Why exactly is a «Raw Read Error Rate» of 1 considered bad? Isn’t it the lower the read error rate, the better the reads (and the less the errors)?
Your research has found that this Raw Read Error Rate is derived from the «total number of correctable and uncorrectable ECC error events». The number is normalized and treated as a percentage, so the current value represents 1%, i.e. 1% of read operations have had an issue.
Modern NAND chips explicitly mandate ECC capability because occasional bit errors on read can occur during normal operation. The requirement will specify a permissible number of bits that might be in error per NAND page read, and need correction.
In other words a read operation may occasionally incur correctable errors, and therefore this is not an indicator of pending failure.
The occurrence of uncorrectable read errors could be problematic. In theory a sector/page/block that (consistently) generates uncorrectable read errors should be identified by the integrated drive controller, marked as a bad block, and retired from use.
The Raw Read Error Rate is not as significant as the number of uncorrectable read errors (which is now available in the SMART report that you appended).
The number of uncorrectable read errors seems to be indicated in Reported Uncorrectable Errors as 0x1B3 or 435.
Compared to the total read errors of 0x1C9 or 457, that would indicate that there were only 22 (benign) correctable read errors (assuming no wrap-around), but 95% of that total are the concerning uncorrectable read errors.
Does this mean my SSD is about to fail imminently? It has been working fine since I bought my laptop years ago…
If you think that the drive is «working fine», then that could mean that the drive was able to recover from those errors by retrying successfully and/or remapping was successful. (Note that the SMART report indicates that 9 blocks have been retired so far during this drive’s lifetime.)
At the very least you could backup your data from that drive, and regularity monitor the SMART report for changes.
With almost 20,000 hours of use, there’s no way to determine when these errors occurred.
But you could try to generate fresh read errors by scanning the entire drive, either using the SMART long/extended test or using a Linux command such as sudo dd if=/dev/sdX of=/dev/null. The first test is a lot faster but would only increment the SMART statistics, whereas the later test could also abort on a read error and thus provide a LBA of a problem area.
If you do not encounter more read errors, then that could be reassuring.
Note that the SMART report indicates the current value of 98% for Percent Lifetime Used indicates that only 2% of the expected lifetime has been used. The raw value of 2 indicates that neither of the two salient end-of-life indicators (average block wear and available spare blocks) are problematic.
Why exactly is a «Raw Read Error Rate» of 1 considered bad? Isn’t it the lower the read error rate, the better the reads (and the less the errors)?
Your research has found that this Raw Read Error Rate is derived from the «total number of correctable and uncorrectable ECC error events». The number is normalized and treated as a percentage, so the current value represents 1%, i.e. 1% of read operations have had an issue.
Modern NAND chips explicitly mandate ECC capability because occasional bit errors on read can occur during normal operation. The requirement will specify a permissible number of bits that might be in error per NAND page read, and need correction.
In other words a read operation may occasionally incur correctable errors, and therefore this is not an indicator of pending failure.
The occurrence of uncorrectable read errors could be problematic. In theory a sector/page/block that (consistently) generates uncorrectable read errors should be identified by the integrated drive controller, marked as a bad block, and retired from use.
The Raw Read Error Rate is not as significant as the number of uncorrectable read errors (which is now available in the SMART report that you appended).
The number of uncorrectable read errors seems to be indicated in Reported Uncorrectable Errors as 0x1B3 or 435.
Compared to the total read errors of 0x1C9 or 457, that would indicate that there were only 22 (benign) correctable read errors (assuming no wrap-around), but 95% of that total are the concerning uncorrectable read errors.
Does this mean my SSD is about to fail imminently? It has been working fine since I bought my laptop years ago…
If you think that the drive is «working fine», then that could mean that the drive was able to recover from those errors by retrying successfully and/or remapping was successful. (Note that the SMART report indicates that 9 blocks have been retired so far during this drive’s lifetime.)
At the very least you could backup your data from that drive, and regularity monitor the SMART report for changes.
With almost 20,000 hours of use, there’s no way to determine when these errors occurred.
But you could try to generate fresh read errors by scanning the entire drive, either using the SMART long/extended test or using a Linux command such as sudo dd if=/dev/sdX of=/dev/null. The first test is a lot faster but would only increment the SMART statistics, whereas the later test could also abort on a read error and thus provide a LBA of a problem area.
If you do not encounter more read errors, then that could be reassuring.
Note that the SMART report indicates the current value of 98% for Percent Lifetime Used indicates that only 2% of the expected lifetime has been used. The raw value of 2 indicates that neither of the two salient end-of-life indicators (average block wear and available spare blocks) are problematic.
Часто интересуетесь техническим состоянием жёсткого диска с результатами работы, фото- и видеоархивами? Вряд ли. Раз тема заинтересовала, значит почуяли неладное с накопителем. У нас сможете загрузить инструмент для диагностирования Кристал Диск Инфо. Мы научим пользоваться приложением, дадим расшифровку параметров программы.
Как проверить жесткий диск с помощью CrystalDiskInfo
Бесплатная утилита от разработчика hiyohiyo для считывания и вывода на дисплей в удобном для человеческого восприятия виде параметров S.M.A.R.T. Мониторит температуру и определяет состояние носителя цифровой информации, сообщает технические и эксплуатационные параметры устройства.
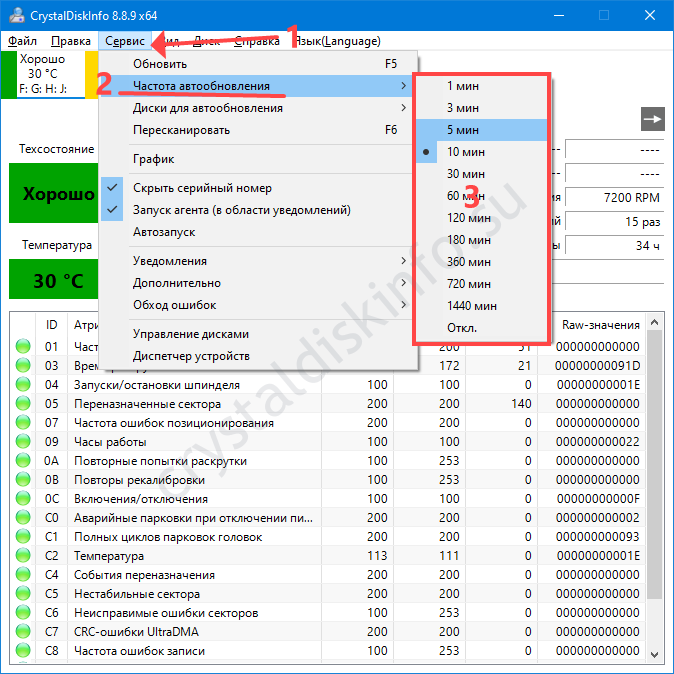
CrystalDiskInfo считывает информацию о накопителе в момент запуска, регулярно в окне изменяется только температура. Остальные сведения повторно считываются каждые 10 минут (по умолчанию), но разработчик предусмотрел функцию повторного получения данных S.M.A.R.T. через пункт меню «Сервис» либо клавишей F6.
Через раздел «Сервис» изменяется частота обновления сведений.
Под меню расположены обнаруженные накопители, ниже – их «здоровье», температура. Справа – технические и эксплуатационные характеристики: скорость вращения пластин, тома, интерфейс и режим передачи информации, время работы, ресурс. Внизу – таблица с перечнем S.M.A.R.T.-данных. Большинство людей интересуют переназначенные и нестабильные секторы – частые причины выхода накопителя из строя.
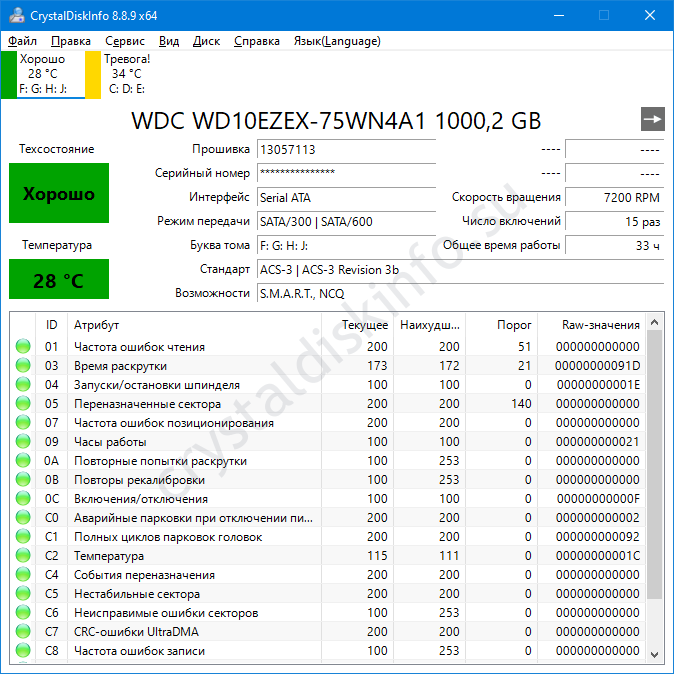
Как проверить общее состояние диска?
Показатель «Техсостояние» определяется, исходя из значений S.M.A.R.T. Чем больше проблем или они серьёзнее, тем ниже оценка.
Кнопка имеет несколько состояний:
- серая – неизвестно;
- зелёная – хорошо;
- жёлтая – тревога;
- красная – критическое состояние.
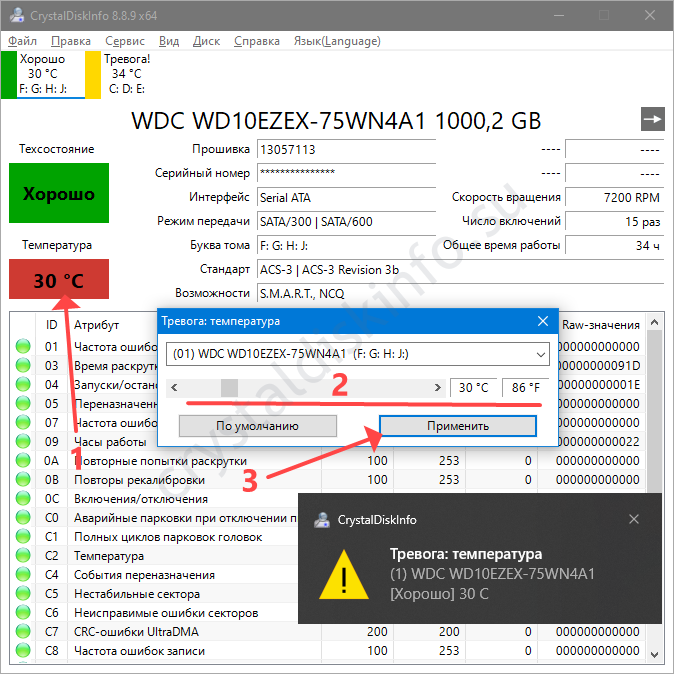
Температура обновляется ежесекундно. Кликом по иконке вызовете окно для изменения пикового значения, при достижении которого получите уведомление.
S.M.A.R.T.-показатели жесткого диска
Количество записей в таблице отличается в зависимости от накопителя. В старых устройствах могут отсутствовать последние параметры из списка. Чтобы пользоваться Crystal Disk Info, нужно понимать значения (расшифровку) атрибутов S.M.A.R.T.
- Частота ошибок чтения – периодичность появления проблем при чтении и записи.
- Время раскрутки – продолжительность разгона шпинделя с нуля до рабочего состояния.
- Запуски/остановки шпинделя – число запусков и остановок шпинделя.
- Переназначенные сектора – количество секторов, заменённых на резервные.
- Частота ошибок позиционирования – как часто головка оказывается в неправильном месте.
- Часы работы – отработанное время.
- Повторные попытки раскрутки – число повторных запусков, если первый оказался неудачным.
- Повторы рекалибровки – повторные попытки сброса накопителя.
- Включения/отключения – число полных циклов включений-отключений.
- Аварийные парковки при отключении питания.
- Полных циклов парковок головок.
- Температура – текущий показатель.
- События переназначения – число операций переназначения.
- Нестабильные сектора – кандидаты на переназначение.
- Неисправимые ошибки секторов – аналог предыдущего атрибута. Секторы, обнаруженные при самотестировании во время простоя накопителя.
- CRC-ошибки UltraDMA – количество проблем, возникших при передаче в режиме UltraDMA;
- Частота ошибок записи.
Способы лечения жесткого диска
Через Кристал Диск Инфо избавиться от проблем с битыми секторами нельзя. Для их переназначения воспользуйтесь средством Windows или утилитой Victoria (подробнее в статье). Если накопитель перегревается, позаботьтесь об охлаждении: почистите корпус от пыли, купите подставку для ноутбука. Убедитесь, что программы и вирусы не нагружают HDD под 100%.
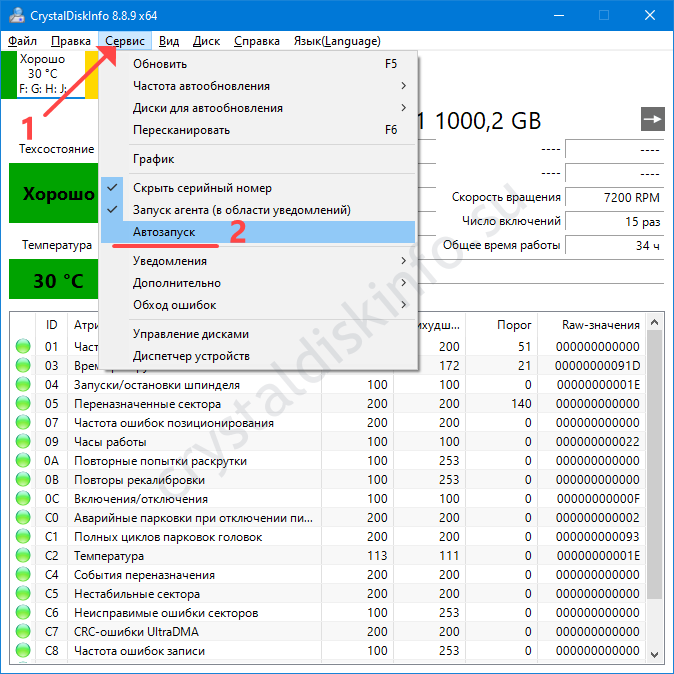
Как настроить автозапуск для CrystalDiskInfo
Для мониторинга температуры Кристал Диск Инфо целесообразно загружать с операционной системой. Скопируйте ярлык программы в папку Автозагрузка в Пуске или поставьте флажок возле опции «Автозапуск» в пункте главного меню «Файл».
Как настроить уведомления в программе
Кристал Диск Инфо оповестит об обнаружении проблем всплывающим информационным окном, звуковым сигналом или сообщением на указанный почтовый ящик. Для выбора способа уведомления поставьте соответствующий флажок в одноимённом пункте меню «Сервис».
Запуск «агента»: для чего нужен
Агент Кристал Диск Инфо – модуль, работающий в фоне и отслеживающий изменения в дисковой подсистеме. При обнаружении проблем (перегрев, изменение S.M.A.R.T.) выводит уведомление с информацией о неполадке. В разделе «Сервис» поставьте флажок возле опции «Запуск Агента».
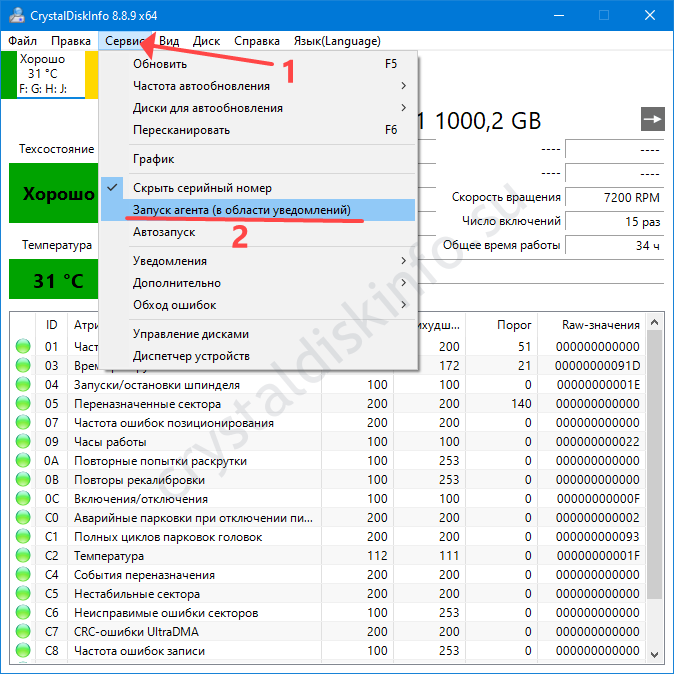
Как «найти» жесткий диск, если CrystalDiskInfo его не обнаружил
Если уверены, что твердотельный или жёсткий накопитель исправный, например, обнаруживается в BIOS и утилитой «Управление дисками»:
- Разверните пункт меню «Сервис».
- Через подраздел «Дополнительно» кликните по «Расширенный поиск дисков».
Управление энергопитанием и уровнем шума жестких дисков
Кристал Диск Инфо позволяет управлять уровнем шума для повышения акустического комфорта.
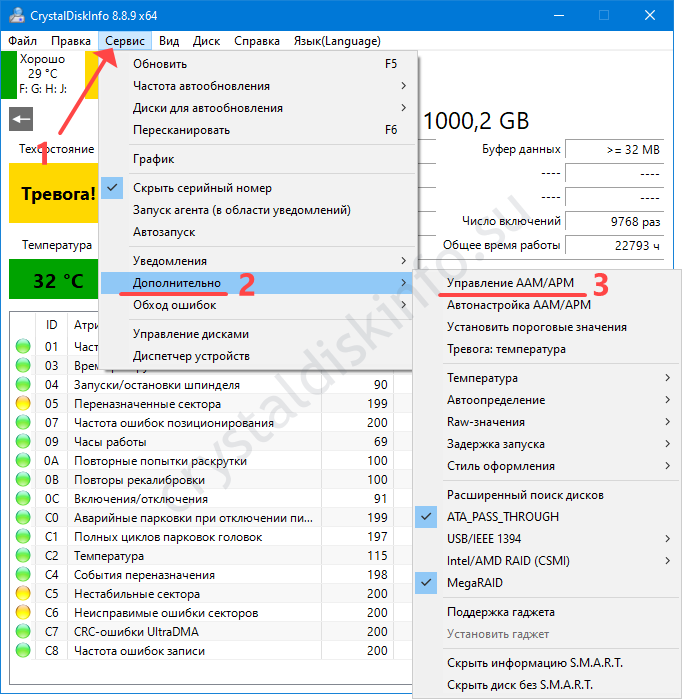
- Выберите винчестер в выпадающем списке.
- Перетаскивайте первый ползунок (AAM) влево для снижения интенсивности шума, вправо – для увеличения.
- Второй ползунок (APM) отвечает за энергопотребление устройства.
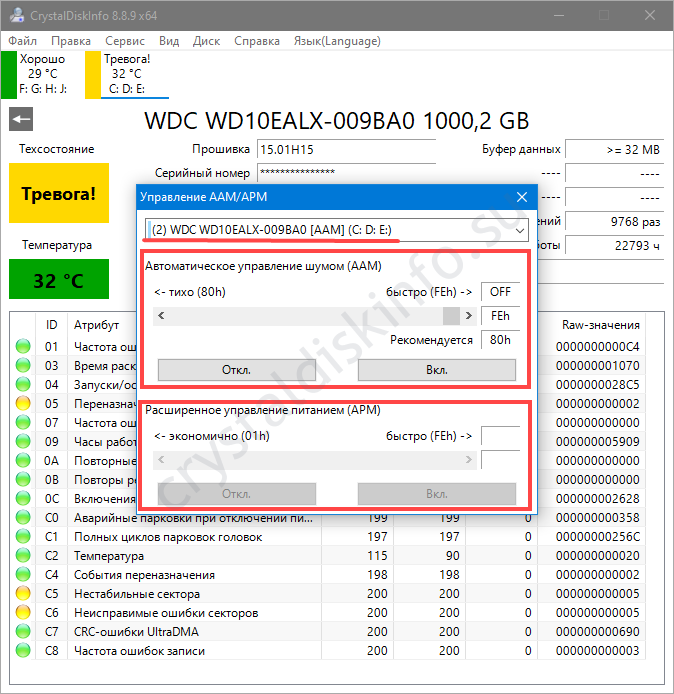
Для возврата параметров выставьте автоматическую настройку.
Вопросы и ответы
Спрашивайте – ответим.
Как ведет себя программа в случае «Тревоги»?
Выводит текстовое уведомление. Если указано, отправит сообщение на почту, проиграет выбранный звуковой файл.
Если нужно сделать скриншот, то как скрыть серийный номер?
Поставьте флажок возле пункта «Серийный номер» в списке «Сервис».
Как посмотреть график температуры?
Через главное меню откройте окно с графиками, выбрав диск из списка под главным меню (если на ПК несколько устройств).
В выпадающем перечне укажите «C2 Температура» в подразделе «Нормированные значения».
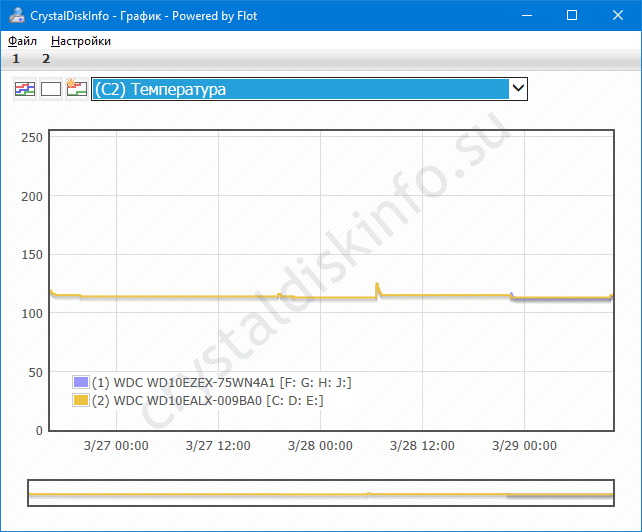
Содержимое можете сохранить в файл, изменить представление информации.
Жёсткие диски HDD — надёжные и выносливые устройства, но всё же не вечные. Как и все механизмы, они подвержены повреждениям и физическому износу, в результате которого на диске появляются так называемые бэды и прочие ошибки. Обнаруживаются они, как правило, при анализе диска утилитами вроде CrystalDiskInfo. Поводом же для проверки диска становятся различные неполадки.
Источником проблем в конкретной ситуации нестабильные показатели SMART могут и не являться, однако их появление способно повергнуть пользователя в состояние лёгкого шока.
В поисках решения обеспокоенные пользователи бросаются на форумы и хорошо, если найдётся грамотный специалист, который поможет разобраться в ситуации, но чаще всего им приходится выслушивать приговоры в духе «полетел винт», «меняй хард» и прочее. Да, тут есть от чего прийти в уныние. В реальности всё может оказаться не так уже и плохо. Возьмём для примера такой «критически важный» показатель как «Нестабильные сектора» (Current Pending Sector Count). В CrystalDiskInfo этот показатель имеет ID С5.
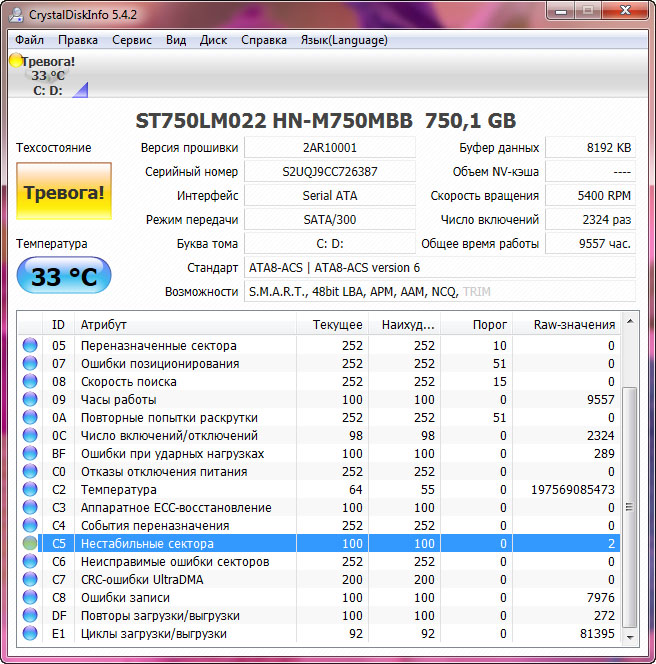
Появление нестабильных секторов не обязательно свидетельствует о физической деградации магнитной поверхности диска, как это ошибочно утверждается некоторыми. Чаще всего их причиной становятся именно программные ошибки, возникающие вследствие сбоев или внезапного отключения компьютера. По сути, Current Pending Sector Count — это сектора, по которым ожидается решение. Если при чтении сектора у контроллера возникают некие затруднения (не удалось прочитать сектор с первого раза, медленное чтение), то он помечает его как нестабильный. Если в дальнейшем с чтением помеченного сектора проблем не возникает, то он удаляется из таблицы и значении С5 уменьшается, что означает «выздоровление» диска.
Если ошибки чтения повторяются, контролер делает ремап сектора и опять выбрасывает его из таблицы. При этом показатель С5 уменьшается, а значение параметра 05 (Reallocated Sector Count) увеличивается. Рост значения С5 — ещё не повод для паники, но за диском всё же необходимо установить наблюдение. Есть примеры, когда данные на дисках без проблем читались при 1000 и более нестабильных секторов.
Если же увеличиваются оба показателя и притом быстро, делайте резервную копию ваших файлов, вот тут диску действительно угрожает опасность, хотя даже в таком случае он может прослужить приличный срок. И только при растущем показателе С6 (Неисправимые ошибки секторов) начать резервное копирование данных нужно как можно скорее. Рост значения этого параметра указывает либо на то, что в резервной области диска закончилось место, либо на физическое разрушение магнитной поверхности диска или серьёзные проблемы в работе механики накопителя.
Что делать при появлении нестабильных секторов
Если другие показатели SMART относительно стабильны, серьёзных проблем чтения/записи не возникает, то предпринимать активных действий не нужно. Лучше оставить диск под наблюдением. С запуском Chkdsk /f/r также можно повременить, так как вследствие повышенной нагрузки на диск она может спровоцировать ускоренное решение по неопределённым ещё секторам и отремапить из них потенциально хорошие. Если всё же решитесь на обслуживание диска Chkdsk, обеспечьте максимально качественную вентиляцию корпуса, так как перегрев диска при длительном сканировании может привести как раз к противоположному результату.
![]() Загрузка…
Загрузка…