Стандартное отклонение и стандартная ошибка: в чем разница?
17 авг. 2022 г.
читать 2 мин
В статистике студенты часто путают два термина: стандартное отклонение и стандартная ошибка .
Стандартное отклонение измеряет, насколько разбросаны значения в наборе данных.
Стандартная ошибка — это стандартное отклонение среднего значения в повторных выборках из совокупности.
Давайте рассмотрим пример, чтобы ясно проиллюстрировать эту идею.
Пример: стандартное отклонение против стандартной ошибки
Предположим, мы измеряем вес 10 разных черепах.

Для этой выборки из 10 черепах мы можем вычислить среднее значение выборки и стандартное отклонение выборки:

Предположим, что стандартное отклонение оказалось равным 8,68. Это дает нам представление о том, насколько распределен вес этих черепах.
Но предположим, что мы собираем еще одну простую случайную выборку из 10 черепах и также проводим их измерения. Более чем вероятно, что эта выборка из 10 черепах будет иметь немного другое среднее значение и стандартное отклонение, даже если они взяты из одной и той же популяции:

Теперь, если мы представим, что мы берем повторные выборки из одной и той же совокупности и записываем выборочное среднее и выборочное стандартное отклонение для каждой выборки:

Теперь представьте, что мы наносим каждое среднее значение выборки на одну и ту же строку:

Стандартное отклонение этих средних значений известно как стандартная ошибка.

Формула для фактического расчета стандартной ошибки:
Стандартная ошибка = s/ √n
куда:
- s: стандартное отклонение выборки
- n: размер выборки
Какой смысл использовать стандартную ошибку?
Когда мы вычисляем среднее значение данной выборки, нас на самом деле интересует не среднее значение этой конкретной выборки, а скорее среднее значение большей совокупности, из которой взята выборка.
Однако мы используем выборки, потому что для них гораздо проще собирать данные, чем для всего населения. И, конечно же, среднее значение выборки будет варьироваться от выборки к выборке, поэтому мы используем стандартную ошибку среднего значения как способ измерить, насколько точна наша оценка среднего значения.
Вы заметите из формулы для расчета стандартной ошибки, что по мере увеличения размера выборки (n) стандартная ошибка уменьшается:
Стандартная ошибка = s/ √n
Это должно иметь смысл, поскольку большие размеры выборки уменьшают изменчивость и увеличивают вероятность того, что среднее значение нашей выборки ближе к фактическому среднему значению генеральной совокупности.
Когда использовать стандартное отклонение против стандартной ошибки
Если мы просто заинтересованы в измерении того, насколько разбросаны значения в наборе данных, мы можем использовать стандартное отклонение .
Однако, если мы заинтересованы в количественной оценке неопределенности оценки среднего значения, мы можем использовать стандартную ошибку среднего значения .
В зависимости от вашего конкретного сценария и того, чего вы пытаетесь достичь, вы можете использовать либо стандартное отклонение, либо стандартную ошибку.
Стандартное отклонение (SD), измеряет количество изменчивости или дисперсии, из отдельных значений данных, к среднему значению, в то время как стандартная ошибка среднего (SEM) мер, как далеко образец среднее (среднее) данных, вероятно, будет от истинного среднего значения населения. SEM всегда меньше SD.
Ключевые выводы
- Стандартное отклонение (SD) измеряет разброс набора данных относительно его среднего значения.
- Стандартная ошибка среднего (SEM) измеряет, насколько вероятно расхождение между средним значением выборки по сравнению со средним значением генеральной совокупности.
- SEM берет SD и делит его на квадратный корень из размера выборки.
SEM против SD
Стандартное отклонение и стандартная ошибка используются во всех типах статистических исследований, включая исследования в области финансов, медицины, биологии, инженерии, психологии и т. Д. В этих исследованиях стандартное отклонение (SD) и расчетная стандартная ошибка среднего (SEM) ) используются для представления характеристик данных выборки и объяснения результатов статистического анализа. Однако некоторые исследователи иногда путают SD и SEM. Таким исследователям следует помнить, что расчеты SD и SEM включают разные статистические выводы, каждый из которых имеет свое значение. SD – это разброс отдельных значений данных.
Другими словами, SD указывает, насколько точно среднее значение представляет данные выборки. Однако значение SEM включает статистический вывод, основанный на распределении выборки. SEM – это стандартное отклонение теоретического распределения выборочных средних (выборочное распределение).
Расчет стандартного отклонения

Формула SD требует нескольких шагов:
- Во-первых, возьмите квадрат разницы между каждой точкой данных и средним значением выборки, найдя сумму этих значений.
- Затем разделите эту сумму на размер выборки минус один, который представляет собой дисперсию.
- Наконец, извлеките квадратный корень из дисперсии, чтобы получить стандартное отклонение.
Стандартная ошибка среднего
SEM рассчитывается путем деления стандартного отклонения на квадратный корень из размера выборки.
Стандартная ошибка дает точность выборочного среднего путем измерения изменчивости выборочного среднего от образца к образцу. SEM описывает, насколько точное среднее значение выборки является оценкой истинного среднего значения совокупности. По мере увеличения размера выборки данных SEM уменьшается по сравнению с SD; следовательно, по мере увеличения размера выборки среднее значение выборки оценивает истинное среднее значение генеральной совокупности с большей точностью. Напротив, увеличение размера выборки не обязательно делает SD больше или меньше, это просто становится более точной оценкой SD населения.
Стандартная ошибка и стандартное отклонение в финансах
В финансах стандартная ошибка средней дневной доходности актива измеряет точность выборочного среднего как оценки долгосрочной (постоянной) средней дневной доходности актива.
С другой стороны, стандартное отклонение доходности измеряет отклонения индивидуальных доходов от среднего значения. Таким образом, SD является мерой волатильности и может использоваться в качестве меры риска для инвестиций. Активы с более высокими ежедневными движениями цен имеют более высокое SD, чем активы с меньшими ежедневными движениями. Предполагая нормальное распределение, около 68% дневных изменений цен находятся в пределах одного стандартного отклонения от среднего, при этом около 95% дневных изменений цен находятся в пределах двух стандартных значений среднего.
(note that I’m focusing on standard error of the mean, which I believe the questioner was as well, but you can generate a standard error for any sample statistic)
The standard error is related to the standard deviation but they are not the same thing and increasing sample size does not make them closer together. Rather, it makes them farther apart. The standard deviation of the sample becomes closer to the population standard deviation as sample size increases but not the standard error.
Sometimes the terminology around this is a bit thick to get through.
When you gather a sample and calculate the standard deviation of that sample, as the sample grows in size the estimate of the standard deviation gets more and more accurate. It seems from your question that was what you were thinking about. But also consider that the mean of the sample tends to be closer to the population mean on average. That’s critical for understanding the standard error.
The standard error is about what would happen if you got multiple samples of a given size. If you take a sample of 10 you can get some estimate of the mean. Then you take another sample of 10 and new mean estimate, and so on. The standard deviation of the means of those samples is the standard error. Given that you posed your question you can probably see now that if the N is high then the standard error is smaller because the means of samples will be less likely to deviate much from the true value.
To some that sounds kind of miraculous given that you’ve calculated this from one sample. So, what you could do is bootstrap a standard error through simulation to demonstrate the relationship. In R that would look like:
# the size of a sample
n <- 10
# set true mean and standard deviation values
m <- 50
s <- 100
# now generate lots and lots of samples with mean m and standard deviation s
# and get the means of those samples. Save them in y.
y <- replicate( 10000, mean( rnorm(n, m, s) ) )
# standard deviation of those means
sd(y)
# calcuation of theoretical standard error
s / sqrt(n)
You’ll find that those last two commands generate the same number (approximately). You can vary the n, m, and s values and they’ll always come out pretty close to each other.
(note that I’m focusing on standard error of the mean, which I believe the questioner was as well, but you can generate a standard error for any sample statistic)
The standard error is related to the standard deviation but they are not the same thing and increasing sample size does not make them closer together. Rather, it makes them farther apart. The standard deviation of the sample becomes closer to the population standard deviation as sample size increases but not the standard error.
Sometimes the terminology around this is a bit thick to get through.
When you gather a sample and calculate the standard deviation of that sample, as the sample grows in size the estimate of the standard deviation gets more and more accurate. It seems from your question that was what you were thinking about. But also consider that the mean of the sample tends to be closer to the population mean on average. That’s critical for understanding the standard error.
The standard error is about what would happen if you got multiple samples of a given size. If you take a sample of 10 you can get some estimate of the mean. Then you take another sample of 10 and new mean estimate, and so on. The standard deviation of the means of those samples is the standard error. Given that you posed your question you can probably see now that if the N is high then the standard error is smaller because the means of samples will be less likely to deviate much from the true value.
To some that sounds kind of miraculous given that you’ve calculated this from one sample. So, what you could do is bootstrap a standard error through simulation to demonstrate the relationship. In R that would look like:
# the size of a sample
n <- 10
# set true mean and standard deviation values
m <- 50
s <- 100
# now generate lots and lots of samples with mean m and standard deviation s
# and get the means of those samples. Save them in y.
y <- replicate( 10000, mean( rnorm(n, m, s) ) )
# standard deviation of those means
sd(y)
# calcuation of theoretical standard error
s / sqrt(n)
You’ll find that those last two commands generate the same number (approximately). You can vary the n, m, and s values and they’ll always come out pretty close to each other.
Автор:
Laura McKinney
Дата создания:
7 Апрель 2021
Дата обновления:
27 Январь 2023

Содержание
- Сравнительная таблица
- Определение стандартного отклонения
- Определение стандартной ошибки
- Ключевые различия между стандартным отклонением и стандартной ошибкой
- Вывод
 Стандартное отклонение определяется как абсолютная мера дисперсии ряда. Он уточняет стандартную величину отклонения по обе стороны от среднего. Его часто неправильно истолковывают со стандартной ошибкой, поскольку он основан на стандартном отклонении и размере выборки.
Стандартное отклонение определяется как абсолютная мера дисперсии ряда. Он уточняет стандартную величину отклонения по обе стороны от среднего. Его часто неправильно истолковывают со стандартной ошибкой, поскольку он основан на стандартном отклонении и размере выборки.
Стандартная ошибка используется для измерения статистической точности оценки. Он в основном используется в процессе проверки гипотез и оценки интервала.
Это две важные концепции статистики, которые широко используются в области исследований. Разница между стандартным отклонением и стандартной ошибкой основана на различии между описанием данных и их выводом.
Сравнительная таблица
| Основа для сравнения | Стандартное отклонение | Стандартная ошибка |
|---|---|---|
| Имея в виду | Стандартное отклонение подразумевает меру отклонения набора значений от их среднего. | Стандартная ошибка означает меру статистической точности оценки. |
| Статистика | Описательный | Логический |
| Меры | Насколько наблюдения отличаются друг от друга. | Насколько точно среднее значение выборки соответствует истинному среднему значению генеральной совокупности. |
| Распределение | Распределение наблюдения относительно нормальной кривой. | Распределение оценки относительно нормальной кривой. |
| Формула | Корень квадратный из дисперсии | Стандартное отклонение, деленное на квадратный корень из размера выборки. |
| Увеличение размера выборки | Дает более конкретную меру стандартного отклонения. | Уменьшает стандартную ошибку. |
Определение стандартного отклонения
Стандартное отклонение — это мера разброса ряда или расстояния от стандарта. В 1893 году Карл Пирсон ввел понятие стандартного отклонения, которое, несомненно, является наиболее часто используемой мерой в научных исследованиях.
Это квадратный корень из среднего квадрата отклонений от их среднего значения. Другими словами, для данного набора данных стандартное отклонение — это среднеквадратичное отклонение от среднего арифметического. Для всего населения он обозначается греческой буквой «сигма (σ)», а для выборки — латинской буквой «s».
Стандартное отклонение — это мера, которая количественно определяет степень дисперсии набора наблюдений. Чем дальше точки данных от среднего значения, тем больше отклонение в наборе данных, что означает, что точки данных разбросаны по более широкому диапазону значений и наоборот.
Определение стандартной ошибки
Вы могли заметить, что разные выборки одинакового размера, взятые из одной и той же совокупности, дадут разные значения рассматриваемой статистики, т.е. выборочное среднее. Стандартная ошибка (SE) представляет собой стандартное отклонение различных значений выборочного среднего. Он используется для сравнения выборочных средних по совокупности.
Короче говоря, стандартная ошибка статистики — это не что иное, как стандартное отклонение ее выборочного распределения. Он играет большую роль в проверке статистических гипотез и интервальной оценке. Это дает представление о точности и достоверности сметы. Чем меньше стандартная ошибка, тем больше однородность теоретического распределения и наоборот.
- Формула: Стандартная ошибка для выборочного среднего = σ / √n
Где, σ — стандартное отклонение совокупности
Ключевые различия между стандартным отклонением и стандартной ошибкой
Приведенные ниже моменты существенны с точки зрения разницы между стандартным отклонением:
- Стандартное отклонение — это мера, которая оценивает степень вариации набора наблюдений. Стандартная ошибка измеряет точность оценки, т. Е. Является мерой изменчивости теоретического распределения статистики.
- Стандартное отклонение — это описательная статистика, тогда как стандартная ошибка — это выводимая статистика.
- Стандартное отклонение измеряет, насколько отдельные значения отличаются от среднего значения. Напротив, насколько близко среднее значение выборки к среднему значению генеральной совокупности.
- Стандартное отклонение — это распределение наблюдений относительно нормальной кривой. В отличие от этого, стандартная ошибка — это распределение оценки относительно нормальной кривой.
- Стандартное отклонение определяется как квадратный корень из дисперсии. И наоборот, стандартная ошибка описывается как стандартное отклонение, деленное на квадратный корень из размера выборки.
- Когда размер выборки увеличивается, это дает более конкретную меру стандартного отклонения. В отличие от стандартной ошибки, когда размер выборки увеличивается, стандартная ошибка имеет тенденцию к уменьшению.
Вывод
В целом стандартное отклонение считается одним из лучших показателей дисперсии, который измеряет отклонение значений от центрального значения. С другой стороны, стандартная ошибка в основном используется для проверки надежности и точности оценки, поэтому чем меньше ошибка, тем выше ее надежность и точность.
Стандартное отклонение оно определяется как абсолютная мера рассеивания ряда. Уточнить стандартное количество вариаций с каждой стороны от среднего. Это часто неверно истолковывается как стандартная ошибка, поскольку основывается на стандартном отклонении и размере выборки.
Стандартная ошибка Он используется для измерения статистической точности оценки. Он в основном используется в процессе проверки гипотез и интервал оценки.
Это две важные концепции статистики, которые широко используются в области исследований. Разница между стандартным отклонением и стандартной ошибкой основана на разнице между описанием данных и их выводом.
Сравнительный график
| чувство | Стандартное отклонение подразумевает меру разброса множества значений его среднего значения. | Стандартная ошибка обозначает меру статистической точности оценки. |
| статистика | описательный | выведенный |
| меры | Сколько наблюдений отличаются друг от друга? | Насколько точный образец означает для истинной популяции. |
| распределение | Распределение наблюдения относительно нормальной кривой. | Распределение оценки относительно нормальной кривой. |
| формула | Квадратный корень дисперсии | Стандартное отклонение, деленное на квадратный корень размера выборки. |
| Увеличение размера выборки. | Дает более конкретную меру стандартного отклонения. | Уменьшает стандартную ошибку. |
Основа для сравнения Стандартное отклонение Стандартная ошибка
Определение стандартного отклонения
Стандартное отклонение является мерой протяженности ряда или расстояния от нормы. В 1893 году Карл Пирсон ввел понятие стандартного отклонения, которое, возможно, является наиболее широко используемой мерой в научных исследованиях.
Это квадратный корень из средних квадратов отклонений от их среднего значения. Другими словами, для данного набора данных стандартное отклонение является среднеквадратичным отклонением среднего арифметического. Для всего населения это обозначено греческой буквой «sigma ()», а для выборки – латинской буквой «s».
Стандартное отклонение является мерой, которая количественно определяет степень разброса набора наблюдений. Чем дальше точки данных от среднего значения, тем больше отклонение в наборе данных, что означает, что точки данных распределены по более широкому диапазону значений и наоборот.
Определение стандартной ошибки
Возможно, вы заметили, что разные выборки одинакового размера, взятые из одной и той же популяции, будут давать разные статистические значения, то есть среднее значение выборки. Стандартная ошибка (SE) обеспечивает стандартное отклонение при различных значениях от среднего значения по выборке. Он используется для сравнения средних выборок во всех популяциях.
Таким образом, стандартная ошибка статистики является не чем иным, как стандартным отклонением ее выборочного распределения. Он играет большую роль в статистической гипотезе и тесте оценки интервалов. Дает представление о точности и достоверности оценки. Чем меньше стандартная ошибка, тем больше однородность теоретического распределения и наоборот.
- формула : Стандартная ошибка для выборочного среднего = / н Где стандартное отклонение населения
Ключевые различия между стандартным отклонением и стандартной ошибкой
Точки, перечисленные ниже, являются существенными, когда речь идет о разнице между стандартным отклонением:
- Стандартное отклонение – это мера, которая оценивает количество вариаций в наборе наблюдений. Стандартная ошибка измеряет точность оценки, то есть является мерой изменчивости теоретического распределения статистики.
- Стандартное отклонение является описательной статистикой, в то время как стандартная ошибка является логической статистикой.
- Стандартное отклонение показывает, насколько далеко отдельные значения от среднего значения. И наоборот, насколько близко выборка означает среднее значение для населения.
- Стандартное отклонение – это распределение наблюдений со ссылкой на нормальную кривую. В противоположность этому, стандартной ошибкой является распределение оценки со ссылкой на нормальную кривую.
- Стандартное отклонение определяется как квадратный корень из дисперсии. И наоборот, стандартная ошибка описывается как стандартное отклонение, деленное на квадратный корень размера выборки.
- Поскольку размер выборки увеличивается, это обеспечивает более конкретную меру стандартного отклонения. В отличие от стандартной ошибки, когда размер выборки увеличивается, стандартная ошибка имеет тенденцию уменьшаться.
заключение
В целом, стандартное отклонение считается одной из лучших мер дисперсии, которая измеряет дисперсию значений центрального значения. С другой стороны, стандартная ошибка в основном используется для проверки достоверности и точности оценки и, следовательно, чем меньше ошибка, тем выше ее надежность и точность.
Вступление
стандарт D (SD) а также S tandard Е rror (SE) по-видимому, аналогичные терминологии; однако они концептуально настолько разнообразны, что они используются почти взаимозаменяемо в статистической литературе. Каждому термину обычно предшествует символ плюс-минус (+/-), который указывает на то, что они определяют симметричное значение или представляют диапазон значений. Неизменно оба выражения появляются со средним (средним) набором измеренных значений.
Интересно, что SE не имеет ничего общего со стандартами, с ошибками или с сообщением научных данных.
Подробный взгляд на происхождение и объяснение SD и SE покажет, почему профессиональные статистики и те, кто использует это сдержанно, оба склонны ошибаться.
Стандартное отклонение (SD)
SD является описательный статистика, описывающая распространение распределения. Как метрика, это полезно, когда данные обычно распределяются. Однако это менее полезно, когда данные сильно искажены или бимодальны, потому что они не очень хорошо описывают форму распределения. Как правило, мы используем SD при представлении характеристик образца, поскольку мы намерены описывать насколько данные изменяются по среднему значению. Другая полезная статистика для описания распространения данных — это межквартильный диапазон, 25-й и 75-й процентили и диапазон данных.
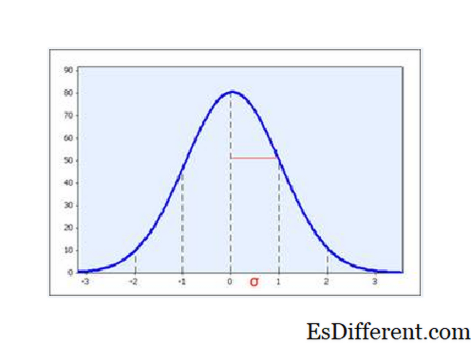
Рисунок 1. SD является мерой распространения данных. Когда данные являются образцом из нормально распределенного распределения, тогда ожидается, что две трети данных будут находиться в пределах 1 стандартного отклонения среднего значения.
Разница заключается в описательный статистика также, и она определяется как квадрат стандартного отклонения. Обычно это не сообщается при описании результатов, но это более математически приемлемая формула (a.k.a. сумма квадратов отклонений) и играет роль в вычислении статистики.
Например, если у нас есть две статистики п & Q с известными отклонениями вар (П) & вар (Q) , то дисперсия суммы Р + Q равна сумме дисперсий: вар (P) + вар (Q) , Теперь очевидно, почему статистикам нравится говорить об отклонениях.
Но стандартные отклонения имеют важное значение для распространения, особенно когда данные обычно распределяются: среднее значение интервала +/- 1 SD можно ожидать захвата 2/3 образца, а среднее значение интервала + — 2 SD можно ожидать захвата 95% образца.
SD дает представление о том, насколько индивидуальные ответы на вопрос меняются или «отклоняются» от среднего. SD рассказывает исследователю, насколько распространены ответы: сосредоточены ли они вокруг среднего или разбросаны по всему миру? Все ваши респонденты оценили ваш продукт в середине шкалы, или кто-то одобрил его, а некоторые отклонили его?
Рассмотрим эксперимент, в котором респондентам предлагается оценивать продукт по ряду атрибутов по 5-балльной шкале. Среднее значение для группы из десяти респондентов (обозначаемое «A» через «J» ниже) для «хорошей стоимости за деньги» составляло 3,2 с SD 0,4, а среднее значение для «надежности продукта» составляло 3,4 с SD 2,1.
На первый взгляд (смотря только на средства), казалось бы, надежность была оценена выше стоимости. Но более высокий SD для надежности может указывать (как показано ниже в распределении), что ответы были очень поляризованы, где большинство респондентов не имели проблем с надежностью (с оценкой атрибута «5»), но меньший, но важный сегмент респондентов, проблема надежности и оценили атрибут «1». Однако, глядя на среднее значение, он говорит только часть истории, однако чаще всего это то, на что ориентируются исследователи. Распределение ответов важно учитывать, и SD обеспечивает ценную описательную меру этого.
| ответчик | Хорошая ценность для денег | Надежность продукта |
| 3 | 1 | |
| В | 3 | 1 |
| С | 3 | 1 |
| D | 3 | 1 |
| Е | 4 | 5 |
| F | 4 | 5 |
| г | 3 | 5 |
| ЧАС | 3 | 5 |
| я | 3 | 5 |
| J | 3 | 5 |
| Имею в виду | 3.2 | 3.4 |
| Std. Девиация | 0.4 | 2.1 |
Первый опрос: респонденты оценивают продукт по пятибалльной шкале
Два очень разных распределения ответов на 5-балльную рейтинговую шкалу могут дать одно и то же значение. Рассмотрим следующий пример, показывающий значения ответа для двух разных оценок.
В первом примере (Рейтинг «A») SD равен нулю, потому что ВСЕ ответы были точно средним значением. Индивидуальные ответы не отклонялись от среднего.
В рейтинге «B», хотя среднее значение группы одинаково (3.0) в качестве первого распределения, стандартное отклонение выше. Стандартное отклонение 1.15 показывает, что индивидуальные ответы в среднем * были чуть более 1 балла от среднего.
| ответчик | Рейтинг «A» | Рейтинг «B» |
| 3 | 1 | |
| В | 3 | 2 |
| С | 3 | 2 |
| D | 3 | 3 |
| Е | 3 | 3 |
| F | 3 | 3 |
| г | 3 | 3 |
| ЧАС | 3 | 4 |
| я | 3 | 4 |
| J | 3 | 5 |
| Имею в виду | 3.0 | 3.0 |
| Std. Девиация | 0.00 | 1.15 |
Второй опрос: респонденты оценивают продукт по пятибалльной шкале
Другой способ взглянуть на SD — это построить распределение как гистограмму ответов. Распределение с низким SD будет отображаться как высокая узкая форма, в то время как большая SD будет обозначаться более широкой формой.
SD обычно не указывает «правильно или неправильно» или «лучше или хуже» — более низкая SD не обязательно более желательна. Он используется исключительно как описательная статистика. Он описывает распределение по отношению к среднему.
T echnical disclaimer, относящийся к SD
Думая о том, что SD как «отклонение» — это отличный способ концептуально понять его смысл. Тем не менее, он фактически не рассчитывается как среднее (если бы это было так, мы бы назвали это «отклонениями»). Вместо этого он «стандартизирован» — несколько сложный метод вычисления значения с использованием суммы квадратов.
Для практических целей вычисление не имеет значения. Большинство программ табуляции, электронных таблиц или других инструментов управления данными будут вычислять SD для вас. Более важно понять, что передает статистика.
Стандартная ошибка
Стандартная ошибка — это выведенный статистика, которая используется при сравнении выборочных средств (средних) по группам населения. Это мера точность от среднего значения выборки. Среднее значение выборки — это статистическая информация, полученная из данных, имеющих базовое распределение. Мы не можем визуализировать его так же, как и данные, поскольку мы выполнили один эксперимент и имеем только одно значение. Статистическая теория говорит нам о том, что среднее значение выборки (для большого, более выбранного образца и в нескольких условиях регулярности) приблизительно нормально распределено. Стандартное отклонение этого нормального распределения — это то, что мы называем стандартной ошибкой.

Фигура 2. Распределение в нижней части распределяет данные, тогда как распределение сверху — это теоретическое распределение среднего значения выборки. SD 20 является мерой распространения данных, тогда как SE of 5 является мерой неопределенности вокруг среднего значения выборки.
Когда мы хотим сравнить средства исходов от эксперимента с двумя образцами Лечения A против лечения B, нам нужно оценить, насколько точно мы измерили средства.
На самом деле нас интересует, насколько точно мы измерили разницу между этими двумя средствами. Мы называем эту меру стандартной ошибкой разности. Вы не можете быть удивлены, узнав, что стандартная ошибка разницы в средствах выборки является функцией стандартных ошибок средств:

Теперь, когда вы поняли, что стандартная ошибка среднего (SE) и стандартное отклонение распределения (SD) — это два разных зверя, вам может быть интересно, как они запутались в первую очередь. Хотя они принципиально отличаются друг от друга, они имеют математическую форму:

, где n — количество точек данных.
Обратите внимание, что стандартная ошибка зависит от двух компонентов: стандартного отклонения выборки и размера выборки N , Это делает интуитивный смысл: чем больше стандартное отклонение выборки, тем менее точным может быть наша оценка истинного среднего.
Кроме того, большой размер выборки, чем больше информации мы имеем о населении, тем точнее мы можем оценить истинное значение.
SE является показателем надежности среднего значения. Небольшой SE является показателем того, что среднее значение выборки является более точным отражением фактического значения популяции. Более большой размер выборки обычно приводит к меньшему SE (тогда как SD не зависит напрямую от размера выборки).
Большинство исследовательских исследований включает в себя выборку из населения. Затем мы делаем выводы о популяции из результатов, полученных из этого образца. Если был сделан второй образец, результаты, вероятно, были бы точно совпадают с первым образцом. Если среднее значение для атрибута рейтинга составляло 3,2 для одного образца, это может быть 3,4 для второго образца того же размера. Если бы мы собирали бесконечное количество выборок (равного размера) из нашей популяции, мы могли бы отображать наблюдаемые средства как распределение. Затем мы могли бы вычислить среднее значение всех наших образцов. Это означало бы равное истинное значение популяции. Мы также можем рассчитать SD распределения средств выборки. SD этого распределения средств выборки является SE каждого отдельного образца.
Таким образом, мы имеем самое значительное наблюдение: SE является SD среднего значения.
| Образец | Имею в виду |
| первый | 3.2 |
| второй | 3.4 |
| третий | 3.3 |
| четвёртая | 3.2 |
| пятые | 3.1 |
| …. | …. |
| …. | …. |
| …. | …. |
| …. | …. |
| …. | …. |
| Имею в виду | 3.3 |
| Std. Девиация | 0.13 |
Таблица, иллюстрирующая взаимосвязь между SD и SE
Теперь ясно, что если SD этого распределения помогает нам понять, насколько далека среднее значение выборки от истинной совокупности, то мы можем использовать это, чтобы понять, насколько точна какая-либо индивидуальная выборка по отношению к истинному среднему значению. В этом суть SE.
На самом деле, мы набрали только один образец из нашего населения, но мы можем использовать этот результат для оценки надежности нашего наблюдаемого образца.
На самом деле, SE говорит нам, что мы можем быть на 95% уверены, что наше наблюдаемое среднее значение выборки плюс или минус примерно 2 (на самом деле 1,96). Стандартные ошибки от населения.
В приведенной ниже таблице показано распределение ответов от нашей первой (и единственной) выборки, используемой для наших исследований. SE 0,13, будучи относительно небольшим, дает нам указание на то, что наше среднее значение относительно близко к истинному среднему для нашей общей популяции. Предел погрешности (с доверием 95%) для нашего среднего значения (примерно) в два раза превышает это значение (+/- 0,26), сообщая нам, что истинное среднее значение, скорее всего, составляет от 2,94 до 3,46.
| ответчик | Рейтинг |
| 3 | |
| В | 3 |
| С | 3 |
| D | 3 |
| Е | 4 |
| F | 4 |
| г | 3 |
| ЧАС | 3 |
| я | 3 |
| J | 3 |
| Имею в виду | 3.2 |
| Std. заблуждаться | 0.13 |
Резюме
Многие исследователи не понимают различия между стандартным отклонением и стандартной ошибкой, хотя они обычно включаются в анализ данных. Хотя фактические расчеты для стандартного отклонения и стандартной ошибки выглядят очень схожими, они представляют собой две очень разные, но взаимодополняющие меры. SD рассказывает нам о форме нашего распределения, насколько близки значения отдельных данных от среднего значения. SE рассказывает нам, насколько близка наша выборка к истинному средству общей популяции.Вместе они помогают обеспечить более полную картину, чем может сказать нам только одно значащее.
a:
Стандартное отклонение, или SD, измеряет величину изменчивости или дисперсии для объекта набора данных из среднего значения, тогда как стандартная ошибка среднего или SEM измеряет, насколько далеко среднее значение выборки данных, вероятно, будет от истинного значения популяции. SEM всегда меньше SD. Формула для SEM представляет собой стандартное отклонение, деленное на квадратный корень от размера выборки. Формула для SD требует нескольких шагов. Сначала возьмите квадрат разницы между каждой точкой данных и средним значением выборки, набрав сумму этих значений. Затем разделите эту сумму на размер выборки минус один, что является дисперсией. Наконец, возьмите квадратный корень дисперсии, чтобы получить SD.
SEM описывает, насколько точным является среднее значение выборки по сравнению с истинным средним населением. По мере увеличения размера данных выборки SEM уменьшается по сравнению с SD. По мере увеличения размера выборки истинное среднее населения известно с большей специфичностью. Напротив, увеличение размера выборки также обеспечивает более конкретную меру SD. Однако SD может быть более или менее в зависимости от дисперсии дополнительных данных, добавленных к образцу.
SD — это показатель волатильности и может использоваться в качестве меры риска для инвестиций. Активы с более высокими ценами выше, чем активы с более низкими ценами. SD можно использовать для измерения важности движения цены в активе. Предполагая нормальное распределение, около 68% дневных изменений цен находятся в пределах одного SD от среднего значения, причем около 95% дневных изменений цен в пределах двух SD от среднего.
Я читаю курс статистического мышления магистрам, и одна тема вызывает у них явные затруднения – чем стандартное отклонение отличается от стандартной ошибки, и в каких случаях, применять ту или иную статистику. А недавно в книге Искусство статистики Дэвида Шпигельхалтера я узнал про бутстрэппинг, и понял, как объяснить различия стандартного отклонения и стандартной ошибки.
Для начала зададим 100 значений стандартной нормально распределенной случайной величины. В этом контексте стандартная означает, что ее матожидание μ = 0, а среднеквадратичное отклонение σ = 1. Поскольку значения в Excel получены с помощью волатильной функции СЛМАССИВ(), после любого действия они пересчитываются. Поэтому диаграммы в заметке и в файле будут отличаться.
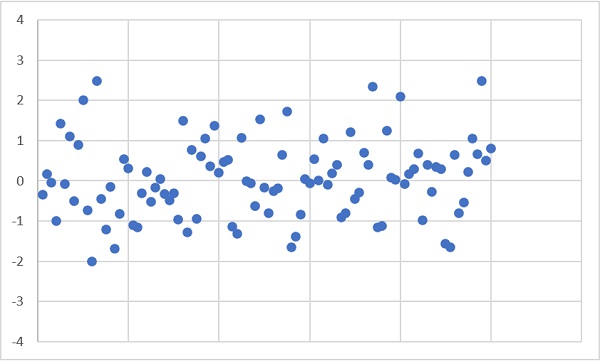
Рис. 1. Нормально распределенная случайная величина
Скачать заметку в формате Word или pdf, примеры в формате Excel
Стандартное отклонение
… является наиболее распространенным показателем рассеивания значений случайной величины относительно её среднего арифметического.
Стандартное отклонение вычисляют по формуле:
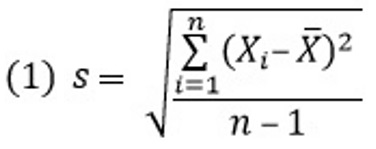
где X̅ – среднее арифметическое значений случайной величины (далее я буду называть его просто средним), Хi – отдельные значения случайной величины, n – число значений случайной величины.
Вообще термины разными авторами используются немного по-разному. Мне нравится следующий подход. Генеральную совокупность описывают параметрами, обозначаемыми греческими буквами: математическое ожидание μ и среднеквадратичное отклонение σ. Выборки описывают статистиками, обозначаемыми латинскими буквами: среднее арифметическое X̅ и стандартное отклонение s. Стандартное отклонение иначе называют оценкой среднеквадратичного отклонения. Как правило, есть генеральная совокупность с неизвестным нам среднеквадратичным отклонением σ. Извлекая выборку, и вычисляя стандартное отклонение s, мы кое-что узнаем о среднеквадратичном отклонении генеральной совокупности σ. Поэтому и говорят, что s является оценкой сигмы.
На самом деле за термином стандартное отклонение стоят две немного отличающиеся статистики. Но эта заметка о другом)) Подробнее см. СТАНДОТКЛОН.В и СТАНДОТКЛОН.Г: в чем различие?
Нанесем на диаграмму линию среднего и границы, отстоящие от среднего на расстоянии ±2s.

Рис. 2. Линия среднего и границы ±2s
Для стандартного нормального распределения за границы ±2s попадают 4,6% значений.
=(1-НОРМ.СТ.РАСП(2;ИСТИНА))*2 = 4,6%
И действительно 5 точек на рис. 2 лежат вне границ. Совпадение не обязано быть таким точным. Если вы откроете файл Excel на листе «Рис. 2» и понажимаете F9, принудительно изменяя случайные значения, то увидите, что вне границ может лежать от 2 до 8 точек. А если нажимать F9 достаточно долго, то вы получите более экстремальные числа точек вне границ. Для стандартного нормального распределения в пределах ±2s лежат приблизительно 95% значений. Поскольку s – оценка среднеквадратичного отклонения σ, которое в свою очередь равно 1, то 95% всех значений попадают в диапазон ≈ ±2.
Чем меньше s, тем кучнее значения случайной величины располагаются вокруг среднего. Итак
стандартное отклонение – мера разброса случайной величины
Среднее арифметическое выборки
Напомню, что мы задаем наши 100 значений с помощью генератора случайных чисел формулой в Excel
=НОРМ.СТ.ОБР(СЛМАССИВ(100;;0;1;ЛОЖЬ))
Хотя мы установили для генератора случайных чисел μ = 0 и σ = 1, значения X̅ и s будут немного отличаться для каждой выборки.
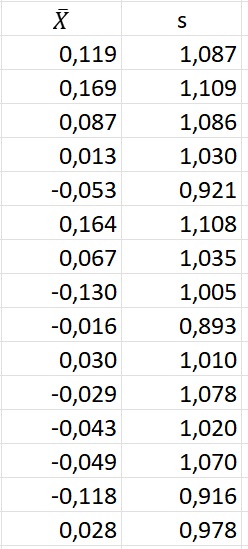
Рис. 3. Среднее и стандартное отклонение для 15 выборок размером n = 100
Теперь мы хотим узнать, что можно сказать о неизвестном математическом ожидании генеральной совокупности μ, подсчитав среднее арифметическое конкретной выборки, например, первой X̅ = 0,119?
Бутстрэп
Как пишет Евгения Поникарова, переводчик книги Дэвида Шпигельхалтера «Искусство статистики», слово bootstraps означает ремешки в виде ушка, которые прикрепляются к верхней части обуви, чтобы ее было проще натягивать. В английском языке есть выражение To pull oneself over a fence by one’s bootstraps (буквально — перетащить себя через ограду за ушки своей обуви), которое означает «выпутаться из своих проблем самому». Еще можно вспомнить барона Мюнхгаузена, который вытащил себя за волосы из болота.
Бутстрэп – компьютерный метод исследования распределения статистик, основанный на многократной генерации выборок методом Монте-Карло на базе имеющейся одной выборки. Термин ввел в 1977 году Брэдли Эфрон.
Итак, возьмем одну выборку из 100 случайных чисел и зафиксируем значения. Это наша исходная выборка (столбец А на рис. 4). Её среднее X̅(100) = 0,121, а стандартное отклонение s(100) = 0,995. 95% значений попадают в диапазон ≈ 0,121 ± 1,990.
С помощью генератора случайных чисел будем формировать из исходной выборки бутстрэп-выборки разного размера. Хитрость заключается в том, что выбирать значения мы будем с возвращением. Т.е., все значения любой бутстрэп-выборки взяты из исходной, а вот уникальность значений будет потеряна. Например, выборка в столбце С содержит два значения 0,7394. Я подсветил их с помощью условного форматирования. Опять же, если вы откроете Excel-файл, то дублей может не быть, так как бутстрэп-выборка сформирована волатильной функцией СЛМАССИВ().
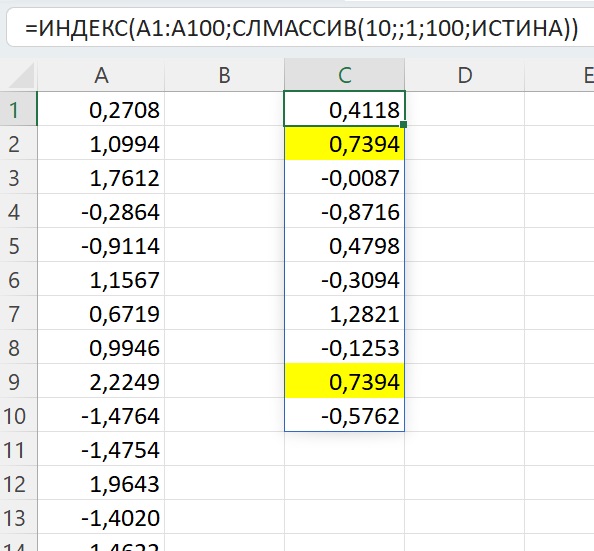
Рис. 4. Бутстрэп-выборка может содержать повторения
Для удобства последующей обработки расположим значения бутстрэп-выборки по горизонтали. Начнем со значения n = 3. Извлечем 1000 бутстрэп-выборок (рис. 5). В столбце А исходная выборка, n = 100. Столбец С содержит номер бутстрэп-выборки. В столбцах D, E и F извлеченные значения, в G – средние значения по выборкам. В ячейке G1 среднее D1:F1, в ячейке G2 – среднее D2:F2 и т.д. На диаграмме показано распределение средних значений бутстрэп-выборок для n = 3.
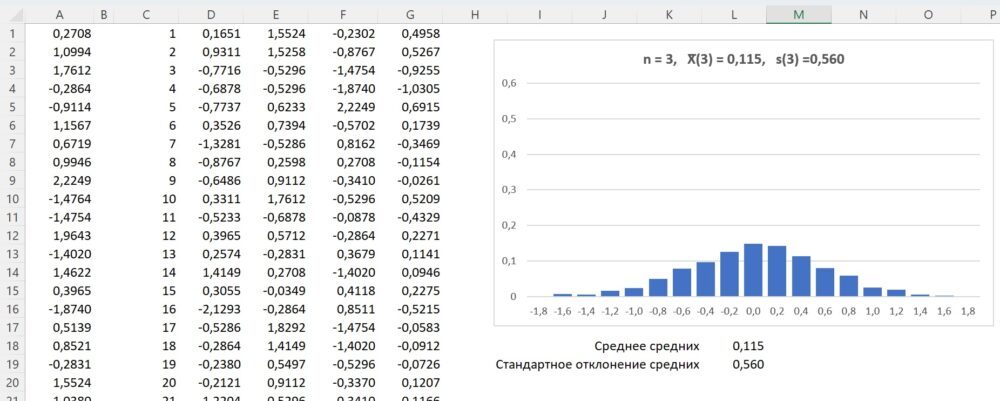
Рис. 5. Распределений средних значений 1000 бутстрэп-выборок, n = 3
Среднее средних 1000 бутстрэп-выборок = 0,115, стандартное отклонение средних значений 1000 бутстрэп-выборок = 0,560. Напоминаю, что 95% исходных значений выборки попадают в диапазон 0,12 ± 1,99. Для бутстрэп-выборок n = 3 мы только что нашли, что 95% средних попадают в диапазон 0,115 ± 1,120 (0,560*2 = 1,120). Кажется естественным, что разброс средних меньше, чем разброс отдельных значений.
Повторим моделирование для n = 5, 20, 50.
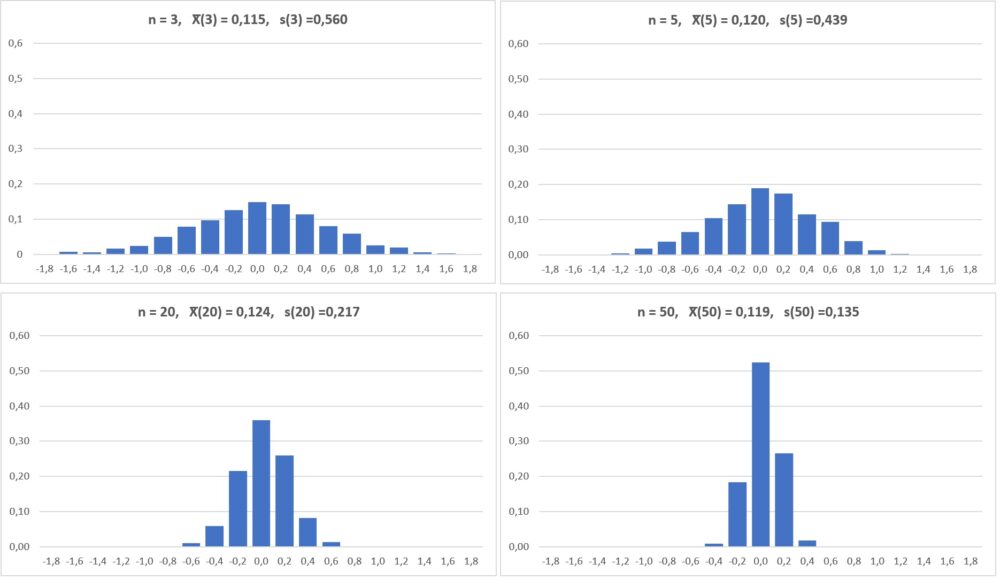
Рис. 6. С увеличением n стандартное отклонение средних значений бутстрэп-выборок уменьшается
Осмыслим, что мы получили. На рис. 6 представлены распределения средних значений бутстрэп-выборок разного размера из исходной выборки 100 случайных нормально распределенных чисел. Среднее каждого распределения близко к нулю (в нашей конкретной выборке из 100 чисел это среднее равно 0,121). А вот стандартное отклонение s(n) уменьшается по мере роста размера бутстрэп-выборок: s(3) = 0,560, s(5) = 0,439, s(20) = 0,217, s(50) = 0,135.
Стандартна ошибка
…или стандартная ошибка среднего – статистика, характеризующая стандартное отклонение выборочного среднего, рассчитанное по выборке размера n из генеральной совокупности.
Ничего не напоминает!? А что за статистику s(n) мы рассчитали выше в бутстрэп-анализе!? Да, это было стандартное отклонение выборочного среднего X̅(n).
Величина стандартной ошибки зависит от дисперсии генеральной совокупности σ2 и объёма выборки n. Стандартная ошибка среднего вычисляется по формуле
![]()
где σ – величина среднеквадратического отклонения генеральной совокупности, и n – объём выборки. Поскольку дисперсия генеральной совокупности, как правило, неизвестна, то оценка стандартной ошибки вычисляется по формуле:
![]()
где s — стандартное отклонение случайной величины.
Сведем в одной таблице рассмотренные статистики:

Рис. 7. Рассмотренные статистики
Здесь в столбцах J:L приведены статистики для одной выборки размера n, а в столбце M – статистики для бутстрэп-выборок соответствующего размера с рис. 6. Если в Excel-файле на листе «Рис. 7» понажимать F9, вы увидите, что не всегда совпадение между столбцами L и M будет таким хорошим, но тенденция будет прослеживаться.
Выше я писал, что мы исследуем неизвестное математическое ожидание генеральной совокупности μ на основе среднего арифметического выборки X̅(100) = 0,119.
Мы можем использовать статистику, именуемую стандартной ошибкой. Для нас она черный ящик – формула, выведенная на основе теории вероятностей. С другой стороны мы можем построить множество бутстрэп-выборок размера n = 100, и подсчитать стандартное отклонение средних этих бутстрэп-выборок. И мы показали, что стандартная ошибка для одной выборки и стандартное отклонение средних бутстрэп-выборок, это одно и то же! В нашем примере, получив X̅(100) = 0,119, мы можем сказать, что с вероятностью 95% математическое ожидание генеральной совокупности μ лежит в диапазоне 0,119 ± 0,212 (0,106*2=0,212). Итак
стандартная ошибка – мера оценки математического ожидания генеральной совокупности μ на основании статистик выборки
Например, 95%-ный доверительный интервал для μ
Понятно, что с увеличением размера выборки n доверительный интервал будет сужаться. В пределе при n → ∞, X̅ → μ и SE → 0.