Доброго времени суток, уважаемые читатели. Идея написать эту статью появилась у меня после того, как мне достался 10GB WesternDigital, сильно убитый (Windows 98 с него загружался около 10 минут, и постоянно включалась проверка диска при запуске компьютера). У владельца этого HDD S.M.A.R.T. был отключен, и поэтому не появлялось сообщения об ошибках. На моем компьютере в конце Post выскакивало сообщение – «Один из атрибутов S.M.A.R.T.(Seek Time Performance, как потом выяснилось) превысил пороговое значение, рекомендуется сделать резервную копию данных» (не помню как это на английском). Дальше компьютер не грузился. Загрузка продолжалась, когда S.M.A.R.T. был отключен в биосе. После отрезания бэдов диск все равно работал плохо. Обнуление атрибутов ни к чему не привело, после 2ой перезагрузки наблюдалась та же картина, вот и пришлось выяснять, что это за атрибут и с чем он связан.
В этой статье я постараюсь описать технологию S.M.A.R.T. – Self-Monitoring, Analysis and Reporting Technology («Технология Самодиагностики, Анализа и Отчета») — в доступной для понимания форме. Конечно, полностью охватить все ее возможности не возможно, т.к. в настоящее время отсутствует какая-либо полная документация по этому вопросу, да и производители накопителей о своих продвижениях в этой области сообщать не спешат.
Что такое S.M.A.R.T.
Итак, S.M.A.R.T. позволяет отслеживать и, самое главное, предсказывать возникновение ошибок, связанных с функционированием HDD, отсюда появляется возможность вовремя сделать резервную копию данных, тем самым избежать морального и материального ущерба от потери информации, ограничившись лишь покупкой нового диска.
S.M.A.R.T. – это набор программ, вшитых в микрокод винчестера. Каждая фирма-производитель дисков ведет свои разработки, отсюда и разнообразие параметров для разных дисков. Однако существуют общие параметры:
1.Атрибуты, отражающие общее состояние диска (примерно 30);
2.Внутренние тесты (self-tests);
3.Журналы S.M.A.R.T. (ошибок, общего состояния, дефектных секторов и т.п.).
Полный обязательный перечень S.M.A.R.T атрибутов описан в стандарте ATA/ATAPI-6.
Атрибуты S.M.A.R.T.
Атрибуты S.M.A.R.T. – особые характеристики, которые используются при анализе состояния и запаса производительности накопителя. Они выбираются производителем, основываясь на их способности предсказывать ухудшение рабочих характеристик накопителя или определить его дефектность.
Значения атрибутов (value) используются для представления относительной надежности отдельного эксплуатационного или эталонного атрибута. Допустимое значение атрибута лежит в диапазоне от 1 до 255. Его высокое значение говорит о том, что результат анализа данной рабочей характеристики указывает на низкую вероятность ее ухудшения или выхода накопителя из строя. Соответственно, низкое значение атрибута говорит о том, что результат анализа данной рабочей характеристики указывает на высокую вероятность ее ухудшения или выхода накопителя из строя.
Каждый атрибут имеет собственное пороговое значение (threshold), которое используется для сравнения со значением атрибута (value) и указывает на ухудшение рабочих характеристик или дефектность накопителя. Числовое значение порогового атрибута определяется производителем через конструкционные особенности накопителя и анализ результатов испытаний на надежность. Пороговое значение каждого атрибута указывает на его нижнюю допустимую границу, до которой накопитель нормально функционирует.
Ниже приведено краткое описание основных атрибутов:
Raw Read Error Rate — Частота появления ошибок при чтении данных с диска. Данный параметр показывает частоту появления ошибок при операциях чтения с поверхности диска по вине аппаратной части накопителя.
Throughput Performance — Средняя производительность (пропускная способность) диска. Уменьшение значения value этого атрибута с большой вероятностью указывает на проблемы в накопителе.
Spin Up Time— Время раскрутки шпинделя. Среднее время раскрутки шпинделя диска от 0 RPM до рабочей скорости.
Start/Stop Count— Количество циклов запуск/останов шпинделя. Хранит общее количество включений/выключений диска.
Reallocated Sectors Count — Количество переназначенных секторов. Когда жесткий диск встречает ошибку чтения/записи/верификации, он пытается переместить данные в специальную резервную область (spare area) и, в случае успеха, помечает сектор как «переназначенный». Также, этот процесс называют remapping, а переназначенный сектор — remap. Благодаря этой возможности, на современных жестких дисках очень редко видны (при тестировании поверхности) так называемые bad block. Однако, при большом количестве ремапов, на графике чтения с поверхности будут заметны «провалы» — резкое падение скорости чтения (до 10% и более).
Seek Error Rate — Частота появления ошибок позиционирования МГ (магнитной головки). В случае сбоя в механической системе позиционирования, повреждения сервометок (servo), сильного термического расширения дисков и т.п. возникают ошибки позиционирования. Чем их больше, тем хуже состояние механики и/или поверхности жесткого диска.
Seek Time Performance — Средняя производительность операций позиционирования МГ. Данный параметр показывает среднюю скорость позиционирования привода МГ на указанный сектор. Снижение значения этого атрибута говорит о неполадках в механике привода.
Power-On Hours — Количество отработанных часов во включенном состоянии. Значение value этого атрибута показывает количество часов (минут, секунд — в зависимости от производителя), отработанных жестким диском. Снижение значения атрибута до критического уровня (threshold) указывает на выработку диском ресурса. На практике, даже падение этого атрибута до нулевого значения не всегда указывает на реальное исчерпывание ресурса и накопитель может продолжать нормально функционировать.
Spin Retry Count — Количество повторов попыток старта шпинделя диска. Данный атрибут фиксирует общее количество попыток раскрутки шпинделя и его выхода на рабочую скорость, при условии, что первая попытка была неудачной. Снижение значения этого атрибута говорит о неполадках в механике привода.
Recalibration Retries— Количество повторов попыток рекалибровки накопителя. Данный атрибут фиксирует общее количество попыток сброса состояния накопителя и установки головок на нулевую дорожку, при условии, что первая попытка была неудачной. Снижение значения этого атрибута говорит о неполадках в механике привода.
Device Power Cycle Count — Количество полных циклов запуска/останова жесткого диска.
Soft Read Error Rate — Частота появления «программных» ошибок при чтении данных с диска. Данный параметр показывает частоту появления ошибок при операциях чтения с поверхности диска по вине программного обеспечения, а не аппаратной части накопителя.
Load/Unload Cycle Count — Количество циклов вывода МГ в специальную парковочную зону/в рабочее положение.
Temperature — Температура. Данный параметр отражает показание встроенного температурного сенсора в градусах Цельсия.
Reallocation Event Count — Количество операций переназначения (ремаппинга). Показывает общее количество попыток переназначения сбойных секторов в резервную область, предпринятых накопителем. При этом, учитываются как успешные, так и неудачные операции.
Current Pending Sector Count — Текущее количество нестабильных секторов. Показывает общее количество секторов, которые накопитель в данный момент считает претендентами на переназначение в резервную область (remap). Если в дальнейшем какой-то из этих секторов будет прочитан успешно, то он исключается из списка претендентов. Если же чтение сектора будет сопровождаться ошибками, то накопитель попытается восстановить данные и перенести их в резервную область, а сам сектор пометить как переназначенный (remapped).
Uncorrectable Sector Count — Количество нескорректированных ошибок. Атрибут показывает общее количество ошибок, возникших при чтении/записи сектора, которые не удалось скорректировать. Рост значения в поле raw value этого атрибута указывает на явные дефекты поверхности и/или проблемы в работе механики накопителя.
UltraDMA CRC Error Count — Общее количество ошибок CRC в режиме UltraDMA, содержит количество ошибок, возникших в режиме передачи данных UltraDMA в контрольной сумме (ICRC — Interface CRC). В большинстве случаев ошибки CRC возникают при сильном завышении частоты PCI (больше номинальных 33.3 MHz), сильно перекрученом кабеле, а также — по вине драйверов ОС, которые не соблюдают требований к передачи/приему данных в режимах UltraDMA.
Write Error Rate — Частота появления ошибок при записи данных. Показывает общее количество ошибок, обнаруженных во время записи сектора. Чем ниже значение value, тем хуже состояние поверхности диска и/или механики привода.
Disk Shift — Сдвиг пакета дисков относительно оси шпинделя.
G-Sense Error Rate — Частота появления ошибок в результате ударных нагрузок. Данный атрибут хранит показания ударочувствительного сенсора — общее количество ошибок, возникших в результате полученных накопителем внешних ударных нагрузок (при падении, неправильной установке, и т.п.).
Здесь приведены атрибуты, с помощью которых можно определить надежность функционирования диска. Остальные же не представляют практической важности.
Автономное сканирование поверхности (off-line read scanning).
Большинство накопителей обеспечивают поддержку автономного сканирования поверхности, которое является одной из функций подпрограммы автономного сбора данных о состоянии накопителя (off-line data collection). При выполнении этой функции, накопитель выполняет полное сканирование поверхности путем чтения каждого сектора с замещением ненадежных секторов на запасные из резервной области (spare area) для предотвращения потери пользовательских данных.
Примечание! Если во время выполнения сканирования накопитель получает команду по интерфейсу, то процесс сканирования прерывается и накопитель приступает к обработке поступившей команды. При этом гарантируется максимальное время реагирования на поступившую команду — до 2 секунд.
Встроенные функции самоконтроля (self-test)
Практически с момента появления стандарта S.M.A.R.T. II, в большинстве накопителей появилась новая функция — внутренняя диагностика и самоконтроль, для углубленного контроля состояния механики накопителя, поверхности дисков и т.п. Для запуска этой функции, в набор команд S.M.A.R.T. была введена новая команда — SMART EXECUTE OFF-LINE IMMEDIATE. Результат работы сохраняется либо в специализированных атрибутах, либо отдельным параметром среди других данных в атрибутах
После выполнения теста, накопитель в обязательном порядке обновляет показания во всех атрибутах и других параметрах. Если во время выполнения внутреннего теста накопитель получит по интерфейсу новую команду, то выполнение теста прерывается и накопитель приступает к обработке поступившей команды.
Методы тестирования.
Существует два способа запуска тестов S.M.A.R.T.: автономный (off-line) или монопольный (captive). Результат теста всегда сохраняется накопителем в данных S.M.A.R.T.
При автономном запуске накопитель сообщает о успешном завершении команды до ее фактического исполнения и только после этого выполняет тест. При этом, по интерфейсу флаг «занято» (busy) не выставляется и накопитель в любой момент готов приступить к выполнению очередной интерфейсной команды, приостанавливая работу теста. Фактически, тест выполняется в фоновом режиме.
При запуске теста в монопольном режиме, по интерфейсу выставляется флаг «занято» (busy) и накопитель начинает непосредственное выполнение теста в режиме реального времени. Любая интерфейсная команда во время выполнения этого теста приведет к его прерыванию и остановке, после чего накопитель приступит к обработке поступившей команды.
Монитор параметров S.M.A.R.T. программа SIGuardian.
Существует большое количество программ, контролирующих SMART, это может быть специально направленная программа (Drive Health, SIGuardian), или программа, содержащая контроль параметров SMART как дополнительную функцию. На мой взгляд, наиболее функциональной является SIGuardian (siguardian.ru). Программа предоставляет возможность следить за практически всеми атрибутами SMART, имеет приятный интерфейс, и обладает большим количеством настроек.
Общие сведения о дисках.
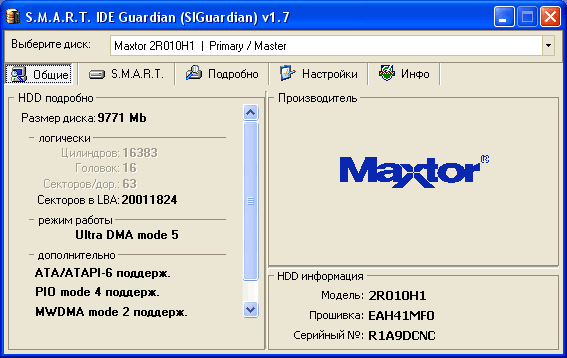
Рис. 1
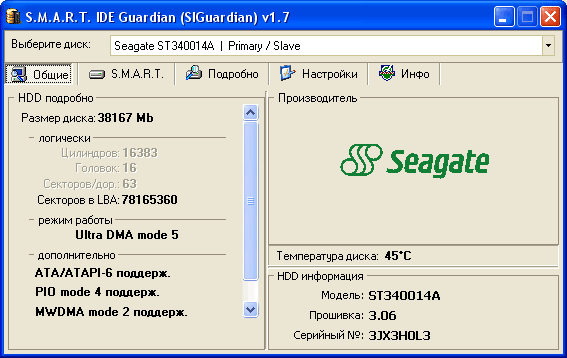
Рис. 2
Закладка «Общие» содержит общую информацию о выбранном жестком диске. В левой половине указаны: технические характеристики, такие как объем диска, количество цилиндров, головок и т.п.; режим работы диска в настоящий момент (PIO, multiword DMA, UDMA); поддерживаемые режимы работы диска (только в Расширенном режиме). В правой половине показывается логотип фирмы-производителя жесткого диска и ниже – общая информация о диске: модель диска, серийный номер диска, дата/ревизия прошивки микропрограммы.
Обратите внимание, на рис. 1 отсутствует показание температуры. Диск достаточно старый и не обладает таким сенсором.
Общие сведения S.M.A.R.T.
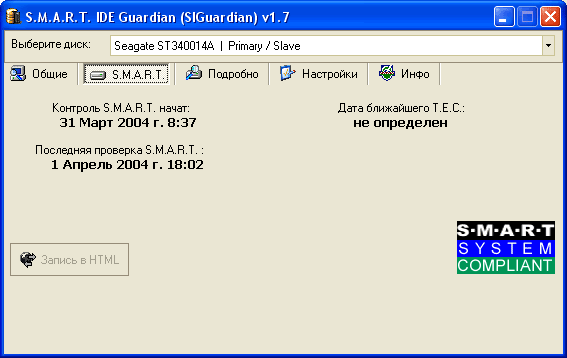
Рис. 3.
Закладка «S.M.A.R.T.» показывает общую информацию о состоянии диска на основе S.M.A.R.T. атрибутов или S.M.A.R.T. – информацию:
1.Дату начала мониторинга S.M.A.R.T. – т.е. дату, когда вы начали контроль за состоянием диска при помощи SIGuardian. Чаще всего, это дата первого запуска SIGuardian.
2. Ближайшую прогнозируемую дату T.E.C. (ThresholdExceedCondition) – т.е. дату, когда по прогнозам SIGuardian один из S.M.A.R.T. атрибутов достигнет порогового (критического) значения.
S.M.A.R.T. подробно
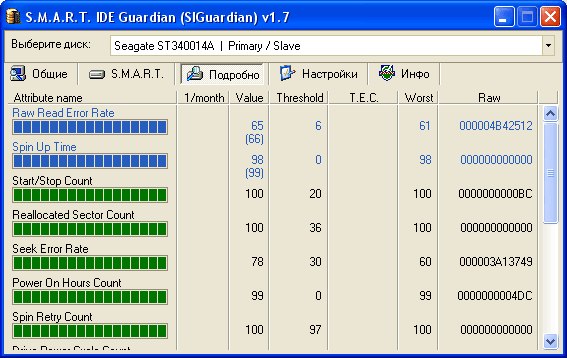
Рис.4.
Закладка «Подробно» предназначена для отображения полной информации о S.M.A.R.T.-атрибутах диска. Она показывает:
1. Attribute name – Графическое отображение значения атрибута. При наводке указателя мыши на него показывается в окне всплывающей подсказки более подробное текстовое описание смысла этого атрибута;
2.1/month – скорость падения атрибута – на сколько пунктов в месяц упало значение атрибута. Этот коэффициент вычисляется автоматически при любом изменении атрибутов S.M.A.R.T. для каждого атрибута в отдельности. Вычисление производится ежедневно, поэтому относитесь нормально к колебаниям этого показателя, особенно сразу после изменения атрибута;
3.Value – значение атрибута – текущее значение данного атрибута S.M.A.R.T.;
4.Threshold – пороговое (критическое) значение атрибута – значение, величину которого производитель жесткого диска считает критической и при достижении которого вполне вероятен выход диска из строя;
5.T.E.C. – Threshold Exceeds Condition – предполагаемая дата, когда данный атрибут достигнет порогового значения, иначе говоря, дата возможного выхода из строя диска. Прогноз этой даты делается на основе показателя «скорости падения атрибута», поэтому не удивляйтесь сильным колебаниям даты сразу после изменения атрибутов S.M.A.R.T.;
6.Worst – худшее значение атрибута – самое худшее (минимальное) значение, которое данный атрибут принимал за всё время жизни жесткого диска. Может использоваться чисто в ознакомительных целях;
7.Raw — «чистое» значение атрибута – просто числовое значение атрибута в чистом, необработанном виде.
Настройки
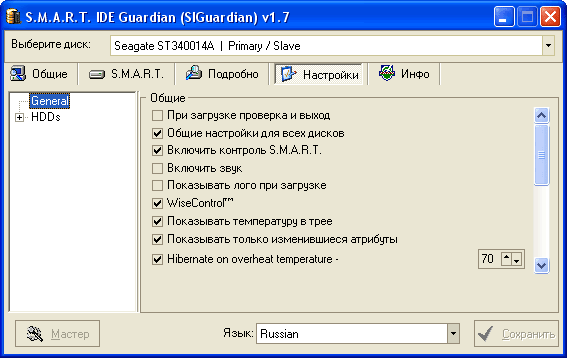
Рис. 5.
Закладка «Настройка» предназначена для самостоятельной настройки пользователем параметров SIGuardian для работы на компьютере. Если вы не считаете себя опытным пользователем, рекомендуем воспользоваться «Мастером настройки» — он поможет вам выбрать наиболее подходящие параметры работы.
Основные и наиболее важные настройки:
При загрузке проверка и выход – отметьте этот режим, если вы хотите чтобы SIGuardian проверял состояние S.M.A.R.T. только при загрузке операционной системы.
Общие настройки для всех дисков– SIGuardian будет использовать общие настройки для всех дисков в компьютере. Они включают: контроль S.M.A.R.T., период опроса S.M.A.R.T. и адрес электронной почты для сообщений. Вы можете установить общие или индивидуальные для каждого диска параметры.
Включить контроль S.M.A.R.T.– при выключении этого режима SIGuardian не будет проверять этот диск (или все диски) на значения атрибутов S.M.A.R.T.
Режим работы – Обычный или Расширенный – Обычный режим – основной для пользователей. В этом режиме SIGuardian показывает значение атрибута, пороговое значение и T.E.C., скорость падения атрибута. На закладке «Общее» Вы не увидите информации о поддерживаемых диском режимах работы (передачи данных). В расширенном режиме дополнительно показывают Худшее и Чистое (Raw) значение атрибута и полную информацию о диске на закладке «Общее».
Опрос S.M.A.R.T. – установите здесь период опроса S.M.A.R.T. при работе SIGuardian фоном.
Отчеты на e-mail – введите здесь адрес электронной почты, на который SIGuardian должен посылать сообщения. Вы не должны видеть никаких сообщений при работе в этом случае.
WiseControl – информация только о значительных изменениях (ухудшениях) параметров S.M.A.R.T.
Hibernate on overheat temperature– если температура HDD превышает установленное значение, компьютер переходит в режим hibernate.
Why exactly is a «Raw Read Error Rate» of 1 considered bad? Isn’t it the lower the read error rate, the better the reads (and the less the errors)?
Your research has found that this Raw Read Error Rate is derived from the «total number of correctable and uncorrectable ECC error events». The number is normalized and treated as a percentage, so the current value represents 1%, i.e. 1% of read operations have had an issue.
Modern NAND chips explicitly mandate ECC capability because occasional bit errors on read can occur during normal operation. The requirement will specify a permissible number of bits that might be in error per NAND page read, and need correction.
In other words a read operation may occasionally incur correctable errors, and therefore this is not an indicator of pending failure.
The occurrence of uncorrectable read errors could be problematic. In theory a sector/page/block that (consistently) generates uncorrectable read errors should be identified by the integrated drive controller, marked as a bad block, and retired from use.
The Raw Read Error Rate is not as significant as the number of uncorrectable read errors (which is now available in the SMART report that you appended).
The number of uncorrectable read errors seems to be indicated in Reported Uncorrectable Errors as 0x1B3 or 435.
Compared to the total read errors of 0x1C9 or 457, that would indicate that there were only 22 (benign) correctable read errors (assuming no wrap-around), but 95% of that total are the concerning uncorrectable read errors.
Does this mean my SSD is about to fail imminently? It has been working fine since I bought my laptop years ago…
If you think that the drive is «working fine», then that could mean that the drive was able to recover from those errors by retrying successfully and/or remapping was successful. (Note that the SMART report indicates that 9 blocks have been retired so far during this drive’s lifetime.)
At the very least you could backup your data from that drive, and regularity monitor the SMART report for changes.
With almost 20,000 hours of use, there’s no way to determine when these errors occurred.
But you could try to generate fresh read errors by scanning the entire drive, either using the SMART long/extended test or using a Linux command such as sudo dd if=/dev/sdX of=/dev/null. The first test is a lot faster but would only increment the SMART statistics, whereas the later test could also abort on a read error and thus provide a LBA of a problem area.
If you do not encounter more read errors, then that could be reassuring.
Note that the SMART report indicates the current value of 98% for Percent Lifetime Used indicates that only 2% of the expected lifetime has been used. The raw value of 2 indicates that neither of the two salient end-of-life indicators (average block wear and available spare blocks) are problematic.
Why exactly is a «Raw Read Error Rate» of 1 considered bad? Isn’t it the lower the read error rate, the better the reads (and the less the errors)?
Your research has found that this Raw Read Error Rate is derived from the «total number of correctable and uncorrectable ECC error events». The number is normalized and treated as a percentage, so the current value represents 1%, i.e. 1% of read operations have had an issue.
Modern NAND chips explicitly mandate ECC capability because occasional bit errors on read can occur during normal operation. The requirement will specify a permissible number of bits that might be in error per NAND page read, and need correction.
In other words a read operation may occasionally incur correctable errors, and therefore this is not an indicator of pending failure.
The occurrence of uncorrectable read errors could be problematic. In theory a sector/page/block that (consistently) generates uncorrectable read errors should be identified by the integrated drive controller, marked as a bad block, and retired from use.
The Raw Read Error Rate is not as significant as the number of uncorrectable read errors (which is now available in the SMART report that you appended).
The number of uncorrectable read errors seems to be indicated in Reported Uncorrectable Errors as 0x1B3 or 435.
Compared to the total read errors of 0x1C9 or 457, that would indicate that there were only 22 (benign) correctable read errors (assuming no wrap-around), but 95% of that total are the concerning uncorrectable read errors.
Does this mean my SSD is about to fail imminently? It has been working fine since I bought my laptop years ago…
If you think that the drive is «working fine», then that could mean that the drive was able to recover from those errors by retrying successfully and/or remapping was successful. (Note that the SMART report indicates that 9 blocks have been retired so far during this drive’s lifetime.)
At the very least you could backup your data from that drive, and regularity monitor the SMART report for changes.
With almost 20,000 hours of use, there’s no way to determine when these errors occurred.
But you could try to generate fresh read errors by scanning the entire drive, either using the SMART long/extended test or using a Linux command such as sudo dd if=/dev/sdX of=/dev/null. The first test is a lot faster but would only increment the SMART statistics, whereas the later test could also abort on a read error and thus provide a LBA of a problem area.
If you do not encounter more read errors, then that could be reassuring.
Note that the SMART report indicates the current value of 98% for Percent Lifetime Used indicates that only 2% of the expected lifetime has been used. The raw value of 2 indicates that neither of the two salient end-of-life indicators (average block wear and available spare blocks) are problematic.
Содержание
- 1 Как работает жесткий диск и логика исправления ошибок по чтению информации с него
- 1.1 Итак как проверить состояние жёсткого диска?
- 1.2 Почему жёсткий диск скрипит и щёлкает иногда при работе?
- 2 Проверяем и устраняем ошибки и битые сектора жесткого диска
- 2.1 Совсем чуть-чуть теории
- 2.2 Ошибки файловой системы
- 2.3 Битые сектора
- 2.4 Симптомы проявления ошибок и битых секторов
- 2.5 Проверяем ошибки средствами Windows
- 2.6 Проверка неактивного тома
- 2.7 Проверка системного тома
- 2.8 Программы проверки жесткого диска на бэд-сектора
- 2.9 Data Lifeguard Diagnostic
- 2.10 Ashampoo HDD Control
- 2.11 Victoria HDD
- 2.12 Краткий итог
- 3 Проверка SMART жесткого диска с помощью программы Виктория. Лечение битых секторов на жестком диске
- 4 Сброс SMART на жестких дисках SEAGATE. Обнуление SMART HDD. Ремонт HDD Seagate
- 4.1 После всех процедур через «Терминал» рекомендуется выполнить
- 4.2 Теги этой статьи
Как работает жесткий диск и логика исправления ошибок по чтению информации с него

Как проверить жесткий диск на работоспособность, а самое главное можно ли убрать сбойные сектора с жёсткого диска или как их ещё зовут-бэд-блоки, которые как оказалось бывают нескольких видов:
– физические (осыпающийся магнитный слой рабочих пластин, сколы и т.д.
),
– логические (ошибки логики сектора), к логическим бэд-блокам, так же можно отнести программные бэды, то есть софт-бэды (ошибки файловой системы).
Многие считают что все сбойные сектора или бэд-блоки убираются обычным форматированием, но это не так.
Физические бэды убрать вообще невозможно, а логические только с помощью специальных программ и только программные бэд-блоки или софт-бэды (ошибки файловой системы) можно убрать обычными средствами Операционной системы, к примеру с помощью команды fsck -y или обычным форматированием.
Итак как проверить состояние жёсткого диска?
Но прежде очень краткая информация о том, как же всё-таки устроен жёсткий диск, если данного отступления не сделать, вы просто не поймёте принцип работы программы для диагностики жестких дисков, Victoria и других подобных программ, тем более не поймёте, что такое S.M.A.R.T, а так же сбойные сектора (бэд-блоки) и почему некоторые из них невозможно исправить.
Жёсткий диск изготовлен из алюминиевых или стеклянных пластин, покрытых слоем ферромагнитного материала. Жёсткий диск это в первую очередь устройство работающее по принципу магнитной записи.
Магнитные головки, считывающие, записывающие или стирающие информацию с жёсткого диска, парят над его поверхностью на высоте 10-12 нм и никогда не касаются поверхности магнитного диска, который легко повредить.
- На заключительном этапе производства винчестера, проводится низкоуровневое форматирование, то есть на рабочие пластины жёсткого диска наносятся дорожки, каждая дорожка делится на секторы. Так же на магнитную поверхность жёсткого диска наносятся специальные магнитные сервометки, они нужны для точного попадания магнитной головки винчестера на дорожки жёсткого диска. Минимальная единица информации на жёстком диске это сектор, объём доступный пользователю составляет 512 байт данных. Низкоуровневое форматирование в жизни жёсткого диска происходит только один раз друзья и только на специальном и очень дорогом заводском оборудовании – называемом Серворайтер. Информация записанная с помощью такого форматирования уже никогда не будет перезаписана. Ни в каком сервисе, такое форматирование сделать не удастся. Поэтому ответ на вопрос, можно ли провести низкоуровневое форматирование средствами операционной системы, будет ответ — нет нельзя. Низкоуровневое форматирование можно сделать только на заводе, оно уничтожает даже дорожки, сектора и магнитные сервометки. К примеру, режим Write в программе Victoria затирает всю информацию на жёстком диске путём заполнения всех секторов нулями, это нельзя назвать низкоуровневым форматированием, но и форматированием назвать нельзя, это что-то среднее. После режима Write все сектора жёсткого диска заполнены нулями и не содержат никаких ошибок и его можно форматировать в файловую систему средствами Операционной системы.
- На заводе в секторы записывается только служебная информация (сервоинформация servo-служба, к примеру физический адрес сектора и адресный маркер, определяющий начало сектора), данную информацию можно назвать разметкой, она нужна для нормальной работы жёсткого диска, это информация о номерах дорожек и секторов, нужная для безошибочного попадания головок на эти дорожки и сектора при считывании информации записанных в них.Уже после покупки жёсткого диска, пользовательские данные так же позже будут записаны в эту область (к примеру первый сектор жёсткого диска будет содержать главную загрузочную запись MBR), но данные пользователя можно будет записывать и стирать, в отличии от служебной информации, которая обладает намного большей намагниченностью, именно поэтому головки чтения-записи накопителя не могут её затереть.
Вся служебная информация о номерах дорожек и секторов будет храниться в специальной таблице, находящейся в закрытой и недоступной для средств ОС и BIOS служебной зоне, представляющей из себя миниоперационную систему, вместе с прошивкой Firmware они управляют работой жёсткого диска.
Иногда задают вопрос — Нужно ли иногда обновлять прошивку жёсткого диска, ответ отрицательный, современные винчестеры в обновлении не нуждаются. Так же в данной служебной зоне будет храниться паспорт диска, значения атрибутов SMART, а так же таблица-дефектов с информацией о невосстановимых или переназначенных сбойных секторах (бэд-блоках).
Вот мы и добрались с Вами до физических, логических и программных сбойных секторов.
Дело в том, что если операционная система, испытывает проблемы с чтением данных с какого-либо сектора, то контроллер винчестера предпринимает ещё несколько дополнительных попыток прочитать данные, если они так же неудачны, данный сектор признаётся сбойным, в дальнейшем информация записывается в нормальный сектор, находящийся на резервной дорожке, а проблемный сектор признаётся сбойным и выводится из обращения, это называется (Remapping, в простонародье ремап).
- проводить ремап или нет, решает только контроллер жёсткого диска в процессе работы, а не какие-либо программы по работе с винчестером (Victoria, MHDD). Данные программы, могут только намекнуть своими тестами (например Advanced REMAP в программе Victoria — улучшенный алгоритм скрытия сбойных блоков) контроллеру винчестера о том, что нужно сделать ремап.
Факт признания сектора сбойным заносится в таблицу-дефектов с информацией о невосстановимых или переназначенных сбойных секторах, находящуюся в служебной зоне.
Кстати таблиц дефектов бывает две, одна начальная P-list (Primary-list), создаётся после конечных заводских испытаний, любой жёсткий диск уже при выходе с завода имеет уже несколько переназначенных бэд-блоков. Ну а растущая таблица дефектов G-list (Grown-list), заполняется по мере использования жёсткого диска уже нами.
Какие бывают сбойные сектора и как их исправить?
- Физические сбойные сектора являются механическими дефектами магнитного покрытия поверхности жёсткого диска (осыпающийся магнитный слой рабочих пластин, сколы и т.д.). То есть сама структура сектора физически является неисправной, несомненно такой бэд-блок подлежит переназначению нормальным сектором с резервной дорожки. Очень часто это происходит из-за удара, вызванного например падением жёсткого диска на пол, образуются механические повреждения магнитного покрытия жёсткого диска, повреждение магнитных головок, то же самое может произойти из-за перегрева. Так же опасна вибрация жёсткого диска, если он ненадёжно закреплён. Пыльное помещение, курение, не смотря на установленный в жёстком диске фильтр, тоже играют огромную роль в образовании бэд-блоков, табачные смолы и пыль прилипают к поверхности жёсткого диска и мешают считыванию информации.
- Физические бэд-блоки невозможно исправить никаким форматированием, можно только переназначить запасными секторами с резервных дорожек, естественно из-за этого несколько упадёт быстродействие, так как магнитной головке винчестера придётся делать много дополнительных движений, выискивая информацию на переназначенных секторах с резервных дорожек.
Почему жёсткий диск скрипит и щёлкает иногда при работе?
Когда операционная система встречает сбойный сектор, контроллер жёсткого диска, предпринимает несколько попыток прочесть информацию из него, при этом щелчки и скрип может издавать позиционер головки винчестера.
Так же причиной щелчков и скрипа жёсткого диска может быть следующая причина. При переназначении сбойного сектора нормальным с резервной дорожки (находящейся не всегда рядом), магнитной головке естественно приходится менять направление, как говорят многие скакать из стороны в сторону.
Третья причина –как я уже говорил выше, при изготовлении жёсткого диска, производится специальная разметка магнитной поверхности жёстких дисков специальными сервометками, служат данные сервометки для точного позиционирования магнитной головки на дорожках винчестера, именно с помощью сервометок магнитная головка винчестера двигается правильно. Иногда сервометки разрушаются по тем же причинам, по которым образуются физические бэд-блоки и магнитная головка не может занять и удержать нужное ей положение, при этом из жёсткого диска раздаются щелчки и скрип.
Последней причиной этому бывает фрагментация, это когда данные на диске расположены не по порядку а в разброс, естественно головке винчестера приходится делать много дополнительных движений, данная проблема актуальна для операционных систем Windows. В файловой системе Ext4, которая используется в актуальной версии образа ПО EasySoft данные записываются последовательно.
- Логические бэд-блоки (ошибки логики сектора), в свою очередь делятся на исправимые и неисправимые. В каком случае логический бэд-блок невозможно исправить? Каждый сектор несёт в себе кроме пользовательской информации ещё служебную (сервоинформацию, например физический адрес сектора и адресный маркер, определяющий начало сектора), простыми словами разметку, при помощи которой магнитная головка винчестера попадает на нужные дорожки секторов, такая разметка наносится путём низкоуровневого форматирования на заводе при изготовлении жёсткого диска. Данную информацию практически невозможно удалить так как она сильно намагничена, но при определённых обстоятельствах, схожих с причинами появления физических бэд-блоков (удар, вибрация, люфт подшипников и так далее) происходит нарушение данной информации и восстановить её можно только в заводских условиях. Да, есть специальные фирменные утилиты перезаписывающие служебную информацию, но в силу сложности их применения, данный вопрос сложен даже для узких специалистов и мы его рассматривать не будем.
- Логические бэд-блоки, которые можно исправить. При записи в сектор пользовательской информации, дополнительно записывается порция служебной информации, так называемая контрольная сумма сектора ECC (Error Correction Code-код коррекции ошибок), данный код позволяет восстанавливать данные, если они были прочитаны с ошибкой. Но бывает данный код не записывается, а соответственно сумма пользовательских данных в секторе не совпадает с контрольной суммой ECC. Одним из простых примеров, почему такое происходит, можно привести внезапное отключение компьютера из-за сбоев с электричеством, из-за этого информация в сектор жёсткого диска была записана, а контрольная сумма нет. В следующий раз операционная система обратится к данному сектору и попробует сосчитать с него данные, но они не будут соответствовать контрольной сумме ECC, будет предпринята попытка прочесть данные ещё раз и опять безуспешно (вот вам и зависания и сбойный бэд-блок).
- Программные бэд-блоки (ошибки файловой системы- например неправильно помеченный сектор, принадлежащий двум файлам) можно убрать средствами операционной системы, проверкой жёсткого диска на ошибки, надёжнее обычным форматированием.
Вы скажете, что всё это хорошо и понятно, но как избавиться от бэд-блоков, может перекинуть с винчестера данные и форматировать в программе установки операционной системы?
При форматировании всеми способами, доступными операционной системе, произойдёт та же самая попытка прочесть информацию из сбойного сектора, потом сравнить их с контрольной суммой ECC, а она не совпадает и значит перезапись неправильной информации не произойдёт и сбойный сектор останется сбойным даже после форматирования. Вот и получается, что нужна специальная программа, например МHDD или Victoria, которая ничего не будет считывать, а просто принудительно сделает перезапись, обычно заполнит сбойный сектор нулями, а вот затем уже прочитает записанное и сравнит контрольную сумму, после этого сектор вернётся в работу.
А лучше всего совсем снять ваш жёсткий диск и подсоединить его к другому компьютеру имеющему программу для диагностики, затем запустить тест Erase и проверить весь ваш винчестер. Можно и не снимать ничего, записать на загрузочный накопитель программы MHDD или Victoria, загрузиться с них и запустить данные программы с функцией Advanced remap, но это мы сделаем в других статьях.
Примечание: читайте по этой теме новую статью Как пользоваться одной из легендарных программ по диагностике жёстких дисков под названием Victoria!
Источник: http://support.easysoft.ua/diagnostika-oborudovaniya-terminala/kak-rabotaet-zhestkij-disk-i-logika-ispravleniya-oshibok-po-chteniyu-informatsii-s-nego/
Проверяем и устраняем ошибки и битые сектора жесткого диска

Жесткий диск компьютера — очень чувствительный компонент. Появившиеся ошибки в его файловой системе, битые сектора на поверхности, механические неполадки иногда становятся причиной полного отказа компьютерной системы.
Те же проблемы характерны для флеш-накопителей, которые по своей сути практически ничем не отличаются от винчестера. Как же определить наличие ошибок и бэд-секторов и как по возможности их исправить?
Совсем чуть-чуть теории
Многие просто путают ошибки файловой системы и плохие сектора. Поэтому попытаемся разъяснить разницу между этими явлениями и причину их появления. Также, определим, какой может оказаться симптоматика проявлений, появившихся ошибок на поверхности винчестера.
Ошибки файловой системы
Когда говорят об ошибках жесткого диска и попытке их исправить с помощью встроенной в Windows утилиты chkdsk, то чаще всего имеют в виду именно ошибки файловой системы. Такие ошибки связаны с проблемами метаданных, описывающих саму файловую систему: ошибки файлов $Bitmap, $BadClus, главной файловой таблицы, различных индексов.
Например, ошибки в файле $Bitmap файловой системы NTFS могут стать причиной неверного распознавания системой объема свободного пространства тома. А проблемы с файлом $BadClus могут привести к неверному определению бэд-секторов и попытке записи данных в такие сектора, что станет причиной полного зависания компьютера.
Битые сектора
Природа битых секторов несколько иная. Жесткий диск «нарезается» на сектора еще на заводе при производстве. Именно тогда создается его логическая структура, тогда он получает магнитные свойства для записи данных.
Эти структуры становятся сбойными в результате постепенной деградации областей поверхности жесткого, которые становятся таковыми из-за неосторожного обращения с винчестером, который нечаянно когда-то упал на пол или подвергся удару по корпусу даже обыкновенной отверткой.
Тестирующие программы, попадающие на части деградирующей поверхности, обнаруживают так называемые сбойные или поврежденные сектора — бэд-сектора. Потерявшие магнитные свойства сектора не позволяют считывать и записывать в них данные.
Устранить сбойные структуры винчестера возможно. Для этого производители создают специальные резервные области секторов.
При появлении бэд-сектора, диагностируемого по определенному адресу, его адрес переназначается сектору из этой резервной области.
Симптомы проявления ошибок и битых секторов
О симптоматике проявления ошибок файловой системы мы уже немного поведали выше. Однако симптомы иногда очень разнообразны. Приведем некоторые проявления возникших в винчестере ошибок и битых секторов.
- Заметное подвисание операционной системы при выполнении операций считывания и записи.
- Отказ при загрузке операционной системы. Например, загрузка продолжается только до появления уведомления о загрузке и эмблемы Windows.
- Внезапная перезагрузка компьютера.
- Частое возникновение ошибок в работе операционной среды.
- Чрезвычайно медленная и непроизводительная работа операционной системы.
Здесь приведен далеко неполный список проявлений ошибок, связанных с неполадками файловой системы и наличием деградирующих областей жесткого диска. Что же делать в таких случаях?
Проверяем ошибки средствами Windows
Проверка и исправление ошибок файловой системы в Windows осуществляется штатной утилитой этой операционной среды под названием chkdsk.
Она также может быть полезна при устранении программно возникших сбойных секторов в результате действия вирусов.Ее можно запустить как в графической среде, так и из командной строки.
Рассмотрим наиболее доступный вариант ее выполнения в графической среде.
Проверка неактивного тома
Проверка неактивного тома наиболее простая. Выполнить ее можно полностью в графическом режиме. Под неактивным томом подразумеваем раздел, на котором не установлена действующая в данный момент операционная система. Это может быть подключенный другой винчестер или, например, диск D.
Нажмем кнопку «Выполнить проверку».
Запуск утилиты осуществляется из вкладки «Сервис» свойств тома. В данной вкладке находится кнопочка «Выполнить проверку». Если нажать ее, то откроется окошко утилиты chkdsk.
Для проверки битых секторов, которые появились в результате программных ошибок нужно установить флажок напротив соответствующей опции.
Далее, достаточно нажать кнопочку «Запуск» — утилита произведет проверку и исправление ошибок.
Утилита chkdsk проверяет том D, диагностируя также сбойные сектора.
Проверка системного тома
Проверка и исправление ошибок системного тома, где находится действующая на момент проверки операционная среда, осуществляется немного по-другому. Утилита определяет такой том как подключенный, а поэтому предупреждает, что выполнить проверку она не может, но предлагает произвести ее при последующей перезагрузке.
Утилита chkdsk сообщает, что не может проверить диск.
Перезагрузив компьютер, пользователь обнаружит, что во время загрузки, после появления эмблемы Windows, появляется черный экран. Этот черный экран постепенно заполняется строчками текста. Это работает утилита chkdsk, проверяющая системный том жесткого диска. После проверки и необходимых исправлений, она продемонстрирует результат, а затем загрузка операционной системы продолжится.
Утилита chkdsk проверяет том С после перезагрузки.
Программы проверки жесткого диска на бэд-сектора
На рынке программного обеспечения существует целый ряд приложений, умеющих тестировать поверхность жесткого диска. При этом тестируется не один какой-либо том, а вся поверхность винчестера. Конечно же, пользователь может самостоятельно установить граничные сектора и протестировать отдельные области. Для определения сбойных секторов обычно проводят тест на считывание данных сектора.
Важно: результаты теста на наличие поврежденных секторов обязательно следует рассматривать в комплексе со SMART показателями, такими как Reallocation Sector Count, Reallocation Event Count.
Data Lifeguard Diagnostic
Эта утилита создана разработчиками компании Western Digital. Она доступна для загрузки на официальном сайте компании. Lifeguard Diagnostic отлично работает с винчестерами практически любого производителя, а не только с родными для WD жесткими, как можно было бы подумать. Она предлагает ряд тестов: Быстрый, Расширенный, а также возможность заполнения нулями секторов винчестера.
Интерфейс утилиты Data Lifeguard Diagnostic.
Нас больше всего интересует расширенный тест. Данный тест позволяет обнаружить поврежденные сектора на поверхности дисков. Когда программа находит бэд-сектор, она сообщает об этом пользователю, предлагая ему выбрать, хочет ли он исправить обнаруженную ошибку. Если он соглашается, то приложение записывает в сектор 0, поэтому данные сектора будут потеряны.
Выборка тестов утилиты. Нам нужен Extended Test.
Продолжительность этого теста длительней быстрого теста. Время тестирования зависит от размера накопителя, так как тест проводится пот всей поверхности, начиная от 0 сектора и заканчивая максимальным значением LBA.
Extended Test утилиты в работе.
Отличным тестировщиком поверхности винчестера представляется также приложение HDDScan. Его часто можно увидеть в составе целых программных комплексов таких как LiveCD. Это приложение имеет графический интерфейс и предлагает целый ряд тестов, среди которых в нашем случае наиболее интересен «Surface Tests».
Выберем тест Surface Test из выпадающего списка.
Важно: при проведении тестов поверхности из-под Windows необходимо закрыть все работающие программы, чтобы избежать во время теста случайных результатов, инициированных действием этих программ.
После выбора теста, откроется дополнительное окошко, в котором представлены параметры теста. Оставим опцию «Read» включенной, что позволит только лишь считывать данные из секторов.
Так, мы определим сектора, из которых нельзя считать информацию за установленное время (бэд-сектора), сектора зависания и нормальные ячейки.
Поля начального и конечного секторов оставим без изменения, если хотим проверить всю поверхность.
Оставим опцию Read теста включенной.
При тестировании этой программой выявляется целый ряд секторов:
- бэд-сектора,
- сектора зависания, на считывание данных из которых уходит более 500 мс,
- сектора с временем считывания от 150 до 500 мс,
- сектора с временем считывания от 50 до 150 мс,
- сектора с временем считывания от 20 до 50 мс,
- сектора с временем считывания от 10 до 20 мс,
- нормальными HDDScan считает такие сектора, данные которых считываются за 5 мс.
Результат теста программы доступен в виде линейного графика, карты распределения секторов, а также в виде обычного текстового отчета.
Проверка поверхности жесткого диска.
Ashampoo HDD Control
В отличие от выше рассмотренных программ HDD Control не является бесплатной программой. Это приложение — целый комплекс инструментов, предназначенных для восстановления здоровья жесткого диска. Предлагает эта программа также возможность протестировать поверхность винчестера.
Выберем опцию «Тестирование поверхности».
Тест очень простой и доступный обыкновенному пользователю HDD Control. Для его запуска нужно лишь нажать кнопку «Тестирование поверхности». Он лишен дополнительных опций, которые позволили бы настроить вид теста. При тестировании выявляются лишь два вида секторов: с отличным результатом считывания и бэд-сектора.
Ashampoo HDD Control проверяет поверхность диска.
Victoria HDD
Victoria — наиболее популярная программа среди IT-специалистов, работающих с жесткими дисками и их проблемами. Она также обладает графическим интерфейсом, однако может быть выполнена не только в графическом режиме Windows, но и в режиме DOS, что делает ее незаменимым помощником при работе с жесткими.
Victoria считает здоровье проверяемого жесткого диска «GOOD».
Это приложение умеет собирать информацию о SMART-здоровье винчестера. Также, оно позволяет провести тест поверхности диска, осуществить переназначение поврежденных секторов операцией Remap, обнулить бэд-сектора. Она также подразделяет сектора по группам:
- сбойные сектора (Error),
- сектора зависания с временем считывания более 600 мс,
- сектора зависания с временем считывания от 200 до 600 мс,
- сектора с временем считывания от 50 до 200 мс,
- сектора с временем считывания от 20 до 50 мс,
- нормальные сектора Victoria диагностирует в рамках считывания данных до 5 мс.
Чтобы произвести тестирование жесткого диска, можно запустить эту программу в графическом режиме Windows. Далее, понадобится выбрать вкладку «Tests». Именно там расположены тесты поверхности. Доступно четыре опции работы с поверхностью жесткого:
- Ignore,
- Remap,
- Erase,
- Restore.
Первым делом, можно осуществить тест Ignore, чтобы определить есть ли на поверхности винчестера сбойные сектора. Если они есть, то нужно приступать к тесту Remap. Данный тест позволит переназначить адреса поврежденных секторов в область зарезервированных, где размещены нормальные сектора.
Виды доступных тестов и категории секторов. Victoria проверяет поверхность.
Если после теста Remap Victoria продолжает диагностировать плохие сектора, то можно еще попытаться восстановить их работоспособность, применив тест Restore.
Опцию Erase нужно использовать с умом из-под Windows, так как она записывает нули в сектора — стирает данные секторов.
Ею можно пользоваться только в пределах какой-либо выборки секторов, данные которых не имеют отношения к операционной системе.
Краткий итог
Следует отметить, что существует разница между ошибками, устраняемыми утилитой chkdsk операционной системы Windows и сбойными секторами, устраняемыми такими программами как Victoria HDD.
Первые вызываются неполадками файловой системы, а вторые часто являются результатом потери магнитных свойств секторами поверхности жесткого диска и постепенной его деградации.
Однако и chkdsk умеет устранять некоторые проблемы сбойных секторов.
Для устранения бэд-секторов можно воспользоваться такими приложениями как: Data Lifeguard Diagnostic, Ashampoo HDD Control, HDDScan, Victoria.
Выделим приложение Victoria HDD как наилучшее для проверки и устранения битых секторов, так как оно предлагает целый ряд тестов: Ignore, Remap, Erase и Restore.
Оно позволяет не только обнаруживать сбойные структуры поверхности жесткого, но и лечить HDD.
Источник
Юрий созерцатель
- Активность: 105k
- Пол: Мужчина
Юрий созерцатель
Источник: https://pomogaemkompu.temaretik.com/1547116231213714262/proveryaem-i-ustranyaem-oshibki-i-bitye-sektora-zhestkogo-diska/

Привет, друзья! Один хороший человек попросил посмотреть его жесткий диск. Диск емкостью 500 Гб, Seagate, выкидывать такой жалко. Система стала жутко тормозить. Позже Windows перестала с него нормально загружаться, запуск долгий, автоматическое восстановление при загрузке результатов не давало. Появились равномерные стуки. Они хорошо ощущаются, если приложить ладонь (очень мощный инструмент для анализа всего и вся
Источник: https://fast-wolker.ru/proverka-smart-zhestkogo-diska-viktoriya.html
Сброс SMART на жестких дисках SEAGATE. Обнуление SMART HDD. Ремонт HDD Seagate
Винчестеры Seagate Barracuda очень популярны среди пользователей персональных компьютеров. Многие диски отрабатывают по 5-10 лет и имеют при таком возрасте отличное «здоровье».
Под словом «здоровье» я понимаю как само функционирование жесткого диска, его скорость и стабильность, так и показатели его системы самодиагностики и восстановления S.M.A.R.T.. Зачастую, за многие годы работы, показатели системы самодиагностики S.M.A.R.T.
изменяются с момента начала использования жесткого диска. В этих показателях самим жестким диском запоминаются такие параметры как: максимальная температура жесткого диска, время работы жесткого диска (часы наработки), количество включений и выключений, количество парковок головок и т.д.
Однако, самые нежелательные показатели, которые могут появится при многолетней работе жесткого диска — это количество сбойных секторов.
Причины появления сбойных секторов бывают разные. Основная причина — время.
Со временем на диске, даже очень качественном, могут появляться участки с нестабильным чтением записанной информации, особенно если эта информация была записана очень давно, а диск не использовался долгое время.
Среди причин могут быть и низкое качество самих пластин жесткого диска, некачественная сборка или использование дешёвых материалов при изготовлении HDD производителем.
Однако бывают случаи, когда сбойные сектора появляются не по причине самого жесткого диска.
Я имею ввиду случаи, когда происходит выключение питания в момент записи информации на диск, или дефект в SATA кабеле, или ошибки в контроллере SATA на материнской плате компьютера, или нестабильная работа блока питания ПК (скачки напряжения по линиям 5V и 12V).
В этих случаях система самодиагностики может найти на поверхности жесткого диска от нескольких штук, до нескольких тысяч так называемых «софтовых бэдов», т.е. участков, где информация не может прочитаться, т.к. не совпадают контрольные суммы с самой информацией, что записана в эти блоки.
Система диагностики зачастую определяет их как нестабильные или плохие и изменяет показатели системы S.M.A.R.T. не в лучшую сторону. Система S.M.A.R.T. может даже заменить эти блоки хорошими и в своих показателях отобразить их как Realocated (перемещённые), хотя сами блоки могут быть очень даже хорошими. Такое бывает довольно часто, но не всегда.
Ниже на фото показан скриншот программы Victoria с показателями S.M.A.R.T. проблемного диска. Можно видеть более тысячи уже перемещённых секторов и сотни готовящихся к перемещению.
Итак, что мы можем сделать, чтобы попытаться вернуть показатели S.M.A.R.T. в норму? Мы можем обнулить показатели S.M.A.R.T. или перенести плохие сектора в скрытую область системы самодиагностики, так называемый P(Slip)-лист.
Эта операция не гарантирует того, что после обнуления показателей, эти показатели через несколько дней или недель не появятся вновь. Если диск действительно имеет плохие сектора, то система самодиагностики их выявит и пометит через некоторое время использования диска.
Так что Вам скорее всего не получится из действительно «убитого» жесткого диска сделать «конфетку».
В данном руководстве изложена процедура сброса показателей S.M.A.R.T. для жестких дисков Seagate Barracuda 7200.11, Seagate Barracuda 7200.12, Seagate Barracuda ES, Seagate Barracuda ES.2. На других жестких дисках Seagate Barracuda я не проверял, возможно процедура подобная.
Для начала нам необходимо обзавестись адаптером RS232-to-TTL. Можно cобрать переходник на базе микросхемы MAX232 как показано на схеме:
Примечание к схеме: Если есть возможность подключиться к стабилизированному напряжению +5В, то схему можно упростить, выкинув из нее стабилизатор 7805 с двумя конденсаторами обвязки.
Альтернативная схема адаптера RS232-to-TTL:
Ещё, как вариант, можно использовать USB программатор на CH341A как адаптер USB в TTL. Он позволит подключится даже к компьютеру без COM порта. Подключение будет осуществлятся через USB, что более удобно. Купить USB программатор на CH341A можно у нас в магазине с доставкой по Украине службами доставки.
Внимание! Всё, что Вы будете делать дальше, делается Вами на свой страх и риск. Это может привести как к потере информации, так и поломке самого жесткого диска!
Далее порядок действий следующий:
1.) Если на жестком диске установлена перемычка «режим работы SATA I», то заранее уберите эту перемычку, переводящую диск в режим работы SATA I.
2.) Подключаем контроллер 232-to-TTL к COM порту. (Если Вы используете USB конвертер или программатор на CH341A в качестве 232-to-TTL адаптера, то драйвер должен быть уже установлен заранее. Описывать установку драйвера я не буду.)
3.) Запускаем программу ГиперТерминал (входит в состав Windows XP).
Если у Вас установлена Windows Vista, Windows 7, Windows 8 или более новая, то в стандартной поставке ГиперТерминал не входит. Вы можете скачать англоязычную версия HyperTerminal с нашего сайта.
Запускаем HyperTerminal и вводим название подключения. Название подключения указываем любое, я ввёл «1«.
4.) В гипертерминале выбираем COM порт. У меня COM3, у Вас может быть другой. Всё зависит от того как Вы подключили адаптер 232-to-TTL.
5.) Устанавливаем скорость порта 38400, управление потоком — нет, остальное по умолчанию как показано ниже на скриншоте.
6.) Перед подключением контроллера 232-to-TTL к жесткому диску рекомендую проверить работу связки ГиперТерминала и адаптера 232-to-TTL.
Для проверки работоспособности замкните между собой Rx и Tx проводки и в окне ГиперТерминала напечатайте что-то на клавиатуре. В окне должны отображаться введённые символы — «эхо» терминала. Каждый введенный вами символ — должен появлятся на экране (возвращаться через Tx-Rx).
Если «эхо» нет, значит ваш девайс не работает или неправильно настроен COM порт. На деле это выглядит так: подключаем кабель — запускаем теминал — настраиваем его на нужный порт — пытаемся что-нибудь напечатать — в терминале тишина. Значит что-то не работате.
Если замыкаем Tx-Rx — пытаемся что-нибудь напечатать — в терминале появляется то, что мы напечатали. Вывод — «эхо» работает и у нас всё готово к подключению HDD диска.
7.) Тремя проводками подключаем контроллер 232-to-TTL к винчестеру. Подключаем Tx и Rx как показано на фото (GND можно не подключать, но в этом случае возможны появления в ГиперТерминале лишних символов — мусора). Я подключал все три провода.
8.) Подаем питание на винчестер. В результате у Вас должно быть вот такое подключение:
9.) В ГиперТерминале наблюдаем подобное сообщение:
Rst 0x20M(P) SATA Reset
10.) Один раз жмем CTRL+Z и терпеливо ждем приглашение в виде:
F3 T>
Примечание: Чтобы увидеть список команд и описание к ним для вашего жесткого диска, необходимо ввести /C и «Enter», а затем Q и «Enter». Не забудьте после просмотра команд опять перейти в режим T командой /T.
11.) Набираем /1 жмем «Enter» (переход на уровень 1). Наблюдаем на терминале:
F3 2>/1
F3 1>
12.) Набираем N1 жмем «Enter» (очистка SMART и снятие блокировки «CC»). Наблюдаем на терминале:
F3 1>N1
F3 1>
13.) Набираем /T жмем «Enter» (переход на корневой уровень). Наблюдаем на терминале:
F3 1>/T
F3 T>
14.) Отключаем разъём питания жесткого диска (все остальное включено) на 10 сек. Жесткий диск полностью останавливается за 8-10 секунд.
15.) Включаем разъём питания жесткого диска. Диск раскручивается. Видим сообщение:
Rst 0x20M (P) SATA Reset
16.) Жмем Ctrl+Z. Наблюдаем на терминале:
F3 T>
17.) Набираем команду чтобы перенести из G(Alt)-листа дефекты в заводской P(Slip)-лист m0,2,3,,,,,22 и жмем «Enter». Наблюдаем на терминале:
F3 T>m0,2,3,,,,,22
Винт через некоторое время (от полу минуты до нескольких минут) напишет длинное сообщение вроде этого:
Max Wr Retries = 00, Max Rd Retries = 00, Max ECC T-Level = 14, Max Certify Rewrite Retries = 00C8 User Partition Format 4% complete, Zone 00, Pass 00, LBA 00004339, User Partition Format Successful — Elapsed Time 0 mins 30 secs
F3 T>
Далее m0,2,2,,,,,22 и жмем «Enter». Наблюдаем на терминале:
F3 T>m0,2,2,,,,,22
Max Wr Retries = 00, Max Rd Retries = 00, Max ECC T-Level = 14, Max Certify Rewrite Retries = 00C8 User Partition Format 4% complete, Zone 00, Pass 00, LBA 00004339, User Partition Format Successful — Elapsed Time 0 mins 30 secs
F3 T>
18.)Этот пункт можно пропустить. Теперь можно полностью отформатировать весь диск. Процесс форматирования может занять от получаса до нескольких часов. Набираем m0,8,2,,,,,22 и жмем «Enter». Наблюдаем на терминале:
F3 T>m0,8,2,,,,,22
И дальше много строк в процессе форматирования всего диска. В конце процесса мы получим следующее:
F3 T>
19.) Набираем /2 жмем «Enter» (переход на уровень 2). Наблюдаем на терминале:
F3 T>/2
F3 2>
20.) Набираем Z жмем «Enter» (команда на останов двигателя). Наблюдаем на терминале:
F3 2>Z Spin Down Complete Elapsed Time 0.138 msecs
F3 2>
Жесткий диск пишет что остановил двигатель.
21.) Выключаем разъём питания жесткого диска. Выключаем компьютер. Подсоединяем винчестер в штатном режиме и готовимся радоваться.
После всех процедур через «Терминал» рекомендуется выполнить
Отключаем питание. Выключаем компьютер. Подсоединяем винчестер к компьютеру в штатном режиме. Контролле SATA рекомендую перевести из режима AHCI в IDE если этого не сделано ранее, так будет меньше шансов, что диск не определится.
Проделываем следующее:
- Полное стирание жёсткого диска в программе Victoria (Erase), SeaTools или MHDD;
- Затем Scan + Remap в программе Victoria (проверку со включенным Remap) для того, чтобы точно убедиться, что диск имеет только хорошие блоки;
- Затем создаём на диске раздел в системе NTFS и заливаем на весь диск информацию, лучше всего видео AVI, музыку MP3 или архивы RAR;
- Выключаем и отлаживаем диск на денёк (неделю) на полку, отлежаться. Если времени в обрез, то можно этот пункт пропустить.
- Затем снова подключаем и прогоняем несколько раз в программе Victoria весь диск в режиме Scan + Remap, как в пункте 2.
Статья написана по материалам сайта: www.texnotron.com
Теги этой статьи
Близкие по теме статьи:
Источник: http://www.sector.biz.ua/docs/clear_s.m.a.r.t._on_seagate_hdd/clear_s.m.a.r.t._on_seagate_hdd.phtml