ISBN 978-981-329-019-8. Retrieved 2022-05-13.
- ^ Wetherill, G. Barrie. (1981). Intermediate statistical methods. London: Chapman and Hall. ISBN 0-412-16440-X. OCLC 7779780.
- ^ a b A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ Bruce, Peter C., 1953- (2017-05-10). Practical statistics for data scientists : 50 essential concepts. Bruce, Andrew, 1958- (First ed.). Sebastopol, CA. ISBN 978-1-4919-5293-1. OCLC 987251007.
{{cite book}}: CS1 maint: multiple names: authors list (link) - ^ Steel, Robert G. D.; Torrie, James H. (1960). Principles and Procedures of Statistics, with Special Reference to Biological Sciences. McGraw-Hill. p. 288.
- ^ Zelterman, Daniel (2010). Applied linear models with SAS ([Online-Ausg.]. ed.). Cambridge: Cambridge University Press. ISBN 9780521761598.
- ^ «7.3: Types of Outliers in Linear Regression». Statistics LibreTexts. 2013-11-21. Retrieved 2019-11-22.
- Cook, R. Dennis; Weisberg, Sanford (1982). Residuals and Influence in Regression (Repr. ed.). New York: Chapman and Hall. ISBN 041224280X. Retrieved 23 February 2013.
- Cox, David R.; Snell, E. Joyce (1968). «A general definition of residuals». Journal of the Royal Statistical Society, Series B. 30 (2): 248–275. JSTOR 2984505.
- Weisberg, Sanford (1985). Applied Linear Regression (2nd ed.). New York: Wiley. ISBN 9780471879572. Retrieved 23 February 2013.
- «Errors, theory of», Encyclopedia of Mathematics, EMS Press, 2001 [1994]
External links[edit]
- Media related to Errors and residuals at Wikimedia Commons
В статистике и оптимизации ошибки и остатки тесно связаны и легко запутанные меры отклонения наблюдаемого значения элемента статистической выборки от его «теоретического значения». ошибка (или возмущение ) наблюдаемого значения — это отклонение наблюдаемого значения от (ненаблюдаемого) истинного значения интересующей величины (например, среднего генерального значения), и остаток наблюдаемого значения представляет собой разность между наблюдаемым значением и оценочным значением представляющей интерес величины (например, выборочное среднее). Это различие наиболее важно в регрессионном анализе, где концепции иногда называют ошибками регрессии и остатками регрессии, и где они приводят к концепции студентизированных остатков.
Содержание
- 1 Введение
- 2 В одномерных распределениях
- 2.1 Замечание
- 3 Регрессии
- 4 Другие варианты использования слова «ошибка» в статистике
- 5 См. Также
- 6 Ссылки
- 7 Внешние ссылки
Введение
Предположим, есть серия наблюдений из одномерного распределения, и мы хотим оценить среднее этого распределения. (так называемая локационная модель ). В этом случае ошибки — это отклонения наблюдений от среднего по совокупности, а остатки — это отклонения наблюдений от среднего по выборке.
A статистическая ошибка (или нарушение ) — это величина, на которую наблюдение отличается от его ожидаемого значения, последнее основано на всей генеральной совокупности из которого статистическая единица была выбрана случайным образом. Например, если средний рост среди 21-летних мужчин составляет 1,75 метра, а рост одного случайно выбранного мужчины — 1,80 метра, то «ошибка» составляет 0,05 метра; если рост случайно выбранного мужчины составляет 1,70 метра, то «ошибка» составляет -0,05 метра. Ожидаемое значение, являющееся средним для всей генеральной совокупности, обычно ненаблюдаемо, и, следовательно, статистическая ошибка также не может быть обнаружена.
A невязка (или аппроксимирующее отклонение), с другой стороны, представляет собой наблюдаемую оценку ненаблюдаемой статистической ошибки. Рассмотрим предыдущий пример с ростом мужчин и предположим, что у нас есть случайная выборка из n человек. среднее значение выборки может служить хорошей оценкой среднего значения генеральной совокупности. Тогда у нас есть:
- Разница между ростом каждого человека в выборке и ненаблюдаемым средним по совокупности является статистической ошибкой, тогда как
- разница между ростом каждого человека в выборке и наблюдаемой выборкой среднее — это остаток.
Обратите внимание, что из-за определения выборочного среднего, сумма остатков в случайной выборке обязательно равна нулю, и, таким образом, остатки не обязательно независимы. Статистические ошибки, с другой стороны, независимы, и их сумма в случайной выборке почти наверняка не равна нулю.
Можно стандартизировать статистические ошибки (особенно нормального распределения ) в z-балле (или «стандартном балле») и стандартизировать остатки в t-статистика или, в более общем смысле, стьюдентизированные остатки.
в одномерном распределении
Если мы предположим нормально распределенную совокупность со средним μ и стандартным отклонением σ и независимо выбираем людей, тогда мы имеем
- X 1,…, X n ∼ N (μ, σ 2) { displaystyle X_ {1}, dots, X_ {n} sim N ( mu, sigma ^ {2}) ,}

и выборочное среднее
- X ¯ = X 1 + ⋯ + X nn { displaystyle { overline {X}} = {X_ { 1} + cdots + X_ {n} over n}}
— случайная величина, распределенная так, что:
- X ¯ ∼ N (μ, σ 2 n). { displaystyle { overline {X}} sim N left ( mu, { frac { sigma ^ {2}} {n}} right).}
Тогда статистические ошибки
- ei = X i — μ, { displaystyle e_ {i} = X_ {i} — mu, ,}
с ожидаемыми значениями нуля, тогда как остатки равны
- ri = X i — X ¯. { displaystyle r_ {i} = X_ {i} — { overline {X}}.}
Сумма квадратов статистических ошибок, деленная на σ, имеет хи -квадратное распределение с n степенями свободы :
- 1 σ 2 ∑ i = 1 nei 2 ∼ χ n 2. { displaystyle { frac {1} { sigma ^ {2}}} sum _ {i = 1} ^ {n} e_ {i} ^ {2} sim chi _ {n} ^ {2}.}
Однако это количество не наблюдается, так как среднее значение для генеральной совокупности неизвестно. Сумма квадратов остатков, с другой стороны, является наблюдаемой. Частное этой суммы по σ имеет распределение хи-квадрат только с n — 1 степенями свободы:
- 1 σ 2 ∑ i = 1 n r i 2 ∼ χ n — 1 2. { displaystyle { frac {1} { sigma ^ {2}}} sum _ {i = 1} ^ {n} r_ {i} ^ {2} sim chi _ {n-1} ^ { 2}.}
Эта разница между n и n — 1 степенями свободы приводит к поправке Бесселя для оценки выборочной дисперсии генеральной совокупности с неизвестным средним и неизвестной дисперсией. Коррекция не требуется, если известно среднее значение для генеральной совокупности.
Замечание
Примечательно, что сумма квадратов остатков и выборочного среднего могут быть показаны как независимые друг от друга, используя, например, Теорема Басу. Этот факт, а также приведенные выше нормальное распределение и распределение хи-квадрат составляют основу вычислений с использованием t-статистики :
- T = X ¯ n — μ 0 S n / n, { displaystyle T = { frac {{ overline {X}} _ {n} — mu _ {0}} {S_ {n} / { sqrt {n}}}},}
где X ¯ n — μ 0 { displaystyle { overline {X}} _ {n} — mu _ {0}}
- Var (X ¯ n) = σ 2 n { displaystyle operatorname {Var} ({ overline {X}} _ {n}) = { frac { sigma ^ {2}} {n}}}

Распределения вероятностей числителя и знаменателя по отдельности зависят от значения ненаблюдаемого стандартного отклонения генеральной совокупности σ, но σ появляется как в числителе, так и в знаменателе и отменяет. Это удачно, потому что это означает, что, хотя мы не знаем σ, мы знаем распределение вероятностей этого частного: оно имеет t-распределение Стьюдента с n — 1 степенями свободы. Таким образом, мы можем использовать это частное, чтобы найти доверительный интервал для μ. Эту t-статистику можно интерпретировать как «количество стандартных ошибок от линии регрессии».
Регрессии
В регрессионном анализе различие между ошибками и остатками является тонким и важным, и приводит к концепции стьюдентизированных остатков. Для ненаблюдаемой функции, которая связывает независимую переменную с зависимой переменной — скажем, линии — отклонения наблюдений зависимой переменной от этой функции являются ненаблюдаемыми ошибками. Если запустить регрессию на некоторых данных, то отклонения наблюдений зависимой переменной от подобранной функции являются остатками. Если линейная модель применима, диаграмма рассеяния остатков, построенная против независимой переменной, должна быть случайной около нуля без тенденции к остаткам. Если данные демонстрируют тенденцию, регрессионная модель, вероятно, неверна; например, истинная функция может быть квадратичным полиномом или полиномом более высокого порядка. Если они случайны или не имеют тенденции, но «разветвляются» — они демонстрируют явление, называемое гетероскедастичностью. Если все остатки равны или не разветвляются, они проявляют гомоскедастичность.
Однако терминологическое различие возникает в выражении среднеквадратическая ошибка (MSE). Среднеквадратичная ошибка регрессии — это число, вычисляемое из суммы квадратов вычисленных остатков, а не ненаблюдаемых ошибок. Если эту сумму квадратов разделить на n, количество наблюдений, результатом будет среднее квадратов остатков. Поскольку это смещенная оценка дисперсии ненаблюдаемых ошибок, смещение устраняется путем деления суммы квадратов остатков на df = n — p — 1 вместо n, где df — число степеней свободы (n минус количество оцениваемых параметров (без учета точки пересечения) p — 1). Это формирует объективную оценку дисперсии ненаблюдаемых ошибок и называется среднеквадратической ошибкой.
Другой метод вычисления среднего квадрата ошибки при анализе дисперсии линейной регрессии с использованием техники, подобной той, что использовалась в ANOVA (они одинаковы, потому что ANOVA — это тип регрессии), сумма квадратов остатков (иначе говоря, сумма квадратов ошибки) делится на степени свободы (где степени свободы равно n — p — 1, где p — количество параметров, оцениваемых в модели (по одному для каждой переменной в уравнении регрессии, не включая точку пересечения). Затем можно также вычислить средний квадрат модели, разделив сумму квадратов модели за вычетом степеней свободы, которые представляют собой просто количество параметров. Затем значение F можно рассчитать путем деления среднего квадрата модели на средний квадрат ошибки, и затем мы можем определить значимость (вот почему вы хотите, чтобы средние квадраты начинались с.).
Однако из-за поведения процесса регрессии распределения остатков в разных точках данных (входной переменной) могут различаться, даже если сами ошибки распределены одинаково. Конкретно, в линейной регрессии , где ошибки одинаково распределены, изменчивость остатков входных данных в середине области будет выше, чем изменчивость остатков на концах области: линейные регрессии соответствуют конечным точкам лучше среднего. Это также отражено в функциях влияния различных точек данных на коэффициенты регрессии : конечные точки имеют большее влияние.
Таким образом, чтобы сравнить остатки на разных входах, нужно скорректировать остатки на ожидаемую изменчивость остатков, что называется стьюдентизацией. Это особенно важно в случае обнаружения выбросов, когда рассматриваемый случай каким-то образом отличается от другого в наборе данных. Например, можно ожидать большой остаток в середине домена, но он будет считаться выбросом в конце домена.
Другое использование слова «ошибка» в статистике
Использование термина «ошибка», как обсуждалось в разделах выше, означает отклонение значения от гипотетического ненаблюдаемого значение. По крайней мере, два других использования также встречаются в статистике, оба относятся к наблюдаемым ошибкам прогнозирования:
Среднеквадратичная ошибка или Среднеквадратичная ошибка (MSE) и Среднеквадратичная ошибка (RMSE) относятся к величине, на которую значения, предсказанные оценщиком, отличаются от оцениваемых количеств (обычно за пределами выборки, на основе которой была оценена модель).
Сумма квадратов ошибок (SSE или SSe), обычно сокращенно SSE или SS e, относится к остаточной сумме квадратов (сумма квадратов остатков) регрессии; это сумма квадратов отклонений фактических значений от прогнозируемых значений в пределах выборки, используемой для оценки. Это также называется оценкой методом наименьших квадратов, где коэффициенты регрессии выбираются так, чтобы сумма квадратов минимально (т.е. его производная равна нулю).
Аналогично, сумма абсолютных ошибок (SAE) является суммой абсолютных значений остатков, которая минимизирована в наименьшие абсолютные отклонения подход к регрессии.
См. также
 Портал математики
Портал математики
- Абсолютное отклонение
- Консенсус-прогнозы
- Обнаружение и исправление ошибок
- Объясненная сумма квадраты
- Инновация (обработка сигналов)
- Неподходящая сумма квадратов
- Погрешность
- Средняя абсолютная погрешность
- Погрешность наблюдения
- Распространение ошибки
- Вероятная ошибка
- Случайные и систематические ошибки
- Разбавление регрессии
- Среднеквадратичное отклонение
- Ошибка выборки
- Стандартная ошибка
- Стьюдентизированная невязка
- Ошибки типа I и типа II
Ссылки
- Кук, Р. Деннис; Вайсберг, Сэнфорд (1982). Остатки и влияние на регресс (Отредактированный ред.). Нью-Йорк: Чепмен и Холл. ISBN 041224280X. Проверено 23 февраля 2013 г.
- Кокс, Дэвид Р. ; Снелл, Э. Джойс (1968). «Общее определение остатков». Журнал Королевского статистического общества, серия B. 30(2): 248–275. JSTOR 2984505.
- Вайсберг, Сэнфорд (1985). Прикладная линейная регрессия (2-е изд.). Нью-Йорк: Вили. ISBN 9780471879572. Проверено 23 февраля 2013 г.
- , Энциклопедия математики, EMS Press, 2001 [1994]
Внешние ссылки
- СМИ, связанные с ошибками и остатками на Викимедиа Commons
| Часть серии по |
| Регрессивный анализ |
|---|
 |
| Модели |
|
|
|
|
|
| Оценка |
|
|
|
|
| Фон |
|
|
В статистике и оптимизации ошибки и остатки являются двумя тесно связанными и легко путаемыми мерами отклонения наблюдаемого значения элемента статистической выборки от его «теоретического значения». В ошибка (или же беспокойство) наблюдаемого значения — это отклонение наблюдаемого значения от (ненаблюдаемого) истинный значение интересующей величины (например, среднее значение генеральной совокупности), и остаточный наблюдаемого значения — это разница между наблюдаемым значением и по оценкам значение интересующей величины (например, выборочное среднее). Это различие наиболее важно в регрессионном анализе, где концепции иногда называют ошибки регрессии и остатки регрессии и где они приводят к концепции стьюдентизированных остатков.
Вступление
Предположим, что есть серия наблюдений из одномерное распределение и мы хотим оценить иметь в виду этого распределения (так называемый модель местоположения ). В этом случае ошибки — это отклонения наблюдений от среднего по совокупности, а остатки — это отклонения наблюдений от среднего по выборке.
А статистическая ошибка (или же беспокойство) — это величина, на которую наблюдение отличается от ожидаемое значение, последнее основано на численность населения из которого статистическая единица была выбрана случайным образом. Например, если средний рост среди 21-летних мужчин составляет 1,75 метра, а рост одного случайно выбранного мужчины — 1,80 метра, то «ошибка» составляет 0,05 метра; если рост случайно выбранного мужчины составляет 1,70 метра, то «ошибка» составляет -0,05 метра. Ожидаемое значение, являющееся иметь в виду всего населения, обычно не наблюдается, и, следовательно, статистическая ошибка также не может быть обнаружена.
А остаточный (или подходящее отклонение), с другой стороны, является наблюдаемым оценивать ненаблюдаемой статистической ошибки. Рассмотрим предыдущий пример с ростом мужчин и предположим, что у нас есть случайная выборка п люди. В выборочное среднее может служить хорошей оценкой численность населения иметь в виду. Тогда у нас есть:
- Разница между ростом каждого человека в выборке и ненаблюдаемой численность населения означает это статистическая ошибка, в то время как
- Разница между ростом каждого человека в выборке и наблюдаемым образец означает это остаточный.
Обратите внимание, что из-за определения выборочного среднего, сумма остатков в случайной выборке обязательно равна нулю, и, следовательно, остатки обязательно нет независимый. Статистические ошибки, с другой стороны, независимы, и их сумма в пределах случайной выборки равна почти наверняка не ноль.
Можно стандартизировать статистические ошибки (особенно нормальное распределение ) в z-оценка (или «стандартная оценка») и стандартизируйте остатки в т-статистический, или в более общем смысле стьюдентизированные остатки.
В одномерных распределениях
Если предположить нормально распределенный совокупность со средними μ и стандартное отклонение σ, и выбираем индивидуумов независимо, то имеем
и выборочное среднее
случайная величина, распределенная таким образом, что:
В статистические ошибки тогда
с ожидал значения нуля,[1] тогда как остатки находятся
Сумма квадратов статистические ошибки, деленное на σ2, имеет распределение хи-квадрат с п степени свободы:
Однако это количество не наблюдается, так как среднее значение для населения неизвестно. Сумма квадратов остатки, с другой стороны, наблюдается. Частное этой суммы по σ2 имеет распределение хи-квадрат только с п — 1 степень свободы:
Эта разница между п и п — 1 степень свободы дает Поправка Бесселя для оценки выборочная дисперсия популяции с неизвестным средним и неизвестной дисперсией. Коррекция не требуется, если известно среднее значение для генеральной совокупности.
Примечательно, что сумма квадратов остатков и средние выборочные значения могут быть показаны как независимые друг от друга, используя, например, Теорема Басу. Этот факт, а также приведенные выше нормальное распределение и распределение хи-квадрат составляют основу расчетов, включающих t-статистика:
куда
Распределения вероятностей числителя и знаменателя по отдельности зависят от значения ненаблюдаемого стандартного отклонения совокупности σ, но σ появляется как в числителе, так и в знаменателе и отменяется. Это удачно, потому что это означает, что даже если мы не знаемσ, мы знаем распределение вероятностей этого частного: оно имеет Распределение Стьюдента с п — 1 степень свободы. Поэтому мы можем использовать это частное, чтобы найти доверительный интервал заμ. Эту t-статистику можно интерпретировать как «количество стандартных ошибок от линии регрессии».[3]
Регрессии
В регрессивный анализ, различие между ошибки и остатки тонкий и важный, и ведет к концепции стьюдентизированные остатки. При наличии ненаблюдаемой функции, которая связывает независимую переменную с зависимой переменной — скажем, линии — отклонения наблюдений зависимой переменной от этой функции являются ненаблюдаемыми ошибками. Если запустить регрессию на некоторых данных, то отклонения наблюдений зависимой переменной от приспособленный функции — остатки. Если применима линейная модель, диаграмма рассеяния остатков, построенная против независимой переменной, должна быть случайной около нуля без тенденции к остаткам.[2] Если данные демонстрируют тенденцию, регрессионная модель, вероятно, неверна; например, истинная функция может быть квадратичным полиномом или полиномом более высокого порядка. Если они случайны или не имеют тенденции, но «разветвляются» — они демонстрируют явление, называемое гетероскедастичность. Если все остатки равны или не разветвляются, они демонстрируют гомоскедастичность.
Однако возникает терминологическая разница в выражении среднеквадратичная ошибка (MSE). Среднеквадратичная ошибка регрессии — это число, вычисляемое из суммы квадратов вычисленных остатки, а не ненаблюдаемые ошибки. Если эту сумму квадратов разделить на п, количество наблюдений, результат — это среднее квадратов остатков. Поскольку это пристрастный Для оценки дисперсии ненаблюдаемых ошибок смещение устраняется путем деления суммы квадратов остатков на df = п − п — 1 вместо п, куда df это количество степени свободы (п минус количество оцениваемых параметров (без учета точки пересечения) p — 1). Это формирует несмещенную оценку дисперсии ненаблюдаемых ошибок и называется среднеквадратической ошибкой.[4]
Другой метод вычисления среднего квадрата ошибки при анализе дисперсии линейной регрессии с использованием техники, подобной той, что использовалась в ANOVA (они такие же, потому что ANOVA — это тип регрессии), сумма квадратов остатков (иначе говоря, сумма квадратов ошибки) делится на степени свободы (где степени свободы равны п − п — 1, где п — количество параметров, оцениваемых в модели (по одному для каждой переменной в уравнении регрессии, не включая точку пересечения). Затем можно также вычислить средний квадрат модели, разделив сумму квадратов модели за вычетом степеней свободы, которые представляют собой просто количество параметров. Затем значение F можно рассчитать, разделив средний квадрат модели на средний квадрат ошибки, и затем мы можем определить значимость (вот почему вы хотите, чтобы средние квадраты начинались с).[5]
Однако из-за поведения процесса регрессии распределения остатков в разных точках данных (входной переменной) может отличаться даже если сами ошибки одинаково распределены. Конкретно в линейная регрессия где ошибки одинаково распределены, вариативность остатков входных данных в середине области будет выше чем изменчивость остатков на концах области:[6] линейные регрессии лучше подходят для конечных точек, чем средние. Это также отражено в функции влияния различных точек данных на коэффициенты регрессии: конечные точки имеют большее влияние.
Таким образом, чтобы сравнить остатки на разных входах, необходимо скорректировать остатки на ожидаемую изменчивость остатки, который называется студенчество. Это особенно важно в случае обнаружения выбросы, где рассматриваемый случай чем-то отличается от другого случая в наборе данных. Например, можно ожидать большой остаток в середине домена, но он будет считаться выбросом в конце домена.
Другое использование слова «ошибка» в статистике
Термин «ошибка», как обсуждалось в предыдущих разделах, используется в смысле отклонения значения от гипотетического ненаблюдаемого значения. По крайней мере, два других использования также встречаются в статистике, оба относятся к наблюдаемым ошибкам прогнозирования:
Средняя квадратичная ошибка или же среднеквадратичная ошибка (MSE) и Средняя квадратическая ошибка (RMSE) относятся к количеству, на которое значения, предсказанные оценщиком, отличаются от оцениваемых количеств (обычно за пределами выборки, на основе которой была оценена модель).
Сумма квадратов ошибок (SSE или же SSе), обычно сокращенно SSE или SSе, относится к остаточная сумма квадратов (сумма квадратов остатков) регрессии; это сумма квадратов отклонений фактических значений от прогнозируемых значений в пределах выборки, используемой для оценки. Это также называется оценкой наименьших квадратов, когда коэффициенты регрессии выбираются таким образом, чтобы сумма квадратов была минимальной (т. Е. Ее производная равна нулю).
Точно так же сумма абсолютных ошибок (SAE) — сумма абсолютных значений остатков, которая минимизируется в наименьшие абсолютные отклонения подход к регрессу.
Смотрите также
- Абсолютное отклонение
- Консенсус-прогнозы
- Обнаружение и исправление ошибок
- Объясненная сумма квадратов
- Инновации (обработка сигналов)
- Неподходящая сумма квадратов
- Допустимая погрешность
- Средняя абсолютная ошибка
- Ошибка наблюдения
- Распространение ошибки
- Вероятная ошибка
- Случайные и систематические ошибки
- Разбавление регрессии
- Среднеквадратичное отклонение
- Ошибка выборки
- Стандартная ошибка
- Студентизованный остаток
- Ошибки типа I и типа II
Рекомендации
- ^ Уэзерилл, Дж. Барри. (1981). Промежуточные статистические методы. Лондон: Чепмен и Холл. ISBN 0-412-16440-Х. OCLC 7779780.
- ^ а б Современное введение в вероятность и статистику: понимание, почему и как. Деккинг, Мишель, 1946-. Лондон: Спрингер. 2005 г. ISBN 978-1-85233-896-1. OCLC 262680588.CS1 maint: другие (связь)
- ^ Брюс, Питер С., 1953- (2017-05-10). Практическая статистика для специалистов по данным: 50 основных концепций. Брюс, Эндрю, 1958- (Первое изд.). Севастополь, Калифорния. ISBN 978-1-4919-5293-1. OCLC 987251007.CS1 maint: несколько имен: список авторов (связь)
- ^ Steel, Robert G.D .; Торри, Джеймс Х. (1960). Принципы и процедуры статистики с особым акцентом на биологические науки. Макгроу-Хилл. п.288.
- ^ Зельтерман, Даниэль (2010). Прикладные линейные модели с SAS ([Online-Ausg.]. Ред.). Кембридж: Издательство Кембриджского университета. ISBN 9780521761598.
- ^ «7.3: Типы выбросов в линейной регрессии». Статистика LibreTexts. 2013-11-21. Получено 2019-11-22.
- Кук, Р. Деннис; Вайсберг, Сэнфорд (1982). Остатки и влияние на регресс (Ред. Ред.). Нью-Йорк: Чепмен и Холл. ISBN 041224280X. Получено 23 февраля 2013.
- Кокс, Дэвид Р.; Снелл, Э. Джойс (1968). «Общее определение остатков». Журнал Королевского статистического общества, серия B. 30 (2): 248–275. JSTOR 2984505.
- Вайсберг, Сэнфорд (1985). Прикладная линейная регрессия (2-е изд.). Нью-Йорк: Вили. ISBN 9780471879572. Получено 23 февраля 2013.
- «Ошибки, теория», Энциклопедия математики, EMS Press, 2001 [1994]
внешняя ссылка
- СМИ, связанные с Ошибки и остатки в Wikimedia Commons
Что нужно знать о линейной регрессии
Прежде чем приступать к обсуждению преимуществ линейной регрессии, вам, возможно, будет полезно вспомнить наши публикации о таких технологиях машинного обучения как нейронные сети и метод опорных векторов. Мы уже говорили о том, что, при всех их достоинствах, они не всегда идеально подходят для создания моделей. Модели, созданные на основе машинного обучения, отличаются большой размерностью и сложностью интерпретации. Несмотря на то, что они обладают большой производительностью, и часто являются единственным решением сложных задач, у них есть и свои недостатки. В частности, не так просто их понять и оценить их валидность.
Например, представим, что физику необходимо расшифровать модель взаимодействия частиц. Если он создаст для этого нейронную сеть, такая модель будет обладать большой точностью, но понять ее человеку будет нелегко, и она не приблизит его к пониманию законов природы, которым подчиняются частицы. Экономисту важнее понять общий характер взаимодействия таких факторов, как исход выборов, политическая нестабильность и нестабильность финансовых рынков, вместо того чтобы создавать сложную модель взаимного влияния этих факторов друг на друга, которая не позволит сделать обобщения, универсально применимые в отношении системы управления, предвыборной кампании и рынка. Поэтому не раз вам придется отказываться от мощных, но при этом необузданных, технологий машинного обучения в пользу традиционных методов статистического моделирования, главный из которых – линейная регрессия.
Что такое “линейная регрессия”?
Линейная регрессия – один из самых простых инструментов статистического моделирования, но именно в его простоте и заключается его эффективность. Для начала необходимо понять значение термина. В упрощенном виде регрессионный анализ можно определить как способ описания взаимоотношений между зависимой переменной и набором независимых переменных. Например, с помощью этого метода при наличии набора данных о росте, весе, поле и других физических параметрах ребенка, мы можем описать влияние этих переменных на целевую переменную – рост этого человека во взрослом возрасте.
![]()
Что значит сам термин “регрессия?” В основном, это просто дань традиции: он возник несколько веков назад и прочно закрепился в обиходе. Наверняка, вам знаком термин “регрессия к среднему значению”. За ним скрывается мысль о том, что данные могут отклоняться от ожидаемого “среднего” значения, но, если наблюдений много, они возвращаются или “регрессируют” к прогнозируемому значению. Например, у высокого человека почти наверняка будут высокие дети. Они могут “регрессировать” к среднему значению роста, но вряд ли окажутся выше своего родителя.
Обратите внимание на то, что регрессия моделирует числовые отношения, т.е. выходные данные регрессионного анализа – всегда число. Этим он отличается от категоризации, результатом которой является класс объектов или метка для исходных данных. Вторая часть термина “линейная регрессия” подчеркивает линейный характер зависимости между переменными.
Обратимся к известному примеру с данными о разных сортах цветков ириса. Рассмотрим зависимость между длиной чашелистика и длиной лепестка цветов сорта Virginica. Линейная регрессия определит зависимость этих двух переменных с помощью линии наилучшего соответствия.
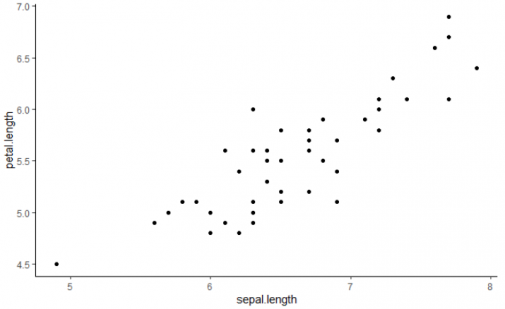
На рисунке ниже очевидна линейная зависимость данных: при увеличении длины чашелистика увеличивается и длина лепестка. Линейная регрессия создает линейное уравнение, которое является моделью системы.
Результат этой регрессии отображается на графике вместе с данными. Линия на графике есть результат модели, спрогнозировавшей длину лепестка в зависимости от длины чашелистика. Конечно, существует вероятность ошибки, которая связана с вариативностью данных, но в целом модель точна. Уравнение зависимости выглядит следующим образом:
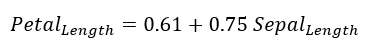
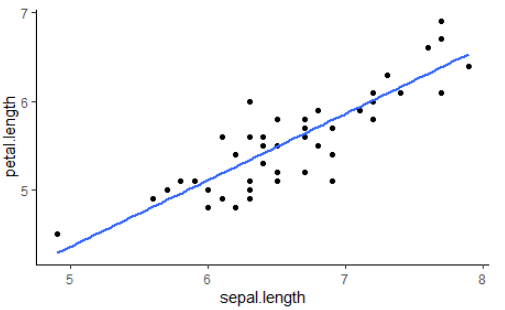
Результат такого метода моделирования легко поддается анализу и интерпретации, и может быть весьма полезен. Уравнение говорит о том, что для ирисов сорта Virginica на каждый дополнительный сантиметр длины чашелистика приходится дополнительных 0.75 сантиметров лепестка.
Как рассчитывается линейная модель?
Теперь вы наверно можете наглядно представить себе вид линейной регрессии. Наша модель выглядит следующим образом:
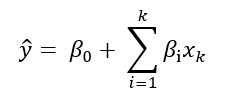
Прогнозируемое значение целевой переменной выражается в виде суммы постоянного смещения и взвешенной суммы исходных переменных. Далеко не всегда линейная модель будет такой же ровной, как в нашем случае. Нам необходим способ оценки качества модели. В связи с этим приходится говорить об ошибках или “остатках” регрессии. Для каждой точки данных нам необходимо определить разность между наблюдаемым значением и значением, предсказанным регрессионной моделью. Есть несколько способов это сделать, но наиболее часто используемый способ – остаточная сумма квадратов (анг. Residual Sum of Squares (RSS)). Часто возникает вопрос, почему разность между реальным и прогнозируемым значением обозначается термином “остаток регрессии”, вместо того чтобы называть ее просто ошибкой. В данной статье вы не найдете исчерпывающего ответа на данный вопрос, поскольку это – предмет отдельной, сугубо специальной беседы. Но в общих чертах можно сказать, что эта разница по большому счету “ошибкой” не является. При создании модели мы всегда прекрасно понимаем, что в распределении целевой переменной может присутствовать некоторая неравномерность. Полное уравнение линейной модели содержит шумовую составляющую, которая представляет собой гауссовскую случайную величину с нулевым средним значением, и стандартное отклонение, определяемое моделью. Таким образом, “остатки регрессии” это и есть та самая шумовая составляющая. В нашем случае остаточная сумма квадратов равна:
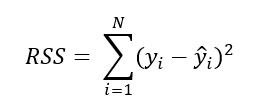
Теперь, когда мы можем измерить эффективность модели, у нас есть возможность сравнить разные линии и выбрать линию наилучшего соответствия. RSS позволяет определить степень вариативности данных на расстоянии от нашей линии. Линия наилучшего соответствия имеет наименьшее значение RSS. Математический метод, основанный на минимизации суммы квадратов отклонений некоторых функций от искомых переменных, называется методом наименьших квадратов (анг. Ordinary Least Squares (OLS)). Именно он позволит решить стоящую перед нами задачу.
Оценка качества линейной модели
Вы выдели, как определяются условия линейной модели путем минимизации уравнения остатка регрессии (уравнения невязки), но сама модель пока еще не завершена. В отличие от моделей машинного обучения, которые могут содержать миллионы скрытых параметров, каждый параметр линейной регрессии можно подвергнуть анализу. Модель регрессии создает несколько метрик, которые могут быть использованы в дальнейшем. Прежде всего, это R2 , или коэффициент детерминации. R2 позволяет измерить, насколько модель может объяснить дисперсию данных. Если R-квадрат равен 1, это значит, что модель описывает все данные. Если же R-квадрат равен 0,5, модель объясняет лишь 50% дисперсии данных. Оставшиеся отклонения не имеют объяснения. Чем ближе R2 к единице, тем лучше.

Кроме того, для каждого коэффициента в модели мы можем рассчитать p-величину для того, чтобы определить статистическую значимость оценки. Если p-величины большие, стоит задуматься о том, стоит ли включать такие переменные в модель, поскольку они могут быть бесполезны. Вместо того, чтобы удалять созданную модель, рекомендуется добавлять по одной переменной за один раз, а затем проверять, как изменилась статистическая значимость модели после добавления переменной. Такой подход называют дисперсионным анализом AnoVa (анг. Analysis of Variance). Еще один способ проверки модели состоит в анализе распределения остатков регрессии. В идеале они должны иметь нормальное распределение и быть гомоскедастическими, т.е. они должны сохранять более или менее постоянную дисперсию для подобранных значений и исходных данных модели. Важно, чтобы остаток регрессии был одинаковым по всем данным, поскольку это гарантирует четкую отработку модели.

Модель линейной регрессии легко понять и интерпретировать по сравнению с другими методами моделирования данных.
Гибкость модели линейной регрессии
Главный недостаток линейной регрессии состоит в том, что она может моделировать только прямые линейные зависимости, в то время как часто возникает необходимость создания модели других типов отношений между данными. К счастью, существуют простые способы отображения данных, между которыми нет линейной зависимости, с помощью линейной регрессии. Первый способ – преобразование исходных данных. Вместо того, чтобы использовать переменные для создания модели в их исходном виде, на практике часто приходится использовать различные преобразования, такие как определение логарифма значений или возведение в степень. Даже если между значениями нет прямой линейной зависимости, она может существовать между логарифмами этих значений. В таком случае модель покажет, что при увеличении зависимой переменной на 1% целевая переменная увеличится на X%.
Другой способ предполагает включение в модель квадратных членов. Для этого данные возводятся в квадрат и добавляются в уравнение как дополнительная переменная. Еще одна технология преобразования данных предполагает учет взаимодействия предикторов, когда исходные переменные рассматриваются в комбинациях. Например, если в модель добавить такие переменные как Пол и Рост, в модель можно включить объединенный член Пол:Рост. Фактически при этом создаются две новые переменные – Мужчина:Рост (она будет добавлять в модель только рост мужчин) и Женщина:Рост (рост женщин). Такое взаимодействие предикторов позволит создать модель зависимости роста от пола отдельно для женщин и для мужчин.
Эффективность модели линейной регрессии
Модели линейной регрессии очень популярны в различных сферах исследований благодаря быстроте их создания и простоте интерпретации. Благодаря возможности преобразования данных, они могут быть использованы для моделирования широкого спектра зависимостей. Благодаря простоте формы, по сравнению с нейронными сетями, их статистические параметры легко поддаются анализу и сравнению, что позволяет извлекать из них ценную информацию. Линейная регрессия используется не только в прогностических целях; она также показала свою эффективность в описании систем. Если вы хотите смоделировать значения числовой переменной, у вас имеется относительно небольшой список независимых переменных, и вы рассчитываете на то, что модель будет вам понятна, вы, скорее всего, выберете именно линейную регрессию в качестве инструмента моделирования. Система PolyAnalyst предлагает пользователям возможность сравнить разные инструменты моделирования и выбрать ту технологию, которая оптимально подходит для использования с конкретными исходными данными.
Related Articles
Июль 15, 2020
Что такое “анализ временных рядов”?
Апрель 29, 2020
Что нужно знать о линейной регрессии
Февраль 12, 2020
Совместное использование правил и машинного обучения
[c.109]
У = /( /) +е/, = , п, (1.5) где ошибки регрессии удовлетворяют условиям
[c.15]
Модели временных рядов, как правило, оказываются сложнее моделей пространственной выборки, так как наблюдения в случае временного ряда вообще говоря не являются независимыми, а это значит, что ошибки регрессии могут коррелировать друг с другом, т. е. условие (1.4) вообще говоря не выполняется. В последующих главах мы увидим, что невыполнение условия (1.4) значительно усложняет статистический анализ модели.
[c.16]
В число регрессоров в моделях временных рядов могут быть включены и константа, и временной тренд, и какие-либо другие объясняющие переменные. Ошибки регрессии могут коррелировать между собой, однако, мы предполагаем, что остатки регрессии образуют стационарный временной ряд.
[c.179]
Рассмотрим отдельно три случая. 1. Регрессоры Хи ошибки регрессии е не коррелируют, т. е. генеральная ковариация ov (xi )=0 для всех s, t = I,…, n.
[c.192]
Значения регрессоров X не коррелированы с ошибками регрессии Е в данный момент времени, но коррелируют с ошибками регрессии в более ранние моменты времени t — т.
[c.193]
Насколько достоверны полученные результаты Очевидно, и доставка сырья в город В, и доставка конечного продукта в город С связаны с перевозками, а значит, такие факторы, как затраты на топливо, зарплата водителей, состояние дорог и т. д. будут влиять и на формирование цены X, и на конечную цену Y при заданном А, т. е. на величину ошибок регрессии модели. Таким образом, регрессоры и ошибки регрессии оказываются коррелированными, и оценки, полученные методом наименьших квадратов, несостоятельны.
[c.195]
Переменные Xj не коррелируют с ошибками регрессии, так как линейно выражаются через инструментальные переменные Z, …, Ze. Рассмотрим Xj как новые инструментальные переменные.
[c.198]
В следующем параграфе мы опишем еще некоторые возможные способы оценивания моделей, в которых регрессоры коррелируют с ошибками регрессии.
[c.199]
Приведенные здесь выкладки можно почти дословно повторить и в том случае, если в модели присутствует объясняющая переменная X, не коррелирующая с ошибками регрессии. Приведем их окончательный результат. Оценка (8.20) сходится по вероятности к величине вида
[c.202]
Явный вид (8.44) случайного члена показывает, что имеет место корреляция между лаговой переменной Yt и ошибкой регрессии е то есть оценки метода наименьших квадратов не будут состоятельными.
[c.208]
Будем предполагать, что ошибки регрессии , независимы и
[c.219]
Считается, что ошибки регрессии представляют собой стационарный авторегрессионный процесс первого порядка. Можно ли сделать вывод, что коэффициент Я. а) больше 0,5 б) больше 0,7 Объем выборки достаточно велик.
[c.222]
С математической точки зрения, главное отличие между экзогенными и эндогенными переменными заключается в том, что экзогенные переменные не коррелируют с ошибками регрессии, между тем как эндогенные могут коррелировать (и, как правило, коррелируют). Естественно предположить, что схожие случайные факторы действуют как на цену равновесия, так и на спрос на товар. Причинная зависимость между переменными и приводит, очевидно, к коррелированности их со случайными членами.
[c.225]
Замену в структурной форме системы YJ на Yf иногда называют очищением эндогенной переменной. При этом удаляется та часть переменной, которая коррелирует с ошибками регрессии.
[c.234]
При изучении литературы оказывается, что ошибка регрессии вызывает самую сильную критику метода анализа по множеству объектов. Спорят, что производимая (и продаваемая) каждой фирмой продукция обычно является случайной переменной и колебания выпускаемой продукции вокруг среднего значения не контролируются фирмой. Фирма определит наилучший способ распределения выпускаемой продукции. По словам Фридмена, если нет переменных затрат, то исследование на множестве объектов продемонстрирует резкое снижение средних затрат. Когда фирмы классифицируются по действительному выпуску продукции, тогда возникает именно такой тип смещения. Фирмы с наивысшими объемами выпуска вряд ли будут производить продукцию на непривычно низком уровне в среднем они явно скорее будут выпускать продукцию на необычно высоком уровне в отличие от тех, чей уровень выпуска является самым низким [39]. Эта критика была широко принята. Были предприняты попытки избежать ошибки регрессии путем классификации фирм по предприятиям и проверкой значимости внутризаводской и межзаводской регрессии [11]. С другой стороны, спорили, что если выпускаемая продукция является случайной переменной, то оценочной кривой затрат для принятия решения будет кривая ожидаемых затрат, а не кривая затрат, вызываемых случайными изменениями объемов выпуска [94]. Кривые ожидаемых затрат будут более пологими, чем исходные кривые. Поскольку учетный период обычно включает в себя много единичных экономических периодов, имеющиеся реально в наличии данные в основном будут приближаться к ожидаемому объему выпуска. Если данное положение справедливо, то это дает начало объяснению того, почему в оцененных кривых затрат наблюдается почти линейность и почему следует более серьезно воспринимать результаты этих исследований.
[c.192]
Как определяются стандартные ошибки регрессии и коэффициентов регрессии [c.135]
Как и в случае парной регрессии, S = л/S2 называется стандартной ошибкой регрессии. Sb =Л/8Ь. называется стандартной ошибкой коэффициента регрессии.
[c.151]
Тогда стандартная ошибка регрессии S = 1.7407. Следовательно, дисперсии и стандартные ошибки коэффициентов равны [c.170]
Вычислите величину стандартной ошибки регрессии, если
[c.175]
В ряде случаев проблема мультиколлинеарности может быть решена изменением спецификации модели либо изменением формы модели, либо добавлением объясняющих переменных, которые не учтены в первоначальной модели, но существенно влияющие на зависимую переменную. Если данный метод имеет основания, то его использование уменьшает сумму квадратов отклонений, тем самым сокращая стандартную ошибку регрессии. Это приводит к уменьшению стандартных ошибок коэффициентов.
[c.252]
Отношение стандартной ошибки регрессии к среднему значению
[c.327]
Yt = Yt + t — о + bXt + t- He следует путать остатки регрессии с ошибками регрессии в уравнении модели Yt = a+bXt+ t- Остатки et, так же как и ошибки t, являются случайными величинами, однако разница состоит в том, что остатки, в отличие от ошибок, наблюдаемы.
[c.44]
Ошибки регрессии t независимы и распределены по нормальному закону [c.56]
Д2=0.8921, Д =0.8892, стандартная ошибка регрессии 0.2013.
[c.87]
Тест Голдфелда—Квандта. Этот тест применяется в том случае, если ошибки регрессии можно считать нормально распределенными случайными величинами.
[c.159]
Чаще всего функция / выбирается квадратичной, что соответствует тому, что средняя квадратическая ошибка регрессии зависит от наблюдаемых значений регрессоров приближенно линейно. Гомоскедастичной выборке соответствует случай /= onst.
[c.161]
Как видно, значимым оказывается только регрессор е , т. е. существенное влияние на результат наблюдения е, оказывает только одно предыдущее значение е . Положительность оценки соответствующего коэффициента регрессии указывает на положительную корреляцию между ошибками регрессии etvi е,-. К такому же выводу приводит и значение статистики Дарбина— Уотсона, полученное в 7.7.
[c.175]
Предполагая, что ошибки регрессии представляют собой нормально распределенные случайные величины, проверить гипотезу о гомоскедастичности, используя тест Голдфедда— Квандта.
[c.188]
В этом случае естественно возникает вопрос о коррелиро-ванности между регрессорами и ошибками регрессии е. Покажем, что от этого существенно зависят результаты оценивания — причем не только количественно, но и качественно.
[c.191]
Именно такого вида модели имеют наибольшее практическое значение, и именно такого вида механизм возникновения корреляции между регрессорами и ошибками регрессии наиболее часто встречается в экономических приложениях. На практике чаще всего возникают модели ADL порядка (0,1), т. е. модели вида2
[c.200]
Объяснение здесь очень простое тест Дарбина—Уотсона неприменим в том случае, если имеется корреляция между регрессо-рами и ошибками регрессии. В самом деле, идея теста заключается в том, что корреляция ошибок регрессии имеет место в том и только том случае, когда она значимо присутствует в остатках регрессии. Но для того, чтобы это было действительно так, необходимо, чтобы набор значений остатков можно было бы интерпретировать как набор наблюдений ошибок. Между тем это не так, если регрессоры коррелируют с ошибками.
[c.213]
Модели AR H и GAR H удовлетворяют всем условиям классической модели, и метод наименьших квадратов позволяет получить оптимальные линейные оценки. В то же время можно получить более эффективные нелинейные оценки методом максимального правдоподобия. В отличие от модели с независимыми нормально распределенными ошибками регрессии в AR H-модели оценки максимального правдоподобия отличаются от оценок, полученных методом наименьших квадратов.
[c.217]
Пусть ошибки регрессии удовлетворяют следующим условиям E(et) = 0 ov(e ,еа) = 0,t s- v(et) = azxt, xt > 0.
[c.163]
В статистике и оптимизации ошибки и остатки — это две тесно связанные и легко перепутанные меры отклонения наблюдаемого значения элемента статистической выборки от его « истинного значения » (не обязательно наблюдаемого). Ошибка наблюдения — это отклонение наблюдаемого значения от истинного значения интересующей величины (например, среднего значения генеральной совокупности ). Остаток – это разница между наблюдаемым значением и расчетнымзначение интересующей величины (например, выборочное среднее ). Различие наиболее важно в регрессионном анализе , где понятия иногда называют ошибками регрессии и остатками регрессии , и где они приводят к понятию студенческих остатков . В эконометрике «ошибки» также называют нарушениями . [1] [2] [3]
Введение
Предположим, есть ряд наблюдений из одномерного распределения , и мы хотим оценить среднее значение этого распределения (так называемая модель местоположения ). В этом случае ошибки — это отклонения наблюдений от среднего значения генеральной совокупности, а остатки — отклонения наблюдений от среднего значения выборки.
Статистическая ошибка ( или возмущение ) — это величина, на которую наблюдение отличается от своего ожидаемого значения , причем последнее основано на всей совокупности , из которой статистическая единица была выбрана случайным образом. Например, если средний рост в популяции 21-летних мужчин составляет 1,75 метра, а один случайно выбранный мужчина имеет рост 1,80 метра, то «ошибка» составляет 0,05 метра; если случайно выбранный мужчина имеет рост 1,70 метра, то «ошибка» составляет -0,05 метра. Ожидаемое значение, являющееся средним значением всей совокупности, обычно ненаблюдаемо, и, следовательно, статистическая ошибка также не может наблюдаться.
С другой стороны, невязка (или аппроксимирующее отклонение) является наблюдаемой оценкой ненаблюдаемой статистической ошибки. Рассмотрим предыдущий пример с ростом мужчин и предположим, что у нас есть случайная выборка из n человек. Среднее значение выборки может служить хорошей оценкой среднего значения генеральной совокупности . Тогда у нас есть:
- Разница между ростом каждого мужчины в выборке и ненаблюдаемым средним значением популяции является статистической ошибкой , тогда как
- Разница между ростом каждого мужчины в выборке и наблюдаемым средним значением выборки является остатком .
Обратите внимание, что из-за определения выборочного среднего сумма остатков в пределах случайной выборки обязательно равна нулю, и, таким образом, остатки обязательно не являются независимыми . Статистические ошибки, с другой стороны, независимы, и их сумма в пределах случайной выборки почти наверняка не равна нулю.
Можно стандартизировать статистические ошибки (особенно нормального распределения ) в z-оценке (или «стандартной оценке») и стандартизировать остатки в t — статистике или, в более общем случае, студенческие остатки .
В одномерных распределениях
Если мы предположим нормально распределенную популяцию со средним значением μ и стандартным отклонением σ и выберем индивидуумов независимо, то мы получим
и среднее значение выборки
случайная величина, распределенная так, что:
Тогда статистические ошибки
с ожидаемыми значениями нуля, [4] , тогда как
остатки
Сумма квадратов статистических ошибок , деленная на σ 2 , имеет распределение хи-квадрат с n степенями свободы :
Однако эта величина не поддается наблюдению, поскольку неизвестно среднее значение генеральной совокупности. С другой стороны, сумма квадратов остатков является наблюдаемой. Частное этой суммы по σ 2 имеет распределение хи-квадрат только с n — 1 степенями свободы:
Эта разница между n и n — 1 степенями свободы приводит к поправке Бесселя для оценки выборочной дисперсии совокупности с неизвестным средним значением и неизвестной дисперсией. Коррекция не требуется, если известно среднее значение генеральной совокупности.
Примечательно, что можно показать , что сумма квадратов остатков и выборочное среднее не зависят друг от друга, используя, например , теорему Басу . Этот факт, а также приведенные выше нормальное распределение и распределение хи-квадрат составляют основу расчетов с использованием t-статистики :
кудапредставляет ошибки,представляет стандартное отклонение выборки для выборки размера n и неизвестного σ , а член знаменателяучитывает стандартное отклонение ошибок в соответствии с: [5]
Распределения вероятностей числителя и знаменателя отдельно зависят от значения стандартного отклонения ненаблюдаемой совокупности σ , но σ появляется как в числителе, так и в знаменателе и сокращается. Это удачно, потому что это означает, что даже если мы не знаем σ , мы знаем распределение вероятностей этого частного: оно имеет t-распределение Стьюдента с n − 1 степенями свободы. Поэтому мы можем использовать это частное, чтобы найти доверительный интервал для µ . Эту t-статистику можно интерпретировать как «количество стандартных ошибок вдали от линии регрессии». [6]
Регрессии
В регрессионном анализе различие между ошибками и остатками является тонким и важным и приводит к понятию студенческих остатков . Учитывая ненаблюдаемую функцию, которая связывает независимую переменную с зависимой переменной, например, линию, отклонения наблюдений зависимой переменной от этой функции являются ненаблюдаемыми ошибками. Если выполнить регрессию на некоторых данных, то отклонения наблюдений зависимой переменной от подобранной функции будут остатками. Если применима линейная модель, диаграмма рассеяния остатков, построенных по отношению к независимой переменной, должна быть случайной относительно нуля без тенденции к остаткам. [5]Если данные демонстрируют тенденцию, регрессионная модель, скорее всего, неверна; например, истинная функция может быть квадратичным или многочленом более высокого порядка. Если они случайны или не имеют тренда, но «разветвляются» — они демонстрируют явление, называемое гетероскедастичностью . Если все остатки равны или не расходятся веером, они проявляют гомоскедастичность .
Однако в выражении среднеквадратичной ошибки (MSE) возникает терминологическое различие . Среднеквадратическая ошибка регрессии — это число, вычисленное из суммы квадратов вычисленных остатков , а не ненаблюдаемых ошибок . Если эту сумму квадратов разделить на n , количество наблюдений, результатом будет среднее значение квадратов остатков. Поскольку это смещенная оценка дисперсии ненаблюдаемых ошибок, смещение устраняется путем деления суммы квадратов невязок на df = n − p − 1 вместо n , где df — число степеней свободы.( n минус количество оцениваемых параметров (исключая точку пересечения) p — 1). Это формирует несмещенную оценку дисперсии ненаблюдаемых ошибок и называется среднеквадратичной ошибкой. [7]
Другой метод расчета среднего квадрата ошибки при анализе дисперсии линейной регрессии с использованием метода, подобного тому, который используется в ANOVA (они одинаковы, потому что ANOVA является типом регрессии), сумма квадратов остатков (она же сумма квадратов ошибки) делится на степени свободы (где степени свободы равны n − p − 1, где p— количество параметров, оцененных в модели (по одному для каждой переменной в уравнении регрессии, не включая точку пересечения)). Затем можно также рассчитать средний квадрат модели, разделив сумму квадратов модели за вычетом степеней свободы, что представляет собой просто количество параметров. Затем значение F можно рассчитать, разделив средний квадрат модели на средний квадрат ошибки, и затем мы можем определить значимость (именно поэтому вы хотите, чтобы средние квадраты начинались с). [8]
Однако из-за поведения процесса регрессии распределения невязок в разных точках данных (входной переменной) могут различаться , даже если сами ошибки распределены одинаково. Конкретно, в линейной регрессии , где ошибки распределены одинаково, изменчивость невязок входных данных в середине области будет выше , чем изменчивость невязок на концах области: [9] линейные регрессии подходят к конечным точкам лучше, чем середина. Это также отражено в функциях влияния различных точек данных на коэффициенты регрессии : конечные точки имеют большее влияние.
Таким образом, чтобы сравнить остатки при различных входных данных, необходимо скорректировать остатки на ожидаемую изменчивость остатков, что называется студенческим анализом . Это особенно важно в случае обнаружения выбросов , когда рассматриваемый случай каким-то образом отличается от другого в наборе данных. Например, большой остаток можно ожидать в середине домена, но считать выбросом в конце домена.
Другое использование слова «ошибка» в статистике
Использование термина «ошибка», как обсуждалось в разделах выше, означает отклонение значения от гипотетического ненаблюдаемого значения. По крайней мере, два других использования также встречаются в статистике, оба относятся к наблюдаемым ошибкам прогнозирования:
Среднеквадратическая ошибка (MSE) относится к величине, на которую значения, предсказанные оценщиком, отличаются от оцениваемых величин (обычно за пределами выборки, на основе которой была оценена модель). Среднеквадратическая ошибка (RMSE) представляет собой квадратный корень из MSE. Сумма квадратов ошибок (SSE) представляет собой MSE, умноженную на размер выборки.
Сумма квадратов невязок (SSR) представляет собой сумму квадратов отклонений фактических значений от прогнозируемых значений в пределах выборки, используемой для оценки. Это основа для оценки по методу наименьших квадратов , где коэффициенты регрессии выбираются таким образом, чтобы SSR был минимальным (т. е. его производная равнялась нулю).
Точно так же сумма абсолютных ошибок (SAE) представляет собой сумму абсолютных значений остатков, которая минимизируется в подходе наименьших абсолютных отклонений к регрессии.
Средняя ошибка (ME) – это смещение . Средняя невязка (MR) всегда равна нулю для оценок методом наименьших квадратов.
Смотрите также
- Абсолютное отклонение
- Консенсус-прогнозы
- Обнаружение и исправление ошибок
- Объяснение суммы квадратов
- Инновации (обработка сигналов)
- Несоответствие суммы квадратов
- Погрешность
- Средняя абсолютная ошибка
- Ошибка наблюдения
- Распространение ошибки
- Вероятная ошибка
- Случайные и систематические ошибки
- Приведенная статистика хи-квадрат
- Регрессионное разбавление
- Среднеквадратичное отклонение
- Ошибка выборки
- Стандартная ошибка
- Студенческий остаток
- Ошибки первого и второго рода.
Ссылки
- ^ Кеннеди, П. (2008). Руководство по эконометрике . Уайли. п. 576. ИСБН 978-1-4051-8257-7. Проверено 13 мая 2022 г. .
- ^ Вулдридж, Дж. М. (2019). Введение в эконометрику: современный подход . Cengage Learning. п. 57. ISBN 978-1-337-67133-0. Проверено 13 мая 2022 г. .
- ^ Дас, П. (2019). Эконометрика в теории и на практике: анализ поперечного сечения, временных рядов и панельных данных с помощью статистики 15.1 . Спрингер Сингапур. п. 7. ISBN 978-981-329-019-8. Проверено 13 мая 2022 г. .
- ^ Уэтерилл, Г. Барри. (1981). Промежуточные статистические методы . Лондон: Чепмен и Холл. ISBN 0-412-16440-Х. OCLC 7779780 .
- ^ a b Современное введение в вероятность и статистику: понимание, почему и как . Деккинг, Мишель, 1946-. Лондон: Спрингер. 2005. ISBN 978-1-85233-896-1. OCLC 262680588 .
{{cite book}}: CS1 maint: другие ( ссылка ) - ↑ Брюс, Питер С., 1953- (10 мая 2017 г.). Практическая статистика для специалистов по данным: 50 основных понятий . Брюс, Эндрю, 1958- (первое изд.). Севастополь, Калифорния. ISBN 978-1-4919-5293-1. OCLC 987251007 .
{{cite book}}: CS1 maint: несколько имен: список авторов ( ссылка ) - ^ Сталь, Роберт Г.Д.; Торри, Джеймс Х. (1960). Принципы и процедуры статистики с особым упором на биологические науки . Макгроу-Хилл. п. 288 .
- ^ Зельтерман, Дэниел (2010). Прикладные линейные модели с SAS ([Online-Ausg.]. Ред.). Кембридж: Издательство Кембриджского университета. ISBN 9780521761598.
- ^ «7.3: Типы выбросов в линейной регрессии» . Статистика LibreTexts . 21.11.2013 . Проверено 22 ноября 2019 г. .
- Кук, Р. Деннис; Вайсберг, Сэнфорд (1982). Остатки и влияние в регрессии (Представитель ред.). Нью-Йорк: Чепмен и Холл . ISBN 041224280X. Проверено 23 февраля 2013 г.
- Кокс, Дэвид Р .; Снелл, Э. Джойс (1968). «Общее определение остатков». Журнал Королевского статистического общества, серия B. 30 (2): 248–275. JSTOR 2984505 .
- Вайсберг, Сэнфорд (1985). Прикладная линейная регрессия (2-е изд.). Нью-Йорк: Уайли. ISBN 9780471879572. Проверено 23 февраля 2013 г.
- «Ошибки, теория» , Математическая энциклопедия , EMS Press , 2001 [1994]
Внешние ссылки
 СМИ, связанные с ошибками и остатками на Викискладе?
СМИ, связанные с ошибками и остатками на Викискладе?